
深度学习中的单阶段车辆检测算法综述
2022-04-08 03:40杨锦帆王晓强李雷孝杨艳艳李科岑
计算机工程与应用 2022年7期
杨锦帆,王晓强,林 浩,李雷孝,杨艳艳,李科岑,高 静
1.内蒙古工业大学 信息工程学院,呼和浩特 010080
2.天津理工大学 计算机科学与工程学院,天津 300384
3.内蒙古工业大学 数据科学与应用学院,呼和浩特 010080
4.内蒙古农业大学 计算机与信息工程学院,呼和浩特010011
目标检测作为图像处理和计算机视觉学科的重要分支,基本任务是找出图像中所有感兴趣的目标,获得目标的类别和位置信息。车辆检测作为目标检测的具体应用领域,对构建智能化交通系统起关键性作用。传统车辆检测算法主要分为三个部分:区域选择、特征提取、分类器分类。首先通过滑动窗口对图像进行扫描,根据车辆在图像中的位置及大小特征选择感兴趣的区域。然后从候选区域中提取特征,如方向梯度直方图[1](histogram of oriented gradient,HOG)、haar-like[2]和局部二值模式[3](local binary pattern,LBP)。最后通过人工神经网络[4](artificial neural network,ANN)、支持向量机[5](support vector machine,SVM)、Adaboost[6]等方法对特征进行分类,完成车辆检测。
传统车辆检测算法基于滑动窗口的区域选择没有针对性,导致产生大量窗口冗余,造成算法时间复杂度高;车辆运动过程中由于摄像机放置角度不同会产生车辆不同程度的形变以及光照强度、背景的复杂多变都使得人工设计一个鲁棒性强的车辆特征变得极其困难,而特征提取的效果直接影响了分类的准确性。以上缺陷导致传统车辆检测模型无法实现车辆准确及实时性检测。随着深度学习的快速发展,利用卷积神经网络对车辆特征进行提取而非使用人工设计的目标特征,大幅提高了车辆实时检测的准确性。同时,基于深度学习的单阶段目标检测网络相较二阶段不需要经过候选区域的获取,通过输入图像直接回归目标边界框位置及类别,检测速度更快;模型结构简单,更适合应用于计算及存储能力有限的嵌入式设备中,有更大的应用价值。本文首先简介了传统的车辆检测算法并分析其局限性,提出车辆检测面临的问题,之后列举了常用的单阶段车辆检测算法及在真实交通场景下的检测缺陷,重点阐述了单阶段车辆检测算法的改进、优势以及仍存在的问题,之后列举了车辆检测相关数据集,最后分析了车辆检测未来的研究方向。
1 传统车辆检测算法
传统车辆检测算法[7]一般分为两类:第一类是基于特征数学模型的,包括帧间差分法[8]、背景差分法[9]、Hough变换法[10]、光流法[11]。第二类是基于区域选择特征的,包括滑动窗口模型[12]和DPM[13](deformable part model)。
帧间差分法通过对视频图像序列相邻两帧图像做差分运算获取运动目标轮廓。算法需要设置合适的时间间隔,否则会出现漏检及错检问题。
背景差分法采用当前帧与背景参考模型比较检测运动物体,对复杂交通场景的背景建模和模拟困难。
Hough变换法用于检测图像中直线、圆等能够用一定函数关系描述的曲线。在交通场景中,一般用在对车道线的检测[14-15]。
光流法利用图像序列中像素在时间域上的变化及相邻帧之间的相关性寻找上一帧与当前帧存在的对应关系,计算物体运动信息。由于光流法基于相邻帧亮度不变假定,受光照等外界环境影响大且不同场景下的检测效果也有较大差别。
滑动窗口模型将固定卷积区域按指定步长在图像上滑动,对每次滑动得到的区域进行预测,判断该区域是否存在目标。若图像划分的区域增多,计算成本也相应增加。
DPM算法采用改进后的HOG特征,SVM分类器和滑动窗口,针对目标本身形变问题,采用可变部件模型策略。
虽然传统目标检测算法在车辆检测领域有不错的应用,但图像特征获取需要人工建立并结合目标检测器和分类器,算法复杂且性能不高;同时,人工建立特征的方法受环境变化、光照强弱及物体形态变化影响,鲁棒性和泛化性差;另外,基于滑动窗口选择检测区域会增大算法复杂度,导致检测效率下降,无法满足对车辆实时性检测需求。因此,随深度学习的发展,传统车辆检测算法应用越来越少。
2 基于深度学习的单阶段车辆检测算法
与传统车辆检测方法相比,基于深度学习的车辆检测算法无需进行人工特征设计,通过卷积神经网络,自动提取从原始图像浅层位置信息到高层语义信息的多层次车辆特征。利用卷积神经网络进行车辆检测的基本思想是通过监督学习的方式分析图像底层特征和对应目标标签,得到一组损失函数最小的网络权值,通过网络正向推理识别图像中车辆目标。具有较好的鲁棒性,且随车辆检测数据集的增大,卷积神经网络提取多层次特征效果就会越好。因此,基于深度学习的车辆检测算法成为车辆检测领域的研究趋势。
基于深度学习的目标检测算法,可分为基于候选框的二阶段方法和基于回归的一阶段方法。由于二阶段算法采用RPN网络对候选区域进行推荐,算法模型复杂,导致算法检测速度降低。而单阶段目标检测模型结构简单且检测速度快,能更好地应用于复杂的交通场景,因此针对单阶段车辆检测算法的应用研究更有价值。
目前常用的单阶段目标检测框架有YOLO(you only look once)系列、SSD系列等,以下介绍了基于常用单阶段目标检测框架的车辆检测算法以及基于最新算法框架(RetinaNet、RefineDet和CenterNet)的车辆检测算法。
2.1 YOLO系列车辆检测算法
YOLO系列算法包括YOLOv1[16]、YOLOv2[17]、YOLOv3[18]、YOLOv4[19]以及最新的YOLOv5算法。由于单阶段车辆检测算法不需要经过候选区域的获取,检测速度较二阶段车辆检测算法提升,但损失了检测精度,尤其针对小物体的检测精度。这就导致YOLO系列车辆检测算法存在对远处小目标车辆、车牌以及遮挡车辆检测效果差,光线变化或拍摄角度等客观因素对检测效果影响大的问题。
2.2 SSD系列车辆检测算法
SSD[20]车辆检测算法平衡了R-CNN系列检测精度较高但检测速度慢和YOLO检测速度快但对远处小目标车辆检测效果差的不足。相比YOLO而言,SSD采用多尺度特征图进行预测,网络结构如图1所示。
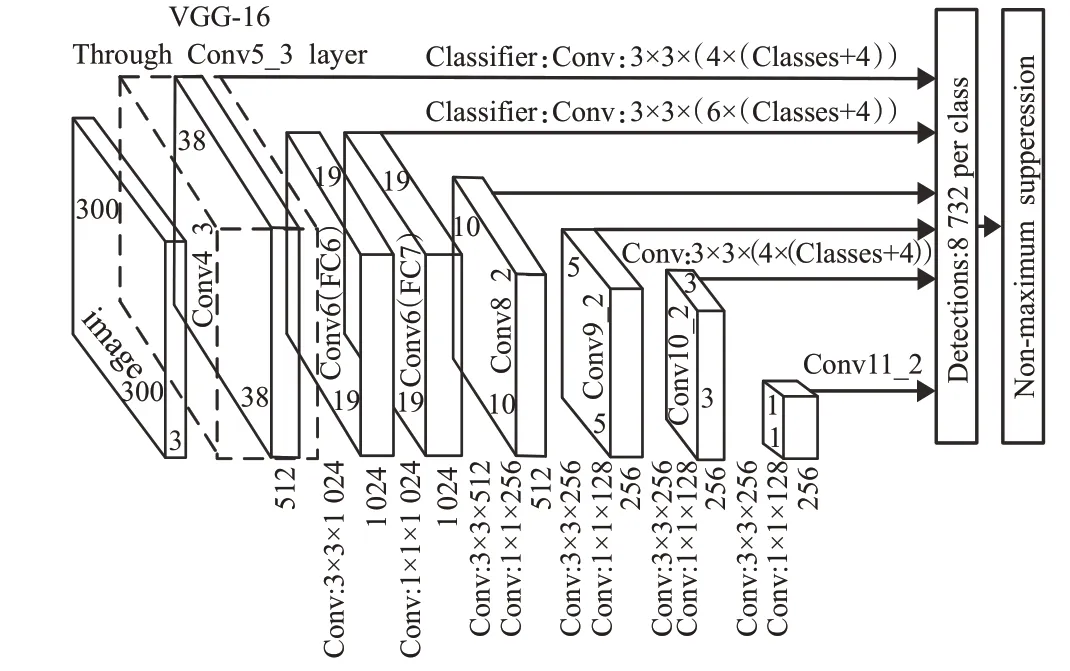
图1 SSD模型Fig.1 SSD model
借鉴Faster R-CNN中的锚框设计,提高算法对不同尺度特征的检测能力,但需人工设置prior box尺寸及aspect_ratio值,且default box基础大小与形状无法通过学习得到,非常依赖经验;使用conv4_3低级特征图检测小目标,浅层特征图的表征能力不够强;不同层的特征图独立作为分类网络的输入,存在重复框的问题。以上算法局限性导致其在车辆检测中出现对遮挡车辆,以及视线远处的小目标车辆信息漏检和错检问题,并且模型参数量大,很难直接应用于嵌入式设备。常用单阶段车辆检测算法对比如表1所示[21-24]。

表1 常用单阶段车辆检测算法对比Table 1 Comparison of common one-stage vehicledetection algorithms
2.3 基于最新单阶段框架的车辆检测算法
单阶段算法虽然检测速度快,但检测精度较二阶段算法低。研究发现,正负样本的极度不均衡是造成单阶段算法精度不高的主要原因。同时,锚框的应用引入大量超参数,且由于需要大量锚框来确保与大多数真实框充分重叠,在正负锚框之间产生巨大的不平衡,减缓了训练速度。此外,为解决目标实例中尺度变化问题,单阶段与双阶段检测器都使用特征金字塔结构,但主干网络生成的多尺度特征金字塔适用于分类并不一定很好地适用于检测。针对以上问题,研究者结合单阶段与二阶段车辆检测优势,提出改进的单阶段车辆检测算法RetinaNet[25]、RefineDet[26]、CenterNet[27]及CornerNet-Sccade[28]。设计新的损失函数[25]改善正负样本不均衡;对锚框大小、位置进行改进[26],改善正负锚框不均衡;考虑锚框数量对检测速度的影响,提出anchor-free框架[27]。算法对比如表2所示。

表2 基于最新单阶段框架的车辆检测算法对比Table 2 Comparison of vehicle detection algorithms based on latest one-stage framework
3 单阶段车辆检测算法改进及应用
3.1 基于YOLO系列车辆检测算法改进及应用
针对YOLO系列车辆检测算法存在的问题进行一系列改进,如改进损失函数[29-31]、修改网络结构与残差结构[32-34]、改进输入[35]等,提高算法对遮挡车辆与小目标车辆检测的准确率;通过与多种算法相结合实现对车辆行为的检测,使得算法模型更好应用于特定领域检测如车速检测[35]、车辆违章检测[36-37]、车型识别[38]、车牌检测[39]、无人驾驶[31,40-44]、以及车辆烟雾检测[45]等。
Tian等[29]提出基于传统YOLO算法上搭建Darknet-53特征提取网络的实时车辆检测算法。构建更深层卷积神经网络提取更多车辆信息;原始YOLO算法设置固定阈值筛选候选框,算法复杂度减小,但不同场景下背景噪声及目标数量不同,阈值设置过大会带来漏检,过小则会增大处理难度,导致错误识别车辆目标。因而,设置动态阈值,避免候选框定位不准确问题,算法整体检测精度获得提升;YOLOv1使用非极大值抑制算法筛选重叠候选框,实现最终输出,虽然可以有效减少计算量,但强制删除与最大置信度重叠的候选框很有可能在车辆密度大的环境下造成误删,造成准确率下降。因而使用高斯函数设置删除规则,检测框置信度根据高斯函数衰减,减少漏检,加快模型收敛速度;引入批量归一化,解决随网络加深以及训练过程造成的数据漂移与梯度消失问题;YOLOv1算法整体损失由预测框的坐标误差、目标的置信度误差以及网格预测类别误差三部分组成,全部使用均方误差实现显然不合理。因此,采用模型参数变化率归一化思想,改进坐标位置宽高误差计算,允许不同尺度目标以相对误差形式出现,加快神经网络的收敛速度。算法实现实时车辆检测与定位,对无人驾驶领域研究有重要借鉴价值,但由于使用高斯函数仍无法完全解决同类别目标相距较近时的检出问题,所以算法对重叠车辆的检测准确率并不高。金宇尘等[36]提出一种结合多尺度特征的车辆实时检测算法。由于车辆距摄像头的距离不同,车辆在图像中所占像素也不同,特征层会丢失部分较小车辆信息,因而YOLOv2算法仅通过聚类锚框检测的方法效果有限,同时,将原始图像划分网格的方式会导致落入同一网格的相互遮挡车辆漏检。因此,改进YOLOv2网络结构,如图2所示,将Conv_20与Conv_13进行特征融合,获得新的特征检测层,提高了检测较小车辆及遮挡车辆的准确率。
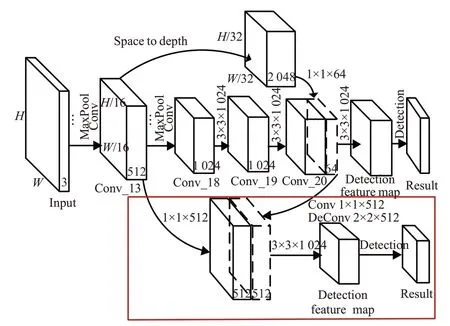
图2 多尺度网络结构Fig.2 Multiscale network structure
YOLOv2通过加大正样本的权重系数增大正样本损失,解决正负样本数量极度不平衡问题,但不合适的权重系数会带来较为严重的漏检问题。针对这一局限性,构造自适应损失函数,防止训练时正样本产生的梯度被淹没,解决正负样本极度不平衡带来的模型训练缓慢以及性能下降问题;YOLOv2算法中类别预测没有设置背景标签,容易出现错误预测含类似车辆或不存在车辆的网格置信度,且由于只学到正样本的物体类别特征,Softmax函数生成的类别概率也会产生错误,带来车辆错检问题。从而提出难样本生成方法,将置信度预测错误的负样本置为难负样本参与模型训练,有效降低错检。改进的算法在不仅在实时性方面获得优势,在性能上也超过了Faster-RCNN,但由于YOLOv2算法本身划分网格检测目标的局限性,改进的算法即使增加大分辨率特征层,仍无法解决对严重遮挡车辆的准确检测。顾恭等[38]提出车辆实时定位与识别模型Vehicle-YOLO,如图3所示。该模型增加了两层残差网络,加深了模型,并提取5种尺寸特征图,优化模型对不同尺寸车辆的适应程度;改进传统YOLO算法上采样方式,舍弃邻域插值算法对上一层特征图的级联过程,减少卷积降维操作带来的计算量;整合多种车辆数据集对车辆类别进行识别。改进的算法对中远距离车辆有较好的定位能力,实现同步车辆定位与类型识别,但由于预测单元格增多,增加残差模块,模型实时性降低且后续要进一步改进数据集大多为国外车辆导致特征单一化问题。张成标等[46]提出基于YOLOv2改进的车辆违章掉头检测算法。借鉴YOLOv3网络结构,增加残差结构与多尺度预测,提高检测精度;减少卷积层,解决模型厚重问题;使用Relu激活函数。改进的车辆多方位识别算法可应用于更多车辆违章检测,但由于Relu激活函数涉及指数运算,算法实时性不高。更多基于YOLOv1~v3改进的车辆检测算法见表3。
表3 基于YOLOv1~v3改进的车辆检测算法Table 3 Vehicle detection algorithms based on improved YOLOv1~v3
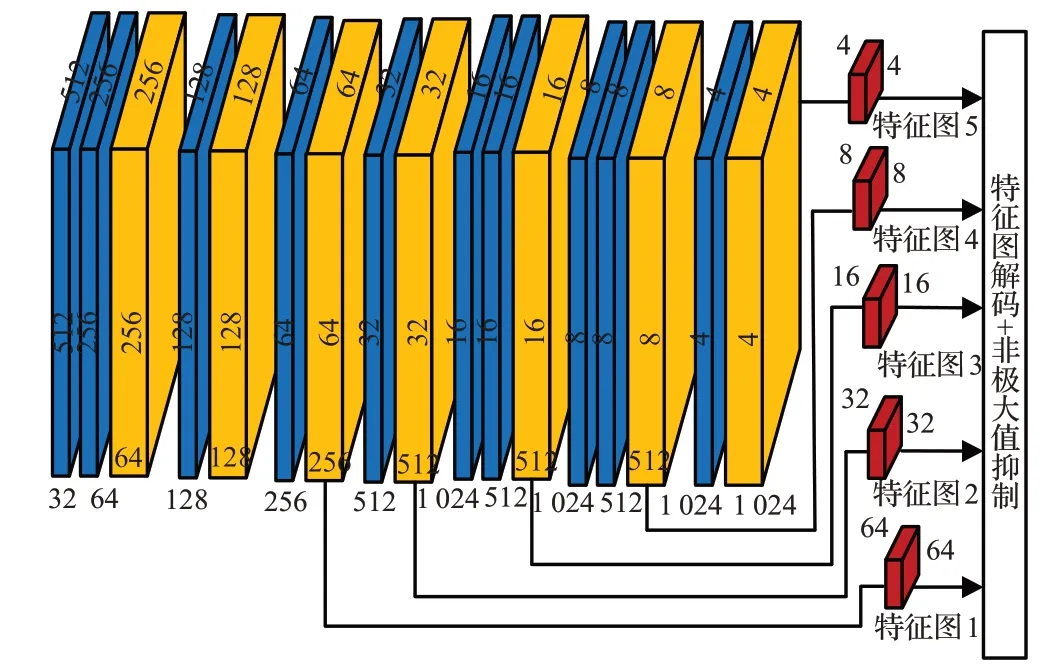
图3 Vehcle-YOLO网络结构Fig.3 Vehicle-YOLO network structure
基于YOLO系列改进的车辆检测算法研究十分广泛,尤其针对YOLOv3算法的相关改进。因为相较YOLOV1、YOLOv2算法,YOLOv3算法的检测速度更满足实时检测需求,且检测精度大大提升,在车辆检测领域更具研究价值。针对YOLOv3车辆检测算法的改进集中在增强卷积神经网络的特征提取能力,提高对不同尺度车辆以及严重遮挡车辆的检测准确率;减少模型参数,从而更易工作在硬件条件有限的嵌入式设备中;不断提升算法检测速度,实现实时车辆检测;利用YOLOv3优越的检测精度,结合多种算法,实现特殊环境、特定领域下的车辆检测。YOLOv4由于模型主干网络参数量大,难适用于算力与存储有限的移动终端设备中,即使相较YOLOv3车辆检测算法有更优越的检测准确率,在车辆检测方面的应用不如YOLOv3普遍,更多地应用于遥感车辆与车辆环境感知领域,而YOLOv5网络较新,现阶段应用研究并不如YOLO系列其他算法广泛。基于YOLOv4-v5改进的车辆检测算法见表4。
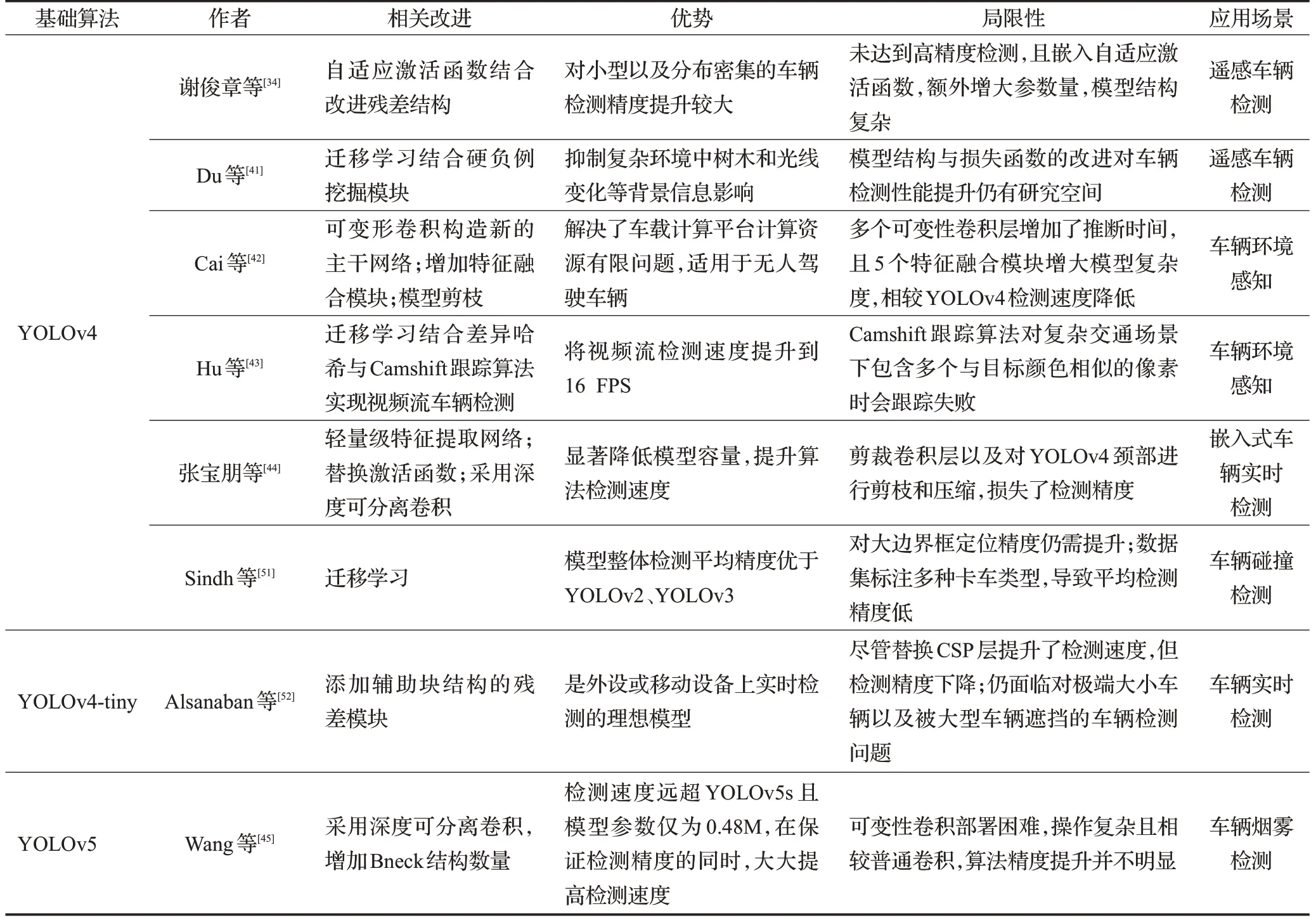
表4 基于YOLOv4-v5改进的车辆检测算法Table 4 Vehicle detection algorithms based on improved YOLOv4-v5
YOLO系列车辆检测算法的改进思路围绕提升算法检测速度的同时提高检测精度进行,通过改进特征提取网络、模型剪枝等方式减少模型参数数量,改进特征融合策略、卷积方式以及结合多种算法减少精度损失。尽管改进的车辆检测算法在推理速度以及检测精度上获得一定提升,但现阶段基于YOLO系列改进的车辆检测算法对远处小目标车辆以及遮挡车辆的检测性能仍有很大提升空间,对因拍摄角度问题产生的极端大小车辆及光照强度改变造成部分信息丢失车辆的检测仍面临不小挑战,对交通信号灯等小目标的检测精度仍较低,应用于实时高精度无人驾驶领域还有一定距离。
3.2 基于SSD车辆检测算法改进及应用
针对SSD系列车辆检测算法存在的问题,研究人员提出许多改进的车辆检测算法。通过改进主干网络[53-58]、融合策略[57,59-60]、锚框机制[58,61]、边界框定位[54]以及激活函数[55]等方式提高算法在车辆遮挡情况下以及对小目标车辆的检测准确率;对图像进行预处理[59,61-63],提升算法在夜间以及恶劣天气下车辆检测准确率;提出轻量化模型[56,60],扩大算法应用范围。
Guo等[53]提出以ResNet50为主干网络的SSD模型。将ResNet50前4层卷积层合并作为预测层的输出,再增加6层依次卷积层作为预测输出;在Bottleneck结构后添加注意力机制(SENet)。算法检测精度得到提升,但在车辆目标较多且遮挡较严重情况下仍存在漏检较多问题且融合不同输出尺寸特征图并增加卷积层,模型复杂度增加,极大降低检测速度,未能达到实时检测要求。李国进等[54]改进Inception模块,如图4所示。
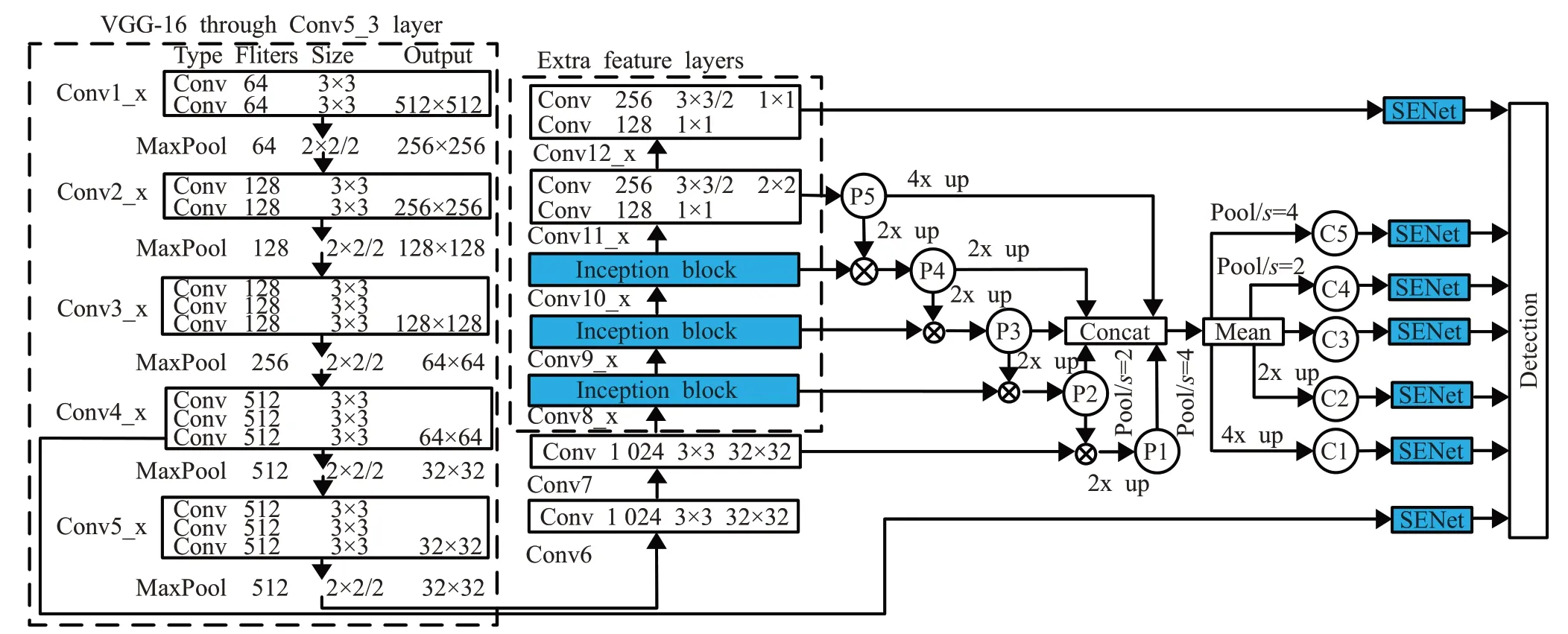
图4 引入改进Inception模块的网络结构Fig.4 Network structure with improved Inception module
引入不同空洞率的空洞卷积,代替SSD中Conv8、Conv9和Conv10层,在不增加参数量的前提下提升对中目标车辆的特征提取能力;提出多尺度融合均衡化网络,提升对小目标车辆检测精度;每个特征层后加入SENet,自动学习每个通道特征的重要程度。算法计算量及模型大小远小于SSD,对比SSD与YOLOv4算法,平均检测精度及检测速度获得显著提升,但当场景中存在大量重叠小目标车辆时,仍存在部分漏检问题。徐浩等[55]提出结合残差网络和注意力机制的轻量级特征提取网络,降低算法复杂度;使用h-swish激活函数替换残差结构中的ReLU激活函数,提高网络检测精度;使用K-means算法聚类先验框,极大减少默认框数量,检测效率获得大幅提升。算法改进了嵌入式摄像设备识别移动车辆效率低的问题,但由于默认框数量的减少,目标位置回归精度受到一定影响,算法改进对检测效率的提升有显著效果,但检测精度提升并不明显。杨帆等[61]改进锚框数量,将各特征层对应的锚框种类数提升至[6,6,6,6,4,4],增加底层特征图锚框类别;引入红外热像图,融合红外热像图与可见光图像提取的特征。降低小目标车辆漏检率,提高夜间、雾天等天气下对大型车辆目标的检测性能,但锚框数量的增加增大了模型参数量,直接导致检测速度的下降,且仅从图像输入角度改进算法,并未对原始SSD算法特征融合局限性与边界框生成方式做进一步改进,因此车辆检测算法精度提升不明显,实时性也未能达到要求。Kitvimonrat等[62]提出基于SSD的车辆制造商识别算法。使用YOLOv3算法检测图像中车辆,将车辆定位图像进行剪裁,送入SSD模型进行车标定位。该模型对20个车辆品牌的检测和识别取得不错成绩,但模型只能处理白天的图像,且受阴影和车标反射光的影响较大。更多基于SSD改进的车辆检测算法见表5。
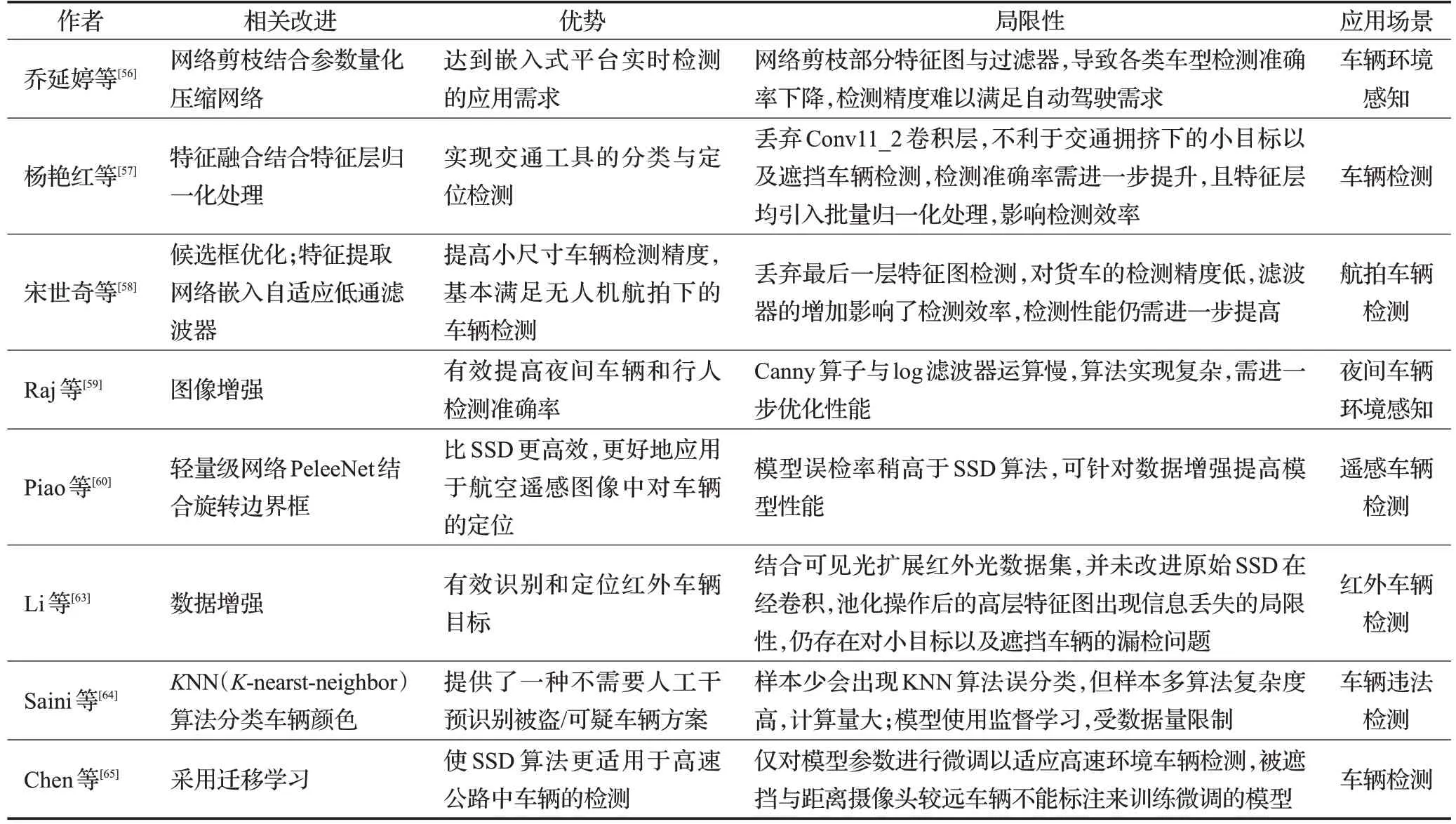
表5 基于SSD改进的车辆检测算法Table 5 Vehicle detection algorithms based on improved SSD
尽管对原始SSD车辆检测算法进行了多方面改进,但从上述改进可以看出,改进后的车辆检测算法仍存在许多问题:(1)对出现大量遮挡车辆的拥堵交通环境下的车辆检测以及远处小目标车辆的检测准确率仍然较低。(2)对夜间小目标车辆检测仍有很大的改进空间。(3)对车标、车型的检测会受到数据集车标、车型种类有限以及光照和拍摄角度限制。(4)为达到应用于嵌入式设备需求提出的轻量级网络准确率并不理想。
3.3 基于最新单阶段框架车辆检测算法改进及应用
针对最新算法框架在车辆检测中对小目标车辆漏检和错检,对遮挡车辆检测效果差,以及难应用于计算力不足且存储有限的移动终端设备中这些突出问题,研究人员通过改进损失函数[66-67],提高模型的定位精度;改进网络结构[66-75]和融合策略[70,73],引入注意力机制[72,75],增强网络提取特征能力同时减少网络计算量;对网络进行剪枝、压缩通道以及采用深度可分离卷积来获取轻量级检测模型[71]等措施改进算法模型。
张炳力等[66]对RetinaNet损失函数进行优化,提出基于IoU的分类损失函数,将网络定位与分类联系起来;改进定位函数对宽高进行归一化方式,提高检测小目标车辆性能;针对夜间车辆特征对网络结构进行优化。提高了定位精度,对夜间小目标车辆的检测具有良好效果。梁礼明等[70]借鉴CenterNet框架,提出一种基于中心点的多类别车辆检测算法。在Hourglass中引入残差网络,避免随网络加深可能出现的梯度爆炸和梯度消失问题;融合通道数与尺度相同的各层特征图,避免频繁进行的上下采样操作带来的有效特征丢失;引入可变形卷积和GIoU损失,克服车辆检测中受到车辆种类、大小以及视觉变化带来的影响。相较CenterNet算法,精准率与召回率均得到提高,但可变性卷积部署困难,操作复杂且相较普通卷积,算法精度提升并不明显;针对IoU损失无法对真实框与检测框无交集时的模型进行优化提出的GIoU仍有自身的局限性,当两个矩形框位置非常接近的时与IoU损失值接近,所以需进一步改进算法流程与检测精度。更多基于最新单阶段框架车辆检测算法相关改进见表6。
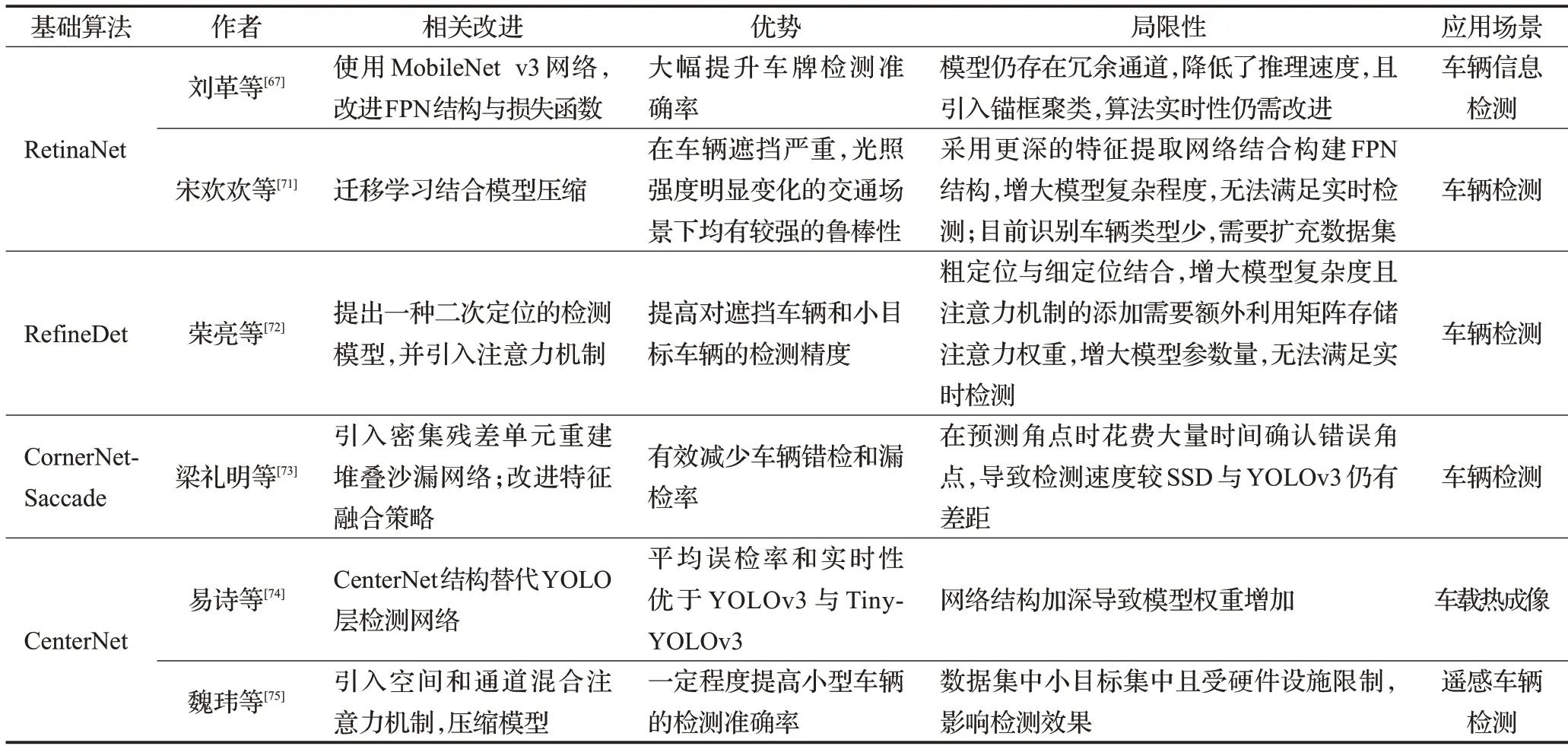
表6 基于最新单阶段框架车辆检测算法的相关改进Table 6 Vehicle detection algorithms based on improved latest one-stage framework
基于最新算法框架的车辆检测算法模型将改进的重点放在降低小型车辆目标及遮挡车辆的错检及漏检率上,进一步提升算法在复杂交通环境下的检测性能,试图在模型算法复杂度尽可能低的情况下实现模型检测精度与检测速度的最大平衡。如若融合多种策略提升对远处、遮挡车辆的检测效率势必会增大网络计算复杂度,在损失检测速度与增大内存的前提下提升检测精度;若考虑硬件计算能力与存储大小,对模型进行压缩,轻量化的模型在检测速度与存储大小上会获得不小改进,但相应地会牺牲部分检测精度。以上提出的车辆检测算法还需进一步提升其检测速度与检测精度,在实现检测精度与检测速度的平衡上还有很大的研究空间。
4 数据集
近10年来,目标检测领域发布了许多知名的公开数据集,除了应用于一般目标检测任务,特定领域内的检测应用也逐渐繁荣。车辆检测作为智能交通系统的关键组成部分,在车牌检测、车型检测、车标识别等领域有着广泛应用,随着无人驾驶领域的发展,车辆检测技术成为关键技术。车辆检测领域有许多公开的数据集,例如Stanford cars数据集主要用于细粒度分类任务,该数据集一共包含196类汽车的16 185张图片,将数据分成8 144张训练图像和8 041张测试图像。针对车辆品牌的识别数据集OpenData V11.0-车辆重识别数据集VRID,包含最常见的10种车辆款式,共10 000张图像,每个车辆款式各有100种不同的车辆ID,每个车辆ID含有10张图像,拍摄于不同的道路卡口、光照、尺度以及姿态各有差异。BIT-vehivle dataset-车辆车型识别数据集包含9 850张车辆图像,被划分为公共汽车、微型客车、小型货车、轿车、SUV和卡车6类。自动驾驶领域的BDD100K自动驾驶数据集,拥有超过1 100小时的100 000个高清视频序列,100 000张图像,含一天中不同时间、天气条件和驾驶场景,由10个类别组成,包含1 021 857个标记汽车实例。辅助夜间车辆检测的FLIR thermal starter数据集共计14 452张红外图像,所有视频都来自街道和高速公路,提供了带注释的热成像数据集和对应的无注释RGB图像。遥感数据集vehicle detection in aerial imagery(VEDAI)dataset包含不同方向角度、光照变化、镜面反射以及不同程度遮挡的车辆图像。除了以上数据集,也有应用更广泛的车辆检测数据集,例如MS COCO数据集、KITTI数据集等。MS COCO数据集包含80类目标,其中有5种类别与车辆有关,包含328 000图像和2 500 000个标签。KITTI数据集由市区、村庄、高速公路等复杂交通场景下的图片数据,7 481张训练用图,7 518张测试用图组成,含汽车、货车、卡车、电车4类车辆样本,每张图片最多包含15辆车。相关数据集详细信息见表7。
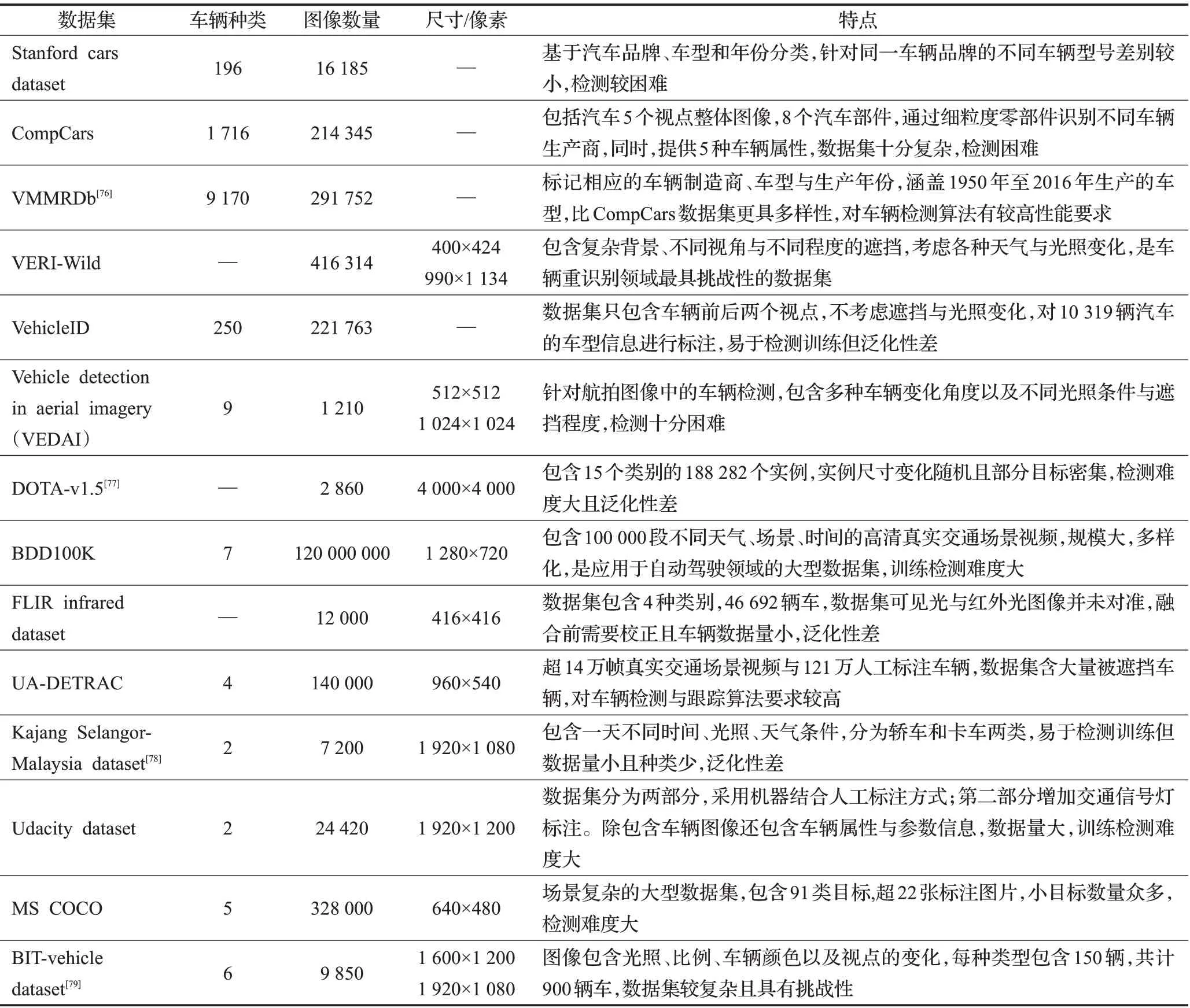
表7 车辆检测常用数据集Table 7 Common datasets for vehicle detection
5 总结与展望
本文深入研究与分析了单阶段车辆检测算法现状,列举了常用单阶段车辆检测算法的改进措施、优势以及存在的问题,详细阐述了研究者们针对YOLO系列、SSD系列以及基于最新单阶段框架车辆检测算法的不足之处进行的一系列改进。由于智能交通系统的不断发展给车辆检测提出更高的要求。实现在视频流中车辆实时检测,然而传统车辆检测算法效率低且准确率不高,因此要进一步改进算法;准确检测与跟踪车辆,达到缓解交通拥堵,减少交通事故发生的目的;考虑硬件条件,设计既能满足实时性又能满足精度需要的算法,这正是车辆检测面临的最大难点。尽管经过改进的车辆检测算法取得了不错的检测性能,但仍存在一些难以解决的问题:
(1)受光照、天气等客观因素影响,图像中车辆信息模糊甚至丢失,为车辆检测如车标、车型识别以及夜间车辆检测等带来困难。
(2)交通拥堵、摄像机放置角度等会造成一定程度的车辆遮挡,出现车辆漏检、误检等问题。
(3)目前公开的数据集中车辆类别和车辆数量有限且对车辆违规检测的数据量不足,不能充分训练相关检测模型。
(4)考虑硬件设施条件,要求轻量级模型在追求车辆检测速度的同时兼顾车辆检测精度,给车辆检测带来挑战。
(5)图像中远处较小车辆检测准确率低是车辆检测领域面临的普遍问题。
针对以上问题,本文经过分析认为车辆检测算法未来要在以下5个方面进行深入研究:
(1)结合多种算法实现数据增强。针对夜间光线不足与恶劣天气下车辆信息的部分丢失,提取更多车辆细节特征,改进图像输入质量,提升车型、车标等检测精度。
(2)改进特征提取网络。通过构建更深层网络、融合残差结构与注意力机制等加强车辆特征提取能力,改善车辆形变带来的检测困难问题。
(3)改进特征融合方式。针对拥挤交通状况下的车辆遮挡与较远处小目标车辆检测困难,构建合适特征检测层。
(4)构建轻量级网络。通过模型压缩、参数量化、改进传统卷积等方式减少模型参数量,使其适用于计算与存储能力有限的移动终端设备中。
(5)构建更大型车辆检测数据集。针对车辆特定领域的检测数据样本不足、遥感图像数据集中样本分布不均等问题,进一步扩充样本数量,改进泛化性弱的检测局限性。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子制作(2019年11期)2019-07-04
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
小太阳画报(2018年3期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
阅读与作文(小学低年级版)(2016年12期)2016-12-22
