
一种改进的图域频谱感知算法*
2022-09-28 07:25:46赵敦博胡国兵赵嫔姣
电讯技术 2022年9期
赵敦博,胡国兵,杨 莉,赵嫔姣
(1.南京邮电大学 电子与光学工程学院、柔性电子(未来技术)学院,南京 210023;2.金陵科技学院 电子信息工程学院,南京 211169)
0 引 言
认知无线电(Cognitive Radio,CR)作为一种动态机会频谱接入机制,为提高频谱资源利用效率提供了更加有效的解决途径[1-2]。对于CR系统而言,频谱感知是其有效工作的前提与基础,其任务就是检验主用户信道是否被占用,本质上讲就是信号检测[1]。
目前,常用的频谱感知算法大致可分为基于非机器学习的频谱感知算法[1](如能量检测法、匹配滤波法、循环平稳特征法等)和基于机器学习的频谱感知算法(如反向传播神经网络法等)。前者通常从信号的时域、频域、变换域等角度提取特征[1],后者虽可获取较好的检测性能,但需要大量的训练样本,导致其在非协作条件下应用受限。通常,提高特征的可分性是提升其性能的关键因素,但这往往需要增加观测样本量,势必增加算法的复杂度。因此,为了提高算法的效能,对新的信号表征及特征定义方法的研究已成为该领域的热点课题[3-4]。
近年发展起来的图域信号处理方法[3-6]为解决这个问题提供了新的思路,其基本思想是将信号样本(时域或频域形式)变换成特定的图并进行检测,图的顶点和边由变换前信号域中采样点的关系和映射规则决定。目前,有关图域信号处理在频谱感知或信号检测中应用的文献较少,主要是基于完全图特征来实现信号检测,但由于在进行图域变换时需将具有大量采样点的信号集合转换成图的拓扑结构来进行处理,且在特征提取时需要进行矩阵的特征分解,也增加了信号处理的复杂度。
针对复杂度增加的问题,本文引入极值理论,提出了一种改进的基于功率谱分组极差图域处理的认知无线电频谱感知算法。仿真结果表明,本文算法的计算复杂度相较于已有的基于特征值检验的图域频谱感知算法有较大幅度的下降,且其在低信噪比下性能更佳。
1 信号模型与背景知识
1.1 信号模型
假设被加性高斯白噪声(Additive White Gaussian Noise,AWGN)污染后的离散观测信号r(n)可表示为
r(n)=s(n)+ω(n),n=0,1,…,N-1。
(1)
信号分量
(2)
式中:NC为码元个数;ξ(ζ)代表第ζ个信息符号样本值;g(n)为成形脉冲,此处假定为脉宽为T0的矩形脉冲;ω(n)是实加性高斯白噪声,其均值为0、方差为σ2。
可将频谱感知问题归结为如下假设检验[4]:
(3)
1.2 信号的图域变换
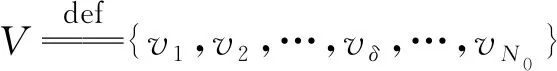
(1)归一化
由式(4)可将离散序列归一化到[0,1]区间:
(4)

(2)量化及顶点映射
量化级数设为N0,经均匀量化后序列可表示为
(5)
式中:μ=0,1,…,N0-1。将图的顶点v与量化区间[0,1]的特定子区间(量化级)之间按如下规则进行映射:
(6)
(3)边定义
图的边由量化后序列Q(τ)的幅度变化决定,对于τ=0,1,…,T-h-1,其中步长h满足1≤h≤T-1,如果存在至少一次Q(τ)=δ且Q(τ+h)=β,则认为相应的边eδβ是连通的,否则就认为这两个顶点(vδ和vβ)不连通。通过遍历所有的样本可以得到相应边集为
2 改进的图域频谱感知算法
2.1 现有图域检测算法的问题
一般而言,独立同分布的随机序列,在适当选择顶点数且具有一定规模的样本量时,可以较大概率变换成完全图;而独立非同分布的随机序列,尤其是稀疏信号,一般不易构成完全图[3]。现有的图域频谱感知算法主要基于检测图的完全连接性,其检测的依据主要是基于在零假设下图拉普拉斯矩阵的次大特征值等于顶点数这一结论[4]。但在实际计算中,该方法存在一定的复杂度,主要体现在两个方面。
(1)图域变换环节:由于在将随机序列转换成图的过程中,需要对每一个样本进行归一化、量化及图转换,因此参与图域变换的样本数越多,其运算复杂度越高。
(2)特征提取环节:由于计算图的拉普拉斯矩阵特征值需要进行特征分解,其计算复杂度为图顶点数的三次方阶[6],即O(N03)。可见,即便顶点在10左右,其复杂度也较大。
针对上述问题,本文提出一种改进算法,一方面从观测信号的功率谱中提取分组极差序列,并将其作为图域变换的输入,减少了参与图域变换的样本数;另一方面,选择以图的Gini系数作为判定图完全连接性的特征,避免了对高维矩阵的特征分解,进一步减少了算法的计算量。
2.2 分组极差序列图域特性分析
设观测信号rϑ(n)的功率谱为Rϑ(k),有
(7)
式中:0≤k≤N-1;ϑ=0,1,ϑ=0代表H0情形,ϑ=1代表H1情形;N是观测信号样本数。
由文献[3]知,图的完全连接性与图域变换的输入信号样本的概率分布及样本量有关,当样本量一定时,其分布越接近于均匀分布,则其随机性越大,相应地转换成完全图的概率也就越大。易知,在H0情况下,观测信号的功率谱服从自由度为2的中心卡方分布,属于Ⅰ型分布(Gumbel分布)的极大值吸引场[7],故其分组极大值(Block Maxima,BM)序列渐进服从Gumbel分布。由文献[8]可知,在相同样本量条件及相同数据尺度下,独立同分布Gumbel随机变量的随机性大于独立同分布的中心卡方随机变量。也就是说,相对于未分组的功率谱样本R0(k),当分组数适当时,分组极大值序列转换成完全图的概率更大。

Zϑ(l)=ZMϑ(l)-Zmϑ(l) 。
(8)
式中:ϑ=0,1;l=0,1,…,L-1;ZMϑ(l)为每组的极大值组成的序列;Zmϑ(l)为每组的极小值组成的序列;显然,Zϑ(l)也可看成分组极大值序列与分组极小值序列取负值的和。由文献[9]知,分组极差序列Z0(l)是两个连续独立同分布随机序列的和,其概率密度的随机性大于其中任意一个随机变量。因此,当分组长度适当时,分组极差序列Z0(l)概率密度的随机性大于分组极大值序列ZMϑ(l),也就自然大于未分组的功率谱R0(k)。因此,在分组数适当时,H0假设下分组极差序列Z0(l)成为完全图的概率大于未分组的功率谱R0(k)。
由文献[10-11]知,若对于服从某一特定连续型分布的随机信号,经均匀量化后的样本的概率分布是对原连续型概率密度函数的理想采样。也就是说,量化前后的随机量的概率密度函数具有近似相同的随机性。实际中可以用量化后各顶点的直方图(或称顶点的概率向量随机性)作为比较特定样本集构成完全图的概率大小[3]。
假定Gp(Vp,Ep)和图Gq(Vq,Eq)分别为由本文提出的分组极差序列和直接由未分组的功率谱[4]生成的图,Vp和Vq分别为相应图的顶点集,表示为
Vp={vp1,vp2,…,vpδ,…,vpN0},
(9)
Vq={vq1,vq2,…,vqδ,…,vqN0} 。
(10)
定义1 顶点概率向量
令
(11)
(12)
分别为顶点集Vp和Vq的概率向量,其中:
(13)
(14)
式中:i,j=1,2,…,N0,Ii(Gp)和Ij(Gq)分别表示图Gp的第i个量化级(即第i个顶点)的总量化样本数和图Gq的第j个量化级(即第j个顶点)的总量化样本数,L和N分别是图Gp和Gq的输入样本数。
图1所示为H0情形下未分组的功率谱和分组极差序列顶点概率分布直方图。仿真中,H0假设为零均值实高斯白噪声,H1假设为叠加了高斯白噪声的二进制相移键控(Binary Phase Shift Keying,BPSK)调制信号,码元速率RB=2 000 baud,载波频率fc=4 000 Hz,过采样因子Q=50,样本点数N=300点,量化级N0=10,分组长度λ=7,信噪比为0 dB。H0情形时,由图可见,分组极差序列顶点概率向量的分布比未分组的功率谱均匀。图2~4的仿真条件与此相同。
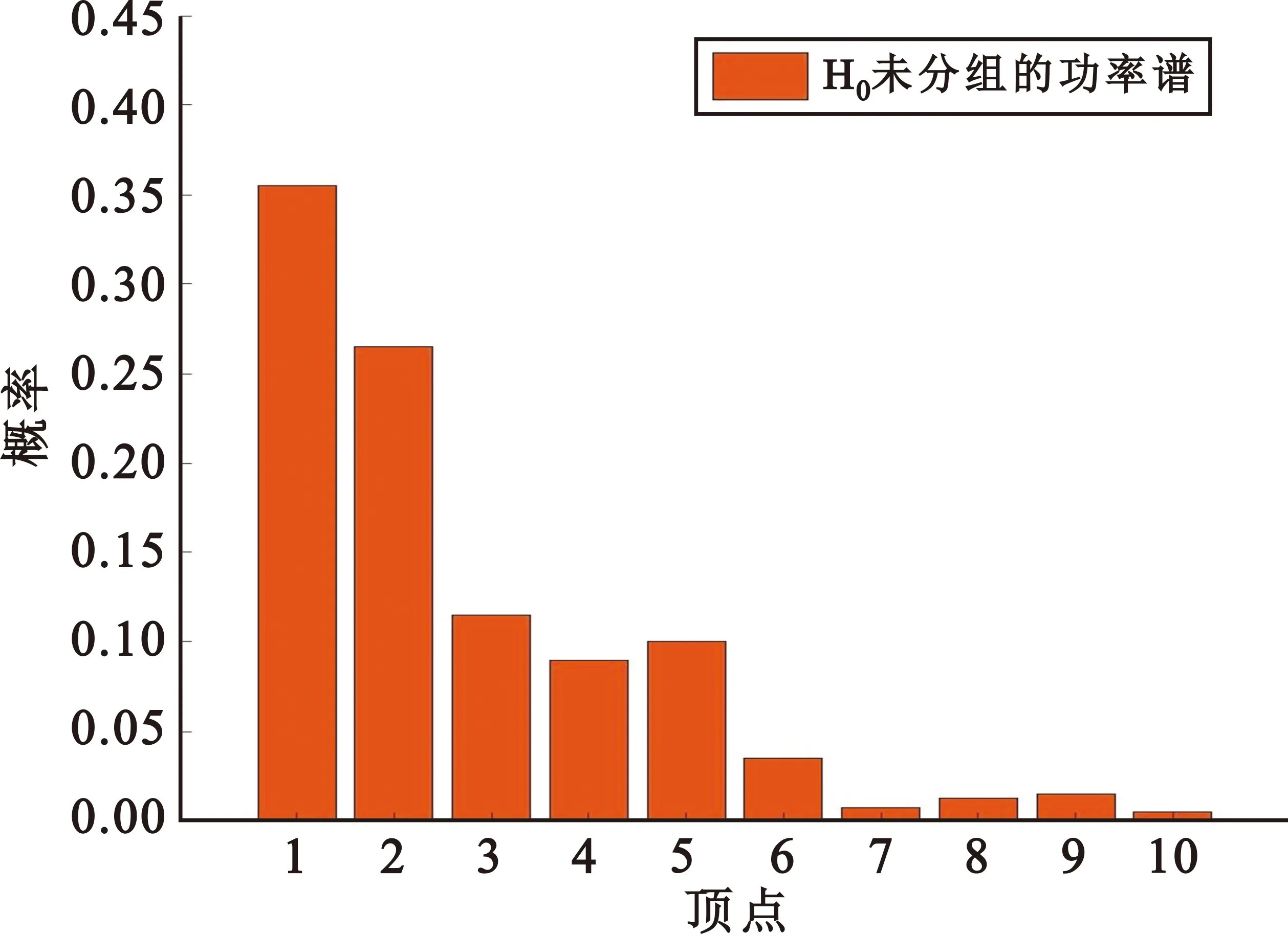
(a)未分组的功率谱
图2(a)所示为H0情形下分别采用未分组的功率谱(300个样本点)及分组极差序列(分组长度为7,实际样本数为43点)变换得到的无向简单图,可见分组极差序列仅需43个样本即可构成完全图,所需要样本数远少于未分组功率谱的情形。图2(b)所示为H0情形下未分组的功率谱在采用与分组极差序列相同的实际样本点数(43点)时变换得到的无向简单图,可见其无法构成完全图。图2印证了上文所述结论。

(a)未分组的功率谱(300点)与分组极差(43点)
必须注意到,如果某一统计量在两种不同假设下,其样本分布的随机性差异越大,则在由其转换成图后,两图之间的完全连接性差别也越大,或者说H0时越容易转换成完全图,而H1时越不容易转换成完全图,这样越有利于检测。前面已经分析,在H0时,分组极差序列的随机性更大。下面对H1时两种不同统计量的随机性进行分析与比较。
H1情形下,由于其功率谱不满足独立同分布的条件,两种不同统计量都很难变换成完全图。如图3所示,H1情形下两种统计量经均匀量化后得到的顶点概率向量都形如delta函数,根据完全图的判决规则,在样本数量有限时,这种分布很难转换为完全图[3]。
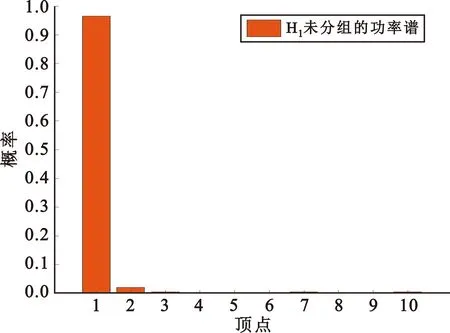
(a)未分组的功率谱
由于H1时未分组的功率谱R1(k)和分组极差序列Z1(l)不是独立同分布的随机变量,它们的概率密度函数难以解析表达,因此很难用解析的方法比较两种不同情形的随机性差异。因此,我们借助于顶点概率向量的部分和来进一步进行说明。
定义2 顶点概率向量的部分和
令
(15)
(16)
分别为顶点概率向量p和q的前Ω项的部分和,其中p[i]和q[j]为经过降序排列后的顶点概率向量元素,1≤i,j≤Ω≤N0。
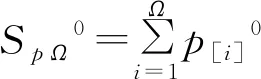
p0q0。
(17)
上式称为p0受控于q0,即顶点概率向量p0的随机性大于q0。
图4为两种不同假设下未分组功率谱与分组极差序列对应的顶点概率向量部分和曲线对比示意图。由图4(a)可见,H0时,p0的部分和一直小于q0的部分和。这说明本文提出的分组极差序列的随机性大于未分组的功率谱,其生成完全图的概率更大。由图4(b)可见,H1时p1和q1的部分和曲线相互交叠,均在[0.93,1]之间变化。这说明H1时未分组的功率谱与分组极差序列的随机性差异较小,其构成完全图的概率差距不大,均很难构成完全图。
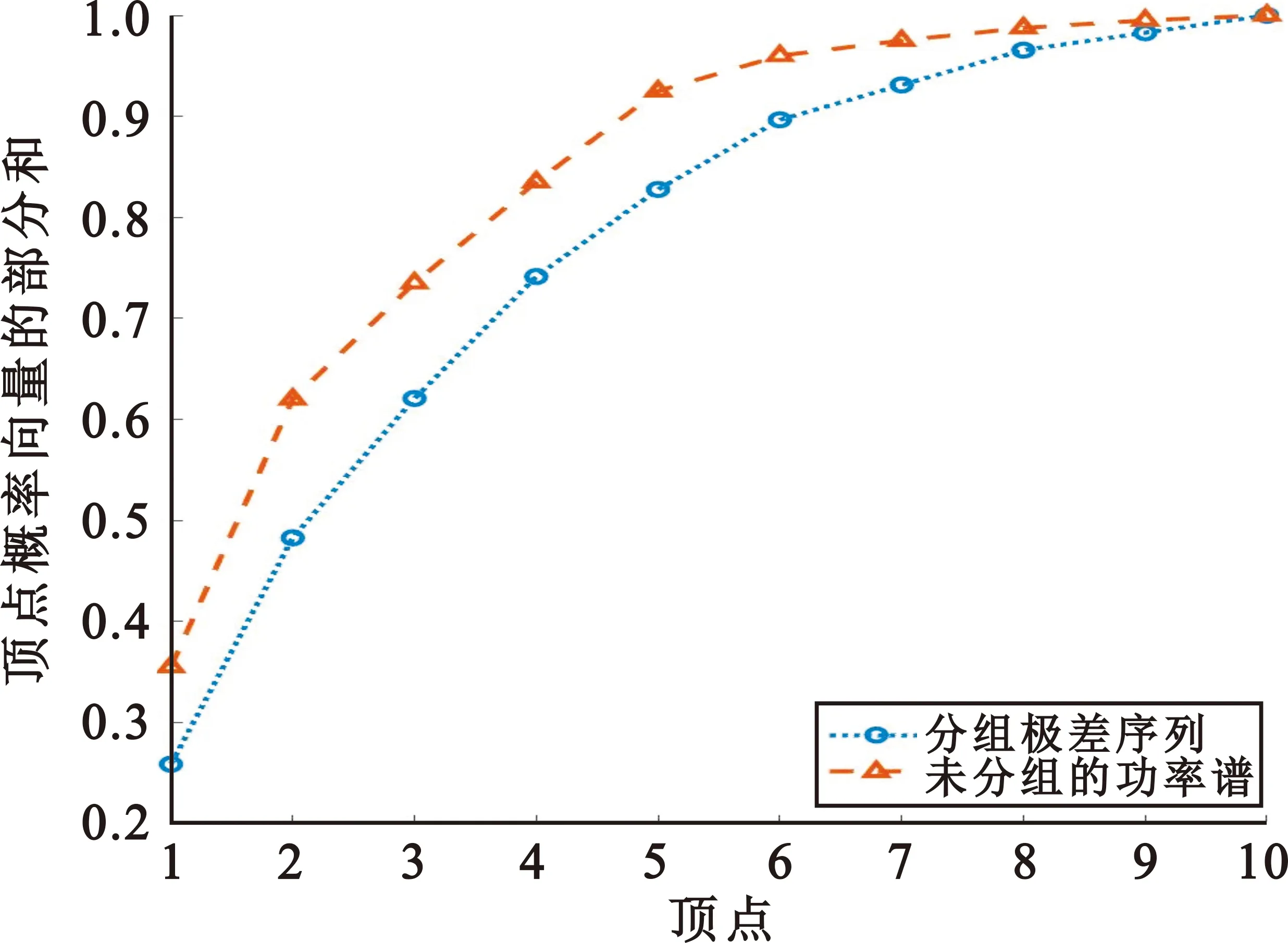
(a)H0情形下对比
定义3 顶点概率向量部分和距离
令两种不同统计量在两种不同假设下顶点概率向量部分和的距离分别为Cp和Cq:
(18)
(19)
从某种程度上,顶点概率向量部分和的距离可以用来表征两种样本间的随机性的差异,从而有助于判断其转成所得到的图的完全连接性的差异。图5是不同信噪比时顶点概率向量部分和距离Cp和Cq的对比图,除了信噪比变动外,图5的仿真条件与图4相同。从图中可以看出本文提出的分组极差序列在H0和H1时顶点概率向量部分和距离较未分组的功率谱更大,表明H0和H1时分组极差序列生成的图顶点分布的均匀性差距更大,更有利于信号检测。
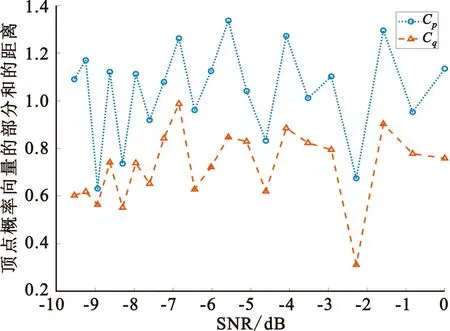
图5 不同信噪比时Cp和Cq对比图
2.3 特征定义:Gini系数
定义4 图的Gini系数[13]
对于具有N0个顶点的图G(V,E),其Gini系数定义为
(20)
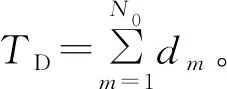
若将分组极差序列变换为图,根据定义4可知,理想条件下,在H0假设下图的Gini系数C0=0,在H1假设下图的Gini系数C1>0。
图6是不同信噪比时H0和H1情形下的Gini系数对比示意图,图中每种信噪比下的Gini系数是通过1 000次仿真求均值得到。除了信噪比为-11~-2 dB(步长为1 dB)、样本点数为100点和700点外,其他仿真条件与图4相同。由图可见,当样本数量一定时,H0与H1下Gini系数存在差异;H1假设下Gini系数随着信噪比增大而增大;当信噪比一定时,样本点数越大,H0下Gini系数越趋于0,样本点数小时,H0下Gini系数略偏移0;小信噪比时,样本数越大,H0和H1下Gini系数差异也越大;随着信噪比的增大,样本点数对Gini系数差异的影响减小。

图6 不同信噪比H0和H1情形下Gini系数对比示意图
根据上述结论,定义图的Gini系数作为统计量,可有效检测图的完全连接性以实现频谱检测。判决规则:若C<η,则接受H0;否则,拒绝H0。其中η为判决门限,其取值范围一般为0~0.5,具体应综合考虑选定的虚警概率及信号样本长度等因素进行选取。
2.4 算法流程
Step1 功率谱计算:对过采样后的观测信号r(n)进行快速傅里叶变换,并进一步计算得到功率谱R(k)。
Step3 图域变换:将极差序列Z(l)转化为具有N0个顶点的图Gp。
Step4 Gini系数计算:计算反映图的各顶点度数分布均匀度的Gini系数C,以此为判决指标,并设置相应的门限η。
Step5 比较判决:通过将Gini系数C与门限η进行比较,若C<η,则判为H0,否则判为H1。
3 仿真与分析
3.1 仿真设置
除非另有说明,仿真条件设为:待观测的信号为叠加了高斯白噪声的BPSK调制信号,码元速率RB=2 000 baud,载波频率fc=4 000 Hz,过采样因子Q=50,样本点数N=300点,量化级N0=10,分组长度λ=7,门限η=0.35;仿真中所定义的信噪比为全频段信噪比,为-3 dB;每种条件下的仿真次数为1 000次。仿真中使用两种指标来衡量算法的统计性能,即检测概率(Pd)和接收机工作曲线(Receiver Operating Characteristic Curve,ROC)。检测概率用于考察本文提出的检测算法在不同条件下的检测性能,而ROC用于比较本文算法与其他文献算法的性能。
3.2 不同信噪比下的检测概率
图7为不同信噪比条件下本文算法的检测概率示意图。仿真中,SNR为-11~0 dB(步长为1 dB)。由图可见,随着信噪比的增大,本文算法的检测概率也随之提高,在信噪比为-5 dB时检测概率接近90%。其原因在于,由图6可知,样本点数一定时,随着信噪比的增大,H0和H1时的Gini系数距离在增加,更利于判决图的完全连接性,从而提高检测性能。

图7 不同信噪比时本文算法的检测概率示意图
3.3 不同分组长度时的检测概率
图8为不同分组长度下本文算法的检测概率示意图。仿真中,分组长度λ为3~9(步长为2)。由图可见,当分组长度较大(如λ=9)时,分组极差序列的样本数变少,H0下进行Gumbel拟合时,拟合参数的方差变大,拟合优度下降,无法保证其相对于不分组情形时的均匀性增益,变换成完全图的概率下降,从而导致检测概率下降;当分组长度较小(如λ=3)时,分组极差序列的样本数虽多,H0情形时,其样本序列难以满足Gumbel渐进分布的条件,进行Gumbel拟合的优度变差,同样难以保证均匀性,从而使检测概率下降。因此,分组长度不宜过大,也不宜过小,具体选择要根据实际可获得观测信号样本数来定,样本数多时,可适当增加分组长度。

图8 不同分组长度时本文算法的检测概率示意图
3.4 不同量化级数时的检测概率
图9为不同量化级数时本文算法的检测概率示意图。仿真中,量化级N0为6~14(步长为2)。由图可见,随着量化级数的增加,检测概率先上升后下降。其原因在于,样本点数一定时,过少的量化级数会让H0和H1情况下变换为完全图的概率都增大,当H1情况下也有很大的概率变换为完全图时,H0和H1时Gini系数差值变小,就难以区分是否检测到信号;同样,过多的量化级会使H0和H1情况下变换为完全图的概率都减小,当H0情况下变换为完全图的概率也变小时,H0和H1情况下Gini系数差值变小,导致信号检测的性能下降。

图9 不同量化级数时本文算法的检测概率示意图
3.5 不同调制方式时的检测概率
图10为不同调制方式下本文算法的检测概率示意图。仿真中,SNR为-8~3 dB(步长为1 dB),调制方式采用BPSK、正交相移键控(Quadrature Phase Shift Keying,QPSK)和16进制正交振幅调制(Quadrature Amplitude Modulation,QAM)。由图可见,在相同的传码率下,调制方式对检测概率几乎没有影响。其原因在于,传码率相同时,三种调制方式信号的功率谱的形状和带宽基本相同,其随机性也基本相同,从而导致构成完全图的概率也基本相同。
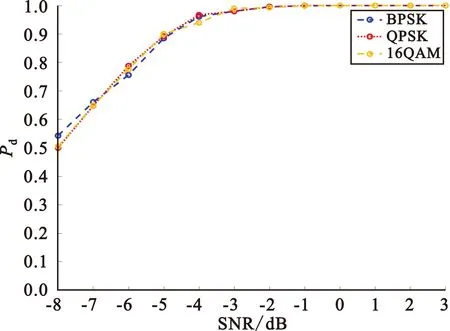
图10 不同调制方式时本文算法检测概率示意图
3.6 不同成形脉冲时的检测概率
图11为在不同的成形脉冲下本文算法的检测概率示意图。仿真中,SNR为-11~0 dB(步长为1 dB),成形脉冲分别采用滚降系数α=1、α=0.6和α=0.3的平方根升余弦成形脉冲以及矩形成形脉冲。由图可见,不同的成形脉冲对检测概率影响较小。其原因在于,平方根升余弦成形脉冲和矩形脉冲功率谱的主瓣宽度和峰值高度基本相同,故其转换到图域时构成完全图的概率也基本相同,因此检测概率差别较小。

图11 不同成形脉冲时本文算法检测概率示意图
3.7 性能对比
图12为相同条件下分别采用本文算法、不分组图域检测法(简称不分组方法)[4]、能量检测法[14]和正态性检测法[15]四种算法进行频谱感知得到的ROC对比示意图。仿真中,SNR为-7 dB和-9 dB,样本点数N=700,量化级N0=20,分组长度λ=9。由图可见,无论是信噪比为-7 dB还是-9 dB,本文算法性能都优于其他三种算法,在-9 dB时能量检测法和正态性检测法已基本失效。

图12 四种频谱感知算法的ROC对比示意图
表1给出了相同条件下四种算法运行时间的对比结果,仿真条件与图10相同。仿真中所用的硬件平台是处理器为AMD Ryzen 7 PRO 4750U(1.7 GHz)的ThinkPad,软件平台为Matlab R2021a。由表可见,在相同条件下,本文算法的运算时间大约是不分组方法的5.6%,能量检测法的5倍,正态性检测法的10倍。虽然本文算法运算时间长于能量检测法和正态性检测法,但在低信噪比时性能更佳。

表1 四种频谱感知算法仿真时间对比
4 结束语
本文提出了一种改进的基于分组极差图的频谱感知算法,通过提取观测信号功率谱的分组极差序列作为图域转换的输入,并定义图的Gini系数来表征完全图特性,从而达到检测信道中是否存在信号的目的。仿真结果表明,该算法的计算复杂度适中,且在低信噪比时性能优于现有算法,具有较好的鲁棒性,便于工程实现。后续将进一步研究基于非均匀图域变换的频谱感知算法。
猜你喜欢
中等数学(2021年9期)2021-11-22 08:06:58
北京航空航天大学学报(2019年9期)2019-10-26 02:30:12
中学数学研究(江西)(2019年5期)2019-06-11 12:47:28
山东科学(2018年6期)2018-12-20 11:08:58
电子测试(2018年11期)2018-06-26 05:56:02
雷达学报(2017年3期)2018-01-19 02:01:27
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
西南石油大学学报(自然科学版)(2015年5期)2015-04-16 05:12:24
中学数学杂志(初中版)(2014年1期)2014-02-28 21:05:24
统计与决策(2012年9期)2012-07-25 08:13:30
