
基于学习者模型的教育资源推荐方法*
2022-05-10 07:26赫少华尹四清景志宇王文杰
计算机与数字工程 2022年4期
赫少华 尹四清 景志宇 王文杰
(1.中北大学软件学院 太原 030051)(2.北方自动控制技术研究所 太原 030006)
1 引言
在线教育资源的增多,引发教育资源“信息过载”,针对此问题,研究者把推荐技术引入到教育资源领域。
目前推荐算法有协同过滤推荐算法、基于内容的推荐算法、混合推荐算法等。协同过滤算法是目前在推荐领域最成熟的算法[1~2]。其中,温会平和陈俊杰为了解决计算相似度不准确的问题提出一种基于用户模糊聚类的个性化推荐算法,提高了推荐准确性[3];Li等在深度学习框架下引入矩阵分解提出一种新的推荐方法[4];Lei等在协同过滤算法中引入标签权重,提出一种基于标签权重相似度量方法的协同过滤推荐算法提高了推荐效果[5]。
教育资源推荐领域,Wang结合学习者兴趣模型提出了一种改进的协同过滤算法[6];Ding等提出融合学习者社交网络的协同过滤学习资源推荐[7]。
上述算法中,传统协同过滤的算法存在计算特征单一、计算量大的问题,结合教育资源的特点,教育资源推荐领域不仅要考虑用户对教育资源评分的相似度,同时也要考虑用户的学习水平和学习能力相似度。本文以教育资源为目标,工作如下:
1)新用户,使用深度学习方法自动抽取用户的关键信息然后进行分类,找到对应的类别,然后根据兴趣类别进行计算和推荐。
2)老用户,提取用户历史信息确定用户的兴趣类型,使用学习者模型类内计算相似度,然后增加对目标用户的学习水平以及课程难度的计算。
2 相关工作
2.1 长短时记忆(LSTM)网络
LSTM模型是对循环神经网络(Recurrent Neural Network,RNN)改进的一种新型网络模型[8],LSTM对RNN起到了扩展的作用[9]。由于RNN存在无法处理处理长时间序列问题的缺陷[10]。研究人员提出RNN的改进模型LSTM,LSTM在捕获长期时间依赖性方面既通用又有效[11~12]。LSTM通过“门”控制结构来实现对信息的筛选,输入门决定保留多少个有效的输入信息,输出门决定当前时刻输出多少个有效的单元状态,遗忘门决定是否保留上一个状态输出的信息[13]。网络结构如图1。
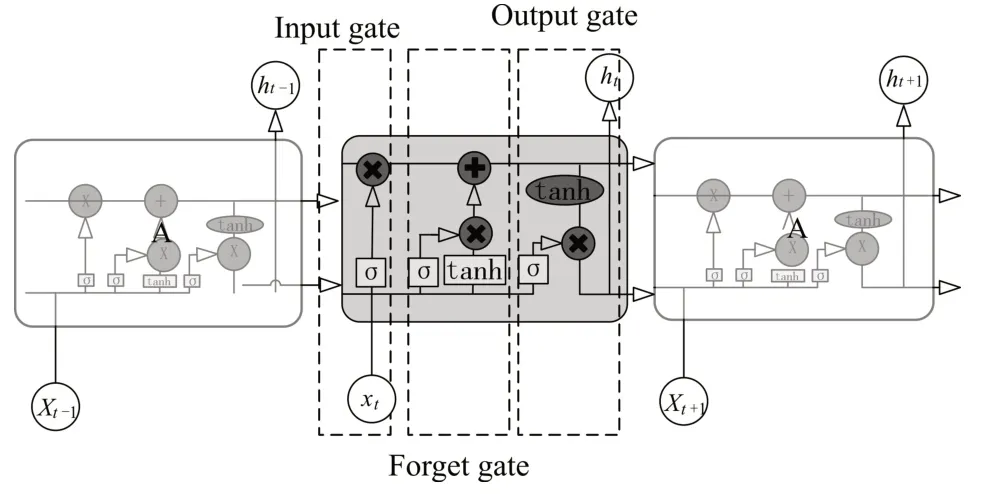
图1 LSTM网络结构图
2.2 协同过滤算法
协同过滤(Collaborative Filtering,CF)算法是目前智能推荐系统中使用最成熟的算法[14]。其核心思想是从用户或项目角度出发,计算用户或项目之间的相似度,根据相似度由高到低排列取出前N个作为邻居,从而进行推荐。
协同过滤算法在应用中仅考虑用户对项目的打分特征,未考虑用户固有的特征和行为,忽略了用户自身的客观信息,并且随着用户数量的增多计算复杂度也会相应的增加[15]。教育资源推荐领域,使用协同过滤算法,不仅要计算用户评分相似度,同时仍需考虑目标用户的学习水平等特征。基于此分析,本文结合传统的协同过滤算法提出了一种基于学习者模型的混合推荐算法用于教育资源推荐。
3 学习者模型构建
构建学习者模型有两部分:学习者行为特征收集、学习者模型构建。
1)学习者行为特征收集:模型包括学习者个人信息特征和学习者的学习特征两大类特征,如表1所示。
2)学习者模型构建:以表1中的用户特征作为学习者的基本特征进行建模。以图2为例,U为学习者,用户偏好为C同时映射为用户兴趣类型也为C,C={1,2,3,…},学习课程为K={K1,K2,K3…Kn},学习能力为l,学习时间为h、学习经验为e、学习得分为s、学习进度为p、作业提交次数为z、课程评分为S core。

表1 学习者特征

图2 学习者模型图
4 基于学习者模型的推荐算法
用户基本信息反映用户兴趣较少,如果对用户的个人简要说明数据挖掘和分析可以更为准确地获取用户兴趣。解决文献[16]中,人工对学习者分类的问题,缓解新用户冷启动问题。
4.1 学习者模型的整体结构
学习者模型整体结构如图3,主要包括两部分:

图3 学习者模型整体流程图
1)新用户。使用神经网络自动抽取用户兴趣的方法缓解冷启动,通过用户兴趣得到用户喜欢的课程类别,然后类内计算用户间学习能力相似度得到相似用户,进行推荐;
2)老用户。通过用户历史信息确定用户类别,引入学习者学习行为特征和学习能力相似度类内计算,得到模型相似度分数,在此基础上计算类内用户评分相似度,最后,融合计算模型相似度分数和评分相似度分数得到最终用户集合进行推荐。
4.2 使用神经网络缓解冷启动
针对推荐系统冷启动问题,利用LSTM文本分类方法对新用户进行分类。
4.2.1 基于LSTM_Maxpooling实现文本分类
本文使用如图4的LSTM分类模型,该网络模型单元由5层组成,第一层为embedding层用于完成分词及向量化操作;第二层为spatial_dropout1d提高特征之间的独立性;第三层为LSTM层,其中包含100个神经元,输入、输出激活函数使用tanh,“门”激活函数使用sigmoid;第四层使用MaxPooling,以获取到最显著特征;第五层为使用SoftMax进行分类。为防止过拟合现象的产生,训练过程中使用dropout,并提升模型的泛化能力。模型工作流程如下:
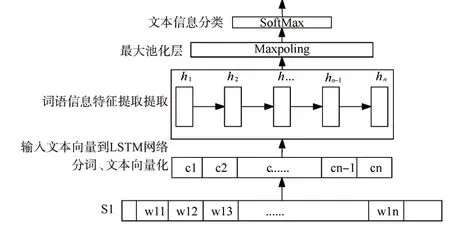
图4 LSTM-Maxpooling分类模型图
Step1:句子分词及向量化;
Step2:输入词向量,经LSTM层处理输出n个时刻的向量h1,h2,…hn;
Step3:输入上层输出的向量进行最大池化操作得到特征向量h;
Step4:将上层的特征向量h经SoftMax层处理完成文本信息分类。
4.2.2 计算用户学习能力相似度
定义:C为用户偏好同时映射为资源类别,C∈{1,2,3,…},根据课程类别映射出用户的兴趣类别;l∈{1,2,3}表示学习者的学习能力水平,其中1,2,3分别对应初级、中级和高级;U表示全体用户,UCj表示第j个类别为C的用户,UCt表示目标用户。对于新用户类内相似度计算,计算学习水平相似可以使用标准高斯分布,其表达式如式(1)所示:
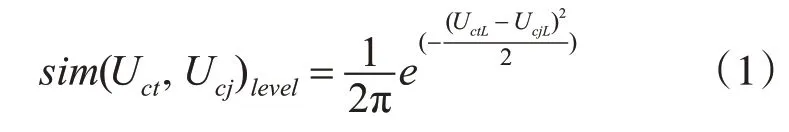
式(1)中UCt,UCj分别表示目标用户和同类别下的其他用户,UCtL,UCjL分别表示两个用户的学习水平。sim(UCt,UCjlevel)的值越大两个用户的相似度越大,反之相似度越小。
4.3 使用学习者特征改进相似度计算
4.3.1 提取用户的兴趣标签
使用统计方法对用户的历史学习信息进行统计得到用户的兴趣标签,其计算方式如式(2)所示:
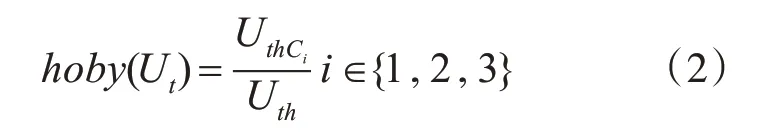
式(2)中Uthci表示用户Ut历史信息中学习第i类课程的次数,Uth表示用户的学习的总次数。
4.3.2 类内计算
根据上一步提取到的用户兴趣标签在用户兴趣类别中进行计算,具体过程如下:
1)使用表1中老用户的学习特征计算学习特征相似度。
U表示全体用户,Uci,t表示目标用户Uci,j表示同一个类别下其他用户,其中t∈U,j∈U。使用两个用户对同一个课程的行为特征做计算,Uci,t→K表示用户Uci,t对课程K的行为特征,Uci,j→K表示用户Uci,j对课程K的行为特征,K为两个用户共同学过的课程,用户对课程的行为使用行向量表示,如式(3)所示:
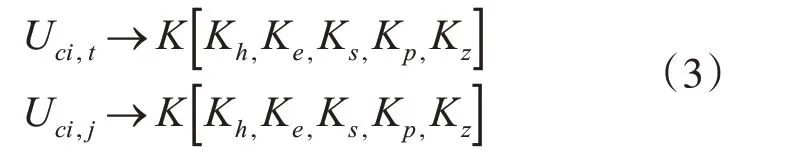
式(3)中kh,ke,ks,kp,kz分别表示学习者学习课程的时间、获得的经验、得到的分数、学习的进度以及作业提交次数。为了得到两个用户共同课程的相似度使用式(4)进行计算:
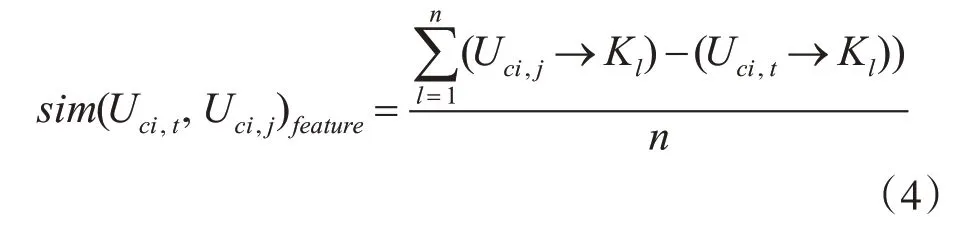
式(4)中l表示两个用户之间共同学习的课程l∈{1,2,3,…,n},n表示两个用户共同学习过的课程的总数。结合式(4)和式(1)计算学习者模型相似度,其表达式如式(5)所示:
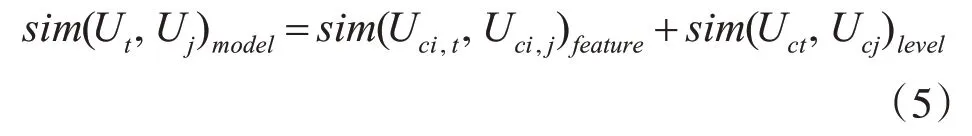
2)用户资源评分相似度计算
结合式(2)计算出目标用户历史信息中目标用户感兴趣的类别,找到与目标用户兴趣相同其他用户,使用用户ID为行索引,课程ID为列索引,构建“用户-评分”表,评分表中每一行表示一个用户对所有课程的评分信息,每一列表示一个课程所得到的用户的评分,表中数据表示具体的评分,其“用户-评分”表的结果如表2所示。

表2 用户-评分表

最后,将学习者模型相似度和评分相似度进行相加,具体如式(7)所示:

根据式(7)的计算结果,由高到低进行排序,取其前N个作为邻居集合。
3)产生推荐
通过上述评分计算得出直接邻居,预测最终邻居用户中目标用户没有产生评分的课程的分数,选取预测分数最高的前N个课程进行推荐,计算表达式如式(8)所示:

5 实验分析
本文实验环境设置如下:
硬件环境:Intel(R)Core(TM)i5-3210M CPU@2.50GHz、8G RAM
软件环境:Python 3.7、Tensorflow 2.0
5.1 LSTM_Maxpooling模型性能分析
实验采用采集自某教育网站的教育资源数据集,包含1000个用户的个人注册信息和10类别的课程资源,实验流程如下:
Step1:数据进行预处理,去除停用词;
Step2:分词并完成分词数据向量化;
Step3:将类别标签向量化;
Step4:划分训练和测试数据集;
Step5:构建LSTM_Maxpooling进行实验。
实验使用本文模型分别与CNN、GRU、LSTM三种网络模型进行对比实验,结果如表3,在测试集和训练集划分为1∶4的时候的训练和测试的Accuracy如图6,Loss如图7所示。
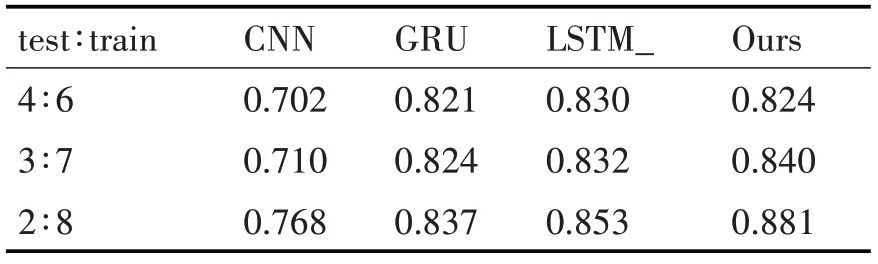
表3 实验结果
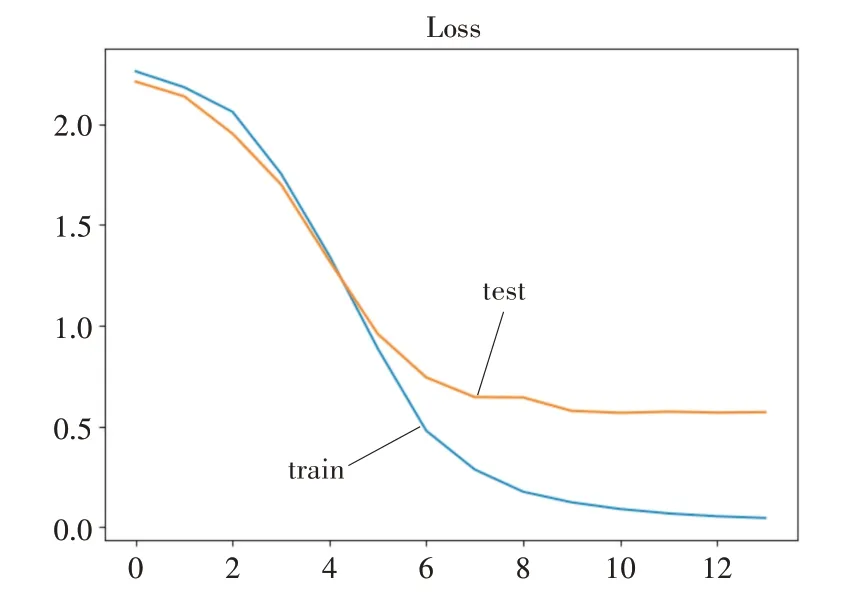
图6 Ours_Loss图
由表3和图5可以看出,随着训练数据的增加,本文的模型效果越好。间接证明对于分析新用户注册信息定位新用户的兴趣,本文模型较其他3种算法(CNN、GRU、LSTM)准确率更高,应用到教育资源推荐领域,可以缓解冷启动问题。
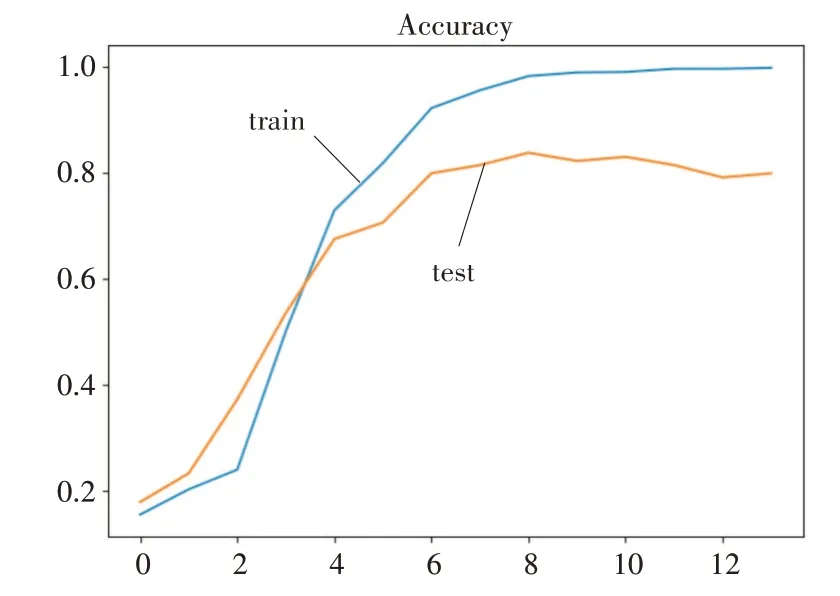
图5 Ours_Accuracy图
5.2 学习者特征模型实验及分析
实验使用处理后的某教育网站数据集,其中包括50000个用户和861门课程,该数据集中包括用户对课程的显性行为信息和隐性行为信息,将实验数据随机化划分为训练集和测试集进行实验,实验流程如下:
Step1:分析用户的历史信息得到用户的历史兴趣标签;
Step2:根据兴趣标签,找到与之对应的相同用户的集合;
Step3:通过式(1)和式(4)分别得到用户学习能力水平相似度分数和用户的学习特征相似度分数,并结合式(5)得到最终模型相似度分数;
Step4:由step1得到用户集合,构成“用户-课程”评分表,使用式(6)计算评分相似度;
Step5:根据式(7)得到用户间最终的相似度分数,进而得到相似用户集合;
Step6:使用式(8)对用户集合中目标用户未评分项目进行预测,输出推荐结果。
为了分析模型的有效性,本文从准确率、新颖性和F1综合指标3方面进行定量分析。其具体形式如式(9)~式(11)所示:
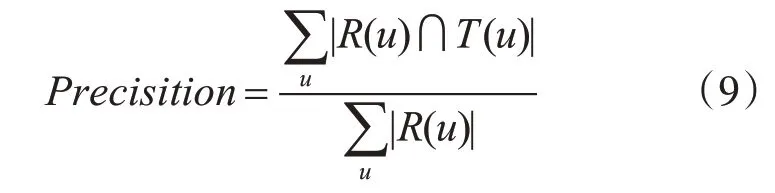
式(9)中R(u)表示通过学习者模型算法推荐给用户u的课程,T(u)表示测试集上的用户u喜欢的课程。
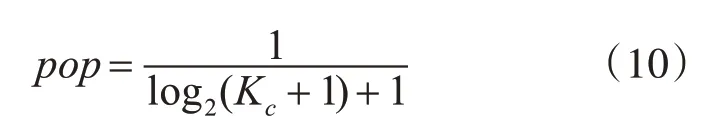
式(10)中Kc表示课程的流行度,为了防止冷门课程的流行度为0导致分母为0所以在分母为位置加1,pop为新颖度,pop越大说明推荐的新颖度越高。

式(11)中,p表示准确率,r表示召回率。
根据图7的结果可以看到,在数据比较少的情况下本文模型由于过滤掉的条件太多,很难找到与目标用户有太多交集的用户所以导致推荐的准确率较低,但是随着数据的不断增多,本文的在一定程度上优于传统的协同过滤算法。
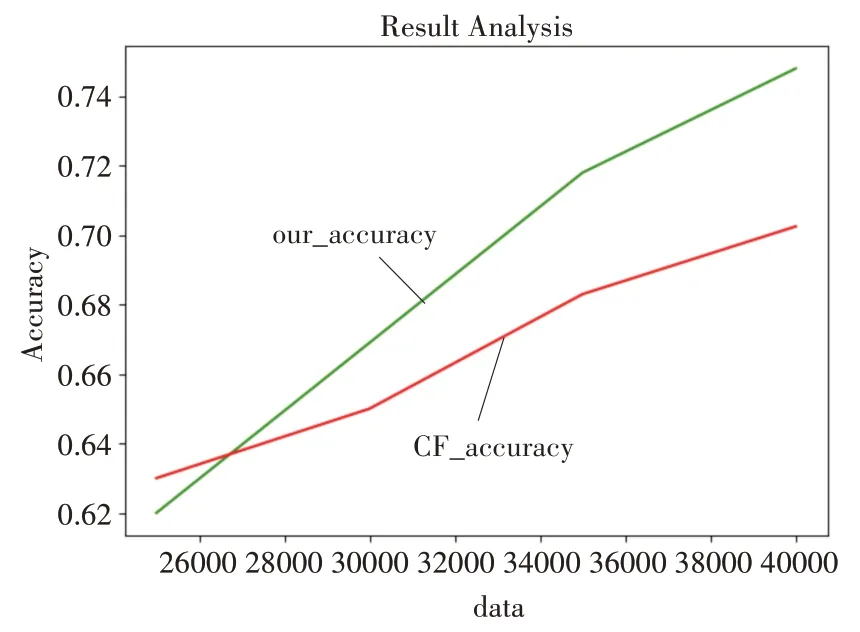
图7 学习者模型推荐算法准确率图
根据图8可以看出,随着数据量的增加,学习者模型推荐方法的新颖度逐渐高于传统协同过滤算法的推荐新颖度,由此证明本文的模型在大数据场景下相比于传统协同过滤在推荐新颖性方面更具有优势。
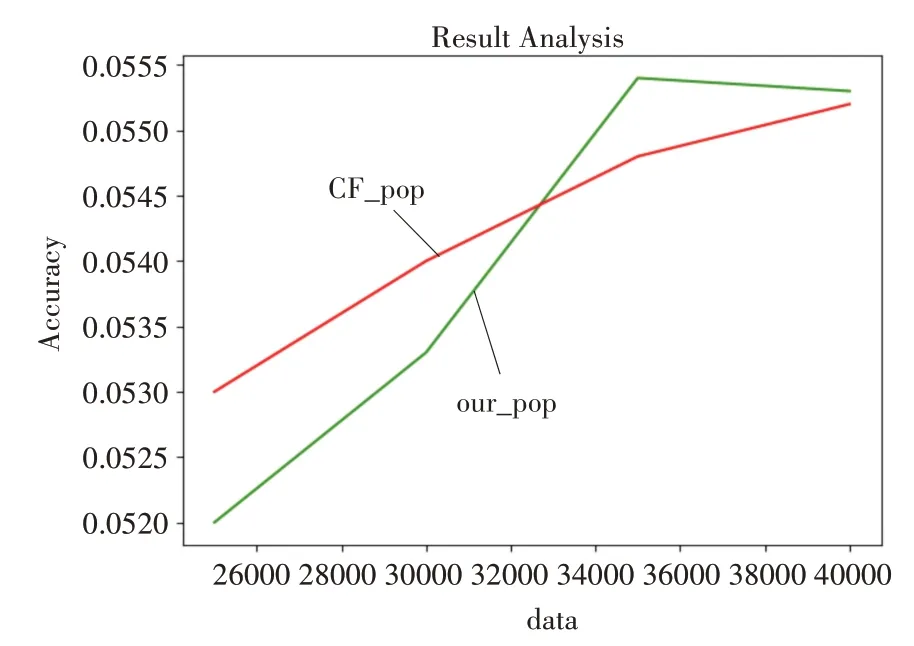
图8 学习者模型推荐算法准确率新颖度图
根据图9可以看出F1指标在整体上呈上升趋势,并且随着数据量的增加,学习者模型推荐方法的F1score的变化曲线高于传统的协同过滤算法点变化曲线,由此证明,本文模型更适合数据较大的场景。

图9 学习者模型推荐算法F1综合指标图
基于以上分析,本文提出的基于学习者模型的推荐方法取得了较为显著的效果,缓解了新用户冷启动问题,同时对于老用户该模型使用学习者存在的客观特征进行计算,解决了传统协同过滤单一评分计算的问题。
6 结语
本文提出的模型共分为两大部分,第一部分通过神经网络对用户进行预先分类,然后类内进行计算和推荐,缓解冷启动问题;第二部分对老用户类内多特征计算,解决了传统协同过滤单一评分特征计算的不足。经实验论证分析,本文模型可以较好地适用于数据量较大的场景。因此,学习者模型在大数据环境下教育资源推荐领域有一定的现实意义。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
电脑知识与技术(2022年11期)2022-05-31
中国药学药品知识仓库(2021年18期)2021-02-28
意林·少年版(2020年2期)2020-02-18
知识文库(2019年24期)2019-12-30
现代职业教育·职业培训(2019年6期)2019-10-09
华人时刊(2019年23期)2019-05-21
足球周刊(2017年27期)2018-04-16
足球周刊(2016年13期)2016-10-18
师道·教研(2016年5期)2016-05-14
