
数据增广策略在英语语法纠错中的应用综述
2022-04-08 03:40孙晓东杨东强
计算机工程与应用 2022年7期
孙晓东,杨东强
山东建筑大学 计算机科学与技术学院,济南 250101
语法错误是英语学习者常犯的错误之一,其主要包括拼写错误、主谓一致错误、名词形式错误、动词形式错误、时态和冠词错误等。随着自然语言处理技术的不断发展,语法错误纠正(grammatical error correction,GEC)的方法也在不断创新。早期GEC的研究方法以基于规则和基于统计的模型为主[1-2]。随后出现了基于机器学习分类的方法[3]、基于语言模型的方法[4]和基于机器翻译方法[5]等。基于翻译的方法又衍生出基于统计的翻译模型[6](statistical machine translation,SMT)和神经机器翻译模型[7](neural machine translation,NMT)。相比于基于规则和分类的GEC方法,基于语言模型和机器翻译的数据驱动方法取得了显著的应用效果,并逐渐成为主流的GEC方法,但是此类模型的最大挑战是人工标注的训练数据不足的问题[8]。在面临数据稀缺的情况下,人工合成的训练数据对解决标注训练语料的匮乏显得尤为重要。
GEC是通过分析输入句子成分之间的依赖性和逻辑性,将可能含有语法错误的句子作为输入,在不改变语义的前提下将其转化为语法正确的句子。GEC系统纠正示例如下:
Input:Travel by bus is exspensive,bored and annoying.
Output:Travelling by bus is expensive,boring and annoying.
模型输出的最佳纠正结果需要将数据优化[9-10]、模型优化[11-12]与输出优化[13-14]相结合,主流的英语语法纠错系统结构图如图1所示。其中针对数据进行优化[15]产生了诸多转移学习和领域自适应学习等策略[16]。迁移学习可以解决真实语料不足的问题,而领域自适应学习是利用与GEC任务相似的合成数据,通过预训练的方式使模型获得较好的泛化能力。目前为止,针对英语语法纠错领域数据增广方法的文献十分缺乏。该文首先介绍GEC领域使用的数据集和评测GEC系统不同的指标,其次介绍在标注训练数据匮乏的情况下,如何人工合成训练数据,之后分析了GEC领域应用现状。最后对未来利用数据增广方法提高英语语法纠错性能、使用数据增广的必要性进行了展望与总结。
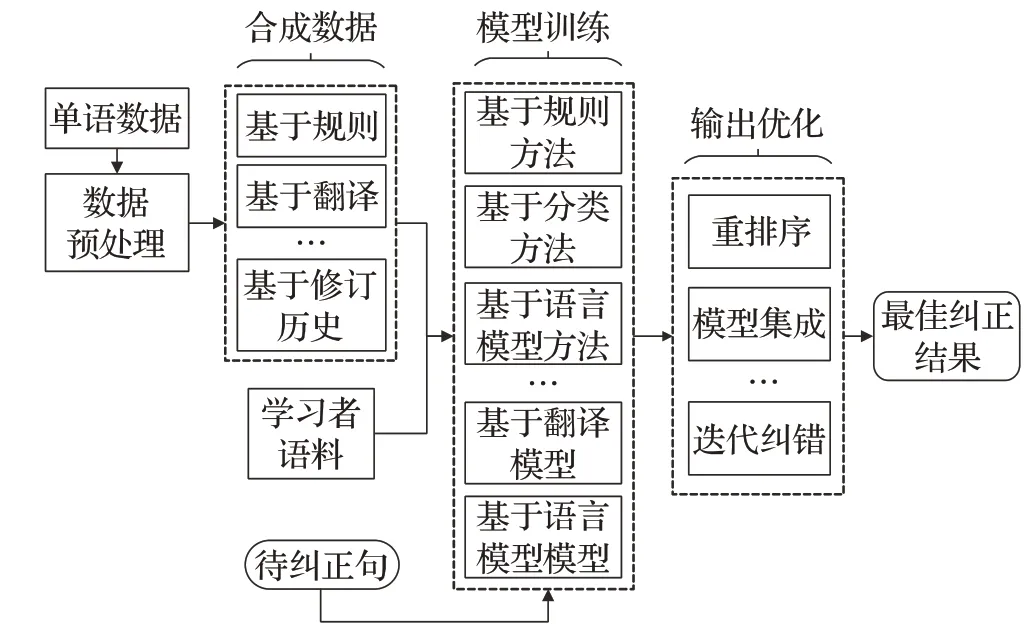
图1 主流英语语法纠错系统结构图Fig.1 Structure diagram of mainstream English grammar error correction system
1 GEC相关介绍
1.1 GEC公开语料库
最近深度学习在语言处理方面取得了重要突破,但GEC仍然是一项具有挑战性的任务,其部分原因是语法错误类型的多样性、语境中共存的多个错误之间语义的依赖性和人工标注数据的稀缺性。人工标注错误文本,将会消耗大量成本。GEC领域的语料库包括单语语料库和学习者语料库。学习者语料库是由“错误-正确”句对构成,质量高,但是数据量较少。单语语料库种类繁多,数据量大,通常使用单语数据人工合成训练句对,将其用于机器翻译系统或其衍生任务。现有公开可用的GEC语料库是有限的,在大规模的注释数据下GEC系统将会取得良好的纠正效果。现有的公开学习者语料库如表1所示。其中,标注者数量为对文本中的错误进行标记、纠正的人数;参考数是错误修改的候选参考数量。
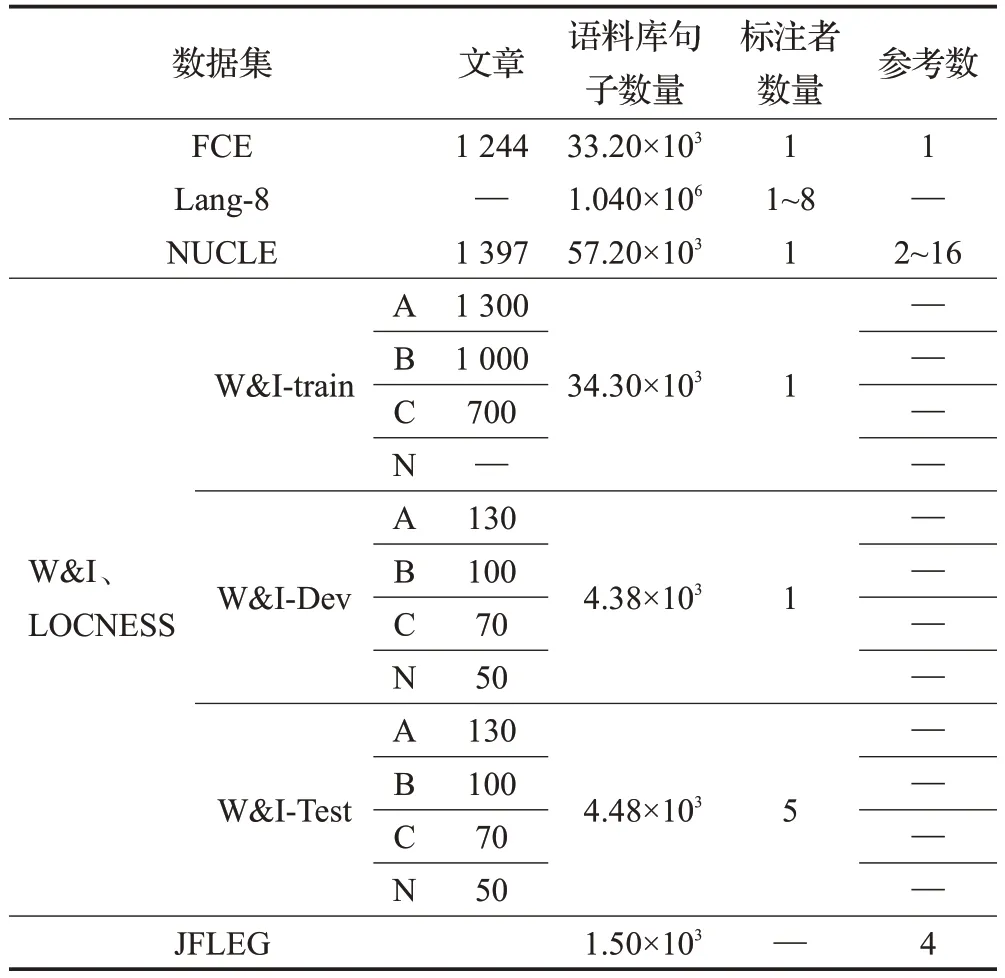
表1 学习者语料Table 1 Learner corpus
1.1.1 GEC学习者语料
(1)FCE语料库
剑桥学习者语料库(Cambridge learner corpus,CLC)收集了全世界不同母语的学习者参加剑桥大学作文考试的语料,其容量大,是一个商业性的学习者语料库。CLC中的文本从Upper Main Suite Examinations中选取,背景信息非常全面。CLC方便词典编撰者检索、查找学习者用得好的单词、句式和语法结构,或者利用语料库发现学习者的学习难点。另外,CLC还应用于书面作文的机器阅卷和评分软件的开发。FCE(first certificate in English)语料库[17]是剑桥学习者语料库(CLC)的子集,其中包括了1 244篇出现在FCE考试中的书面答案,包括了7种错误类型,9种母语类型。
(2)JFLEG
JFLEG是用来评测GEC系统的常用测试集,包含747个句子,开发集包括764个句子,由约翰霍普金斯大学(JHU)提供,此语料库用来评测句子的流利程度。英语语法纠错不仅仅是对不同错误类型的纠错,最终的目的是达到符合人类思维习惯的母语表达的程度。此语料库仅在句子级别上进行标注,并没有在词粒度层面上进行标注。JFLEG测试集使用GLEU评价指标[18]。
(3)Lang-8学习者语料库
Lang-8是一个在线的英语学习网站。鼓励学习者相互纠正自己的错误,它将用户在学习过程中的外语写作文章,交给以此种外语为母语的国人批改。用户自身也可以修改其他国人所写的文章。网站提供需付费的高级服务,可以保存历史文章、优先在网站上显示自己的作文等。Lang-8学习者语料库[19]是从此网站爬取的部分语料,包含80多种语言和大量的“错误-正确”平行句对。Lang-8语料库的英语语料嘈杂,没有明确的标注规则。此语料库为GEC公开预料库中最大的一组[19],包含了200万条句子对。
(4)NUCLE语料库
NUCLE(National University of Corpus of learner English)数据集[20]是新加坡国立大学(NUS)标注的英语学习者语料库,它包含了国立大学大学生撰写的1 400篇论文,主题涉及到环境污染、医疗保健等不同方面。该语料库由专业英语教师进行错误注释,用于对GEC系统的训练与性能评测,是第一个提供错误注释并且可以免费使用的学习者语料库。其中,共包括27种错误类型,比例最高的5种是Wcip(搭配错误、短语错误、介词错误)、Rloc(冗余错误)、ArtOrDet(定冠词错误)、Nn(名词单复数错误)和Mec(格式错误)。5种错误类型注释数量占所有注释数量的57.83%。
(5)W&I+LOCNESS语料库
BEA2019共享任务[21]中,发布了两种新的数据集。分别是CEWI(Cambridge English write&improve)数据集和LOCNESS数据集[22]。W&I+LOCNESS语料库包括了来自CEWI的3 600篇带有人工注释的文章和来自LONCESS的100篇注释文章。
CEWI是英国剑桥大学研究员研究出的一个在线的英语学习系统。众多的学习者可以通过该系统进行英文书面语的在线纠错。通过输入需要纠正的源语句,系统会及时、自动给出每句话的修改建议并对其合理性评分。CEWI数据库是由英语测试试卷中的文本组成,这些文本来自148种不同语言的母语学习者。
LONCESS语料库是由一些以英语作为母语的学生撰写的论文组成。语料库的每一条注释数据有一个特殊的标记区分不同英语学习者的英语水平:A(初级,beginer)、B(中级,intermediate)、C(高级,advanced)。
(6)GMEG Wiki和GMEG Yahoo
近年来,GEC评测数据集主要由非母语的英语学习者所写的论文组成,当测试集迁移到其他领域,GEC的系统可靠性便无法评估。GMEG数据集[23]是以英语为母语的学习者所写的句子组成,包括了来自3个不同领域的GEC系统对该数据产生的纠正结果进行人工评级。GMEG Wiki是基于维基百科修订历史编辑而设定的语料库,GMEG Yahoo是由雅虎的Web邮件中收集的答案组成,GMEG FCE是为FCE语料库建立的新的错误标注。
(7)AESW
AESW[24]是科学写作的自动评估共享任务automatic evaluation of scientific writing的测试集,但没有广泛使用。
(8)CLEC中国英语学习者语料库
中国学习者语料库包括了5种英语水平学生产生的英文语料,涉及中学英语、大学英语、大学四六级英语、专业英语低级和高级等层面,对其包含在内的多种言语失误进行标注,将言语失误共分成61种类型。此语料库还统计了失误的频数、占比,最常见的失误类型,最常见的拼写失误单词汇总等等。
1.1.2 单语语料库
单语语料库可以帮助模型进行预训练,建立一个初始化良好的英语语法检测与纠正系统。通过预处理、人工数据集合成等操作,模型可以充分利用一些非人工注释的数据集来缓解训练数据不足的问题。如今存在许多高质量的英语语料库,比如One-billion word benchmark[25]、Gutenberg语料库[26]、Tatoeba语料库[27]和维基百科语料库[28]等。
(1)one-billion word benchmark
one-billion word benchmark是一套基准语料库,数据集由康奈尔大学在2013年发布,数据来源于网页,凭借近10亿单词规模的训练数据,该测试基准可以快速评估新的语言建模技术。
(2)Gutenberg
古腾堡工程(project Gutenberg,PG)是由志愿者参与、收集、整理的电子化资料,是一个电子文学图书馆,收录包括德语、法语、意大利语以及中文在内的不同语言著作。而Gutenberg语料库[26]是古腾堡工程语料库中的一个子集,包含142位作者的若干篇英、美著名作品,语言风格偏书面语,约1.2 GB。
(3)Tatoeba
Tatoeba语料库是为机器翻译发布的一个新的基准语料库,该基准包含多种语言和用于从该数据集中创建最先进机器翻译模型的工具,当前版本包含超过500 GB的压缩数据,涵盖555种语言。该数据集提供了并行语料和单语语料,其中单语语料来源于Wikimedia中的公共数据,为数据增广方法提供数据来源支持。
(4)维基百科
Wikipedia是一个基于维基技术的在线百科全书,以多种语言编写,超过4 700万页。Simple Wiki与通常的Wikipedia相比,只使用大约1 500个常见的英语单词,这使得信息在语法和结构上更容易理解。
1.2 GEC语料的预处理
数据增广(data augmentation)可以看作是一种对训练集数据的预处理方式。为了提高数据的质量,在进行数据增广、模型训练等任务之前需要对数据进行清理,比如使用Lang-8数据[29]之前,需要对训练数据进行清理,数据清理过程中可以使用moses[30]官方提供的处理脚本,脚本提供标点的规范化,控制有效句子长度,需要大写的地方进行转换、保留等。常见的处理方法包括:
(1)去重。训练过程中,大量重复的数据使得训练结果有一定偏差,可以将完全相同的句对清除。
(2)去空行。对于训练文本中的空行,不会为模型的训练提供任何信息。
(3)特殊符号处理。确定特殊符号列表,对于含有特殊符号的语句对删除特殊符号或者直接删除该语句对。
(4)长度控制。语句对的长度影响模型的训练,长度太短的句子可能对模型的训练没有帮助;长度太长的句对,在送入模型之后需要对句对进行拆分截断处理。
(5)Tokenize操作。SentencePiece、WordPiece是两种tokenization的方法。扫描一遍训练文本后构建一个词表,通过词表对输入的文本进行tokenize。tokenize就是对文本进行分词并对词语的数值化;tokenize操作同时完成了对英语句子和标点的切分。
(6)全半角转换。对于训练文本中的全角符号需要转换成半角。
(7)标点的正则化。英文语料库中不应该出现中文的标点符号,需要将中文的标点符号转换成英文。
(8)Truecase。将每个单词中存在的大小写形式转换成原本的写法。
1.3 GEC评价指标
近年来英语语法纠错在自然语言处理领域取得重要突破,产生了多种对GEC系统的评测方法。评测方法通常将输出序列与黄金标准序列(人工标注的目标句)进行比较,比较过程中需要将输出的原句和目标句进行词对齐。GEC评价指标的发展趋势如图2所示,先前GEC模型的性能只通过精确度度量,后来M2、I指标的产生,通过召回率衡量GEC系统,现如今GLEU、ERRANT错误工具包的产生,使评测结果更加公平。不同评测指标对比如表2所示。
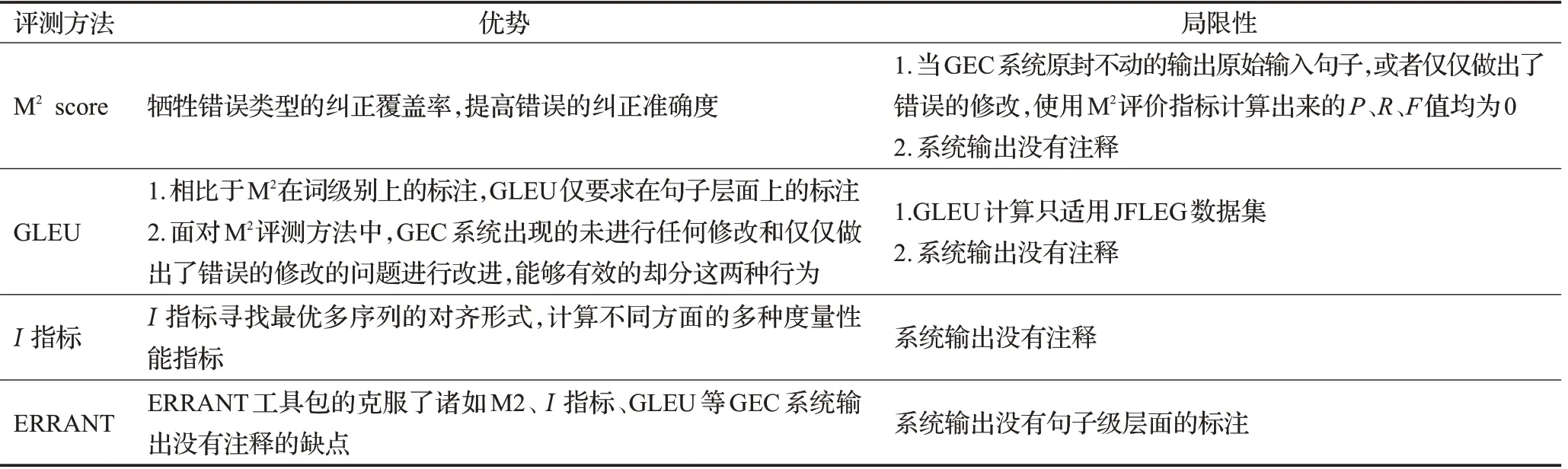
表2 GEC评测指标优缺点对比综述Table 2 Comparison of advantages and disadvantages of GEC evaluation indicators
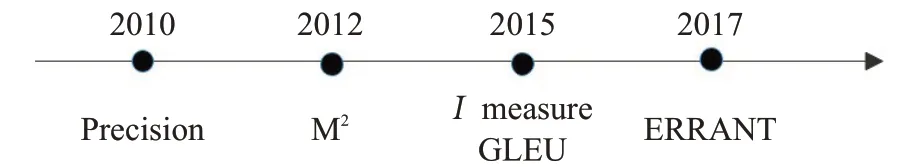
图2 GEC评价指标发展趋势Fig.2 GEC evaluation development trend
1.3.1 最大匹配分数
最大匹配分数[31](max match score,M2score),计算的是模型的输出修改和标准修改在字、词或短语级别的最大覆盖,是评估英语语法纠错模型常用的评测方法。此度量方法首先将GEC系统输出的纠正句与人工标注的标准句进行单词对齐,采用基于Levenshtein距离的对齐策略,计算将一个句子转换成另一个句子后所需要的单词基础上的编辑(插入、删除、替换)数,以精确度、召回率、F值评估系统。
1.3.2 GLEU
Napoles等人[18]提出GLEU(generalized language evaluation understanding)评价句子的流利度,这是BLEU[32]的一种变体。原始输入的错误语句简称源句,人工标注修改的句子称为参考句。GEC系统输出的纠正句子为假设句。计算假设句相对于参考句的N-gram精度,并对假设句中本改纠正却没有被纠正的N-gram进行惩罚。
1.3.3 I指标
I指标[33]在源句、系统输出和参考句三者之间应用基于标记(token)级别的多序列对齐优化算法。与M2不同的是此方法为错误检测和纠正都提供了相应的分数。此方法定义了一种特殊的格式:每个句子都包含注释和可能的修改,一个句子可以包含零个及多个错误。每个可以选择的候选纠正必须是互斥的。
1.3.4 ERRANT
ERRANT[34]语法错误注释工具包,从源语句和纠正后的句子中提取编辑数量,并对错误类型进行分类,有助于不同类型错误级别的评估。该工具使用Felice等人[35]提出的源句和修正句之间的对齐算法,然后为提取的编辑使用基于规则的错误类型框架分配错误类型。框架与数据集无关,仅依赖于自动获取的如词性标记等信息。
2 数据增广策略
使用足够多的无错误数据通过噪声函数对其注入噪音,然后将合成的训练数据用于模型的预训练,由此提高了GEC模型的性能。对于不同数据增广的方法、不同语料库所属的风格及其对不同风格的语料库进行合并时如何进行优化以至于获得更好的预训练模型等,均未生成共识。使用不同风格的语料库、不同的数据合成方法、不同的数据集规模等均对模型的结果产生不同的影响[36]。GEC面临的挑战包括数据集的领域适用和低错误密度下将产生更低的精确度。同时,不同的错误概率分布、错误密集程度、错误的种类、语料库所包含的语义变化都会影响到GEC系统的性能。相比于语言学习领域的数据集,使用其他领域数据集训练过的监督系统对于语法错误纠正可能没有效果,还有可能表现出较低的精度。这也表明先进的纠错系统偏向使用较高错误密度的数据集[26]。
对于一个低资源的机器翻译任务,机器翻译的加噪方法通常根据种子语料库得出的错误频率分布,使用随机的替换、取代、删除、插入等规则引入错误。但是,适合机器翻译的噪声函数不一定适合GEC。英语学习者常犯的错误类型中,发生单词顺序的错误概率比发生其他类型的错误概率都要低。因此,不同的数据增广策略不断提出,合成的训练数据质量也在不断提高。有学者提出通过反向翻译的数据增广方法以此来充分利用单语数据,但是高质量的训练句对往往耗费大量的劳动力,如何人工合成更加接近人类真实情景下常犯的英语错误对提高GEC模型的性能至关重要[37]]。初次之外,为了提高合成数据的质量,往往引入合成数据的质量控制。不同数据增广方法间的优缺点基合成示例,如表3所示。
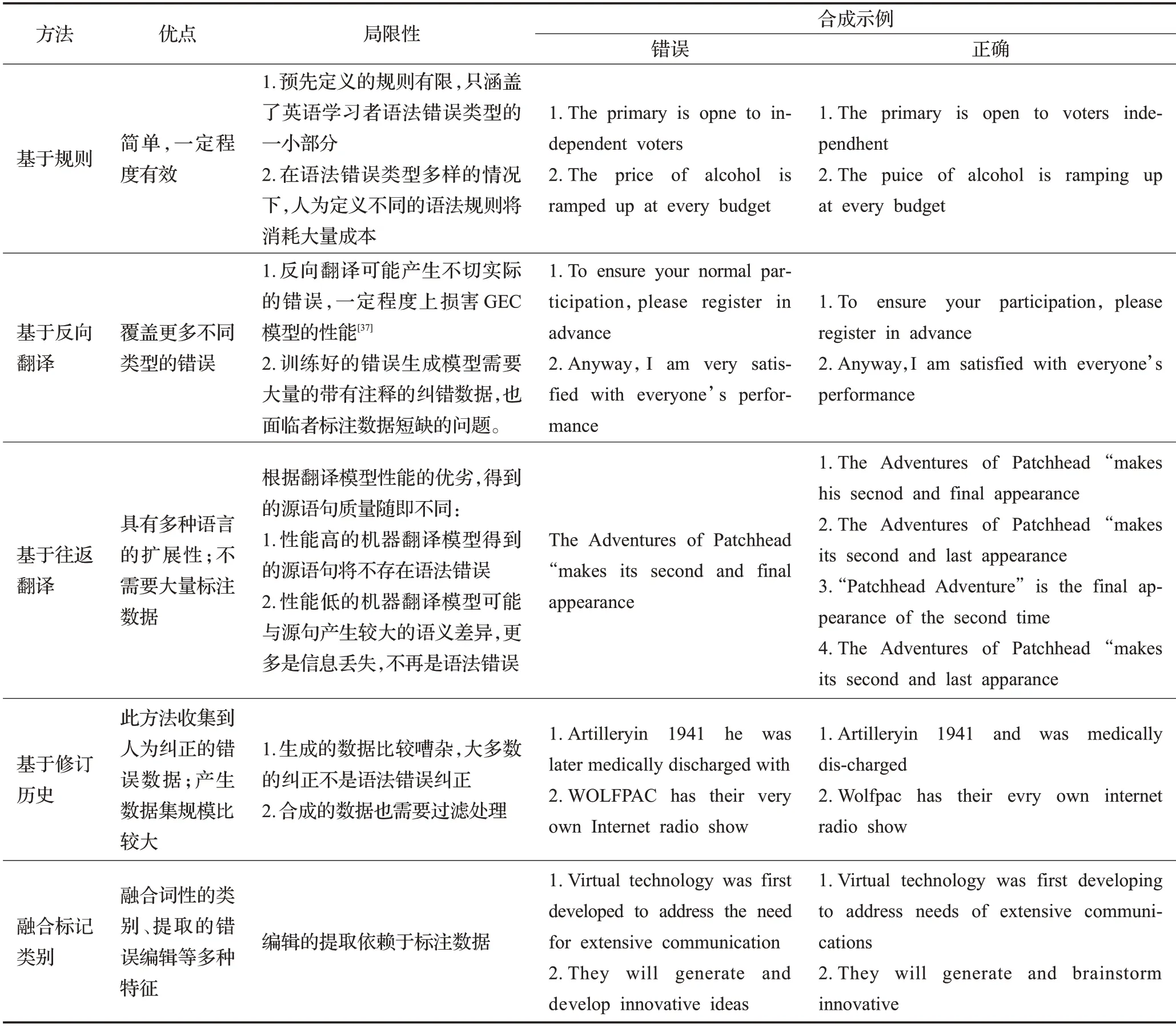
表3 不同数据增广方法优缺点对比及合成示例Table 3 Comparison of advantages and disadvantages of different data augmentation methods and synthesis examples
2.1 基于概率的数据增广方法
2.1.1 基于规则的数据增广方法
基于规则的数据增广方法是使用限制性的语法规则针对特定语法错误对数据进行处理,其成为提高数据质量的一种重要手段,使用特定的限制性规则在数据清理和数据合成任务中也具有重要意义。人为规则不限于增加、删除、取代、交换及其相应的衍生变种,以此更加精确的生成标记(token)级别的错误,插入、删除、交换可以在token级别和chatacter级别上进行操作,越来越多的工作面向替换规则,与简单的从词表中随机挑选单词进行替换,融入拼写混淆集和同类型不同词性单词的替换,提高了模型的性能,如图3所示。对于特定的、不易生成的语法错误,在自然语言处理领域中使用人为限制性的规则进行逻辑性的处理从而弥补此缺陷。

图3 基于规则的数据增广方法示例Fig.3 Examples of rules-based data augmentation methods
使用特定规则进行单语语料处理的方法很多,以一定的概率删除、增加语句中的标记(token),对选中的单词从词典中随机的选择一个单词进行替换及其进行单词与单词之间、单词内部的重排序操作[38]。使用基于规则的数据增广方法过程简单,但是预先定义的规则有限,比如使用“选中的单词”与“临近的单词”进行替换,这样有点欠缺,因为词序错误发生的概率比名词单复数、冠词、动词时态等错误发生的概率小得多,只涵盖了英语学习者语法错误类型中的一小部分。也可以使用手动创建的规则,通过改变量词、生成复数形式单词、插入冗余的限定词来扩大训练数据[39],将句子转换成不符合语法规范的语句,然后使用合成的训练数据训练基于短语的SMT系统进行语法错误纠正。例如:
规则1much→many:much advice→many advice
规则2some→a/an:some advice→an advice
规则3advice→advices:much good advice→many good advices
将特定的错误类型生成固定的模板,使用预先定义好的错误类型引入模板作用于单语语料库人工生成训练数据[40],也是用于GEC领域处理数据的方法之一。
2.1.2 融合标记、类别的数据处理方法
加单的使用人为定义的规则将语法错误注入到单语数据,一定程度上改善GEC的性能[37],但是引入的错误并不接近英语学习者产生的真实错误。将人为定义的规则与单词的词性、形态相结合,将会更加接近英语语法纠错数据集中的真实错误。
在基于标记和基于类别的加噪方法中[41],引入英语学习者最常犯的错误。基于标记的方法首先从学习者语料中提取人类的编辑和频次。通过构建的含有常见错误编辑的字典,随机的将错误编辑应用于语法正确是句子。基于类别的噪声方法,不会改变原始单词的类别,比如更换不同的介词、名词单复数、动词时态等。Yuan和Felice[42]从NUCLE学习者语料库中提取错误标记应用于单语数据,从而进行训练数据的人工合成。
2.2 基于翻译的单语数据处理方法
2.2.1 基于反向翻译的数据增广方法
基于反向翻译的数据增广方法,其思想是训练一个反向模型(错误生成模型),以正确的句子作为输入,输出涵盖语法错误的原句。Sennrich等人[9]首次提出反向翻译模型,将反向模型的输入与束搜索的输出作为训练句对来增加平行训练语料的数量。方法还包括训练反向模型并在集束搜索过程中加入噪音来合成伪数据[43]。基于反向翻译的数据增广方法能够覆盖不同种类的错误类型,但是训练性能高的反向翻译模型往往需要大量的带有注释的纠错数据,也面临着标注数据短缺的问题。反向翻译模型输出时不能保证系统输出的句子中已经注入错误,因此需要进行句子的“质量控制”:结合外部的语言模型,将低于源句概率的输出句子与源句构成“错误-正确”句子对用于训练。
还可以使用基于贪婪搜索策略的反向翻译模型解码生成合成数据[44],分析表明通过取样生成的数据比集束搜索或贪婪搜索生成的合成数据将会产生更高的性能。在此之后基于反向翻译的变体模型出现。Kiyono等人[36]将反向翻译数据用预训练,并通过直接注入噪声的方法,对句子中的每个标记执行随机的掩码、删除、插入和保持不变操作来人工合成训练数据。
Zhou等人[45]提出利用性能不同的机器翻译模型合成训练数据。首先,使用神经机器翻译模型生成高质量的翻译语句。其次,使用基于短语的统计机器翻译模型生成低质量的翻译语句。将单语数据中同一个句子的不同质量的翻译作为训练句对。实验结果表明,使用合成的数据训练无监督的GEC模型可以获得理想的性能。
Yuan和Felice[42]从NUCLE学习者语料中提取标注错误的所有可能编辑将其应用于标记(token)和词性标注两个方面(标记:has→have,to be used→to be use;词性标记:NN→NNS,DT NNP→NNP)。在注入人为错误过程中,token模式优先于词性标注模式,使用合成的训练数据集训练多个基于短语的统计机器翻译模型(phrase-based statistical machine translation,PB-SMT),选择性能最好的进一步完善提高。
2.2.2 基于往返翻译的单语数据处理方法
基于往返翻译的数据增广方法,其思想是训练两种机器翻译模型,一种为英语翻译到非英语的桥语言的模型,另一种是非英语的桥语言翻译到英语的模型。源语句是单语数据,往返翻译生成的是目标语句。使用往返翻译合成的伪数据体现多种语言的可扩展性,并且不需要大量的标注数据,但是根据翻译模型性能的优劣,得到的源语言的质量也随即不同。性能高的机器翻译模型得到的源语句将不存在语法错误,性能低的机器翻译模型结果产生很大的语义差异,可能改变语句原本的表达意思,导致更多的信息丢失。
2.3 基于修订历史的数据增广方法
NMT不适合低资源的任务,因此需要大量的合成数据弥补差距。维基百科提供了所有维基百科修订历史的页面。不同的页面包括的数据量也是不尽相同,从页面中提取连续的数据作为“源-目标”句子对。其中源句是较旧的连续修订历史页面提供,目标句是对应较新的连续修订历史页面提供。使用最小过略的启发式算法从维基百科编辑历史中提取训练句子对[46],从而生成大规模的语料库。与往返翻译相比,此方法生成的数据相对嘈杂。Zhou等人[45]从维基百科的修订历史中提取修订的错误编辑合成训练数据,使用此方法可以收集到人为的修正错误编辑,更加接近英语学习者在学习过程中常犯的英语语法错误。但是大多数的纠正不是语法错误修正,并且合成的数据需要经过过滤处理。
2.4 其他数据合成方法
Felice等人[47]首次利用语言信息推导错误发生的概率。实验过程中,分析了一组对于适合错误注入的文本非常重要的变量,包括主题、题材类型、风格、文本的复杂程度等。结果表明牺牲精度可以提高召回率,不同的语言信息影响不同类型的错误纠正。
2.5 不同数据增广方法系统表现对比
从应用特定的学习者语料库到如今使用数据增广方法合成的训练集,GEC性能逐渐的提高。本文按时间顺序整理了常见的基于数据增广方法的GEC模型性能上的对比,如图4所示[10,14,41,43,45-46,48-65]。
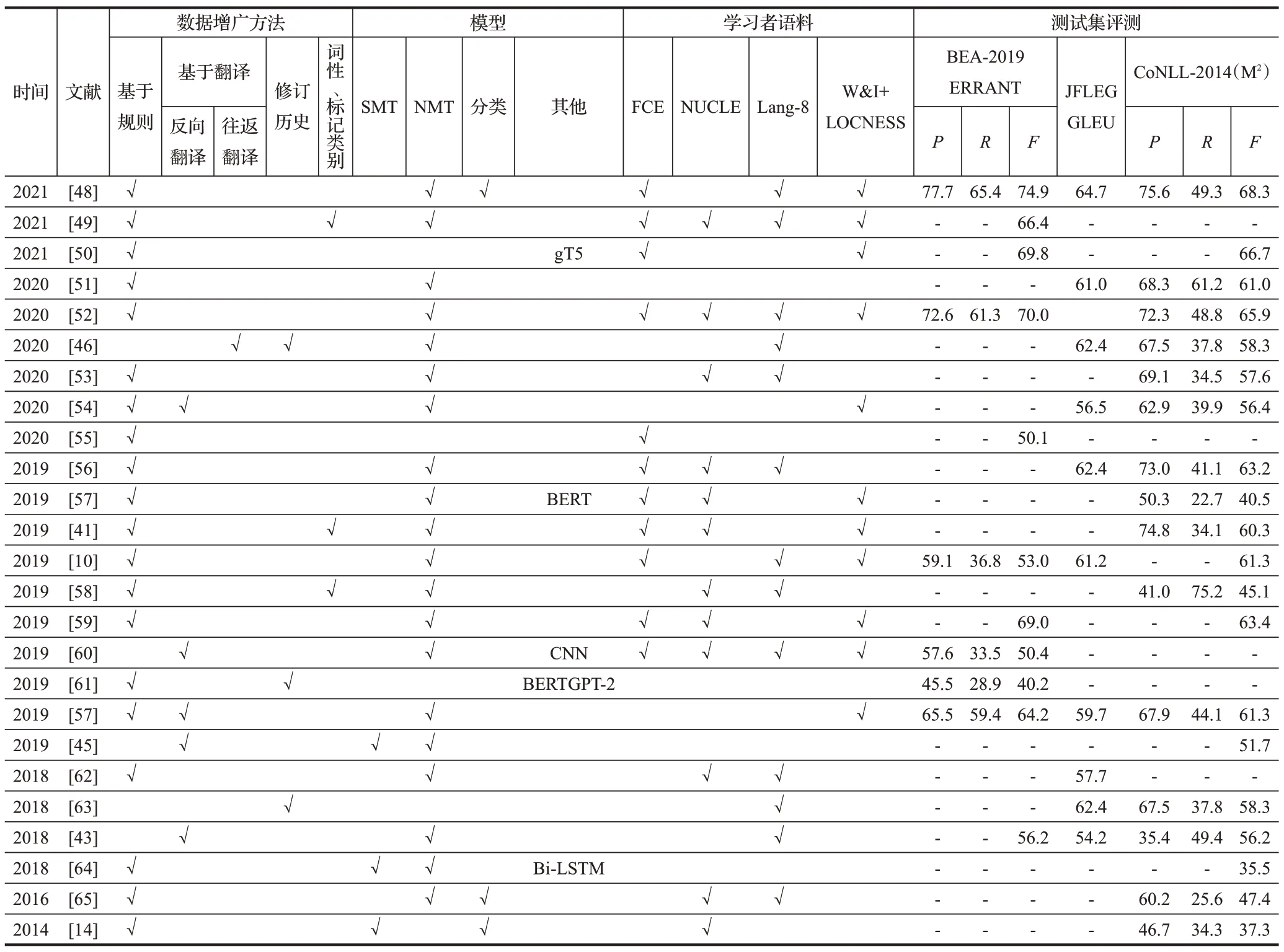
图4 数据增广方法的系统表现Fig.4 System performance using data augmentation methods
3 GEC领域应用现状
与早期的基于规则、分类、语言模型等英语纠错方法相比,目前GEC任务的主流应用是采用基于机器翻译的方法。本文从基于统计的机器学习方法与基于深度学习的英语语法纠错方法两方面详细介绍GEC领域应用现状并对其优缺点进行对比。不同GEC应用现状的优缺点如表4所示。
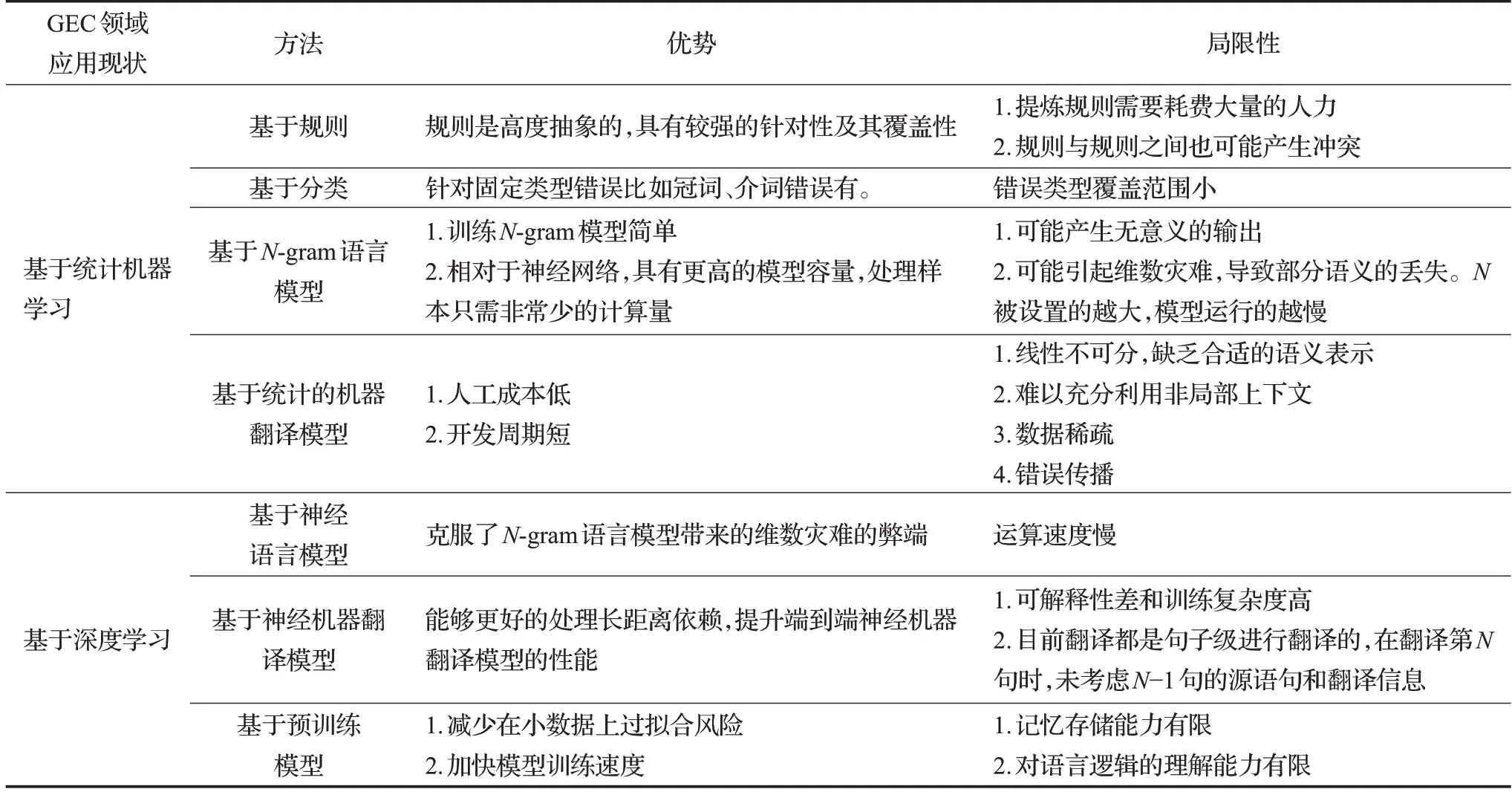
表4 GEC领域应用现状优缺点分析综述Table 4 Summary of advantages and disadvantages of application status in GEC field
3.1 基于统计的机器学习
3.1.1 基于规则
基于规则[1]的最典型GEC方法就是将语言知识总结、抽象,以特定的形式存储。在纠错过程中,结合待纠正的输入,选择相应的规则性知识进行推理或变换。规则包括源语言的分析规则、源语言内部表示形式向目标语言内部表示形式的转换规则,以及目标语言的内部表示转换为目标语言的规则。
3.1.2 基于分类
基于分类[3,65]的英语语法纠错方法主要将纠错任务视为分类问题,早期主要针对冠词和介词错误。其主要思想是人工进行特征选取,对每种语法错误类型标记不同的分类标签,比如冠词,可以分为a、an、the、没有冠词4种情形,分别标记0、1、2、3标签。分类器通过特征对目标单词进行预测,目标单词最可能的预测结果作为最终的分类输出。例如,Felice等人[66]通过提取18个定冠词和13个介词的上下文特征进行训练,最终冠词和介词的纠正精确度分别达到70.6%和92%,取得了良好的效果。
3.1.3 基于N-gram语言模型
许多GEC应用基于语言模型[67],语言模型定义了关于自然语言中的字、字符或字节序列的概率分布。N-gram是一种基于统计语言模型的算法,基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度为N的字节片段序列。每个字节片段为gram,对所有gram的出现频度进行统计,并按照事先设定好的阈值进行过滤,形成关键的gram列表,列表中的每一种gram为一个特征向量的维度。N-gram模型最终按照前N个词语预测当前的词语。
3.1.4 基于统计机器翻译
统计机器翻译[6]是一种参数学习方法,统计翻译模型利用实例训练模型参数,其本质是带参数的机器学习。因此,模型适用于任意语言对,也方便迁移到不同应用领域。
其中,基于短语的统计机器翻译的GEC模型[39]应用较广,其基本思想是在词语对齐的预料库上,寻找并记录所有的互为翻译的双语短语,并在整个语料库上统计这种双语短语的概率。解码(翻译)的时候,只将被纠正的句子与语库中的源语句短语进行匹配,找出概率最大的短语组合,并适当调整目标短语的语序。
3.2 基于深度学习GEC模型应用
3.2.1 基于神经语言模型的方法
传统的N-gram模型由于参数空间的爆炸式增长,通常仅能对长度为两三个词的序列进行评估,其次,N-gram模型没有考虑词与词之间内在的联系性。基于神经语言模型的GEC方法[37],其思想是:通过嵌入一个线性的投影矩阵,将原始的独热编码向量映射为一个个稠密的连续向量,并通过训练一个神经语言模型,去学习这些向量的权重,使用词向量预测可能出现在目标词后面的词。随着训练次数的增加和反向传播调整,网络逐渐获得了将上下文相似的词映射为相似的词向量的能力。
3.2.2 基于神经机器翻译的方法
机器翻译是读取一种自然语言句子并产生等同含义的另一种语言的句子。机器翻译系统可能提出多个候选翻译,由于语言之间的差异性,这些翻译中的许多候选句是不符合语法的,例如:许多翻译的候选句在名词后放置形容词(sky blue),目标结果为(blue sky),但也为数据增广方法提供解决思路。其次,还需要语言模型评估翻译系统输出候选句。
端到端的神经机器翻译[7],直接利用神经网络实现源语言文本到目标语言文本的映射。主要以“编码-解码”思想:给定一个源语言句子,首先使用编码器将其映射为一个连续、稠密的向量,然后再使用一个解码器将该向量转化为一个目标语言的句子。此外,还可以将递归神经网络(recursive neural network,RNN)、卷积神经网络(convolutional neural networks,CNN)、长短期记忆(long short term memory,LSTM)、注意力机制引入端到端的神经机器翻译。其中,使用递归神经网络能够捕获历史信息和处理变长字符串的优点。使用LSTM可以较好的捕获长距离依赖,解决了递归神经网络训练时“梯度消失”和梯度爆炸“梯度爆炸”的问题。注意力,是指当解码器在生成单个目标语言词时,仅有小部分的源语言词是相关的,绝大多数源语言词都是无关的。注意力机制的引入,能够更好地处理长距离依赖,提升端到端神经机器翻译模型的性能。
3.2.3 预训练模型
迁移学习是利用在一个场景中已经学习到的内容去改善另一个情景中的泛化情况,预训练方法属于迁移学习领域的应用。使用海量、无标签的数据预先训练模型,使模型学习到通用的语言表示。通过学习每个输入句子中每个单词的上下文相关表示,从而提升下游任务效果。现如今,优异的语言模型基于Transformer[68]构建,比如GPT、BERT、RoBERTa、XLNET等。Zhao等人[38]通过改进Transformer模型,在注意力模型中使用Copy-Augmented Tarnsformer,即将原句中未改变的单词复制到目标语句,每条语句需要纠正的仅仅几个单词。基于复制机制的Transforner模型能够判断复制还是从词表空间中生成。研究表明,使用Transformer及其衍生变种模型可能成为下一个关键技术。
4 展望和总结
4.1 展望
目前,基于数据驱动的GEC方法面临诸如需要大量注释训练数据、人工标注错误数据消耗昂贵成本等问题。例如,基于规则的方法完全靠人工编纂纠错规则;基于统计的方法能够从数据中自动学习翻译知识,但仍需要人工设计翻译过程的隐结构和特征。近年来,GEC领域未来的研究方向可能集中在以下几个方面:
(1)模型训练数据。通过降低训练的复杂度,有效地提高模型纠错的质量。近期的工作表明[52,69],直接优化数据增广方法、合成更加真实的加躁数据可以显著提升模型的纠错性能。
(2)评价指标。在GEC评价指标中,由于存在候选编辑序列对齐的多样性及歧义性问题,如何建立视为有效、正确的纠正句编辑集合,从而综合客观的评价系统的性能具有重要意义。
(3)模型应用架构。如何设计表达能力更强的新架构,充分相邻句子甚至段落级的上下文语义信息。例如近期提出的BERT、Transformer及其衍生变种可能成为下一个关键技术。
4.2 总结
本文主要梳理了近年来数据增广策略在英语语法纠错过程中的应用。首先介绍的GEC领域的背景知识并探讨GEC评测指标的难点及解决方案。然后,详细说明了数据增广方法,最后描述了在GEC领域中的应用。文中通过对评测指标、数据增广方法、相关应用进行横向对比,指出了各类方法的优缺点。同时,对数据增广方法、模型架构、评测指标等未来发展方法进行分析,为后续进一步研究提供指导工作。
由于GEC领域没有单一的评价指标,指标的有用性取决于应用领域和研究目标。其次,主流的基于机器翻译的GEC模型对其在不同错误类型上的准确性和覆盖率,在实践中并不完全令人满意。性能优异的模型得益于大量的学习者语料数据。不幸的是这些数据需要大量的专业知识,构建相应的语料库成本很高,一种有效的数据扩充方式使GEC的性能进一步提高。总之,近年来基于数据增广的英语纠错方法在自然语言处理领域取得重要的成就,具有较高的应用价值和发展前景。
猜你喜欢
通信技术(2021年12期)2022-01-25
文化创新比较研究(2020年13期)2021-01-14
学生天地(2020年15期)2020-08-25
天津外国语大学学报(2020年1期)2020-03-25
意林·少年版(2020年2期)2020-02-18
湘潮(上半月)(2019年3期)2019-05-22
计算机应用与软件(2018年9期)2018-09-26
成人教育(2015年7期)2015-12-21
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
