
基于计算机视觉的中药饮片分类技术综述与案例研究
2022-11-08 12:43张谊万华涂淑琴
计算机应用 2022年10期
张谊,万华,涂淑琴
(华南农业大学 数学与信息学院,广州 510642)
0 引言
中药饮片包括了原形药材和经过切制、炮制后的饮片[1],可直接用于中医临床用药。由于药材本质的真伪、炮制方式的不同及储存情况对饮片药效起着关键作用,饮片鉴定成为了传统中医用药安全及促进中药饮片产业化发展的当务之急。传统人工鉴别的方式采用我国著名的中药学家谢宗万提出的“辨状论质”方法[2],依靠人的经验根据中药饮片的形、色、气、味等特征判断饮片的优劣。该方法虽然有一定的直观性、实用性,但个人主观性以及专业能力等方面的影响会造成判断结果的差异。
在信息技术高速发展的今天,中医药信息化建设是使中医药走向现代化的必然选择。中医药信息化是集中整合中医药信息资源、改善中医药服务质量、促进信息交流和知识共享的重要手段。相较于传统的人工鉴定手段,图像处理技术能够更好地提取中药饮片图像和结构化数据的各种特征,再结合分类识别模型对中草药进行区分,有效克服人为鉴别的主观性影响,为中医药研究提供筛选参照。基于此技术背景,深度学习有望在饮片识别、质量评级等方面,发挥其优越的性能,提高识别精度,降低人力成本。
本文对近年来中药领域计算机视觉的应用现状进行综述,为药物分析研究者在筛选饮片上提供计算机视觉识别参考。
1 计算机视觉在中药图像识别的应用
计算机视觉是模拟人类视觉系统[3-4],对视觉信息进行捕获,在人为不干预或少干预的情况下对图像内容进行解读。在计算机视觉领域中,常见的数字图像处理技术有图像增强技术[5]、图像压缩变换[6]、边缘锐化[7]、图像分割[8]、特征提取技术[9]、图像识别[10]等,常用的识别算法主要分为传统识别算法、深度学习算法两大类,如图1 所示。
对于传统中草药识别算法,文献[9-12]采用底层特征提取方法,结合浅层机器学习分类器对药用植物进行分类。对于深度学习算法,张万义等[13]针对黄河三角洲地区特有的17 种中草药利用深度学习算法分类,使训练集分离出来的验证集的平均识别准确率达到了96%。
2 中药饮片图像的预处理
由于图像的质量对识别算法有直接影响,在开始使用算法进行图像识别之前,良好的数据预处理能够提高识别准确度。常用的图像预处理操作如图2 所示。
图像归一化在中草药识别中主要用于对叶片类药用植物位置及朝向进行归一。由于叶片具有良好的对称性,常通过极小转动惯量的方法确定对称轴,进而利用沿对称轴旋转叶片以实现叶片朝向归一化[14]。
图像增强在中药饮片识别领域中常用的处理手段为空间域的平滑、锐化,以达到噪点调整的目的。周法律等[15]利用平滑空间滤波器进行平滑处理,去除图像中比较尖锐的噪声点,提高饮片在图像中可检测性。
图像灰度化通过将彩色图像的RGB(Red Green Blue)三通道转化为单通道,从而提高整个应用系统的处理速度,减少所需处理的数据量。周法律等[15]利用加权平均法将输入的彩色图像灰度化转变成黑白图像,利用灰度门限法将高于某一灰度值的背景与叶片图像分割开。
图像分割是指通过图像处理技术把图像中饮片主体与周围背景分离开来,以对饮片区域进行分析处理。谢树莹等[16]和张宁等[17]将中药图像传递给基于分水岭算法以达到去除背景的目的。张宝文等[18]运用阈值分割法经过反复“分割-均值-迭代”的方法对石楠叶片图像进行分割,利用亮度值将石楠叶片主体与背景分开,如图3 所示。
图像增广通过对饮片图像进行几何变换、调整亮度等方式对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。孙俊等[19]将14 种植物叶片图片经过几何变换得到新的图片以将原数据集扩充至56 626张,增强模型泛化能力。
形态学变换技术包括膨胀、腐蚀等方法,常用于饮片形状特征的边界提取。梁丽金等[20]对饮片显微图像进行脱帽变换、形态学开闭运算、填充等操作得到防风的二值图。
有效的图像预处理手段有助于特征提取及图像分类,表1 为常见的饮片图像预处理方法及作用归纳。
除了表1 所示的方法外,霍夫曼编码、Golom 编码等压缩方法也是常用的数字图像处理手段,但是该方法在饮片图像预处理应用较少。由于中药饮片近似品等的区分以纹理、形状细微特征作为饮片性状鉴别标准,对饮片图像进行压缩处理过度不利于特征提取,以及分类识别。

表1 常用的中药饮片图像预处理方法Tab.1 Common image preprocessing methods of Chinese herbal slices
3 中药饮片图像的底层特征
图像的三大底层特征包括纹理、颜色以及形状。由于中药材物种丰富,即使是属于同一品种的药材,由于生长地区、气候的差异,同样导致质量优劣有别。此外,采收时间或加工方法不同会导致中药饮片的色泽、纹理、大小等性状有所不同,这些差异为图像分类提供了重要的依据,常见底层特征提取方法如图4 所示。
3.1 纹理
中药饮片纹理结构具有高度的复杂性,纹理特征是中药饮片形状鉴别的重要因素。例如,因产地不同导致差异的川黄柏与关黄柏[26],川黄柏内表皮具有细密的纵棱纹,关黄柏内表皮较平滑;同科不同植物根茎的知母与玉竹[27],知母外表皮有少量残存的黄棕色叶基纤维和凹陷或突起的点状根痕,玉竹切面有角质样或显颗粒性。
贾伟等[28]使用Tamura 方法[29]提取白芍等12 种饮片在粗糙度、对比度、方向度、线性度、规整度和粗略度6 个分量的纹理特征。
常见的纹理特征提取手段还有灰度共生矩阵法。陶欧等[30-31]选取羌活等12 味药材利用灰度共生矩阵提取了11 个纹理特征参数。
针对相似纹理的不同药材,王雪琰等[32]和Kan等[33]提出结合纹理和颜色形状特征的方式对药用植物进行特征提取。
由于饮片本身纹理特征的复杂多样性单从糙度、对比度、方向度等几个微观维度衡量饮片纹理仍然具有局限性,还需要多种纹理特征参数结合从而更好描述饮片纹理细节。目前,缺乏统一的数学模型衡量多种纹理参数特征融合效果的优劣程度。纹理提取方法在对复杂环境的感知能力与适应性仍处于研究空白阶段。
3.2 颜色
中药饮片由于本身科属、产地、炮制方式等因素,色泽会有差异。例如,宁夏枸杞色泽红润,而新疆枸杞新鲜时红润,晒干后变暗;陈皮随着存放时间增加,受氧化反应的影响导致表面颜色会变得暗沉。常用颜色直方图法、颜色参量统计特征法等手段提取饮片图像颜色特征。
颜色直方图描述的是不同色彩在整幅图像中所占的比例,适于描述那些难以进行自动分割的图像。如式(1)所示:
其中:k为图像特征值;nk表示特征值k的像素总数;L为特征个数;N为图像总像素数。
程铭恩等[26]利用OpenCV 通过颜色直方图提取彩色饮片颜色特征,使用支持向量机(Support Vector Machine,SVM)分类器对自行采集的大黄等五种饮片的彩色图像进行辨色处理,达到100%的准确率。
颜色参量统计特征法是对彩色图像的颜色参量进行统计、分析和处理,常用RGB、HSI(Hue Saturation Intensity)等模型。HSI 模型在RGB 模型的基础上加入饱和度(Saturation)、亮度(Intensity)两个特征参量,将RGB 模型转化成HSI 模型,如式(2)~(4)所示:
夏永泉等[34]利用HSI 模型对药用植物叶片病斑彩色图像的色调、饱和度分量进行阈值分割,通过去除绿色像素以获取病斑区域。
常用于中药饮片颜色特征提取的模型还有HSV(Hue Saturation Value)模型[22]等。杨涛等[25]通过麦冬病斑图像在RGB 与HSV 颜色空间各颜色分量的一阶矩、二阶矩、三阶矩提取病斑颜色特征,从而实现饮片颜色客观量化。
颜色直方图可以有效描述彩色图像的全局颜色分布情况,但是容易受背景环境干扰。RGB 模型跟颜色直方图有所类似,仅能对色调方面进行分析。通过引入饱和度、亮度、明度等特征可以衍生为HSI、HSV 模型等。目前,利用OpenCV可以实现特定颜色的识别和选取,通过RGB 颜色空间转换可以转换成HSI、HSV 等空间便于颜色特征提取。例如,西洋参与人参的颜色极其相似,单从颜色方面作为提取饮片图像特征指标,容易导致对于饮片图像的识别泛化效果差,系统鲁棒性不高等问题。
3.3 形状
由于药用植物本身有性状区别,形状成为了中药饮片分类的重要标准。不少学者利用饮片边缘形状以及大小进行植物识别。常见的形状特征提取方法有:几何特征计算法、不变矩阵特征法等。
1)几何特征法是对饮片的面积、周长、偏心率、圆形度、矩形度等特征的计算。该方法普遍应用于叶类药用植物特征提取。金梦然等[35]利用tpsDig2 软件对10 种蔷薇科植物叶片轮廓及主叶脉标记,计算特征参数,通过K最近邻(KNearest Neighbor,KNN)分类算法。Kolivand等[36]通过边缘检测、叶片边界去除、曲线提取、色调归一化图像生成和图像融合5 个步骤完成了物种识别。
2)不变矩阵特征计算法是对饮片图像区域特征的描述,矩不变量对饮片图像的放缩、旋转、平移具有不变性。金力等[37]利用Hu 不变矩结合几何特征法提取12 种药用植物叶片的10 个形状特征,使用灰度共生矩阵法提取5 个纹理特征,通过SVM 分类器分类,平均识别率达到93.3%。
叶类中草药的边缘主要分为锯齿状、波状、全缘、牙齿状等,例如,茜草叶片边缘呈细锯齿状,连钱草为凸波缘。常用的边缘直方图、边缘方向直方图提取植物外部轮廓。Anami等[38]从900 幅药用植物图像中利用边缘直方图和边缘方向直方图获得边缘特征。
形状特征提取虽然对叶类饮片有比较好的描述效果,但该方法在根茎类饮片应用仍存在较大的挑战。由于根茎类饮片的切制方法多样,如斜切、横切、纵切等,不同的切制方法边缘特征提取效果不同,一定程度上的影响识别结果。结合纹理、颜色、形状的多特征融合手段可以更全面地描绘饮片特征,以达到更好的分类效果。
4 中药图像的分类模型
中药识别算法主要有基于机器学习、模式识别的传统算法和基于卷积神经网络(Convolutional Neural Network,CNN)的深度学习算法,其发展历史如表2 所示。
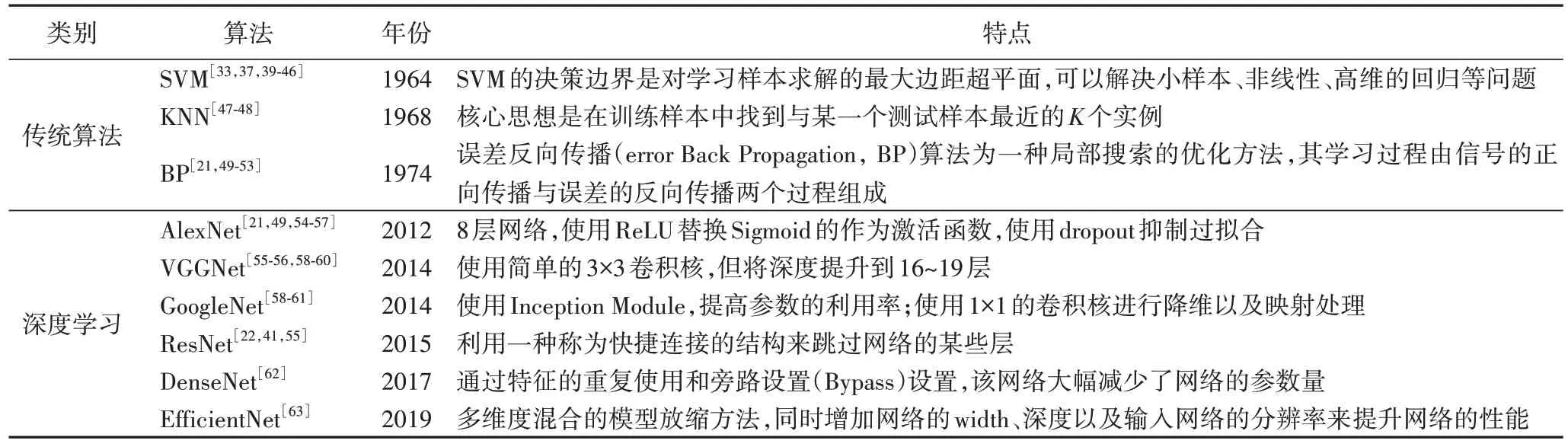
表2 中草药识别常用算法举例Tab.2 Examples of common algorithms for Chinese herbal medicine recognition algorithms
4.1 传统算法
传统算法指的是基于浅层机器学习模型,利用神经元构建的浅层神经网络,该网络由输入层、隐藏层和输出层构成。目前在中药领域的浅层机器学习模型主要有误差反向传播(error Back Propagation,BP)算法[21,49-53]、SVM[39-40]、KNN[47]等算法。
4.1.1 SVM
SVM 分类器在20 世纪90 年代在图像识别、文本分类等场景中有很好的应用。SVM 具有算法简单、训练短时等优点,但是存在对于核函数的高维映射解释力不强以及对缺失数据敏感等问题。
陆楷煜等[41]利用融合纠错输出编码(Error Correcting Output Codes,ECOC)的支持向量机(SVM)识别模型对UCI(University of California,Irvine)数据集32 种640 张植物叶片图像进行训练、分类,识别率达92%,识别效果较好。
Mahajan等[42]提出了一种利用自适应助推技术结合支持向量机(SVM)从相应叶片图像中提取形态特征的植物物种识别模型。
4.1.2 KNN
与其他算法不同,KNN 没有参数训练过程,简单、易于理解。KNN 对每个待测试样本都要计算它到事先加载在内存中的已知样本的距离,导致计算复杂度高、内存消耗大。
王雷宏等[47]基于灰度共生矩阵提取胡颓子属植物的纹理特征,构建KNN 分类模型准确率达到了93.75%。谢文涌等[48]将人工培养6 个品系的金线莲叶片图像经过纹理、颜色特征融合,构建以逻辑回归、KNN、随机森林和梯度提升决策树为基分类器的Stacking 分类模型。
4.2 深度学习算法
深度学习算法主要分为卷积神经网络和循环神经网络,在计算机视觉领域应用最多的是卷积神经网络[64]。卷积神经网络在原来多层神经网络的基础上,加入了更加有效的特征学习部分,具体操作就是在原来的全连接的层前面加入了部分连接的卷积层与池化层。目前在中药识别领域应用的深度学习算法主要有GoogleNet[58-61]、VGGNet[55-56,58-60]、ResNet[22,41,55]、AlexNet[21,49,54-57]等。
4.2.1 AlexNet
产供集团目前也正为研究堆开发新型燃料。产供集团总裁纳塔利娅·尼基佩洛娃9月25日在一次会议上表示,对于产供集团,研究堆燃料市场的重要性不亚于商业反应堆燃料市场。产供集团在研究堆燃料领域与国外伙伴开展了大规模合作,根据客户的特定需求提供燃料。
AlexNet 于2012 年提出,具有8 层网络结构,大约有6 000 万个参数。AlexNet 使用层叠的卷积层来提取图像的特征,同时使用dropout 进行训练。该算法利用ReLU()取代Sigmoid 作为激活函数,有效提高收敛速度;但是带来了死神经元的问题,在小于0 的地方会出现神经单元死亡,并且不能复活的情况。其网络结构如图5 所示。
黄方亮等[21]在百度图片爬取5 类中草药共计3 000 张图片,经过图像增广将数据集量增加到12 000,在AlexNet 下准确率为87.5%。王艳等[49]对长白山野外实习采摘的15 种中草药经过AlexNet 算法分类识别,平均识别精度为99.38%。
4.2.2 VGGNet
VGGNet[55-56,58-60]采用堆叠3 个3×3 卷积核的方式来替代1 个7×7 的卷积核,以保持和7×7 卷积核一样的感受野。随着卷积核尺寸的减小,参数量大幅减少,因此收敛速度更快,过拟合的风险也降低了。VGGNet 在2014 年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛中,赢得了定位任务的冠军,在分类任务中排名第二。VGGNet的网络结构如图6 所示。
左羽等[54]将经典卷积神经网络VGGNet 16 与全卷积网络(Fully Convolutional Network,FCN)相结合,把VGGNet 16中两个通道数为4 096 的全连接层改为卷积层,构造一个新的VGGNet 16 模型为植物图像分类模型,在植物图像分类上的准确率达到97.23%。樊湘鹏等[55]对VGGNet 16 结构改进和优化,在病害叶片检测平均准确率为98.02%,单幅图像平均检测耗时为0.327 s。陈雁等[56]在VGGNet 下对何首乌等60 种中药饮片进行分类,分类准确率优于AlexNet。
4.2.3 GoogleNet
AlexNet、VGGNet 等算法主要通过增加网络的深度以达到更好的分类效果,但网络层数增加的同时也带来了梯度消失、overfit、梯度爆炸等问题。GoogleNet 于2014 年面世,该分类算法使用1×1 卷积核进行降维以及映射处理,引入了Inception 结构(图7)以融合不同尺度特征信息。
GoogleNet 的网络架构的主要特点就是提升了对网络内部计算资源的利用。相较于AlexNet 和VGGNet,GoogleNet 添加两个辅助分类器帮助训练,从而提高低层网络的分类能力、阻止网络中间部分梯度消失。同年,GoogleNet 获得ImageNet 竞赛的分类任务冠军。
4.2.4 ResNet
ResNet[22,41,55]利用Shortcut Connection 结构(见图8)来跳过网络的某些层,以3.57%的Top5 错误率赢得了2015 年ILSVRC 比赛的冠军。当增加网络深度时,VGGNet 精度会达到饱和,然后很快下降。为了解决这个问题,ResNet 引入了快捷连接,网络的输出不是y=F(x),而是残差块的输出y=F(x) +x或y=F(x) +ωx(当F(x)的维度与x不同时,需要将x调整到相同的维度),从而将网络学习过程由直接构造原始输入的函数转变成构造相较于原始输入的扰动特征函数,降低了学习的难度,反向传播时梯度也可以快速回传,解决了深层次网络退化问题。
刘捷[61]利用植物数据集训练VGGNet、GoogleNet、ResNet以及ResNet-inception 网络模型,分别得到79.8%、90.4%、89.7%、92.8%的准确率。
4.2.5 DenseNet
鉴于ResNet 模型训练生成的网络中存在有的层贡献很少的局限性,Huang等[67]于2017 年提出了DenseNet(见图9),该模型脱离了传统的网络层数加深、网络结构加宽机制,使用了跨层连接及以前馈方式,每个层都会接受其前面所有层作为其额外的输入。相较于ResNet,DenseNet 旁路加强了特征的重用且具有更少的参数量,有效缓解了梯度消失(gradient vanishing)、模型退化(model degradation)的问题,更易于训练。
吴云志等[62]将87 867 张植物病害图像分别在DenseNet169、ResNet50 和MobileNet 下实验,发现在DenseNet169 下识别效果最好,得到测试集识别准确率为98.23%。
除了以上介绍常用于中药饮片分类的算法外,还有SqueezeNet[68]、ShuffleNet[69-70]、MobileNet[71-73]、ESPNet(Efficient Spatial Pyramid Network)[74-75]、FBNet(Facebook Berkeley Nets)[76-78]、EfficientNet[79-80]、SkipNet[81]等轻量级CNN如表3 所示,其主要特点是在保持精度的前提下,从体积及速度两方面对网络进行轻量化。虽然现阶段神经网络在GPU 上运行速度已经可以达到实时性要求,但是移植到手机端或者其他设备上还存在运行速度的问题,测试速度过慢会导致用户时间上等待的负担。在移动设备上推理速度上的提升尤为重要,而轻量级CNN 研究在此方面具有良好的优势。
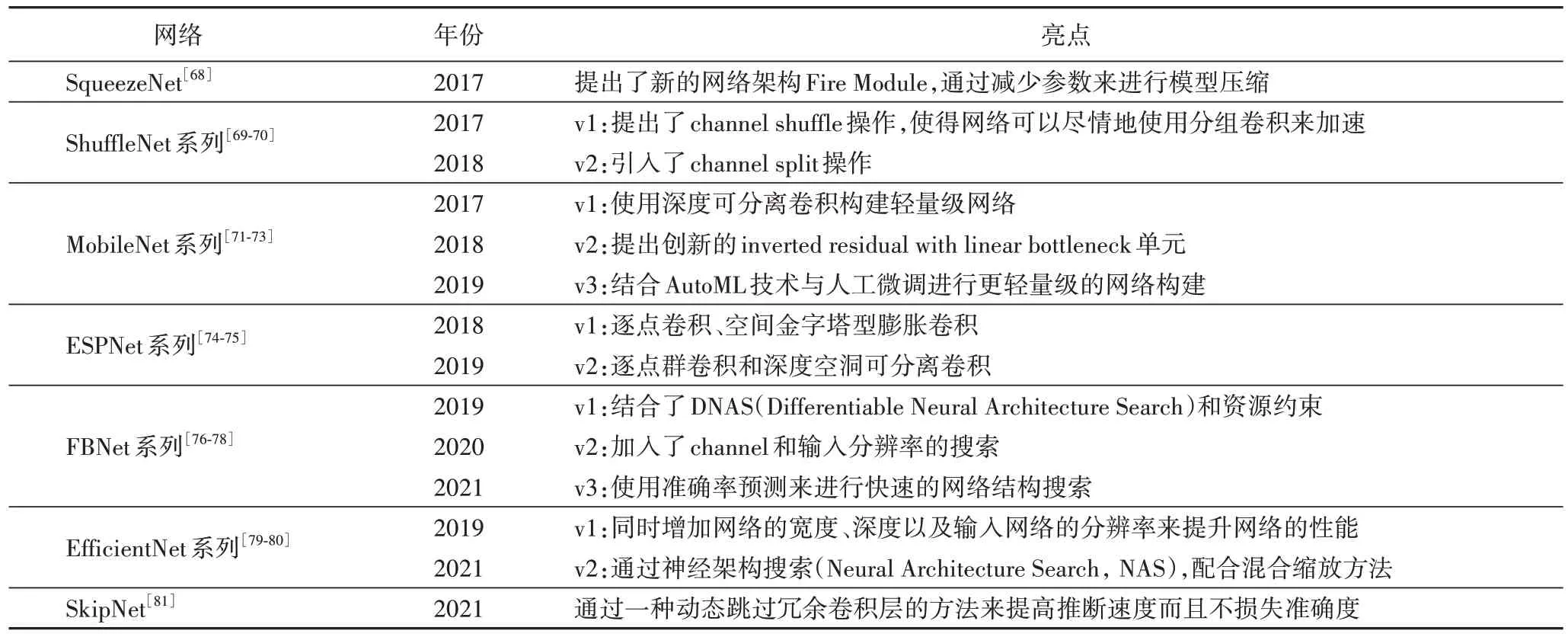
表3 常用的轻量级CNNTab.3 Common lightweight CNN
5 案例研究
5.1 数据集情况
实验数据集包括12 类饮片(图10,括号中的数字为该饮片对应的标签序号),参照2020 版《中国药典》一部对中药饮片图像进行筛选,筛选后得到共9 156 张图片,其中,3 702 张图片来自网络,手工拍摄5 454张,拍摄工具是华为荣耀50se。针对形态相似的花类、根茎类饮片做图像分类,数据集具体分布情况如图11 所示。利用留出法(Holdout cross validation)按照固定比例将数据集静态划分为训练集、验证集、测试集,三者比例为6∶2∶2。
5.2 特征提取
对于传统分类方法,利用HOG 提取饮片图像特征。深度学习模型由于卷积核有提取特征的功能,故不另做传统特征提取。
5.3 实验结果
对自建数据集进行分类测试,利用以下指标对模型进行性能评估:准确率(Accuracy)、召回率(Recall)、精确度(Precision)、特异性(Specificity)以及混淆矩阵。表4 为饮片图像在各分类网络下利用宏平均法的实验结果。
Accuracy、Recall、Precision、Specificity的计算公式分别如式(5)~(8)所示:
其中:TP(True Positive)为真实是正确类,预测成正确类的样本数量;FP(False Positive)为真实是错误类,预测成正确类的样本数量;TN(True Negative)为真实为错误类,预测成错误类的样本数量;FN(False Negative)为真实是正确类,预测成错误类的样本数量。
在本次案例分析实验中由于所挑选的根茎类中药饮片性状特征较为相似,常常容易被误判,ShuffleNet v2 相较于其他算法表现出更好的分类效果。如图12 所示,红芪在不同分类模型下预测示例中,只有ShuffleNet v2 正确识别出了红芪。如表4 所示,ShuffleNet v2 表现最佳,Precision为91.4%,Recall为90.0%,Accuracy为98.6%,比同为轻量级网络的MobileNet v2在Accuracy上高2.2 个百分点。
图13 为ShuffleNet v2 下饮片图像的混淆矩阵,横轴表示中药饮片图像的真实标签值,纵轴表示每类中药饮片图像的预测标签值,标签序号对应的饮片图像如图10 所示,对角线上的数值代表每一类图像中被正确分类的数量,颜色越深代表该中药饮片类别预测准确的数量越多。如混淆矩阵所示,ShuffleNet v2 对于本身区分特征不够明显或者由于拍摄角度没拍出其鲜明特征的相似饮片图像,仍出现误判状况。对于本身区分特征不够明显或者由于拍摄角度没拍出其鲜明特征的相似饮片图像,仍出现误判状况。例如,在该算法下金边玫瑰由于相较于其他品种具有花托上有金色窄边的鲜明特点,准确率较高,但是主要依赖大小以及叶柄小叶数量区分的重瓣玫瑰与月季在各网络中常被误判。
5.4 实验分析
如表4 所示,基于卷积神经网络的分类算法比传统浅层机器学习算法在图像分类上存在较大优势。由于饮片图像涉及多种特征,单一利用HOG 提取图片边和角等特征有较大局限性,利用传统浅层机器学习方法分类需要尝试多种不同的提取特征方法,工作量较大。利用深度学习方法通过卷积核可以有效提取图片特征,工作量较小且可以达到良好的识别效果。ResNet 参照VGGNet 使用3×3 卷积核,并在此基础上加入Shortcut 结构,使得ResNet 在更深的网络得以有效训练,在计算效率跟准确率上相较于VGGNet 有明显的提高。ResNeXt 提出aggregrated transformations,利用平行堆叠相同拓扑结构的blocks 代替原来 ResNet 的三层卷积的block,通过分组卷积机制减少超参数,降低复杂度,还提高了性能。ResNet 与ReNeXt 分类效果较好,适用于药企等单位进行精细化饮片筛选,减少员工工作量,但是存在内存需求量大且测试时间较长等问题。
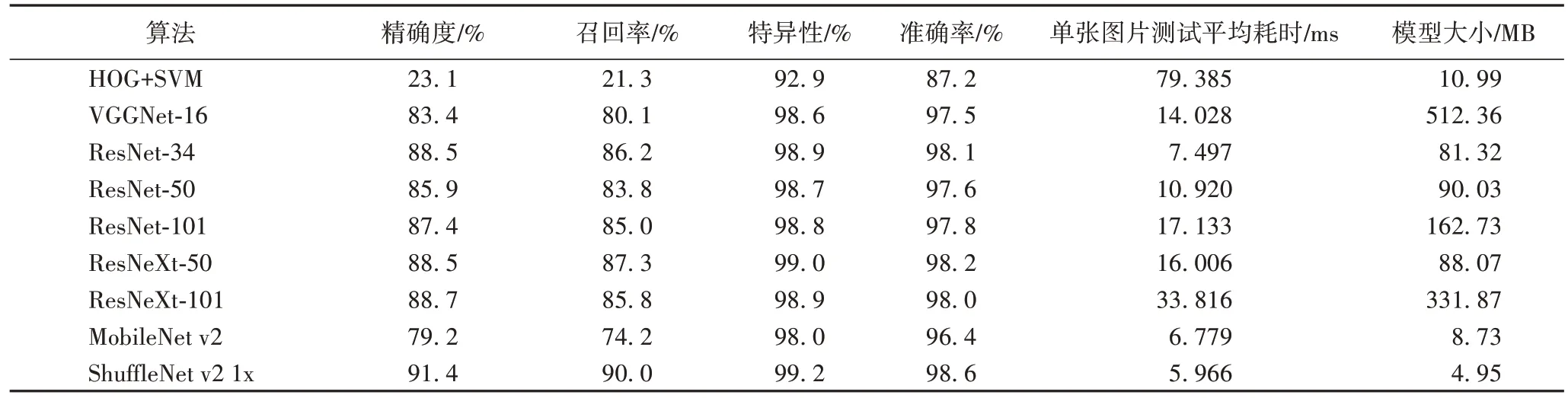
表4 各算法分类结果Tab.4 Classification results of different algorithms
随着轻量级CNN 的快速发展,SqueezeNet、ShuffleNet 等轻量级网络逐渐活跃在大众视野中。MobileNet v2 在沿用MobileNet v1 的Width Multiplier 的基础上,借鉴ResNet 引入残差结构,通过先升维再降维的方式,减少3×3 模块的计算量,提高残差模块的计算效率。本文实验中MobileNet v2的Recall为74.2%,而模型大小为8.73 MB,远比VGGNet-16、ResNet 小。ShuffleNet v2 提出channel split 操作,在加速网络的同时进行了特征重用,在本文实验中Recall为90.0%,Precision为91.4%,均比MobileNet v2高,模型大小接近MobileNet v2 的一半。MobileNet 与ShuffleNet 测试速度快、内存需求量小且运算量小,适用于基于移动设备辅助广大群众日常对药食同源的饮片进行选择。
除了以上网络外,还有VGGNet 的演变RepVGG、ResNet的发展ResNeSt 以及近期比较火热的Transformer 等网络,在中药饮片识别上仍存在较大发展空间。RepVGG 借鉴ResNet 残差结构的特点,在VGG 网络的Block 中加入了Identity 和残差分支,可用于饮片图像分类时处理深层网路中的梯度消失问题,使得网络更加易于收敛。ViT(Vision Transformer)基于自注意力机制,相较于CNN,ViT 更善于把握整体,具有在区分饮片形状细微特征的优势。叶类饮片晒干易碎,可借助ViT 在叶片边缘形状鉴别上的优势区分。将不同网络的优势相结合以提高不同状况中药饮片识别的性能具有较大发展潜力。
6 目前存在的问题与展望
虽然目前计算机视觉在中药饮片分类研究领域取得了一些突破,但在实际应用上还是有很大的发展空间。本文通过对目前计算机视觉在中药领域存在的应用范围、分类算法改造、数据集的建立等方面进行归纳和总结,希望能为领域内研究人员提供新的探究方向与思路。
1)在应用领域方面,目前研究多是对中药饮片类型的判定,采用计算机视觉方法应用中药饮片质量等级鉴定、真伪判别、霉变情况、道地药材筛选等的研究仍然处于空白阶段。尤其是基于细粒度识别对同种饮片人工栽培品,野生品的区分,具有较大的市场推广潜力。在饮片识别领域普遍为单目标分类,缺乏对多目标识别的研究。多目标识别可应用于在复方中对饮片的识别,帮助大众了解认识中药饮片以及常见配伍。
2)在数据集方面,目前在中药领域研究多针对鲜活植物数据集,缺乏中药饮片图像的标准数据集。相较于鲜活植物,饮片在炮制方式、存储状况方面具有更大的研究挑战性。
3)不同研究者使用的饮片数据库各不相同,难以比较不同算法的性能优劣和鲁棒性。不同背景、光源下的图像数据集的缺乏,直接导致识别模型泛化能力差,识别精度易受复杂背景干扰。本案例中数据集所采用图片多为主体明显的图片,后期需要补充复杂背景、不同光源下主体不明显的饮片图像。
4)大部分中药材都需要经过切片、晒制或烘焙等流程,经过这些流程,颜色、形状等特征的特异性被减弱,分类难度被提高。饮片单一特征提取分类效果较差,单特征具有可变性、不确定性,直接影响识别的稳健度。HOG 目前在行人检测领域有很好的效果,但是在本次案例研究中,HOG+SVM在识别月季以及不同品种的玫瑰上表现较差,由于其主要针对纹理特征忽略了颜色特征的作用。因此,需要结合多种底层特征或者结合深度学习方法提取饮片本体特征以提升分类效果。
5)饮片识别算法大多数是探索性的,没有一个统一的评价标准,所以难以实现饮片种类系统之间的定量比较。在算法改造上,目前研究显示深度学习相较于传统算法的性能有了较大提升,但算法的鲁棒性和可解释性方面需要更深入的研究。在本次实验中,各分类网络对于本身区分特征不够明显或者由于拍摄角度没拍出其鲜明特征的相似饮片图像常出现误判,仍需要进行更多分类网络改进等方面的研究。
7 结语
本文针对计算机视觉在中药饮片领域的应用,介绍了图像分类技术在中药饮片方面的相关原理和知识,并对图像预处理、特征提取、分类网络等方法以及研究现状进行深入探讨。这些方法对基于计算机视觉的饮片分类研究具有很好的指导价值。
中药饮片筛选是中医临床用药必不可少的部分,基于计算机视觉技术可以辅助企业饮片筛选智能化,帮助大众认识中药。虽然传统分类算法方法在外观特征区别较大的中药饮片有很好的表现,但是面对性状相似饮片,深度学习方法的分类效果明显高于传统分类算法。在中药饮片图像分类领域中,目前面临着饮片图像标准数据集缺乏、没有统一的评价标准等问题。面对性状相似饮片区分的挑战,在网络结构改进方面的研究具有很大的发展空间。
猜你喜欢
天津药学(2022年4期)2022-09-14
药学实践杂志(2022年3期)2022-05-27
中草药(2022年10期)2022-05-24
康颐(2020年15期)2020-11-10
软件(2020年3期)2020-04-20
保健与生活(2019年7期)2019-07-31
家庭用药(2017年12期)2017-12-27
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
中国民族民间医药·上半月(2013年1期)2013-11-01
