
脑启发的视觉目标识别模型研究与展望
2022-04-08 03:40李少毅
计算机工程与应用 2022年7期
杨 曦,闫 杰,王 文,李少毅,林 健
1.西北工业大学 航天学院,西安7 10072
2.空军军医大学 放射科 陕西省功能与分子影像重点实验室,西安 710038
3.西北工业大学 无人系统技术研究院,西安 710072
人类通过视觉、触觉、听觉和嗅觉等感觉器官获取外部信息,从而实现与外部世界的交互,其中视觉在人类的感觉世界中担负着重要任务。研究表明人类视觉系统具备并行计算与处理模拟信息的能力,同时对外界信息的处理具有很强的筛选能力。人类与灵长类动物的大脑视觉皮层具有多级互连结构,同一层中的神经细胞在获取信息后高速、并行地进行特定的信息处理,并逐层简化数据规模,实现图像特征信息的提取,最终完成对物体的认知理解。
尽管神经科学取得了重大进展,但仍然对大脑视觉通路如何组织、产生物体识别和学习的行为知之甚少。在缺乏明确的构建指令的情况下,神经科学和受脑启发的目标识别之间的互动一直是一种共同进化。脑启发的目标识别模型是一个开放而有吸引力的研究领域(如图1所示),具有广泛的类别和应用范围。很多研究者在设计目标识别算法时尝试模拟视觉皮层的信息处理机制。类脑视觉是以生物大脑为研究参考的人工智能技术在机器视觉领域的应用,通过研究和理解大脑皮层中的神经回路如何实现准确快速的目标识别机制,尝试将神经科学转化为目标识别算法,促进计算机视觉与模式识别的发展。经过几十年的开发,研究人员构建出的深度神经网络,在目标识别任务达到甚至超过人类的表现。但是,用于深度学习的人工神经网络是否类似于人们大脑中的生物神经网络?两者在很多方面可以进行对比研究。
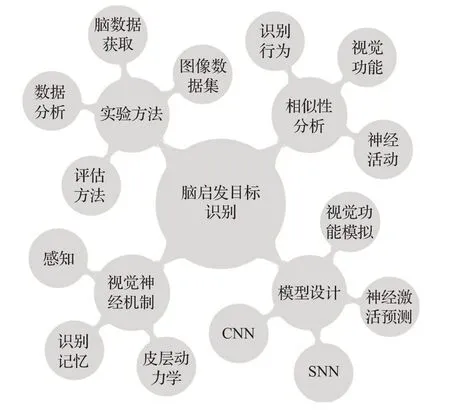
图1 视觉物体识别的脑启发模型综述Fig.1 Review of brain-inspired model for object recognition
在泛化推理方面,人类可以从视觉环境中提取信息,通过复杂的操作使人类拥有迁移学习的能力。理解和因果关系仍然是人类大脑的独特优势。人工神经网络具有一定的决策推理能力,但常常被认为是无法解释的熏盒子,因为深度神经网络检查数百万张图像及其相关标签,然后无意识地将数百万个参数调整到从图像中提取的模式,并没有理解更高层次的语义概念和知识。研究人员试图在训练过程中添加更多样本提高深度学习模型的鲁棒性,但这通常不能解决问题。在网络输入方面,与人工神经网络相比,人类大脑的神经网络输入机制非常差,不具备摄取和处理大量数据的能力,这使得人类的大脑不可避免地学习新的任务而不是学习潜在的规则。但是人们经常低估了大脑处理的数据量,可能接触到成千上万个样本被取样很多次,所以视觉系统输入的数据量也是相当惊人的。
此外,随着互联网、大数据时代的到来,拥有海量数据和尖端仪器探索灵长类大脑视觉信息处理的奥秘。一些组织或团队已经开始发起了大型的、跨国的努力,使用深度神经网络模拟部分大脑视觉通路的生理功能或神经机制。与此同时,一些研究团队正在研制突触结构,其基本构件的工作原理更像神经元突触。除非在神经元功能的基本本质上有大的意外,可能会在不久的将来完成模拟整个视觉通路的工作。
在这里,本文研究工作回顾了近二十年在视觉目标识别的研究方向,重点关注视觉神经科学和计算机视觉之间在目标识别任务的联系。在许多方面,视觉处于神经科学和机器感知的前沿;可以说,人们对大脑视觉系统的了解比人们对几乎任何其他大脑子系统的了解都要多,而且计算机视觉在机器学习、机器感知和脑启发的计算[1]的发展中发挥了主导作用。物体识别为神经科学和计算机科学的交叉提供了一个经典的案例。
本文第一部分主要描述了从神经科学理论试图分析大脑视觉系统在目标识别任务中可能使用的计算原理,以准确有效地将神经活动和识别行为整合到生物启发的计算模型中。具体地,通过实验获得的大脑活动数据,旨在表征大脑激活的皮层动力学,将视觉神经活动与目标识别任务中的行为联系起来,总结出视觉目标表征的内容和信号流向形式,揭示目标识别任务背后的计算机制。第二部分主要探索了基于大脑启发的目标识别模型的发展,建立了从神经科学到计算机视觉的桥梁。回顾了最近的一些类脑目标识别模型的研究工作,使用大脑或识别行为数据训练和测试执行识别任务的计算模型。其中的深度卷积神经网络模型整合并抽象了神经生物学的部分特征,被证明与灵长类视觉神经通路具有很强的相似性。这些模型通过神经科学提供的功能机理执行目标识别任务,其计算机制同时可以反向解释神经活动和识别行为。本文主要的贡献总结如下。
(1)类脑模型的全面、深入探索:针对目前最先进的基于大脑启发的目标识别方法,根据模型架构(CNN、SNN、HMAX)、模型开发(神经激活预测和神经功能机制模拟)进行详细分类的研究,涵盖了这些所有方面,在之前是没有的。
(2)网络对比分析:总结了基于CNN的目标识别模型与灵长类动物视觉神经系统的相似性研究(神经活动预测、识别行为匹配和功能相似性比较)。据大家所知,这种在人工神经网络与生物神经网络的比较分析方面从未被提出过,这种分类为设计在生物学上可信的视觉目标识别模型提供了适当的指导方向和参考标准。
(3)实验设计总结:视觉目标识别实验设计一个基础而关键的任务。本文从视觉数据集、脑视觉信号获取、数据分析三个方面回顾了实验条件及方法,对视觉神经活动和识别行为表现的实验设计进行了总结。
本文首先对近年来提出的几类基于脑启发的视觉物体识别模型进行详细介绍,并根据模型的发展阶段和模型构建方式进行分类;接着介绍基于DNN的目标识别模型于视觉系统的相似性分析;然后介绍脑启发模型的实验条件和评价方法;最后是本文的总结。
1 脑启发目标识别模型
基于脑启发的目标识别模型的主要动机是通过模拟视觉功能机理、神经活动预测的方式提取、抽离大脑中视觉目标表征和识别过程的生物网络模型,进而构建生物学上可信的类脑目标识别模型。它们一般通过心理物理学实验或脑信号采集实验发现大脑目标识别的一般规律,进而采用人工神经网络模型映射到人类视觉皮层,揭示出大脑目标识别的大规模动力学。随着认知心理学和认知神经科学不断发展,脑电图(EEG)、fMRI以及脑磁图(MEG)等脑信号获取技术先后问世,使得采用科学手段对大脑活动进行解读成为可能。研究人员通过采集不同时空尺度的大脑活动信号,利用数学模型建立这些信号与大脑视觉感知与认知状态间的映射关系,实现对人类的视觉认知进行辨识或重构的目的,将大脑中的想法转化成自动化设备的驱动力。
然而,目前利用先进的成像设备已经探索出大脑视觉系统的部分神经机制和功能特性,如何将其映射到人类可以修改和控制的计算机软件或设备上,模拟脑视觉功能实现机器视觉智能。因此类脑视觉成为计算机视觉领域最新的热点方向。视觉信息编解码技术为类脑视觉领域发展提供了可能。如图2所示,视觉信息编解码以视觉认知理论为基础,通过采集人眼接受不同图像刺激时大脑响应的时空数据建立并训练数学模型,可以预测人眼看到新的图像时的大脑响应,或者根据采集到的大脑响应进而识别、重构人眼所看到的图像。通过视觉信息编解码技术,探究大脑的认知机理,模拟人类视觉处理信息的过程。
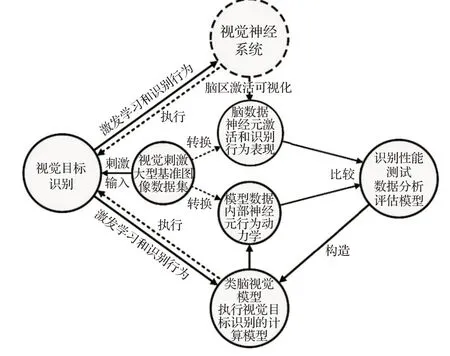
图2 受脑启发的目标识别模型的逻辑关系Fig.2 Logical relationship of brain-inspired object recognition model
许多受生物启发的目标识别模型试图通过视觉信息编解码的方式复制灵长类动物腹侧流中观察到的现象,并应用于计算机视觉领域。尽管最近重新发现了卷积神经网络已导致机器视觉分类性能的显著改进,但是在目标识别、解释视觉场景方面,机器仍然无法达到人类表现出的出色性能。在这里,回顾神经科学与计算机视觉之间在视觉目标识别任务中的相互作用,并对未来的交叉授粉提出可能的途径。
在梳理和查阅大量文献的基础上,根据发展阶段,脑启发模型的构建大致分为宏观模型和微观模型,宏观模型侧重于整体结构层面,微观模型更侧重于微观神经元的模拟。此外,根据第2章中所述的视觉物体识别的神经机制,构建大脑激发的物体识别模型主要需要以下特征:视觉神经结构、视觉特征、视觉皮层的神经功能和信息表达。因此,将从模型架构和模型发展两个角度对脑源性物体识别模型进行综合分类。从模型构建所采用的基本框架来划分模型架构,包括模拟视觉通路结构和神经功能两个特点,分为基于CNN、基于SNN和仿生突触。从模型建立的方法来看,模型发展分类包括两个特征:模拟视觉特征和视觉皮层信息表达。该模型分为视觉神经功能模拟模型和神经激活预测模型。所提出的基于脑启发的视觉目标识别模型分类如图3所示。在本章中,不仅对最先进的基于脑启发的目标识别方法进行分类,还对这些方法的主要动机和贡献进行分类,为确定未来的方向提供了有益的视角。
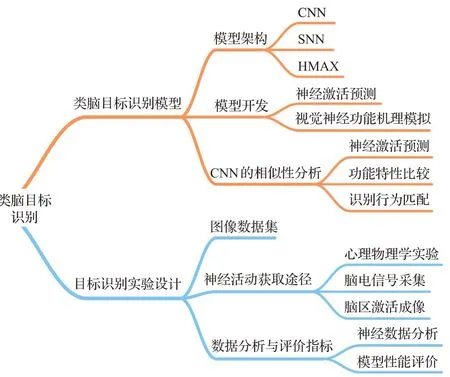
图3 脑启发目标识别的研究分类Fig.3 Research classification of brain-inspired object recognition
1.1 目标识别的生物启发模型简史
1.1.1 宏观层次模型
如图4所示,表示脑启发的视觉目标是被模型的时间轴,其中的里程碑分别为Hubel和Wiesel[2-3]、HMAX模型[4-5]、AlexNet[6]、Look and Think Twice[7]、Spaminato[8]。生物视觉系统模型的研究起始于Hubel和Wiesel[2-3]获得诺贝尔奖的工作。
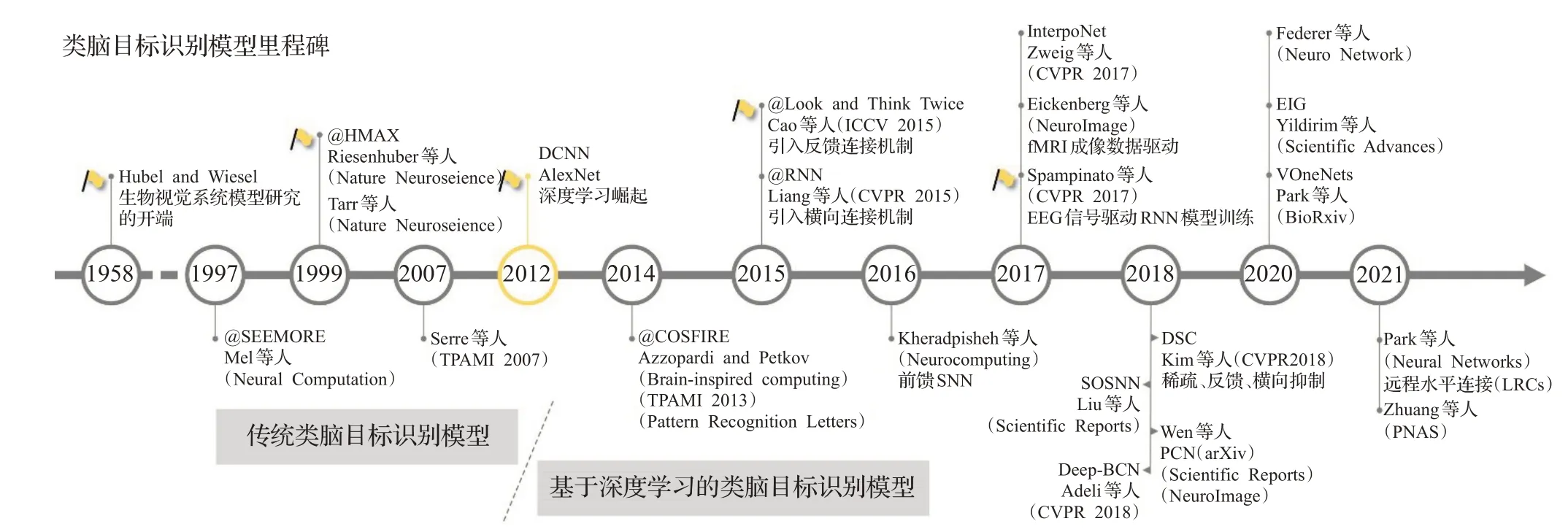
图4 脑启发的视觉目标识别模型的时间轴Fig.4 Timeline of brain-inspired object recognition model
他们的关键发现是:视觉皮层中的神经元形成一种包含局部滤波器的结构,滤波器以空间频率和方向性的成栏排列与组织。他们指出形状、颜色、运动和深度等视觉信息,是采取了既平行又分级的串行信息处理方式,从视网膜、外侧膝状体、V1区、V2区到V4区的视觉通路流动。基于视觉感知机理的分层结构模型则是根据上述生理结构以及视觉感受野理论提出的。
Mel[9]在1997年结合视觉系统的并行处理机制提出了一种前馈等级结构的SEEMORE模型。该模型兼顾了颜色、形状、纹理等102种特征,提高了识别的准确性和健壮性。但是每个特征通道对图像单独进行一次运算,导致运算量过大。Rybak等人[10]首先于1998年提出了著名的Rybak模型,该模型主要用于场景感知和物体识别。其包括三个子系统,低层子系统模拟视网膜中央凹的特性,将原始图像进行初级变换并检测对应的初级特征;中层子系统主要对初级特征集进行变换以获得具有一定不变性的二级特征;最后高级子系统通过分离的“what”结构(感觉记忆)和“where”结构(动作记忆)实现目标识别。模型存在的缺陷是它是基于符号表示的,并注重复杂的视觉搜索语义问题。
HMAX模型最先由Riesenhuber和Poggio[4]在1999年提出。该模型总结了灵长类动物的视觉皮层腹侧视觉流的要点,尝试通过研究大脑区域的层次特征模拟视觉皮层的目标识别过程。HMAX模型总结了灵长类动物的视觉皮层的腹侧视觉流的要点,通过研究大脑区域的层次特征模拟视觉皮层的目标识别过程。HMAX的体系结构由四个层次的计算层组成,命名为S1、C1、S2和C2,其中简单的S单元与复杂的C单元[11]交替使用。S单元和C单元的设计灵感分别来自于简单细胞和复杂细胞的特性,同时,该模型的输出特征不受比例、位置和方向的影响。自引入HMAX模型以来,基于视觉显著性的注意机制和HMAX模拟哺乳动物视觉系统功能[12],被应用到图像目标识别任务当中。同时,人们提出了许多方法来开发和提高该模型的识别性能。其中一些方法专注于特定应用[13]的模型增强,还有一些方法提高了所有应用模型的一般性能[14]:基于视觉注意计算模型的启发,提出了用于物体识别的patch选择方法。还有一些研究工作基于主旨的场景识别、基于显著性的注意和基于HMAX设计物体识别模型,并将模型移植到硬件加速系统中实现[12]。该模型基于对哺乳动物大脑视觉皮层中视觉系统的理解。在这些前人的基础上,一些科研人员以灵长类为实验目标,研究其视觉皮层的工作过程,并提出了新的分层结构模型[15-16]、感受野模型[17]和注意机制模型[18]。
早期模型主要停留在模拟腹侧通路的初级视觉区域(V1和V2),忽略了更高层次视觉皮层神经机制对目标表达的重要作用[19]。2013年,Azzopardi等人[20-22]从形状选择性V4神经元的功能中获得灵感,设计了可训练的视觉模式识别滤波器COSFIRE,可以检测线、顶点和更复杂的轮廓特征。通过选择一组定向选择性滤波器的给定信道,并通过加权几何平均值组合响应配置COSFIRE,使其对形成给定原型模式的线条和边缘的空间安排具有选择性。同时,COSFIRE滤波器实现了旋转、尺度和反射不变性。
1.1.2 神经元微观模型
以上的模型研究致力于视觉功能模拟的类脑计算,但是与人类视觉依旧存在较大的差距。2004年,Deco等人[23]提出了一种神经元处理意义上的模型,该模型通过模拟来自后顶叶或颞叶皮层(IT)的自上而下的注意力反馈,以及V1和V2区中两视觉通路的相互作用,实现基于空间和基于目标的视觉搜索。研究发现了神经元群体的交错连接构成神经网络,并受此启发构建了具有自适应性单神经元组成的逐级并行互联的人工神经网络(artificial neural network,ANN)[24]。进一步发展的深度神经网络学习大量样本的内在规律和层次表征,其在计算机视觉领域取得了巨大的进步。深度神经网络使用的计算概念可以追溯到Hubel和Wiesel[3]的灵长类动物视觉系统的早期模型,他们假设在初级视觉皮层中存在更复杂的功能反应(“复杂”细胞)是由更简单的响应(“简单”单元格)构建。深度神经网络的层次化结构借鉴了人脑中前馈视觉表征的层次化结构。主要思想是从训练数据中学习各层的呈现形式,在进行参数优化时使用监督或非监督学习。层次卷积网络的关键在于学习一系列具有层级体系的滤波器组,这些模型的深度导致了有相当数量的参数需要学习,以及需要解决复杂的非凸优化问题。然而,目前的神经网络(CNN、SNN)已逐渐远离生物学主题,这主要是由于过去几年的工程突破已经改变了计算机视觉领域。神经网络的进一步工程设计已达到饱和点、层数、激活函数、参数调整、梯度函数等方面的新颖性带来的准确性提高幅度较小。尽管有证据表明在某些狭义的任务上目标分类已经达到了人类的水平[25],但对于一般应用而言,生物视觉系统要远远优于任何计算机。
1.2 模型架构
尽管CNN已经广泛应用于基于深度学习的目标识别方法,近年来,其他结构也用于模拟大脑视觉目标识别机制,提高识别准确率和鲁棒性。根据模型框架的不同,分为基于CNN、基于SNN和基于仿生突触的模型。
CNN-based模型是一类包含卷积计算且具有深度结构的前馈神经网络,具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,卷积神经网络仿造生物的视知觉机制构建,由S层(simple-layer)和C层(complex-layer)交替构成网络的层级结构。但是其神经元结构进行了简化和抽象,与视皮层的神经元特性相去甚远。SNN-based模型精确地建立基于脉冲产生时间神经网络模型,这种新型的神经网络采用脉冲编码,通过获得脉冲发生的精确时间,获得更多的信息和更强的计算能力。同时,脉冲网络的神经元在膜电位达到阀值才被激活,相较于CNN-based模型,其模拟神经元的特性更加接近实际。其中,每个类别中按照开发模型的不同方式进行分类,包括神经激活预测和神经功能机理模拟两个方面。
1.2.1 基于CNN的模型
最近的基于深度神经网络的目标识别模型都在试图复制灵长类动物视觉系统中观察到的神经机制和功能特性。这些模型中使用的计算概念可以追溯到Hubel和Wiesel[3]的灵长类动物视觉系统的早期模型。生物视觉模型通过暗示更高的视觉区域概括了这种机制并形成了等级结构,从而扩展了这一假设[4,9,26-29]。在过去的几年中,已经产生了一系列利用深度神经网络的视觉目标识别系统,并在计算机视觉基准上取得了最先进的性能[24,30-31]。卷积神经网络(CNN)框架最近的成功很大程度上归功于其大脑启发性的体系结构,类似于Hubel和Wiesel[3]描述的简单和复杂的细胞层次结构。因此,大量的研究人员通过获取灵长类动物大脑信号,指导和设计DNN模型模拟脑视觉神经机制,实现类脑目标识别。因此,基于CNN的类脑目标识别模型根据以下方式分类。
视觉神经功能机理模拟:视觉系统的信息处理过程被认为是复杂的行为目标识别能力的基础,模型也必须在性能指标上与其相匹配,在目标识别任务上等于或超过视觉皮层的性能。在这里,为了实现模拟视觉信息处理和神经机制并构建类脑目标识别模型的目标,研究人员通过观察和联想信息处理的过程设计视觉认知水平上的目标识别模型,而不必同时处理其执行在神经活动上可信的成分,如表1中的方法所示[32-39]。这一类模型抽象、简化了部分视觉功能机理,即使是一种连接机制也可以用神经网络模型捕获。

表1 模拟视觉系统功能机理的CNN类脑目标识别模型Table 1 CNN-based brain-inspired object recognition models based on functional mechanism simulation of visual system
(1)模拟视觉皮层目标感知能力从而提供稳定的目标表征:结合初级视觉皮层自上而下的影响在轮廓整合和视觉显著性过程中发挥的重要作用[40]。反馈连接机制也参与视觉目标特征提取过程,Karimi-Rouzbahani等人[41]建立网络模型整合这一研究成果。还有部分研究[42-43]在建立脑启发的深度网络模型进行训练视觉目标识别的过程中,自发的产生了数字选择神经元,解释了基于视觉系统固有机制的数字感的自发出现。
(2)模拟神经反馈连接机制:反馈机制作为最先引入基于CNN模型进行改进的方法,模拟视觉皮层自上而下的影响,显著提高了传统的前馈架构的识别性能。Cao等人[7]受到人类视觉皮层中的反馈机制的启发,最先提出一种反馈卷积神经网络体系架构,保持前馈阶段不变,通过共同推理类节点的输出以及在反馈循环期间激活隐藏层神经元实现分类。后续的研究者[32-33,36,41]普遍都采取了自上而下的反馈机制增强标准的前馈深度模型,即便还添加了其他的连接机制。
(3)模拟神经元横向连接机制:视觉皮层中丰富的循环(横向)连接在环境调节中起着重要作用[44]。鉴于CNN模型是典型的前馈结构,Liang等人[45]根据视觉系统中具有丰富的循环连接,提出一种循环CNN(RCNN)框架(神经科学领域常用横向连接),通过将循环连接合并到每个卷积层中进行目标识别。这一特性增强了模型整合上下文信息的能力,这对目标识别非常重要。之后很多研究人员考虑到了缺乏横向连接的CNN结构与生物目标处理严格地区分开来,在网络学习过程中引入递归连接结构修改经典的CNN结构。Zweig等人[32]从视觉皮层的填充过程受到启发,将神经元之间的横向依赖性和多层监督引入网络学习过程,显著提高性能。其后有更多的研究者通过引入横向抑制[33]、横向连接[36]的方式修改经典的CNN架构,在网络中引入自底向上和自顶向下计算的递归循环,更新其内部表示,减少每层自底向上输入和自顶向下预测的差异。Park等人[39]发现并模拟了视觉皮层中的远程水平连接(LRCs)机制并添加到浅层前馈网络中,实现在浅层层次深度的物理约束下的目标识别,进一步挖掘了横向连接机制的在目标识别任务中的性能。
(4)注意力控制:物体检测是由注意力控制机制介导的,认为物体检测是由注意力控制机制介导的,计算机视觉和生物视觉在本质上具有相似性。利用这种共性,Adeli等人[34]将基于CNN的网络结构与灵长类注意力控制系统的注意偏见竞争(BC)理论融合,使用注意力启发的深度网络(DNN)预测人类的目标定向行为。还有研究使用类别一致特征(CCFs)表示目标类别设计的基于灵长类腹侧流的卷积神经网络(VsNet)可以通过提取和使用类别一致的特征预测目标导向的注意力控制[35]。
神经激活预测:另一种可能的解决方案是采用逆向工程的方式,即通过神经生理学或神经成像技术记录大脑神经激活数据,进而识别大脑用于视觉分类的特征空间。与此相关的是,较高的视觉神经通路也被认为是复杂的行为目标识别能力的基础[46-47]。很多研究人员通过建模的方式在性能指标上匹配视觉皮层,一个在视觉皮层中具有完美神经预测能力的模型必然会表现出高性能。因此,结合fMRI和EEG等技术,大量研究工作探索了多种生物学上可信的层次神经网络模型,根据测量的视觉神经反应数据对它们进行评估。如表2的最新研究结果表明[8,48-55],在一个具有挑战性的视觉目标识别任务上,基于CNN架构的目标识别模型的表现与其预测视觉神经单元反应的能力之间有很强的相关性。尽管这些模型没有明确地限制在匹配神经数据上,但输出层能够高度预测视觉皮层的神经反应。下面从神经激活信号获取途径的角度对类脑目标识别模型进行分类。
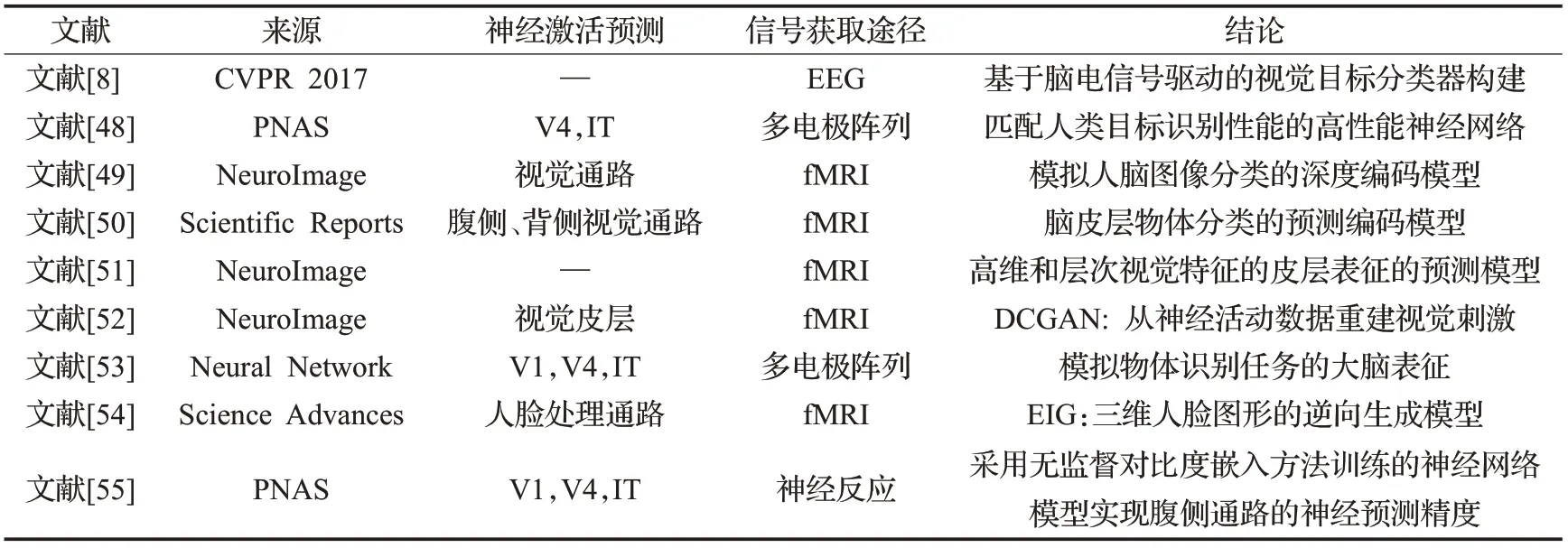
表2 基于神经激活预测的CNN类脑目标识别模型Table 2 CNN-based brain-inspired object recognition models based on visual neural activation prediction
(1)基于BOLD fMRI技术:功能磁共振成像(functional MRI)是一种非常有效的研究脑功能的非介入技术,已经成为最广泛使用的脑功能研究手段。通过显示大脑各个区域内静脉毛细血管中血液氧合状态发现脑区激活部位,实现大脑活动的功能定位。同时,由于CNN模型的表现与其预测视觉神经单元反应的能力之间的相关性,因此,大量的科研团队借助fMRI技术生成的大脑活动信号映射到基于CNN架构的预测编码模型,使用图像识别驱动的人工网络模型模拟视觉皮层的目标识别性能。Eickenberg等人[49]利用卷积网络的层次组织识别目标,通过构建基于不同层次和BOLD fMRI激活的预测模型模拟人类大脑活动。为了解决大脑分布式视觉表示如何实现目标分类的问题,Wen等人[50]建立了基于深度残差网络的预测编码模型,其以高通量和准确性将皮层映射到的视觉目标涵盖了腹侧和背侧通路,反映了目标特征的多个级别,同时还保留了类别之间的语义关系,以预测对自然动作的皮层反应。针对较少的研究目标得到的实验结果在整个人群中推广的困难,还提出一种针对受试者和人群的高维和层次视觉特征的皮层表征预测DNN模型,使用图像识别驱动的深度残差神经网络模拟视觉皮层处理[51]。Seeliger等人[52]基于BOLD fMRI的大脑活动信号预测生成模型的潜在空间,探索了使用深度卷积生成对抗网络(DCGAN)[56]重建任意自然图像的能力。以上的模型开发虽然解决的问题略有差异,但是都具有共同的特征:基于fMRI视觉功能数据的CNN模型关注于视觉皮层表征预测,通过被试在自然图像刺激下采集到的fMRI视觉功能数据,利用fMRI数据以及刺激图像构造、优化和训练深度卷积神经网络模型,提高基于CNN模型的目标识别准确性。
(2)基于脑电信号采集技术:脑电图是脑神经细胞群的电生理活动在大脑皮层或头皮表面的总体反映。视觉皮层的脑电波中包含了大量视觉信息处理过程的表征,通过对脑电图信号进行分类探索直接的人类参与形式,学习一种视觉类别的大脑信号鉴别流形,用于自动视觉分类。通过对脑电波的采集和处理,可以为类脑目标识别模型的构建提供依据。最新的一些研究[48]结合高通量计算和电生理技术,提出了一种可以生成定量的下颞叶(IT)皮层(最高腹侧皮层区域)层次神经网络模型,该模型在视觉目标识别任务上的性能与其预测单个IT神经单元响应数据的能力之间存在很强的相关性。Federer等人[53]使用多电极阵列采集神经活动的统计属性作为训练DNNs的指导信号,模拟大脑对物体识别任务的表征,观察到所有的训练网络都得到了性能提升,包括较小的(CORNet-Z)架构与较大的(VGG-16)架构,证明了这种方法的潜在效用。Spampinato等人[8]开发了由人脑信号驱动的视觉目标分类器,利用由视觉目标刺激诱发的脑电图数据结合递归神经网络(RNN)学习进行视觉类别的判别性大脑活动流形,并基于此,发布了用于视觉目标分析的最大的EEG数据集。借助脑电信号技术具有较好的时间分辨率的特性,利用由视觉目标诱发的脑电图数据“指导”深度神经网络的构建与学习,开发由人脑信号驱动的视觉目标分类器,一方面可能为人类视觉感知系统提供有意义的见解;另一方面,这一新的生物启发方式对计算机视觉方法的影响是巨大的,可能从根本上改变目标分类器的发展方式。
综上所述,虽然现有的基于CNN架构的类脑目标识别模型在视觉功能模拟和神经激活预测方面都具有优异的表现,但仍然有一些主要的局限性:一个受监督的框架必须使用大型手动标记的训练集对其训练。同时,缺乏一个正式的框架引入更高层次的抽象——用于对不同目标和概念一起出现的场景进行上下文理解,这是发展一个强健的视觉框架所必需的。另一方面,生物视觉系统基本上是无监督的学习系统,可以基于熟悉程度和在不同环境中反复的视觉刺激学习高度灵活的目标模型。其次可以在各种规模下检测学习到的目标,并且保持很高的分辨率和计算效率。因此,探索生物系统和深度卷积神经网络之间的潜在协同作用仍然是一个令人关注的话题。
1.2.2 基于SNN的模型
通过生物可解释的方式建立人工神经系统,科学家希望可以通过神经科学和行为实验达到预期目的。大脑中的学习可以理解为突触连接强度随时间的变化过程,这种能力称为突触可塑性。为了设计更具有生物学合理性的计算模型,神经可塑性在自组织中的作用及其对神经网络完成分类任务学习性能的影响越来越受到关注。SNN作为第三代神经网络,正是这种基于脉冲时间层次的学习方法研究,其模拟神经元更加实际,同时考虑了时间信息的影响,这对于通过理论模型验证生物神经系统的信息处理和学习机制是必须的。
与传统的人工神经网络相似,脉冲神经网络同样分为功能机理模拟和神经激活预测,如表3所示[57-62]。在功能机理模拟方面,引入突触神经机制模拟神经元的学习规则。由于视觉皮层通过不同的神经连接结构和接受野实现快速的物体识别,这种不均匀性是通过神经可塑性过程的自组织进化而来的。并基于此,Liu等人[57]提出了一种层次自组织尖刺神经网络(SOSNN),该网络模拟人体腹侧通路的结构和功能组织,应用了突触可塑性、稳态可塑性和侧抑制等多种神经机制。同样,Liang等人[63]动态调节脉冲的时间依赖可塑性学习规则构成模拟区域的神经元之间的兴奋性和抑制性连接。同时,受脑皮层-纹状体环机制的启发,构建了时序信息编码的依赖时序模块。Kheradpisheh等人[59]提出一种生物启发的异步前馈SNN,较高层的神经元具有脉冲时间依赖可塑性,这些神经元逐渐成为选择中等复杂性的视觉特征适合目标分类。Liu等人[61]提出了一种分层尖峰神经网络(HSNN)模拟人脑腹侧通路的视觉信息处理,同时该模型引入了侧抑制、内稳态(适应阀值)和不应期等生物机制,证明了生物启发的网络结构和生物机制的结合可以显著提高模型的性能。Song等人[62]整合高级突触学习,提出基于脑启发的无监督匹配追踪编码方法,设计了一个用于图像识别的统一SNN框架。该方法使用较少的神经元和峰值,实现了当时最佳的基于时间的精度性能。此外,还有一些研究基于反馈机制的学习规则开发的小样本学习SNN[15]。在神经激活预测方面,Doborjeh等人[64]提出一种基于脉冲神经网络(SNN)模型学习脑电/ERP数据的深度时空模式。该模型表现出熟悉的刺激具有更强的连通性和更广泛的动态时空模式,支持了SNN模型可以作为探索脑感知机制的新工具。还有研究[58]通过修改的脉冲神经网络证明了该时间模型更好地反映了人类在物体识别任务中的准确性,并预测了人类在物体识别上的反应时间。

表3 基于SNN的类脑目标识别模型Table 3 SNN-based brain-inspired models for object recognition
然而,当前深度学习的成功浪潮并不包括任何峰值的概念,而是通过网络以离散时间步长传播标量值的“激活”。即使在神经科学领域,虽然没有人怀疑神经元中存在许多时间依赖的现象(如尖峰时间依赖的可塑性[65]),但关于了解详细的脉冲神经网络对理解感觉编码是否至关重要,仍存在大量争论[66]。而理论神经科学的一个日益增长的分支领域正在使用生物神经动力系统和统计力学的工具描述和理解相互关联的峰值神经元群体的行为[67]。虽然可以肯定地说,脉冲神经网络迄今为止从未作为机器视觉领域的佼佼者参与进来,但随着理论和可用计算能力的发展,这种情况可能很容易改变。
1.2.3 仿生突触
通过引入能够识别视觉目标,并以一种认知的、类似人类的方式与外部世界互动的机器,大脑启发的视觉计算可以彻底改变信息技术。要实现这一目标,除了需要对大脑的神经计算模式有一个详细的了解,其次需要确定一种可扩展的微电子技术,能够复制一些人类大脑固有的功能,如高突触连通性(104)和特殊的依赖时间的突触可塑性。在详细研究大脑视觉系统的功能特性的同时,一种可编程逻辑器件的构造思路——基于忆阻器交叉阵列的突触设计。这种计算装置就是试图通过尽可能微型的元器件模拟神经元,进而实现与大脑神经元相似的连接模式进行类脑计算。这种能够复制大脑神经突触的固有功能的类脑计算机,结合类脑视觉目标识别模型的开发,为未来达到甚至超越人类视觉系统性能的硬件实现带来可能。目前已经有研究团队在Pedretti等人[68]通过一个具有记忆性突触的无监督学习和跟踪神经网络复制部分人类大脑固有的功能,其中突触权重通过大脑激发的放电时序依赖可塑性(spike timing dependent,STDP)更新。在一个混合单晶体管/单电阻(1T1R)记忆性突触内,突触电导通过突触前和突触后的局部时域叠加而更新,突触的高低阻状态可以满足学习和识别模型。基于成熟的短期突触可塑性(STP)模型,Berberian等人[69]开发了一个由尖突神经元组成的微电路基序,诱发大量单位表现出初级视觉皮层(V1)所观察到的典型皮层方向选择特性。然后将该模型的视觉反应与V1多电极记录进行比较,验证了STP可以作为解释来自V1的方向选择性的补充机制。
以上,主要考虑了三种技术架构的类脑目标识别模型,可以帮助人们从大脑活动数据中提取、模仿视觉目标识别能力。可以分析总结出,基于CNN的模型和基于SNN的模型共同点在于模拟视觉皮层的层次结构特性,同时抽象和模拟了神经元的功能特性,在视觉特性和识别能力上都具有一定的生物可信度。差别在于SNN-based模型更加细化神经元模型,采用膜电位的累积效果激活神经元。CNN-based模型具有易训练和结构灵活多变的特性,导致CNN的发展已经逐渐脱离生物学的主题,其改进模型更契合于实际工程应用。此外,文献中介绍的目标识别模型可以驻留在不同的描述层次,在认知水平和神经激活水平之间进行权衡。仅捕捉神经元成分和动态的模型往往无法解释视觉认知功能。相反,只捕捉视觉认知行为的模型很难与大脑联系起来。为了将思维和大脑联系起来,模型必须试图捕捉行为和神经元动力学方面内容。
2 深度神经网络与视觉皮层的相似性分析
人类的视觉物体识别是由复杂的多阶段视觉信息处理过程实现的,这些视觉信息是在一个分布的皮层区域网络中快速出现的。因此,理解皮层中的视觉目标识别需要一个预测和定量的模型,该模型能够捕获潜在时空动力学的复杂性。最主要的挑战是执行目标识别任务的计算模型与目标识别过程的大脑神经激活或行为表现数据之间建立坚实的桥梁。这样一个模型与视觉皮层的相似性判断关键在于中、高级视觉区域神经调谐特性的高度非线性和稀疏性质[70-72],这很难在实验中捕捉。
一种新兴的文献开始用大脑活动数据测试目标识别模型,特别是深度神经网络模型。最近的一些研究多项功能性磁共振成像(fMRI)研究表明,卷积神经网络在视觉信息处理方面预测了灵长类动物腹侧视觉流中图像信息的表征[3,73]。然而,深度学习方法是否达到或者超过了大脑视觉性能,目前并没有统一的结论。本文这一部分描述了从实验数据向计算模型建立联系的自下而上的发展,将重点关注最近在目标识别任务上成功的模型,这些模型分别从神经激活、功能机理和行为表现三个角度解释了视觉目标认知功能。为了保证视觉皮层预测的准确性,在实验过程中被试的刺激集与模型的测试集均保持一致(如果模型需要训练的话)。值得说明的一点是,与1.2.1小节中基于CNN的目标识别模型的本质区别在于,本节所总结的研究成果是将在目标识别任务中表现优异的已有模型或架构(例如基于CNN的模型、基于HMAX的模型)与脑视觉系统的神经活动或行为表现进行对比分析,目的是探索人工网络与人类视觉皮层的神经激活表征相似性,验证与人类视觉系统的目标识别性能一致性,而不是构造了一个全新的模型。
2.1 神经激活预测
从详细的脑信号测量到脑视觉信息处理的理解,一直是突出的。人们通过测量和建模视觉神经动力学实现对大脑视觉目标识别的理解,从细胞层次的信息描述到更大规模的识别行为表现。为了与人工神经网络相比较,与类脑目标识别建模相同,通过神经激活信号采集的方式表达人类大脑中物体表征过程与DNN的处理阶段之间的有序关系。
CNN是目前计算机视觉目标识别基准上表现最好的模型,并在目标分类方面达到人类的表现水平。
由表4所示[48,74-82],最近的神经影像学研究比较了CNN输出和视觉腹侧通路的相似性分析。有研究[51]发现早期视觉皮层(V1)和CNN的早期层编码形状信息,颞前腹侧皮层和CNN的最后一层对类别信息进行编码,人类视觉的腹通路与多个深度网络均发现了形状和类别之间的相互作用。同时,具有中央选择性和图像背景选择性的模型单元分别对具有中央偏向和外周偏向的大脑视觉区域表现出强烈的表征相似性[75],这些层次对应关系说明目标分类的DCNN模型是生物神经网络产生感知表征的良好近似。Agrawal等人[79]探索了基于Fisher向量(FV)和CNN的模型都能准确地预测高级别视觉区域的大脑活动,直接从像素出发,而不需要任何语义标签或图像的手动注释。还有一些研究是将基于CNN的编码模型与脑磁图(MEG)结合的方式探索CNN模型与大脑信号之间的对应关系,同样发现了层次网络模型中的刺激表征与视觉腹侧流不同部位的空间对应关系[76],以及模型中处理过程的各个阶段与目标在人脑中呈现的时间进程之间的时间有序关系[77]。
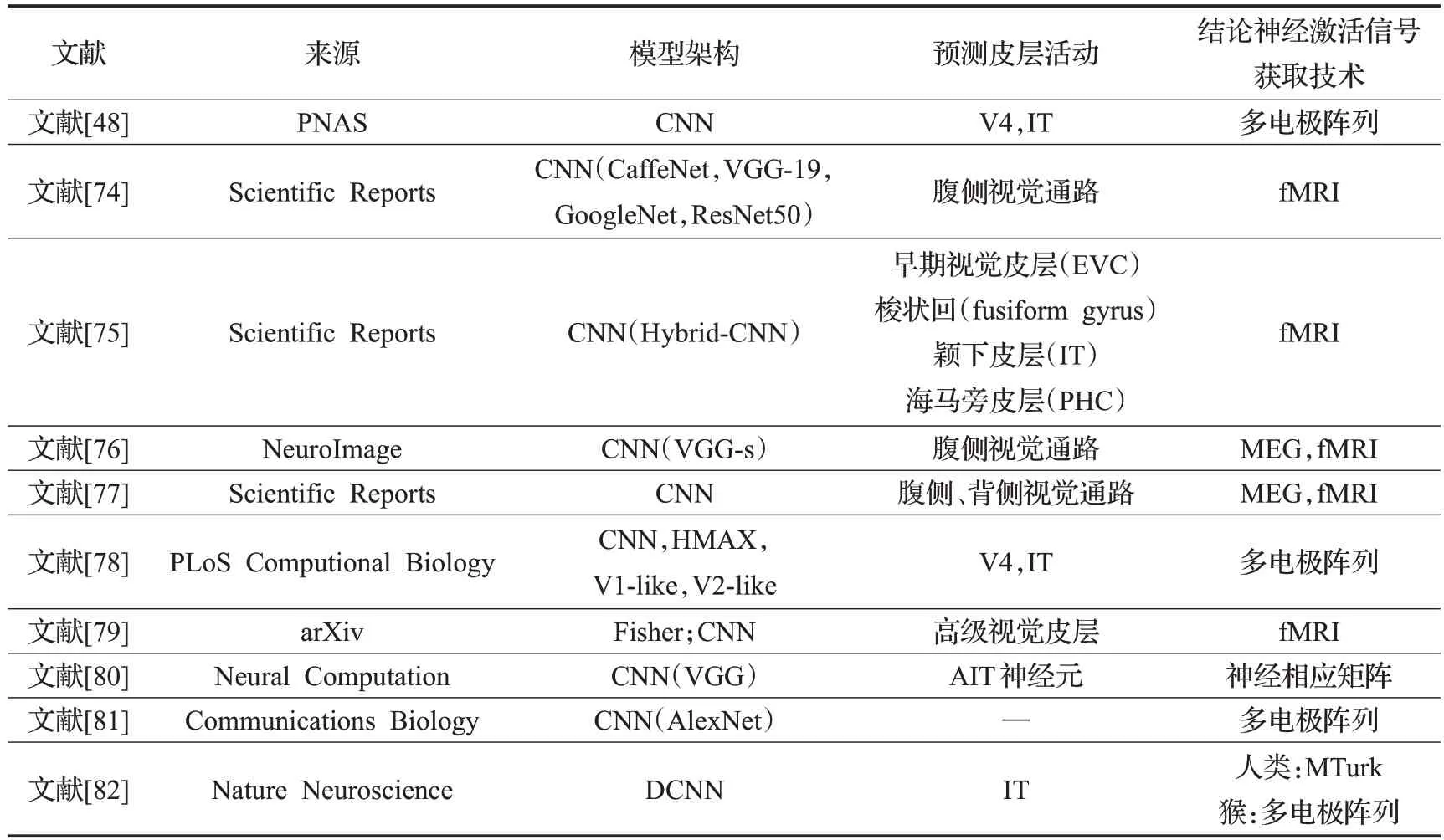
表4 测量CNN模型对视觉神经激活的预测精度研究Table 4 Research on measuring prediction accuracy of CNN-based models for neural activation
此外,部分研究工作利用多级阵列电生理系统,将模型表示性能与同一任务和视觉图像上的神经反应进行比较,重点关注了最新的CNN模型在视觉目标识别任务上的性能与其预测IT皮层响应数据的能力之间的相关性[48,78,82]。有研究[78]观察到性能相关性,并给出了生物学科新的实际IT神经响应模型。而前馈深度CNN激活对后期IT响应模式的预测,论证了循环回路对快速物体识别的重要性[82]。Dong等人[80]分析了图像刺激对AIT神经元的响应统计和DNN神经元在单神经元选择性和种群稀疏性上的响应统计量存在的差异。特别的是,有研究[81]使用DCNN研究沿腹侧视觉通路的复杂特征转换与频域信号的相关性,证明深度神经网络的活动在频域上也具有生物目标识别的本质特征。
2.2 反映视觉功能特性
一个综合的视觉目标识别模型不仅要产生感知结果,而且要捕捉适应的神经生理动态。广泛应用于计算机视觉的CNN模型通过一些固定的结构保证一些视觉功能特性,它们在很大程度上依赖于通过大量数据或数据增强学习其他变换的属性。然而,还不清楚编码这些内在属性的人工模型是否与人类视觉系统相一致。
表5展示了最近的研究通过关键的神经生理和心理物理实验评估所提出的实现类脑目标识别的计算模型是否具有人类视觉系统的功能特性[42-43,82-87]。Georgin等人[83]通过距离比较重新塑造了众所周知的知觉和神经现象,并且分析了为物体识别而训练的前馈深度神经网络对这些现象的存在情况。部分现象在训练网络中是缺乏的,如三维形状处理,表面不变性,遮挡,自然部分和全局优势。这些对比发现为改进深层网络的特性提供了线索。Vinken等人[84]通过视觉处理的前馈深度神经网络模型捕获自适应现象的内在抑制机制,结果表明了内在抑制的前馈传播改变了网络的功能形态,复制了适应的关键神经生理和知觉特性。由于目标识别行为被由密集循环的下颞叶皮层(IT)支持,Kar等人[82]通过前馈深度CNN激活对后期IT响应模式的预测,浅层的循环CNN能更好地预测这些晚期IT反应,论证了循环回路对快速物体识别至关重要。Han等人[86]通过实验测试结果指导神经网络建模应该通过神经元的感受野大小和采样密度捕捉到的偏心相关表示,以及编码不同的尺度通道,内置尺度不变性功能。Hong等人[87]系统地探索了多个腹侧视觉区域支持各种“类别正交”物体属性的能力,发现下颞种群编码所有测量的类别正交目标属性,比早期的腹流区域更明确。同时,他们基于简单计算原理的层次神经网络模型解释了这种跨区域层次结构。可以发现,尽管目前的卷积神经网络在许多方面与生物视觉不同[88]但它们构成了一个合理的一阶近似建模腹侧流处理,使得沿着腹侧视觉流显示与神经元表征相似的内部特征表征[48,78]。并为建立一般和全面的适应模型提供了一个合适的契机。
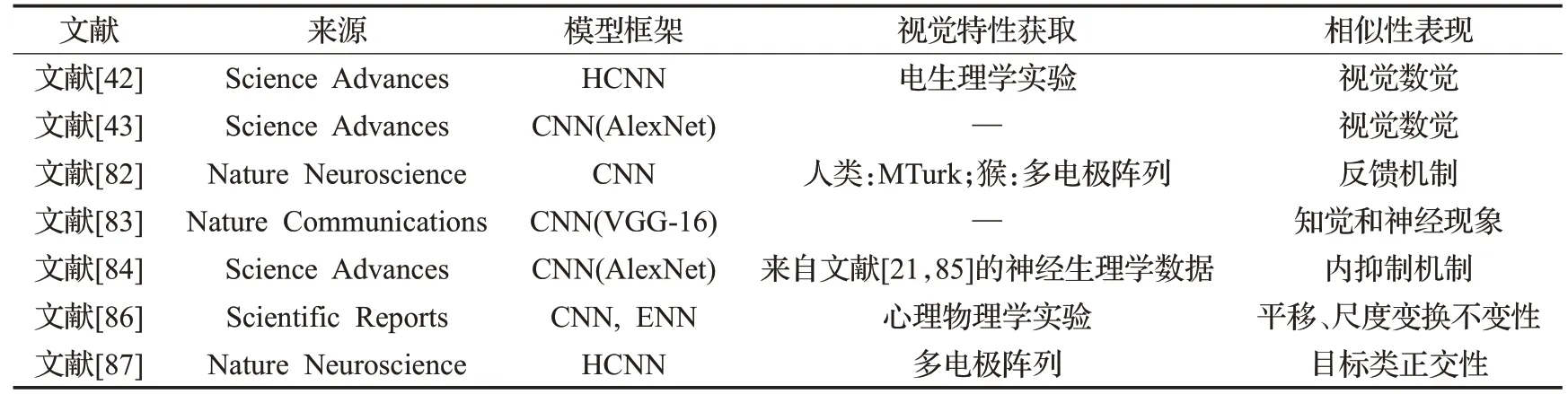
表5 测量CNN模型反映视觉功能特性研究Table 5 Research on verifying visual neural mechanism of CNN-based models
2.3 识别行为表现的匹配程度
同样,人脑的目标识别行为表现是否与模型的行为模式相一致,最近的心理物理研究对这一方面进行了多方面的探索,如表6所示[41,89-93]。为了寻求计算机系统和人脑使用的计算模式是相似的还是不同,Ullman等人[90]通过结合一种最小可识别图像的新方法和仿真表明,人类识别系统的特征提取和学习过程。并且展示了在非最小图像中,图像的微小变化会对其识别产生巨大影响。为了验证深度卷积神经网络(DCNN)在视点不变的物体识别任务中是否与人类的表现相匹配,Kheradpisheh等人[91]对8个当时最先进的DNN、HMAX模型和基线浅模型进行了基准测试和比较,发现视点变化的幅度决定了DNN的网络深度,以匹配人类的性能和错误分布。因此,基于CNN的模型的行为模式与灵长类动物的行为模式相似[89,91],可以为灵长类核心物体识别的行为表现提供定量解释。Rajalingham等人[89]使用灵长类视觉的主要机制模型(DCNNIC)与灵长类的行为特征进行比较,发现现有的DCNNIC模型不能解释灵长类动物的图像级行为模式,而且不是由简单地模型修改所解释,需要更精确的网络模型捕捉灵长类动物目标视觉的神经机制。为了证明人类和机器的性能差距是否是由于目标表示的系统差异造成的,部分研究的实验结果展示出所有的计算模型都显示出了感知的系统性偏差,揭示了计算机视觉算法中缺失的关键元素,并指出了大脑高级视觉区域对这些属性的明确编码[92]。
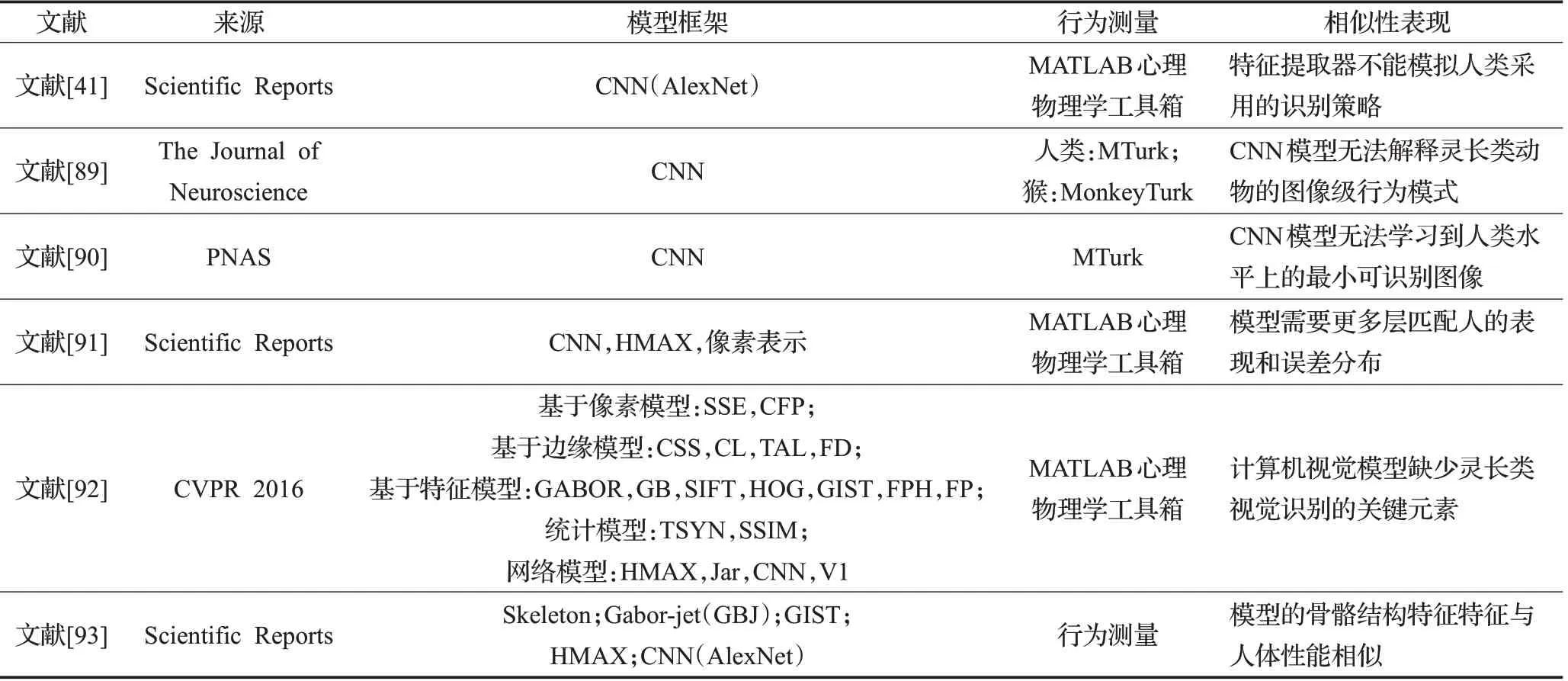
表6 评估CNN模型匹配灵长类识别行为表现Table 6 CNN models for achieving primate recognition behavioral performance
综上所述,基于CNN的目标识别模型与人类视觉系统在神经预测、神经机理特性和识别行为表现等方面都具有一定的相似性表现,深度神经网络模型单元编码的特征是由一组丰富的、为目标识别优化的、日益复杂的特征组成,这与灵长类动物腹侧流[48,78]的神经元编码的特征相当吻合。其次,在层次网络中,被训练识别目标的早期深度神经网络层包含了类似于早期视觉皮层的表征。当沿着腹侧视觉流移动时,神经网络需要复杂的多层模型捕捉层叠的适应[94]。但是人类与当前深度神经网络的一个重要的区别在于所需训练集的规模大小。人类可以通过短暂的视觉信息中准确地学习到复杂的视觉目标类别[95]。相比之下,目前基于CNN的模型需要大量数据才能工作。
3 脑视觉实验条件与方法
无论是开展人脑目标识别神经机理研究,或是构建大脑启发的目标识别网络或模型,需要引入灵长类动物脑实验设计方法,对视觉系统的功能机理或神经激活进行提取,定量描述视觉通路的神经机制。实验开展首先对刺激集选取有一定的要求,其主要动机是选择统一、多样的视觉目标图像激发灵长类动物识别行为表现或视觉皮层的神经反应。接着,脑信号获取途径旨在有效的测量用于被试。他们的一般动机分为定量测量被试的行为表现或神经反应(例如,fMRI、EEG、心理物理学实验)。最后,对获得的脑视觉目标识别反应的测量数据进行统计分析,其主要分为表征相似性分析、统计分析、分类准确性、相关性。下面从图像数据集选取、脑信号获取途径以及数据分析方法三个方面对目标识别神经机理研究方法和类脑目标识别建模方法进行综合分类。
3.1 图像数据集
根据第2章分析可知,视觉通路上的各个脑区在视觉目标识别过程中产生的神经活动和功能机理各不相同,因此,图像数据集的选取与需要探究的视觉神经机制具有较强的相关性,这些脑视觉目标识别的神经机制研究方法所采用的刺激集依据实验目的而定。按照获取的途径进行分类如下所示。
视觉刺激集:大多数研究灵长类动物的视觉目标识别的神经机制,通过视觉刺激输入分析脑神经激活状态或识别行为表现。其中,根据实际研究的神经机制和方法,采用公开的彩色图像数据集或互联网收集的方式建立视觉图像刺激集,有针对性地诱发出可识别的、具有特征性的神经活动或识别行为表现。
(1)根据实际研究的视觉神经功能机理自建数据集:文献[49],[51],[74],[75],[81],[86],[89],[91],[92],[96],[97],[98],[99],[100],[101],[102],[103],[104]。
(2)基于已有的计算机建模软件生成(如表7所示):文献[1],[41],[78],[82],[93],[105],[106],[107],[108]。

表7 基于计算机模型软件生成视觉刺激集Table 7 Generate visual stimulus sets based on computer modeling software
(3)采用公开数据集:文献[85],[109],[110](hemera photo objects);文献[111](Radboud[112]);文献[41](3D car mesh models);文献[113],[114](LabelMe[115]);文献[116](super formula[117]);文献[118](PICS);文献[119],[120](Snodgrass and Vanderwart normed set);文献[121],[122](a standardized set of 260 pictures[123]);文献[124](Kriegeskorte[125]);文献[102](PrimFace);文献[82],[108](COCO[126]);文献[127](Caltech-256[128]);文献[48](neural representation benchmark[129]);文献[7](ImageNet[130]);文献[52](GRAINS、vim-1、generic object decoding[131]);文 献[58](Caltech 101[132]);文 献[53](CIFAR100[133]);文献[84](quick,draw!);文献[83](IISc Indian face dataset[134]);文献[76](BOSS[135]、ALOI[136]);文献[90](PASCAL[137]、ILSVRC2015);文献[79](ImageNet、PASCAL、SUN[138])。
根据脑视觉神经功能机理模拟方式设计数据集:一部分模拟神经连接机制设计人工网络模型,与一般网络设计采用的数据集相同;另一部分方法为了最大限度地模拟在生物学上可信的目标识别模型,使用了同一个数据集作为实验被试的刺激集和网络模型的测试集,验证人工网络模型的神经激活预测能力和目标识别性能,如表8所示。

表8 设计图像数据集模拟脑视觉神经功能机理Table 8 Datasets used to construct and validate brain-inspired visual object recognition models
比较人工模型与大脑视觉通路的功能特性采用的数据集:为了最大限度地模拟在生物学上可信的目标识别模型,表9所示的方法使用了同一个数据集作为实验被试的刺激集和网络模型的训练集。视觉神经系统和人工神经网络共享同一个数据集进行训练,主要是通过保证相同的刺激输入比较表现输出或神经激活的状态。基于DNN的目标识别模型在腹侧流的神经激活预测和目标识别表现都具有一致性。由表可以发现,所有参与比较的模型均采用大型ImageNet数据集进行预训练,目的是对模型通过大型数据集的训练以尽可能逼近人类的目标识别和分类能力,进而预测其中可能存在的神经机制和行为表现。

表9 比较人工、生物神经系统功能特性选取的数据集Table 9 Datasets selected for comparing functional characteristics of artificial and biological neural systems
用于视觉目标分类或识别数据集之一,MNIST[142]是机器学习领域中非常经典的数据集,包括60 000个训练样本和10 000个测试样本,其中的训练集由来自250个不同人手写的数字构成,测试集(test set)也是同样比例的手写数字数据。PASCALVOC(pattern analysis,statistical modelling and computational learning,visual object classes)为图像识别和分类提供了一整套标准化的优秀的数据集,它包括20类物体,从2005年到2012年每年会举行一场图像识别竞赛。在目标分类、图像分割网络对比实验与模型效果评估中被频频使用。SVHN[147]是一个真实世界的图像数据集,来源于谷歌街景门牌号码,常用于开发机器学习和目标识别算法。与MNIST具有相似的风格,但包含更多的标签数据(超过60万数字图像),并来自一个明显更难、未解决的真实世界问题(识别自然场景图像中的数字)。CIFAR10/100数据集(2009)[133]是包括8 000万张微型自然图像数据集,其中CIFAR数据集又根据所涉及分为
CIFAR-10和CIFAR-100,这些类间是完全互斥的。该数据集主要用于深度学习的图像分类,目前已被广泛应用。Caltech 101数据集[132]是加利福尼亚理工学院收集整理的图像物体识别数据集,包含有101类视觉物体,每个类别中最小包含31张图片。Caltech 256数据集[128]是Caltech-101的改进版,图片被分为256类,每个类别的图片超过80张,其中的部分类别包含了Caltech-101的图像。在Caltech-101的基础上,Caltech 256增加了类别数量,避免因图像旋转造成的伪影,并且引入了一个新的更大的杂波类别测试背景。
这些小的、饱和的视觉目标分类数据集大多用于视觉目标分类任务。2009年,李飞飞教授提出了用于视觉目标识别软件研究的大型可视化数据库ImageNet,旨在为世界各地的研究人员提供易于访问的图像数据。目前ImageNet共有14 197 122幅图像,总共分为21 841个类别。ILSVRC(ImageNet large scale visual recognition challenge)是ImageNet大规模视觉识别挑战赛,其中使用到的数据是ImageNet的子集。视觉神经科学家主要关注于大量的可视化的彩色自然图像,对于视觉目标分类研究和构建人工分类模型具有较好的普适度和自由度。最近的类脑目标识别模型研究中绝大多数都在使用ImageNet作为预训练数据集,并采用ILSVRC作为刺激集和测试集,得到的网络模型与大脑视觉神经反应具有较强的一致性,体现出了数据集在视觉目标识别研究中的地位。
3.2 脑视觉神经活动的获取途径
人们的视觉目标识别过程隐藏在复杂的大脑信号中,视觉神经活动的获取是视觉目标识别的神经机理研究和类脑目标识别建模的重要的阶段。借助成像等生理记录设备和视觉心理物理学的快速发展,对脑视觉目标识别的神经机制研究逐渐深入,甚至可以将大脑中的想法转化成自动目标识别设备的驱动力。根据获取方式,将视觉目标识别的神经机制和模型构建研究方法分类如下所示。
(1)心理物理学实验(生成视觉目标识别行为数据):文献[1],[82],[85],[89],[90],[96],[109],[111],[157](Amazon Mechanical Turk(MTurk));文 献[41],[86],[91],[92],[113],[158](MATLAB心理物理学工具箱);文献[93](Visual Basic(Microsoft))。
(2)BOLD fMRI信号获取实验:文献[49],[50],[51],[52],[54],[74],[75],[76],[77],[79],[97],[98],[99],[100],[101],[102],[107],[114],[116],[120],[121],[122],[158],[159],[160],[161],[162],[163]。
(3)脑电信号获取实验:EEG,文献[7],[64],[113],[119],[127];ERP,文献[64],[122];MEG,文献[76],[77],[101],[118],[124];ECOG,文献[120];multi-electrode array,文 献[48],[53],[78],[80],[81],[82],[87],[101],[105],[106],[108],[110],[164],[165],[166]。
3.3 数据分析和评价指标
为了在大规模数据集上对目标识别过程中的神经活动数据进行分析,并且与人工模型的神经元激活状态进行实验比较,本文根据数据采集方法总结了常用于数据分析和模型性能评价的方法如下。
3.3.1 神经数据分析
为了研究神经活动数据蕴含的内在神经机理,人们提出了各种数据分析的软件和方法,试图直观、准确地提取大脑目标识别的内在神经机制和功能特性。下面对这些方法进行简要介绍。
用于人脑结构和脑成像数据分析和可视化的交互式软件:统计参数图(statistical parametric mapping,SPM)[101,121,163]、VoxBo[100]、AFNI[102,107,114]、Brain Voyager软件包[99,122,158]。
多体素模式分析(multivoxel pattern analysis,MVPA):是用分类的机器学习算法(例如SVM分类器)进行多体素分析,从大量体素的BOLD信号中解码大脑的视觉信息表示,探索大脑视觉目标识别的编码机制:文献[52],[111],[116]。
皮尔逊相关系数(Pearson’s correlation coefficient):又称“皮尔逊积矩相关系数“,是一种线性相关系数如式所示,用来反映两个变量线性相关程度的统计量。该方法可用于显著性检验,视觉神经科学实验中常用来测量两个目标表示之间的相似度:文献[41],[54],[55],[79],[89],[116],[120]。
方差分析(analysis of variance,ANOVA):用于两个及两个以上样本均数差别的显著性检验。神经科学实验通过方差分析方法确定各因素的互作用效应以及对对比效应百分比的影响,通常采用两种方差分析方法:单因素方差分析(one-way ANOVA)用来研究单个控制变量的不同水平对观测变量产生的显著影响。而重复量测变异数分析(repeated-measures ANOVA)进一步确定了控制变量的不同水平对观测变量的影响程度:文献[64],[82],[85],[86],[87],[96],[100],[102],[105],[106],[107],[116],[118],[119],[121],[122],[157],[167]。
滑动t检验(student t-test):统计推断中非常常见的一种检验方法,使用t分布理论推论差异发生的概率,从而比较两个目标表示的差异是否显著。与方差分析相同,通过对神经数据或人类行为表现进行定量的统计分析:文献[82],[87],[100],[105],[116],[118],[157],[168]。
3.3.2 模型性能评价
为了反映视觉分类模型的性能,在大型数据集中测量模型对视觉图像或场景的分类精度。同时,利用相似性度量方法,试图比较视觉神经活动或行为表现与目标识别模型之间在不同因素的预测程度。
在不同的大型数据集中评价模型的分类精度或误差:文献[6],[7],[20],[32],[35],[36],[37],[38],[45],[50],[53],[57],[58],[59],[60],[61],[62],[90],[91],[93],[103]。
表征相似性分析(RSA):提供了一个有用的和说明性的工具,给定一组实验条件下的一组活动模式(生物的、行为的或人工的),模式之间的相似性计算为1减去组成模式的单元之间的相关性。通过将每层CNN的表现与行为表现或神经活动数据进行比较,研究不同的视觉刺激产生的表征几何响应,并检查是否相同类别的图像产生相似的响应在表征空间。RSA比较的相似性表征矩阵(representational dissimilarity matrix,RDM)描述了大脑或模型的代表性信息:文献[51],[54],[59],[60],[74],[75],[77],[78],[81],[91],[101],[116]。
4 总结与展望
针对视觉目标识别任务,大脑神经机理研究和类脑模型构建可以根据模型架构和开发途径进行分类。此外,对脑视觉通路与人工模型的一致性表现进行了分析和研究,对这些方法从比较对比方法方面进行了分类。同时,简要介绍了这些研究中设计的实验条件和数据分析方法。
人工神经网络整体都受到了20世纪中期开始发展的神经生物学的启发。设计人工神经元模拟神经元接收和转换信息的基本特性,卷积网络模拟人脑层次化信息处理机制,所执行的主要功能和计算受到了某些关于视觉系统的早期发现的启发[8]。随着越来越多的研究人员对大脑视觉神经机理开展研究,浅层的神经连接机制和激活状态被开发出来,最近的人工神经网络的很多设计都源于神经科学的启发,例如:反馈、递归、注意力机制。另一方面,最近的很多神经科学领域的研究将CNN模型与视觉系统相关联,通过神经激活预测或信息表征方式评估两者在目标识别任务上的一致性表现。不同的实验证明了同一个结果,CNN模型的层级结构与视觉通路之间存在对应关系,可以更好地预测视觉皮层的神经活动,超越了其他方法。人工神经网络是在视觉神经科学与计算机视觉之间的相互作用下逐渐发展的。
反观基于CNN的目标识别模型对视觉皮层具有较强的预测能力,可以借助CNN这一工具尝试反推出视觉神经的工作原理,了解有关视觉系统的信息处理机制。这些研究的方法见解和发展都需要通过与实验数据的交互而进行验证和分析。CNN对理解视觉系统的方式主要有以下三点:首先,CNN模型在目标识别任务上的成功,证明了从整体、直观的角度对视觉系统的理解基本上是正确的,只是缺少训练数据和计算能力。其次,基于已有的数据建立所感兴趣的内容的合理模型是允许的。最后,将关于视觉系统的工作方式整合成具体的数学计算模型,尽管在建模时通常需要进一步假设和简化,但这仍然能为模型行为的一般趋势和局限性提供有帮助的见解。
深度神经网络模型提供了一个生物学上可信的快速识别视觉目标的技术元素,可以解释高效计算的模式识别成分。然而,他们无法解释人类是如何理解元素之间的语义关系以及物体之间的物理相互作用。贝叶斯非参数模型解释了从单一经验形成深刻的推论和概念。该模型可以解释大脑惊人的统计效率,通过建立生成式模型,提供抽象的先验知识,从小样本数据中推断出很多能力[169]。因此,根据深度卷积神经网络的设计来源和突出表现可以整理出一些未来的发展方向。要理解大脑的视觉目标识别机制,需要先从需要解释的视觉行为功能开始发展理论框架,设计的类脑视觉计算模型需要能够执行有助于灵长类动物视觉目标识别的功能。其次,通过数据驱动的方法补充理论驱动的模型架构,根据视觉神经活动的丰富测量实验有效的推动模型架构的完备性和生物可信性。
类脑视觉的目标识别模型已取得了阶段性的进展,但是目标仍然没有任何一个模型或方法能够接近人类的水平,对复杂视觉环境具备较强的自适应能力和自主学习、自主决策能力等。一方面,在未来的脑启发目标识别模型的研究中,需要基于多模态、多尺度的脑神经数据分析结果对脑视觉通路进行建模计算,构建识别视觉目标的多模态、多尺度的神经网络计算模型,满足自主感知、自主决策等智能行为能力;另一方面,需要更多关注视觉神经系统在不同尺度上的神经区域是如何协同工作,进行动态感知、认知、决策,完成目标识别任务。对于模型开发框架方面,传统的人工神经网络虽然受到脑神经网络工作机制的启发,但是经过简化和抽象,其神经元的训练并不具备原有突触的神经机理支撑,因此,未来的类脑目标识别模型需要依据相关视觉神经工作机理作为支撑设计和构建多尺度目标识别模型框架。
然而,当前人工神经网络的快速发展,在计算方面已逐渐远离生物学主题。这主要是由于过去几年的工程突破已经改变了计算机视觉领域。因此,有人提出疑问:人工神经网络未来的发展是否需要神经科学的指导?这些网络的成功也有助于人们对计算机目标识别领域的未来进行思考。一方面,这些网络的进一步工程设计已达到饱和点,层数、激活函数、参数调整、梯度函数等方面的新颖性不断提高,其准确性仅得到提高。对于一般应用而言,生物视觉系统要远远优于任何计算机;另一方面,虽然神经科学和计算机视觉之间的思想交流经历了起起落落,但人们很难不对以神经科学为基础的计算机视觉的未来充满热情。在许多方面,神经科学、计算机视觉和机器学习领域之间从未有过如此多的交流,最近在机器学习方面的成功和最近在神经科学技术方面的进展高度重合,而且这两个领域可能准备以前所未有的规模利用彼此的洞察力。然而,抓住这个机会需要努力和文化的转变,因为这两个领域通常有非常不同的目标和方法。
猜你喜欢
现代电力(2022年2期)2022-05-23
中国医学影像技术(2020年11期)2021-01-04
中国现代医药杂志(2020年3期)2020-05-08
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
中国当代医药(2017年17期)2017-07-25
支部建设(2016年18期)2016-11-28
海军航空大学学报(2015年4期)2015-02-27
