
融合协同知识图谱与优化图注意网络的推荐算法
2022-10-18 01:02唐宏,范森,唐帆
计算机工程与应用 2022年19期
唐 宏,范 森,唐 帆
1.重庆邮电大学 通信与信息工程学院,重庆 400065
2.重庆邮电大学 移动通信技术重庆市重点实验室,重庆 400065
随着网络时代的高速发展,用户面临着严重的“信息过载”问题,为了缓解此问题,推荐系统发挥着不可替代的作用。
在传统的推荐算法中,主要包含基于内容的推荐算法(content-based recommendations,CB)[1]、基于协同过滤的推荐算法(collaborative filtering,CF)[2]和混合推荐算法[3]。
然而传统推荐算法存在严重的数据稀疏及冷启动问题,导致推荐结果性能不佳,给用户带来不好的体验。因此,为了缓解以上两个问题,通过往推荐模型中添加相关的辅助信息可以取得较好的效果,其中常见的辅助信息主要包括用户/项目属性信息、社交网络、知识图谱、上下文信息等。其中知识图谱作为一种网络信息,将节点与节点进行连接构建成一个三元组KG=(h,r,t)形式,通过节点之间的连接关系可以很好的捕捉节点之间的潜在信息和关联信息。文献[4]使用多任务学习框架,将知识图谱与推荐系统使用交替学习的方式进行训练,构成了MKR模型,使得最终的推荐结果性能有一定提升。文献[5]的GraphRec模型,将用户-用户知识图谱与用户-项目知识图谱结合辅助整个模型,从而捕获用户-项目的交互和意见。文献[6]的DEKGCN 模型,通过增加对用户属性信息的考虑,可以更好地缓解数据稀疏问题。文献[7]的KG-BGAT 模型将知识图谱与双线性采集网络进行结合捕捉用户的高阶关系。
同时,为了捕获用户的高阶兴趣和输入数据更强的表征能力,将深度学习融入到推荐系统中也逐渐成为研究热点。使用效果最好的就是图卷积网络与推荐系统相结合的方式,再搭配注意力机制使用,能很好地捕捉用户-项目高阶线性关系和潜在兴趣。
文献[8]将协同知识图谱嵌入到推荐模型中构成NGCF 模型,该模型不仅缓解了数据稀疏问题,也更好地捕捉了用户的潜在兴趣;文献[9]提出了LightGCN模型,该模型在传统GCN的基础上,通过实验验证去除特征转换与非线性激活模块可以在不影响推荐性能的基础上极大地降低模型复杂度;文献[10]的KGCN 模型,将知识图谱作为嵌入到图卷积网络推荐模型中,从而给最终的推荐性能带来明显的提升;文献[11]的KGAT 模型,相比于KGCN模型,该模型添加了注意力机制模块,可以生成用户-项目自适应表征,提升了整体推荐效率以及性能。文献[12]的LGCA 模型,是在LightGCN 模型上加入一个注意力机制,通过对不同领域信息进行区分,从而提升推荐性能。文献[13]为了降低推荐模型复杂度,使用简单GCN模型,并取得了较好的效果。
因此,为了更好地缓解推荐系统的数据稀疏和冷启动问题,本文将协同知识图谱作为辅助信息嵌入到推荐模型中;与此同时,为了更好地捕捉用户的潜在兴趣以及用户-项目之间的高阶关系和降低模型复杂度,采用优化的图卷积网络可以适当解决这两个问题。本文的主要贡献如下:
(1)将用户-项目交互图与用户/项目知识图谱结合,构成协同知识图谱(CKG)进行嵌入,因此可以更好地挖掘节点之间的高阶关系和潜在兴趣,同时也能更好地缓解数据稀疏问题。
(2)为了降低模型复杂度和更好地获取用户-项目之间的高阶关系,采用优化的图卷积网络,去除特征转化和非线性激活模块,经过实验证明,该模块可以在不影响推荐性能的基础上极大地降低模型复杂度。
(3)使用基于偏差的三元组注意力机制,该机制可以及时捕获推荐项目与用户真实感兴趣项目之间的偏差,并且根据不同的偏差分配不同的关注度,来辅助模型更好建模和提升模型训练效率。
1 CKG-OGAT推荐算法模型
本文将用户-项目交互图与用户/项目知识图谱构建成协同知识图谱嵌入到推荐模型中,再结合优化的图卷积网络,加上基于偏差的三元组注意力机制,便成了本文的CKG-OGAT模型,如图1所示。
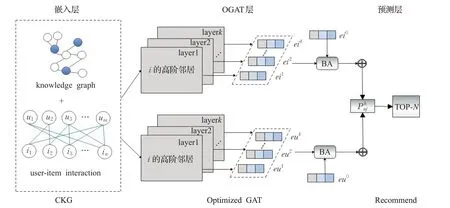
图1 CKG-OGAT模型框架Fig.1 KG-NAMR model framework
在CKG-OGAT 模型中,首先将用户-项目交互图与用户/项目知识图谱构建成协同知识图谱,嵌入到优化的含有基于偏差的三元组注意力机制的图卷积网络推荐模型中,最后在进行TOP-K推荐。
1.1 问题定义
在整个推荐模型中,将用户定义为U={u1,u2,…,um},将项目定义为I={i1,i2,…,im},将用户-项目交互矩阵定义为Y∈Rm×n,当用户与项目有交互(比如用户点击、用户购买、用户分享等),则Y=1;当用户与项目之间没有交互,Y=0,但是并不表示用户对该项目不感兴趣,只是用户与该项目之间没有交互关系而已。
另外,本文使用的协同知识图谱定义为CKG,它主要是以三元组的形式呈现,包含头实体、关系、尾实体,用CKG={h,r,t}表示。
本模型主要就是通过给定相关的用户-项目交互矩阵I与用户/项目知识图谱KG,通过推荐模型预测候选用户u对相关项目i兴趣程度并进行推荐的过程。
1.2 协同知识图谱嵌入层
为了更好地获取数据之间的信息和缓解数据稀疏问题,将用户-项目交互图与用户/项目知识图谱进行结合构建成协同知识图谱,具体结构如图2所示。
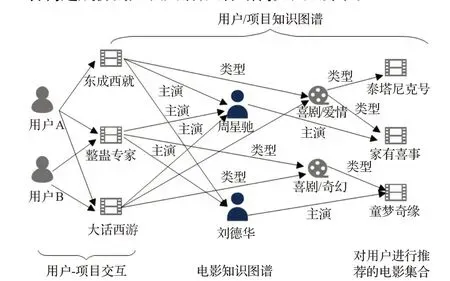
图2 电影领域协同知识图谱示例Fig.2 Example of collaborative knowledge graphs in film domain
由于CKG-OGAT算法使用的辅助信息是协同知识图谱,因此为了更好地处理协同知识图谱中的信息,使用TransD 嵌入方法,该方法可以很好地识别出协同知识图谱中三元组CKG={h,r,t}之间不同三元组中实体之间对应的不同属性关系或者类型。
比如在一个电影知识图谱三元组(你好李焕英,主演,贾玲)和三元组(你好李焕英,导演,贾玲)中,第一个三元组表示了贾玲是这部电影的主演,另一个三元组则表示了贾玲是这部电影的导演,通过使用TransD 嵌入方法就可以很好地捕捉不同知识图谱三元组之间的关系,它不仅考虑了知识图谱三元组中实体的多样性,还考虑了实体之间关系的多样性,因此对于整个推荐模型挖掘用户潜在兴趣和用户-项目之间的高阶关系具有很大的帮助。具体的结构图如图3所示。
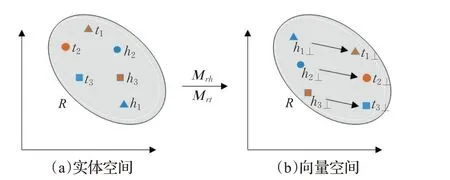
图3 TransD结构Fig.3 TransD structure
如图3所示,使用TransD对协同知识图谱进行嵌入处理,可以很好地识别CKG 中不同三元组中实体与实体之间的多层关系,并且通过两个映射矩阵Mrh、Mrt对原始协同知识图谱进行处理,具体的公式见式(1)和(2)所示:

式中,h⊥和t⊥表示的是CKG三元组中的头实体和尾实体经过TransD嵌入后在向量空间里面的表示,h和t表示CKG三元组中的头实体和尾实体。
同时,TransD 嵌入方法对应的评分函数便如式(4)所示:
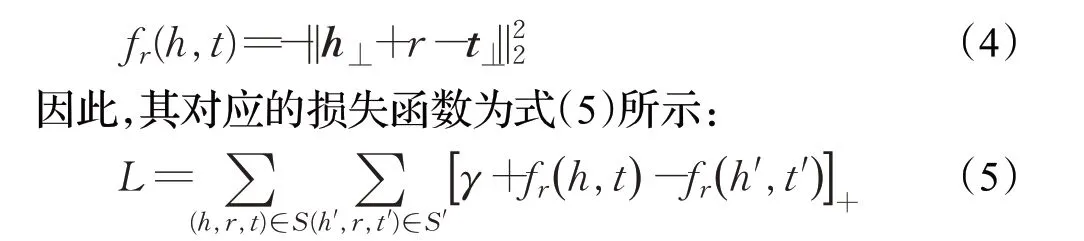
其中L表示的是损失函数,当损失函数趋近于0 时,整个知识图谱嵌入模块处理性能最优,γ是知识图谱中正实例与负实例之间的最小间隔,正实例表示的是与用户有过真实交互关系的实体,负实例表示的是一些没有历史交互记录的实例。
通过以上分析,使用TransD 对协同知识图谱进行处理,可以很好地捕捉CKG 不同三元组之间实体之间的潜在关系和用户-项目高阶关系,还能考虑到实体之间的多样性,整体模型复杂度也不高。
1.3 OGAT层
为了更好地处理嵌入的协同知识图谱,采用图卷积作为推荐模型的核心,同时借鉴LightGCN模型[8]的处理思想,在传统图卷积的基础上去除了特征转换以及非线性激活模块,因此可以在不影响整体推荐性能的基础上极大地降低模型复杂度。
传统的GCN主要是通过嵌入知识图谱上的特征来学习节点的表示[13-14],同时需要多次进行卷积操作,将嵌入数据的邻居信息进行聚合操作来作为目标节点的表示,具体见式(6)、(7)所示:

基于此,本文在传统图卷积的基础上进行优化的,去除了特征转换和非线性激活模块,因此本文的领域聚合公式如式(8)所示:

因此,本文使用的简单的AGG 加权聚合函数如下式所示,并去除了传统的图卷积操作的特征转换和非线性激活模块:


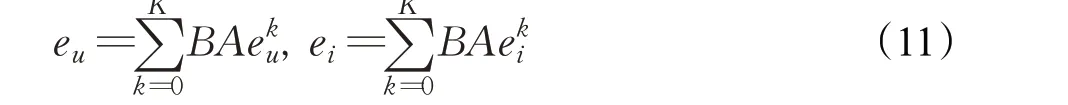
其中BA表示的是用户/项目的第k层嵌入的重要程度,也就是注意力机制,主要介绍在1.4节介绍。
1.4 基于偏差的注意力机制
本文使用基于偏差的注意力机制,该机制可以及时捕获候选项目与用户真实感兴趣的项目之间的偏差,并且根据这个偏差大小为不同候选项目分配不同大小的关注度,从而协助模型取得更好的推荐性能。
其中,基于偏差的注意力机制计算式如式(12)所示:

式中,BA(h,r,t)的得分越大,就表示预测项目与用户真实感兴趣的项目之间偏差越小,因此整个推荐模型就会对此类项目给予更高的关注,协助模型更好捕捉用户的高阶关系和潜在兴趣。
1.5 预测层
经过以上的分析,可以得出本文的预测结果,见式(14)所示:

2 实验与分析
为了验证本文算法的有效性,接下来就进行相关的实验分析。
2.1 数据集
本文选取了以下数据集,包括较新但数据量较小的Movielens-latest-small 数据集、用户数据量较大的Movielens-1M 数据集和项目数据量较大的Douban(豆瓣)数据集。
从表1可以看出,在这3个数据集中,Movielens-latest-samll数据集数据量最小,包含686位用户和9 878部电影,评分记录42 694 条,并且该数据集科研根据获取的links.csv文件去IMDB网站爬取更多相关电影的信息,包括电影主要、电影导演、电影类型、电影上映年份等。

表1 数据集基本统计Table 1 Basic statistics of datasets
豆瓣数据集相比于Movielens-latest-samll数据集来说,其数据量就较大,包含4 132 位用户、32 185 部电影和998 972个交互评分记录,在该数据集中,也是包含电影的属性信息,比如电影类型、电影导演、电影主演等。
最后就是Movielens-1M 数据集,该数据集相比于前两个数据集,它更新年代比较久远,包含6 040 位用户,3 952部电影和1 000 209个评分记录,并且它的数据稀疏度最低,同时它也是一个包含用户属性信息的,比如用户年龄、用户职业等。
以上3个数据集中,均保证了每个用户至少与20部电影有过交互记录,并且:数据密集度=评分数/(用户数×项目数),数据稀疏度=1-数据密集度[17]。
2.2 对比算法
使用最近较新及效果较好的算法,并且根据是否包含图卷积操作、知识图谱嵌入以及注意力机制3个方面考虑,因此选择以下几个算法作为对比算法:
NGCF 模型[8],该算法将完整的图卷积操作与基于协同过滤的算法进行结合,通过显式建模用户-项目之间的高阶关系从而提升整体的推荐性能。
LightGCN模型[9],该算法是在NGCF模型的基础山进行的改进,摒弃了完整的图卷积操作,去除了特征转换和非线性激活模块,从而在不影响推荐性能的基础上极大地降低推荐模型复杂度。
KGCN模型[10],该模型将知识图谱作为辅助信息嵌入到含有图卷积操作的推荐模型中,因此可以丰富数据集中的语义信息,更好挖掘用户的潜在兴趣和高阶关系。
KGAT 模型[11]不仅训练了项目嵌入,同时也对用户嵌入进行了训练,并且使用了KG 与图注意网络的思想,因此在整个模型训练时得到了更优的处理。
2.3 评价指标
本文选取了3种电影数据集进行算法验证,并且将数据集随机按照80%用于模型训练,20%用于模型测试,经过10 次实验取得平均值。所选取的评价指标主要是对用户进行TOP-K推荐领域比较常用的指标:包括准确率Precision、召回率Recall 和归一化累计折损增益NDCG[17]。其中R(u)表示的是给用户u进行TOP-K推荐的项目集合,T(u)表示的是用户u在交互记录中原本感兴趣的项目集合。
首先是准确率Precision指标,主要是指模型给用户进行推荐的项目中用户感兴趣的项目占给用户进行推荐的项目总和数的比例,见式(15)所示:
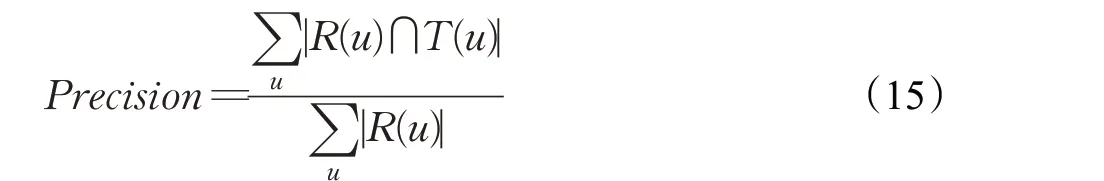
接着就是召回率Recall指标,该指标主要指最终给用户进行推荐的项目中用户感兴趣的项目数占用户历史交互项目总数的比例,见式(16)所示:
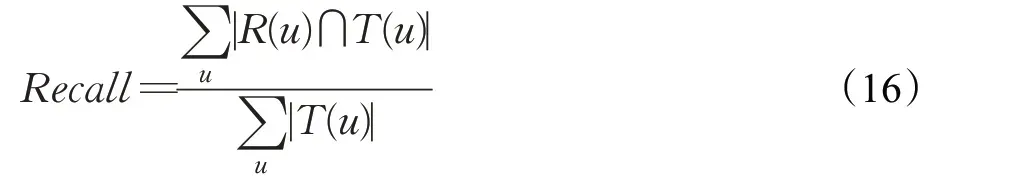
最后就是归一化累计折损增益NDCG,其主要是表示进行TOP-K推荐项目时对相关项目进行排序时准确性的一个评价指标,反映推荐结果是否与用户历史交互记录相关,具体见式(17)所示:
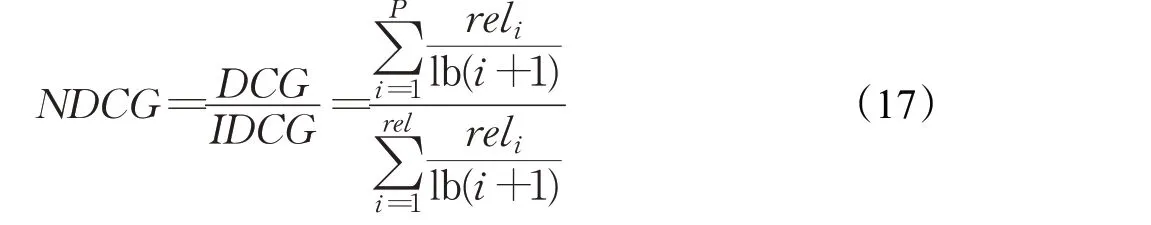
其中DCG 指的是折损累计增益,IDCG 则是对DCG 进行归一化处理后的结果,reli表示的用户真实交互过得项目与推荐系统进行推荐项目之间的相似度大小,取值为[0,1],主要是用来衡量TOP-K推荐排序的一个评价指标[18]。
2.4 参数设置
嵌入维度默认设置为16,默认学习率设置为0.001,批量大小默认设置为256,并且使用Adam 优化器对整个模型进行优化,TOP-K默认设置为15,将epoch 设置为300。
接着就是在基本参数设置时,所获得的不同算法的性能对比,见表2所示。
根据表2 可以看出,在默认参数设置下,本文算法CKG-OGAT取得了最优性能。并且根据数据集Douban(豆瓣)和数据集Movielens-1M 结果看出,虽然两者在数据稀疏度上存在5%差距,但是指标结果并没有存在很大差距,这也从侧面反映出了本文算法可以缓解数据稀疏问题。
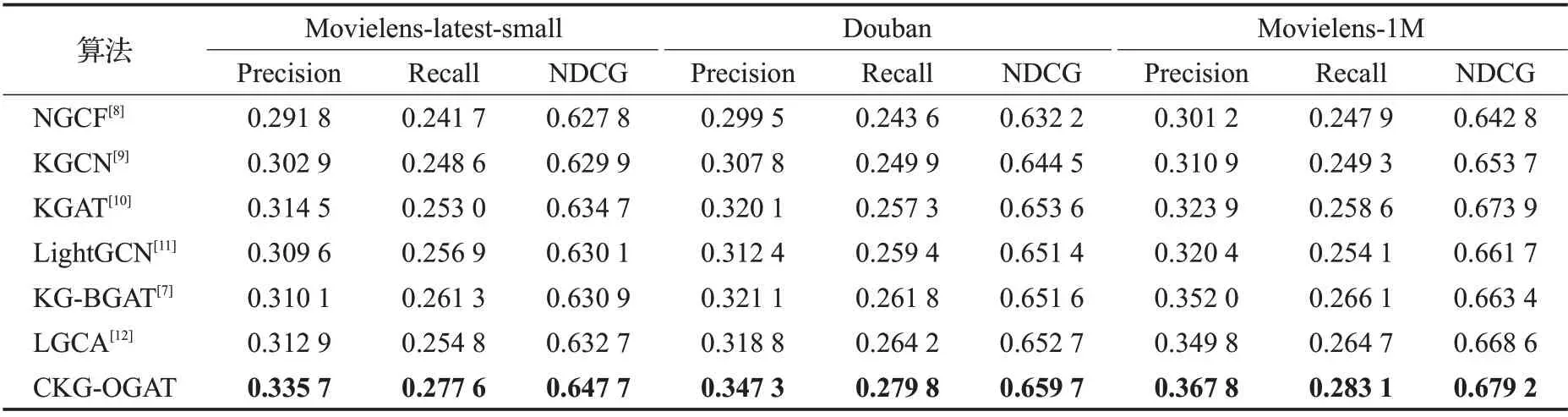
表2 不同算法的性能对比Table 2 Performance comparison of different algorithms
接着就是通过调整K找出不同算法在不同数据集基础上的准确率变化趋势,保证其他参数都是默认设置的情况,具体如图4所示。
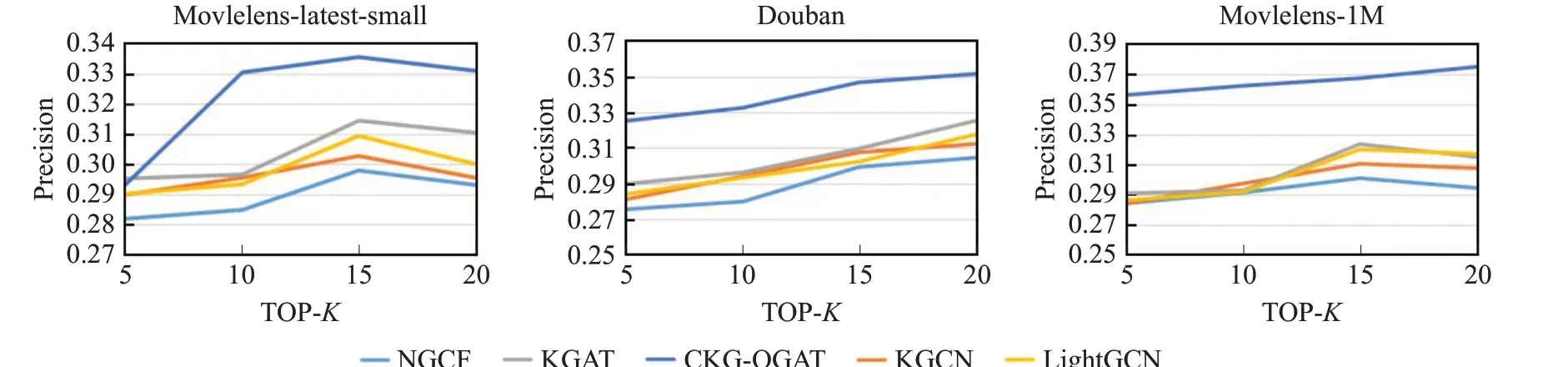
图4 不同算法在3个数据集上的性能对比Fig.4 Performance comparison of different algorithms on three datasets
根据以上3个图可以看出,本文所提CKG-OGAT算法在3个数据集上面都呈现了最优性能。
3 实验验证与分析
为了让CKG-OGAT算法在不同数据集上呈现最优性能,因此本章将针对不同数据集进行相关参数调优,以下参数调优都是在其他参数默认设置时进行调整验证的。
3.1 TOP-K调优
首先是对TOP-K的调整,以便找出不同数据集下K的最优选择,表3就是在3个数据集上进行K调整获取的结果:
表3可以看出,对于数据量较小的Movielens-latestsamll数据集来说,在K=15 时达到最优性能,而对于数据量相对更大的其他两个数据集,均在K=20 时取得了最优性能。

表3 不同数据集TOP-K参数调优结果Table 3 TOP-K parameter tuning results for different datasets
3.2 epoch参数调优
接着就是通过调整epoch,观察在不同数据集上面的性能变化,具体见图5所示。
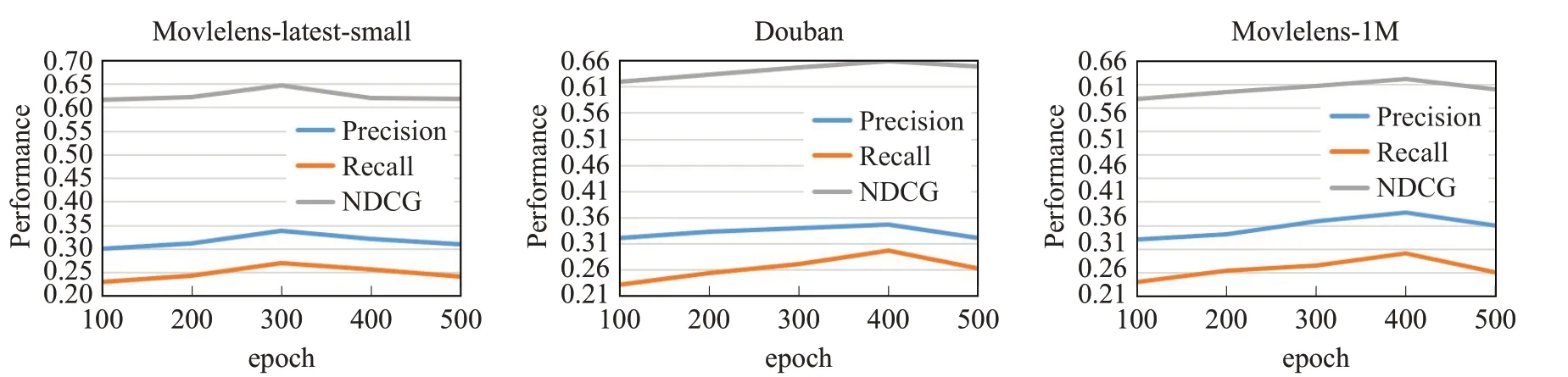
图5 本文算法在Movielens-latest-small数据集上的epoch参数调优Fig.5 Epoch parameter tuning of proposed algorithm on Movielens-latest-small dataset
如图5所示,Movielens-latest-small数据集在epoch=300时性能最优。在豆瓣(Douban)数据集上面,当epoch=400 时性能最优,这也不难解释,Douban(豆瓣)数据集相对于Movielens-latest-small 数据集来说,其数据量较大,并且电影数据较多,因此整个数据就更加具有多样性。在Movielens-1M数据集中,当epoch=400时性能最优,主要原因也是由于该数据集数据量较大。
3.3 嵌入维度调优
最后就是嵌入维度的调整,观察对不同数据集的影响,具体见表4~6所示。

表4 Movielens-latest-small数据集Table 4 Movielens-latest-small dataset
由表4 看出,在Movielens-latest-samll 数据集上,当嵌入维度为16时性能最优。
由表5 看出,对于Douban 数据集来说,当嵌入维度为32时推荐效果最优。
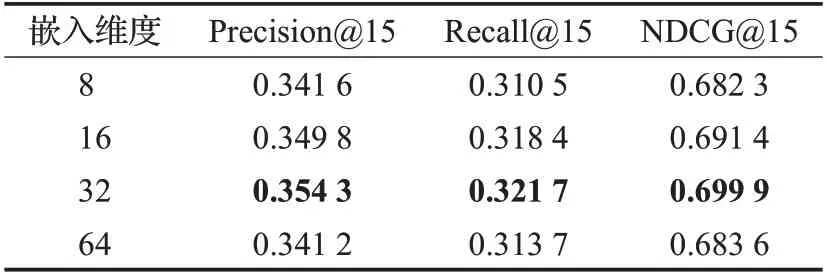
表5 Douban数据集Table 5 Douban dataset
由表6 看出,在Movielens-1M 数据集下,当嵌入维度为32时性能最优。
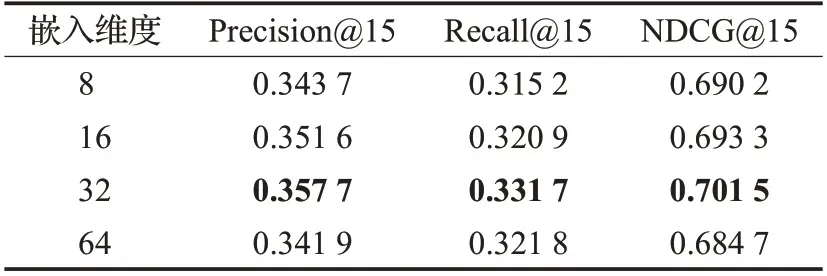
表6 Movielens-1M数据集Table 6 Movielens-1M dataset
3.4 参数调优整合
最后,根据调整TOP-K、epoch数和嵌入维度3个参数,可以分析出对于不同数据集在不同参数下的性能,如表7~9就是参数调优整合。

表7 Movielens-latest-small数据集参数调优整合Table 7 Movielens-latest-small dataset parameter tuning integration
根据表7可知,Movielens-latest-small数据集在TOPK为15、epoch数为300、嵌入维度为16时,在CKG-OGAT模型下性能最优;由表8 可知,Douban 数据集在TOP-K为20、epoch 数为400、嵌入维度为32 时,在CKG-OGAT模型下性能最优。

表8 Douban数据集参数调优整合Table 8 Douban dataset parameter tuning integration
由表9 可知,Movielens-1M 数据集在TOP-K为20、epoch 数为400、嵌入维度为32 时,在CKG-OGAT 模型下性能最优,并且当两个数据集都在最优参数时,所获取的准确率差距并不大,这也反映出CKG-OGAT 模型可以很好地缓解数据稀疏问题。

表9 Movielens-1M数据集参数调优整合Table 9 Movielens-1M dataset parameter tuning integration
4 有效性分析
为了验证本文所提算法的有效性,包含协同知识图谱的有效性、优化的图卷积网络的有效性、基于偏差的注意力机制地有效性,其中有效性分析都是在不同数据集参数最优情况下进行验证的。
4.1 协同知识图谱有效性分析
这里将移除协同知识图谱的算法叫作OGAT,具体的准确率指标见表10所示。
根据表10 可以看出,当推荐模型中含有协同知识图谱时,数据集Douban(豆瓣)和数据集Movielens-1M数据集的性能指标差距不是很大,但是当去除CKG 模块时,更加稀疏的Douban(豆瓣)数据集就比Movielens-1M 数据集在准确率上面低了2.48%;因此这也从侧面反映出CKG模块可以很好地缓解数据稀疏问题。
4.2 优化的图卷积网络有效性分析
这里将使用传统图卷积网络的算法叫做CKG-GAT,为了更加全面地分析优化图卷积网络的有效性,还与另外两个使用传统图卷积网络的推荐算法进行对比分析,具体如表11所示。

表11 优化的图卷积网络有效性分析Table 11 Effectiveness analysis of optimized graph convolutional network
由表11 可以看出,本文所提算法CKG-OGAT 使用的优化的图卷积网络,在整体推荐性能上面没有特别大的影响,但是通过出去特征转换和非线性激活模块,平均每个epoch的训练时间减少了一半,从而极大地降低整个模型的复杂度。
4.3 基于偏差的注意力机制有效性分析
这里将去除掉含有基于偏差的注意力机制模块的算法叫做CKG-OGCN,具体如表12所示。

表12 基于偏差的注意力机制有效性分析Table 12 Effectiveness analysis of bias-based attention mechanism
由表12 可以看出,去除掉基于偏差的注意力机制模块的算法在3个数据集上面性能都有一定的降低。
4.4 TransD有效性分析
为了验证本文模型使用的TransD 嵌入模块有效性,将本文模型中的知识图谱嵌入模块TransD 替换成TransR 模块所得的算法叫做CKG-OGAT′,具体如表13所示。

表13 TransD有效性分析Table 13 Effectiveness analysis of TransD
由表13 可见,本文模型所使用的TransD 嵌入模块相对于TransR模块,在3个数据集上面所获取的推荐性能均更优,因此这也能反映出本文模型使用的TransD模块的有效性。
5 结束语
针对推荐系统的数据稀疏和模型复杂度较高等问题,本文提出了融合协同知识图谱和优化的图注意网络推荐算法CKG-OGAT。
首先将用户-项目交互图与用户/项目知识图谱结合构建成协同知识图谱,嵌入到优化的图卷积网络中,通过去除特征转换及非线性激活模块,因此可以在不影响整体推荐性能的情况下极大地降低模型复杂度;最后再结合基于偏差的注意力机制,及时获取推荐项目与用户真实感兴趣项目之间的偏差,从而更高效地进行推荐。最后在3个数据集上验证分析,CKG-OGAT算法可以适当缓解数据稀疏问题,并且极大地降低模型复杂度。
由于本文对用户的动态兴趣没有考虑,因此下一步的计划就是结合动态推荐模型捕获用户的动态兴趣变化,同时在模型可扩展性方面进行更深入的研究。
猜你喜欢
社会科学战线(2022年9期)2022-10-25
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
计算机仿真(2022年7期)2022-08-22
新班主任(2022年4期)2022-04-27
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
新城乡(2018年6期)2018-07-09
领导决策信息(2018年7期)2018-05-22
