
基于知识图谱的k-modes文本聚类研究
2022-03-17 12:46:46高静,王钢
南京理工大学学报 2022年1期
高 静,王 钢
(郑州商学院 信息与机电工程学院,河南 巩义 451200)
数据挖掘技术全面推广,各行业领域运行及管理迎来新的发展机遇。聚类作为数据挖掘的重要技术方法,解决了非标签的数据分类问题[1],通过聚类,将文本数据进行有效归类整理,提高数据的可用性。
当前网络中的文本数据,由于行业差异性及文本异构性,所产生的文本要完成精确聚类并不简单,常因为文本分词不当或者语义模糊而造成错误聚类,若是首先能够确定文本所处行业领域,或者能够确定文本所包含的核心概念,将聚类的领域范围进一步缩小,将有效提高聚类的有效性。现有文本聚类研究中,杨慧婷等[2]采用k-means算法进行聚类,并采用深度信念网络进行聚类准确度提升,但由于深度信念网络收敛需要消耗大量时间,因此该算法的聚类效率并不高;谢娟英等[3]和张志龙等[4]分别采用谱聚类算法和密度峰值聚类算法进行文本分割聚类,解决了复杂文本的聚类问题。
知识图谱采用概念、实体和关系的三元模型,可以有效地分析文本的核心概念及关键内容,得到文本的所有知识元节点。相比于文本的分词后立即聚类,通过知识图谱建模后对知识元节点聚类,可以获得更高的聚类准确度。因此,本文研究旨在进一步提高聚类准确率,采用知识图谱进行文本分析预处理,然后通过k-modes算法[5]完成聚类,经过知识图谱分析之后,k-modes能够获得更优的聚类性能,提高了k-modes算法的聚类适用度。
1 知识图谱
知识图谱(Knowledge graph,KG)采用四元组表示知识,其主要包含概念(Concept)、实体(Entity)、关系(Relation)和属性(Attribute),以及知识图谱的构成要素知识元,其结构如图1所示。
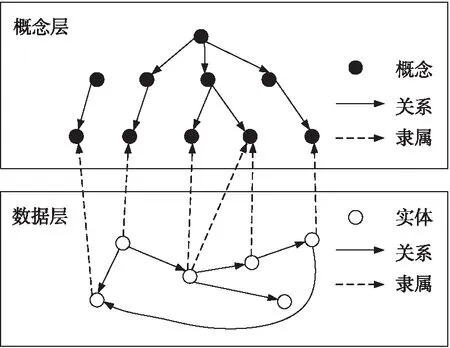
图1 知识图谱结构
知识域d内包含的知识元[6]为
KEd={ke1,ke2,…,kei,…,ken}
(1)
式中:kei={ci,ei,ri,ai},KEd表示领域d内所有知识元集合,kei表示第i个知识元,其包含概念知识ci、实体知识ei、关系知识ri和属性知识ai。
其中领域d内的概念、实体和关系集合分别为Cd、Ed和Rd[7]
Cd={c1,c2,…,ck,…,cnc}
(2)
Ed={e1,e2,…,ek,…,ene}
(3)
Rd={r1,r2,…,rk,…,rnr}
(4)
式中:nc、ne和nr分别代表概念、实体和关系的总数。
每个概念ci对应的属性集合[8]
Aci={a1,a2,…,aj,…ana}
(5)
式中:na表示属性总数。
对复杂文本首先进行知识集合分类,接着进行知识单元解析,最后提取知识单元包含的知识元及图谱,通过逐层分析,获得知识图谱,其中知识的规模结构如图2所示[9]。
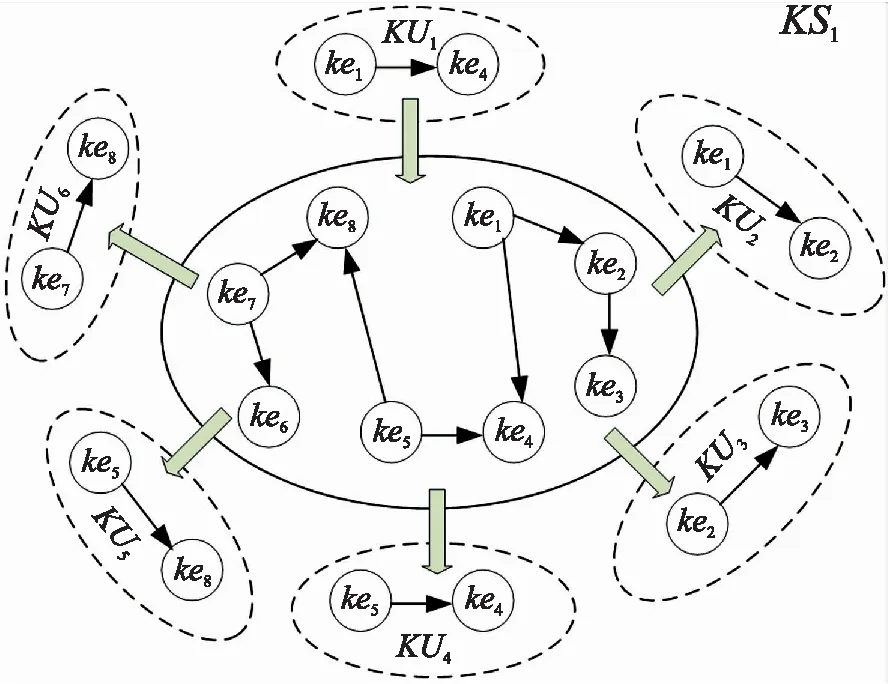
图2 知识结构组成
2 k-modes聚类
2.1 文本聚类设计
设X={x1,x2,x3,…,xn},xi(i=1,2,…,n),其中每个样本点包含m个属性。n个样本被划分为了k个簇z,则k-modes聚类的目标函数P(W,Z)[10]
(6)
(7)
式中:ωi,l∈{0,1},1≤i≤n,1≤l≤k,W为n×k的二进制隶属矩阵,Z={z1,z2,…,zk}是一个包含k个簇z的k×m簇中心矩阵。
D(xi,zl)为节点到某个簇中心的距离。k-modes算法距离计算公式[11]为
(8)
(9)
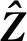



(11)
式中:nzl,j为簇zl的属性值等于zl,j的样本个数。
2.2 聚类流程
首先,所提KGK-modes(Knowledge graph k-modes,KGK-modes)算法将文本进行知识图谱分析,生成包含知识图谱四元组的样本集合,然后进行k-modes聚类。先确定k个簇心,从样本中随机选择k个簇作为聚类中心点,组成初始簇集合Z1,确定W1使得P(W1,Z1)取得最小值,设定t=1。
更新簇点Zt,确定Zt+1使得P(Wt,Zt+1)取最小值,若满足P(Wt,Zt+1)=P(Wt+1,Zt+1)则停止,否则继续更新Wt+1使得P(Wt+1,Zt+1)最小化,若P(Wt,Zt+1)=P(Wt+1,Zt+1)则停止,否则更新簇点[13]。具体流程如图3所示。
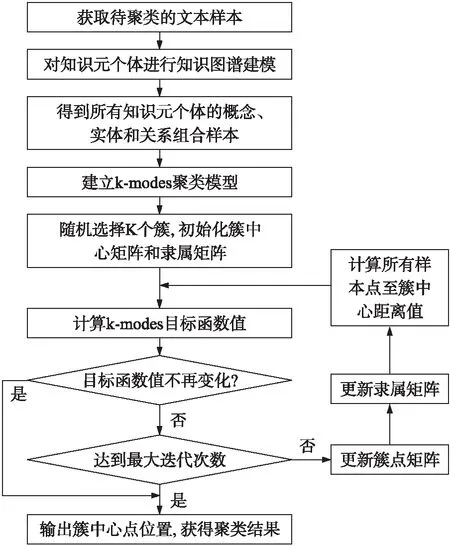
图3 KGK-modes文本聚类流程
3 实例仿真
为了验证KGK-modes在文本聚类中的性能,进行性能仿真。实验仿真的硬件环境为64位Windows 10操作系统的台式电脑,CPU为Intel 7,8G内存,显卡为GTX3060;实验仿真的软件为MATLAB R2018b。首先验证知识图谱对k-modes聚类的性能影响;其次采用常用文本聚类算法和本文算法分别进行文本聚类性能仿真,验证不同的算法的仿真性能。聚类评价指标主要为纯度(Purity,P)、标准互信息(Normalized mutual information,NMI)和F值(F-Value,F)。仿真数据分别来自于公开的UCI数据集和Sogo实验室的搜狐新闻数据集,其具体仿真数据如表1和表2所示。
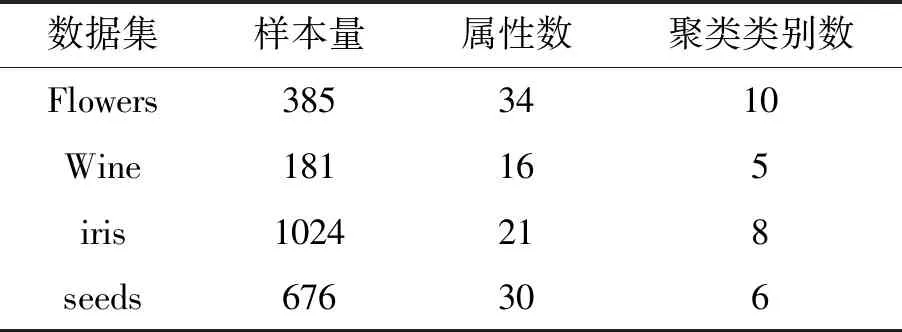
表1 UCI仿真集

表2 新闻文本集
3.1 知识图谱对k-modes的聚类性能影响
为了验证知识图谱对k-modes的聚类影响,分别采用k-modes和KGK-modes算法对表1中的数据集进行性能仿真。
3.1.1 UCI数据集仿真性能
从表3可以看出,在4种不同数据集的聚类过程中,经过了知识图谱的k-modes算法表现出更优的性能。横向对比发现,k-modes算法在seeds数据集的聚类纯度最高为0.806 1,在Flowers数据集的聚类纯度最低为0.766 2;而KGK-modes算法在seeds数据集的聚类纯度最高为0.904 6,在Flowers数据集的聚类纯度最低为0.882 4,因此2种算法均在seeds数据集中聚类性能最优,在Flowers数据集聚类最差。对比NMI和F性能,经过了知识图谱分析之后,k-modes算法表现出了更优的聚类性能,这主要是经过知识图谱分析后,对文本概念、实体和关系的准确划分在一定程度上确定了样本类别,降低了后期的k-modes聚类难度,提高了聚类的性能。

表3 2种算法的聚类性能(UCI集)
KGK-modes在UCI的4类数据集聚类中,P、NMI和F值方面均表现出良好的性能。为了分析聚类纯度的稳定性,对2种算法的聚类纯度RMSE性能进行仿真,从表1的4个样本集中随机抽取1 000个样本进行聚类仿真,结果如图4所示。
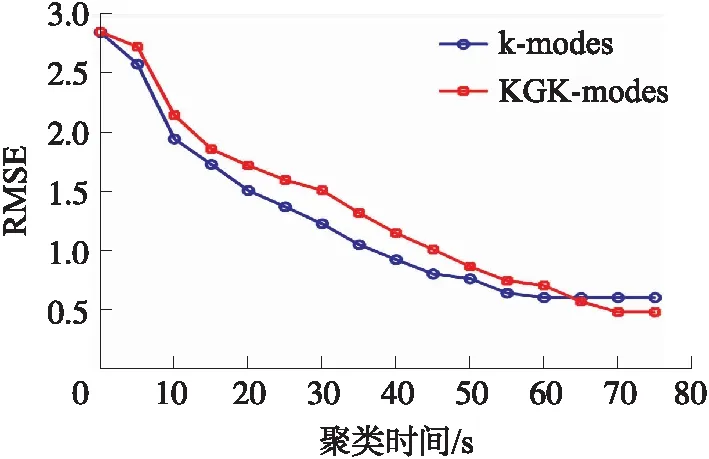
图4 2种算法的聚类纯度RMSE
从图4得,随着聚类迭代次数增加,2种算法的聚类纯度RMSE逐渐下降,对比发现,KGK-modes对于UCI数据集的聚类纯度RMSE下降速度更快,最后收敛于0.5左右,而k-modes约收敛于0.75。
为了进一步分析k-modes算法和KGK-modes算法的聚类性能,对2种算法在4个数据集上的聚类时间性能进行仿真,统计结果如表4所示。
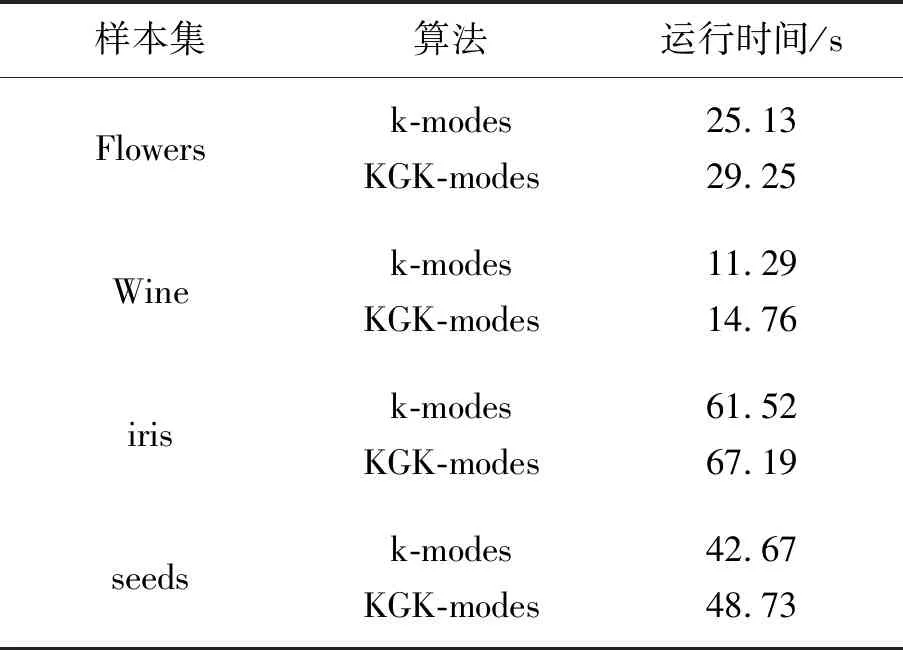
表4 2种算法的聚类时间(UCI集)
从表4得,2种算法在UCI 4个数据集的聚类时间与样本量关系密切,样本量最多的iris数据集聚类时间最长,样本量最少的Wine数据集聚类时间最短。对比发现,知识图谱分析需要消耗一定的时间,因此KGK-modes聚类时间比k-modes聚类时间更长,但两者相差的时间并不大。
3.1.2 新闻数据集仿真
为了验证知识图谱对k-modes算法在Sogo新闻文本中的聚类影响,分别采用k-modes和KGK-modes算法对表2中的数据集进行性能仿真,如表5所示。
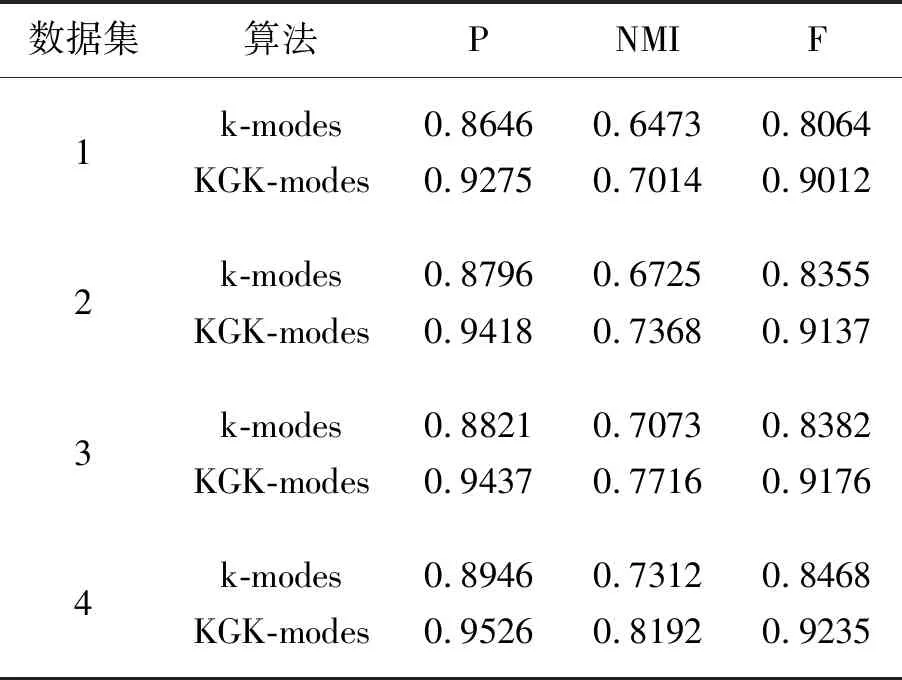
表5 2种算法的聚类性能(新闻集)
从表5可以看出,相比于k-modes算法,经过了知识图谱的k-modes算法在4个新闻样本集聚类过程中表现出了更优的性能。k-modes算法在数据集4的聚类纯度最高为0.894 6,在数据集1的聚类纯度最低为0.864 6;而KGK-modes算法在数据集4的聚类纯度最高为0.952 6,在数据集1的聚类纯度最低为0.927 5,这表明对于同一类型的样本集,样本量越大,聚类纯度越高。和UCI数据集一样,经过了知识图谱分析之后,k-modes算法表现出了更优的NMI和F性能。对比表3和表5得,2种算法的新闻样本集聚类性能明显优于UCI 4个样本集。
对新闻集聚类纯度的稳定性进行仿真,采用2种算法对表2的数据集4聚类纯度RMSE性能进行仿真,结果如图5所示。

图5 2种算法的聚类纯度RMSE
从图5得,随着聚类迭代次数增加,2种算法的聚类纯度RMSE下降明显。KGK-modes的聚类纯度RMSE下降速度快于k-modes算法,最后收敛于0.3左右,而k-modes约收敛于0.5。
对k-modes算法和KGK-modes算法聚类时间性能对比仿真,对2种算法在4个数据集上的聚类时间性能进行统计,结果如表6所示。
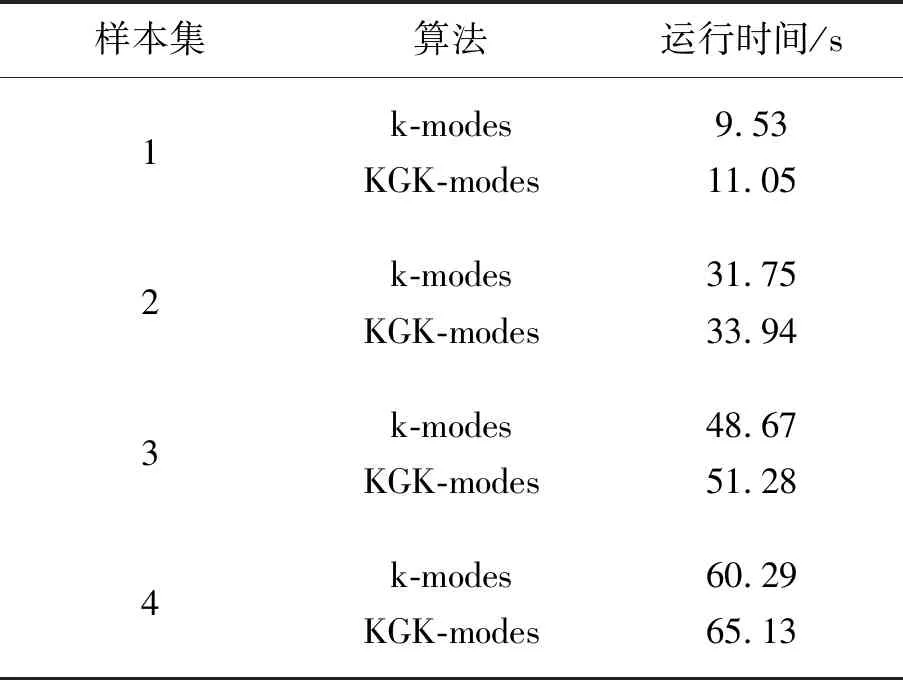
表6 2种算法的聚类时间(新闻集)
从表6得,对于同容量的新闻集,KGK-modes聚类时间比k-modes聚类时间略长,但差距不大。根据上述结果可以看出,KGK-modes算法在新闻数据集上表现出的性能高于UCI数据集,主要原因是新闻数据集的特征维度明显少于UCI数据集,因此数据聚类效果更显著。
3.2 不同算法的文本聚类性能
为了进一步验证KGK-modes算法在文本聚类中的性能,分别采用常用文本聚类算法K-means[14]、K-medoid[15]、卷积神经网络(Convolutional neural networks,CNN)[16]和知识图谱+k-mode算法对表1和2中的数据集进行聚类准确率性能仿真。分别从表1中的UCI的4个数据集中随机抽取1 000个样本进行性能仿真,表2中的数据集4参与仿真,结果分别如图6和7所示。
从图6得,在UCI的1 000个样本聚类中,KGK-modes算法聚类准确率最高约为0.9,CNN算法次之,K-means算法聚类准确率最低约为0.78。从收敛性方面看,K-means算法在55 s左右达到稳定,而KGK-modes和K-medoids算法两者聚类稳定的时间约为65 s,CNN算法聚类稳定时约消耗了70 s。
从图7得,KGK-modes算法的新闻集聚类准确率最高约为0.94,CNN算法次之,K-means算法最差约为0.81;在聚类时间方面,K-means和K-medoids算法聚类时间最优,约在60 s左右达到稳定,而KGK-modes算法和CNN算法聚类稳定的时间分别为65 s和70 s。
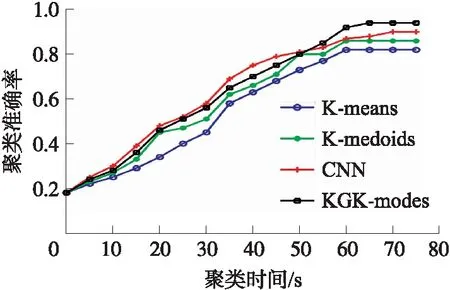
图7 4种算法的聚类准确率(新闻集)
综合对比,KGK-modes算法的聚类准确率最高,K-means算法的聚类时间最优,本文算法在聚类效率方面还需进一步改进。
4 结束语
采用KGK-modes算法进行本文聚类,获得了较高的聚类性能,相比于常用文本聚类算法,表现出了较高的聚类纯度、NMI和F值性能。后续研究将在聚类的效率方面进行展开,一方面考虑引用Spark并行聚类平台,将知识图谱分析和k-modes聚类并行进行,以降低文本聚类时间,另一方面,优化k-modes聚类目标函数优化时间,以提高聚类算法效率,增强KGK-modes在大规模文本聚类中的适用度。
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28 06:26:50
少先队活动(2020年12期)2021-01-14 01:47:40
电子测试(2017年15期)2017-12-18 07:19:27
童话世界(2017年29期)2017-12-16 07:59:32
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
中学生数理化·高二版(2016年6期)2016-05-14 13:19:33
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
应用化工(2014年11期)2014-08-16 15:59:13
