
基于混沌关联维特征的电能表计量多维数据聚类方法
2022-03-24 06:50窦圣霞程志强
电力需求侧管理 2022年2期
窦圣霞,程志强
(国网宁夏电力有限公司 营销服务中心(计量中心),银川 750001)
0 引言
在大数据智能电网环境下,电能计量装置相关技术处于不断创新阶段,使得电能计量多维数据采集量急剧上涨。然而,针对海量电能计量多维数据的有效管理、计算机系统性能优化、计量装置易发生故障等成为了新的挑战[1]。因此,研究出有效的电能计量多维数据分析技术成为亟待解决的问题。
为了解决上述存在的问题,文献[2]公开了基于Hadoop 模型的MapReduce 算法配合Hive 数据仓库储存技术的计算分析系统,这种方案虽然利用大数据技术对计量数据进行了深彻的挖掘分析,但该算法计算效率低下,Hive 数据仓库储存技术复杂的读写信息会转换成MapReduce 的计算过程,降低了分析效率。文献[3]采用Hbase 数据库分布式存储数据,虽然提高了分析效率,但依然存在MapReduce计算的缺陷。文献[4]采用基于LaVIEW的大数据分析聚类算法,应用位置标记方法,通过循环分批读取,解决了大数据块文本数据的快速聚类难题。这种方法虽然聚类过程简单迅速,但是需要建立一个数据模型专门进行管理,比较复杂。文献[5]公开了基于分布式技术的多维数据分析方法,利用云计算在数据存储、数据管理和虚拟化等方面的技术优势,构建了基于云计算的大数据管理和处理模式,对多维数据进行分析。该方法虽然具有较好效果,但处理效率仍较为低下。针对上述存在的缺陷,本文采用一种合适的解决方案,具体内容如下。
1 总体方案设计
本研究基于ADE7953 电能计量芯片配合微处理器,实现电能计量多维数据的采集,并通过优化电能计量算法提高采集系统的精准度。本文技术亮点在于采用混沌关联维聚类分析法对电能计量数据进行多维分析。通过将混沌特征提取与大数据聚类算法巧妙结合在一起,充分发挥双方优势,高效且精确地分析电能计量多维数据。分析系统架构如图1所示。

图1 电能计量多维数据分析系统架构图Fig.1 Architecture diagram of energy metering multidimensional data analysis system
如图1 所示,采集终端从各个新型智能电能表中收集电能计量数据,并通过优化电能计量算法提高采集系统的精准度。对电能计量数据进行预处理,通过新型智能电能表的通信技术可以实时远程传输数字信号至大数据云端平台。大数据平台应用计算机处理相关技术,对电能计量多维数据进行高效率的处理[6]。接着基于关联维和聚类算法的混沌特征分析法对电能计量多维数据进行多维分析。最后将分析结果传输至管理人员,由管理人员针对分析结果进行可视化分析,并通过数据挖掘出隐藏信息,以便进行进一步的决策与判断,还可以将其应用到其他系统中。
2 混沌关联维聚类分析法
本研究采用混沌关联维聚类分析法,该方法将混沌特征提取与大数据聚类算法糅合,充分进行优势互补,合理地分析电能计量多维数据。混沌理论可以用公式进行表达如下。
存在一个函数f(x)和一个紧性度量空间M,其中x∈M。在x中有一个领域c(c>0),领域c中存在任意值y,使得
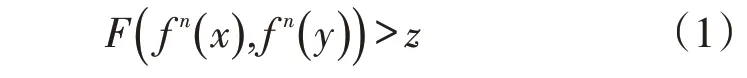
式中:n>0;z为初始值敏感性,z>0。在度量空间M上存在任意两个开集A、B,使得

式中:k>0。从式(2)得出函数f的值在度量空间M中密集,有f(x):M→M,定义f为度量空间M上的混沌[7—9]。
在电能计量多维数据中,混沌特征一般表现为无规则非周期性,非常复杂,因此可以利用混沌特征参数来描述数据非周期性无规则特性,例如Lyapunov 指数、关联维数、近似熵、复杂度等参数。其中Lyapunov 指数和关联维数能直接反映数据信号的周期性或混沌性,是普遍使用的混沌特征参数[10—11]。本研究采用混沌特征参数关联维数来反映电能计量多维数据的混沌程度,下面将阐述具体过程。
2.1 相空间的重构
电能计量多维数据序列一般是无规则非周期性序列,相空间重构是无规则非周期性序列的关键。相空间重构的原理是在一个时间延迟点上进行测量,并构成多相空间中的一个点,重复该过程构成若干个点,即重构出多相空间。在多相空间中能够提取电能计量多维数据的混沌关联维特征[12]。关于相空间重构具体步骤如下。
首先假设原始时间序列为{a1,a2,…,an} ,则相空间重构矩阵A为

式中:k=n-(u-1)r;r为时间延迟;u为最佳嵌入维数。
从式(3)可以看出,相空间重构矩阵中r和u是两个重要参数,关于参数r和u的取值是后续步骤中重点阐述的内容[13]。
接着关于时间延迟r的最佳选择,主要方法有线性自相关函数法和平均互信息法。本研究采用平均交互信息法,通过原始时间序列定义出平均交互信息公式,从中选择第一个相关极小值的时间序列间隔,作为最佳时间延迟r。关于延迟时间中交互信息量O公式为
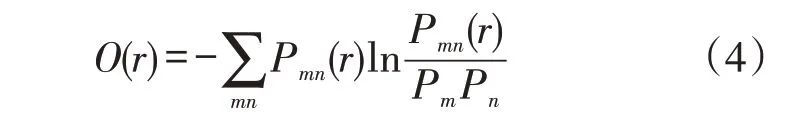
式中:m和n均为某区间;mn为区间m和区间n共有的分布;P为分布概率。若O(r)为0,则a(t+r)和a(t)相互独立导致无法预测,O(r)越小,a(t+r)和a(r)相互独立越明显。最终,O(r)取极小值,此刻r是最佳时间延迟。
最后关于嵌入维数u的最佳选择,主要方法有虚假邻点法和奇异值分解法。本研究选用虚假邻点法,通过对随机两个邻近的时间序列点进行维数增加,比较相邻距离的增大量,以此来确定是否互为虚假邻点。假设在u维度空间,两个邻近的时间序列点处于时间序列
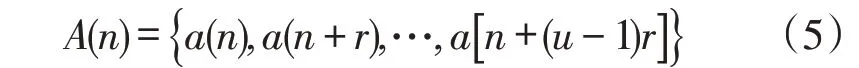
邻近点a(n)与a(n+r)之间的距离为B1;当维度增加到u+1 时,距离为B2。如果B2远远大于B1,则说明a(n)与a(n+r)互为虚假邻点。
然而在时间序列太小的情况下,不易判定虚假邻点,这种情况下可采用相对度量法。实现公式如
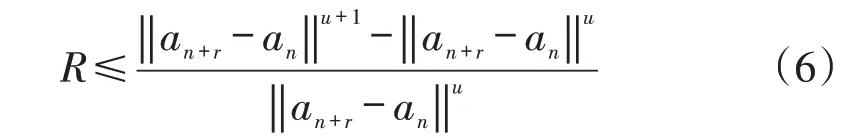
若式(6)成立,则说明a(n)与a(n+r)互为虚假邻点。一般情况下R值为15,通过不断重复计算直到虚假邻点不再随着维度u变化而出现,此刻维度u是最佳嵌入维数。
2.2 基于关联维的混沌特征提取
在重构相空间后,进行下一步提取电能计量多维数据的混沌特征,关于混沌特征参量选用关联维数。关联维数主要是通过关联积分计算电能计量多维数据的混沌程度,它的原理在于计算原始时间序列中给定两个中心点之间的距离,并给出一个距离标准值。计算任意一点与中心点之间的距离,超过这个标准值的其他任意一点都与中心点不具有相关性;小于标准值,且大于中心点之间的距离的点与中心点具有相关性。这些相关的点数目越多,则代表多项空间内关联维度越多。下面将通过算法实现该过程。
在多相空间的重构过程后,关于原始时间序列矩阵Am可表示为

设立两个中心点am和an,在关联维数为u的相空间内计算am与an之间的距离,不超过L的点数集合Q为
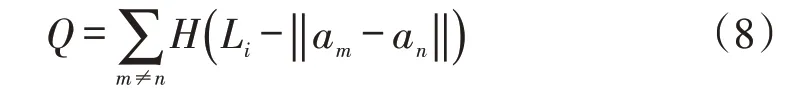
式中:H为赫维赛德函数;Li为相空间内任意一点i到中心点的距离,大于两个中心点之间的距离。关于关联函数D(L)的表达式为
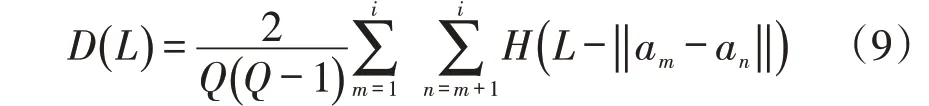
式(9)中含有集合Q的分数主要作用是对关联函数的去重。下面计算给定的距离标准值为

式中:v为符合要求的关联维数,通过这个关联维数范围参数表示出电能计量多维数据的混沌程度,为下一步大数据聚类分析算法提供条件。
2.3 聚类分析算法的实现
在提取出电能计量多维数据混沌特征后,需要实现聚类分析算法。聚类分析算法指将电能计量多维数据样本进行分类,同一个类簇中的样本具有相似性,不同类簇中的样本之间具有差异性。下面将根据混沌特征进行聚类分析,具体算法流程如下。
(1) 输入n个电能计量多维数据样本集{x1,x2,…,xn} ,从该集合中随机选取N个凝聚点,这些凝聚点组成的集合为{z1,z2,…,zN} 。
(2)计算任意电能计量多维数据样本点与凝聚点之间的距离

式(11)用于描述x和zn之间的最短距离。同时假设电能计量多维数据样本集合wn中存在Nn个电能计量多维数据样本。
(3)根据关联函数D(L)求和得到凝聚点zn的表达式为
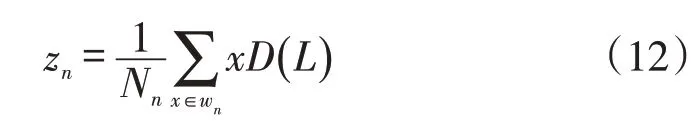
(4)分类。假设x和zn之间的最大距离为

用d1代表分类距离,如果x和zn之间的最大距离大于分类距离,说明wm点并不适合作为凝聚点,要在此聚类区间分成两个凝聚点,可描述为
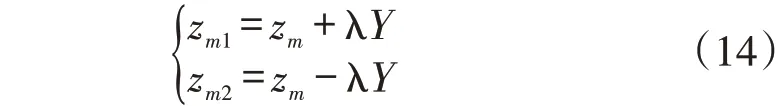
式中:λ 为一个大于0 的常数。若x和zn之间的最大距离小于分类距离,说明wm点适合作为凝聚点,能够很好的进行聚类,则不需要进行步骤(5),直接迭代结束。
(5)合并。假设zm和zn之间的最小距离为l,关于l的表达式为

用d2表示合并距离,若最小距离l小于合并距离,说明分类得到的wm和wn之间具有相似性,将其进行合并,得到zm点和zn点的凝聚点zmn为

若最小距离l大于合并距离,则重新进行步骤(4)。综上所述,基于关联维数混沌特征参量,本研究应用了电能计量多维数据的聚类,将相似的混沌特征样本分成了同一类,成功实现了混沌特征提取与大数据聚类分析法的结合。
3 实验与分析
下面将通过仿真实验进行分析,通过对比验证本文所研究的混沌关联维聚类分析法的优势。
电能计量数据样本信息主要通过电能计量数据库提取,使用大数据云端平台进行数据的预处理,最终得到电能计量多维数据。由于数据库中电能参数种类过多,因此选择其中几个重要参数列出,如表1所示。

表1 电能计量多维数据样本参数Table 1 Parameters of electric energy metering multidimensional data sample
本研究分别采用LaVIEW算法和混沌关联维聚类分析法(chaos correlation dimension cluster analysis method,CCDCAM),针对不同数据量的电能计量多维数据进行聚类,通过实验统计出LaVIEW 算法和CCDCAM算法计算所耗时间。将统计得到结果进行对比如表2所示。

表2 两种算法聚类耗时对比Table 2 Time-consuming comparison of two algorithms for clustering
从表2可以看出,在不同电能计量多维数据量的条件下,本文所研究的混沌关联维聚类分析法所耗时间更短。在数据量为1 024 GB的环境下,本研究的CCDCAM 算法耗时少2 倍多,这也直接表明了本研究的混沌关联维聚类分析法更加高效。
在耗时对比实验后,本文又分别采用这两种算法处理相同的数据量统计系统所损失的能量,并进一步统计两种算法的关联维数,MATLAB 输入统计结果得出仿真曲线如图2和图3所示。

图2 两种算法聚类能耗对比Fig.2 Energy consumption comparison of two algorithms for clustering

图3 两种算法聚类关联维数变化对比Fig.3 Comparison of correlation dimension changes of two algorithms for clustering
从图2可以得出,在不同电能计量数据量的环境下,CCDCAM算法曲线均在LaVIEW算法曲线之下,这体现了本研究的算法系统损耗更低。如图3所示,本研究所采用的混沌关联维聚类分析法关联维数更加稳定。以此证明了本研究算法稳定和性能要求低的优点。
为了验证CCDCAM算法比MapReduce算法直接计算处理效果更好,本文通过对比来表现这两种方法处理数据的差异。根据表1数据样本,实验分别统计对同类电能计量数据不同数据量分析处理的精准度,得到对比结果如图4所示。

图4 不同方法精准度对比图Fig.4 Comparison of the accuracy of different methods
本文所采用的CCDCAM 算法比传统MapReduce 算法处理数据精准度要更高,随着电能计量数据量不断增加,处理电能计量数据的精准度也会略微降低,但是相同数据量情况下CCDCAM算法比使用MapReduce 算法优势大。因此,本文所采用的混沌关联维聚类分析法具有更良好的实用性,适合于电能计量大数据的聚合应用。
4 结束语
本研究首先通过在一个时间延迟点上进行测量,并构成多相空间中的一个点,重复该过程构成若干个点,重构出多相空间。其次在重构相空间后,进行下一步提取电能计量多维数据的混沌特征,通过关联维表现混沌程度。最后将电能计量多维数据样本进行分类,基于混沌特征将相似的样本分为一类,成功实现混沌特征提取与大数据聚类分析法的结合。实验表明,相比传统的聚类分析算法,本研究所采用的分析算法适用性较高,能有效地提高电能计量多维数据聚类分析效率。D
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
广西大学学报(自然科学版)(2022年2期)2022-07-06
南京理工大学学报(2022年1期)2022-03-17
科技风(2021年24期)2021-09-25
计算机应用与软件(2021年7期)2021-07-16
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
人大建设(2018年2期)2018-04-18
成长·读写月刊(2017年11期)2017-11-25
科学启蒙(2017年3期)2017-04-10
发明与创新·大科技(2016年10期)2016-10-22
