
融合LPCC和MFCC的支持向量机OSAHS鼾声识别
2020-12-03 05:35:22沈侃文李文钧岳克强
杭州电子科技大学学报(自然科学版) 2020年6期
沈侃文,李文钧,岳克强
(杭州电子科技大学射频电路与系统教育部重点实验室,浙江 杭州 310018)
0 引 言
打鼾是“阻塞性睡眠呼吸暂停低通气综合征”(Obstructive Sleep Apnea-Hypopnea Syndrome,OSAHS)的症状之一[1],打鼾和呼吸暂停之间存在密切关系。目前,医学界检测OSAHS的国际标准是多导睡眠图(Polysomnography,PSG),但PSG检测价格昂贵,耗时较长且操作复杂,难以满足当前便捷、低成本检测方式的需要[2]。鼾声是一种重要的生理信号,包含与OSAHS相关的许多信息,并反映出OSAHS的病理特征[3],可以通过检测鼾声来实现OSAHS的诊断。在语音识别的特征参数选择方面,王彪[4]采用线性预测倒谱系数(Linear Prediction Cepstrum Coefficient,LPCC)进行语音识别,郭春霞等[5]采用梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficient,MFCC)进行说话人识别,取得一定的成果。但是,由于特征参数过于单一导致识别准确率偏低。支持向量机(Support Vector Machines,SVM)基于结构风险最小化原则,泛化能力强,故本文从鼾声的声学特征出发,提出一种基于支持向量机(Support Vector Machines,SVM)的融合特征鼾声分类算法,为OSAHS诊断提供一定参考价值。
1 基于Fisher准则的融合特征提取方法
声音的特征提取方法主要包括基音频率、短时能量、共振峰、线性预测编码(Linear Predictive Coding,LPC)、线性预测倒谱系数LPCC、梅尔倒谱系数MFCC等,其中LPCC和MFCC特征提取性能较好,本文使用一种基于Fisher准则的融合特征提取方法将LPCC和MFCC进行融合,产生新的特征参数,有效表征鼾声的特征,达到区别鼾声类别的目的。
1.1 LPCC特征提取
LPCC特征参数[6]是在LPC特征参数[7]的基础上得到的。通过LPC分析获得的声道模型系统函数为:
(1)

(2)
将式(1)代入式(2),然后两边各自关于z求导,则有:
(3)
所以有:
(4)
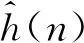
(5)
1.2 MFCC特征提取
人的听觉特性是MFCC分析[9]的基础,其中对语音频谱的分析是基于人耳的听觉实验,以此获得良好的语音特性。
MFCC特征参数[10]的提取首先经过预处理、离散傅里叶变换、语音信号功率谱计算,再通过一组梅尔尺度的三角形滤波器组对频谱进行平滑化,从而避免特征参数受到语音的音调高低的影响,最后计算每个滤波器组输出的对数能量:
(6)
式中,X(k)为各帧信号进行快速傅里叶变换得到的频谱并取模平方得到语音信号的功率谱,H(k)为能量谱通过三角滤波器得到的频率响应,M为梅尔滤波器总数,N为频域中的谱线总条数。得到每个滤波器组输出的对数能量s(m)后经离散余弦变换得到MFCC系数C(n):
(7)
式中,L为离散余弦变化后的谱线总条数。
1.3 融合LPCC和MFCC的特征提取
Fisher准则[11]的原理是在特征向量空间中找到投影子空间,以使其中的特征点在该空间中获得最佳分类。Fisher准则是模式识别中的降维方法和特征提取方法。LPCC特征参数和MFCC特征参数分别代表鼾声信号的不同特征并且具有不同的表征能力。本文结合不同特征参数的优势进行鼾声识别。
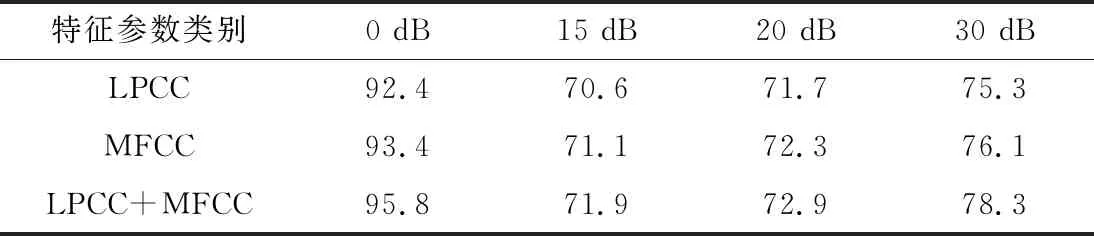
特征参数的选择是从C维特征参数中选择最有效的c(c (8) (9) (10) σbetween越大,表明第d维的特征参数分量与其他维的特征参数分量对不同鼾声信号包含的特征信息的区分度较好。σwithin越小,表示第d维的特征参数分量表示的同一鼾声信号包含的特征信息越集中。总体来说,Fisher比越大,表明该维特征参数能更有效准确地反映鼾声信号的特征信息。 本文先根据Fisher比进行特征选择,再进行特征参数的融合,具体步骤如下。 (1)将输入的鼾声信号进行预加重、加窗、分帧、端点检测等处理。 (2)分别求取鼾声信号的LPCC特征参数和MFCC特征参数。 (3)将LPCC特征参数和MFCC特征参数分别构建成LPCC特征参数序列和MFCC特征参数序列。 (4)根据Fisher准则分别求出LPCC特征参数序列和MFCC特征参数序列中每一维特征参数的Fisher比,选择Fisher比大的维数,并分别构成LPCC特征参数序列和MFCC特征参数序列。 (5)将步骤4中的LPCC特征参数序列和MFCC特征参数序列进行融合,得到新的特征参数序列。 如上所述,本文特征参数提取的方法是先根据Fisher比选择LPCC特征参数和MFCC特征参数,然后再进行融合特征参数。这样,融合特征参数由LPCC特征参数的Fisher维度和MFCC特征参数的Fisher维度组成,因此,构成LPCC特征参数和MFCC特征参数的数量相等。 SVM是一种二分类模型,能够正确划分训练数据集并且求解几何间距最大的分离超平面。当数据无法在低维特征空间中线性可分时,通过非线性变换x=K(x)将样本映射到高维空间,K(x)为x映射后的特征向量。当核函数满足Mercer定理时,使用适当的内积函数获得高维空间的分类函数,从而实现线性可分,且不会增加计算的复杂度。假设超平面能将训练样本正确分类,则约束条件为[13]: (11) 式中,xi为第i个特征向量,yi为类标记,w为分类超平面法向量,b为分类超平面偏移项,h为样本总数。为使得几何间距最大化,新的最优问题转化为: (12) 式(12)的对偶问题为: (13) 式中,αi≥0为拉格朗日乘子。决策函数为: (14) 本文将SVM用于融合鼾声特征分类,算法步骤如下。 (1)从整夜录音声中用端点检测的方法提取鼾声段。 (2)通过MATLAB-R2016b平台提取鼾声段的LPCC,MFCC,LPCC+MFCC特征数据,并将这3种特征数据保存为MAT文件。 (3)通过PyCharm平台导入MAT文件,获取特征数据。 (4)将不同种类的数据集标记为0和1,然后将数据集分为训练集和测试集,最后进行模型的训练和测试。 实验用的鼾声数据来源于某附属医院,采样频率为16 000 Hz,16位采样位数,单声道。在特征提取期间,对输入的鼾声片段进行预加重、加窗、分帧、端点检测等处理,其中帧长选为480点,帧移为160点,使用滤波器进行预加重,最后通过MATLAB平台提取LPCC,MFCC,LPCC+MFCC特征参数,LPCC滤波器个数为16,LPCC输出维度为40,MFCC滤波器个数为40,MFCC输出维度为40,LPCC+MFCC(其中LPCC滤波器个数取16,输出维度为56,MFCC滤波器个数为36,输出维度为36)的输出维度为40。本文通过录音设备采集5名医院患者的鼾声数据(2男3女),文件格式为WAV格式。5名受试者中,单纯打鼾者鼾声为1 060例,OSAHS患者的鼾声为1 060例。首先通过MATLAB-R2016b平台分别提取鼾声信号的LPCC,MFCC,LPCC+MFCC的特征参数,并保存为MAT文件,然后在PyCharm平台上通过调用MAT文件导入特征数据,进行去均值和方差归一化处理,运用SVM模型进行训练和测试。 本文分别采用SVM学习算法、随机森林学习算法、决策树学习算法进行实验,特征参数选用MFCC,实验结果如表1所示。 表1 不同学习算法的识别准确率 % 由表1可知,SVM学习算法的准确率高于决策树和随机森林学习算法,分别提高了7.5%和4.7%。 本文在SVM核函数的选择上也进行了实验分析,分别采用多项式核函数、高斯径向基核函数、Sigmoid核函数,特征参数选用LPCC+MFCC,实验结果如表2所示。 表2 不同SVM核函数的识别准确率 % 由表2可知,当SVM采用高斯径向基核函数时识别准确率高于多项式核函数和Sigmoid核函数,分别提高了15.3%和4.1%,有助于提高鼾声识别系统的准确率。 在以核函数为高斯径向基核函数的SVM模型上,运用LPCC特征参数、MFCC特征参数和LPCC+MFCC特征参数对原始鼾声信号进行训练和测试,基于3种特征参数的鼾声识别系统的识别准确率如表3所示。 表3 不同特征参数的识别准确率 % 最后在原始鼾声信号中分别加入15 dB,20 dB,30 dB的白噪声,来验证本文融合特征参数的抗噪性。结合LPCC特征参数、MFCC特征参数、LPCC+MFCC特征参数的实验测试结果,在不同噪声环境下的鼾声识别系统的识别准确率如表4所示。 表4 不同噪声环境下,不同特征参数的识别准确率 % 由表3可知,3种特征参数都有较高的准确率,都在90%以上。MFCC特征参数的抗噪性能要比LPCC特征参数的抗噪性能好。与LPCC和MFCC特征参数相比,本文的融合特征参数大大提高了抗噪声能力,同时鼾声识别系统的准确率也大大提高了。 基于以上实验数据,本文的融合特征参数可以更好地表征鼾声信号的特征,从而提高了鼾声识别系统的准确率,从表3计算得出,相对于LPCC和MFCC,分别提高了3.4%和2.4%。 本文设计了一种基于SVM的Fisher准则的融合特征鼾声分类算法,通过Fisher准则结合不同特征参数的优势来进行鼾声识别。与传统的LPCC和MFCC特征参数相比,融合LPCC和MFCC特征参数的系统的准确率有所提高。但是,在噪声环境下的准确率还是偏低,接下来将在抗噪方面做进一步研究,以提高算法的抗噪性。
2 基于SVM的鼾声分类
2.1 SVM原理

2.2 SVM的融合鼾声特征分类
3 实验仿真与分析



4 结束语
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
电子制作(2018年19期)2018-11-14 02:37:08
制造技术与机床(2017年11期)2017-12-18 06:46:39
自动化学报(2017年11期)2017-04-04 02:52:58
人生十六七(2015年26期)2015-08-22 12:12:14
电测与仪表(2015年7期)2015-04-09 11:40:04
小天使·一年级语数英综合(2015年2期)2015-01-14 06:28:39
噪声与振动控制(2015年4期)2015-01-01 07:08:21
作文周刊·小学一年级版(2014年38期)2014-04-29 00:44:03
