
K-Means聚类算法在线上学习效果测评中的应用
2020-07-08 07:30郭玉栋左金平王溢琴
晋中学院学报 2020年3期
郭玉栋,左金平,王溢琴
(晋中学院信息技术与工程学院,山西晋中030619)
在教育信息化2.0背景下,基于人才培养模式的教学改革如火如荼,特别是混合教学模式的教学改革更为突出.混合教学模式[1]的教学改革是基于线上学习和线下教学相结合的教学模式,更加注重学生学习的主动性和积极性,教学的重心由教师的“教”向学生的“学”转变.学生“学”的主要形式就是利用移动技术和信息技术手段进行线上学习,教师通过对知识点的设计,把各种学习视频及课件资源以一定的组织形式部署到学习平台,学生通过学习平台进行自我学习,通过对学生学习情况的分析,把难点和重点问题通过多种线下教学模式进行再次学习.混合教学模式模型如图1所示.
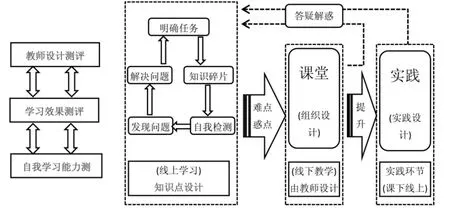
图1 混合教学模式模型
混合教学模式一方面可提升学生的学习能力,符合人才培养的新模式;另一方面减少了教学资源的重复浪费,减轻了教师的教学工作量.混合教学模式对教师提出了更高的要求,在这种模式下教师的角色发生了较大的转变,即以课程教学为主,转化为以设计教学为主,教学模式设计的好与坏直接关系到学生的学习效果.混合教学模式将知识点进行碎片化[2],把课程内容碎片为一个个小的知识点,更易于学生理解和掌握.通过学生的线上学习,自我检测,完成知识点的学习.
1 线上学习效果测评分析
在混合教学模式中,教师对于线上知识点学习效果的评价是一个比较复杂的问题,不能单纯依赖学生的成绩去评定教师对于知识点学习设计的好与坏.影响学生学习效果的因素很多,例如学生仅看了一遍学习视频,还没思考和消化就参加学习测试,学生投入的学习时间不够而且还没有专心学习,知识点组织设计不合理等因素都会影响学生的测评成绩.
针对混合教学改革中出现的设计评价问题,本文提出了K-means均值聚类算法[3].该算法是针对学生线上学习成绩进行挖掘分析,对不同知识点的学习效果进行聚类分组,并对最终聚类进行分析,获取需要改进的知识点设计的一种方法.
2 K-means均值聚类算法
2.1 K-means均值聚类算法描述
聚类分析是数据挖掘[4]领域的重要技术之一,聚类分析处理的数据对象是未知的,聚类分析的过程就是把给定集合中的数据对象分组为多个簇的过程,同一簇内的数据对象相似性很强,而不同簇之间的数据对象具有相异性,把集合中数据对象分成多个聚簇,这个过程就叫聚簇分析.聚簇分析被广泛应用于气象分析、金融分析、实验分析等的数据处理过程中.
K-means聚类算法是聚簇分析中最流行的算法,基于K-means的聚类算法又派生出很多算法,如standardK-means、ScalableK-means、EM等,目的是使得聚类分析的结果能达到最优.在K-means均值聚类算法中,以K为参数,作为簇的数量,即把n个数据对象划分为K个簇,使簇内的数据对象具有较高的相似度,而簇间的数据对象相似度最低.
2.2 K-means均值聚类算法定义
在数据集B中包含n个数据点,即B{x1,x2…xn},k为预期聚类的数量值,M1,M2,M3…MK是M的K个子集,且Mi∩Mi=Φ.在K-means聚类算法中,使用欧几里得距离来获取离xi点最近的质心Cj.
2.3 K-means均值聚类算法描述
算法输入:(1)聚簇的数量K;(2)具有n个数据对象的数据集.
算法功能:K-means算法计算基于簇中对象的平均值.
算法输出:形成K个簇,使得每个簇中数据对象间距离均值最小.
2.4 K-means均值聚类算法步骤
1)在数据集中的n个数据对象中,选取K个随机数据对象作为K个聚类的质心.
2)将其余数据对象分配给与其距离最近的质心所属的类,形成K个类,使用聚类准则函数[5]:

通过该聚类准则函数来进行距离的计算,其中K值是类的数量,Mi是类Ci的代表,是类Ci中其余的数据对象O与类Ci的代表Mi的欧几里得距离的平方.
3)计算各个类的重心,将这些重心作为各个类的代表,具体算法为:

4)不断重复步骤(2)和(3),直到所有的数据对象不再被分配或者是达到最大的迭代次数,或达到函数收敛,结果是导致准则函数最小的K个簇的划分.
2.5 K-means均值聚类算法实现过程
1)从数据集 B 中随机选取 K 个不同的数据对象作为 K 个类 C1,C2,C3…Ck的代表 H1,H2,H3…Hk.
2)repeat for B中每个数据对象O.

For每个类Cj(1≤j≤k)

3)until K个类代表不再变化.
一般聚类效果的优劣通过平均量化误差q(c)来测评,具体如下:

当 xi∈Dj,q(c)的值很小时,效果较佳.
3 应用算法
知识点分布在学习平台上,学生对于每个知识点的学习情况及测评成绩都已经在平台的数据库中有记录,可以运用K-means均值聚类算法对平台上学生的知识点学习成绩进行挖掘分析,形成不同学习效果的K个簇,在对每个知识点测评学习情况进行数据挖掘分析的基础上,可以得知哪些测试成绩的知识点需要进行改进设计并找出知识点设计需要改进的地方.
3.1 线上学习数据的分析与假设
在学习平台记录学生对于知识点的学习情况,记录主要如下:
知识点的记录格式为(知识点学号,知识点名称,视频时长,……);
学生知识点学习数据记录格式(知识点序号,学生学号,测评成绩,……);
学生登录平台学习知识点信息(时间,知识点序号,学号,学习时长,……).
决定学生学习知识点的因素很多,线上学习过程中要考虑的因素主要为学习次数、学习时长,对于一个知识点的学习过程至少应该在1次以上,假如是视频资源,至少应该大于视频的播放时长.假如一个学生对某知识点学习次数为1次,但是学习时长还不及视频时长的1/3,考试成绩差是合理的,不能计作是学习资源设计不合理.因此对于学习平台数据库中的存储信息应该有选择地选取,同时,由于知识点是碎片化的,假设碎片化的知识点难度系数忽略不计,因此本文对于平台资源的数据选取需要符合两个条件:
1)Times>=1(Times是知识点的学习次数);

3.2 线上学习数据的筛选与实验结果
现以晋中学院在超星学习平台[6]部署的《软件工程》线上知识点学习的数据为例进行挖掘分析.平台共有2017~2019年三年的数据,其中学生学习本课程的人数共计约300人,《软件工程》课程线上知识点86个,现在通过对符合要求的学习数据采用K-means均值聚类[7]算法进行挖掘.通过对线上学习数据的挖掘与分析,预期得出至少三类知识点:第一为设计较优的知识点,体现为学生测试成绩较高;第二为需要改进设计的知识点,体现在学生测试成绩为中等;第三为设计较差的知识点,体现为学生测试成绩较差.
首先对于线上知识点的学习数据进行整理,符合条件的数据记录条数约26000条,具体数据见表1.
预期对知识点进行划分为3类,因此K-means均值聚类算法中定义K值为3.
本文将上述整理后的线上学习数据在Matlab中采用K-means均值聚类算法进行模拟计算,计算结果如图2所示,图上展现出上述数据聚类分析以后的聚类分布,按照预期要求,把知识点分为三个聚类,每个聚类代表一类知识点的学习效果,其中第一类聚类点表示此类知识点学习效果良好,第二类聚类点代表学
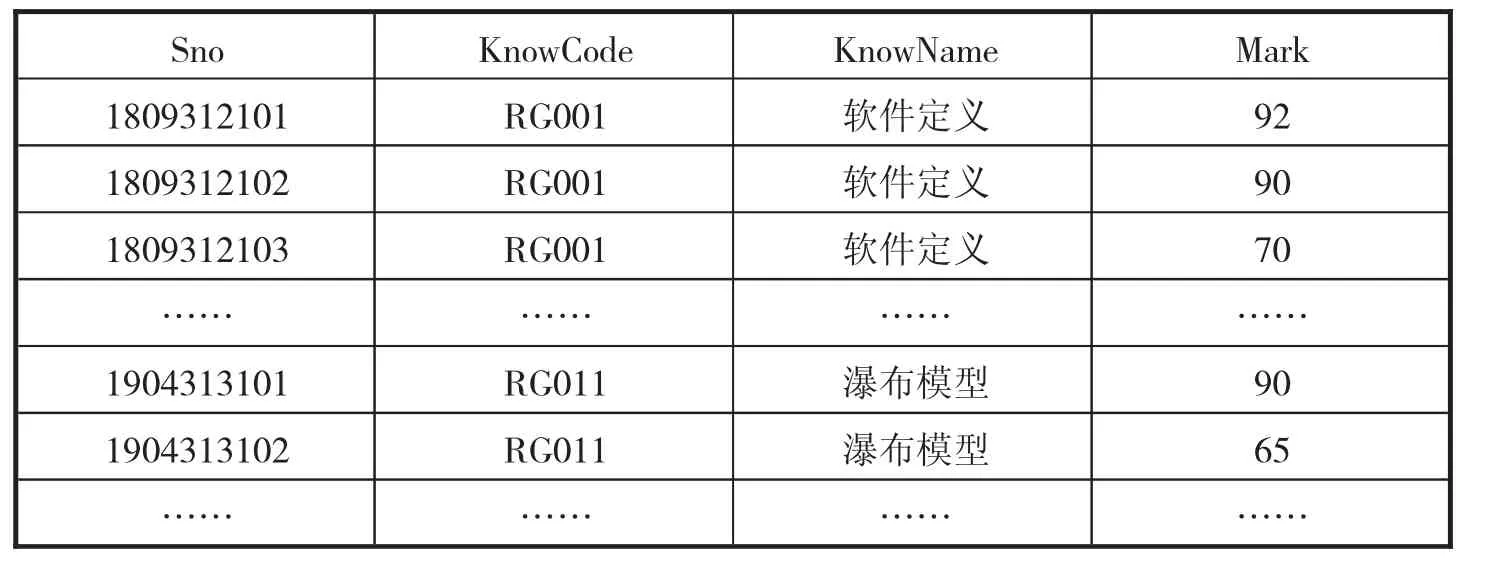
表1 整理后的线上学习数据
习效果次之,知识点的设计需要改进,红色聚类点表示知识点设计效果不好,学生成绩不佳,需深入改进.
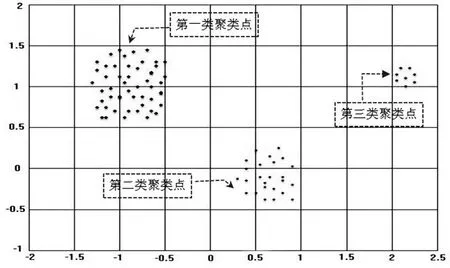
图2 聚类后聚类分布
获取聚类分析的结果,结合线上学习平台数据库中的关联信息,得出需要深入改进的知识点,见表2.

表2 通过对聚类结果分析后需要改进的知识点
根据对需要改进的知识点的分析,发现这些知识点都是实践性很强的内容,一些知识点确实需要进一步改进,但是也从侧面得知,不是所有的知识点都适合进行线上学习,特别是一些实践性很强的知识点,还是需要进行线下学习,以提升其实践性.采用K-means均值聚类算法在对线上学习数据的挖掘分析中得到满意的聚类结果,那么《软件工程》线上知识点学习数据符合设计要求.
4 总结
线上学习是当前教育教学改革中非常重要的一种形式,特别是2020年冠状病毒爆发以来,线上学习已经成为大、中、小学学生学习的一种主要形式,突显了这种教学模式强大的生命力,也将成为今后教学中最主要的一种形式,线上学习资源的建设以及知识点的设计变得非常重要.
本文提出的采用K-means均值聚类算法对学生线上学习信息和数据挖掘分析,来获取需要进行改进的知识点的方法,进一步提高线上学习的效果.学习效果的影响因素很多,通过知识点学习效果的聚类分析,虽然不能准确地说明知识点设计不合理之处,但是最起码能说明该知识点在学生学习过程中需要进行调整,例如有些知识点实践性很强不适合在线上学习,有些知识点设计的容量较大,有些知识点需要进行重新设计,有些知识点难度系数较大需要进一步拆分等.通过采用大数据技术和数据挖掘技术对学生的线上学习情况进行挖掘和分析,能够发现学生在学习过程中出现的问题,很好地实现评价诊断功能,为今后教学模式的改革和评价提供一些有价值的依据,促进教学水平的提升.
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
民族文汇(2022年14期)2022-05-10
课程教育研究(2021年10期)2021-04-13
铁道通信信号(2019年6期)2019-10-08
作文大王·笑话大王(2019年8期)2019-09-09
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
