
利用ERB尺度划分对补偿相位谱语音增强算法的改进*
2022-05-10 07:27许清臣张再跃
计算机与数字工程 2022年4期
许清臣 韦 怡 张再跃
(1.江苏科技大学 镇江 212003)(2.中国石油化工股份有限公司金陵分公司 南京 210033)
1 引言
语音增强是语音信号处理中的一项重要技术,其广泛应用于语音识别、语音编码等领域[1]。由于人类生活的环境中存在着各种各样的噪声,使得语音通信系统性能严重恶化,导致信息传输不准确[2]。从而,在过去的几十年中,人们为此提出了许多语音增强算法,其增强的目的在于提高语音质量,减轻听力疲劳,从一定程度上来说,语音增强就是为了减少或者抑制背景噪声[3]。本文主要研究的是单通道语音增强,即只使用一个麦克风录制语音信号,并在多频带谱减法的基础上对其进行改进得到提出的语音增强算法。
Boll于1979年最早提出了一种较为有效的语音增强算法,称为谱减法[4]。随着心理声学应用的发展,近些年Upadhyay和Karmakar提出了一种基于Bark尺度听觉感知的多频带语音增强算法[5]。实验结果表明,基于听觉感知的多频带谱减法对于语音质量会有较好的改善。本文把一种最新的心理声学模型应用于语音增强的补偿相位谱中。
另外,在之前谱减法的语音合成过程中,有新的研究表明,相位谱对人耳的感知是有一定影响的[6]。文献[7~8]中给出了基于相位谱补偿的语音增强算法,该算法在语音合成过程中,是将带噪语音幅度谱与改进的相位谱相结合来生成修正后的语音复频谱,其保持了带噪语音的幅度谱,改变了相位谱,虽然捕捉了语音的细节,但是带噪语音幅度谱会影响到语音的整体结构。因此,本文对补偿相位谱进行了改进,将应用ERB尺度划分临界频带进行多频带谱减后的语音幅度谱来得到修正后的相位谱补偿函数,以此获得增强的语音复频谱。除此之外,其它文献[9]中提出了一种基于短时傅立叶变换的相位重建算法。
近年来,更加符合人耳听觉特性的ERB尺度频带划分方式逐渐取代了用Bark尺度划分临界频带[10],相较于Bark尺度其在低频段处可以获得更窄的听觉滤波器。本文提出了一种改进的基于听觉感知的语音增强算法,其利用ERB尺度来划分临界频带,并对传统的补偿相位谱进行了修正,将ERB尺度应用于补偿相位谱中。提出的该算法基于与人类感知密切相关的特征,在语音失真和噪声抑制之间寻求最佳平衡。实验结果表明,该算法在客观评价和主观评价两方面都取得了较好的效果。
2 多频带谱减法的基本原理
本小节主要介绍多频带谱减法的基本原理,Singh和Kamath提出的多频带谱减法是基于噪声频谱对整个语音频谱的影响是不同的这一事实,将整个语音频谱分为M个互不重叠的频带[11~12],然后在各个单独的频带上进行各自谱减。
假设语音信号为s(t)会受到周围加性环境噪声d(t)的污染,生成带噪语音信号x(t):
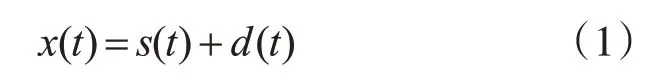
语音信号为非平稳信号,在进行语音信号处理时要对其先进行预处理,分帧加窗后两边做短时傅里叶变换(STFT),则上式可以转换为频域的形式:


其中,ωb和ωe是每个子带中的起始频点和终止频点,αi和δi是各个频带中的谱减参数,分别为过减因子和谱下限参数,用于语音频谱相减的程度控制噪声的去除强度。是带噪语音功率谱,是估计的噪声功率谱。最终合成的增强语音信号由下式可得:
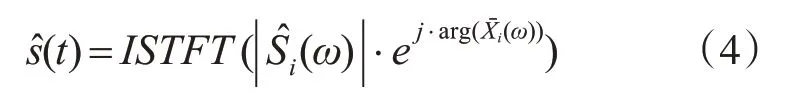
其中,ISTFT代表逆短时傅里叶变换, ||S^i(ω)是谱减后的幅度谱,带噪语音相位谱用arg(Xˉi(ω))表示。
3 提出的相位补偿方法
本文所提出的单通道语音增强算法是基于ERB尺度进行补偿相位谱修正,对经过初次增强后的语音信号进行噪声估计用于相位谱补偿函数中。本文所提算法的流程图如图1所示。
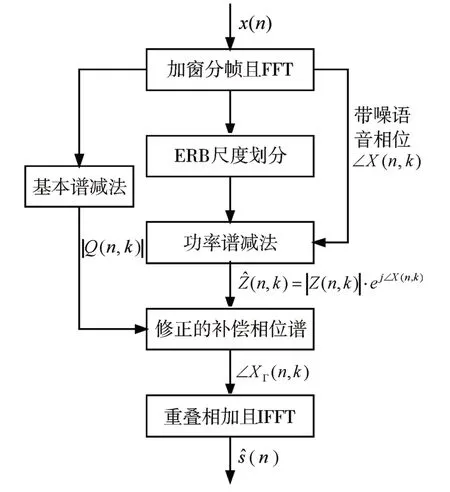
图1 提出算法的流程框图
在图1中,x(n)是待处理的带噪语音信号,s^(n)是由所提出的改进算法输出的增强语音信号。∠X(n,k)为带噪语音相位,|Q(n,k)|表示经过基本谱减法的语音幅度谱,Z^(n,k)表示使用ERB尺度进行多带谱减法后结合带噪语音相位谱构成的语音复频谱,而∠XΓ(n,k)是经过修正的补偿相位谱。该算法主要包括以下步骤:
1)语音预处理;2)使用ERB尺度划分临界频带;3)获得初次增强的语音复频谱;4)修正补偿相位谱;5)通过将多频带谱减后的语音幅度谱与修正的补偿相位谱相结合进行逆傅立叶变换。
接下来,将对步骤中的第二步和第四步进行详细描述。
3.1 ERB尺度划分临界频带
Upadhyay和Karmakar在多频带谱减法中使用Bark尺度对语音进行增强[5],但现在有足够的研究表明Bark尺度划分的临界带宽高于人类听觉掩蔽的实际临界带宽。因此,本文将ERB尺度应用于临界频带的划分[10]。式(5)和(6)给出了ERB尺度和线性频率之间的转换关系。
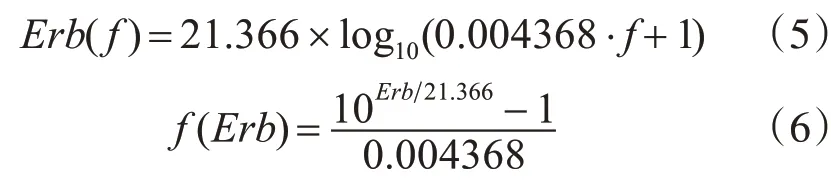
式中,Erb和f分别是ERB尺度值和线性频率值。
采用ERB尺度划分临界频带的步骤如下:先将线性频率根据式(5)转换到ERB尺度,再根据子带数量M把ERB尺度划分成M等份,最终再从ERB尺度转换回线性频率,这就是一个完整的ERB尺度划分临界频带的过程。接下来将把ERB尺度应用于补偿相位谱的修正中。
3.2 修正补偿相位谱
在以往传统的语音增强算法中,通常保留带噪语音相位谱并将其与语音幅度谱相结合。但在本文中,将对相位谱进行修正补偿相位谱用于语音增强算法中,主要的思想是通过改变一对共轭对称复频谱的角度关系来控制背景噪声增强或消除的程度。因此,在对相位谱进行补偿过程中需要使用反对称函数来实现,相位谱补偿的程度是根据噪声估计幅值来确定的,以期更好地适应噪声环境的变化。
对于修正的补偿相位谱,是由一个反对称函数进行相位谱的补偿:
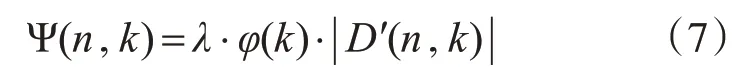
式中,λ是通过实验经验所获得的一个实数,φ(k)是一个反对称函数,|D′(n,k)|是通过使用ERB尺度进行多频带谱减法后计算初次增强的语音信号而获得的噪声估计幅值。对于初次增强后的语音信号,计算前三帧语音得到估计的噪声幅值。式(7)中的反对称函数由下式可得:

其中,对应于离散短时傅立叶变换后的非共轭矢量值的加权值为零。式(7)中反对称函数乘以对称函数仍然是反对称函数,这就构成了噪声消除的基本前提。
接着,将初次增强语音的复频谱与相位谱补偿函数进行加性计算:

公式中,Z(n,k)为图1中经过初次增强后的语音复频谱,Ψ(n,k)表示相位谱补偿函数。
最终修正的补偿相位谱计算如下:
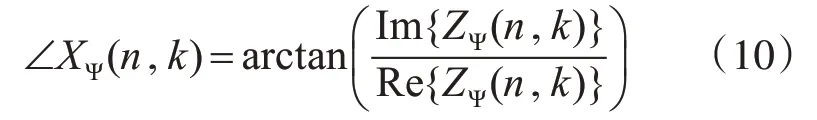
其中,Im和Re分别为计算复频谱的虚部与实部。
采用修正补偿相位谱来去除背景噪声的思想可以通过一对共轭对称矢量进行解释。在本文中先对带噪语音进行ERB尺度多频带谱减法得到初次增强的语音复频谱,接着再对初次增强的语音复频谱加上一个相位谱补偿函数,由于在复频谱上加上一反对称函数可以看作是往相反方向(分别为0和π)推动一对共轭对称矢量来消除背景噪声。噪声消除的强度是根据相位谱补偿函数决定的。因此,将ERB尺度应用于相位谱补偿函数在噪声消除中起着至关重要的作用。
4 实验结果分析
本小节对四种语音增强算法进行性能评估,四种算法分别为本文提出的改进算法(记为PSEA),基于线性划分的多频带谱减法(记为MBSS),基于ERB尺度划分的多频带谱减法(记为Erb)以及Kamil提出的传统补偿相位谱增强算法[7](记为MP)。
本实验中使用的语音数据来自于NOIZEUS语料数据库[13],其中该语料数据库包括30句语音和4种噪声类型。分别对高斯白噪声、汽车噪声、飞机场噪声以及babble噪声加以不同的信噪比来产生不同的带噪语音用于性能评估。在实验性能评估中,语音的采样频率均为8kHz,采样精度为16bit。本章节经过客观评价与主观评价两大方面来评估四种可比较的语音增强算法,为了便于直接进行算法之间的比较,短时傅里叶变换过程中涉及的基本参数在四种单通道语音增强算法中都设置一致。谱减参数中的过减因子α为2,谱下限设置为0.002。在接下来的部分,将从三个方面进行语音增强算法性能评估:信噪比提高,语音质量感知评估测度(PESQ)和语谱图对比。
4.1 信噪比提高
通常采用信噪比提高来评估语音信号的降噪量,信噪比提高即是输出分段信噪比减去输入分段信噪比。图2显示了不同输入信噪比在不同噪声类型下信噪比的提高。
从图2中可以看出,本文提出的算法得到的信噪比提高值最优,而分别采用两种尺度划分多带谱减法的增强效果均差不多,都比提出的算法和采用传统补偿相位谱增强算法的效果要差,这可以看作是一个预期的效果。因为采用多带谱减法只对语音幅度谱进行了变化,其相位谱仍然保持不变导致背景噪声的去除效果并不佳,另外,传统补偿相位谱是将带噪语音谱与补偿相位谱相结合,其噪声去除效果也并不优异,而本文提出的改进算法是在补偿相位谱中应用了ERB多带谱减法以此对语音进行增强,这就可以看出本文改进的补偿相位谱对去除背景噪声有一定的抑制作用。
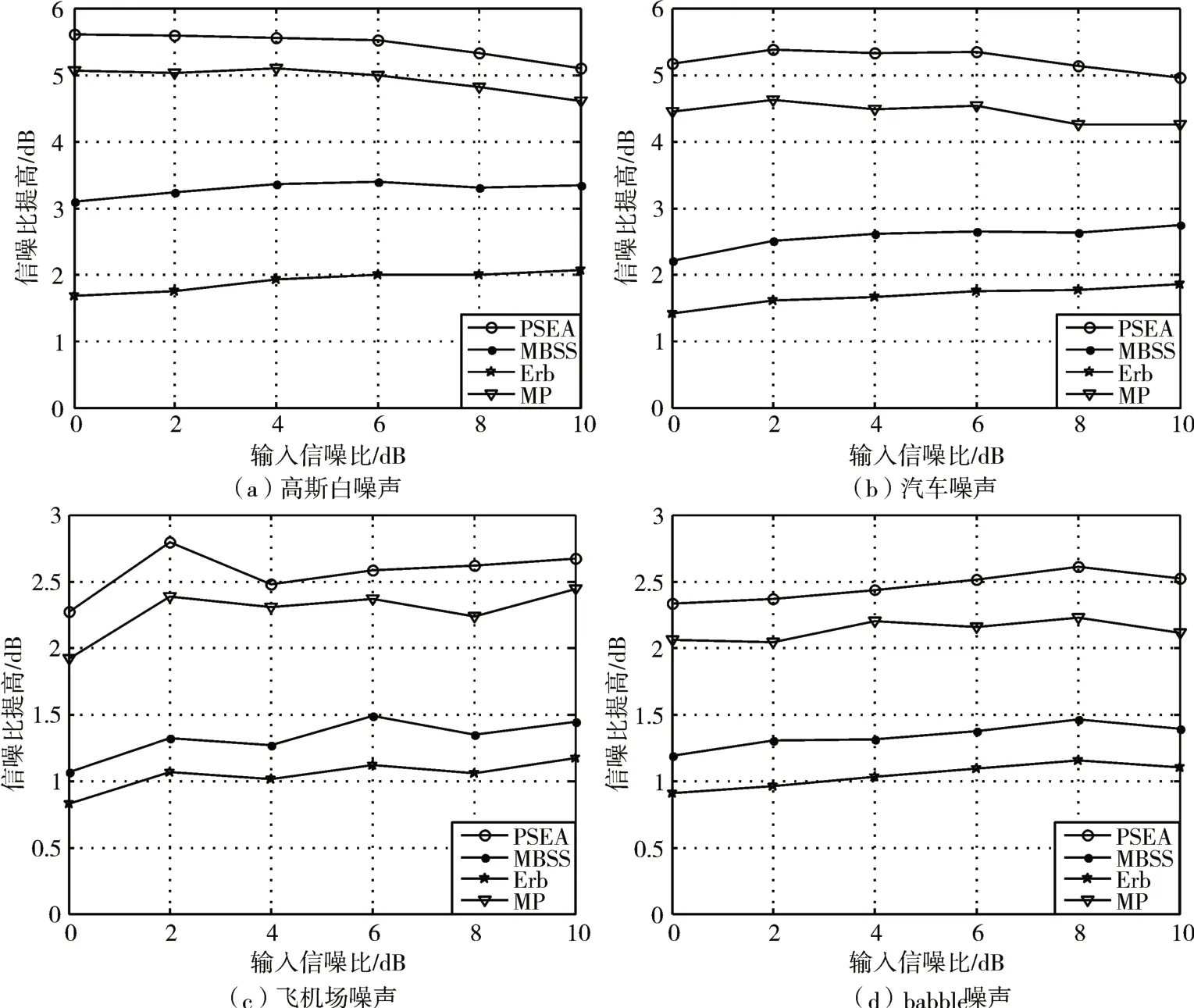
图2 不同噪声类型下信噪比提高
4.2 PESQ
PESQ值是所有客观评估参数中最为复杂的,但是其最能体现主观感知的一种客观评价方式,它的表现方式是采用评分制,即-0.5~4.5之间的数值表示增强语音信号的质量,PESQ值越高则表示增强语音信号的质量越好。在图3中,使用ITU-T推荐的PESQ评估方式对增强算法进行客观评估[14]。
根据图3可以观察到,在四种背景环境噪声中,本文提出的算法结果在高斯白噪声低信噪比环境下优于另外三种对比算法,随着信噪比提高,PSEA算法与MP算法结果一样较优,在另外三种噪声环境下,本文提出算法的效果并不是最优的,但与MP算法相差不大,这是因为高斯白噪声为稳态噪声,其他的噪声可以看作是非稳态噪声,本文提出的增强算法在稳态噪声下去噪效果较好。综合来看,本文提出的算法在PESQ值变化不大的情况下,信噪比在四种噪声下均有较大提升,有一定的进步意义。
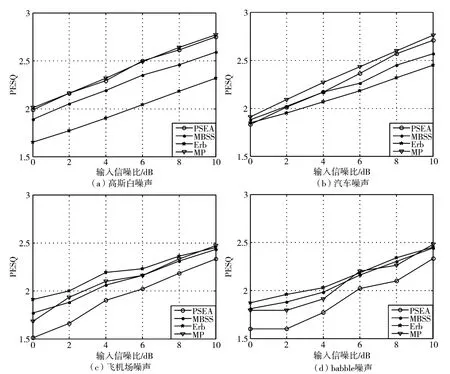
图3 不同噪声类型下PESQ值
4.3 语谱图
语谱图可以反映语音的结构并展示语音信号的动态频谱特性[15]。接下来,图4语谱图将给出一个示例,在这里带噪语音为加输入信噪比为0 dB的babble噪声,图中为所提出的改进算法和其他可比较语音增强算法之间的性能比较。
根据图4语谱图之间的对比可以看到,另外四种对比算法中的残余噪声量明显多于本文提出的改进算法,尤其可以看到(c)、(d)、(e)、(f)语谱图上面的红色残余部分明显较多于(g)中的残余量,经过PSEA算法增强后的语音信号从语谱图上看只有少量的残余噪声,这说明时其残余噪声和语音失真程度是可以令人接受的,同时也验证了4.1节中的结果,也能从另一个角度更好的补充了4.2节中的评估结果。
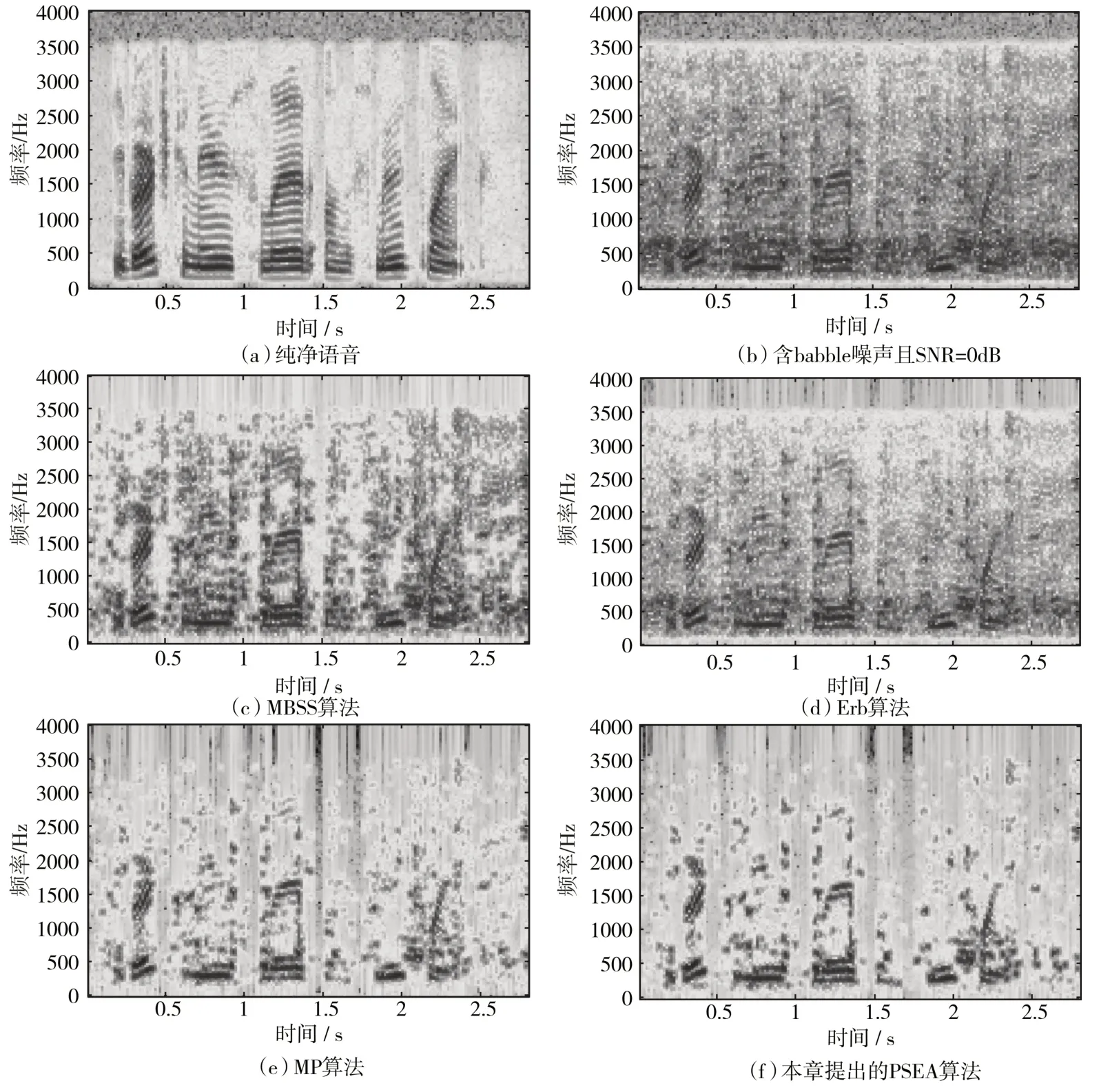
图4 语音语谱图
5 结语
本文提出了一种改进的单通道语音增强算法,将ERB尺度应用于修正传统的补偿相位谱中,并且将修正的补偿相位谱与谱减后语音幅度谱相结合以获得增强的语音信号。这是由于ERB尺度更加符合人耳的听觉特性,从而改进的补偿相位谱可以消除更多的背景噪声。从信噪比提高,PESQ值以及语谱图评估实验结果表明,本文提出的算法优于其他可比较的语音增强算法。
猜你喜欢
社会科学战线(2022年7期)2022-08-26
现代仪器与医疗(2022年1期)2022-04-19
通信产业报(2018年29期)2018-11-24
通信产业报(2018年40期)2018-01-22
移动通信(2017年3期)2017-03-13
科技视界(2016年11期)2016-05-23
现代电子技术(2015年17期)2015-09-23
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
现代电子技术(2009年13期)2009-08-31
