
并行多尺度特征融合的热层析图像分割算法
2022-10-18 01:03胡长康李凯扬
计算机工程与应用 2022年19期
胡长康,李凯扬
武汉大学 物理科学与技术学院,武汉 430072
医学热层析技术通过捕获人体热信息分析癌细胞代谢异常的区域,以热图的形式对人体体内的热源信息进行层析分析,已临床用于乳腺癌的检测。为了提高临床医生的诊断效率和准确率,本文通过对热层析图像进行语义分割,将病变区域和人体正常组织清晰地分割开来,可以辅助医生分析病灶区域的大小、位置、边界等信息。然而病变区域占比很小,而且在热层析图像上形态学特征不明显。因此,本文针对小目标的细节分割展开的研究,有着重要的意义。
近年来,深度学习算法的兴起使得图像的语义分割领域得到了蓬勃的发展。主流上多是通过下采样进行特征提取,获取图像的抽象特征。再通过上采样恢复图像的分辨率,还原空间信息,并通过特征融合、模块优化实现对每一个像素点的分类。
医学图像分割领域的U-Net[1],通过跳跃连接,实现了多尺度的特征融合,适合在小样本上的分割训练。Deeplab 系列[2-4]提出了空洞卷积和空间金子塔池化,实现了多尺度的特征提取,从而增强全局的语义信息。后续很多基于这些经典模型而改进的分割算法,2018年,Dong等人[5]提出了一种U-Net++模型,让模型能够在训练过程中能自行选择下采样的深度。
2019 年,Zhou 等人[6]提出了基于DenseNet 和U-Net的DenseU-Net网络,并针对语义分割的类不平衡问题,提出了一种中值频率平衡的加权损失函数,实现对小目标的精细分割。2020 年,Huang 等人[7]在U-Net++的基础上提出了U-Net3+模型,利用全尺度的跳跃连接和深监督的思想,改善了U-Net++没能从多尺度中提取足够特征的不足。曹源等人[8]提出了一种基于委员会查询的自步多样性学习算法。通过委员会查询的方式实现数据挑选,将训练数据按照由易到难的顺序导入训练,应用到肺部器官分割和视网膜分割上取得了较高的Dice指标。Qian等人[9]提出了一种编码/解码的肺CT图像分割算法,将多尺度的图像作为输入,通过残差网络结构和空洞空间金字塔池化(ASPP)相结合的方式提取多尺度特征信息。在LUNA16 数据集上相似性系数做到了99.56%。2021 年,Wang 等人[10]在传统模糊C-均值聚类(FCM)算法基础上,改进了一种快速自适应非局部空间加权与隶属度链接的FCM算法,用于噪声图像分割,在分割精度和运行时间上均优于传统FCM算法。Zhao等人[11]将半监督学习和主动学习策略相结合,开发了一种深度主动半监督学习框架,依照一定的标准挑选弱标记和强标记样本,该算法在多种医学图像数据集上都表现出了良好的性能。Pang 等人[12]提出了一种名为SpineParseNet的两阶段框架,分别由用于二维残差分割的ResU-Net和用于三维粗分割的三维图卷积分割网络(GCSN)组成。将其用于对体积磁共振图像的脊柱分割,取得了(87.32±4.75)%的平均Dice相似系数。
然而,由于医学热层析技术尚未广泛普及,目前针对热层析图像的语义分割技术还没有得到较好的应用。热层析图像存在数据量匮乏,形态学特征不明显,病灶边界不清晰等困难。同时,还具有小尺度目标带来的类不平衡问题。上述的经典算法很难直接得到较为精细的分割,不过主流的算法采用的跨层融合的思想对恢复图像细节很有帮助。深层的特征图对图像的抽象信息具有很好的表征能力,但丢失了太多的细节信息。将其与浅层的特征融合正好弥补了细节的捕捉能力。
在跨层融合的思路上,本文专注于尽量发挥这种特征融合的思想。即设计一个层与层间反复特征融合的网络,让模型在训练过程中可以自行选择特征融合的程度。Sun 等人[13]提出的高分辨率网络(hign resolution network,HRNet)用于人体的姿势估计,在特征提取端采用了一种并行连接多分辨率子网的结构。基于上述两种思想,本文设计了一种并行的多尺度特征融合模型,在U-Net 的基础上,取代了U-Net 模型串行连接的结构。在整个上采样和下采样的过程中,同时保持各个分辨率子网的表示,将多分辨率子网并行连接,通过反复的特征融合,实现层间信息不断的交换。整个过程保持着高分辨率和低分辨率特征的存在,从而提高模型对细粒度的捕获能力。
本文的主要贡献如下:
(1)提出了一种并行的,多尺度特征融合的分割网络模型,该模型能让自身在训练过程中决定特征融合的程度,能够在保证语义信息准确的前体下,更好的抓取细节特征。
(2)采用一种基于双重阈值的非线性映射算法,处理原始热层析光感值数据。着重将病灶区域的温度细节保留,而忽视背景区域的温度细节,生成更易于模型分割训练的灰度图像数据。
1 并行多尺度特征融合的热层析图像分割算法
考虑到模型深度上的拓展容易导致训练过程中,梯度反向传播时发生梯度消失等现象。本文选择面向宽度方向拓展模型,基于HRNet的多分辨率子网并行的思想,整体上设计了一种端到端的并行连接的分割架构。为了弥补模型反复特征融合导致的参数陡增,修改了一种适用于本模型的瓶颈结构modified bottleneck作为基本单元。选择最大池化实现下采样,采用基于双线性插值法的上池化操作恢复特征图的尺寸,并通过通道拼接Concat 进行特征融合。为了更好的应对小目标分割带来的类不平衡问题,采用了一种适用于三分类的中值平衡的交叉熵损失函数。
1.1 并行多尺度特征融合模型结构
特征提取作为卷积神经网络抓取图像信息的手段,一直是语义分割算法的重点优化对象。除了拓展特征提取的网络深度,以捕获更丰富的语义信息之外。目前很多提升模型宽度的思想,包括InceptionNet 的聚类操作[14],Deeplab系列中的空间金字塔池化模块等。
本文的网络结构整体上采用了对高分辨率特征逐级下采样,提取到低分辨率的抽象特征之后,再通过逐级上采样以恢复图像的尺寸的思想。然后通过不断的特征融合以达到对分割细节的把握,如图1所示。为了避免在特征复原的过程中极易丢失大量的空间和细节信息,造成对分割不连续或者小目标的丢失,本文在模型的架构设计上,整个特征提取的过称中,都没有选择丢弃高分辨的特征,而是让各个分辨率的子网并行向前。维持高分辨率的表示,相当于维持着细节特征。并且可以让模型有条件进行反复的特征融合。
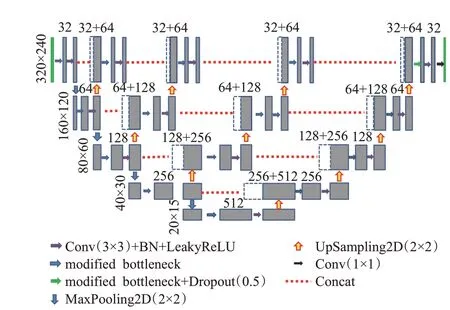
图1 并行多尺度特征融合分割模型结构Fig.1 Structure of parallel multi-scale feature fusion segmentation model
模型以高分辨率子网作为第一阶段开始,通过一种改进的瓶颈结构取代一部分标准的3×3 卷积。这种结构可以使网络更加轻量化,弥补并行拓展带来的参数消耗。模型共分五层,第一层保持原始图像的分辨率,特征图通过瓶颈结构的卷积运算后,再通过一个标准的3×3卷积,输出图像的特征通道数维持在32。在经过瓶颈结构和标准卷积之后都会与下一层子网的上采样特征进行通道融合,采用的是Concat 的方式对特征图进行通道合并,其中上采样是通过基于双线性插值的Unsampling。融合之后再次通过一个瓶颈结构和一个3×3 标准卷积,将特征通道数维持在32,依次递推到输出层。网络的第二层以第一层的下采样开始,通过的是掩膜为2×2 的最大池化,分辨率缩小一倍之后,特征通道数在通过连续两个瓶颈结构的特征提取之后调整到64。然后与下一层子网的上采样特征进行通道融合,融合之后再次通过一个瓶颈结构和一个标准的3×3卷积,依次递推到该层子网的末端。每一层都采用这种构建思路,第五层的特征通道数达到了512,包含着最抽象的特征。
为了减少模型训练过程中过拟合,本文在第一层子网的输出层之前引入了随机失活层(dropout layer),起到正则化的作用。在每一个瓶颈结构之中,都在卷积层和激活函数之间加入了批量归一化层(batch normalization,BN)[15],用来加快模型训练收敛的速度。整个结构通过带修正的线性单元LeakyReLU 函数作为激活函数,为模型来提供非线性因素,同时可以避免ReLU 函数导致的静默神经元(dead neuron)。网络的输出通过1×1 的卷积压缩通道数至分割的类别数,通过Softmax函数对每一个像素点进行多分类。为了应付小目标空间占比小,导致的像素级类不平衡问题,本文引入一种中值平衡的交叉熵损失函数,通过对各个类别交叉熵的系数进行中值平衡,以实现不同目标类别对损失值贡献的平衡。
本文模型设计的初衷,就是提高分割网络抓取细节特征的能力,这主要得益于的并行多尺度特征融合的思想。本文构建了不同分辨率的子网,输入数据经过卷积层和池化层不断地特征提取,从高分辨率子网传递到深层的低分辨率子网上。因此,低分辨率子网包含着更丰富的抽象语义信息,而高分辨率子网上则维持着空间上的细节特征。本文通过设计这种并行的网络结构,始终维持各个分辨率子网的表示,以便在层间进行反复的多尺度特征融合,使空间细节信息和抽象的语义信息更好的结合。模型在做到细节分割的同时可以兼顾对语义信息的准确把握。然而,该算法也伴随着一定的实现成本,模型要始终维持高分辨率子网的表示,带来了复杂的模型结构和较大的参数量;同时,反复的特征融合,使得计算机在Concat计算的过程中,需要不断开辟新的内存来保存中间特征,这会占用更大的显存,也会增加模型训练的时长。
1.2 基于HRNet的并行特征融合方式
本文模型设计的核心思想是通过反复的特征融合来提高模型对感兴趣区域的细节分割能力。HRNet 为本文提供了一种并行子网连接的思想,来实现反复的特征融合。该模型是由微软亚洲研究院针对人体姿势估计所提出。模型从一个高分辨率子网开始,将高分辨率和低分辨率子网逐层增加,形成多分辨率的子网层,然后将这些子网层并行连接,其间进行反复的多尺度特征融合。这使得每个分辨率子网层都可以从上下相邻的子网层中反复接受信息,在输出端保证了信息更丰富的高分辨率表示。这种并行多尺度融合方式的设计思路分为三个步骤:
第一阶段是构建连续的多分辨率子网,现有的姿势估计网络都是通过将高分辨率和低分辨率子网串联,每个子网由一系列卷积组成,子网之间通过下采样层实现分辨率减半。设Lsr为第r层第s阶段的子网络,不同的r表示不同的分辨率,则连续的多分辨率子网结构如图2所示。
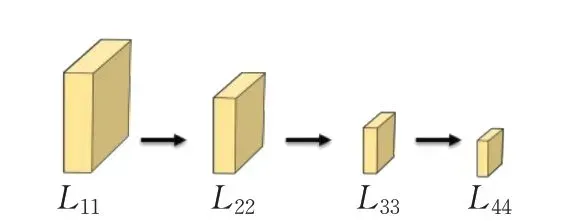
图2 连续多分辨率子网Fig.2 Sequential multi-resolution subnetworks
第二阶段是构建并行的多分辨率子网,在第一阶段的基础上,再横向地拓展每一层子网络。各层分辨率子网都从Lii开始,一直往后都保持着本层分辨率的表示,其间通过一些步长为一的卷积保证特征尺寸不受改变。再将各层子网并行连接,形成并行的多分辨率子网络结构,一个三层的子网络结如图3所示。
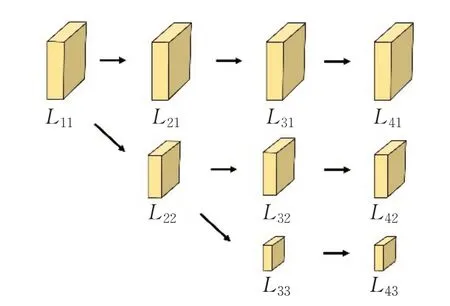
图3 并行多分辨率子网Fig.3 Parallel multi-resolution subnetworks
第三阶段是实现重复的多尺度特征融合,HRNet为了实现每个子网能够反复地从其他并行的子网接受信息,引入了特征融合单元,每个特征融合单元由多个交换块组成,每个交换块由多个并行的卷积单元Csr,以及一个交换单元组成,如图4所示。
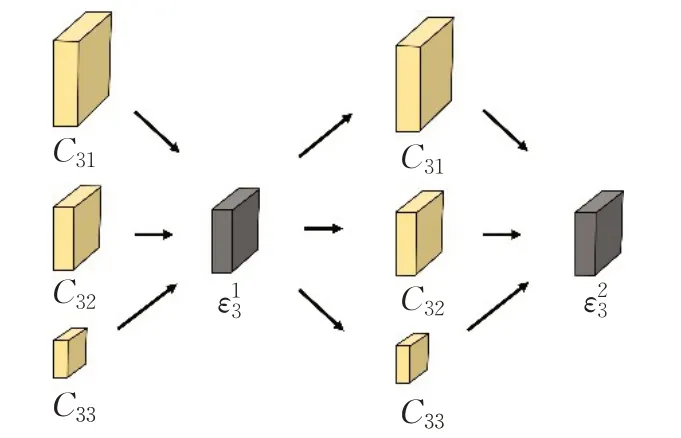
图4 反复的多尺度融合Fig.4 Repeated multi-scale fusion
1.3 修改的瓶颈结构
本文模型在通过浅层和深层之间反复的特征融合之后,增加了网络对细节信息的恢复能力,但同时也导致更为庞大的运算量。为了让模型参数上更加轻量化,本文修改了一种瓶颈结构Bottleneck 作为基本单元,使得更加适合于本文的网络拓扑。
Howard 等人[16]提出的MobileNet,作为一种轻量化模型。其深度可分离卷积(depthwise convolution,DC)的使用,相比于常规卷积,参数量得到了大幅降低,如图5 所示。它由逐通道卷积(depthwise convolution,DWConv)和逐点卷积(pointwise convolution,PWConv)两个部分结合。DW Conv要求卷积核的数量必须与上一层的通道数一致,在相应的通道上进行卷积。一个filter始终是一个二维的卷积核,同时对应输入和输出特征图的一个通道,因此,DW Conv无法调整输出特征图的通道数,同时也无法融合相同位置上在不同通道上的空间信息。而PW Conv 是1×1 的标准卷积,正好可以弥补这一点。相比于常规卷积的每一个filter都要直接提取输入图像多通道的空间信息,深度可分离卷积这种分步卷积大大减少了参数量。
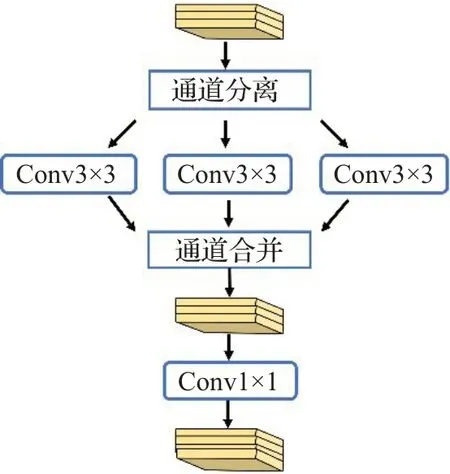
图5 深度可分离卷积Fig.5 Depthwise separable convolution
既然,1×1 的PW Conv 可以调整通道数,用于减少参数量,那么就不妨先将通道数降低,再结合深度可分离卷积,将参数量进一步减小。实际上是两个1×1 的PW Conv 分别控制特征通道数的降低和还原,中间采用DWConv连接成一个瓶颈结构,如图6所示。这种深度瓶颈结构(deeper bottleneck architectures,DBA)在Resnet 中融合进了残差模块[17],其中在旁路的恒等映射,作为残差学习单元的精髓,可以保证Resnet 的网络拓扑就算达到很深也容易被训练。考虑到本文的模型结构主要是横向的扩展,而非深度的叠加,所以本文调整的瓶颈结构舍弃了旁路的恒等映射。
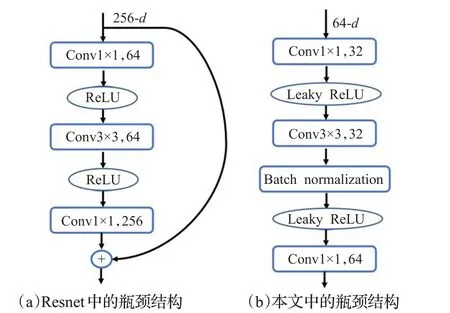
图6 两种瓶颈结构Fig.6 Two bottleneck structures
1.4 损失函数
本文研究的任务是对乳腺癌恶性病例的医学热层析图像进行语义分割,对我们感兴趣的目标,包括病变区域的恶性肿块和恶性血管进行精细化分割。感兴趣目标连同背景一共可分三个像素类别。因此本文选择多分类的交叉熵损失函数,用来面描述每个像素点的类别在概率分布上,预测结果与真实结果的差异。因为多分类的交叉熵损失只用考虑分类正确的情况,并且搭配Softmax 函数的输入求导简单,可以加快权重更新的速度。多分类交叉熵损失定义为:

由于医学热层析图像上我们感兴趣区域(恶性肿块和恶性血管)的占比非常小,其类别像素出现的频数占比小,就导致在对每个像素的类别进行分类的过程中存在严重的类不平衡问题,从而使这种交叉熵损失基本由背景类别贡献。为了让模型损失函数的注意力集中在我们感兴趣的两个目标上面,本文引入了一种平衡交叉熵损失函数,将每个类别的样本对损失的贡献进行一个不同系数的加权。区别于加权交叉熵损失,本文的损失函数对每个类别,包括背景也会进行系数限制。这种平衡交叉熵损失可以定义为:

平衡系数βi对应每个类别的权重,为了平衡各个类别对损失的贡献,尤其是突出人们感兴趣却又占比小的恶性血管和恶性肿块部分。本文采用一种中值频率平衡[18]的算法来确定系数βi:
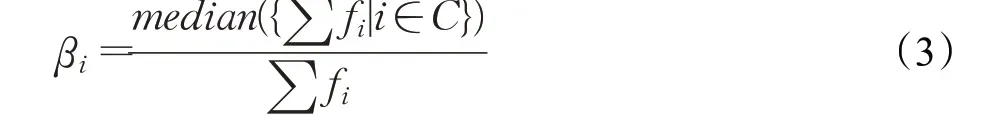
其中∑fi是每个包含了第i类的所有图像在i类上的像素总和,C是类别数的集合,median()函数是对各类别像素总和求中位数。取中位数与某类像素总和的比值作为该类在交叉熵损失上的平衡系数,可以保证原本在图像中占比小的类别对应的系数大于1,而占比大的类别对应的系数小于1,达到平衡的效果。本文基于中值频率平衡的交叉熵损失,有助于提高图像中占比小的类别对损失值的贡献,可有效防止血管分割不连续,肿块分割丢失等问题。
2 实验过程
2.1 实验环境
为本文算法在实验上配置的环境如表1所示。
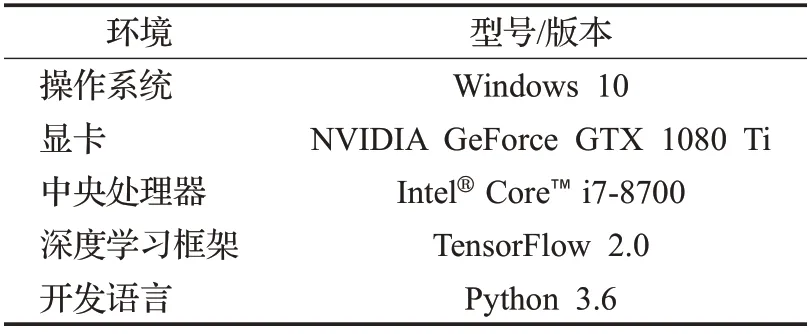
表1 实验环境配置Table 1 Experimental environment configuration
2.2 数据集介绍
本文使用的热层析图像数据集,由自主研发的医学热层析仪在相关合作医院采集而来。针对女性乳腺癌的检测,采集到由14 位的感光值描述的人体二维温度数据[19-20]。本文通过数值转换算法,将其生成更易于网络训练的灰度图像数据。从数据池中挑选出确诊的恶性病例,然后对脏数据进行清洗,去除掉拍摄角度不佳,环境噪声干扰大的样本。通过降噪和图像尺寸调整后,由临床专业人员进行像素级的手工标注,得到936例可供监督学习的数据集。训练数据样本由320×240 大小的灰度图像数据和对应的掩模标签组成,标签按像素类别被标注为恶性肿块、恶性血管和背景三类。经过数据增强后,本文近似于6∶2∶2 的比例划分了训练集3 370例,验证集1 120例,测试集1 126例。
2.3 数据处理
2.3.1 基于双重阈值的非线性映射转换策略
热层析仪采集到的人体乳腺区域的温度信息,以14位光感值数据表征为二维图像矩阵。整个光感值数域范围在区间0~214-1,而正常的室温背景以及人体温度下,得到的光感值数据基本分布在区间[2 500,4 500]。而且其间包含了大量的环境温度噪声,以及做分割任务不感兴趣的背景低温区域。人体乳腺病变区域会因为异常代谢,体现出与周围组织温差的异常。如果直接用光感值数据进行训练,这种温差异常通过光感值数据的反映体现得很微弱,难以被分割模型捕捉到这种病变区域的特征;此外,大量的背景温度噪声也会包含其中,对模型的训练带来干扰。因此,如图7 所示,本文采用一种双重阈值的策略将光感值数据映射成0~255 的灰度图,并维持原始的分辨率大小。其中Tmin和Tmax分别表示低温阈值和高温阈值对应的光感值。该算法可以尽量保留病灶区域的温度细节信息,而滤除环境背景的温度信息。
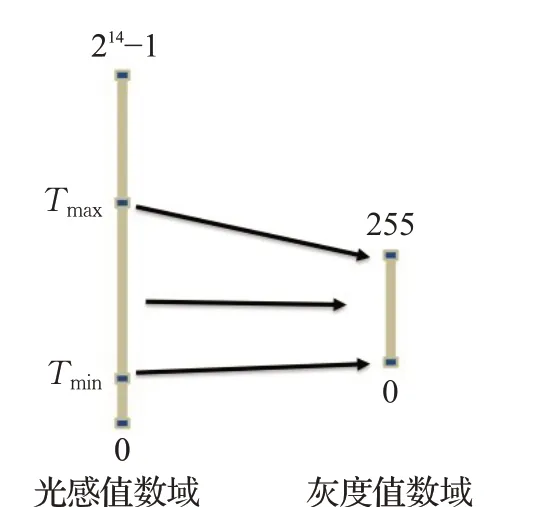
图7 基于双重阈值的转换示意图Fig.7 Schematic diagram of transformation based on double threshold
因为病灶区域表征为人体高温区域,因此,本文算法对两种阈值选定的敏感度不同。如果两种阈值没能准确拟合到人体的最高和最低温区域,Tmax偏高和Tmin偏低都会使人体温度信息进一步压缩,会导致分割精度降低。若Tmin偏高,则会抹掉了人体低温区域的温度信息,容易导致分割结果的边缘信息丢失。而Tmax偏低则会截断人体高温病灶的信息,模型将无法捕获分割目标(病灶)的特征。可见,模型对高温阈值有着更高的敏感度,并且需要尽量准确设置两种阈值。
本文对所有挑选的热层析光感值数据分析光感值的低温阈值门限和高温阈值门限。两种阈值设定的思路就是尽量不截断人体温度信息。由于热层析图像统一采集人体正面上半身的温度信息,而人体的相对低温区域主要集中在腹部,即图像的中部偏下的区域。因此,选取每份样例坐标为[160,0]的固定像素点作为人体低温代表点,用该点的光感值来拟合人体的低温区的光感值,再取所有样例的低温代表点对应的最小光感值,作为低温阈值门限。这样既保证了统一的低温阈值门限,又不会截断人体温度信息。通常热层析仪检测人体的时候,都会控制背景温度低于人体温度,作为感兴趣的人体病变区域往往因为代谢异常表征为高温区域。所以为了尽量不压缩人体病变区域的特征,我们选择每一份样例的光感值的最大值作为其高温阈值门限。所有的样本享有统一的低温阈值门限和特有的高温阈值门限。最后将所有光感值数据转化为0~255 的灰度图像数据,对于光感值低于低温阈值门限的像素点映射到灰度值为0,对于高于高温阈值门限的像素点灰度值映射到255,两个阈值之间的数据按等比例压缩映射到0~255之间,映射效果如图8所示。
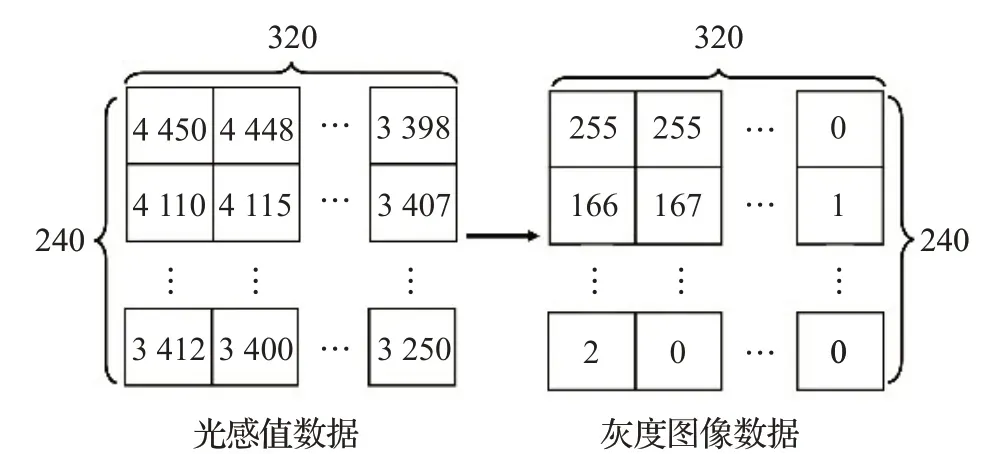
图8 光感值数据到灰度图像数据的转换效果Fig.8 Renderings of conversion of light sensitivity data to grayscale image data
2.3.2 数据增强和数据预处理
为了减小模型训练的结构化风险,提升模型的鲁棒性,本文对所有样本进行了数据增强处理。包括水平方向和垂直方向的镜像翻转,以90°角为单位的随机角度旋转,以及不同尺度的图像裁剪。最后针对上文的低温阈值门限,调整了适当的门限高度再做映射变换,作为了一种新的数据增强方式。
为了提升模型在梯度下降过程中寻找最优解的速率,本文在将数据导入训练之前先进行零均值化和归一化处理,通过约束训练数据的分布来加快模型的收敛速度。
2.4 训练策略
2.4.1 优化策略:
为了较高的计算效率和较低的内存消耗,本文采用带有动量项的Adam优化器[21]。利用梯度的一阶矩和二阶矩的预算来计算出各个参数学习率的更新步长,得到自适应的学习速率。该算法分别计算了梯度和梯度平方的指数衰减平均值,并通过两个参数β1和β2调节这两个指数衰减率:其中θt是网络的可训练参数,η为学习率,∈是一个很小的参数,可以防止分母被置零。本文算法对上述参数的设定为学习率η取0.000 1,β1取0.900,β2取0.999,∈为1E-8。


2.4.2 迁移学习策略
为了加快并优化模型的学习效率,本文借助了迁移学习的策略,先利用公开数据集(ImageNet)对网络进行预训练处理,再以预训练权重初始化模型权重可以加快训练速度。对本文应用的热层析小数据集来说,可以得到更好的性能。
2.5 实验细节
本文将所有训练数据按小批量进行训练,每个batch由打乱顺序的8张图片组成,由数据生成器不断地返回8×320×240×1 格式的张量导入模型的输入。将每个batch 对应的标签转化成8×320×240×3 的One-hot 编码的格式导入模型的输出,与预测输出计算出平衡交叉熵损失值。将每个batch的选择带动量的Adam优化器,初始学习率设为0.000 1,动量为0.900。对所有训练数据迭代一轮需要422 iterations,在每一轮迭代结束后用验证集数据对模型进行评估,保存表现最佳的权重参数,并对所有的数据迭代120 epochs。训练结束后加载保存的最佳权重模型,利用各项评估指标在测试集上进行评测和分析,得到预测的分割结果。为了对比分析本文算法的优势,在相同的实验条件下,分别对U-Net、DenseUNet、U-Net3+等模型在本文的热层析数据集下进行了训练和测试。
3 实验结果与分析
3.1 评估函数
本文用作评测模型训练结果的评估函数主要包括以下指标:像素精度(pixel accuracy,PA),用来描述一个batch 内分类正确的像素点占所有像素点总和的比重;均交并比(mean intersection over union,MIoU),表征为每一个类别预测的像素区域与真实标签的像素区域的交集与并集之比,在所有类别上的均值;类别像素准确率(class pixel accuracy,CPA),针对每个类别,所有分类预测正确的像素点占所有被预测为该类的像素点的比例;平均像素准确率(mean pixel accuracy,MPA),类别像素准确率在所有类别上的均值;召回率(Recall),也是针对每个类别而言,所有分类预测正确的像素点占该类在真实标签上的所有像素点的比重,其计算公式分别如下:
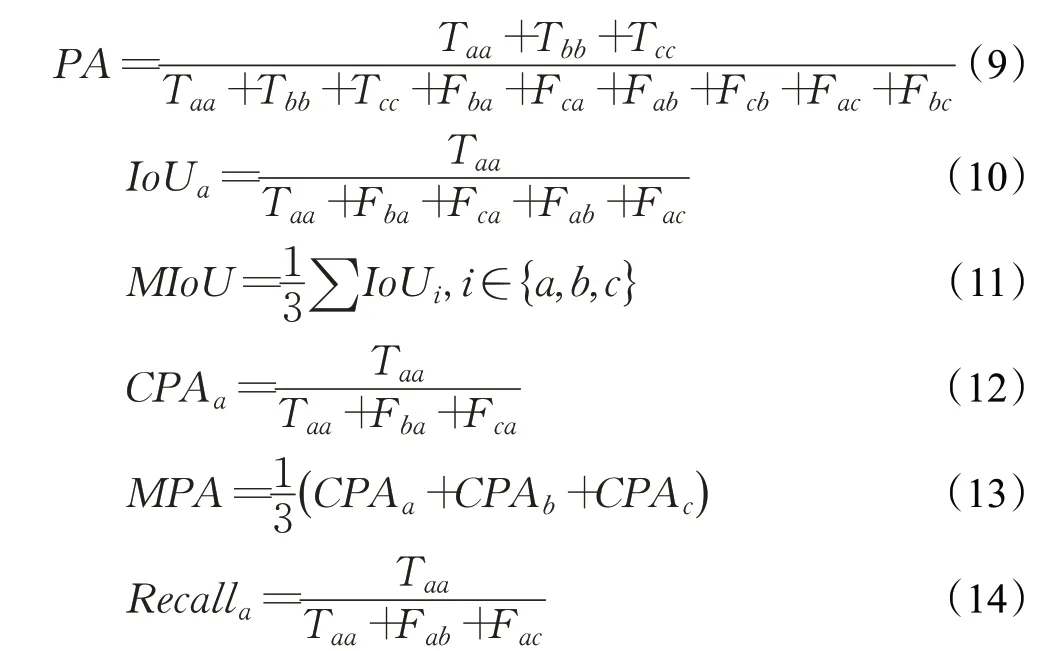
其中Recalla、CPAa、IoUa分别对应类别a的召回率、类别像素准确率和交并比。Taa、Fab、Fac、Tbb、Fba、Fbc、Tcc、Fca、Fcb分别对应图9的三分类混淆矩阵:
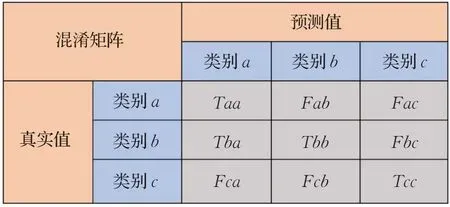
图9 基于三分类的混淆矩阵Fig.9 Confusion matrix based on tri-classification
3.2 实验结果
3.2.1 模型结构对比实验
为了验证本文工作的现实意义,在医学热层析数据测试集上进行了多指标的评估分析,得到了分割的结果。同时为了论证本文算法的改进点,利用相同的训练策略分别对U-Net、DenseU-Net 和U-Net3+等模型在我们的数据集上进行了训练和测试,得到各评估指标的结果如表2所示。
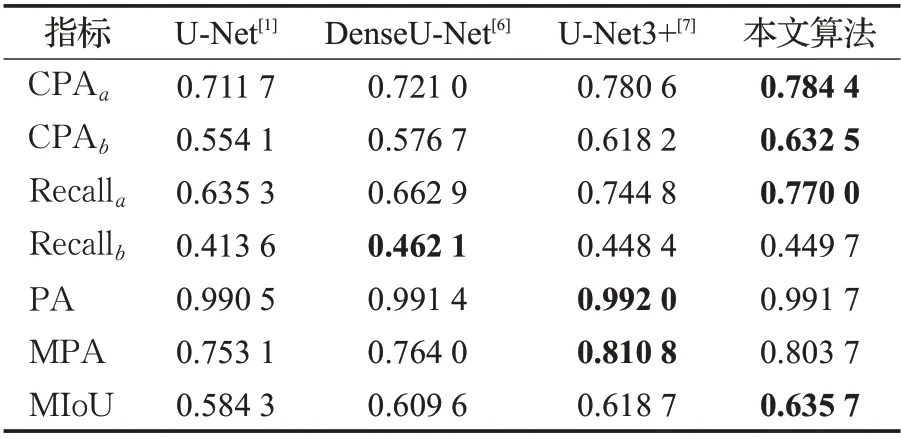
表2 不同模型在热层析数据集上的测试性能对比Table 2 Comparison of test performance of different models on thermal tomography datasets
其中CPAa、Recalla分别代表实验中恶性肿块的类别像素精度和召回率。CPAb、Recallb分别代表实验中恶性血管的类别像素精度和召回率。相比于经典的U-Net模型,本文算法在MIoU上有了5.14个百分点的提升,总体分割效果有了显著改善。相比于DenseU-Net模型,虽然在恶性血管类别上的召回率要略低,但是在肿块和血管的类别像素精度等其他指标上都要优于DenseU-Net,可见在热层析乳腺肿瘤的分割任务上,本文算法有着一定的优势。相比于U-Net3+模型,本文算法在像素精度PA和平均像素精度MPA上均不占优势,但是在肿块和血管的单类别指标和MIoU 值上表现更优。PA 和MPA 的劣势应该主要体现在背景类别上,背景类别占比大,导致对总体像素精度的统计上有着更大的贡献。但本文算法对感兴趣的肿块和血管类别的分割要更加准确,说明本文的并行多尺度特征融合模型对热层析数据小目标的分割精度有着不错的改善。
为了验证分割算法开发具有现实意义,本文将训练好的网络模型对热层析测试集数据进行预测。分割结果可视化可以明了地对比各个模型预测的精确度。图10分别展示了原始图像、标签图像以及以上4种模型的分割结果。其中红色区域表示恶性肿块,绿色区域表示恶性血管,黑色区域表示背景。
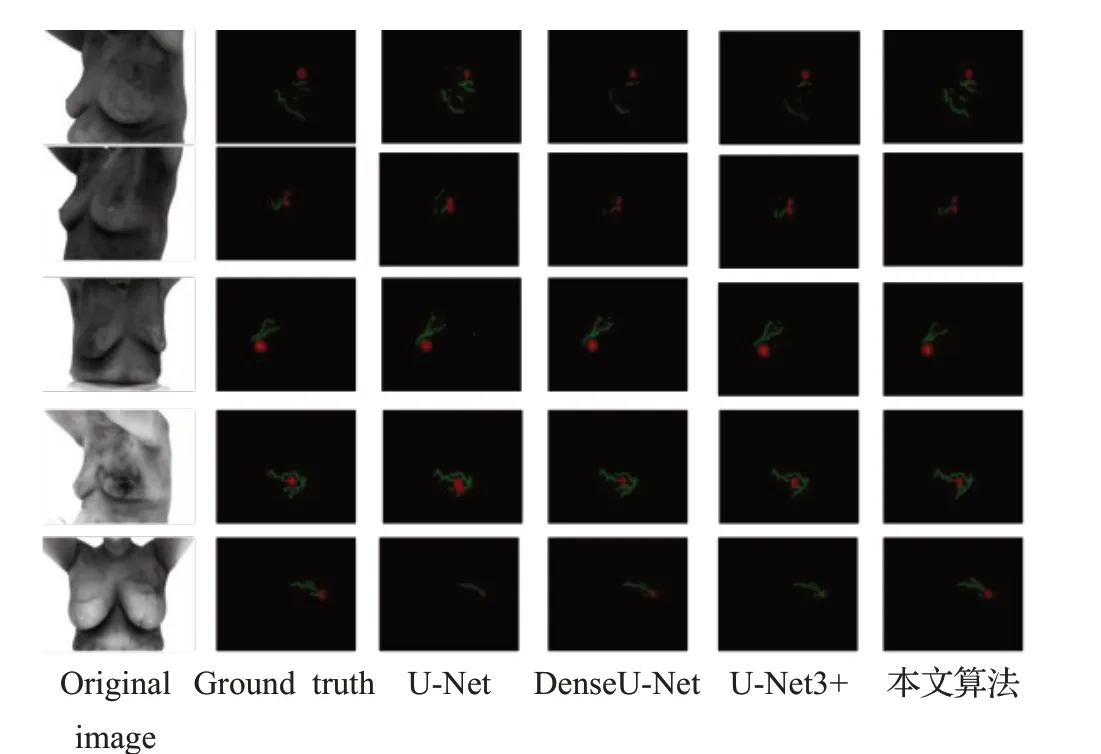
图10 不同模型在热层析数据集上的分割结果Fig.10 Segmentation results of different models on thermal tomographic datasets
为了检验本文分割算法在不同类型的图像上的分割能力,本文利用DRIVE数据集,做视网膜血管图像的分割任务。这是由40 张565×584 大小的数字视网膜图像组成的数据集。并将分割效果和U-Net模型做对比,测试结果如表3所示。

表3 在DRIVE数据集上的性能对比Table 3 Performance comparison on DRIVE dataset
其中Se 表示灵敏度,即分割正确的血管像素点总和占标签图上血管像素点总和比例;Sp表示特异性,即分割正确的非血管像素点总和占标签图上非血管像素点总和的比例。实验分割结果如图11所示。
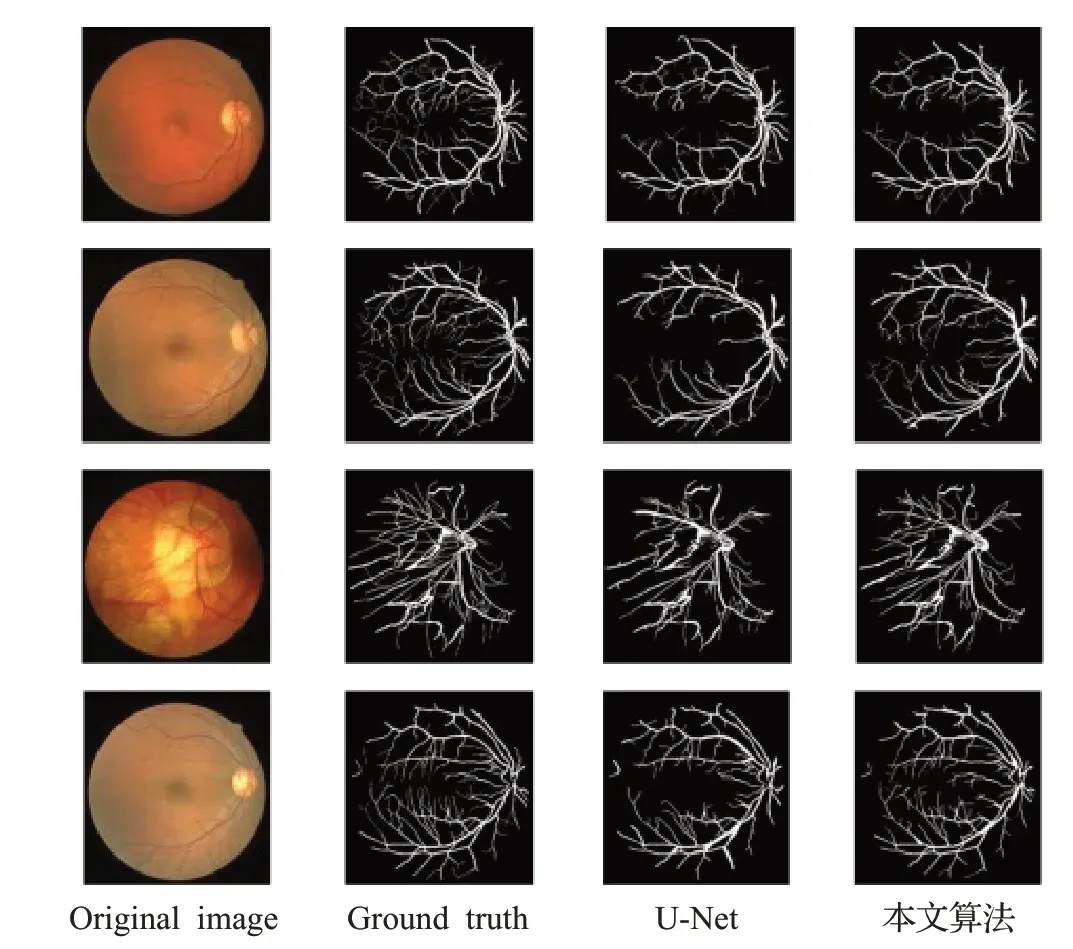
图11 在DRIVE数据集上的分割结果对比Fig.11 Comparison of segmentation results on DRIVE dataset
相比于U-Net模型,本文算法在Se上的指标高出了5.07个百分点,说明本文算法血管分割上更为准确。从分割结果对比来看,本文算法对细小血管的分割效果也更好。因此,如果不在意模型计算成本的增加,同时期望做到对细微目标的分割,那么本文改进的分割算法对热层析以外的医学图像分割任务便有着重要的参考价值。
3.2.2 基于双重阈值的非线性映射转换策略对比实验
本文利用双重阈值策略对原始光感值数据进行映射,放缩到了8位灰度图像数据。为了验证该算法的实际意义,用原始光感值数据作为训练数据,与映射后的灰度图像数据进行对比实验,在相同的算法和实验条件下,测试结果如表4所示。
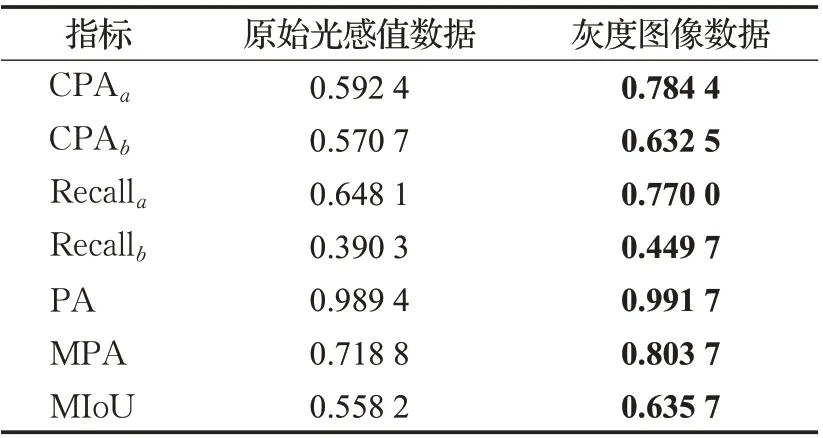
表4数据转换前后测试性能对比Table 4 Comparison of test performance before and after data conversion
实验说明,基于双重阈值的非线性映射转换策略对原始光感值数据的处理对模型性能有着很大的提升。光感值数据虽然能够准确的反映人体的温度信息,但同时也包含很多人体背景和环境的热源信息,会对模型的训练造成很大的干扰。我们通过低温阈值门限阈值的设定,可以有效地滤除大部分背景噪声带来的干扰;通过每个样本特有的高温阈值门限的设定,可以突出人体病灶区域的温度特征,而忽略人体其他部位表征的温差。保证病灶区域温度分布的细节信息进入网络训练,更有助于模型对病变区域的精细分割。本文分割任务将背景和人体病灶以外的区域都归为一个语义类别(背景类),不存在对背景区域的精细化分割。因此,该算法对背景区域温度细节的忽视对有效信息完整性影响不大。但是一味的忽视背景带来的干扰,会降低模型的鲁棒性,对背景干扰大的测试数据泛化能力不强。
4 结束语
热层析图像分割技术的实现对热层析应用于人体乳腺癌的早期诊断、病情分析和手术计划有着很大帮助。现阶段常用于医学图像分割的模型对恶性血管和恶性肿块的分割都存在细节信息丢失,分割不精细等问题。本文设计了一种基于HRNet 模型的并行多尺度特征融合的分割网络,修改Resnet中的瓶颈结构作为基本模块,并将原始数据经过双重阈值的非线性映射转换成更易于训练的灰度图像数据。在热层析小数据集上相比于U-Net 模型有着明显的提升。相比于U-Net3+和DenseU-Net,本文对恶性肿块和恶行血管类别的形状和边界细节上的分割也要更加准确。
未来的工作可以考虑将条件随机场引入模型的后处理,进一步提升模型分割的精度,但也会伴随大量的计算参数。此外,训练数据的标注成本高昂,导致可供训练的数据量太小,可以尝试主动学习的方式改善模型对数据量的依赖。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
现代电子技术(2022年11期)2022-06-14
计算技术与自动化(2022年1期)2022-04-15
建材发展导向(2021年19期)2021-12-06
现代计算机(2021年10期)2021-05-28
现代计算机(2021年3期)2021-03-24
少儿画王(3-6岁)(2020年4期)2020-09-13
上海师范大学学报·自然科学版(2019年5期)2019-12-13
东方教育(2018年20期)2018-08-22
