
基于PCDARTS改进的神经网络架构搜索算法*
2022-05-10 07:26:42赵加坤刘云辉
计算机与数字工程 2022年4期
赵加坤 刘云辉 孙 俊
(西安交通大学软件学院 西安 710049)
1 引言
近些年来,卷积神经网络在图像识别领域已经取得非常好的结果,但是设计一个高效的卷积神经网络依赖于专家经验和知识,并且需要花费大量的时间和精力,因此如何自动找到一个合适的卷积神经网络这一课题受到了越来越多研究者的关注。在深度学习中,这一课题被称为神经网络架构搜索(NAS)。即通过设计经济高效的搜索方法,自动获取泛化能力强的神经网络,大量解放研究者的创造力。
神经网络架构搜索算法主要分为三类:1)基于强化学习的搜索算法,代表性算法包括谷歌的、NASNet[1]、ENAS[2]、DNAS[3]等,这种算法采用RNN网络作为控制器来采样生成描述网络结构的字符串,该结构会用于训练并得到评估的准确率,然后使用强化学习算法学习控制器的参数,使之能产生更高准确率的网络结构。2)基于进化算法的搜索算法,代表性算法包括AmoebaNet-A[4]、MFAS[5],这类算法首先对网络结构进行编码,称为DNA。演进过程中会维扩护网络模型的集合,这些网络模型的调整通过它们在验证集上的准确率给出。这两类方法都是在离散空间中搜索网络结构,效率低下,需要巨大的算力,使得大多数研究者望而却步。3)基于梯度的搜索算法,代表性的算法包括PDARTS[6]、NAO[7]、SETN[8]等,和前两种算法不同,此类算法通过某种变换(例如softmax)将离散空间变成连续空间,目标函数变成可微函数,即可通过梯度下降的方式寻找对应的最优结构,并且使得搜索速度大幅度提高。
本文基于PCDARTS[9]提出一种高效的神经网络架构搜索算法,所做改进如下:
1)引入特征变换效果更好的通道重排操作和global-context操作扩展原算法的搜索空间。
2)设计一个修正网络的reduction cell,算法去搜索normal cell,在cifar-10和cifar-100上搜索时,可以在不损失精度的前提下节约31%的搜索时间。
2 相关工作
近些年来,研究者们在神经网络架构搜索领域已经取得非常好的进展并且发现了许多在cifar数据集以及ImageNet数据集上表现良好的网络架构。谷歌大脑提出的NAS算法,使用RNN作为控制器去采样子网架构,子网在验证集上获得验证精度R,然后验证精度R反馈给控制器并更新下一个子网架构。同样是谷歌大脑的杰作NASNet算法中,它继承了NAS中RNN控制器的核心内容,但不同的是,它不是从头到尾采样一个子网络,而是结合Inception v1[10]网络的观点,将子网看成是由一个个的cell块组成的网络,文中搜索两种不同类型cell,即reduction cell和normal cell,然后按一定顺序叠加构成完整的网络架构。NASNet相比NAS直接搜索完整的网络结构要节约7倍的搜索时间,本文将同样采用这种cell搜索的方式。
在众多基于强化学习和进化算法的搜索算法中,有一个明显的缺点,那就是消耗算力巨大,谷歌提出的NAS曾花费3150gpu days在cifar-10数据集上搜索出一个表现良好的卷积神经网络。为了解决这一问题,研究者开始探索新的搜索策略。近些年来,基于梯度的搜索算法受到了广泛关注,谷歌和CMU的学者提出了DARTS,一种可微的架构搜索算法,该算法将搜索空间表示成有向无环图,通过松弛化操作将原本离散的搜索变成连续可微的搜索,然后通过梯度下降的方式寻找最优的reduction cell和normal cell,最后堆叠两类cell成卷积神经网络。商汤研究院提出了SNAS[11],该方法将搜索过程建模成马尔可夫模型,保持了概率建模的优势,并提出同时优化网络损失函数的期望和网络正向时延的期望,扩大了有效的搜索空间,可以自动生成硬件友好的稀疏网络。华为诺亚方舟实验室提出了基于DARTS改进的PCDARTS算法,该算法通过部分连接和边的正则化解决了DARTS占用内存大的问题,并减少了搜索时间。Xuanyi Dong等提出了GDAS[12]算法,同样是基于DARTS改进,该算法使用Gumbel-max trick[13],在前向传播时用argmax函数选取节点间的连接方式,在后向传播时用softmax函数将one-hot向量可微化,并设计了一个修正后的reduction cell,只搜索normal cell,节省了搜索时间。
3 算法模型
3.1 搜索空间
3.1.1 节点间的拓扑结构
我们为最终的网络结构架构搜索两类不同的cell,按照一定的顺序堆叠成网络。每个cell都是包含了7个节点的有向无环图,每个节点表示卷积网络中的特征图x(i),每条边e(i,j)代表将特征图x(i)变换到特征图x(j)操作O(i,j),如式(1)所示:
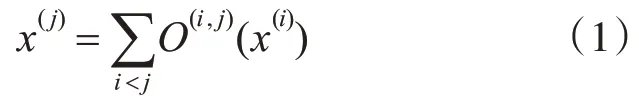
七个节点中有两个输入节点(来自之前的cell输出),一个输出节点,和四个中间节点,输出节点由四个中间节点进行通道连接而成,如图1所示。

图1 节点间的拓扑结构
3.1.2 节点之间的操作列表
如图1所示,节点间左侧的细线代表了节点间的转换操作,在PCDARTS中,所使用到的操作列表如下:
1)None,节点间没有连接;
2)Identity,跳跃连接;
3)Max_pool_3×3,最大池化;
4)Avg_pool_3×3,平均池化;
5)Sep_conv_3×3,3×3分离卷积;
6)Dil_conv_3×3,3×3空洞卷积;
7)Sep_conv_5×5,5×5分离卷积;
8)Dil_conv_5×5,5×5空洞卷积。
本文考虑到较大的卷积核可以通过堆叠小的卷积核代替,这一点和Inception v3[14]提出的用两个3×3卷积核堆叠代替7×7卷积核的方法不谋而合,而且连续的3×3卷积更具有非线性表现力,更能降低模型的参数,所以本文将舍去5×5卷积核,并加入两个新的操作channel shuffle卷积和global context。
Channel shuffle操作:Xiangyu Zhang等[15]提出的shffuleNet,原文提出在叠加组卷积层之前进行一次通道重排操作(称之为channel shuffle操作,如图2所示),然后被打乱的通道会被分给不同的组,使用该操作的好处就是输出的特征向量包含更丰富的通道信息并且更具有表现力。
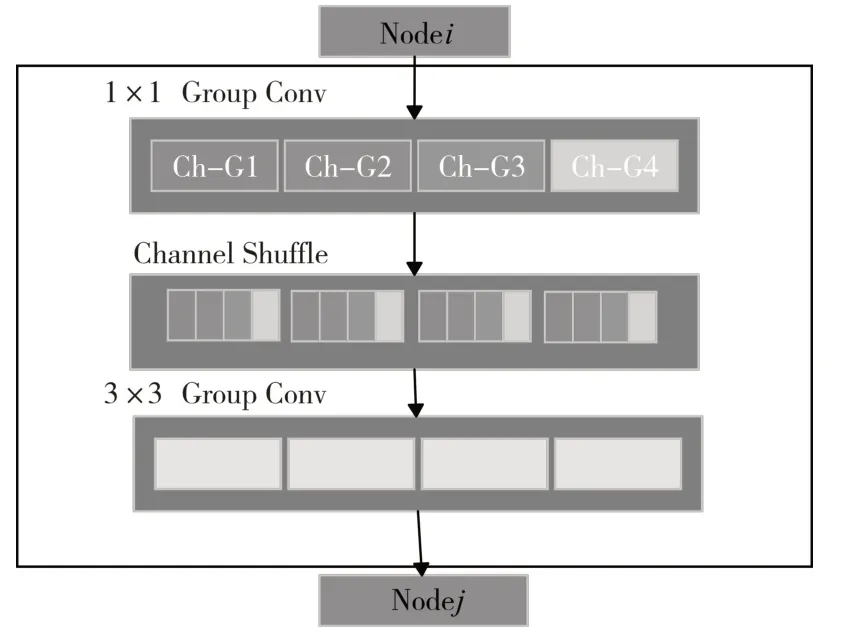
图2 通道重排操作
Global context:Yue Cao等[16]提出的global context(如图3所示,其中scale1表示矩阵相乘,scale2表示矩阵对位相加)是基于自注意力机制的block,它遵循通用的三步骤框架,即全局上下文建模,通道信息的转化,通道融合。而且由于gc block中存在全局信息的相互交互,使得它比普通卷积的特征提取效果更好。

图3 全局上下文操作
3.2 搜索算法PCDARTS
在PCDARTS中,首先将所有离散操作通过SoftMax函数转换成连续空间,然后,架构搜索问题就转化为学习一组连续变量。当我们使用验证集评估网络架构的性能时,我们可以通过梯度下降来优化模型架构,类似于更新网络参数,而这里更新的是架构参数。
PCDARTS将每条边设置为有N+1个并行路径的混合操作,表示为Mix O,N为操作的总数,如图4所示,给定输入x,假定O={oi}表示操作列表,混合操作MixO的输出是基于它的N路输出的加权和和未采样路径输出的叠加,如式(2)所示,1/K每个节点特征图的用于操作混合的取样比例:
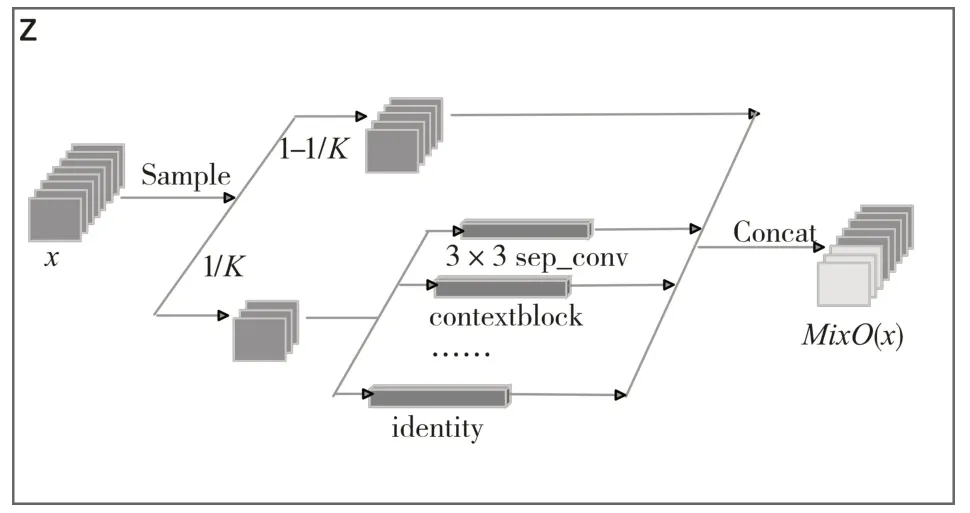
图4 边的混合

如果一个基本运算对边缘有贡献,其权重应该大于其他的操作,我们选择前两个权重最大的操作作为下个节点的输入。
3.3 堆叠cell成网络
Cell的堆叠方法也可以由一些类似于单元结构的搜索算法来完成,但本文的研究重点并不在这方面,所以本文将按照图5的堆叠方式来构建网络。我们在深度上叠加两种不同数量的cell,将第k个cell的输入设置为第k-1和第k-2个cell的输出,为了减少整个网络的大小,将网络的第1/3和2/3的位置设置为reduction cell,其余位置是含有N个normal cell的block,网络搜索阶段,N=2,此时网络由8个cell构成,在网络评估阶段,N=6,此时网络由20个cell构成,而在搜索阶段使用较少cell的原因是在这个阶段只需要找出相对表现较好的网络,使用较少的cell可以大幅度提高搜索速度。

图5 网络的堆叠方式
3.4 对于固定reduction cell的讨论
纵观一些人工设计的卷积神经网络,AlexNet[17]和VggNet[18]使用最大池化减少空间维度,Densenet[19]使用1×1卷积后跟一个平均池化层去降维,Resnet[20]使用步长为2的卷积层代替池化层,这些网络使用的reduction cell大多都简单而高效,而自动搜索的reduction cell往往都很相似且简单,除此之外,联合搜索两种cell也将带来优化难度的增加,所以为了获得最终的更高效的卷积神经网络,本文设计了修正网络的reduction cell(FRC),如图6所示。
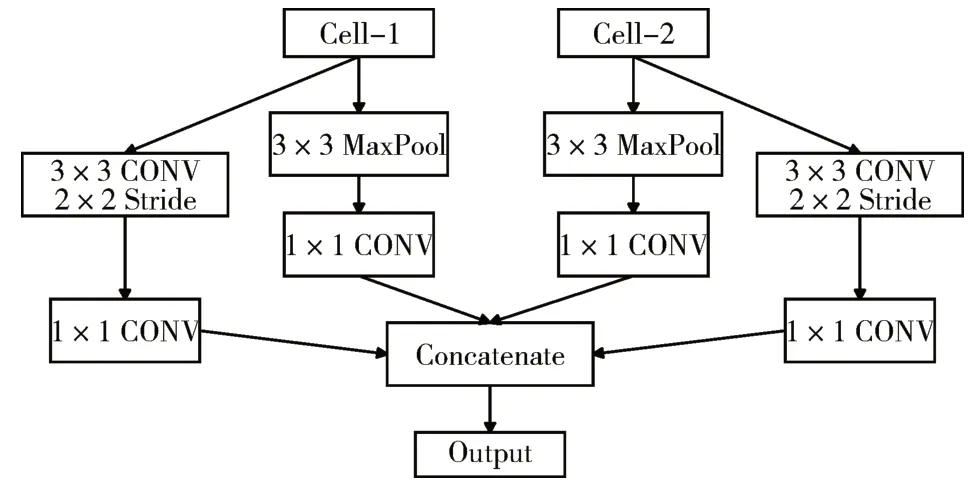
图6 修正的reduction cell
4 实验结果及分析
4.1 数据集
CIFAR数据集是图像分类领域的常用数据集,其中CIFAR-10数据集由10个类的60000个32×32×3图像组成,每个类有6000个图像,总共有50000个训练图像和10000个测试图像。CIFAR-100数据集由100个类的60000个32×32×3图像组成,每个类有600个图像,共有50000个训练图像和10000个测试图像。
Tiny-ImageNet数据集来自ImageNet数据集,和CIFAR数据集分属于不同的应用场景,该数据集包含200个不同的图像类别,每个图像的大小为64×64,训练集有10万个图像,验证集有1万个图像(每个类别50张图片)。
4.2 架构搜索
本次实验所选用的操作列表如下:1)None,2)Identity,3)max_pool_3×3,4)avg_pool_3×3,5)sep_conv_3×3,6)Dil_conv_3×3,7)channel_shuffle_3×3,8)contextblock。
在搜索阶段,和PCDARTS一样,我们设置网络由8个cell堆叠而成,而验证阶段是20个cell(因为在搜索阶段只需找出相对表现较好的网络,使用较少的cell可以提高搜索速度),每个cell使用4个中间节点,设置初始通道数为16并搜索50个epoch,其中前15个epoch为网络参数预热阶段,预热可以减少初始化时某些操作固有权重较高的影响,比如None操作。我们设置K=4,意味着每条边仅有1/4的特征图被采样,可以节省显卡内存占用,网络权重w采用冲量算法优化,初始化学习率为0.1并使用余弦退火算法自动修正,冲量参数0.9,权重衰减率为0.0006(部分参数使用自己调整的参数而非PCDARTS论文给出的参数)。网络架构参数采用Adam算法优化,学习率为0.0005,冲量变化范围为(0.5,0.999),权重衰减为0.003。联合搜索两类cell时在单卡NVIDIA GTX 1080 TI GPU上花费的时间是3小时30分钟(去掉网络预热时间),在修正reduction cell只搜索normal cell的情况下节省了25%的内存消耗且单卡搜索时间为2小时25分钟(去掉网络预热时间,节省了大约31%的时间消耗),表1给出了算法的搜索结果并和主流算法作对比(字体加粗的两行本文做了实验),我们将在cifar-10上搜索然后将搜索的架构迁移到cifar-100和Tiny-imageNet上使用,搜索的架构如图7所示其中(a)和(b)联合搜索下的两类cell,(c)表示加入修正后的reduction cell后搜索得到的normal cell。

表1 和主流算法的对比(cifar-10)
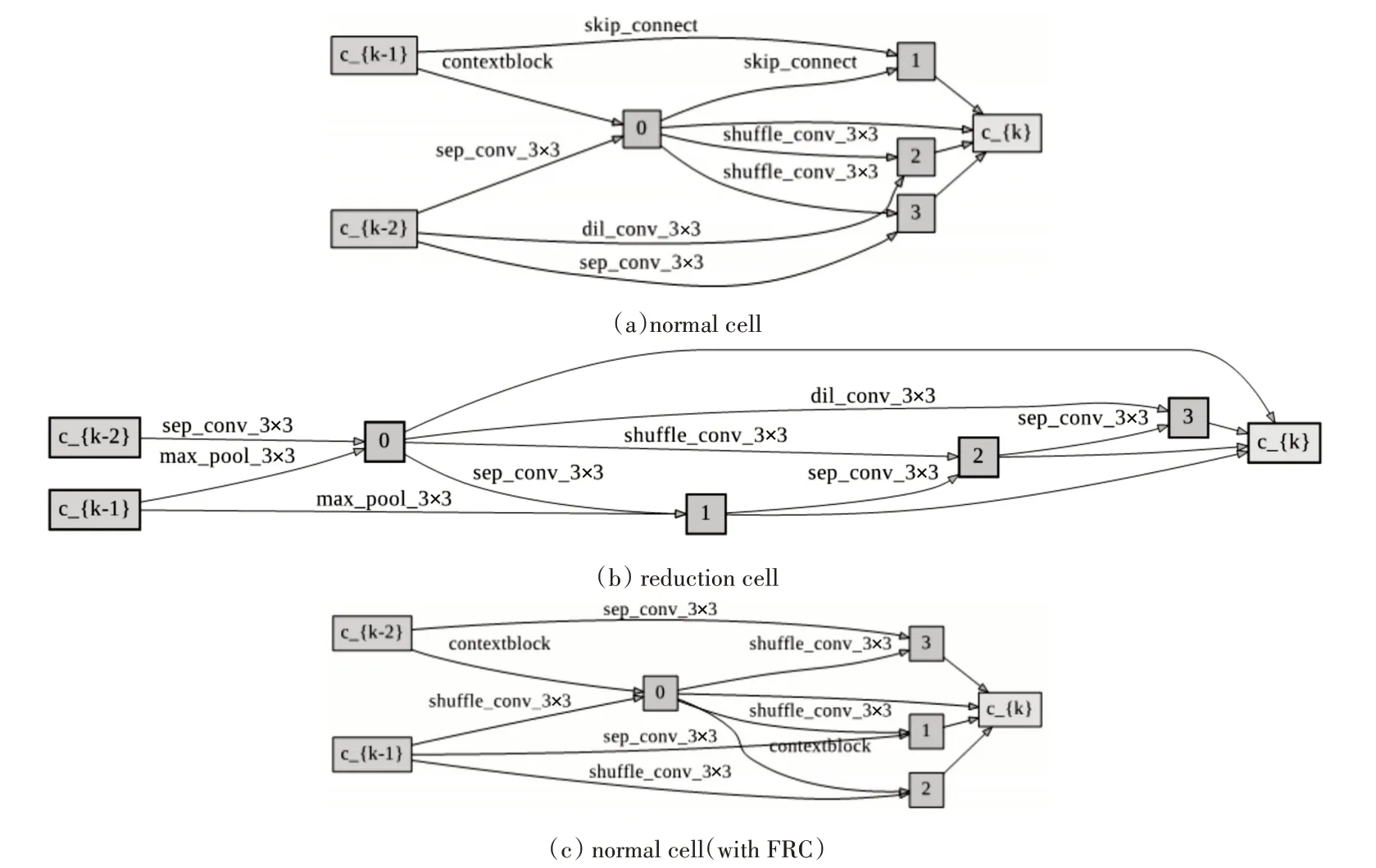
图7 搜索结果
4.3 网络评估
在评估阶段,网络由20个cell(18个normal cell和2个reduction cell)构成,初始化通道数为36,我们采用SGD算法优化权重参数,设置初始学习率为0.025采用余弦退火算法自动修正,冲量参数0.9,权重衰减0.0003,梯度裁剪参数为5,在cifar-10和cifar-100数据集上使用batch_size=64训练600个epoch,训练4次,取最好结果(消除网络初始化的随机性),为了防止不同环境带来的影响,我们将原PC-DARTS得到的网络在我们的环境下进行了测试并和我们最终的结果进行对比。
表2和表3给出了三个模型在cifar10和cifar100数据集上的表现,可以看出我们的模型使用的参数量略微减少,Ours(with FRC)模型获得了最好的精度,在cifar10数据集上的精度提高了0.5%,在cifar100数据集上的top-1精度提高了1%,我们根据日志记录的结果将表现最好的模型Ours(FRC)的损失精度图画出如图8和图9所示,两个模型均在较短的epoch内完成收敛。
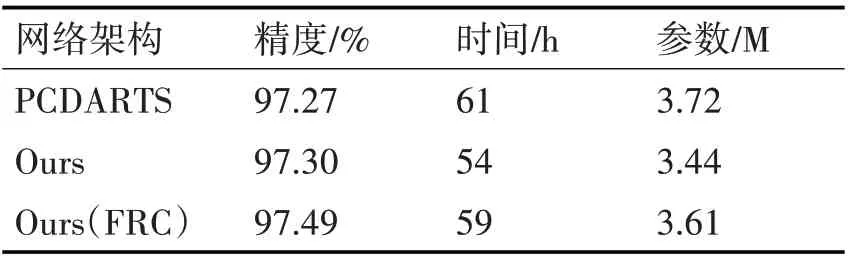
表2 模型表现(cifar-10)
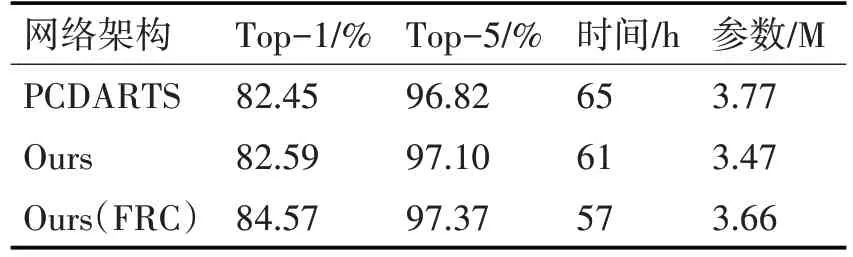
表3 模型表现(cifar-100)

图8 cifar10损失精度变化图(FRC)

图9 cifar100损失精度变化图(FRC)
由于Tiny-ImageNet和cifar数据集存在差异,若将cifar10上搜索的网络拿过来使用并不合理,因此本文会在Tiny-ImageNet数据集上重新搜索出一个可用网络并和从cifar数据集上迁移的网络作对比,我们使用3个模型在NVIDIA GTX1080TI显卡上各训练200个epoch,结果如表4所示,其中Ours(cifar/tiny)模型表示在cifar或tiny-imagenet数据集上搜索得到的架构,当我们直接将架构由cifar-10迁移至tiny-imagenet数据集上时,模型表现会变差,因此,当需要将算法迁移到新的数据集上时最好用新数据集重新搜索网络。
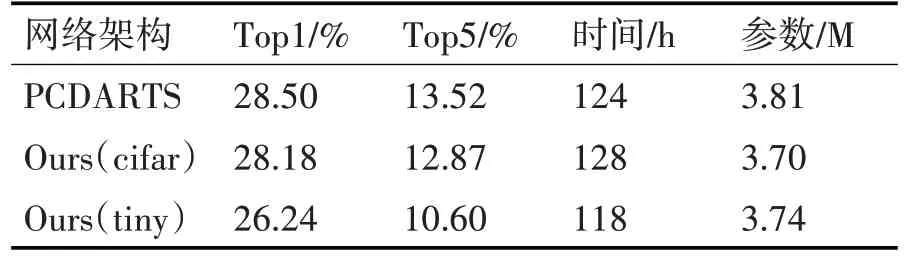
表4 模型表现(tiny-imagenet)
5 结语
本文基于PCDARTS提出一种高效的神经网络架构搜索算法,我们更改了原算法的搜索空间加入了提取图片特征更高效的channel shuffle操作和global context操作,变换了原论文搜索两种cell的思路,设计了一个更高效的reduction cell,仅仅去搜索normal cell,不仅减少了约31%的搜索时间,还提高了分类的精度,使得我们搜索的算法更加高效可用。研究神经网络架构搜索对自动化机器学习有着深远的意义,谷歌的AutoML引入了自研的ENAS算法,极大降低了神经网络设计的复杂度,提高了效率,希望未来的神经网络架构搜索算法会应用到更多的场景里去。在接下来的工作中,我们将考虑在深度上实现堆叠cell的自动化,所以渐进式堆叠cell将是下一阶段的主要研究内容。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
汽车工程(2021年12期)2021-03-08 02:34:30
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
电信科学(2017年6期)2017-07-01 15:45:17
电测与仪表(2015年15期)2015-04-12 00:43:48
电测与仪表(2015年22期)2015-04-09 11:42:18
河北科技大学学报(2015年5期)2015-03-11 16:16:37
