
多负例对比机制下的跨模态表示学习
2022-10-18 01:02丁凯旋陈雁翔赵鹏铖朱玉鹏盛振涛
计算机工程与应用 2022年19期
丁凯旋,陈雁翔,赵鹏铖,朱玉鹏,盛振涛
合肥工业大学 计算机与信息学院,合肥 230601
现如今,互联网上存在海量的诸如图像、文本以及音频等不同形式的多模态数据。相较于单模态数据,多模态数据之间的信息互补性使其在某些特定的任务中具有一定的优越性[1-2]。因此,多模态机器学习在近年来取得了空前的发展。特别是跨模态表示学习,其广泛应用于跨模态检索[3-4]、图像字幕生成[5-7]以及视觉问答[8-9]等领域中。跨模态表示学习旨在拟合不同模态数据之间的异质性差距,在特征层面建立起模态间的语义联系并扩大模态内的类别差异(如图1 所示)。早期的研究者主要利用CCA[10]进行跨模态表示学习,其通过最大程度地利用不同模态数据之间的相关性来学习公共子空间。此后CCA衍生出了许多变体,KCCA[11]通过核函数引入非线性映射,改善了CCA 单纯的线性映射;DCCA[12]则利用深度学习的方法研究两个数据视图的复杂非线性变换以使不同模态样本特征的最终表示形式高度相关联;GMA[13]是CCA在监督任务上的拓展算法,它使用数据的类别信息来学习子空间。在目前的主流方法中,跨模态表示学习一般分为两个步骤:第一步是获取每种模态数据对应的特征表示,第二步是在共享子空间中建立特征间的语义关联性以获取良好的跨模态表示。LCFS[14]同时从两种模态中选择相关特征和判别特征,使学习到的子空间更加有效。ACMR[15]基于对抗学习的思想,并针对特征投影构造了三元组损失,以最小化具有相同语义标签的不同模态特征表示间的语义鸿沟,同时最大化语义不相关的跨模态特征表示在子空间中的距离。DSCMR[16]通过在共享子空间和标签空间中最小化区别度损失来学习跨模态特征的相关性。Peng 等人[17-18]联合模态内和模态间的信息,通过分层学习机制来挖掘复杂的跨模态相关性,以获得跨模态共享表示。Salvador等人[19]和Surís等人[20]借助相似度损失和正则化损失,实现了严格的跨模态特征对齐。Zeng等人[21]提出了基于Cluster-CCA 的深度三重态神经网络,以此来最大化不同模态数据在共享子空间中的相关性。
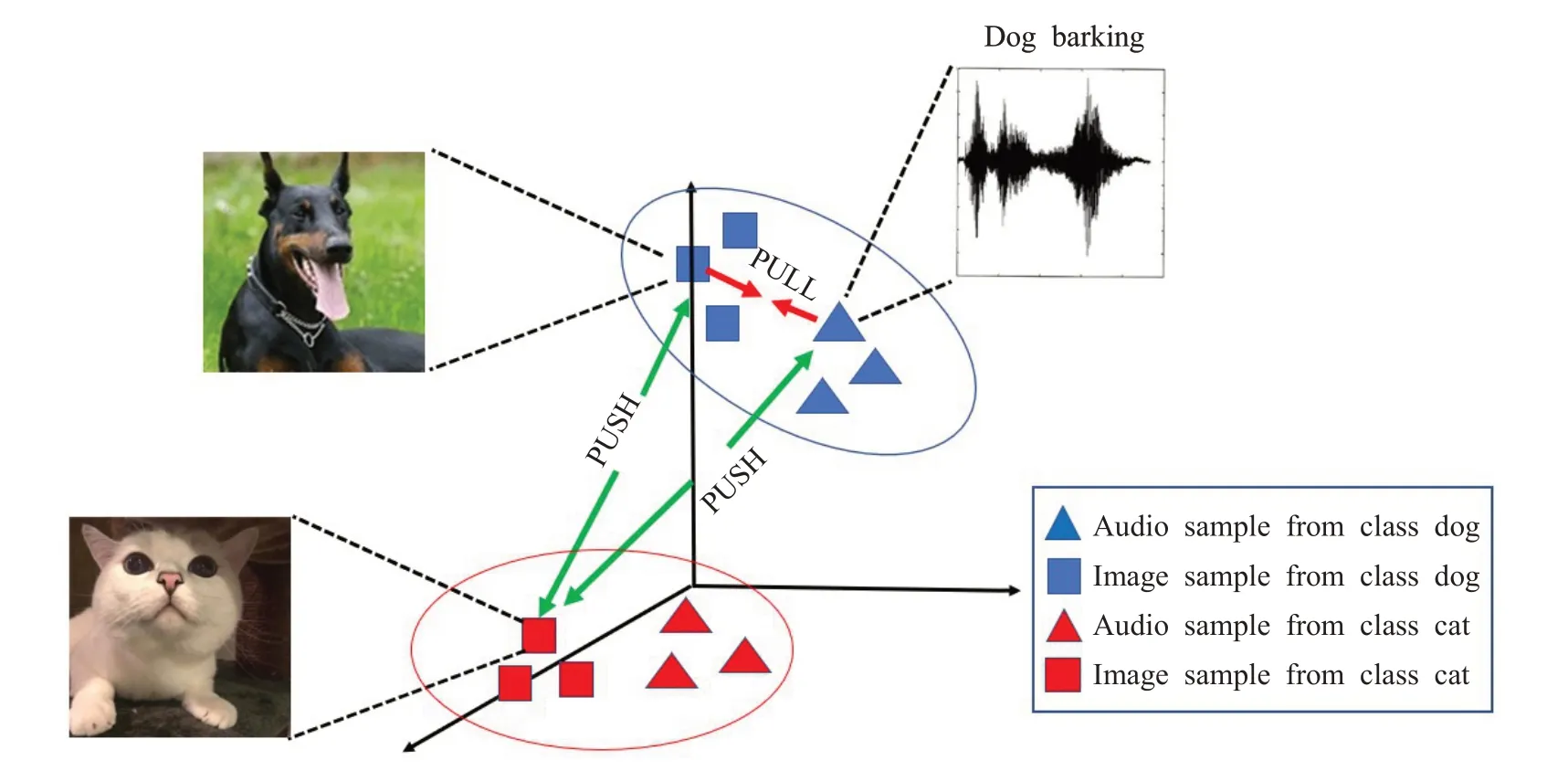
图1 跨模态表示学习的可视化Fig.1 Visualization of cross-modal representation learning
虽然跨模态表示学习领域硕果累累,但是仍然有很大的进步空间。无论样本属于哪种模态,本文将属于相同类别的数据定义为正例,属于不同类别的数据定义为负例。现有的大多数方法在特征空间仅使用少量负例进行训练,未能充分利用跨模态数据集提供的类别信息来辨识类内的区别性和类间的相关性。受到监督对比学习[22]的启发,本文将多负例对比机制应用到跨模态表示学习中,即在训练阶段让正例特征与多个负例特征之间进行对比,使模型学习到的跨模态表示具有模态一致性和语义区分性。现有的跨模态任务大多聚焦于视觉模态和文本模态,然而视觉和听觉是人类与外界环境进行交互时更为重要的媒介,并且视听觉之间存在着十分自然的关联性。例如,当听见狗叫声时,狗的样子可能会浮现在脑海中。因此,有必要对视听觉之间的关联性进行更为深入的研究。在此背景下,本文提出了SCCMRL 算法来进行跨模态表示学习,并将其应用于视听觉跨模态检索任务中,构建了相应的跨模态检索系统,最后结合Sub_URMP数据集和XmediaNet数据集中的视听觉数据实施了一系列实验。实验结果表明,本文提出的SCCMRL算法在跨模态表示学习过程中具有优良的性能表现。综上所述,本文的贡献主要如下:
(1)提出了一种新颖的跨模态表示学习算法SCCMRL,该算法在监督信息的指导下,采用端到端的学习策略,在训练阶段引入了多负例对比机制,使相同类别的数据样本在特征空间中的语义距离尽可能靠近,而不同类别的数据样本的语义距离尽可能远离。与此同时,SCCMRL 利用标签损失和中心损失进一步维护跨模态表示的模态一致性和语义区分性。
(2)将学习到的跨模态表示应用于跨模态视听检索任务,构建出视听跨模态检索系统,并且针对Sub_URMP数据集和XmediaNet数据集实施了大量的实验,实验结果证明了SCCMRL方法要优于现有的跨模态表示学习方法。
1 相关工作
1.1 负例对比损失函数
负例对比损失函数即利用正负例之间对比来突出类间区别性,其广泛应用于人脸识别和视听觉对应等领域中,其中比较有代表性的是contrastive loss[23]和triplet loss[24]。

1.2 多负例对比机制下的表示学习
表示学习的核心就是学习一个映射函数f,把样本x编码成其表示f(x)。而对比学习就是使得f满足公式(3):

公式中的分子即锚样本与正样本的向量积,分母则为锚样本与正样本的向量积加上锚样本与所有负样本向量积的和。在优化该式的过程中锚样本与正样本的向量积逐渐增大,即距离缩小;锚样本与负样本的向量积逐渐缩小,即距离增大。实际上,这种对比思想已经广泛应用于自监督学习领域并取得了良好的效果。He 等人[25]提出负例样本数量在对比学习中十分重要,并采用动量更新的训练方式来解决内存库和端到端这两种方式在大样本数量下的所存在的问题。Dai等人[26]使用对比学习来解决图像字幕中标题文本可区别性的问题。Oord 等人[27]则是通过自回归模型与InfoNCE 损失建立真实帧与预测帧之间的对比关系。
1.3 跨模态检索
以往的检索工作只关注单一模态[28],而跨模态检索的目标是实现不同模态数据间的相互检索,其首先需要解决的问题就是如何消除不同模态数据样本之间的异质性差距,因为这种异质性差距使得多模态数据表示间的特征相似性变得难以度量[29]。通过将不同模态特征投射到子空间,进而在子空间中学习到不同模态间的共生关系。Ngiam等人[30]、Wang等人[31]利用深度卷积神经网络提取不同模态的特征并建立其对应的跨模态语义联系。Kumar等人[32]、Ding等人[33]以及Wang等人[34]则利用哈希变换将不同模态特征映射到一个汉明二值空间,然后在汉明空间实现快速的跨模态检索。
跨模态检索的方法大多应用于图文检索,然而视觉与听觉是人类与外部世界进行交互的重要媒介,因此有必要研究如何实现视听跨模态检索。现有的一些研究已经对视听跨模态检索进行相当深入的探究。Zeng等人[21]利用聚类CCA 和深度三重神经网络学习使得视频与语音的正负例特征之间的区别更加明显。Surís 等人[20]则利用分类损失和相似度损失将视听觉模态数据投射到一个共同特征空间,以此来获取联合的视听觉表示。
2 提出的方法
本章将介绍提出的多负例对比机制下的跨模态表示学习方法(SCCMRL)。该部分首先对本文的研究方法进行一个简单的表述,然后阐述SCCMRL 的整体架构和所构建的损失函数,最后介绍了网络在训练与优化过程中所使用的策略。
2.1 研究方法
目前,多负例对比机制已经广泛应用于自监督表示学习中。然而自监督任务没有提供标签,通常只能对锚样本进行数据增强来获取正例,而将数据集中其余的样本都视作负例。但这样的负例中极有可能会出现与锚样本属于同一类别的样本,造成了假负例现象,从而使对比学习在拉远正例与这种假负例特征之间距离的过程中获得了坏的样本表示。本文受到监督对比学习[22]的启发,在监督信息的指导下将多负例对比机制与跨模态表示学习相结合,提出了SCCMRL 方法。该方法在标签信息的指导下允许每个锚样本有多个正例,消除了假负例现象,并且通过与多负例样本特征之间的对比,使得正例之间的语义距离更近,负例之间的语义距离更远,从而维护了跨模态表示在共享子空间中的模态一致性和语义区分性。在这项工作中,仅关注并研究了视觉模态数据(图片)和听觉模态数据(语音)。将第j个图

2.2 模型架构
SCCMRL 的目标是把跨模态数据投射到一个共享子空间中以获取跨模态表示,并且该跨模态表示在共享子空间中应具有模态一致性和语义区分性。因此,基于该目标构建了SCCMRL 的总体模型架构,如图2 所示。该模型是以端到端的方式进行训练,其包含了视觉编码器和音频编码器这两个子网络。视觉子网络和音频子网络参考了L3-Net[35],具体参数细节如图3 所示,其中图(a)是视觉编码器的参数细节,图(b)是音频编码器的参数细节;每一部分中的蓝色矩形块代表卷积层,黄色矩形块代表池化层,每个块内第一行代表层的名称,第二行代表层的参数:卷积层的参数分别表示卷积核的大小和通道数;池化层的参数表示步幅的大小,并且没有填充;每个卷积层之后是批归一化层和ReLU非线性激活函数。视觉编码器的输入为224×224×3的图片,音频编码器的输入为257×200×3的声谱图,在视觉编码器和音频编码器后还分别添加了一个全连接层,最终获得维度一致的图片特征fI和语音特征fA,然后针对fI和fA设计监督对比损失函数,从而使正例特征与多个负例特征形成对比,让正例特征之间的语义距离更加接近,并逐渐拉开正例特征与这些负例特征之间的语义距离。假设在共享子空间中获取到良好的视觉表示与听觉表示,那么这种表示对于分类任务来说也必然是理想的。因此,SCCMRL 模型在原有的视觉编码器和音频编码器后连接一个共享权重的线性分类层,通过该线性分类层,图片和语音的类别特征xI和xA也被捕捉到,利用类别特征与标签信息分别计算中心损失与标签损失。通过这样的模型结构设计,跨模态特征的模态一致性和语义区分性能够很好地被学习。SCCMRL 模型的总损失定义为标签预测损失、中心损失、监督对比损失的加权和,各损失函数的定义详见下文所述。
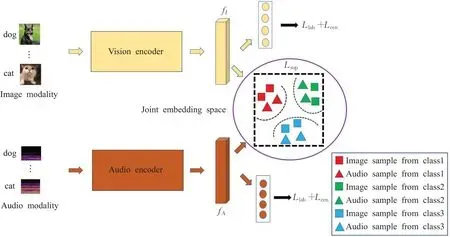
图2 SCCMRL模型的总体结构Fig.2 Overall structure of SCCMRL model
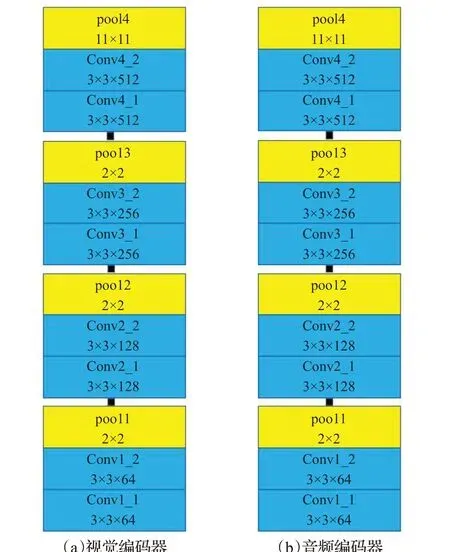
图3 视觉编码器和音频编码器的参数细节Fig.3 Detailed parameters of visual encoder and audio encoder
2.2.1 监督对比损失(supervised contrastive loss)
监督对比损失采用多负例对比机制,能够使得训练集中不同类别样本间的数据特征距离更远,同时使得相同类别样本间的数据特征距离更近。此外,要想实现监督对比损失,正例与负例的定义至关重要。给出一个锚样本数据,无论它属于哪种模态,将正例定义为与锚样本属于同一类别的样本数据,负例定义为与锚样本属于不同类别的样本数据。即正负例的定义只关注样本数据是否属于同一类别,而不关注它们是否属于同一模态。因此,锚数据与正例构成正样本对,锚数据与负例构成负样本对。监督对比损失中的得分函数要求能够对正样本对产生高值,对负样本对产生低值。一般地,可以选择点积和余弦距离作为得分函数,这项工作中把得分函数定义为公共子空间中的样本特征的点积。在监督对比编码中,每个批次中的某个锚样本可能会有多个样本和它属于同一类别,包括相同模态和不同模态。因此SCCMRL中的监督对比损失定义如下:
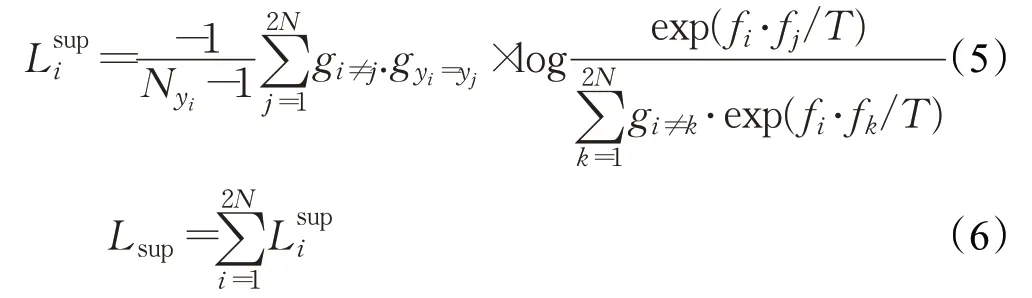
其中N为批次大小,yi代表批次中第i个样本的类别标签,yj表批次中第j个样本的类别标签,Nyi表示批次中类别为yi的样本总数,g(·)的函数定义为:当下标·式为真时函数值为1,否则为0。因此,当fi代表锚样本的特征,fj表示正例样本的特征,fk表示批次中除fi之外所有的样本特征,T代表温度超参。公式(5)表示单个锚样本fi在这个批次里所贡献的监督对比损失,公式(6)表示轮流将批次里的数据作为锚样本来计算总的监督对比损失。当优化整个损失函数时,锚样本与正例之间的点积增大(即余弦距离缩小),而锚样本与负例之间的点积减小(即余弦距离增大)。从损失函数的定义可以看出,由于提供了类别标签,监督对比损失在每个批次里可以处理任意数量的正例样本,并且对于每个锚样本,监督对比损失都会将它与批次中的所有负例进行对比,以使正样本对特征之间更加紧凑,负样本对特征之间更加稀疏。因此,通过这种方式获得的跨模态表示既具有模态一致性又具有语义区分性。
2.2.2 标签损失(label loss)
在进行特征提取后,SCCMRL 模型在视觉编码器和音频编码器后分别添加一个共享权重的线性分类

2.3 训练与优化策略
算法1 SCCMRL的优化步骤

SCCMRL 模型总损失被定义为标签损失、中心损失和监督对比损失的加权之和,即:

其中α、β、γ分别为标签损失、中心损失和监督对比损失的权重系数。在这项工作中,将α、β、γ分别设置为0.05、0.05、0.9。初始学习率设置为0.01,采用变动学习率的策略,每30 轮后学习率降为原来的1/10。使用Adam优化器对SCCMRL模型进行优化,并使用端到端的训练策略。此外,SCCMRL 是基于Pytorch 框架进行模型的设计与搭建,并在一块NVIDIA GTX 1080Ti GPU 进行训练。算法1 中展示了SCCMRL 的训练步骤与优化细节。
3 实验
本文使用Sub_URMP 数据集和XmediaNet 数据集作为实验的基准数据集。为了验证所提出的SCCMRL模型的有效性,在这两种不同的视听数据集上实施了两种任务:跨模态检索和多模态分类。跨模态检索展示了SCCMRL 模型能够很好地建立不同模态数据的语义相关性,多模态分类则表明SCCMRL 模型能够捕捉各种模态内的语义区分性。
3.1 数据集介绍
3.1.1 Sub_URMP数据集
Sub_URMP 数据集是URMP(University of Rochester Multimodal Music Performance)数据集的子集,由罗切斯特大学于2016年发布。Sub_URMP数据集中包含13 类乐器(巴松管、大提琴等)的视听觉双模态信息,分别是乐器演奏的音频和对应的图片。整个数据集是在高清视频下裁剪得到的,在同一个乐器演奏视频下每隔0.5 s截取音频和图片,人为地删去了其中的无声音频和其对应的图片,并选择其中的部分作为训练所用,最后得到了8 151张图片和对应的音频。
3.1.2 XmediaNet数据集
XmediaNet 数据集是北京大学专为跨模态检索任务而设计的大规模多模态数据集,其包含文本、图像、视频、音频以及3D 模型这5 种模态的数据,包含超过100 000个实例的样本数据。选择其中的图片模态和音频模态进行实验。图片和音频都包含多个类别,例如狗叫声、闹钟、键盘打字等。其中的一些特殊对象,例如自行车、闹铃、门铃,统一用铃声作为对应的音频;小船、小汽车、公共汽车统一用引擎声作为对应的音频。对于这样的情况,在数据集中只保留其中一种对象。由于语音片段长度不固定,需要将其统一分割为1 s的语音长度,并通过LMS算法将语音片段生成声谱图,最后获得24个类别共计2 448张图片和2 994个声谱图组成的数据集。
3.2 跨模态检索
为了验证所提出模型的有效性,对其进行了跨模态检索实验,通过对比实验和消融实验来定量地验证SCCMRL 模型的性能表现,并直观地展示了跨模态检索的结果。
3.2.1 对比实验
将mAP(mean average precision)作为跨模态检索性能好坏的评估标准。mAP是跨模态检索领域一个经典的评估标准,它是对查询样本和所有返回的检索样本之间进行余弦相似度或欧式距离的计算(实验中选择余弦相似度),综合考虑了检索结果的精确度和排序信息。在具体的跨模态检索实验中,实施两种不同的任务:用查询图片检索语音样本(Img2Aud)和用查询语音检索图片样本(Aud2Img),并进行了两组对比实验如下:
(1)与仅使用少量负例损失的模型进行比较
为了证明多负例对比机制在跨模态表示学习过程中确实优于少负例对比机制,对比了supervised contrastive loss(Sup loss)、contrastive loss(Con loss)以 及triplet loss(Tri loss)在跨模态表示学习中的表现。为了减少客观因素对实验结果的影响,在实验中摒弃了center loss(Cen loss)和label loss(Lab loss),并且将权重系数均设置为1。
表1 和表2 展示了Sup loss、Con loss 和Tri loss 在跨模态检索任务中的表现,从中可以看出Sup loss在跨模态表示学习中的表现明显优于Con loss 和Tri loss。由此证明,相较于使用少量负例对比的损失函数,采用多负例对比机制的监督对比损失能够更加有效的形成类间区别性,从而获取更为优秀的跨模态表示。
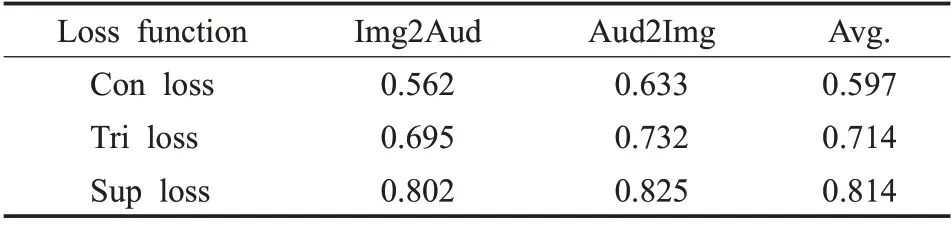
表1 不同损失函数在Sub_URMP数据集上的表现(mAP)Table 1 Performance(mAP)of different loss functions on Sub_URMP dataset
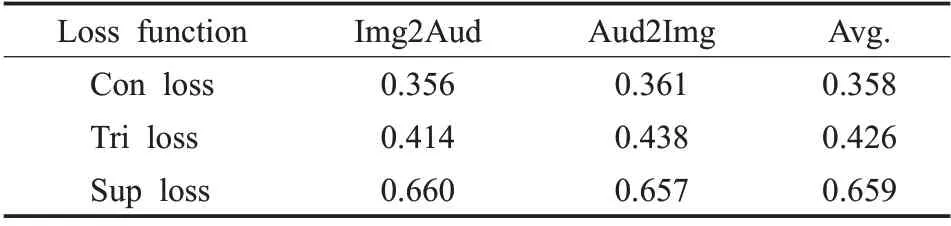
表2 不同损失函数在XmediaNet数据集上的表现(mAP)Table 2 Performance(mAP)of different loss functions on XmediaNet dataset
(2)与当前常用的跨模态检索方法进行比较
现有的大多数跨模态表示学习方法都是聚焦于图片和文本模态之间的跨模态检索,SCCMRL 很难直接同它们进行比较。虽然不同模态的特征提取方法不尽相同,但在特征提取后的处理方式基本相似。因此对现有的模型进行细微的修改,将文本编码器替换为音频编码器,整体模型结构仍与原有方法保持一致。最后,将它们应用到Sub_URMP数据集和XmediaNet数据集上,并和所提出的模型SCCMRL进行实验结果的对比。表3 和表4 展示了SCCMRL 模型和一些现有方法在两种视听数据集(Sub_URMP 和XmediaNet)上的表现。从两张表中的数据可以看出,SCCMRL 的表现要优于目前常用的跨模态检索模型。
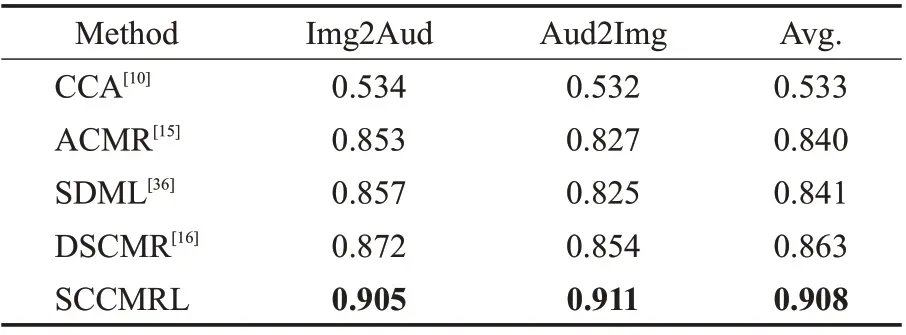
表3 不同模型在Sub_URMP数据集上的表现(mAP)Table 3 Performance(mAP)of different models on Sub_URMP dataset
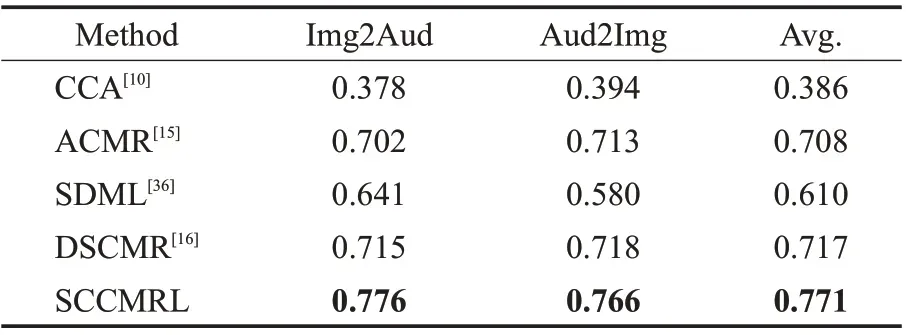
表4 不同模型在XmediaNet数据集上的表现(mAP)Table 4 Performance(mAP)of different models on XmediaNet dataset
3.2.2 消融实验
为了验证SCCMRL 模型所提出的3 种监督对比损失对模型性能的影响,在XmediaNet 数据集上进行了消融实验。消融实验在Sup loss、Cen loss、Lab loss 系数设置为0.9、0.05、0.05的前提下进行。
表5的实验结果表明了Sup loss的存在是模型表现优异的主要原因,进一步说明了多负例对比机制在跨模态表示学习中的有效性。Cen loss 和Lab loss 的添加则进一步增强了不同模态表示间的模态一致性和语义区分性,对模型性能也具有一定的提升。
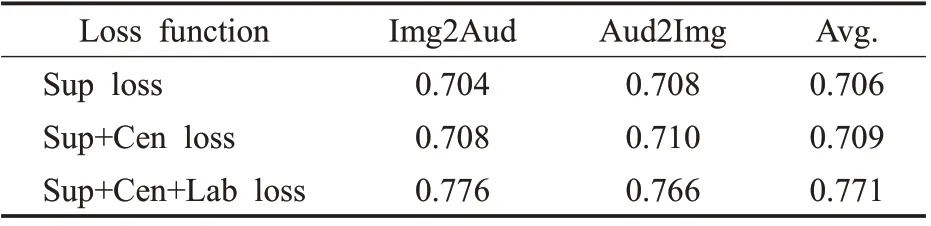
表5 不同损失函数在XmediaNet数据集上的表现(mAP)Table 5 Performance(mAP)of different loss functions on XmediaNet dataset
3.2.3 跨模态视听检索效果展示
除了上述对跨模态检索结果的定量分析,还在图4中直观地展示了跨模态检索的结果,图(a)是查询项(图片或声谱图),图(b)是在该查询条件下检索出的另一模态排名前五的结果。
图4结果表明,无论是由图片检索声谱图或是由声谱图检索图片,SCCMRL 模型的检索结果均对应于查询项的标签,直观地表明SCCMRL 方法在跨模态检索任务中的优越性。
3.3 多模态分类
为了验证SCCMRL模型能够捕捉各种模态内的语义类别信息,将学习到的图片表示和语音表示应用到分类任务上,分类结果的好坏可以间接反映所学习到的跨模态特征表示的语义区分性。在目前主流的分类模型中,最经典的方法是利用交叉熵损失,将学习到的特征向量向one-hot 标签拉近,再将其通过softmax 激活函数,从而预测类别标签。将SCCMRL 模型同仅使用交叉熵损失的分类模型进行对比,表6分别展示了两种方法在分类实验上的性能表现。对于Sub_URMP 数据集中的图片数据分类,二者均获得了100%的准确率;而在音频的分类上,SCCMRL 的表现要略优于传统的交叉熵模型)。对于XmediaNet 数据集,其中的数据构成相对复杂,进而导致其对于分类实验并不友好,例如,其中的乐器图片是由人和乐器组成的,而不是单独的乐器图片,并且存在易拉罐和瓶子这种在视觉效果上差别不大的图片类别。即便如此,SCCMRL 依然实现了88.4%的图片分类准确率(优于交叉熵的70.8%)和82.2%的语音分类准确率(优于交叉熵的73.3%)。总体来看,SCCMRL 方法在多模态分类任务上具有一定的优越性,认为这是因为监督对比损失更自然地进行正负例样本特征之间的对比,进而在特征空间中将同一类别的样本表示拉近到一起,让不同类别的样本表示互相远离,而不是像交叉熵那样强迫它们被拉向特定的one-hot标签。
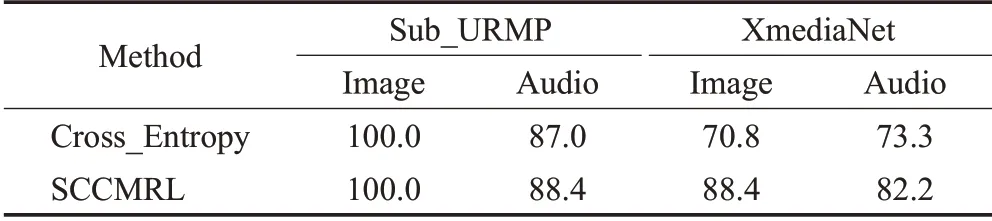
表6 分类准确率的比较Table 6 Comparison of classification accuracy单位:%
为了直观地展示跨模态表示学习效果,选取了XmediaNet数据集中10个类别的图片和语音数据,并使用t-SNE方法将它们的特征进行了可视化。图5和图6分别展示了SCCMRL方法所学习到的特征表示。从图5 和图6 可以看出,当不同模态的高维特征进行降维之后,相同类别的特征表示依然紧凑,而不同类别的表示则相距甚远,进一步反映了SCCMRL 所学习到跨模态表示兼具模态一致性和语义区分性。
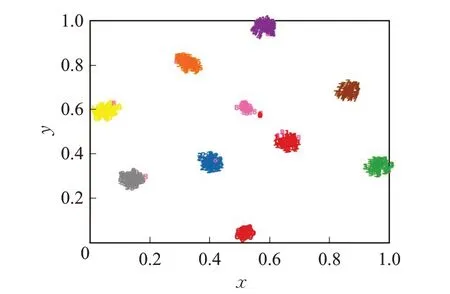
图5 图片特征的t-SNE可视化Fig.5 t-SNE visualization of image features
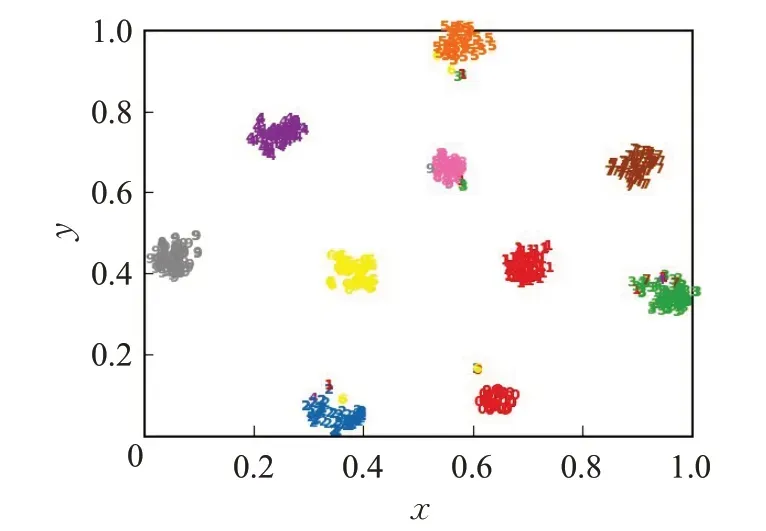
图6 语音特征的t-SNE可视化Fig.6 t-SNE visualization of audio features
4 结束语
提出了一种新的跨模态表示学习方法SCCMRL。相较于现有方法,SCCMRL在有监督学习的形式下,引入多负例对比机制。对于不同模态的特征表示,SCCMRL利用正例特征与多个负例特征之间的对比,确保了相同类别的数据样本在特征空间中的语义距离尽可能靠近,而不同类别的数据样本间的语义距离尽可能远离。除此之外,SCCMRL 还在标签空间引入了标签损失和中心损失联合来联合优化视觉编码器和音频编码器,保证了模型学习到的跨模态表示能够同时满足模态一致性和语义区分性。针对两种不同的视听数据集,进行了大量的对比实验,实验结果证明了本文提出的跨模态表示学习方法SCCMRL 要优于现有的相关模型,同时论证了多负例对比机制的引入对于模型性能的提升至关重要。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
技术与创新管理(2020年5期)2020-10-09
少儿画王(3-6岁)(2020年4期)2020-09-13
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
成长·读写月刊(2018年8期)2018-08-30
东方教育(2018年20期)2018-08-22
科学与财富(2017年28期)2017-10-14
电影新作(2014年1期)2014-02-27
