
基于深度卷积网络与空洞卷积融合的人群计数
2019-12-13 08:26盛馨心苏颖汪洋
上海师范大学学报·自然科学版 2019年5期
盛馨心 苏颖 汪洋

摘 要: 利用空洞卷积设置不同空洞率,得到不同感受野的特点,提出一种基于深度卷积Visual Geometry Group19(VGG19)和空洞卷积相融合的结构.所采用的结构不受输入图像尺寸以及分辨率影响,通过设置锯齿状空洞率,扩大网络的感受野,在保持分辨率良好的情况下,可以较为精确地定位目标,提高检测准确性.经验证,该算法在Shanghai-tech标准数据集上具有较高的实验准确率.
关键词: 人群计数; Visual Geometry Group19(VGG19); 空洞卷积; Shanghai-tech数据集
中图分类号: TN 919.8 文献标志码: A 文章编号: 1000-5137(2019)05-0479-06
Abstract: A combined structure based on Visual Geometry Group19(VGG19) and dilated convolution with different receptive field was proposed for high density crowd counting in the paper.The structure adopted would not be affected by the size and resolution of the input image.By setting the serration dilation rate,the network receptive field was expanded,and the target could be accurately localized without any loss of resolution,which improved the accuracy of detection.Finally,the experimental results showed that the algorithm had higher accuracy on the standard data set of Shanghai-tech.
Key words: crowd counting; Visual Geometry Group19(VGG19); dilated convolution; Shanghai-tech data set
0 引 言
人群计数是一种视觉认知任务,目的在于准确估计拥挤场景中的人数,通过对目标区域的人群数量进行分析,能够对许多社会安全问题起到一定的预警作用,从而实现资源的合理分配和调度.因此,人群计数问题已经成为计算机视觉领域的重要课题[1].然而人群在场景中的分布是多种多样的,人群之间的遮挡、光照不均等各种干扰因素使人群计数问题仍然具有挑战性.
由于卷积神经网络(CNN)在各种视觉任务上取得的成功,许多针对人群计数的多尺度CNN架构[2-3]性能取得了显著的提升,这些方法通常采用多列卷积网络估计静止图像中的人群数目.多列网络通常采用两列或三列对图像特征进行提取,并通过不同卷积核获得不同大小的感受野,解决尺度变化等问题.受图像分割的启发,空洞卷积[4]能够在不影响分辨率的情况下扩大感受野,让每个卷积的输出包含较大范围的信息,弥补池化操作过程中信息的损失;而全卷积神经网络[5]没有全连接层,全部采用卷积层对图像进行特征提取,因此输入图像的大小可以是任意的,同时可以大大减少参数量.鉴于空洞卷積和全卷积网络的特点,本文作者采用全卷积的网络架构,以空洞卷积代替深度卷积网络的全连接层,不仅可以扩大图像的感受野,还能减少网络的参数量,提高了实验的准确率和数据集的训练速度.
2 基于深度卷积和空洞卷积融合的网络架构
2.1 空洞率分析
2.1.1 不同空洞率分析
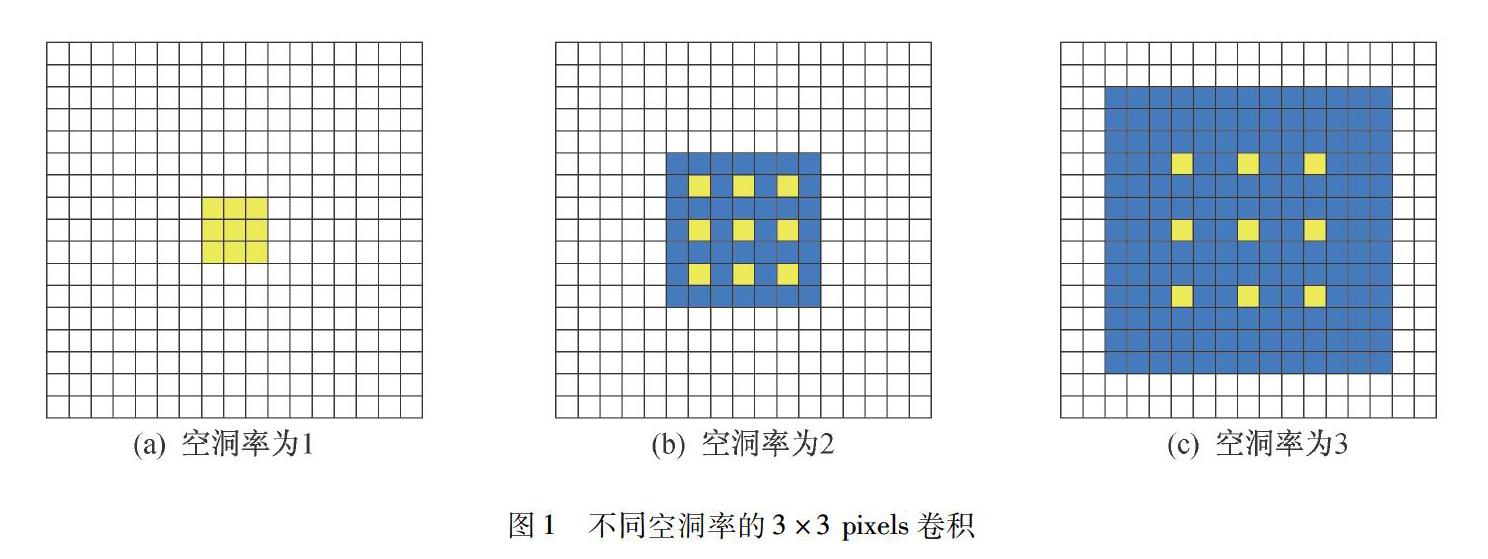
传统的CNN对图像进行卷积操作之后再进行池化操作,在降低图像尺寸的同时增大感受野,但是池化层在降维的过程中会丢失一些重要信息,对提取图像特征有一定的影响.通过图像分割[4]实验可知,空洞卷积既能增大感受野又不丢失图像信息,如图1所示.
图1(a)对应空洞率为1的卷积.图1(b)对应空洞率为2的卷积,虽然实际的卷积核尺寸仍是3×3 pixels,但是相比于普通卷积,其感受野较大.如果前一层是空洞率为1的卷积,那么空洞率为2的卷积中每个像素点是前一层卷积的输出,单个像素点的感受野为3×3 pixels,因此2层卷积的感受野为7×7 pixels.图1(c)对应空洞率为3的卷积,与图1(b)同理,其感受野为13×13 pixels.
实施步长为1的普通3×3 pixels卷积操作,三层之后,感受野才能达到7×7 pixels,而进行空洞卷积,两层操作之后,感受野就能达到7×7 pixels.在不进行池化操作的情况下,空洞卷积操作能较快增大感受野,让每个卷积输出都包含较大范围的信息.
叠加卷积的空洞率不同且最大公约数为1的结构称之为锯齿状结构,符合条件的空洞率称之为锯齿状空洞率.
2.1.2 相同空洞率分析
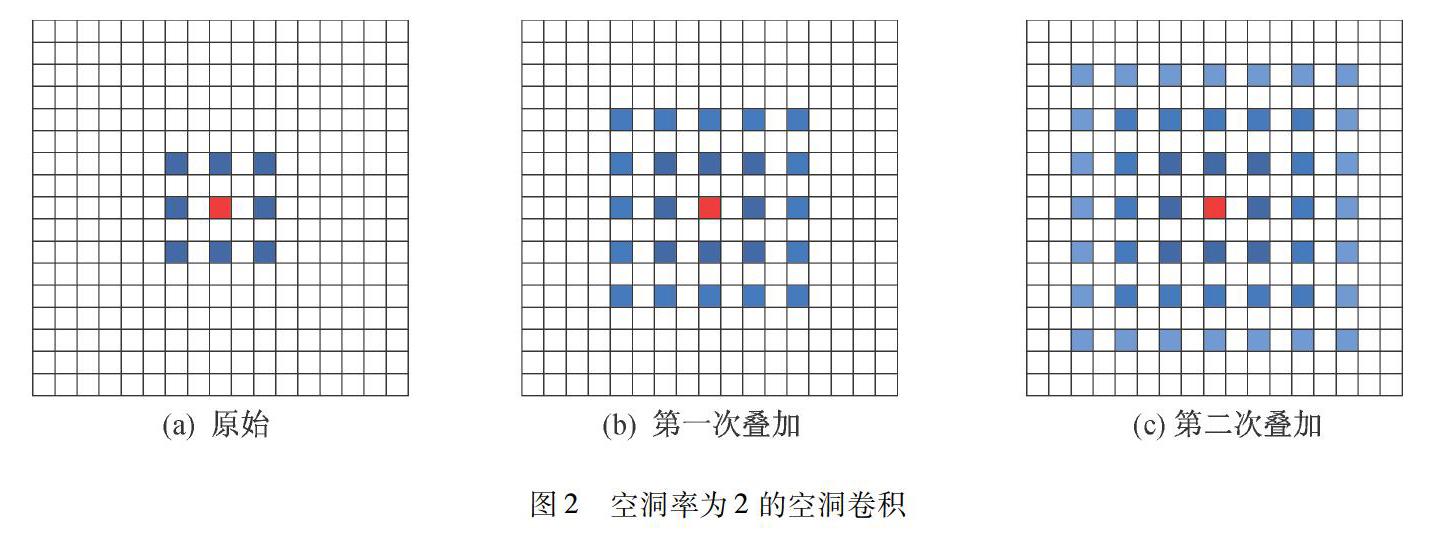
空洞率相同的空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层独立的集合,没有相互依赖关系,因此该层的卷积结果之间没有相关性,导致局部信息丢失.相同空洞率的情况下,空洞卷积操作的棋盘问题如图2所示.
图2(a)对应原始卷积,感受野为5×5 pixels;图2(b)对应卷积核一次叠加后的卷积,每个像素点为原始卷积的输出,所以单个像素点的感受野为5×5 pixels,叠加后的感受野为9×9 pixels;图2(c)与图2(b)同理,最终得到的感受野为13×13 pixels.
[5] LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation [J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,39(4):640-651.
[6] ZHANG Y,ZHOU D,CHEN S,et al.Single-image crowd counting via multi-column convolutional neural network [C]//Computer Vision & Pattern Recognition.Las Vegas:IEEE,2016:589-597.
[7] KRIZHEVSKY A,SUTSKEVER I,HINTON G.ImageNet classification with deep convolutional neural networks [C]//Proceedings of the 25th International Conference on Neural Information Processing Systems.Lake Tahoe:ACM,2012:1097-1105.
[8] SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large-scale image recognition [C]//International Conference on Learning Representations.San Diego:IEEE,2015:1150-1210.
[9] ZHANG C,LI H,WANG X,et al.Cross-scene crowd counting via deep convolutional neural networks [C]//Conference on Computer Vision and Pattern Recognition.Boston:IEEE,2015:833-841.
[10] SINDAGI V A,PATEL V M.Generating high-quality crowd density maps using contextual pyramid CNNs [C]//International Conference on Computer Vision.Venice:IEEE,2017:1879-1888.
[11] LI Y,ZHANG X,CHEN D.CSRNet:dilated convolutional neural networks for understanding the highly congested scenes [C]//Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:1091-1100.
(責任编辑:包震宇)
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
计算机技术与发展(2019年1期)2019-01-21
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
故事作文·高年级(2017年2期)2017-03-01
新闻传播(2015年20期)2015-07-18
世界科学(2013年11期)2013-03-11
