
轴承故障的全视角特征提取与模式诊断方法*
2022-03-23 09:32庄燕
机电工程 2022年3期
庄 燕
(九州职业技术学院,江苏 徐州 221116)
0 引 言
滚动轴承是旋转设备中极其重要的零部件,常被称为“工业的关节”。轴承一般在高温、重载、变载荷等极端环境中长时间工作,因此容易发生裂纹、腐蚀失效、塑性变形等多种形式的故障。轴承故障会使机械设备或生产线停产,严重时造成设备损毁或威胁人身安全[1]。因此,研究滚动轴承的故障诊断技术具有重要的经济意义和安全意义。
对滚动轴承故障进行诊断主要流程包括3个重要方面,即信号采集、特征提取和模式诊断。3个流程具体为:(1)信号采集是依据诊断对象结构特征,选择传感器和信号类型,包括声信号、温度信号、振动信号等。(2)特征提取是对采样信号进行处理和变换,得到能够表征故障模式的特征参数,包括时域参数、频域参数、时频域参数[2,3]、图形参数特征等。(3)故障模式诊断主要有2种,即基于模型驱动和基于数据驱动的模式。其中,基于模型的诊断技术需要建立轴承动力学模型,而精确模型和参数一般难以获得,因此基于模型诊断方法使用较少。基于数据驱动的诊断方法依据大量历史数据进行故障诊断,包括神经网络、支持向量机[4]、深度神经网络[5]等。
范春旸等人[6]采用希尔伯特边际谱的11个统计参数构造了轴承故障的初始特征,而后对其进行了降维,最终使用随机森林算法对轴承进行了故障模式识别;该方法虽然能有效地提取轴承故障特征,但是随机森林算法存在无差别对待随机树的问题。孙岩等人[7]使用多尺度卷积核Inception结构和空间注意力机制替代神经网络的卷积层,从而提取了不同尺度、重点突出的轴承故障特征参数,同时基于改进胶囊网络实现了对轴承的故障诊断;虽然该方法在噪声环境下仍能取得较好诊断结果,但是胶囊网络参数的整定较为困难,且一般要依赖人工经验。王金东等人[8]使用复合多尺度模糊熵提取了轴承的间隙故障特征,并使用支持向量机对其进行了故障识别;虽然该方法有效提取了轴承的故障时频域特征,但是忽视了其他域的敏感特征,因此其故障诊断的准确率有限。
针对特征参数敏感度问题和随机森林无差别对待随机树的问题,笔者从故障特征提取和故障模式识别两个角度对其进行研究,即在故障特征提取方面,结合KPCA和t-SNE方法分别提取基础故障库的全局和局部结构特征;而在故障模式诊断方面,为每个随机树赋予不同发言权,从而提出基于专家森林算法的故障诊断方法。
1 面向全局与局部的特征提取方法
首先,笔者从时域、频域、时频域等多个维度出发,选择能够刻画轴承故障状态的初始特征库;而后,依据核主成分分析法(KPCA)提取初始参数中的全局非线性特征,并依据t-SNE挖掘高维特征参数的局部流形结构,提取局部结构特征;最终,获得用于故障诊断的低维特征参数。
1.1 初始特征选取
笔者从时域、频域、时频域等3个维度中选择轴承故障特征参数作为初始特征库;后续从初始特征库中选择较为敏感的参数作为模式识别参数。采用该方法可以大范围概略地选择时域、频域、时频域特征参数。
初始特征库如表1所示。
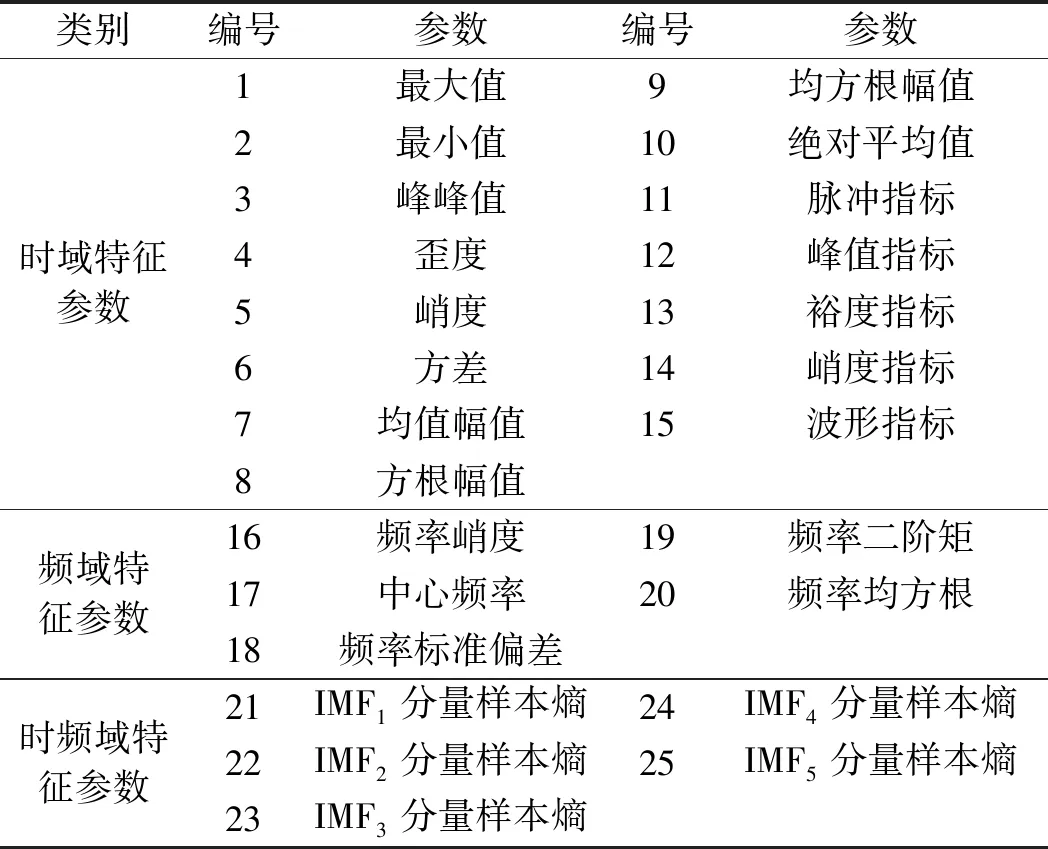
表1 初始特征库
1.2 面向全局特征的参数降维
KPCA依据非线性函数Φ,使低维线性不可分的参数映射为高维的线性可分;而后使用PCA降维方法,提取出初始特征库中的全局非线性特征参数[9]。
笔者将原始数据记为(x1,x2,…,xM),使用非线性函数Φ将其映射到高维空间F后,协方差矩阵表示为:
(1)
式中:CF—协方差矩阵。
求解协方差矩阵CF的特征值和特征向量[10],即:
CFv=λv
(2)
式中:λ—矩阵CF的特征值;v—矩阵CF的特征向量。
特征向量v可以由Φ(xi)线性表示为:
(3)
式中:αi—线性系数。
结合式(1~3),则有:
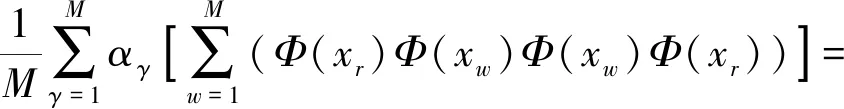
(4)
定义一个M×M维的矩阵K,令Kij=[Φ(xi)Φ(xj)],则式(2)可以变形为:
Mλα=Kα
(5)
对矩阵K的特征值进行排序,为λ1>λ2>…>λM,则前i个特征值的累积贡献率ηi为:
(6)
式(6)中,特征值越大,表明对应的特征向量越能够代表轴承的故障特征。此处,笔者选择累积贡献率不小于95%的前s个主成分特征。
1.3 面向局部特征的参数降维
t-分布随机邻域嵌入(t-SNE)是一种用于非线性降维的机器学习算法,它将高维数据向低维映射时,最大程度实现了相互间分布概率的相似性,解决了样本数据的拥挤问题[11]。基于t-SNE的参数降维与提取可由以下6个步骤来实现。
步骤1。计算高维联合密度函数。笔者将初始高维数据序列维度设置为D,初始数据序列记为X=(x1,x2,…,xN)∈RD,则高维空间中任意两点xi、xj的距离用概率密度函数衡量[12],即:
(7)
式中:σi—xi的高斯方差。
为了避免异常值问题,将高维数据的联合密度函数修正为:
(8)
式中:pij—修正后的联合密度函数;N—数据序列长度。
步骤2。初始化低维数据。笔者将蕴含在X中的低维流形记为Y=(y1,y2,…,yn)∈Rd。其中,d为低维流形维度,且d 则低维数据Y使用随机初始化方法,即: Y(0)=N(0,10-4I) (9) 式中:Y(0)—初始化的低维数据;I—D维单位向量。 步骤3。依据t分布计算低维数据的概率密度qij为[13]: (10) 步骤4。计算目标函数梯度。以高维分布P和低维分布Q的相似度为代价函数C: (11) 式中:KL(P‖Q)—Y和Q之间的Kullback-Leibler散度。 则目标函数梯度为: (12) 步骤5。低维数据的迭代公式。以迭代方式得到低维数据Y(t)为: (13) 式中:t—迭代次数;η—学习效率;μ(t)—动量因子。 步骤6。重复步骤3~步骤5直到达到最大迭代次数T,而后得到低维数据Y(T)。 按照以上步骤,可以从高维数据中提取局部的流形结构特征,得到低维特征参数。 基于KPCA全局特征与t-SNE局部特征的特征参数降维步骤为: 步骤1。采集轴承的原始振动数据,计算表1中的参数构造原始故障特征参数,而后进行参数归一化,得到初始故障特征库X; 步骤2。以径向基函数为核函数,使用KPCA进行参数降维,得到贡献率不小于95%的特征参数,以及基于全局特征的降维参数X1; 步骤3。以X1为高维数据,使用t-SNE对数据进行降维处理,得到基于局部流形结构特征的降维特征参数X2。 故障特征的提取效果可以采用类间间距Sw和类内间距Sb进行评价。笔者将原始序列记为X=(x1,x2,…,xN)∈RD。 假设该数据序列具有L个模式类,第i类的样本数量为Ni,则类间间距Sw和类内间距Sb分别为: (14) 随机森林算法中一棵树为一个决策单元,多个决策树组成一个随机森林,随机森林算法中森林的决策结果为多数决策树的输出结果[15]。这种决策方式充分发挥了决策树的民主作用,但是却忽略了决策树的个体差异,也即忽略了决策树的专家属性差异。为了解决这一问题,笔者提出了一种专家森林算法。 笔者将原始数据集记为D,样本数量记为N′,输入特征数量记为M′,分类标签记为Y。随机森林的构造包括抽样、决策树训练、决策树决策、森林决策等步骤[14]。 (1)抽样。使用bootstrap抽样法从原始数据集D中有放回地抽取K个训练样本,称为bootstrap样本[16]; (2)决策树训练。基于分类回归树构建决策树,在决策树的每个节点位置,从所有输入特征中随机选择m个作为该节点的分裂特征集,而后依据基尼指数最小化准则选择最优分裂特征和切分点,从而将训练样本划分到两个子节点中。重复以上步骤,直至决策树训练完毕; (3)决策树决策。使用bootstrap样本按照上述步骤训练决策树,训练完毕的决策树组成一个随机森林{ti,i=1,2,…,K},ti表示决策树i。将测试样本x输入到该随机森林中,得到各决策树的决策结果{ti(x),i=1,2,…,K}; (4)随机森林决策。随机森林的决策方式较为简单,一般取决策树输出的众数作为随机森林的决策结果,即[17]: (15) 式中:T(x)—随机森林针对样本x的决策结果。 如前所述,为决策树赋予完全相同的投票权忽略了个体之间的专家属性差异,即这是一种将专家决策和普通人决策同等视之的决策方法,因此其存在明显的不合理。 为了解决这一问题,笔者提出了专家森林算法,其基本思想为:在决策树训练完毕后,增加一个预测试过程,根据决策树的预测试准确率为决策树赋予不同的专家属性和专家权值。 在传统随机森林算法[18]中,抽样的K个bootstrap样本全部为训练集。而在专家森林算法中,以随机方式选择0.8K个bootstrap样本作为训练集,另外0.2K个bootstrap样本作为预测试集。 决策树i的预测试准确率记为Ri,为: (16) 式中:Kcorrect—预测试集中决策正确的样本数量;0.2K—预测试集中的样本总数。 毫无疑问,决策树预测试的准确率可以代表决策树的专家属性。预测试准确率越高,表示决策树的专家性越强,其做出的决策信服力也就越强。 为了让专家决策树充分发挥专家作用,笔者依据其预测试准确率赋予其不同权重,即: (17) 式中:wi—决策树i的专家权重。 专家森林根据加权决策值做出最终决定,为: (18) 式中:Tex(x)—专家森林决策结果。 此处笔者以美国凯斯西储大学的轴承实验公开数据作为数据来源,选择SKF6205型轴承试验数据;使用电火花加工技术在内圈、外圈和滚动体上加工出点蚀故障,障碍点直径为0.177 8 mm,数据采样频率为48 kHz。 实验中,分正常状态、内圈故障、外圈故障、滚动体故障等4种状态,每种状态下各包含200个样本,共800个样本,每个样本随机截取0.1 s的原始数据。 首先,验证轴承故障特征提取方法的优劣。为了进行比较,笔者同时使用KPCA、t-SNE、KPCA与t-SNE结合的特征参数降维与提取方法。 3种方法对应的参数降维后的空间分布如图1所示。 图1 不同方法提取的特征 图2 不同提取方法的评价指标 由图2可知: 使用KPCA与t-SNE相结合提取的故障特征指标参数值最大,其次为KPCA方法和t-SNE方法; 参数指标值与图1特征分布相对应,KPCA+t-SNE提取的特征不仅类与类之间区分明显,而且类内样本的聚集度较好; KPCA提取的特征类间区分也较好,但是类内样本的聚集度明显差于KPCA+t-SNE组合法; T-SNE提取的外圈故障而后滚动体故障间还存在交叉现象,因此其指标参数最小。 从理论上讲,KPCA法只提取了故障特征的全局特征,t-SNE只提取了故障特征的局部流形结构特征;而KPCA+t-SNE方法充分挖掘了故障特征的全局和局部结构特征,因此提取效果好于另外两种方法。 笔者从每个状态的200组样本中抽取160组作为Bootstrap样本。在传统随机森林算法中,该160组Bootstrap样本直接用于决策树训练。在专家森林算法中,随机选择其中的80%(即128组)作为训练集,其余的20%(即32组)作为预测试集。 待随机森林算法和专家森林算法训练完毕后,笔者使用随机森林算法和专家森林算法分别对剩余的40×4=160组测试样本进行故障诊断,其结果如图3所示。 图3 两种森林算法的诊断结果 图3所示的实验中,随机森林算法的诊断准确率为96.25%,专家森林算法的诊断准确率为99.38%。 在本次实验中,专家森林的诊断准确率高于随机森林算法。为了进行更加有力的比较,笔者按照上述步骤重复实验10次,每次实验抽取的训练样本和测试样本不同,统计10次实验的诊断准确率参数。 两种森林算法诊断准确率如表2所示。 表2 两种森林算法诊断准确率 由表2可知: 随机森林算法的诊断准确率均值为96.14%,标准差为3.26%;而专家森林算法的诊断准确率为99.48%,比随机森林算法提高了3.47%;专家森林算法诊断准确率标准差为0.87%,远小于随机森林算法,说明专家森林算法诊断结果更加稳定。 以上数据说明,专家森林算法的故障诊断准确率高于随机森林算法,且诊断稳定性好于随机森林算法。 这是因为专家森林算法中,在训练阶段对决策树的专家属性进行了预测试,能够较为准确地评价决策树的专家属性,从而依据专家属性赋予不同的专家权值,使其发言权与自身诊断能力成正比;而随机森林将所有决策树视为同等决策权,忽略了个体间的差异,因此随机森林算法的诊断性能差于专家森林算法。 针对特征参数敏感度问题和随机森林无差别对待随机树的问题,笔者从故障特征提取和故障模式识别两个角度对其进行了研究,即在故障特征提取方面,结合KPCA和t-SNE方法分别提取基础故障库的全局和局部结构特征;在故障诊断方面,为决策树赋予专家属性和专家权值,从而提出了专家森林算法。 经验证得出以下研究结论: (1)基于KPCA与t-SNE结合方法提取的故障特征优于两种方法独立提取的特征; (2)通过故障特征提取,不仅可以降低特征维度,降低计算量,而且可以提高特征向量对故障敏感程度; (3)专家森林算法由于在随机树上赋予了专家属性,因此故障诊断准确率高于随机森林算法。 从轴承故障诊断的研究热点和发展趋势看,在今后的工作中笔者可以展开以下3个方面的研究: (1)研究高敏感特征提取方法,使故障特征对故障模式更加敏感; (2)研究更加准确的分类方法,使模式识别更加精准; (3)研究基于深度学习的故障特征提取与模式识别一体化方法。1.4 特征参数降维步骤与评价参数

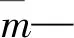
2 基于专家森林算法的故障识别
2.1 随机森林算法
2.2 专家森林算法
3 实验与结果分析
3.1 实验设置与特征提取


3.2 故障模式诊断结果


4 结束语
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
世界科学技术-中医药现代化(2021年8期)2021-12-21
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
空间科学学报(2020年1期)2021-01-14
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
中国交通信息化(2019年12期)2019-08-13
电子制作(2018年16期)2018-09-26
电子制作(2017年24期)2017-02-02
