
基于卷积网络的灰度图像自动上色方法
2022-04-08 03:42张美玉刘跃辉侯向辉秦绪佳
计算机工程与应用 2022年7期
张美玉,刘跃辉,侯向辉,秦绪佳
浙江工业大学 计算机科学与技术学院,杭州 310023
近年来,随着深度学习的发展,许多传统算法难以解决的问题有了突破性的进展,灰度图像上色就是这其中的一种。同时灰度图像上色分为两种:一种是需要提示的上色[1];另一种是灰度图自动图像上色,上色过程不需要人工干涉。Deshpand等[2]在2015年用CNN结构实现了上色网络,证明了灰度图像自动上色这一问题可以得到有效解决。
灰度图像自动上色可运用在历史资料修复、老照片上色等有意义的工作上。与使用传统图像处理软件相比,基于深度学习的灰度图自动上色可以显著的减少人力成本,为人们节约大量的时间和经济成本【3】。
须指出的是,现有的大部分算法虽然可以生成符合自然感的图片,但是建立在大量的训练上,且模型体积都偏大,不利于部署。本文设计了一个基于不同尺度的空洞卷积[4]堆叠结构的与one-hot编码的灰度图自动上色网络,简化了编码过程,并使用传统的高斯卷积处理one-hot编码生成最终结果,提升了最终上色效果。从实验结果来看,实现了一个上色结果较好、易于训练的灰度图自动上色网络。
1 相关工作
1.1 使用端到端的CNN上色网络
这一类方法主要以L2范数的均方误差作为损失函数,如下所示:
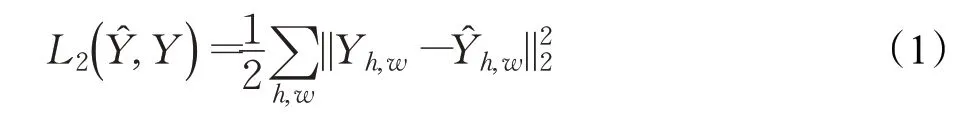
再添加其余的损失函数作为辅助,从而构建的网络。在上色任务中,大多都使用L2损失函数的方法,具体的流程为:给定输入的L通道,学习到相应AB通道的函数:y=f(x)。上色网络本质上也属于分类网络,只是将各种不同的颜色作为标签,不同于传统的少量标签分类网络[5]。
Iizuka等[6]使用了复杂的使用了一个非常复杂的CNN网络,由一个高级特征提取网络,一个低级特征提取网络,一个分类网络,一个特征融合网络,一个上色处理网络组成。色彩编码使用了LAB,使用了交叉熵作为分类损失函数,最终的着色效果损失函数则使用L2的均方误差。文献[6]的方法可以更好的结合空间特征,提升了最后的上色效果。但是由于网络结构复杂,所以网络收敛所需时间很久,原方法使用一块K8连续训练了2周。
Despande等[2]使用了一个结构相对简单的CNN网络,并在L2损失均方误差的基础上,加上了一个直方图。Cheng等[7]使用了一个结构相对简单的CNN网络,并使用了联合双边滤波器结合均方误差函数。
1.2 基于GAN网络的灰度图自动上色方法
DCGAN由Radford等[8]提出,是基于GAN[9]做出的改进,在生成器和判别器中,特征提取层用卷积神经网络代替了原始GAN中的多层感知机。GAN中的生成器(generator)和判别器(discriminator)来往的博弈,最终达到纳什平衡,GAN多用于图像生成一类的任务。DCGAN可以用于人脸表情识别[10]、数据增强[11],图像转换等任务,也可以用于图像自动上色。本文通过DCGAN构建了一个上色网络。
由于判别器还不足以让生成器有上色效果,所以在生成器中加上L2范式的均方误差修正上色结果。由于鉴别网络的存在,最终的效果细节较为真实,比使用端到端的CNN网络上色效果更好。
1.3 使用one-hot编码的灰度图自动上色方法
Zhang等[12]使用了VGG[13]作为主干网络,将LAB空间编码分割成Q=313块。将输入图片作为Y,并定义一个one-hot生成函数:Z=(Y),最终每一个像素上色的结果为选取313块中的一种。每次训练选取邻近像素邻近的5块,并按照空间距离加权,距离越短,权值越大。定义背景平衡函数v(Z h,w),通过统计ImageNet[14]数据集中所有的图片颜色出现的概率。按照颜色出现的概率决定上色的概率,其中,出现的概率越小,颜色越稀有,反向传播的梯度越小,得以保留更加丰富的颜色。得到最终权重编码后,生成的One-Hot与网络生成的结果做比较。最终的损失函数为:
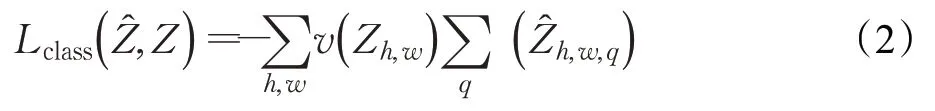
最后引入参数T=0.38,让one-hot中每一个数值除以T,使最后的颜色饱合度更高。
1.4 小样本自动上色方法
Yoo等[15]提出了一个带记忆增强的关色模型Memo-Painter,可以捕获稀有实例并成功着色,可以在较小样本小取得相对可以接受的上色效果。此方法的核心是通过一个类似HashMap的记忆网络,具体做法以记忆空间为key,以颜色为value。使用索引和余弦相似度处理key;使用Zhang等[12]的one-hot编码格式。
2 本文方法
本文设计了一个新的CNN网络,依靠堆叠不同尺寸的普通卷积和空洞卷积,以及上采样、Dropout[16]、1×1卷积[17]构建了一个CNN上色网络。同时本文的网络设计为全卷积[18]网络,可以处理任理任意尺度的图片,本文的体积也控制的比较好,在实验部分也会列出体积对比。本文的结构图如图1所示。
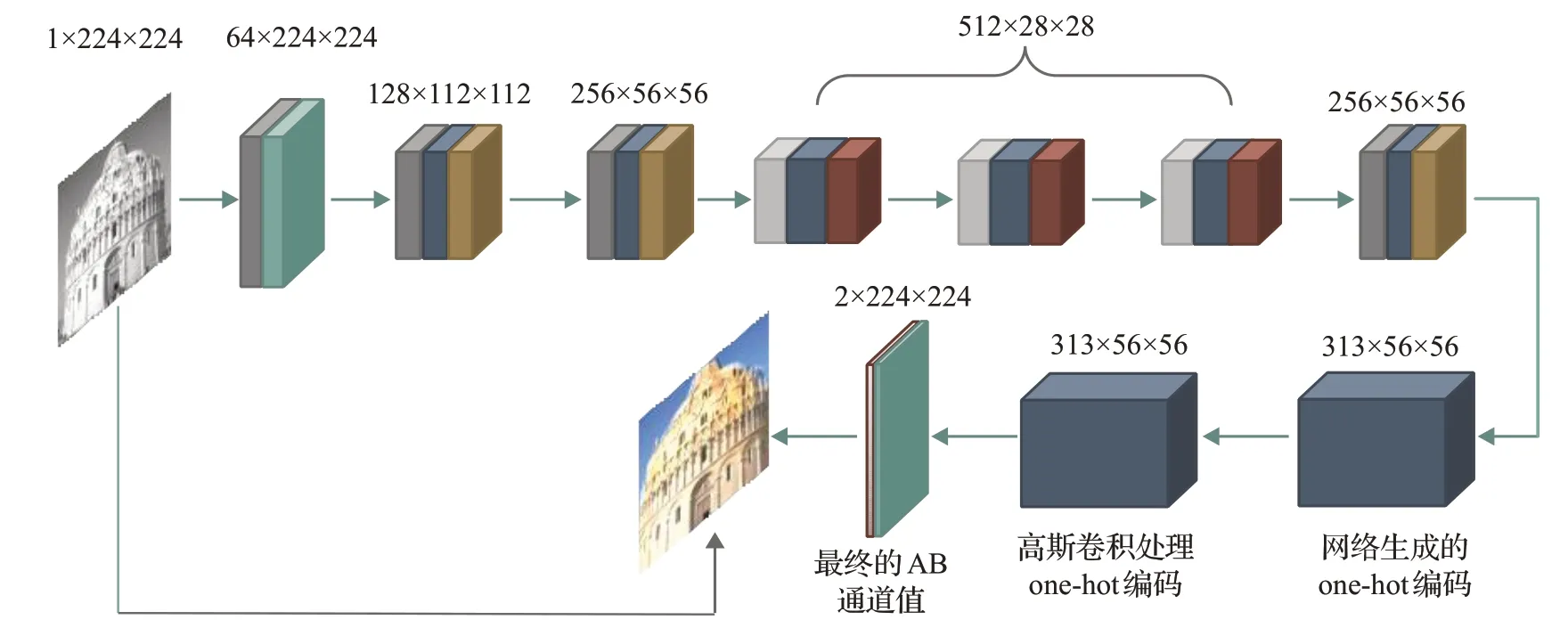
图1 网络总体结构图Fig.1 Overall diagram of network architecture
图片的编码格式采用LAB,主要有两个原因:因为人眼对彩色并不是很敏感,而对亮度敏感,所以使用Lab空间处理图片[19],观感上要比传统的RGB好;如果用LAB格式,那么只要输入1个通道预测2个通道,比采用RGB的输入3个通道预测3个通道更容易训练。L通道代表亮度,A代表从红色到绿色,B代表从黄色到蓝色,A、B都在[ ]-128,128之间。L的亮度通道即是灰度图,已经包含了图片语义信息。从Iizuka等[6]的实验可以看出,使用亮度去预测颜色比传统的RGB更有优势。
本文的损失函数受Zhang等[12]方法的启发,将搜索策略作了调整,在最后的编码阶段使用了高斯卷积,代替了最后使用模拟退火思想得出的用于优化分类权重的阈值。最后使用比Adam[20]效果更好的AdamW[21]进行训练。AdamW则是在Adam的更新策略中采用了计算整体损失函数的梯度来进行更新,而不是只计算不带正则项部分的梯度进行更新之后再进行权重衰减[22]。
2.1 算法流程
(1)将原图O从RGB转成LAB,并取L通道作为Ol。
(2)将原图O的ab通道编码成width/4×hi eght/4×313的向量O h。
(3)取Ol作网络输出的AB通道编码的one-hot结果R h。
(4)使用交叉熵计算两个one-hot向量R h、O h的误差,并反向传播修正误差。
(5)训练结束,对输出的one-hot编码R h使用高斯卷积进行处理。
(6)转换one-hot编码R h为真实的AB通道值Ra、Rb,并将R a、R b的尺寸采用扩大4倍。
(7)取原图的L通道Ol并加上生成的R a、Rb两个通道,以生成最终的上色结果。
2.2 基于one-hot编码解码的设计
一个物体可以有若干个合理的颜色,只要这若干种颜色符合人的认识,就作为可以接受的解,故L2损失函数的功能仅是将数据集中出现的解取平均值作为最优解。经过一定量的训练之后,网络可以根据特征识别出物体,由于使用了L2损失函数,神经网络会拟合每一个训练数据。比如存在各种颜色的绿植:深绿与浅绿。为了拟合所有的数据,神经网络就会取一个深绿与浅绿的中间值,作为绿植的上色颜色。体现在最终结果上,画面整体偏灰,颜色不丰富。比如:房屋大多是同样的偏黑的棕色,绿植多大是相同的绿色。如图2所示,用L2函数的上色网络会尝试拟合各种特征的树木,取训练集中各个树木颜色的平均值。最终,对新的灰度图像进行上色时,绿植的颜色就会是一个非常平淡的绿色。这样的上色结果虽然也符合人类的认知,但是最终的效果并不理想。所以这种损失函数无法解决着色问题的多解问题。一个上色良好的上色网络应该避免这个惟一解问题,所以本文选择基于one-hot编码的操作函数。
图2 L 2损失函数上色效果展示图Fig.2 Visual display of L 2 loss function coloring effect
在相关方法中,Zhang等[12]的方法是唯一一种不使用L2上色方法的结果,虽然相比L2损失函数多出了编码图片与解码图片的过程,并且最后一层分类会显著的增加网络的体积,但是最终的上色结果大幅度优于采用均方误差的方法。所以本文选择沿用Zhang等[12]的思路:将图片编码成one-hot编码,再使用选用基于分类的损失函数进行着色。
2.2.1 图像编码
本文方法的采用Zhang等[12]的量化方法:将AB通道的输出二维空间以10的步长量化为一维313类,并组成键值对,一组A、B对应一类颜色。
本文方法将图像编码的具体流程为:先将图片尺寸缩小至原来的1/4,再取所有点的AB值,并使用KNN的ball tree算法仅搜索一个最邻近点,直至所有点都搜索完成。
最后得到的张量为最终的one-hot编码,大小为:313×width/4×height/4,将L通道输入网络,预测AB通道的one-hot编码,再将one-hot编码转成真实的AB值。
2.2.2 图像解码
如果直接使用每个像素预测而得到的颜色,大部分区域下可以得到符合语义的颜色,但是在小部分区域内,会出现颜色在空间上不连续的现象,比如在同一个区域内的一小块会出现与语义信息不符合的颜色,这样非常影响最后的上色结果。所以图像解码不是图像编码的逆操作。
造成这种现象的原因是本文的核心方法就是将一个像素的上色问题作为313类的分类问题来解决,而每一次的分类结果不会总是正确无误。这就导致有时预测的结果会出现一些异常的分类结果,理想的分类结果为:一个像素如果预测成湖蓝色,那么必然在淡蓝色,深蓝色都会存在相对其他颜色相差不大的权值。但是真实的结果是同时也会有一些异常点出现,这个异常颜色的权值会比较高,甚至高于正确颜色的权值,而这个异常颜色周围的颜色权值又非常的低。Zhang等[12]采用了基于模拟退火的思想去解决这一问题,具体的作法为在softmax分布中引入参数T,然后取结果的平均值。这样的缺点是要不停的尝试参数并且每一次修改网络结构都需要去寻找一个合适的T值,而且并没有对画面有什么过大的影响。
一个固定的T值,仅是将神经网络预测的每一个权值放大1.47倍,使用的交叉熵函数让一些本来无法选中的权值得以选中。经过多组图片试验,加上T值处理的图片会略微改变图像的色调。可能对某一些上色结果有优化的作用,但是无法优化所有的上色结果。所以使用T值有一定的局限性,本文不选用T值优化结果。
在图像解码这一部分中,文本使用传统图像处理中的高斯卷积,作为滤波器处理预测的颜色权值。解决突然出现的异常颜色点,以在最终结果上尽可能消除不符合语义的颜色出现。
高斯卷积的常用于图像模糊中,然而高斯卷积是一种数据平滑技术,可用于多个场合。高斯卷积将正态分布用于数据平滑中,高斯卷积核使用高斯函数生成。
高斯函数就是正态分布的密度函数。一维形式为:
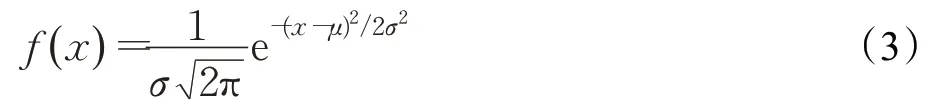
根据一维函数可以得到二维函数:
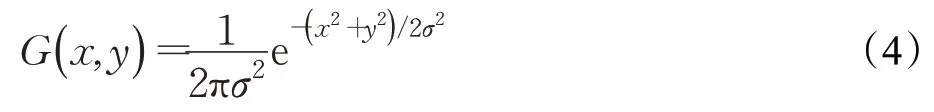
假设中心点的坐标为(0,0),距离它最近的8个点的坐标,范围为:x∈[-1,1],y∈[-1,1],取σ=1.5,得到权重矩阵:

然后计算9个点的加权平均,得到本文最终使用的高斯卷积核:

对于那些异常预测值,即在最后的313类的周围权值都很低,但是本身的权值很高,这样的值通常不会是正解,但是通过使用高斯卷积处理后,那些预测的值很高,将会进一步地强化权值,那些本身权值很低的值,会变得很加的低。所以这样可以进一步的削减异常权值。在最终的实验结果中,也证明了效果的提升。本文方法中对σ的取值并没有特殊的要求,因为高斯卷积拥有数据平滑的功能,使用高斯卷积可以平滑最终one-hot编码。最后使用的交叉熵函数,会选出一个权值最大值并以此选择分类,所以σ的选取对最终的图片结果影响非常微小。
2.3 网络构建
本文的网络结构设计上参考了VGG系列的堆叠卷积结构,并在此基础上加入了1×1卷积、Dropout[16]、不同尺寸的空洞卷积堆叠等结构组成文本的网络。最终组成了一个体积相对较小、上色效较好的深度神经网络。
本文的网络结构在开始使用了3个堆叠结构,之后,经过上采样放大特征。采用了一对VGG上广泛使用的3×3卷积堆叠并进行升维。在本文的网络中,将最后的通道数放大,最高到512,最后一层缩减成313进行分类,最后若干层的卷积均为1×1卷积。下文将对为何使用上文中提到的网络基础结构做逐一说明。
2.3.1 堆叠卷积
VGG结构上使用了很多个卷积堆叠,具体做法是将两个3×3的卷积层串联,相当于1个5×5的卷积层。3×3堆叠卷积首次出现在VGG的结构上,相比于传统的大卷积堆叠,多个3×3结构相比单个5×5的卷积核的优点为以下两点:
(1)拥有相同的感受视野与更小的运算量。运算量的对比如表1所示。

表1 卷积参数表Table 1 Convolution parameters
2个3×3的卷积可以代替1个5×5的卷积的感受野;3个3×3的卷积才能代替1个7×7的卷积的感受野。
2个3×3和1个5×5的参数比例为3×3×2/(5×5)=0.72,同样的3个3×3和1个7×7参数比例为3×3×3/(7×7)=0.55,使用小卷积堆叠可以减少近一倍的参数量,所以选择多个小卷积核代替大卷积核。
(2)与使用多个卷积层比单个卷积层相比,还拥有更多的非线性变换。单个卷积层只能使用一个激活函数,而后者可以使用多次激活函数,使用多个卷积堆叠可以提升对特征的学习能力。
视野变化的过程如图3所示:顶层为特征,初始为1×1,第二层为经过一层卷积之后,视野的变化为3×3,第三层为再次经过一层卷积之后,视野的变化为5×5。
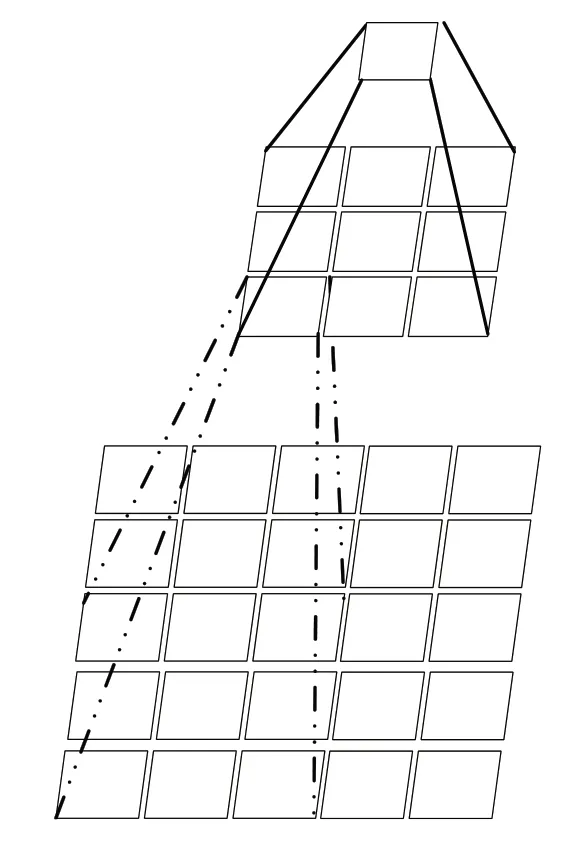
图3 卷积堆叠示意图Fig.3 Convolution stacking diagram
在卷积堆叠基础之上,本文使用了不同参数的空洞卷积进行堆叠。
如果将上图的普通卷积替换成空洞卷积,那么感受视野将进一步扩大,空洞卷积的感受野会随着空洞的数量变化
本文的空洞卷积堆叠使用了两种不同的尺寸,如表2所示。

表2 空洞卷积参数Table 2 Dilated convolution parameters
通过空洞卷积的视野计算公式:
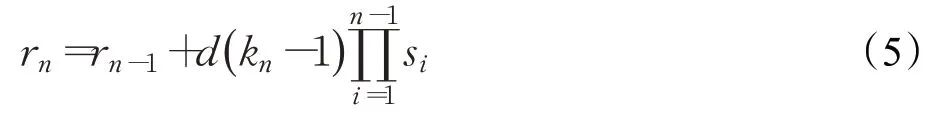
其中,r n来表示第n个卷积层中每个单元的感受视野,k n、s n分别表示第n个卷积层的卷积核尺寸与步长。根据表2的配置参数得出使用本文所使用空洞卷积感受视野为:9×9。
2.3.2 1×1卷积
本文在最后需要降维的位置使用1×1卷积以减少参数量并减少模型体积。为了进一步缩小网络体积且尽可能的不增加运算量,最后生成one-hot编码的部分也采用1×1卷积。
2.3.3 Dropout
Dropout是会按给定的比例,随机将给定比例的神经元权值置0,虽然会降低每一次训练时的效果,但是随着训练次数的增加,会提高整个网络的性能。经过实验的权限,本文方法中选定的权值为0.1,并放置在即倒数第二个卷积层。此卷积层用于最后生成one-hot编码,即此卷积层有10%的概率会失效。
本文使用Dropout并不是为了防止过拟合,而是为了使模型泛化性更强。原因主要有两个:
(1)因为它不会太依赖某些局部的特征。因为Dropout程序导致两个神经元不一定每次都在一个Dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其他特定特征下才有效果的情况,迫使网络去学习更加鲁棒的特征。
(2)因为Dropout会随机丢弃一部分权值,剩余的权值需要利用已读到的特征输出结果去适应这一情况,这样增加了网络整体的性能。
2.3.4 通道数的限制
本文的网络设计目标以体积小为导向,所以尽可能不过多地增加通道数。使用更宽的通道数可以增加网络的表达能力,以提高网络的整体性能,但是网络模型体积及参数也随之上升。为了达到相对较小的体积和相对好的性能这一目标,只在中间及偏后的位置加入通道数偏大的网络。通道数最多为512,此通道在同类网络中已然很大,过大的通道数也没有意义,反而徒增运算量。
2.3.5 上采样
相对的,反卷积也可以起到相似的作用,但是反卷积容易出现棋盘效应,且本身就作为卷积层需要参数[21]。使用上采样可以不用训练就达到增大特征的效果,更适合本文算法。
本文的网络结构如表3所示。

表3 网络详细信息Table 3 Network details
其中,除最后一层外,激活函数采用了ReLU,最后一层的激活函数使用softmax分类生成one-hot编码。这两个激活函数是目前比较常用的激活函数。
在此基础上,如果再加卷积层(升维)时,在空间占用量上,即模型大小上,根据通道数C的大小,及神经网络默认使用的Float32类型,增加Cin×Cout×32字节的空间占用。运算量上,即显存占用上,在不同的位置,根据特征图的大小、通道的多少,对运算量也会有较大影响。如果改变通道数,只会对本层及下一层增加或减少相应数值的空间占用量及显存占用量。同时因为批数量的关系,会进一步的影响运算量。一般来说,常见的网络都会在两端设计选择较小的通道数,并在中网络中间选择较大的通道数与较小的特征图。本文方法也遵循这一经验。
经过大量的调整各个参数,本文采用了表3的参数。如果再加上几层卷积层(升维),对上色结果没有特别大的影响;如果再此基础上再减少若干层,网络将不能很好地进行上色工作。
3 实验与分析
3.1 实验环境
本文方法在Windows 10操作系统上进行。显卡为RTX 2070S 8 GB显存,CPU为AMD Ryzen 2 400G,内存为16 GB DDR4。软件环境为:深度学习框架Pytorch 1.5[23]、Python 3.7、CUDA 10.0,数据集采用Place 365中的室外风景部分。包括楼宇、小屋、山水、庭院等50多个类别大约30万张256×256分辨率的图片。本文方法的优化方法是AdamW,Epoch为10。对比算法严格按照相同的数据集进行训练,且训练的Epoch同样为10。
3.2 模型对比
本文算法将与DCGAN,Zhang等[12]的方法作对比,采用一样的数据集,一样的训练轮数10,并动态地调整批数量使其充分利用8 GB显存。
3.2.1 上色评价
由于上色的最终效果难以用数学的方式衡量,因为着色时颜色越丰富,最终的损失越大,但是最终的效果是可接受的。图4、图5展示一些实验效果的对比,其中图4为彩色照片的重着色效果,图5为黑白照片的上色效果。

图4 彩色图片重上色Fig.4 Colorful image recoloring

图5 黑白图片上色Fig.5 Gray image coloring
从彩色图片重上色(图4)效果来看,经过本文方法上色的图片颜色更加丰富,对细节的处理以及光影效果也比其余算法更好。DCGAN的效果总是偏暗,Zhang等[12]的算法有一些地方语义不到位,图4的C组图山脉处,D组图的建筑部分出现了绿色,E组图的路面一片绿色,F组图的树木也是绿色;本文算法除了在E组图中没有识别出地面,其他几组图片效果都相对较好。
在图5所示的黑白图片上色中,本文方法的语义性较好。在图5的A组图中,本文方法的颜色生动,对天空的还原较好,Zhang等[12]的算法总体也较好,但是天空还原不准。DCGAN则较为平淡,在B组图中,本文算法在树叶与天空的缝隙处上色效果较好。在D组图中,对建筑的上色更加的准确,而Zhang等[12]的算法则偏绿,E组图也是同样的情况。在F组图中,本文算法对地面的彩色着色相对准确,而Zhang等[12]的算法可能将地图看成了海洋。DCGAN的几组结果上色效果均过于平淡。
3.2.2 其他参数对比
网络中的参数如下所示:通过表4的数据可知,由于DCGAN没有使用one-hot编码,在速度上占据一定的优势,但是由于存在鉴别器,同时训练两个网络,体积和训练时显存都占用较多,所以批数量较少,难以训练。从体积大小与批数量来看,本文方法有较大的优势。

表4 不同模型的性能对比Table 4 Performance comparison of different models
4 结束语
本文使用了基于分类思想的上色网络,提出一个使用传统高斯卷积的编码器,并使用空洞卷积堆叠的结构组建的CNN网络,不仅获得了相比于采用L2损失函数更为鲜艳的效果,并且采用一系列方法在保证上色效果的前提下缩小模型的体积。通过在自然图像数据集上进行的实验,所提出的方法可以进行效果良好的上色,与其他方法的结果相比,在最终的上色效果与体积控制上均具有优越性。
猜你喜欢
高技术通讯(2022年7期)2022-09-28
成都信息工程大学学报(2022年3期)2022-07-21
北京航空航天大学学报(2022年6期)2022-07-02
小学生学习指导(中年级)(2021年12期)2021-12-30
天津医科大学学报(2021年1期)2021-01-26
汉字汉语研究(2020年2期)2020-08-13
中国信息技术教育(2020年2期)2020-02-02
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
计算机与数字工程(2018年5期)2018-05-29
