
生成对抗网络及其文本图像合成综述
2022-10-18 01:02李玉洁郭富林何俊霖
计算机工程与应用 2022年19期
王 威,李玉洁,郭富林,刘 岩,何俊霖
1.桂林电子科技大学 人工智能学院,广西 桂林 541000
2.郑州轻工业大学 计算机与通信工程学院,郑州 450002
计算机视觉(computer vision,CV)赋予人工智能感知周围信息的能力,其发展进一步拓展了人工智能感知精度和广度[1]。现如今深度学习算法不断改进和突破,凭借着其“端到端”地提取高维度特征的特点,深度学习在计算机视觉中得到了大规模的应用(如图像分类、目标检测等),并且在各大图像类比赛中准确率和鲁棒性有所提升,超越了一般的传统算法。文本图像合成是计算机视觉的重要课题,它提取出语言和视觉之间的内在联系,并将文本描述翻译成文本语义相似的图像。文本图像合成正广泛的应用于视频游戏,图像编辑,图像艺术生成等方面。
作为深度学习的主要网络模型之一,生成对抗网络(generative adversarial network,GAN)于2014 年 由Goodfellow等人[2]首次提出。随后,GAN及其衍生网络成为了CV领域近几年来最火热的方向之一[3]。GAN在图像合成领域已经引起了较多的关注和研究[4]。与传统的生成式网络不同,传统的生成式网络只有生成器,无法仅从有限的训练集中生成逼真的数据。而GAN包含了生成器和判别器,生成器生成虚假的数据,而判别器负责辨别数据真伪,通过两者的博弈使最终生成的数据以假乱真[5]。这种方法已经有了广泛的应用[6-7],例如:数据增强[8-9]、图像风格迁移[10-11]、图像超分辨率[12-13]、文本图像生成等。
GAN中的对抗学习思想与深度学习中的其他研究方向逐渐相互渗透,以至于诞生了很多新的研究方向和应用。特别是GAN在图像生成方面的能力超越了其他方法,使得近几年文本图像合成成为一个极其活跃的研究领域。作为一个直观的条件图像生成方法,基于GAN的方法使得文本图像合成的图像质量、多样性、语义一致性、视觉真实性获得突破性进展。本文主要介绍GAN 在文本合成图像任务[14]中的应用。该任务与单一的图像任务(如图像分类[15]、图像分割[16])不同,它实现了在计算机视觉和自然语言处理[17]两个领域进行跨模态研究,建立了从文本到图像的联系。文本合成图像的主要流程是自然语言模型将文本转换成语义向量,再利用图像模型生成语义一致性的高质量图像。文本合成图像领域主要模型包括自回归模型(ARM)[18]、变分自编码器模型(VAE)[19-20]以及基于GAN 的模型[21]。如今基于GAN的模型逐渐成为主流。受到条件生成对抗网络(conditional GAN,CGAN)的启发,GAN-INT-CLS 模型[22]和TAC-GAN 模型[23]的提出开始了GAN 在文本图像合成领域的发展,但两者合成图像的分辨率有限,只能达到64×64和128×128,很多细节无法生成,效果令人不满意。随后多阶段(多组生成器、鉴别器分开训练,前一阶段的输出作为后一阶段的输入)的StackGAN[24]、StackGAN++[25],引入注意力机制的AttnGAN[26]模型、逐段嵌套(使用单流的生成器同时带有多个级联的鉴别器)的HDGAN[27]模型,采用对比学习的XMC-GAN[28]等都随之出现,改善了图像合成的质量和语义一致性较差的问题。
随着基于GAN的模型不断更新,模型不仅在CUB-200 Birds[29]、Oxford-102 Flowers[30]等单一对象数据集上应用,目前也可在复杂性数据集(如COCO数据集[31])上改进和验证模型的性能,合成图像的分辨率也达到了256×256 及更高。该领域使用了一系列文本到图像合成模型质量评估指标(如inception score[32]、FID[33]、human rank、R-precision、visual-semantic similarity(VS)[27]等)。从合成图像的质量,多样性以及图像,文本间的匹配程度进行综合评估。
本文总结和强调了基于GAN的文本图像合成领域的发展现状及发展历程。通过对文本编码器,文本直接合成图像,文本引导图像合成等多维度多模型的对比和分析,全面总结和分析了模型的特点,客观地提出该领域目前研究的不足以及未来可能的发展方向。
1 GAN介绍
GAN(如图1)是由两个深度神经网络所构成的非监督式架构,包含一个生成器和一个判别器,两者独自训练。其中生成器中输入随机噪声向量,从而产生图像,通过优化损失函数使得生成图像的分布不断接近真实图像分布,来达到欺骗判别器的目的。判别器对真实图像和生成图像进行判别,来提高判别器的分辨能力。整个训练过程都是两者不断的进行相互博弈和优化。其目标函数如式(1):
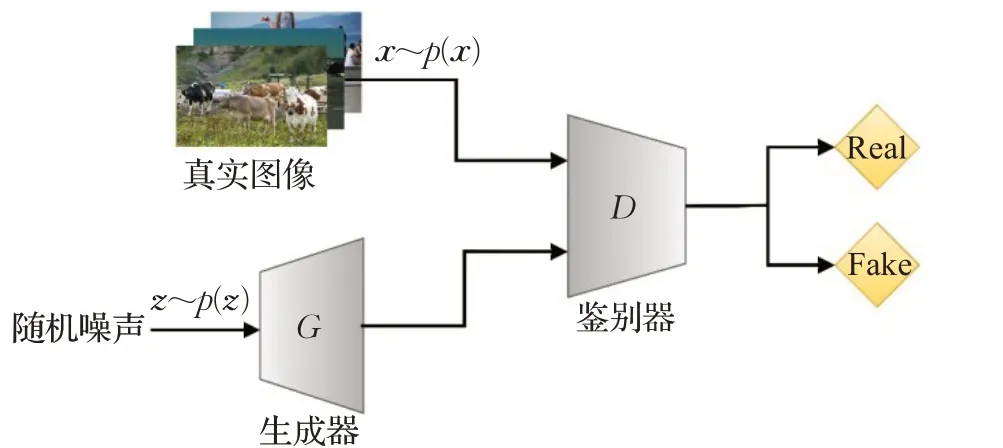
图1 GAN框架Fig.1 GAN framework
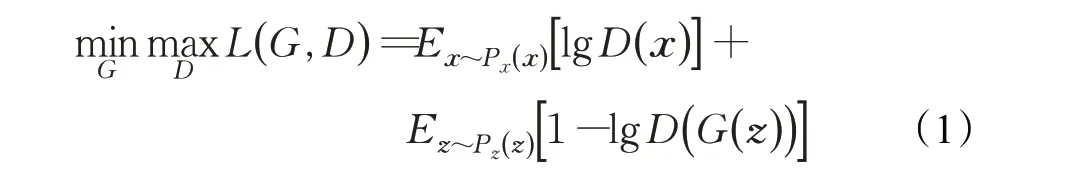
式中D表示判别器,G表示生成器,Ex表示下标分布的期望值,Pz表示生成图像的分布,Px表示真实图像分布,G( )z生成的图像,z表示随机噪声向量,x表示真实图像向量。
2 基于GAN的文本图像生成
文字和图像是人们感受世界的两大重要途径,如何将这两个模态相关联是目前两个领域的重要研究课题。图像中可提取丰富且复杂的文本语义特征,而直接利用文本来合成图像却极其复杂[34],GAN的出现提供了一种无监督模型[35]来生成图像的方式。通过提取文本中的重要属性(如空间、事物关系、事物状态等),再用GAN 中的生成器和鉴别器互相博弈的状态,将属性嵌入图像变得有所可能。因此,近年来的GAN 的多个变种(如图2)[36-38]在文本图像合成领域有着较好的应用和持续的研究。2014年,Goodfellow等人[2]和Mirza等人[39]接连提出GAN 和CGAN 为文本图像合成领域提供了一个崭新的方向。在文本图像合成领域发展前期,为提高生成图像的质量和多样性,Reed 等人[22]于2016 年提出GAN-INT-CLS 模型,Dash 等人[23]于2017 年提出TAC-GAN,Zhang等人[24-25]分别在2017年和2018年提出StackGAN与StackGAN++模型,Zhang等人[27]于2018年提出HDGAN,采用单阶段到多阶段的网络架构转变,通过级联的网络增强图像生成的质量、分辨率、多样性等,同时提高训练的稳定性。随后,生成图像的细粒度特征和文本的语义一致性成为了需要解决的问题。Xu等人[26]于2018 年在多阶段的架构上引入注意力机制,提出AttnGAN关注文本的每一个单词信息以此实现文本与图像的视觉对齐,随后Tan 等人[40]于2019 年提出SEGAN,Li 等人[41]于2020 年提出ControlGAN,都重点关注注意力机制的嵌入应用。2019年,Zhu等人[42]提出DM-GAN,Qiao 等人[43]提出MirrorGAN,分别采用记忆网络和循环一致的方法实现文本图像合成。2019年,基于场景对象布局的中间阶段过渡方法开始兴起,Li 等人[44]提出了基于物体对象的Obj-GAN,Sylvain等人[45]和Hinz 等人[46]于2020 年分别提出了OC-GAN 和OP-GAN等,利用背景图和对象布局加强了生成图像的语义一致性和视觉逼真性。2020年,Li等人[47-48]接连提出ManiGAN和轻量级lightweight GAN,为文本引导图像生成(文本图像合成的分支领域)提供了有效的方法。在2021年和2022年,文献[49-51]基于StyleGAN分别提出了TediGAN和TiGAN,促进了文本引导图像生成领域的快速发展。2019 年,Yin 等人[52]提出的SD-GAN 使用了对比损失,随后,对比学习框架逐渐应用于文本图像合成领域。2021 年,Ye 等人[53]提出现有模型加入对比学习框架,Zhang等人[28]提出XMC-GAN,对比学习在文本图像生成领域的应用极为有效。Zhu 等人[54]于2020 年提出的因果关系导向的CookGAN 也是一种有效且创新的方法。如今,对比学习、因果关系、场景布局、注意力机制等先进的创新方法,都促进着文本图像生成领域的蓬勃发展。
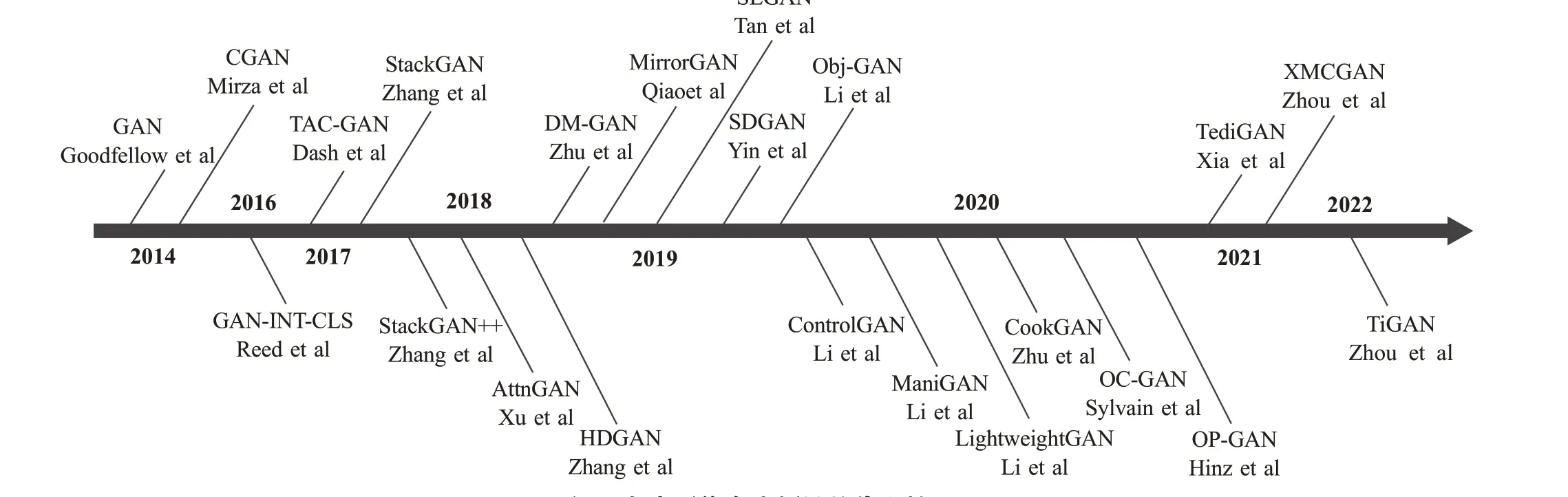
图2 文本图像合成领域的代表性工作Fig.2 Representative work in field of text-to-image synthesis
利用GAN 来进行文本图像合成主要是受到Mirza等人[39]提出的CGAN(如图3)所启发。与原始GAN 相比,CGAN 在生成器和鉴别器上分别加上条件变量c,再利用GAN 的框架进行图像的生成,这样训练生成的图像将会满足条件c,以此来解决生成图像内容的不确定性问题[55]。
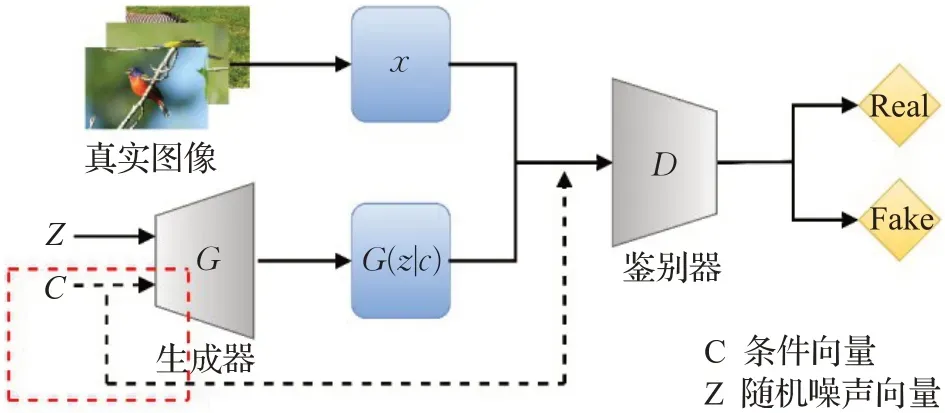
图3 CGAN框架Fig.3 CGAN framework
将文本进行编码[56],提取成文本条件向量[57],再将类似于CGAN 中的条件变量c输入到GAN 的生成器中,可达到文本控制图像合成的目的。而为了达到文本合成图像的目标,主要有两个步骤:文本编码和基于文本的图像合成。下文将主要针对这两个步骤的相关工作进行总结和分析。
2.1 文本编码
文本编码主要有两大类方法,条件增强(conditioning augmentation,CA)和预训练模型(如图4)。条件增强技术在文本提取中增加了额外采样的隐向量,增强了条件流形的鲁棒性以及生成图像的多样性。预训练模型加强了文本中的时间结构特征,对单词级文本进行编码,提高了文本描述和对应图像在视觉上的联系。下文将分别对这两种方法进行介绍。
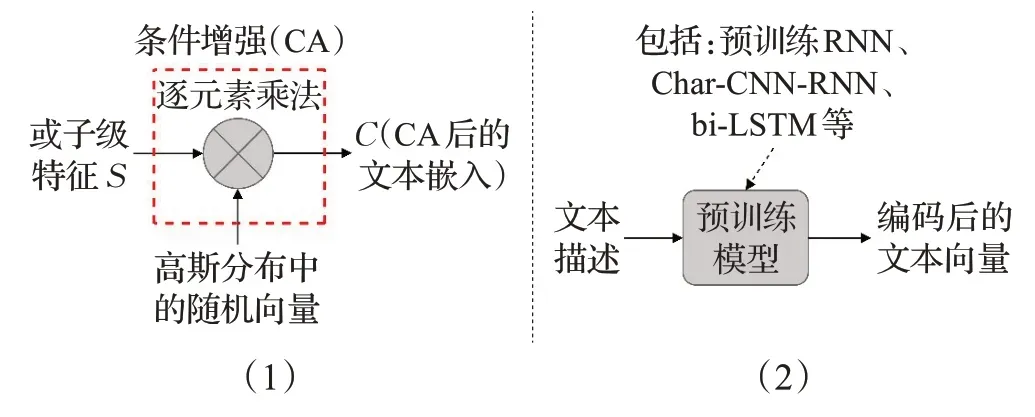
图4 文本编码Fig.4 Text encoding
2.1.1 条件增强
对于一般的文本描述编码方式,都是先进行非线性变换,再将非线性变换后的条件潜变量直接输入到生成器里,此方式下的潜在空间[58]文字嵌入通常都在100 维以上,在数据量较少的情况下会带来潜在空间中数据的不连续性。Zhang 等人[24]的StackGAN 中提出了一种条件增强技术,除去原来在文字描述中提取的条件变量,在高斯分布中又随机采样了隐向量[59]。在训练过程中,提出了在生成器中加入额外的正则化项,即标准高斯分布和条件高斯分布的Kullback-Leibler(KL)散度[60],如式(2):

通过条件增强技术产生了更多的训练对,提升了其在条件流形[61]上的鲁棒性和平滑程度。通过加入随机性来达到生成图像多样性的目的。随后,在提出的StackGAN++[25]、CookGAN[54]以及DM-GAN[42]等多个方法中都借鉴了条件增强技术。
2.1.2 预训练的RNN模型
在文本合成图像领域,使用预训练的RNN 模型极为常见。使用较多的是由Reed 等人[62-63]提出的字符级卷积-递归神经网络(Char-CNN-RNN),将CNN 快速卷积的特点和RNN时序信息处理相结合,在CNN的隐藏层中堆叠递归网络,学习到字符特征,以此来对字符级的文本进行编码,这有利于文本中时间结构的利用,同时编码器得到的特征内积可以使文本和图像更加兼容,加大了文本描述和对应图像在视觉上的联系。在Li等人[47]提出的ManiGAN中,直接使用预训练的RNN模型对文本中的单词级进行编码,使得每一个单词都对应着一个特征向量。Qiao 等人[43]提出的MirrorGAN 中也用了此方法。但随着RNN 的增长,用于组合不同输入向量的预测知识的建模能力将变低,导致模型的效果变差;Li等人[48]后续提出的文本引导图像的轻量级生成对抗网络(LwGAN)中使用预训练的双向RNN 模型[41]进行单词级编码。可以对时间段的过去未来所有输入信息进行训练,以此来提高模型效果。
在Xu 等人[26]的AttnGAN 中,提出了使用双向长短期记忆(Bi-LSTM)[64]来对文本进行编码,提取语义向量,利用双向LSTM 来使每个单词对应两个隐藏状态,通过连接两个隐藏状态来表达单词的语义特征,且利用每个单词的最后一个隐藏状态连接从而产生全局句子向量,达到前后串联的目的。为了检验文本与对应图像的内在关联,在训练过程中还创造性的提出深度注意多模态相似度模型(deep attentional multimodal similarity model,DAMSM)用于定量计算单词与对应图像之间的相似度。后续的多个模型都沿用了此方法。
2.2 基于文本的图像生成
在基于文本的图像生成中,将其分成文本直接生成图像与文本引导图像生成两大类应用,在文本直接生成图像的应用中,总结了单阶段直接生成法(TAC-GAN[23]等)、堆叠架构(StackGAN[24]等)、注意力机制法(Attn-GAN[26]等)、记忆网络法(DM-GAN[42])、循环一致法(MirrorGAN[43])、对比学习法(XMC-GAN[28]等)、场景对象布局法(OP-GAN[46]等)以及因果关系法(CookGAN[54])八类方法。在文本引导图像生成的应用中,文章总结了仿射组合法(ManiGAN[47]等)和基于StyleGAN[49](TediGAN[50]等)两类方法。具体的方法间区别与联系如图5所示。
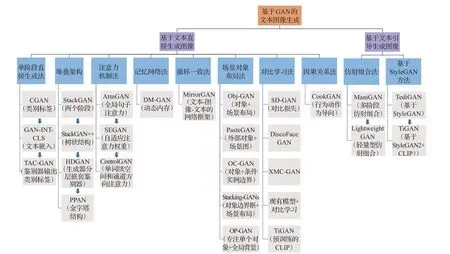
图5 各类方法间的联系与区别Fig.5 Connection and difference between various methods
2.2.1 基于文本直接生成图像
目前由给定文本直接生成图像领域的模型大多是将文本描述作为条件信息,采用单阶段、多阶段、记忆网络法、注意力机制、循环一致性、对比学习、场景对象布局、因果关系等方法,控制逼真图像的生成。本文将文本直接生成图像的方法分成单阶段直接生成法、堆叠架构、注意力机制法、记忆网络法、循环一致法、对比学习法、场景对象布局法、因果关系法八类方法(如表1)。
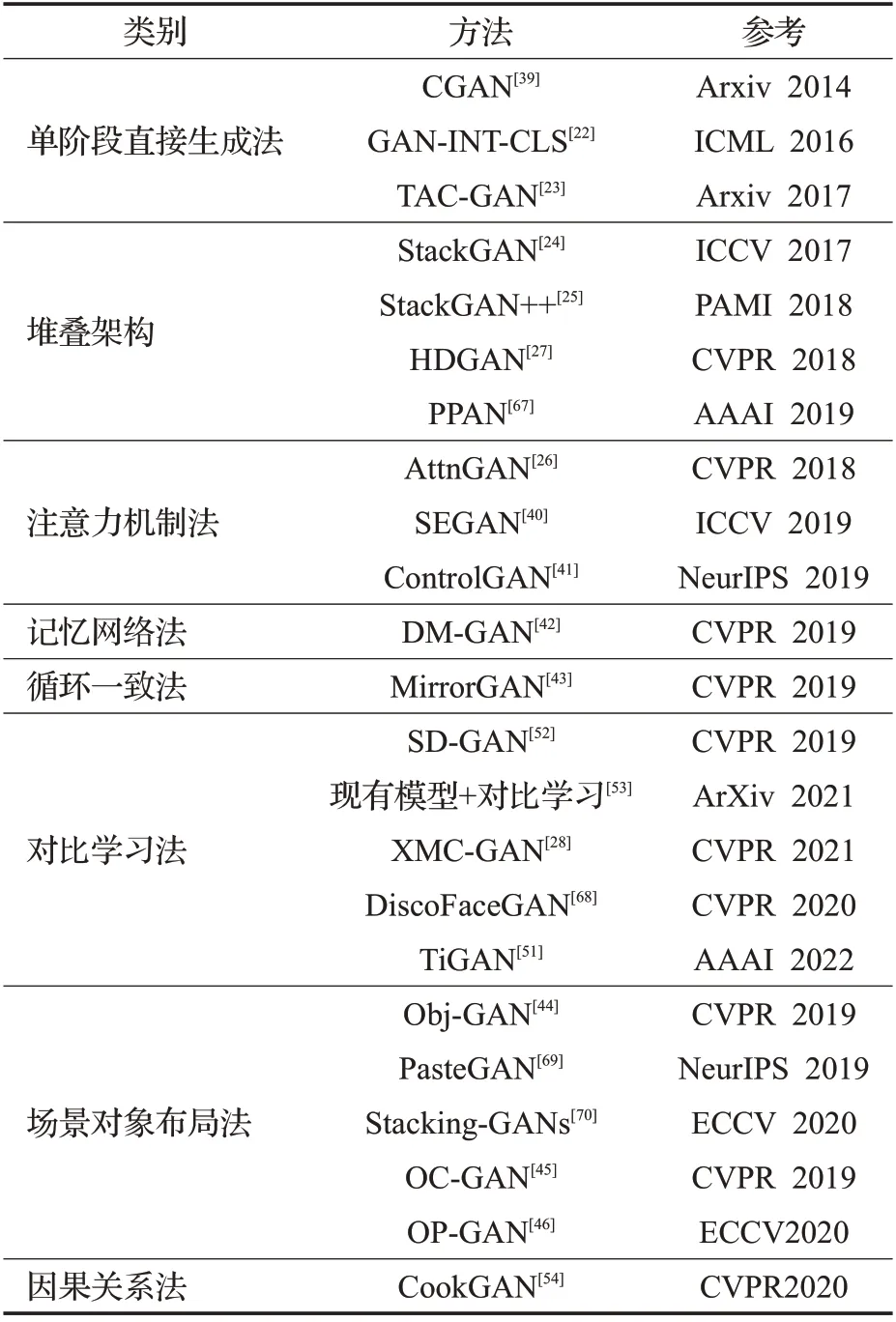
表1 基于文本直接生成图像的分类与参考Table 1 Classification and reference of directly generated images based on text
在单阶段直接生成法中,Mirza等人[39]提出的CGAN可以初步的将文本信息作为条件控制图像的生成。Reed 等人[22]于2016 年提出GAN-INT-CLS,采用单阶段方式生成了分辨率64×64 的图像,但图像质量较差。Dash等人[23]提出的TAC-GAN在AC-GAN[65]的基础上增加了额外的损失条件,生成了分辨率128×128的具有鉴别性和多样性的图像。在堆叠架构中,Zhang 等人[24]提出StackGAN,采用两个阶段的堆叠网络,加入条件增强(CA)技术进行文本编码,生成了分辨率256×256 的图像。为进一步提高生成图像质量和改善细节,继续提出了StackGAN++[25],采用多阶段的树状结构,鉴别器中额外加入条件损失,来提高图像与文本间的匹配程度,还加入颜色一致性正则化,保证生成图像的颜色纹理差异。在注意力机制法中,Xu等人[26]提出AttnGAN,首次在网络中加入注意力模块,关注其最相关单词,提出深度注意多模态相似模型,计算生成图像与句子间的相似度,提供细粒度图像-文本匹配损失。Tan等人[40]提出的语义增强生成对抗网络(SEGAN)提出一个注意力竞争模块,仅保留重要单词的注意力权重,这有利于关键信息的合成,提高了模型的准确性。Li等人[41]提出的ControlGAN通过单词级空间注意力和通道级注意力模块可保留部分背景属性并改动文本关联属性。在记忆网络法中Zhu 等人[42]于2019 年提出DM-GAN,采用了动态记忆更新组件,使用动态内存对初始图像细化,内存写入门动态选择匹配的单词,响应门融合图像和内存表示。进而依据文本描述生成图像。在循环一致法中,受CycleGAN[66]模型的启发,Qiao等人[43]提出MirrorGAN,加入全局-局部协作注意力,使用“文本-图像-文本”的文本再生和对齐模块,监督生成器,保证图像多样性和语义一致性。在对比学习法中,从一开始的Yin 等人[51]提出的SD-GAN中,使用Siamese模块,通过将连体网络参数共享,对最终的输出计算对比损失,再加入语义条件批量归一化,保证了最终图像的多样性。在Zhang 等人[28]提出的XMC-GAN中,在模态内和模态间通过最大化图像和文本的互信息,并加入注意力自调制生成器来使图像文本一致性高。同时,Ye等人[53]提出将对比学习方法应用到现有的各个模型中,通过在AttnGAN[26]和DM-GAN[42]中加入对比学习方法全面提高了原模型的性能。此外基于场景对象布局和因果关系的方法也有着突出的贡献和发展。下文将对上述的单阶段直接生成法、堆叠架构、注意力机制、记忆网络法、循环一致法、对比学习法、场景对象布局、因果关系等方法进行具体介绍。
2.2.1.1 单阶段直接生成法
受CGAN 的启发,通过对CGAN 进行扩展,将原先的类标签用文本嵌入代替,以此来实现端到端的文本控制图像生成。在GAN-INT-CLS[22]模型(如图6(a))[4]中使用匹配感知鉴别器,将“匹配样本的真实图像”“对于样本的生成图像”“不匹配样本的真实图像”3种图像作为鉴别器的输入。使得生成器和鉴别器既能关注真实图像又能进行文本对齐。在AC-GAN[65](如图6(b))[4]的基础上,TAC-GAN[23](如图6(c))[4]提出利用文本描述来代替类别标签,TAC-GAN将噪声向量和文本描述的嵌入向量的组合向量输入生成器。鉴别器中与ACGAN[65]有细微区别,TAC-GAN 同时将文本信息在分类前输入鉴别器。这样模型提升了多样性和可识别性,同时更加易于扩展。
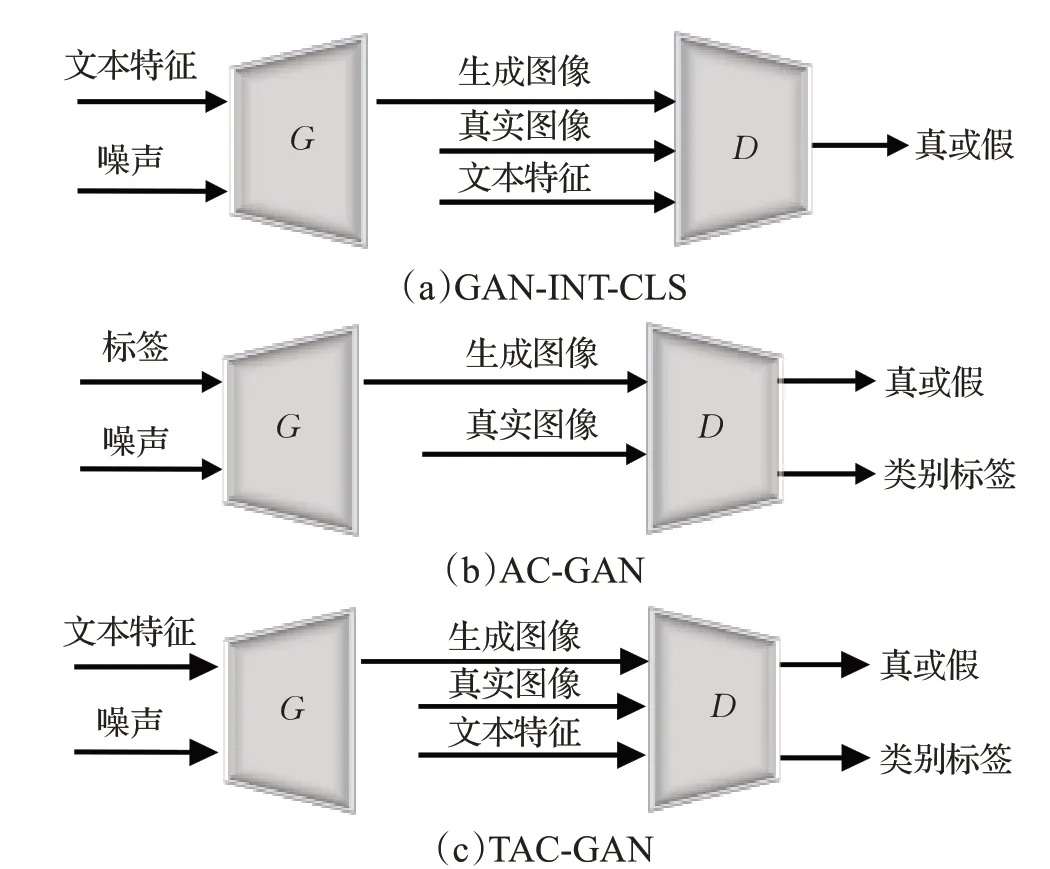
图6 GAN-INT-CLS、AC-GAN、TAC-GAN三者的对比Fig.6 Comparison of GAN-INT-CLS,AC-GAN and TAC-GAN
在文本生成图像的初期,单阶段直接生成法在类条件模型的基础上,将类标签替换为文本描述的嵌入向量并将其输入生成器和鉴别器达到监督的目的,并利用噪声和文本嵌入的组合向量来增加更多的辅助信息,以此提高图像的多样性。
对于单阶段直接生成法,辅助条件信息的选择和数据分布的学习是算法性能的主要影响因素。辅助条件越贴切文本与图像的映射且对数据分布的模式学习越精细,生成图像的质量将会越高,模型训练将会更稳定。该方法的缺点总结如下:
(1)首先,这类方法的图像分辨率较低(最高只达到128×128),生成的图像质量也较差,细粒度特征无法完善,对于文本信息的挖掘也较浅。(2)其次,这类方法一般学习到的仅是数据的分布,这将容易造成模型的坍塌。
2.2.1.2 堆叠架构
生成图像的分辨率一直都是图像领域最重要的指标之一,在StackGAN[24]之前的GAN-INT-CLS[22]只能生成64×64像素的图像,TAC-GAN[23]只能生成128×128像素的图像,在图像的分辨率上遇到了巨大的困难,具体来说就是随着分辨率的提高,自然图像分布和隐式模型分布在高维像素空间可能无法重叠。为了模型可以合成更高分辨率的图像,并能保持模型的训练稳定,利用多个堆叠的生成器鉴别器网络可以有效的改进这一点。
(1)StackGAN
StackGAN[24]的提出,进一步提高了生成图像的分辨率,达到了256×256像素。由于一次无法生成高分辨率图像,Zhang 等人[24]提出将困难问题分解成易于进行的子问题进行解决,利用两个生成对抗网络进行堆叠来生成高分辨率图像。
StackGAN使用级联的GAN使生成的图像细节化,提高了图像的质量。如图6(a)所示,StackGAN 主要由Stage-I和Stage-II两部分组成。Stage-I部分只生成低分辨率(64×64)图像,利用多个条件变量的文本嵌入来实现文本描述细节;生成的图像并不过多关注于图像细节,只需要包含物体轮廓及颜色等粗略信息。相比较于之前方法采用Stage-I 部分直接利用噪声来生成图像,StackGAN 将Stage-I 生成的图像直接输入Stage-II 部分,同时输入的还有文本中的一些被忽略的细节。重新修正了Stage-I 部分的一些错误和不足,从而提高了生成图像的分辨率(256×256)以及图像的质量。同时,StackGAN 提出了条件增强技术,通过将原有的条件变量和在高斯分布中产生的额外条件变量一起输入到生成器中。通过在训练过程中加入KL散度提高了训练过程的稳定性。条件增强技术提高了生成图像过程的鲁棒性及生成图像的多样性。
(2)StackGAN++
为改善生成图像的细节以及文本和图像间的一致性,Zhang等人[25]提出的StackGAN++是一种多阶段的树状生成对抗网络架构。
StackGAN++中从低分辨率到高分辨率生成的图像是由树的不同分支产生的,对于每一个分支,使用生成器来捕获该分辨率下的图像分布,再由鉴别器分辨该尺度下的样本真假。通过使生成的图像与当前尺度下的真实图像分布更近似,交替训练不同分辨率下的生成器和鉴别器,使整个网络训更好。StackGAN++提出了新形式的鉴别器,其损失函数(如式(3))所示,包括无条件损失和条件损失。无条件损失只针对生成的图像,判定其是否为真实图像,而条件损失针对的是图像与文本输入鉴别器的条件变量是否匹配,即图像是否符合文本信息。

式中E表示下标分布的期望值,Di表示鉴别器,Gi表示生成器,xi表示第i个真实图像,si表示第i个假样本输入,pdatai表示第i个真实图像分布,pGi表示第i个生成模型的分布,c表示输入的条件向量。
StackGAN++提出额外的颜色一致正则化。引入颜色一致性正则化项来最小化不同尺度间的颜色纹理差异,使生成器在相同输入样本时产生的图像颜色更加一致。
StackGAN++与StackGAN的定性对比(如图7)[25]得出,StackGAN++多阶段的架构使其生成的图像质量更高更稳定,更加符合文本信息,且颜色生成更加一致,优于StackGAN的生成质量。

图7 由StackGAN(顶部)和StackGAN++(底部)生成的256×256图像样本Fig.7 256×256 image samples generated by StackGAN(top)and StackGAN++(bottom)
(3)HDGAN
典型的GAN框架[27](如图8)包括多阶段模型、一个生成器和多个鉴别器、对称式生成器鉴别器等。为了解决从语义文本描述中处理图像的难题,同时匹配多个生成器网络,Zhang 等人[27]提出的分层嵌套对抗网络(HDGAN,如图8(d))是一种可扩展的单流生成器架构。在多尺度的中间层使用分层嵌套鉴别器来提高最终生成图像的分辨率(512×512),中间层中的不同鉴别器可以匹配不同分辨率生成器生成的图像,更像是充当了生成器中的正则化项。同时利用多用途对抗损失来完善细粒度图像细节。此外,HDGAN提出了视觉语义相似性度量,用于检测生成图像的一致性以及逻辑的一致性。
此外,Gao等人[67]提出的PPAN采用金字塔结构,利用一个自上而下的带有感知损失生成器和并列的三个鉴别器的结构来生成分辨率高、语义一致性强的图像,减少了训练过程中的特征损失,也体现了堆叠型网络可以获得高质量、高语义一致性的图像。
堆叠型网络采用级联的架构,利用初始生成的图像再对其进一步的完善和细化。可以展现生成图像的多样性强,分辨率高的特点。同时级联的架构可以使训练过程更加稳定。
堆叠架构中,第一阶段生成图像的质量将影响着整个模型的最终结果,初始图像若无法包含应有的细节特征和对象框架等信息,将会导致最终图像的细粒度特征和对象布局的信息缺失。同时,堆叠结构的层数越多,不同层间的特征信息间的重叠也会极大地影响最终图像细节特征。该方法的缺点总结如下:
(1)多阶段的训练速度较慢,同时在每个阶段提取特征时都会产生重复,因此会需要很大的计算资源。
(2)多阶段的任务容易无法准确识别任务重点,造成最后生成的图像与文本重点信息无法准确对应。
(3)堆叠型架构更多的只能针对简单文本描述时有良好的生成效果,对复杂的文本和场景无法准确生成图像,细粒度特征也会丢失,图像质量也会较差。
堆叠架构的定量比较如下:单阶段的GAN-INT-CLS在COCO数据集上的IS值为7.88,而多阶段的StackGAN在COCO数据集上的IS值为8.45。StackGAN比GAN-INTCLS 的IS 值提高7.23%。在堆叠架构中,StackGAN++在CUB数据集上的IS值为4.04,FID值为15.3,StackGAN的IS值为3.70,FID值为51.89,StackGAN++比StackGAN的IS值提高了9.19%,FID值降低了70.51%(FID值越低效果越好),性能显著增强。
2.2.1.3 注意力机制法
注意力机制[71]的提出,迅速在计算机视觉,自然语言处理等领域发展起来。通过对目标区域的重点关注,得到注意力焦点,再对这一区域投入更多注意力,以获取更多所需关注目标的细节信息,同时抑制其他无用信息。由于注意力机制具有更好的鲁棒性,扩展性,对局部信息的捕捉能力以及更高的并行性的特点,添加注意力机制的模型普遍效果更好,可解释性变强[72-73]。Xu 等人[26]提出在文本图像生成中加入注意力机制,即AttnGAN。
(1)AttnGAN
AttnGAN[26]由注意力驱动,级联网络细化文本到图像的生成。AttnGAN的总体架构是在StackGAN++[24]上进行优化和改进,添加了一些特殊的部件。AttnGAN的重要创新点之一是注意生成网络。对整个文本建立全局句子向量,在第一次生成低分辨率图像后的每一个阶段,对于子区域的图像向量,添加注意力层来查询词向量,形成上下文向量,再将其与子区域图像向量相结合,形成多模态上下文向量,以此来提高生成图像的细节特征。AttnGAN 的另一个重要创新是提出了深度注意多模态相似模型(DAMSM)。通过此模块,可以在句子级别或更细粒度的单词级别计算生成的图像与对应文本间的相似度以及训练过程中产生对应匹配损失。DAMSM 模块的添加使得合成图像的质量以及文本图像匹配度极大提高。
StackGAN、StackGAN++、AttnGAN 的模型框架对比(如图9),三者的框架都是使用多个生成器,鉴别器级联的网络架构,StackGAN++在StackGAN的基础上增加了一个阶段的生成器和鉴别器,并在损失函数中增加了条件损失。AttnGAN 在此基础上增加了注意力模块和DAMSM模块。
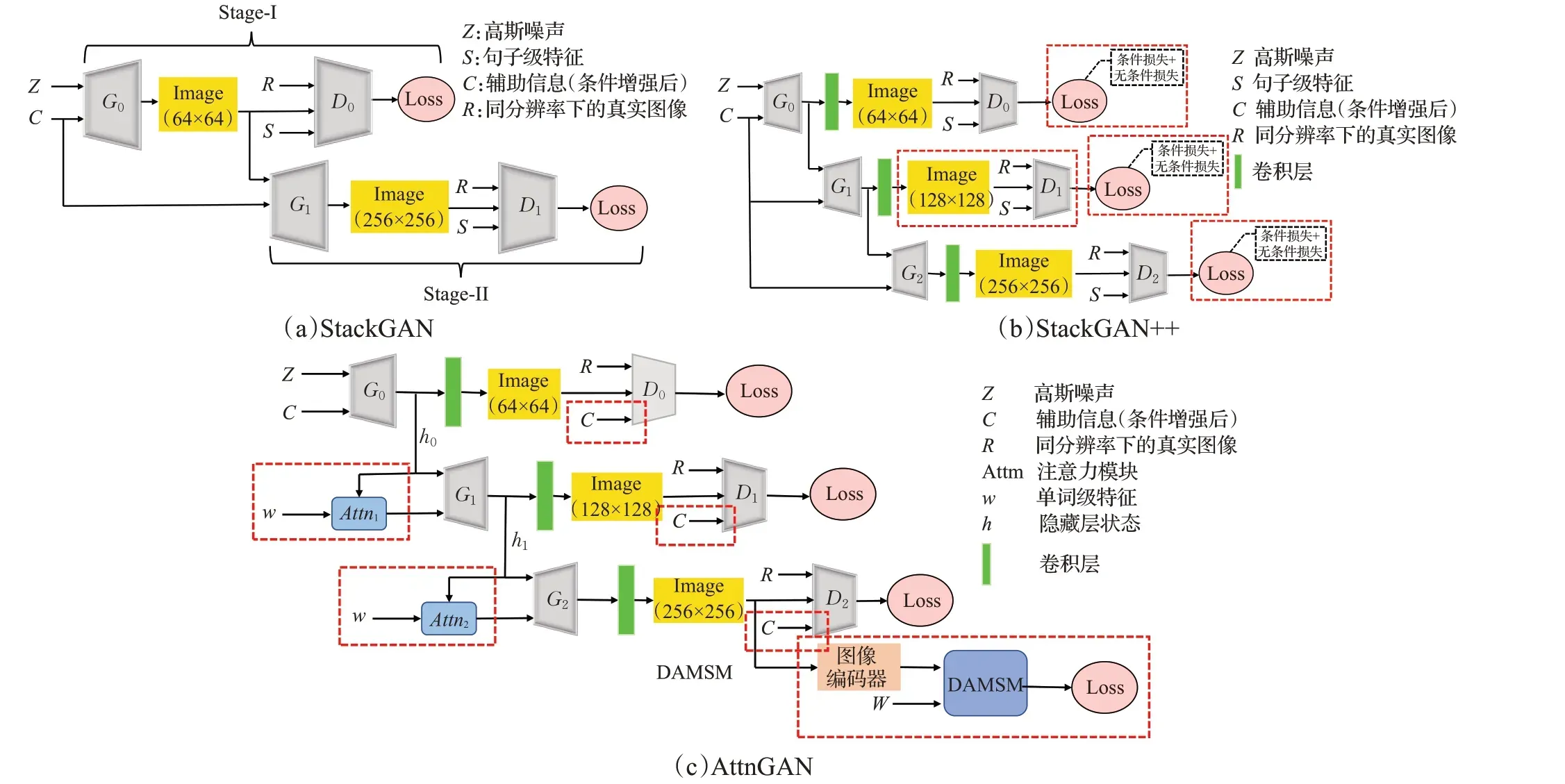
图9 StackGAN、StackGAN++、AttnGAN三者的对比Fig.9 Comparison of StackGAN,StackGAN++ and AttnGAN
(2)SEGAN
由于文本描述中包含了许多不重要的单词信息,使用全局句子加入注意力机制会产生模型训练时间长,稳定性差的问题。为解决这一问题,Tan 等人[40]提出了语义增强生成对抗网络(SEGAN)。
SEGAN提出注意力竞争模块(attention competition module,ACM),设计了特殊的注意力正则化对句子赋予自适应注意力权重,以此来筛选出关键词和非关键词,将ACM 中赋予注意力权重的关键词输入进注意力生成网络(attention generation network,AGN)中,并以此来作为生成器,这样可以突出文本中重要单词在生成图像时的体现。此外SEGAN中加入了语义一致性模块(semantic consistency module,SCM),最小化生成图像和真实图像间的特征距离,最大化与另一个文本的真实图像间的特征距离。并且加入了滑动损失来平衡简单样本和困难样本,从而使最终生成的图像语义一致性强,关键词信息准确性高且生成效率高。
(3)ControlGAN
文本生成图像模型一般是不可控的,当改变文本中的一些单词时会使合成的图像与原始文本对应的图像有很大差别。某些属性改变会导致其他的一些属性(例如姿势、位置等)一同发生改变。为了解决这类问题,Li 等人[41]提出了一种可控型的文本生成图像模型ControlGAN,ControlGAN 也为文本引导图像生成领域提供了研究基础。
ControlGAN提出了单词级空间和通道方向注意力驱动生成器,其中空间注意对应于文本的颜色信息,而通道注意力将语义中有意义的部分和对应的文本单词相关联。使用的词级鉴别器为生成器提供细粒度的训练反馈,利用单词与图像子区域间的相关性来分解不同的视觉属性,从而达到在改变文本所涉及属性(例如颜色、纹理等)的同时保留其他无关属性(例如图像背景等),使得最终的图像语义一致性强,多样性强。
注意力机制的引入对改进语言和视觉体现产生了巨大的影响,它允许网络更关注关键性的不同维度的信息同时忽略一些不重要的信息,注意力模块可以挖掘出更多文本中单词级的重要细粒度特征[74],同时它可以减少对其他辅助信息的需求,灵活的利用文本按照需求改变图像的生成,使得整个模型的稳定性强、效率高。
对于注意力机制法,对象的位置布局会对算法的性能产生影响,复杂的场景会使注意力难以学习对象的位置序列,或许会导致最终的图像细粒度位置信息发生混乱。此外,计算资源的完备也是影响算法性能的重要因素。该方法的缺点总结如下:
(1)当遇到复杂的场景和简短抽象的文本时,模型无法保证细粒度特征维持原状且抽象文本对应的图像区域的合成效果也较差。
(2)模型在面对多个类似文本时所生成的图像质量不佳,生成的图像多样性较差。
(3)大多带有注意力机制的模型都是基于堆叠型网络架构,同时注意力机制需要时刻注意上下文信息,从而导致模型的计算量大,占用的内存等资源变大,模型较为繁重。
注意力机制法的定量比较如下:在堆叠架构中加入注意力机制的AttnGAN 在COCO 数据集上的IS 值为25.89,FID 值为35.49,StackGAN++在COCO 数据集上IS 值为8.30,FID 值为81.59,AttnGAN 比StackGAN++的IS值提高211.93%,FID值降低56.50%。注意力机制法中,在COCO 数据上SEGAN 的IS 值为27.86,FID 值为32.28,比AttnGAN 的IS 值提高7.61%,FID 值降低9.04%。在CUB 数据集上ControlGAN 的IS 值为4.58,AttnGAN 的IS 值为4.36,ControlGAN 比AttnGAN 的IS值提高5.05%。
2.2.1.4 记忆网络法
DM-GAN:
针对文本图像生成领域的快速发展,该领域的模型普遍存在两个问题:
(1)首先是图像的生成高度依赖于初始图像的质量,若初始图像的生成质量较差,图像的细化过程也无法产生高质量的图像。
(2)其次是目前的模型在图像细化过程中都是用统一的文本来表示,而输入文本中的每个词对图像内容都有着不同程度的描述,单词的重要性无法展现,细化过程将变差,最终结果也不尽人意。
针对这些问题,Zhu 等人[42]提出了DM-GAN,DMGAN包含动态内存机制和内存写入门的动态记忆组件[75]。
DM-GAN 针对初始图像质量粗糙问题,提出了动态内存机制[76]来细化图像,它包含4个部分,首先是进行内存写入,只考虑部分的文本信息;其次是进行键寻址[77],通过键储存器来检索并计算内存信息和图像特征的相似概率;接着进行值的读取;最终进行响应,即控制图像特征的重新融合和内存的读取,该融合过程都是使用响应门来进行的,从而得到优化后的图像。针对细化过程的问题,提出了使用内存写入门来计算每个单词的重要性并动态选择与生成图像相对应文本的单词,在每一次的图像细化过程中,都是不断地根据初始图像及文本进行动态的写入和读取内存信息,达到突出重点文本信息的目的。DM-GAN 也是在StackGAN[24],StackGAN++[25]以及AttnGAN[26]等模型基础上的创新发展。
使用记忆网络的模型可以动态的对图像进行存储并灵活的对图像进行细化,使得高质量的图像初步生成。通过记忆网络可以类似于注意力机制一样动态地选择重要的单词信息来确保最终图像的多样性强、分辨率高。
该方法的缺点总结如下:
(1)模型的细化会过多依赖于初始图像中的物体布局,当初始的物体布局发生错误时,最终细化的图像与输入文本无法很好的对应。
(2)在更多具有复杂场景的多样化数据集中,模型的适应能力不佳。
记忆网络法的定量比较如下:使用记忆网络的DMGAN 在COCO 数据集上IS 值为30.49,FID 值为32.64,比AttnGAN 的IS 值提高17.77%,FID 值降低8.03%。CUB数据集上DM-GAN的IS值为4.75,FID值为16.09,AttnGAN 的IS 值为4.36,FID 值为23.98,DM-GAN 比AttnGAN的IS值提高8.94%,FID值降低32.90%。
2.2.1.5 循环一致法
MirrorGAN:
当前的方法在保证文本描述和视觉内容之间的语义一致性方面效果较差,上述的几种方法大多在图像的分辨率方面有着较大的突破,而Qiao等人[43]提出MirrorGAN在多样性增强(相同文本对应的含义可能不同)方面有着更好的突破。在CycleGAN[66]的启发下,提出了一种全局和局部注意及语义保持一致的文本-图像-文本的网络框架。循环一致的特性可以使产生的附加信息供模型学习文本和图像的语义一致性。MirrorGAN提出3个模块:语义文本嵌入模块(STEM)、级联图像生成器中的全局-局部协作模块(GLAM)、语义文本再生和对齐模块(STREAM)[78]。
STEM模块在给定文本描述的基础上,提取句子嵌入以及单词嵌入,为适应文本表述的多样性,MirrorGAN沿用了条件增强技术来对输入的单词进行数据增广。GLAM模块作为一个级联的网络架构,由三个生成网络进行堆叠而成。由于文本图像的模式差异,针对Attn-GAN[26]仅对单词部分添加注意力的机制无法确保全局语义一致的问题,MirrorGAN提出了同时使用单词注意力和全局句子注意力,将两者进行平衡,达到增强生成图像的多样性以及语义一致性。在STREAM 模块中,通过生成的最终图像使用CNN[79]和LSTM[80]进行重新编码和解码,得到新的文本描述,与给定的文本进行语义上的对比,促进网络的生成质量。在整个框架的目标函数上,除了常用的损失,MirrorGAN 提出了一种基于交叉熵损失(cross entropy,CE)[81]的文本语义重建损失,进一步促进生成图像的语义上与给定文本进行对齐。
除了典型的MirrorGAN 的循环网络框架外,Lao等人[82]在对抗推理的方法上提出使用无监督的方法在潜在空间中将噪声中提取的图像风格和文本描述的内容共同体现。利用循环一致性损失来约束包含风格和文本的编码器以及解码器。Nguyen 等人[83]提出基于条件网络的反馈来循环迭代的找出生成器生成图像的潜在信息,并通过反馈使特征在图像中表现的更突出。
循环一致法的应用[84]可以更好地提取图像的风格样式等信息,通过循环反馈的方式灵活地使生成图像的风格多变,以此来提高最终图像的多样性以及语义一致表示。
然而,循环一致法也存在一些缺点:提取图像风格样式变换时,由于图像的整体布局和风格多变以及复杂语义文本的变化,最终生成图像的风格可能会改变,与预期不符。
循环一致法的定量比较如下:使用循环一致性的MirrorGAN在COCO数据上的IS值为26.47,比AttnGAN的IS 值提高2.24%,MirrorGAN 在CUB 数据集上的IS值为4.56,比AttnGAN的IS值提高4.59%。
2.2.1.6 对比学习法
近几年,对比学习在计算机视觉(CV)的自监督学习中取得了突破性的成功,引起了一些人极大的兴趣和研究。对比学习[85-86](如图10)是一种判别方法,利用相似性度量来衡量两个嵌入的接近程度,将类似的样本分组更接近,并将不同样本彼此远离。对比学习在GAN中的应用也逐渐广泛,ContraGAN[87]探索了类条件图像生成的对比学习。DiscoFaceGAN[68]添加了对比学习来强制解开人脸生成。
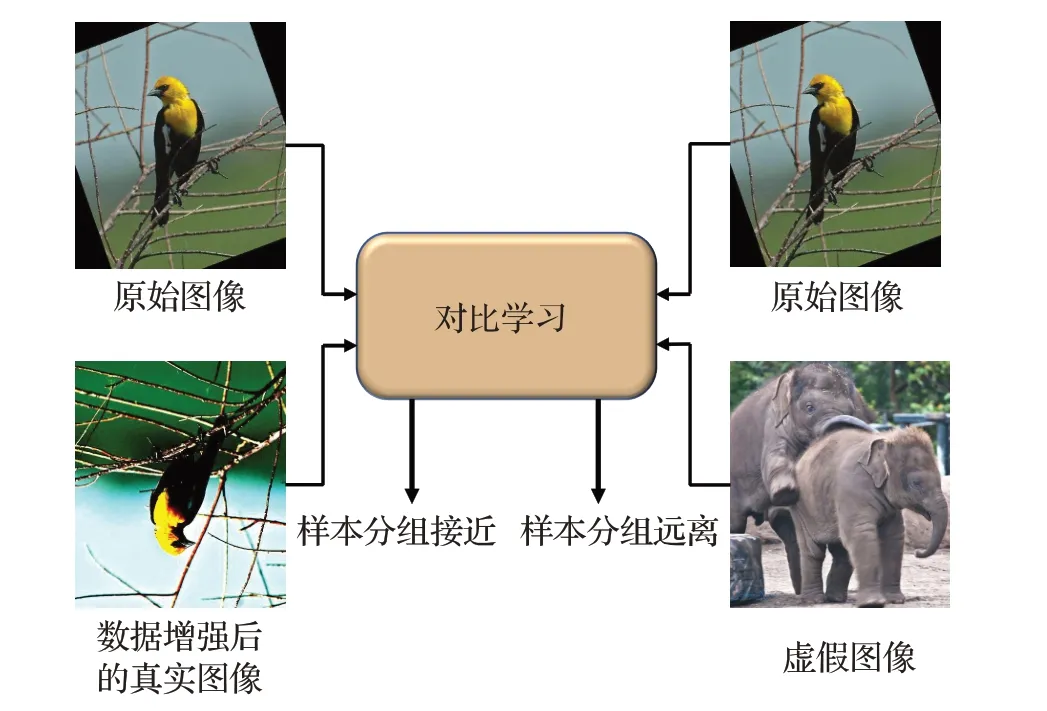
图10 对比学习思想Fig.10 Contrastive learning ideas
文本合成图像的目标是基于给定文本生成相匹配的视觉真实度高的图像,然而同一图像表达的含义在文本表达上存在着很大的差异,同一图像的标题间的文本表达差异会使生成的图像与预期不符。为了解决这一问题,将对比学习的框架嵌入到文本图像合成领域,使用对比学习思想可以有效地增强合成图像的质量并提高其语义一致性。
(1)现有模型(AttnGAN、DM-GAN)+对比学习
对于同一个合成图像的给定文本具有多种描述形式,这会导致生成的图像偏离了真实。Ye等人[53]提出了一种基于现有GAN的对比学习方法来提高合成图像的质量和语义一致性,利用对比损失将同一图像对应的标题聚集到一起,同时将不同图像的标题聚集到一起,以此在预训练编码器时学习图像-文本对中语义一致的文本表示。训练过程中利用对比损失最小化合成图像与真实图像的其他描述文本所合成的假图像之间的距离,最大化合成图像与其他图像的描述文本生成的假图像间的距离。这种方法是适应于当前基于GAN方法的通用框架,Ye等人[53]在AttnGAN[26]和DM-GAN[42]加入了对比学习框架,其应用效果远高于原模型。对比学习框架极大的增加了图像的视觉真实度和语义一致性。
(2)SD-GAN
SD-GAN[52](如图11)提出两个分支的连体网络架构,两个分支模型参数共享,每个分支输入不同的文本,对输出的图像采用对比损失来最大化分支中不同特征的距离并最小化类似特征的距离,以两个分支上共同的语义来学习语义在图像上的特征。是对比学习思想在文本图像合成领域的初步应用,此时模型只能学习连体网络的语义共性,SD-GAN还提出了语义条件批量归一化(SCBN)来生成细粒度的视觉模式,以此来提高生成图像的多样性。
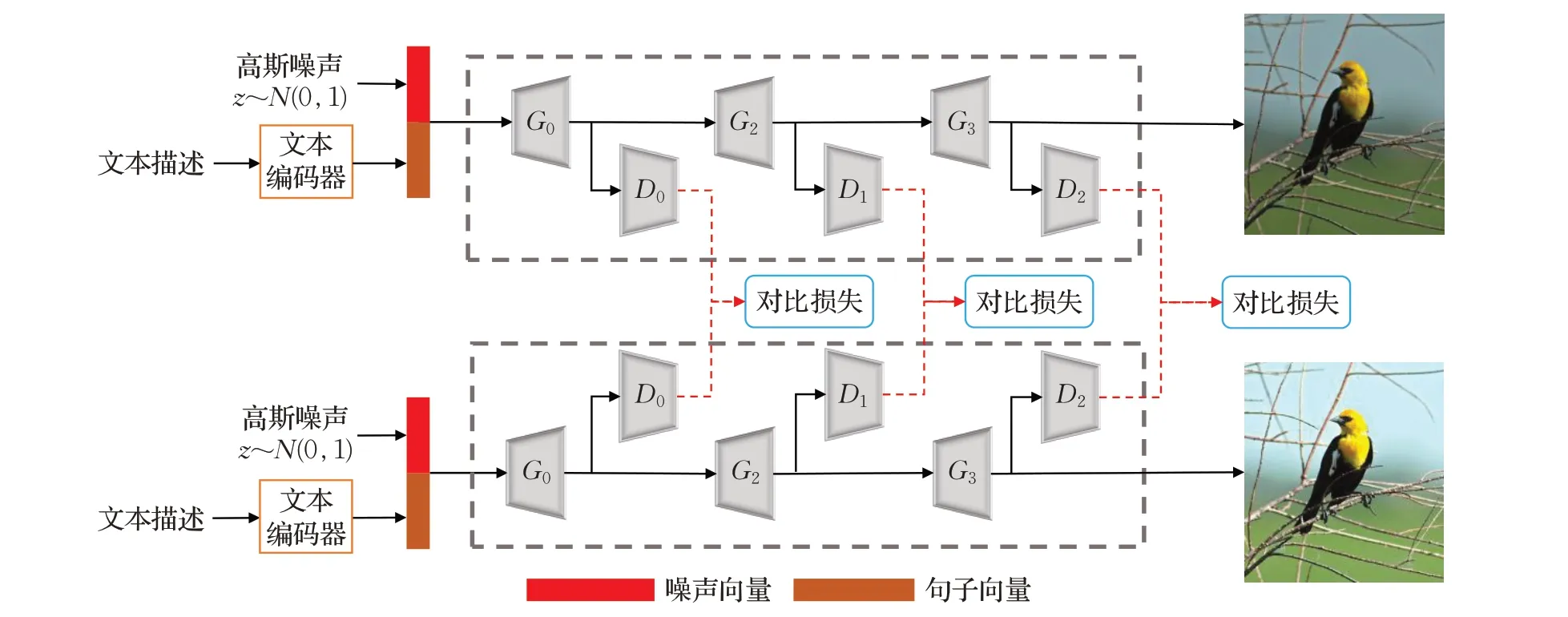
图11 SD-GAN框架Fig.11 SD-GAN framework
(3)XMC-GAN
目前的基于GAN的模型大多是加入注意力机制来实现关键性特征和细粒度特征的生成,但这些模型仅适用于处理简单图像文本数据集,面对复杂场景数据集时效果不佳;而其他利用图像中对象的布局来多阶段生成图像的方法需要更多的标签且无法很好的应用到现实场景中。Zhang等人[28]提出一种文本图像合成的跨模态对比学习方法(XMC-GAN)。
XMC-GAN利用对比学习的InfoNCE损失[88]来最大化相应对之间的互信息下限,分别从图像区域与单词、图像与句子、图像与图像三个方面学习测量两个模态的依赖性函数并利用对比损失加强合成的图像与对应文本相对齐。通过注意力自调制生成器(提高隐藏特征和条件输入的一致性)和对比鉴别器共同生成具有细粒度特征的视觉真实性强的可识别图像,同时保证其文本和图像的语义一致性。
对比学习作为一种自监督学习的方法,也是一种思想,减少了与监督模型的性能差距。Zhou等人[51]提出的TiGAN 利用对比学习来更好的实现文本到图像的映射从而促进交互过程中图像的一致性,在文本引导图像生成领域也有着突破性进展。对比学习框架的建立是为了下游任务获得更好的效果,在文本图像生成这个下游任务中,对比学习框架的嵌入通过建立和优化图像-文本间的对比损失来达到寻找图像文本的语义共性和促进生成图像多样性的目的。因此,基于对比学习的文本图像合成方法在图像质量,视觉真实度以及语义一致性方面都将优于现有模型。
对比学习法中,对比损失的建立至关重要,现在常用的包括Info NCE、NCE loss等,对比损失的是否合理将对模型的稳定性有较大影响。正负样本对的建立也会影响训练中模型收敛的速度与能力。该方法的缺点总结如下:
(1)对比学习的架构设计和采样技术会对下游任务的性能有着深远的影响,对比损失的建立不当极易导致模型的坍塌。
(2)对比学习会受到数据集偏差的影响,只有建立合理的正负样本对比较才能训练好模型的对比损失,否则会限制整个模型快速收敛的能力。
(3)研究其方法的泛化能力时需要更多对比学习中的各个模块的理论分析,但缺乏相应的理论基础。
对比学习法的定量比较如下:在对比学习法中,对比学习+AttnGAN在COCO数据集上FID值为23.93,比AttnGAN 的FID 值降低32.57%;在CUB 数据集上FID值为16.34,比AttnGAN 的FID 值降低31.86%。对比学习+DM-GAN在COCO数据集上FID值为20.79,IS值为33.34,比DM-GAN 的FID 值降低36.31%,IS 值提高9.35%;在CUB数据集上FID值为14.38,比AttnGAN的FID值降低了10.63%。SD-GAN在COCO数据集上的IS值为35.69,比对比学习+DM-GAN 的IS 值提高7.05%。XMC-GAN 在COCO 数据集上的FID 值为9.33,比对比学习+DM-GAN的FID值降低了55.12%。
2.2.1.7 场景对象布局法
目前大多数的方法都只能在文本简短,图像简单的数据集上(例如CUB 鸟类数据集、Oxford-102 花卉数据集等)取得较为不错的结果,而面对每个图像包含多个对象的复杂数据集(例如COCO数据集等),生成图像较为困难且效果不佳。因此,场景对象布局法提出在生成图像的过程中加入一个步骤,先生成图像的场景布局(或者是边界框等),以场景为基础为生成器提供反馈,并联合对应的文本描述,共同生成图像。
Liu 等人[89]提出预测以语义标签图为条件的卷积核,以此更好的利用图像生成器的语义布局,从噪声图生成中间特征图并最终生成图像。Hinz 等人[90]提出生成图像过程中引入生成单个对象的对象路径,生成以单个前景对象的边界框为条件的图像。Li 等人[44]提出的Obj-GAN是一种以对象为驱动的注意力生成网络,将注意力与场景布局相结合,更新了基于网格的注意力机制。Li 等人[69]提出的PasteGAN 以外部对象作为指导,基于注意力使用场景图引导图像生成,允许模型从其他图像中裁剪对象再将其粘贴进生成的图像中。Vo 等人[70]提出Stacking-GANs为给定的标题对应的对象加入边界框,利用标题生成视觉关系场景布局,促进图像的生成。
Sylvain等人[45]提出的OC-GAN以对象为中心,提出基于场景图的检索模块(SGSM),在整个场景中利用对象之间的空间关系,提高模型的布局保证度。加入条件实例边界来生成逼真的场景和清晰的对象。Hinz 等人[46]在原有对象路径的基础上,提出的OP-GAN专注于迭代的关注所有根据当前图像描述生成的单个对象,利用全局路径生成整个图像的背景特征,再将背景特征与逐个对象特征合并。专注于单个对象的特征往往比关注全局图像语义更好地生成逼真图像。
场景布局的方法在文本到图像的过程中加入一个中间状态,在预先展现的边界框,场景对象布局的基础上,调节生成器,促使生成逼真且场景丰富的图像,该方法能更好地适应复杂场景和对象的数据集,适应文本和图像约束,有效地提高了模型的关键属性的生成以及细粒度特征的体现。
在场景对象布局法中,场景与对象的提取和建立会对模型的效果影响较大,如图12所示,对象的边界框可能会发生多个重叠以及细小对象的边界框建立模糊会使最终图像的真实性以及对象关系的合理性产生影响。该方法的缺点总结如下:
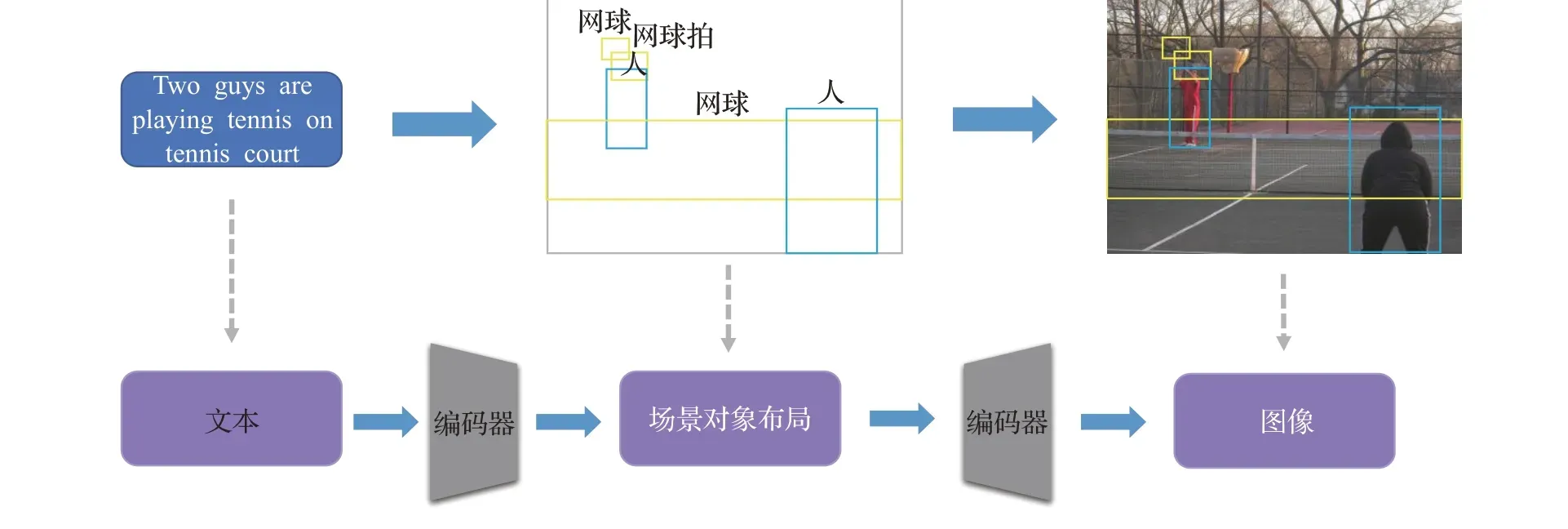
图12 基于场景对象布局方法的流程图Fig.12 Flowchart based on scene object layout method
(1)容易在布局中没有相应边界框的情况下生成虚假图像。
(2)利用场景布局的方法极容易在布局中出现重叠的边界框导致对应图像特征的合并。
(3)在原有的文本到图像的过程中加入场景布局的中间状态,这将需要耗费更长的训练时间和计算资源。
场景对象布局法的定量比较如下:在场景对象布局法中,PasteGAN 在COCO 数据集上FID 值为38.29,IS值为10.2。OC-GAN在COCO数据集上FID值为36.04,比PasteGAN降低了5.88%;IS值为17.0,比PasteGAN的IS 值提高了66.67%。OP-GAN 在COCO 数据集上的FID 值为24.70,比PasteGAN 降低了35.49%,IS 值为27.88,比PasteGAN的IS值提高了173.33%。
2.2.1.8 因果关系法
当前的模型大都以结果作为导向,仅依靠文本和视觉实体之间的映射来完成文本到图像的生成,模型更多强调的是图像的质量,忽略了图像生成过程中的因果视觉场景。且以文本中的行为动作为导向的图像生成缺乏挖掘。
Zhu 等人[54]提出的CookGAN 在食品烹饪的图像生成上基于文本的因果链实现。CookGAN通过在三对堆叠的生成器和鉴别器中加入“烹饪模拟器”来模仿真实的动作场景,利用门控循环单元(GRU)编码行为(烹饪)步骤,结果作为GRU的隐藏状态。在整个文本描述中,每一个动作(例如炒、切等)施加于已有的特征(例如成分、颜色、形状等)都会沿着过程对现有状态进行改变。整个网络可以控制文本中的动作和成分间的明确互动,将成分在动作中的改变准确的可视化。
基于因果关系的方法关注其特征和行为动作,使特征作用的捆绑效应可以被建模(例如同一特征在不同动作的情况下会发生改变),可以显著的表现出文本中的成分(可见或不可见)对最终图像生成的影响。因果关系的准确表达会使最终生成的图像更加符合复杂文本的内在联系,生成的图像视觉感知度更强,语义一致性更强。
该方法的缺点总结如下:
(1)目前在基于因果关系的方法上研究过少,适用的范围局限性较大(目前仅在食品烹饪领域),方法迁移后的效果有待考量。
(2)基于因果关系的方法需要尽可能考虑文本描述中的各个特征和动作,目前的方法考虑不完善(例如烹饪方式和成分数量未考虑完整等)。
基于GAN 的文本直接生成图像方法从2016 年取得初步成效,大都使用多阶段的网络架构以及初步注意力机制的应用,尽管在CUB 鸟类数据集等简单数据集可以准确生成文本描述的细节信息,但在COCO数据集等复杂场景中无法较好应用。2020 年,Vo 等人[70]提出的stacking-GANs和Hinz等人[46]提出的OP-GAN延续场景对象布局的方法,利用标题对应对象的边界框以及专注于单个对象的描述和全局背景的融合,继续提高了场景对象布局这一类方法的模型效果。近几年对比学习发展迅速,并且较为成功的嵌入到文本图像的合成中,2021 年,Ye 等人[53]提出的现有经典模型(AttnGAN[26]、DM-GAN[42])加入对比学习框架以及Zhang 等人[28]提出的XMC-GAN 都是将对比学习的思想应用于文本图像生成中,并且在复杂数据集(COCO)和简单对象数据集(CUB 等)上FID 值和IS 值都有着显著的影响。同时2020年Zhu等人[54]提出的CookGAN利用对象动作间的因果逻辑关系使得最终的图像中对象间的联系更加突出,语义一致性更高。基于GAN 的文本直接生成图像的各类方法间的效果比较如表2所示。
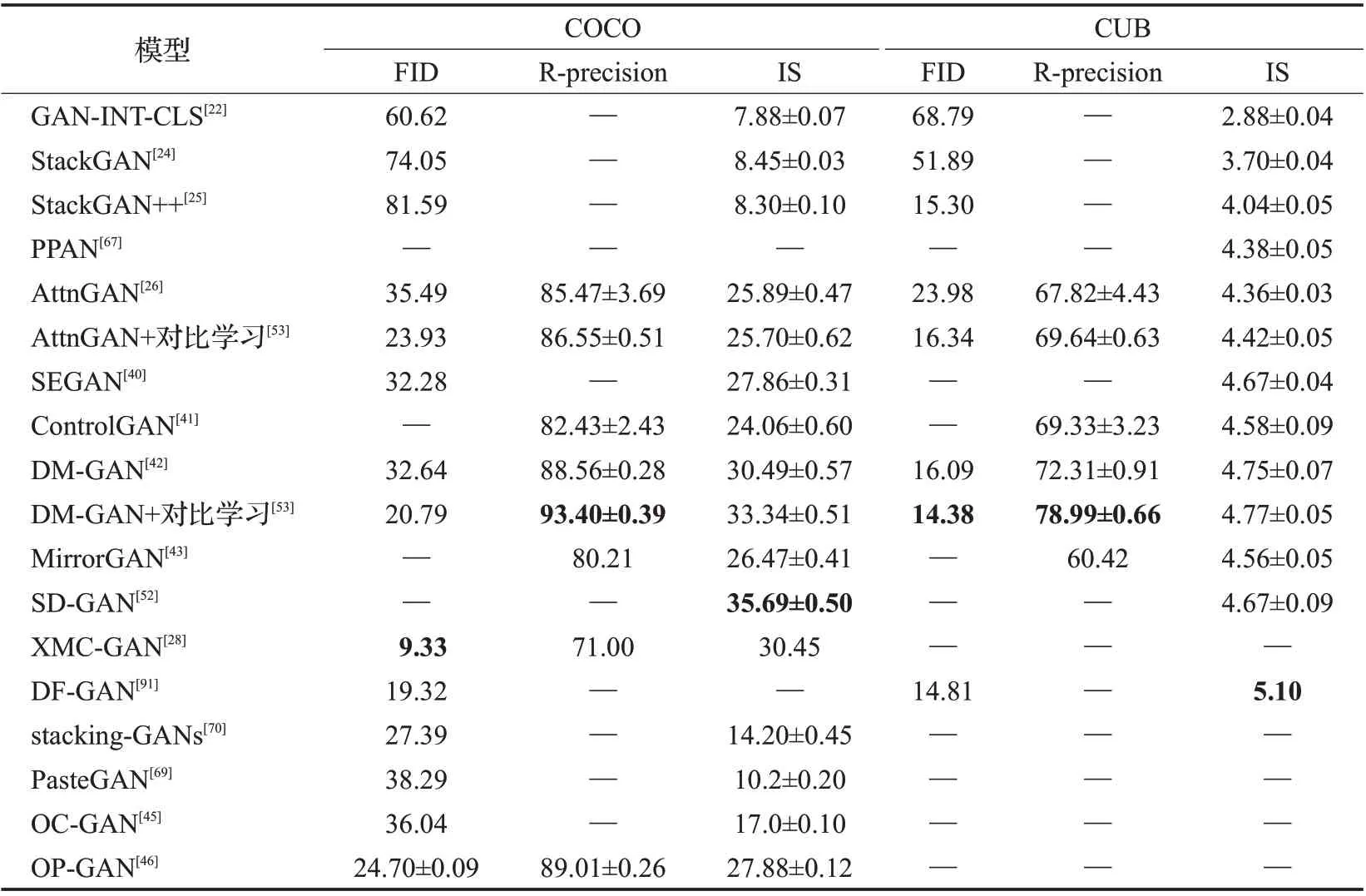
表2 文本直接生成图像模型的定量比较Table 2 Quantitative comparison of text direct synthesis image models
表2是上述文本直接合成图像模型的评估效果(FID值越低效果越好,其余指标值越高效果越好)。可见DM-GAN[42]在加入对比学习后在各个数据集的大多数指标的效果显著高于原模型和其他的模型;XMC-GAN[28]在COCO 数据集中FID 值达到了9.33,优于其他模型;DF-GAN[91]在CUB数据集中IS值达到了5.1,优于其他模型。表中“—”表示评估实验未用到该指标或该数据集。
2.2.2 基于文本引导生成图像
上文所述,基于文本直接合成图像的各类方法大多属于无监督范畴的方法,生成的图像只需要达到分辨率高,文本图像一致性强,图像生成质量高即可。而现实中更需要对于给定的图像,使用不同的文本进行区域性的编辑和改动,并在图像的其他部分仍然保留具体的细节,具有目的性和指向性改动的特点,该领域可以称之为基于文本引导图像生成[92]。Li 等人[41]提出的可控性文本图像生成模型ControlGAN为文本引导图像生成奠定了基础。目前文本引导生成图像领域仍有巨大的发展空间。本文将文本引导图像生成分为仿射组合法和基于StyleGAN法两类方法(如表3)。
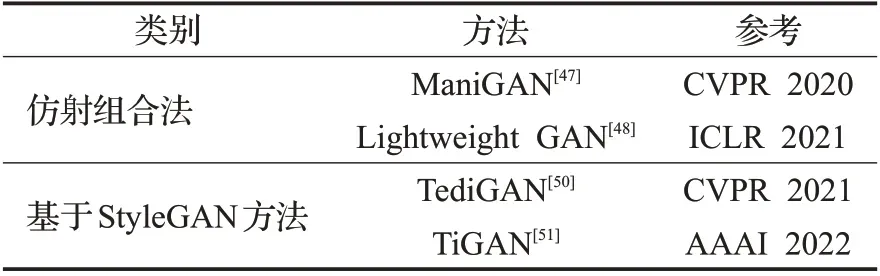
表3 基于文本引导生成图像的分类与参考Table 3 Classification and reference of generated images based on text guidance
在仿射组合法中,Li等人[47]于2020年提出ManiGAN,采用文本图像仿射组合模块将文本与对应图像区域仿射关联,且使用带有注意力机制的细节纠正模块对错误细节进行重构,维持新属性和原有细节的平衡[93]。为解决搭建轻量级架构(较少模型参数、训练所需计算资源少)下的图像质量变差情况,Li等人[48]在ManiGAN基础上提出Lightweight GAN,利用原有的部分框架加入包含词级监督标签的单词级鉴别器,以此构建结构简单的轻量型生成器网络。在基于StyleGAN 的方法中Xia 等人[50]于2021年提出TediGAN,利用反演图像编码器将图像映射到预训练StyleGAN[49]的潜在空间中,使用简洁的视觉-语言相似模块在潜在空间中进行实例级映射对齐。使用实例级优化模块重构不相关属性和改善与文本一致的属性。Zhou等人[51]于2022年提出的TiGAN利用多轮交互的图像生成,以StyleGAN2[94]为主干网络,集成了CLIP模型来评估文本与联合嵌入空间内的图像间的语义相似性,利用对比学习的思想,加入对比损失促进模型解开文本到图像的映射和中间特征。目前,文本引导图像生成领域的研究较少,会面临很多问题,如潜在空间中的属性纠缠,引导产生的低质量图像,或无法有效处理的复杂情况下的场景等。下文将对仿射组合法、基于StyleGAN两类方法进行具体介绍。
2.2.2.1 仿射组合法
(1)ManiGAN
基于给定文本引导图像合成的关键就是同时利用自然语言和图像的跨模态信息,生成新的匹配属性样本,同时保留与文本无关的原始图像内容。当前大多方法都是选择沿着通道方向直接连接图像和全局句子特征[95-96],这样会带来一些潜在问题,如不能准确地将细粒度词和需要修改的属性进行关联;或者无法有效识别与文本无关的内容,无法将其重构。Li 等人[47]提出Mani-GAN(如图13)利用文本图像仿射组合模块(ACM)与细节校正模块(DCM)来产生高质量的保留原有细节特征的图像。
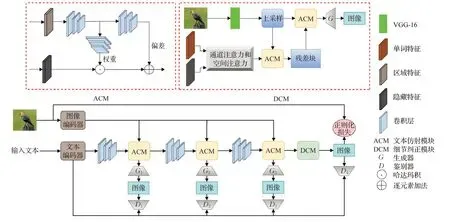
图13 ManiGAN框架Fig.13 ManiGAN framework
ACM模块是ManiGAN中最重要的模块,它主要包含两个部分:第一个是将给定文本描述的相关区域与图像进行关联,通过关联的语义词生成新的对应的图像属性,达到替换原图像特征的目的;第二个部分是将原图像进行重新编码,对文本未描述到的部分进行重构,生成新的文本下的图像。ACM 模块的最大特点是,相较于现有方法无法准确区分修改和重建的图像区域,无法在新属性和原有细节上达到平衡。ACM模块使用的文本与图像之间的乘法,可准确地对修改区域进行选择和细粒度重构,再对图像无需修改部分重新编辑。DCM 模块在单词级特征上进行生成图像细节的修改,添加空间和通道注意力将词级特征进行关联,加强对细粒度特征的调整来达到细节重构缺失,校正错误属性。ManiGAN 的目标函数提出了额外的正则化项[66],如式(4),
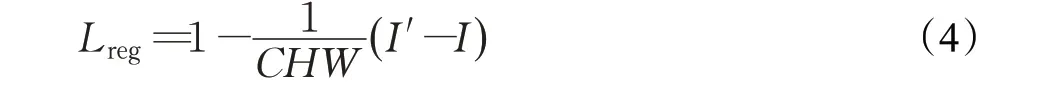
式中I′表示真实图像分布的采样,I表示修改图像后的结果,通过加入正则化来防止生成的图像与输入图像相同,以此来确保生成图像多样性。
(2)Lightweight GAN
长时间的训练推理和巨大的内存计算需求使基于GAN 的图像生成研究变得困难。Li 等人[47]在训练ManiGAN 时减少模型的参数,而最终的图像质量明显变差。ManiGAN的鉴别器无法为生成器提供的单词建立细粒度训练反馈,较少的模型参数下无法将图像属性和对应文本之间建立确切的联系。因此Li 等人[48]在ManiGAN的基础上提出了一个轻量级文本图像生成网络(lightweight GAN,Lw-GAN)(如图14)。它包含了两个部分:单词级鉴别器、轻量级架构的生成器。
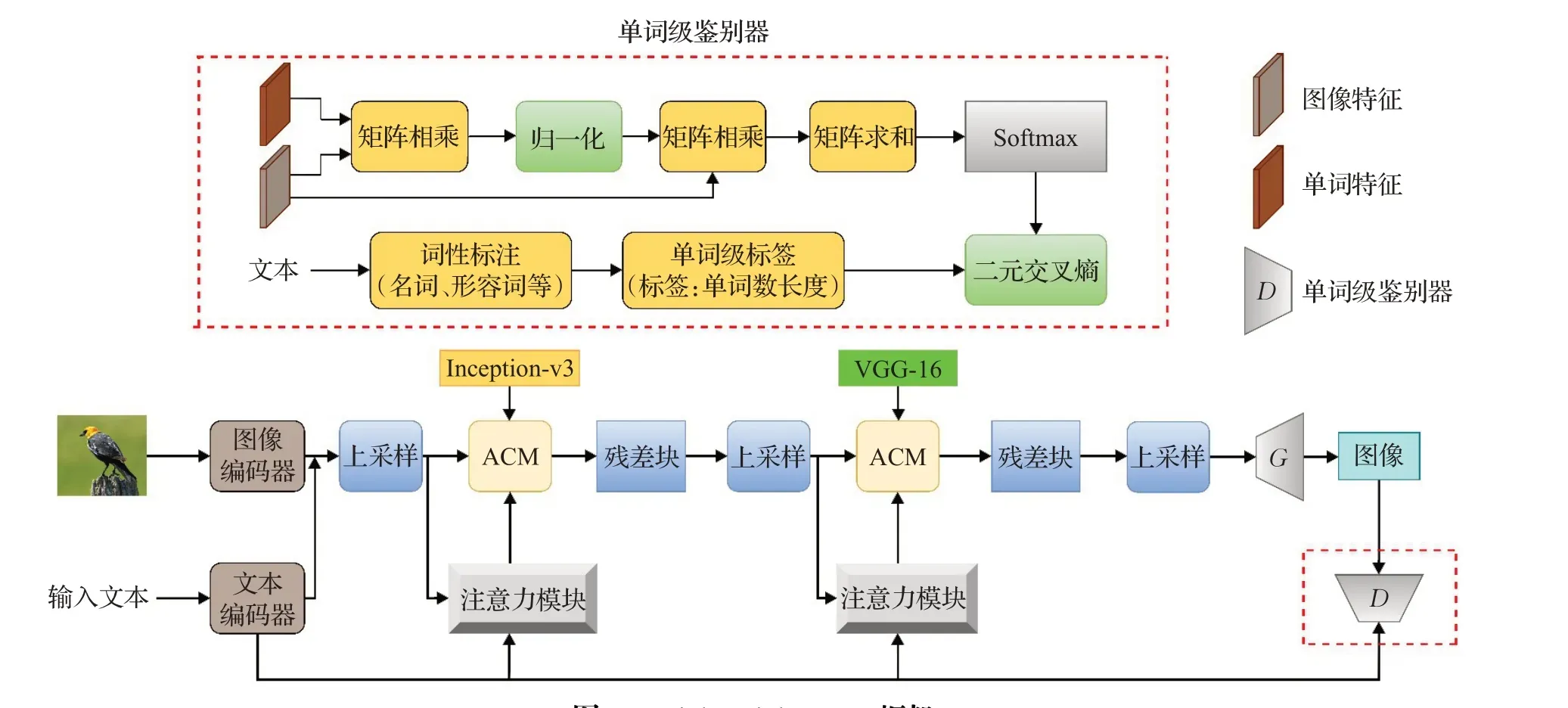
图14 Lightweight GAN框架Fig.14 Lightweight GAN framework
单词级鉴别器中使用词级监督标签和词级鉴别器,前者为生成器提供的每一个词(主要保留名词和形容词)进行训练反馈,建立生成图像与对应文本间准确的对应关系,保证训练参数较少时也能正确地进行映射。在单词级鉴别器和ManiGAN 的大致框架下,可以构建一个结构简单的轻量级生成器网络。模型仅依靠文本编码器、图像编码器以及一些少量的ACM模块、残差模块、上采样组成,且只需要一对生成器和鉴别器,模型对前后两个ACM 模块利用两种不同特点的图像编码器Inception-v3[97]和VGG-16[98],前者网络层更深,提取的特征更具有语义性,后者较浅,提取的特征包含更多内容细节,使得最终生成的图像文本描述区域和其他不变区域质量都较高[99]。多阶段的多对生成器和鉴别器框架需要依靠更大的内存,需要大量的时间进行训练和推理,无法移植到有限的设备上(例如手机、平板等)进行使用。Lw-GAN 的提出使得较少参数下的图像生成质量提高,竞争性更强,在生成图像的质量层次上也高于ManiGAN。
ManiGAN和Lw-GAN模型作为仿射变换法的核心就是其主要的仿射变换(ACM)模块,在文本到图像的跨通道上,利用文本与图像的元素乘法促进了文本描述与对应区域的关联以及重构,避免简单的沿通道方向连接文本与句子导致的图像粗糙。DCM细节处理模块和单词级鉴别器加强了训练反馈和细粒度特征的修改和保留。仿射变换法使得最终的模型视觉真实性高,多样性强,未改动的细节保留完整。
对于仿射组合法,文本与图像之间仿射变换的模态间乘法结果可能会使模型最终产生错误的布局及对象关系等。其次,多阶段的仿射变换会对计算资源的完备有较高要求。该方法的缺点总结如下:
(1)使用跨模态的元素乘法有时会有细节的错误生成,与新属性的稳定共存也需要进一步的探索和完善。
(2)使用多对生成器和鉴别器的多阶段框架较为繁重,训练的稳定性需要加强,使用计算资源较多;Lw-GAN 的轻量型架构在图像生成质量上与多阶段框架仍具有一定差距,需要考虑两者的平衡发展。
仿射组合法的定量比较如下:仿射组合法中,Lightweight GAN 在COCO 数据集上的FID 值为12.39,比ManiGAN 的FID 值(25.08)降低50.60%;Accuracy 值为77.97,比ManiGAN的Accuracy值(22.03)提高253.93%;Realism值为67.53,比ManiGAN的Realism值(32.47)提高107.98%。Lightweight GAN在CUB数据集上的FID值为8.02,比ManiGAN 的FID 值(9.75)降低17.74%;Accuracy值为65.94,比ManiGAN的Accuracy值(34.06)提高93.60%;Realism值为57.82,比ManiGAN的Realism值(42.18)提高37.08%。
2.2.2.2 基于StyleGAN方法
(1)TediGAN
针对如今性能最好的一些文本图像生成方法,大多是采用多阶段的网络框架。StyleGAN[49]是2020 年基于ProGAN[100]提出的模型,沿用了渐近性网络,加入映射网络,使得特征更好分离,生成图像更加随意,且加入自适应规范化(AdalN),从低分辨率到高分辨率都由style控制。受StyleGAN映射网络和AdalN的启发,提出了一种GAN 的反演技术[101-102]——TediGAN[50],将文本、标签、草图等多模态信息映射到一个训练好的StyleGAN 的公共潜在空间(如图15)[50],再对其进行操作。与现有的多阶段网络框架不同,TediGAN 统一了整个过程,直接可生成高质量的图像。TediGAN 包含了StyleGAN 反演模块、视觉-语言相似模块、实例级优化模块。
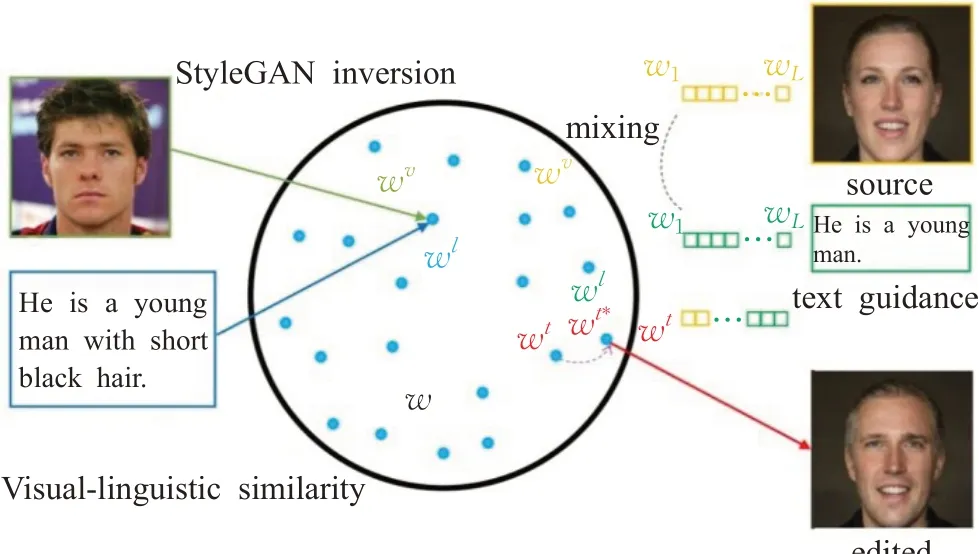
图15 StyleGAN潜在空间Fig.15 Latent space of StyleGAN
StyleGAN反演模块将多模态信息(例如文本、语义标签、草图等)映射到预训练的StyleGAN模型的潜在空间中,通过StyleGAN 的无监督性提高方法的多样性。视觉-语言相似模块不同于往常的图像-文本编码器,它将图像和对应的文本投影到训练好的公共空间中学习与视觉表示一致语言表示,以此来进行图像和对应文本之间的联系和实例级对齐。相比较于DAMSM,该模块更简洁,更易于训练。实例级优化模块以文本的反演潜在代码作为初始化,图像编码器作为正则化使潜在代码保留在生成器的语义域内,使得在潜在空间中可以准确的编辑与文本描述一致的属性和原来存在的细节属性。最终得到高质量,多样性强的生成图像(图像分辨率可达到1 024×1 024)。TediGAN 的关键部分是预训练好的StyleGAN 的潜在空间,潜在空间覆盖面足够广则可以保证模型的鲁棒性较强。
(2)TiGAN
真实用户和模型交互的过程中,自然语言的反馈很难预测,交互式的图像生成将文本引导的图像操作推广到多轮设置。文本到图像的映射和交互过程中的难以理解的图像操作是难以避免的挑战。
现有的方法将图像映射到潜在空间中,操作潜在向量生成预期图像,更多的在操纵潜在向量方面进行改进,针对Xia等人[50]提出的TediGAN利用编码器将不同模态映射到潜在空间中,Zhou 等人[51]提出的TiGAN 将文本和图像都映射到联合的潜在空间中,再对文本和图像潜在向量中的元素重新组合。TiGAN将StyleGAN2[94]作为模型的主干,联合预训练的对比语言图像模型(CLIP)[103],CLIP作为一个预训练的多模态模型,可以将图像和文本映射到统一的联合嵌入空间中,以此可以评估文本和联合嵌入空间中图像的语义一致性,提供训练反馈。TiGAN 利用映射网络和可以在给定文本描述而生成样式向量的模块构成整个合成网络,在CILP 提取的文本特征下精准改动预想的图像区域,保留先前交互的信息。
TediGAN 与TiGAN 都 是在基于StyleGAN 的模型上,将文本和图像映射到训练覆盖面广的潜在空间中进行潜在向量的重新组合,实现文本对图像的引导。基于StyleGAN 的方法中,潜在空间的建立直接影响着最终的模型效果,广度和深度越完整的潜在空间会使最终模型图像的细粒度特征建立的越丰富。该方法的缺点总结如下:
(1)潜在空间的覆盖面需要足够大,图像的微小细节在生成器未覆盖到的区域内无法很好的体现。
(2)与文本无关的属性在潜在空间中可能会纠缠导致特征无法重新映射到引导后的图像中。
基于StyleGAN方法的定量比较如下:基于StyleGAN的方法TediGAN 在CelebA-HQ 数据集上的FID 值为107.25,比仿射组合法中的ManiGAN 的FID 值降低9.03%;Accuracy 值为59.1,比ManiGAN 的Accuracy 值(40.9)提高44.50%;Realism 值为63.8,比ManiGAN 的Realism 值(36.2)提高76.24%。基于StyleGAN 的方法中,TiGAN 在COCO 数据集上的FID 值为8.9,比LightweightGAN的FID值(12.39)降低28.17%;在CelebA-HQ数据集上的FID值为11.35,比TediGAN的FID值(107.25)降低89.42%。
从2016 年开始,文本直接生成图像的方法开始逐渐完善,而仅在近两年,文本引导图像生成的方法才开始研究与探索。在该领域中,提出的仿射组合法(ManiGAN、Lw-GAN)延续了文本直接生成图像的一般方法,在多阶段的级联网络中加入文本和图像元素间的仿射变换以及细节保留模块,Lw-GAN中更是加入单词级鉴别器来促使最终引导的图像语义一致性高,细节效果保留更完备,并促使保证图像质量的前提下,模型的轻量化。而提出的TediGAN和TiGAN则是在StyleGAN中的潜在空间中操作,将文本和图像的潜在向量进行关联组合,以此达到引导图像生成的目的。同时TiGAN利用了对比学习预训练的CLIP模型来提高文本图像特征间的关联和语义一致性并完整保留先前的图像信息。基于GAN的文本引导图像生成的各类方法间的效果比较如表4所示。
表4 是文本引导图像生成模型的评估效果(FID值越低效果越好,其余指标值越高效果越好)。可见Lw-GAN[48]在CUB、COCO 数据集上评估效果全面超过ManiGAN[47],而TediGAN[50]在CelebA-HQ数据集上也超过了ManiGAN。此外,TiGAN[51]在COCO数据集与CelebAHQ 数据集中的FID 值达到最优,分别是8.9 和11.35。表中“—”表示评估实验未用到该指标或该数据集。
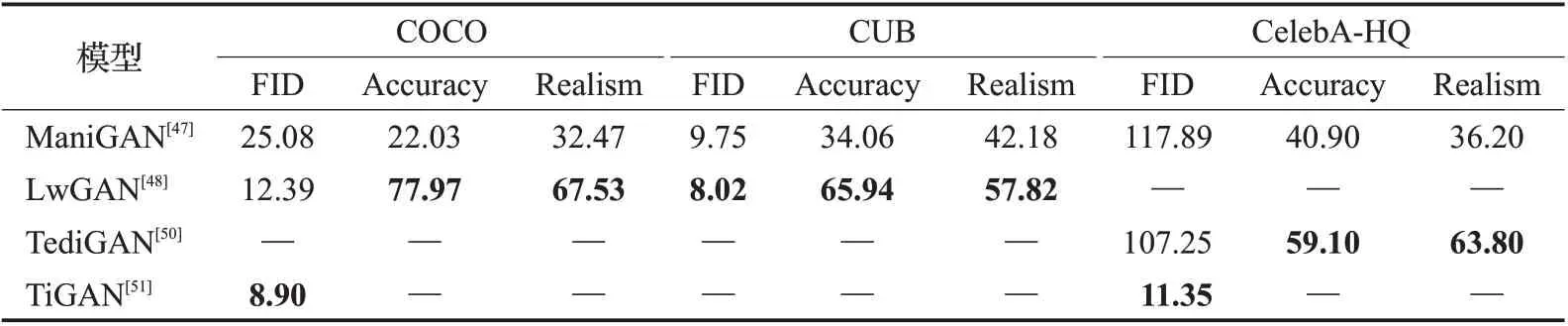
表4 文本引导图像生成模型的定量比较Table 4 Quantitative comparison of text-guided image generation models
为了评估文本图像合成方法的实用价值,对不同方法的复杂度进行了分析对比。如图16 所示,从GANINT-CLS到最近的XMC-GAN、TediGAN的模型架构图来看,图像生成模型的复杂度在不断提高,计算资源的需求也在变大。与此同时,最终生成图像的效果也越佳,语义一致性、多样性以及视觉真实性也在不断提高。
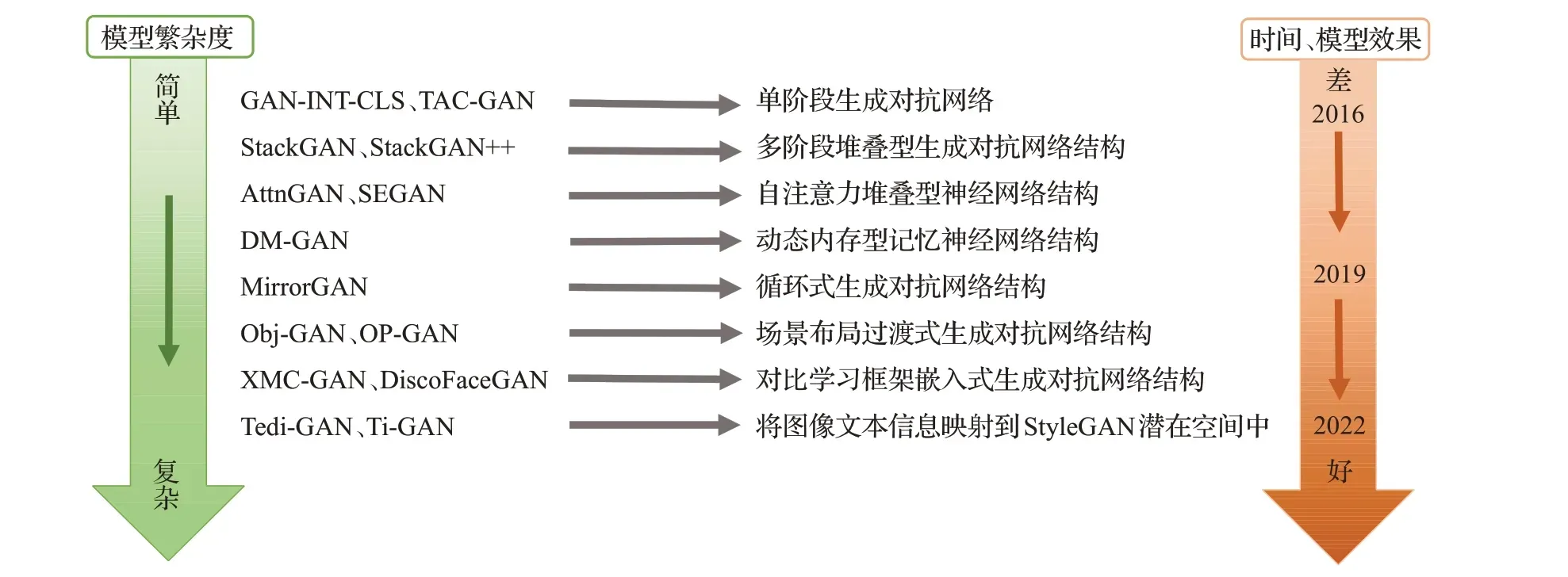
图16 模型复杂度与模型效果的发展流图Fig.16 Development flow diagram of model complexity and model effect
3 文本图像生成常用数据集
高质量模型的研究需要更多高质量、大型的数据集去验证其效果和精度以及提高模型的泛化能力。优质数据集的建立往往更能推动图像领域的发展。
在文本图像生成领域,GAN 中最常用的数据集包括Oxford-102花卉数据集、CUB鸟类数据集、COCO[31]、CelebA-HQ[100]等。
Oxford-102 花卉数据集中包含了102 个类别的花,共有8 189张图片数据,每张图片对应着10个不同文本的描述。CUB鸟类数据集和Oxford-102相类似,图片都是对单个对象的展示,不过CUB数据集中包含200个类别的鸟类图片数据,共有11 788张图片数据。
COCO 数据集几乎是目前使用的最大的数据集,2014版本中包含了超过80 000张训练集图片,40 000张测试集图片,拥有80个类别的thing类别(人、汽车等)和91种stuff类别(天空、陆地等),其拥有比其他数据集更多的对象场景且分辨率较高,可用于提高模型的细节。
CelebA-HQ 是专注于人脸的数据集,包含了超过30 000张高分辨率人脸图像,有着详细的描述文本。此外CIFAR10[104]、FASHION-MNIST[105]数据集也经常被使用。
4 评估指标
评价一个生成模型的质量,需要从三个角度来进行分析。首先是图像的生成质量,要考虑到生成图像是否清晰、图像是否符合要求、是否全面等。其次是生成图像的多样性,是否生成的类型多样也很关键,不仅仅是某一种或几种的图像。最后是生成图像的评价,最终的图像也需要人工对其进行观察和评估。
Inception score(IS)[32](如式(5))是文本生成图像领域最常用的评估指标之一,它客观地从图像的生成质量和多样性两个方面进行评估。它更多地使用预训练好的Inception v3模型来计算边缘分布和条件分布之间的Kullback Leibler(KL)散度。
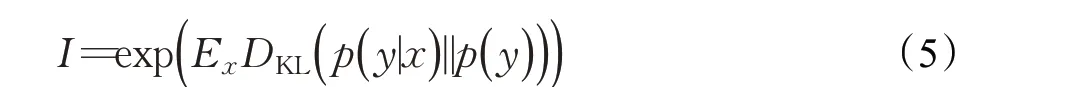
其中,E表示期望,DKL表示两分布间的KL 散度。IS得分越高,即KL 的值越高,说明生成图像的质量越高,多样性更丰富。
Frechet inception distance(FID)(如式(6))[33]也是该领域常用的指标之一,它用来描述两个数据集之间的相似性程度。FID 也使用预训练好的Inception 模型对图片中的特征进行编码,再计算原始图像数据分布和生成图像数据分布间的Frechet距离。
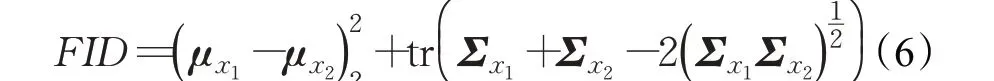
x1、x2表示真实图像和生成图像,μx1、μx2表示各自特征向量的均值,Σx1、Σx2表示特征向量的协方差矩阵,tr 表示矩阵的迹。FID值越低,两个图像的分布越接近,图像越相似,生成图像的质量越高。
IS指标可以反应图像质量和多样性,却体现不了生成图像与原始图像间的相似程度,FID指标刚好与之相反。两者各有利弊,因此,在文本合成图像领域更多的同时使用两个指标进行评估。但IS 和FID 指标只能粗略评估图像质量,无法更好体现文本描述和图像间的相似程度。一些模型中也会用到人工评估(human rank)指标,来弥补此缺陷,通过图像的真实性和语义一致性来评判图像的相似度以及文本和图像间的符合程度。同时,R-precision 指标也经常用于计算生成图像和文本描述间的余弦距离从而评估其相关性。此外,Accuracy、Realism、Similarity、VS、文本图像相似度(sim)、像素差(diff)、操纵精度(MP,如式(7))等指标也会用来验证模型的性能。
MP=(1-diff)×sim(7)
表5 中总结了上文中提到的绝大多数模型的图像分辨率、优缺点,使用的数据集以及评估指标。评估指标包括IS、human rank、FID、多尺度结构相似性(MS-SSIM)、R-precision、VS、MedR(median rank,检索性能的中位数,值越低,检索能力越好)、MP、sim、diff、Accuracy、Realism、NoP-G/D(生成器或判别器中的参数数量)、RPE(每个epoch的运行时间)、IT(生成100个新修改图像的推理时间)、学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)[106]等。
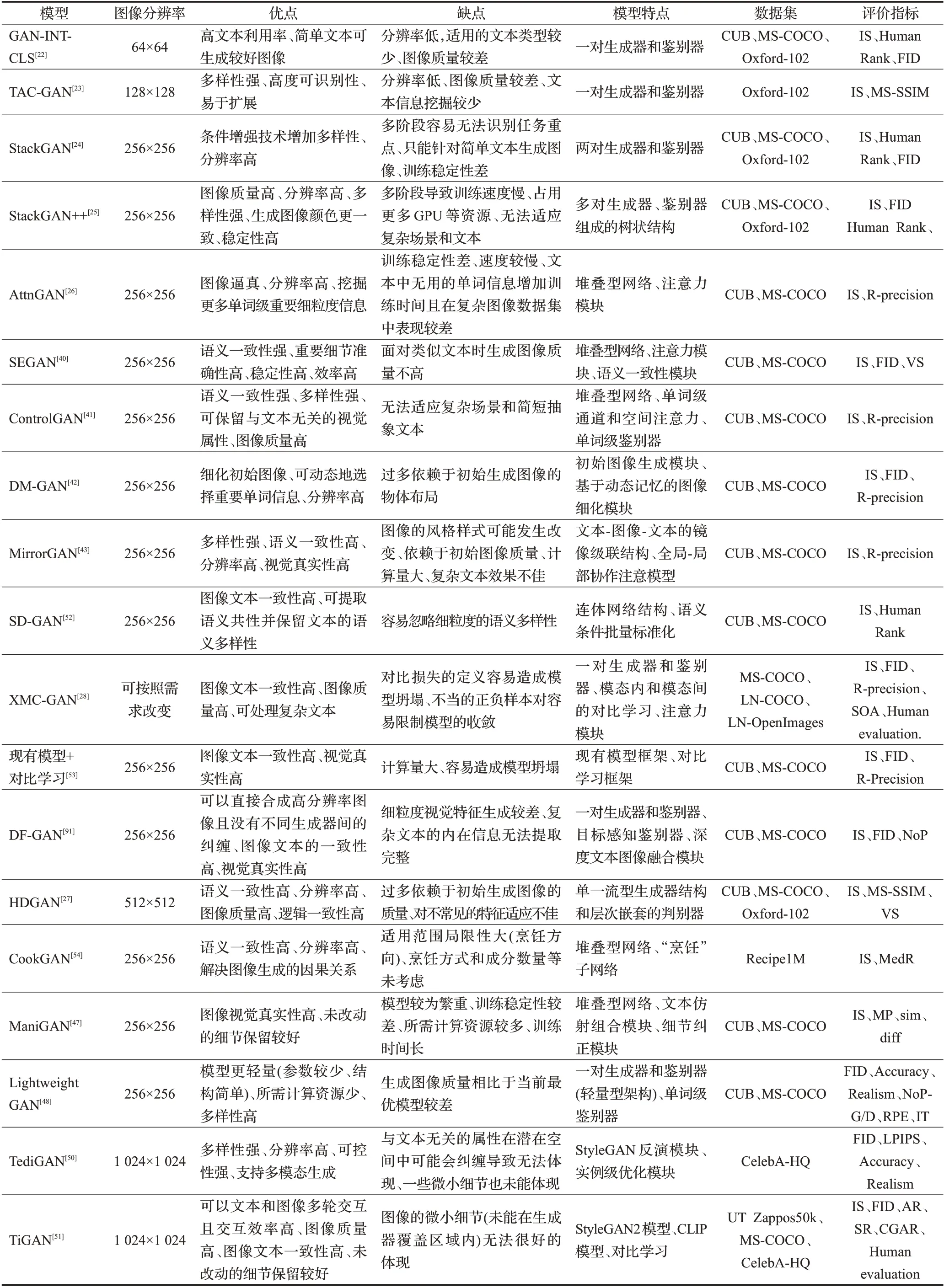
表5 所提模型在文本到图像合成领域的总结Table 5 Summary of proposed models in field of text-to-image synthesis
5 展望
文本图像合成是涉及自然语言处理和图像生成的跨模态研究,目前的方法虽然已经在生成图像质量方面以及图像和语义一致性方面有大幅度的提高。但是在已经达成共识的一些问题(例如文本图像合成过程中的解释性不足,以及如何利用更好的词嵌入模型处理文本等)之外仍然有很多难点待研究。
(1)复杂场景与复杂文本的适应。目前的基于类型一致性的模型在对花、鸟等简单对象的视觉一致性上有较好的约束,但缺乏对复杂场景的多目标视觉一致性约束。针对复杂场景图像,需要将文本视觉表示引入到多标签分类、多目标对象的识别和分割模型中。同时,目前大多模型以图像单条描述语句为研究对象,更为复杂的文本(例如段落式文本、组合型文本描述、对话交互式文本等)也具有很高的研究价值,对复杂文本中不同语句描述内容在图像中的定位、大小以及语句间的交互关系都是需要解决的问题。因此,如何进一步挖掘文本视觉表示和更复杂的视觉识别模型的融合以及文本图像的迭代和交互式操作再生是未来重要的研究方向之一。
(2)多模态的模型。目前在文本到图像合成的模型有了极大的发展,受益于文本到图像,语音到图像可以将已有的文本编码器替换为语音编码器,该方法在未来或许会得到更多的关注。此外利用文本生成视频或许也是未来重要的研究方向之一,但需要探索更多的语音视频评估方法。
(3)轻量化模型和弱监督、无监督方法的应用。局限于数据集的庞大和设备内存的不足,繁重的模型不适用未来在有限时间内的便携式或轻量型设备上(例如手机、平板等)广泛推广,使用较少训练次数和模型参数的轻量型网络或许是文本生成图像领域的未来重要的研究方向之一。同时目前大多数模型都是基于大量文本和类标注的数据集,但人工标注的代价极为昂贵,若利用少量标注信息的图像可以挖掘更多的文本-图像信息或许可以减少模型的监督依赖。
(4)注意力机制的深入应用。自注意力机制[107]可以通过计算图像中像素点之间的关系来协调生成图像的细粒度特征和文本描述的主要特征细节。结合目前最新的目标检测技术和超分辨率重建技术,深度注意力机制的探索与应用或许可以进一步优化模型,依据文本找到实例级别的对应关系,生成分辨率更高、细节与结构更加丰富的图像。
(5)模型评价方法。目前的模型大多使用IS、FID等常用指标评价模型,但存在很多模型在评估时又提出其他的评估方法(或许仅对本模型适用),同时,模型在不同的主观因素(例如实验过程的变动、图像分辨率等)下,使用同样的评估指标会产生不同的结果。此外,使用不同的评估指标可能会导致评价图像合成质量的相互矛盾。因此,探索可以适用于绝大多数模型的优点和局限性公平比较的评价指标是未来需要完善的重要方面,这将有利于更系统、更科学地评价和对比各个模型。
6 结束语
基于计算机视觉和自然语言处理任务的高速发展,将两者搭建联系的跨模态文本图像生成任务是近几年迅速发展的研究方向之一。本文详细地从文本编码、文本直接合成图像、文本引导图像合成三个方向全面回顾了各种基于GAN的文本生成图像方法和网络结构。本文首先在各个类别中将各个模型进行对比分析,介绍了代表性模型的框架和关键贡献(StackGAN[24]、AttnGAN[26]、DM-GAN[42]、ManiGAN[47]、TediGAN[50]、XMC-GAN[28]、TiGAN[51]等);介绍了数据集的发展过程,从单一对象的CUB,Oxford-102的数据集到图像内容丰富的COCO数据集,不断地从庞大且丰富的数据集中训练和验证模型的性能。本文还重新研究了最常用的评估技术(IS、FID、human rank 等),从图像质量、多样性、语义一致性三个方面来评估生成的图像。最后,从复杂场景和文本表示、多模态模型、轻量型网络等角度客观地评价了该领域可能存在的不足和未来的研究方向。总之,文本图像合成是一项具有挑战性的课题,有着重要的研究价值,本文的目的也是为基于GAN 的方法进一步研究提供参考。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
初中生世界·九年级(2018年12期)2018-12-22
第二课堂(课外活动版)(2016年2期)2016-10-21
读者(2015年9期)2015-05-04
长江学术(2015年1期)2015-02-27
初中生世界·八年级(2014年2期)2014-03-15
意林(2011年10期)2011-05-14
中学英语之友·高一版(2008年10期)2008-12-11
