
基于社区发现的专利查询扩展方法*
2022-05-10 07:27:04陈高荣
计算机与数字工程 2022年4期
陈高荣 徐 建
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
专利文件是重要的知识财富,可以帮助保护个人,组织和公司的利益。专利文件具有巨大的研究价值,对工业,商业,法律和政策制定团体都是有益的。如果仔细分析专利文件,可以揭示重要的技术细节和关系,可以说明领先的技术趋势,可以启发新颖的技术解决方案,从而可以做出至关重要的投资决策[1]。
现有专利检索技术中的挑战如下:1)高召回率。专利检索是一项面向召回的任务,其目标是在现有的专利库中找到所有相关文档[2],检索的目的是保证创新理念与任何先前授予的专利之间不存在侵权。2)长查询。与查询非常短的Ad hoc查询和网络搜索不同,专利查询输入通常很长,甚至包括整个专利申请。3)用词含糊不清。申请人频繁使用了同义词和别名,常常使用不常见的非标准技术术语表达常见的语义,以保持专利权利要求的唯一性[3~4],这导致专利术语不匹配问题,使专利检索变得困难。因此,有效的专利检索仍然是一项具有挑战性和困难的检索任务。
查询拓展能很好地解决专利查询中术语不匹配的问题。现有的扩展方法大多是针对普通文档,如果直接将传统的信息检索方法用于专利检索的任务中,很难取得较好的结果。不同于普通文档查询扩展,专利本身是一种包含大量技术术语的半结构文档,并且包含大量复杂术语表达以及创造词。由于专利的特性和专利检索高召回率的要求,传统的查询扩展方法在专利检索任务中难以获取用户完整的查询意图。另外,在专利查询扩展过程中会不可避免地引入噪声词,出现主题漂移现象,导致查询召回率降低。
因此本文提出一种基于社区发现的专利查询扩展方法CD-PQE(Community Discovery Based Patent Query Expansion),该方法从专利文档集中提取专利词表,并构造对应的词网络,充分地利用了专利文档集中的专业术语和创造词之间的相关性,又通过社区发现算法构造稠密子图获得最终得扩展词集,丰富并拓展了查询词集,减少了噪声词的加入,防止主题漂移。通过实验验证本文方法与一些经典的方法相比在准确率和召回率有着的更优的效果。
2 相关工作
专利文件的表达往往比其他文件更加模糊和专业,在同一技术上使用不同的术语表示,这使得搜索相关专利变得更加困难。早期的工作中[7],采用的是基于主题的查询重构方法,但该方法不能很好的利用创造词导致结果准确率并不高。此外通过分类提高词与领域的耦合度的方法也被用于专利检索中,Wang和Qian等[6],提出一种新颖的复合域视角模型,该模型将查询专利的技术特征转换为特定的复合分类域并生成方面查询,加强了技术特征和技术领域之间的相关性。但原始的查询词对于用户查询的表达往往没那么全面。通过查询扩展可以有效地完善查询意图,以达到提高专利检索的效果。现有查询扩展的主要研究方法包括基于反馈的方法、基于词典的方法和基于语义的方法。
PRE模型是一种常见的基于反馈的查询扩展方法通过从初始搜索中排名靠前的伪相关结果中富集扩展词条来扩展查询词[8~9]。Martins等[10]将最新索引与带有外部语料库的PRF结合使用,可以检索更多相关文档并提高排名。但检索多针对某一专利领域,在不同专利领域域的信息差异较大,PRE未能很好地解决这个难题,而且PRE模型中常常存在着主题漂移现象。
基于词典的方法使用额外的词典作为拓展源进行词拓展,往往基于WordNet、Wikipedia等外部资源构建查询扩展[11~12]。许侃等[16]利用谷歌搜索引擎来替代词典将外部信息源作用于专利检索,虽然在检索准确率上有一定成效,但依然没有解决专利名词的特殊性的问题。但是对于某些特定的主题查询,这些方法的性能并不稳定,但仍无法满足专利检索的需求。
基于语义的方法在最大程度上保留查询中查询词相关的语义信息,通过语义关系选择与查询词语义相近的扩展词。El Ghali等[13]基于上下文提取了一种潜在语义索引方法;徐博等[14]提出了一种融合语义资源的生物医学查询,该模型分为两部分,首先通过伪相关反馈进行查询拓展,然后基于拓展词共现和MeSH词表两种方式加权对拓展词进行综合选择,最终完成拓展。这些方法能提高拓展词的有效性从而提高检索的召回率,但现有的基于语义的拓展查询中直接通过计算查询与扩展词的相似度来判断拓展词的有效性,忽视了扩展词的在扩展资源中的重要性,这个过程会引入噪声词出现在扩展词集中,影响检索结果。
3 专利自动查询扩展算法
专利检索中专利文本多以非结构化的形式存储在信息系统中,高召回率和准确率的检索入口可以更好地帮助用户获得完整且准确的检索结果。本文提出了基于社区发现的专利自动查询扩展方法模型。该模型主要分为两个模块:建立具有权重的专利词网络及基于稠密子图的社区发现算法。
3.1 建立具有权重的专利词网络
专利词网络是专利知识的一种图解表示,用节点表示关键词和概念,弧线表示关键词间的联系,本文首先从专利数据库中提取专利中的关键词,专利数据库中有文档D={d1,d2,d3,…,dk},对于每个文档通过TF-IDF获得每个文档的关键词Wi={wi1,wi2,wi3,…,win}将所得排名靠前的关键词汇总汇得关键词候选集W={w11,w12,…,win},再通过word2vec训练获得最终关键词向量矩阵H用于专利词网络中相似度权重的构建。
根据词向量表,构建一个基于关键词的无向图G=(V,E,W)来表示词与词之间的关系,其中节点集V={v1,v2,…,vn},n=|V|,表示由关键词构成的节点集;边集E中每条边ei,j对应V中一对顶点(vi,vj)之间的连接关系,m=|E|;W是G的权重矩阵,表示V中一对顶点(vi,vj)之间的相似度为边的权重。将所有专利文本中的关键词通过网络的方式联系起来更有利于词之间关系的发现与计算。
本文通过计算两个词向量的余弦值来判定两个词的相关度,计算方式如下所示:
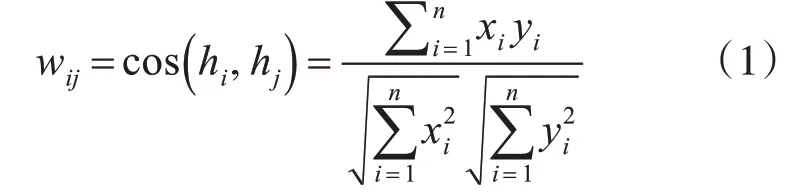
其中hi={x1,x2,…,xn},hj={y1,y2,…,yn}分别是关键词vi,vj的向量表示形式。
基于词向量相似度构建关键词网络算法如下:

3.2 基于稠密子图的社区发现算法
社区发现算法是指从复杂网络中发现并识别出这些网路中高度相关的对象组,这些组别被称为社区[18]。在本文首先构造关键词网络,根据边权重与词的网络拓扑结构相结合,作为社区发现算法的依据,发现识别与查询关键词高度相关的词,将这些词构成了扩展词集,其中这些扩展词集符合社区的概念。
本文提出了一种基于稠密子图的社区发现算法。首先将查询关键词Q={q1,q2,…,qn}作为种子节点为初始点,根据种子节点qi对子图的适应度函数将种子节点扩展为局部稠密子图;当所有的局部稠密子图构造结束后将子图进行合并获得最终关键词扩展集。
为了方便说明本文对局部稠密子图做了如下定义:局部稠密子图集为S={s1,s2,…,sn},其中si=(Vs,Es,Ws),si表示查询关键词qi作为种子节点获得的稠密子图,并且Vs⊂V,Es⊂E,Ws⊂W。
适应度函数是评价稠密子图稠密程度。假设s为图G的一个连通子图,Vs表示该连通子图的顶点集,Es表示其边集,其中ns=|Vs|,ms=|Es|;为获得一个完全图,需要在连通子图s中添加条边,将原关键词网络图G中边权重的平均值作为新添加的边的权重。通过原连通子图s和新添加的边的权重的差异作为评价s稠密度的评估函数f(s)。
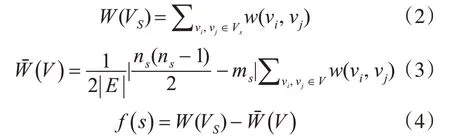
其中W(VS)为原连通子图的权重值,是新添加边的权重值,Vs为稠密子图的点集,w(vi,vj)为点vi,vj之间边的权重,E和V分别为关键词网络图G的点集和边集。显然如果函数f(s)越大,则子图s越稠密。根据定义若|Vs|=1,即s中只有一个节点f(s)=0。
对于节点v∉Vs,定义v对s的适应度函数:
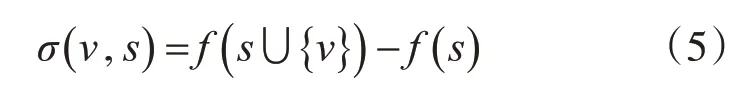
对于一个节点如果稠密度的适应度函数的值越高,说明这个节点与这个子图的关联性就越强,将满足σ(v,s>a)(平均稠密度阈值)的节点扩展到子图s中。
随着以查询关键词为种子节点的图集S={s1,s2,…,sn},并将其合并,去除子图中重叠的部分获得包含扩展词的子图DS。但随着词节点的加入可能存在距离查询关键词Q中某一种子节w*点较远的节点w也会加入到子图中,这个过程会导致噪声词的出现在子图S中。因此同时还设置了距离函数D(w),对节点与种子节点的距离进行限制。
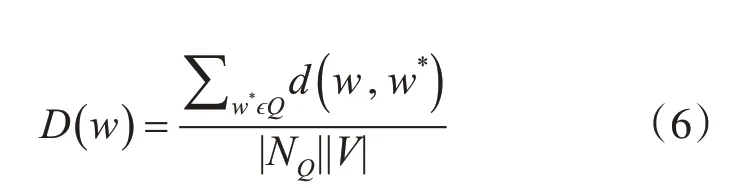
其中d(w,w*)表示节点w到w*的最短距离,其中|NQ|为查询词集的数量,|V|为关键词网络中关键词的数量。当D(w)≤d时(d表示距离阈值)可以有效地避免噪声词的干扰。
算法2基于稠密子图的社区发现算法

如图1所示为部分查询关键词网络子图的示例,假设初始查询词集为Q={w3,w7,w10},所以需要找到包含节点w3,w7,w10的稠密子图。以q1=w3的例首先初始化其扩展子图s1此时Vs1={w3},在关键词网络G中依次找到节点w2,w4,w5,w6,并计算对s1的适应度函数σ(v,s1),并判断σ(v,s1)>a,如果满足则加入图s1中,最后计算得Vs1={w1,w2,w3,w4,w5,w6},分别得到w7,w10对应的扩展子图s2,s3,其中Vs2={w6,w7,w8},Vs3={w9,w10,w11},将子图s1,s2,s3合并获得图DS,最后判断DS中得节点与查询词集Q中得节点的距离将D(w)>d的节点删除,减少扩展词集中得噪声词。
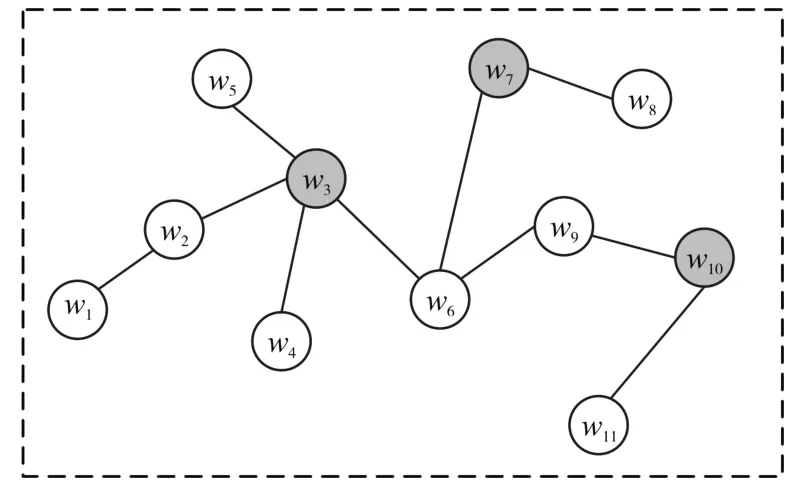
图1 部分查询关键词网络子图
4 实验
4.1 数据集
专利数据集:在本文研究中使用的数据集是CLEP-IP 2010专利数据集。CLEP-IP 2010包含1985年至2001年之间发布的260万份不同的专利文件,并具有标题,摘要,描述和权利要求。在本文的实验中,使用了CLEP-IP 2010的英文小节,共计2000条查询。
4.2 实验评价指标
为了进行评估,本文使用召回率(Recall),平均精度(Mean Average Precision,MAP),专利检索评估得分(Patent Search Evaluation Score,PRES)量化实验结果。
召回率:检索到相关专利与所有相关专利的比率。
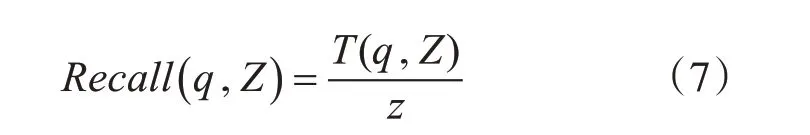
T(q,Z)表示查询q检索结果中排名前Z的相关文档的数量,z是指专利库中相关文档的数量。
平均精度(MAP):它是所有测试专利的平均精度的平均值。

其中Rjk是从检索到排名前k个的检索结果的集合,如果检索列表中未出现相关文档,则精度值为0。
专利检索评估得分(PRES)[19]:是基于召回的专利检索的另一种有效评估指标,可以综合测量召回率和排名质量。

其中ri为检索第i个相关文档的等级,N表示集合大小,n为相关文档的数量,R为召回文档中相关检索文档的数量。
4.3 参数选择
本节主要对实验中的一些参数的设置和选择过程进行讨论,本文方法参数包括构造专利词网络的相似度阈值s、稠密子图的平均稠密度阈值a和距离阈值d。本节在参数评估指标选择召回率和PRES。
图2给出的是构造专利词网络的相似度阈值s对检索性能的影响,在相似度阈值s=0.5的时候PRES达到最优解,当s=0.7时召回率最优,根据性能变化将相似度阈值设置为0.5。
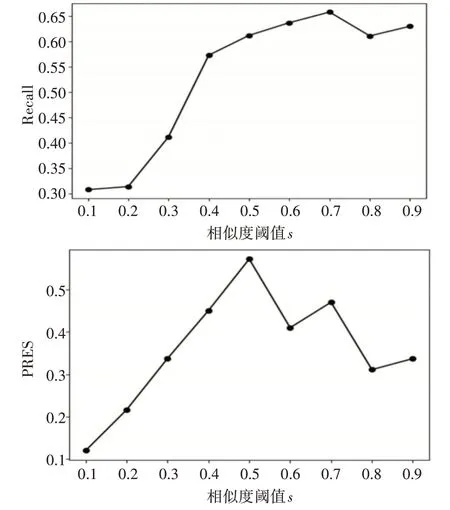
图2 相似度阈值s对检索性能的影响
图3给出的是稠密子图的平均稠密度阈值a对检索性能的影响。从实验结果可看出在召回率和PRES值上,当a取0.6时检索性能最佳。
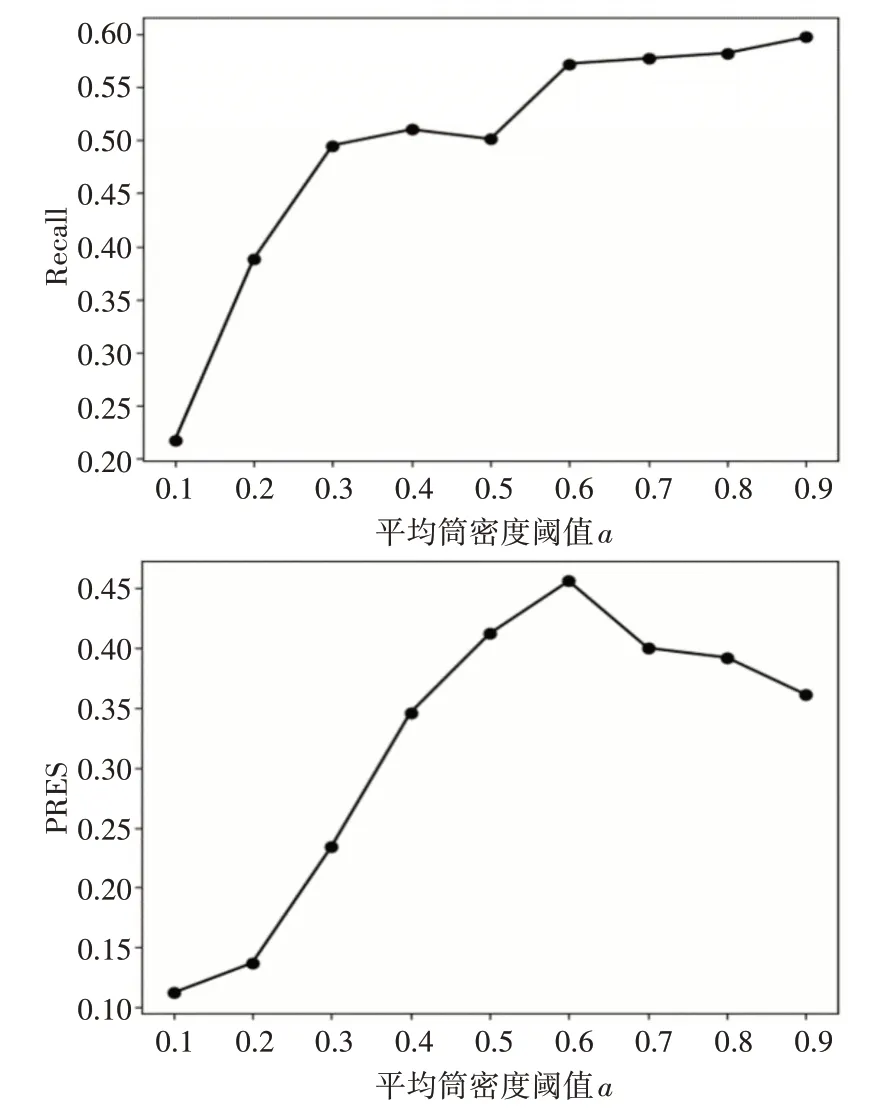
图3 平均稠密度阈值a对检索性能的影响
图4给出的是稠密子图的距离阈值d对检索性能的影响。距离阈值与最终的扩展词集的数量有着强联系。从实验结果可以看出当d取值为0.35时在两种评估指标上取得均衡值。因此最终将距离阈值设置为0.35,从图5可查此时平均扩展查询词为70个,检索性能达到最优。
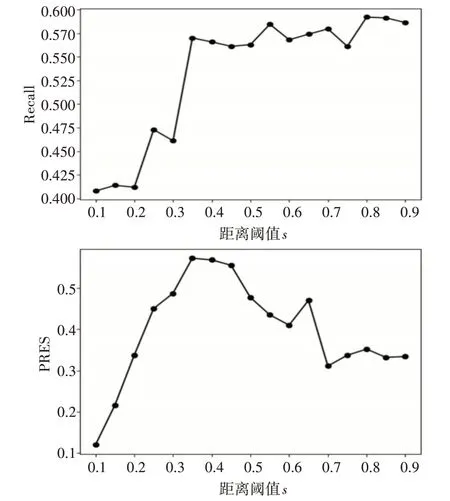
图4 距离阈值d对检索性能的影响

图5 距离阈值与最终平均扩展词数量关系
4.4 基于社区发现的专利查询扩展方法效果
本节基于CLEP-IP 2010大型专利数据集进行实验,实验中对比方法有:语言模型检索(Language Model,LM),词依赖模型检索[15](Term Dependency,TD),相关模型查询扩展(Relevance Model,RM)以及基于聚类的查询扩展模型(Cluster-base Model,CM)。本文选用的相关模型查询扩展是伪相关反馈,基于聚类的查询扩展方法则是通过K-means聚类选择扩展词。实验结果如表1所示。
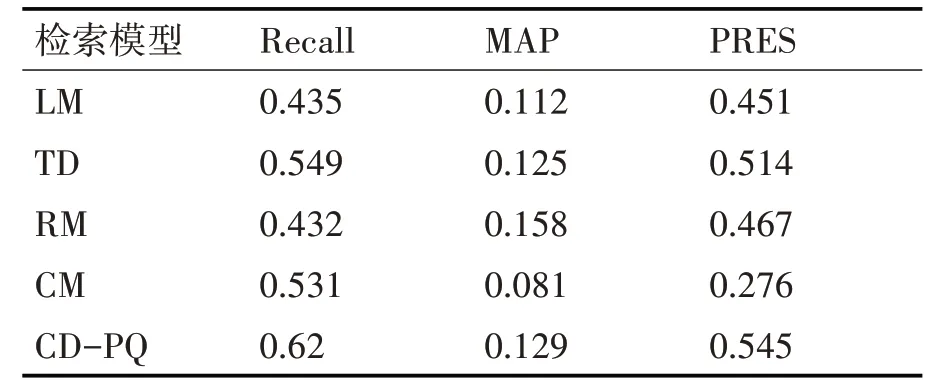
表1 基于CLEP-IP 2010数据集检索结果
从表中实验结果可以看出在召回率和PRES方面CD-PQ取得最优值;而在MAP方面未能取得最优值,是由于专利名词存在特殊性,扩展一些与查询专利描述相近但未用于专利中的相关术语,从而降低大多数相关专利的排名。上述的结果说明,CD-PQ能有效的改善并提升现有检索的性能,特别是在召回率和PRES上表现良好,这是因为本文通过社区网络中图发现的方式判断词节点是否属于同一类别,能够更大程度地覆盖高质量的扩展词,减少噪声词加入到扩展词集中;其次该方法是在专利数据集上构建的专利词网络,这能很好地解决专利中出现的创造词无法用于检索中的问题,使得检索更具针对性。
5 结语
本文探索了基于社区发现的专利自动查询扩展方法,以帮助分析人员尽可能多地找到所有可能相关的文档。本文首先从专利数据库中获得专利领域关键字词库,然后通过词库构造关键词网络,然后通过社区发现算法获得扩展词集。通过对专利文件集合的评估证实了本文方法的有效性,能够有效地提高专利检索的准确率和召回率。未来工作方面会在本文的基础上对文本相似度比较进行优化,进一步探索出提高专利检索性能的综合方法。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
信息安全研究(2016年4期)2016-12-01 06:06:54
电子科技大学学报(2016年2期)2016-08-31 02:50:00
专利代理(2016年1期)2016-05-17 06:14:36
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:50
电脑迷(2012年4期)2012-04-29 06:12:13
采矿技术(2011年5期)2011-11-15 02:53:12
