
信息系统的最大可能约简算法
2020-03-23 04:56詹婉荣
洛阳师范学院学报 2020年2期
詹婉荣,于 海
(洛阳师范学院数学科学学院, 河南洛阳 471934)
粗糙集理论由波兰数学家Pawlak于1982年提出,它是一种新型的处理模糊和不确定知识的数学工具,其主要思想就是在保持分类能力不变的前提下,通过知识约简,导出问题的决策或分类规则.经过多年的发展,该理论已被成功地用于机器学习、决策分析、过程控制、模式识别和数据挖掘等领域[1].
属性约简是粗糙集理论中的核心研究内容之一[2-3].数据库中的属性并不是同等重要的, 甚至其中某些知识是冗余的,通过属性约简, 可以去除数据库中的冗余、无用的成分, 从而揭示数据中隐含的规律.从粗糙集理论的角度看, 在一个信息系统中, 有些属性对于分类来说是多余的, 去掉这些属性后,信息系统的分类能力不会改变, 所以属性约简后仍然会反映一个信息系统的本质信息.然而,在一个信息系统中寻找所有约简或最优属性约简会面临NP-hard问题.目前解决这一问题通常考虑启发式算法,大多数启发式算法都是以属性重要性作为衡量指标对属性进行筛选,最终求得最优或次优的约简组合.根据属性重要性度量方法的不同,目前算法主要分为三大类: 基于属性在区分矩阵中出现的频率的方法[4-7]、基于属性依赖度的方法[8-9]以及基于信息熵的方法[10-11].
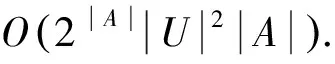
1 信息系统及其属性约简
定义1(信息系统)信息系统S是一个四元组:S=(U,AT,V,f),其中,U表示对象的非空有限集合,称为论域;AT表示属性的非空有限集合;V是属性的值域集;f是信息函数,即f∶U×AT→V.
AT可进一步划分为2个集合: 条件属性集C和决策属性集D,并满足AT=C∪D且C∩D=φ, 则S被称为决策系统.
定义2(不可区分关系)设A⊆AT,不可区分关系ind(A)⊆U×U定义如下:
ind(A)={(x,y)∈U×U|∀a∈A,f(x,a)=f(y,a)}.
对任意两个对象x,y∈U,若xind(A)y,则基于属性集A,x和y是不可区分的.
根据不可区分关系的定义,Pawlak将信息系统的约简定义为保持不可区分关系ind(AT)不变的极小属性集.
定义3(约简)设S=(U,AT,V,f)为一信息系统,如果满足以下两个条件,那么属性集R⊆AT被称为一个约简.
(1)ind(R)=ind(AT);
(2)∀a∈R,ind(R-{a})≠ind(AT).
一般情况下,信息系统的约简不唯一,所有约简之集记作Red(S).
定义4(核)所有约简的交集称为核,记作Core(S).
设S=(U,AT,V,f)为信息系统,以下我们设
U={u1,u2,…,un},AT={a1,a2,…,am}.
定义5(区分矩阵)设S=(U,AT,V,f)为信息系统,|U|=n,S的区分矩阵是一个n×n的矩阵M=(Mij),其中Mij对应一对对象(ui,uj),定义如下:
Mij={a∈AT|f(ui,a)≠f(uj,a)}.
Mij的含义为:Mij是由能区分对象ui和uj的属性组成的集合.如果Mij≠φ,那么对象ui和uj是可区分的.另外,区分矩阵M是对称的,即Mij=Mji,且Mii=φ.所以,只需给出区分矩阵的下三角矩阵即可.
定义6(区分函数)区分矩阵M的区分函数定义为
f(M)=∧{∨Mij|Mij≠φ,1≤i,j≤n}.
其中∨Mij表示Mij中的属性的析取,∧{∨Mij}表示∨Mij的合取.
2 最大可能约简算法
虽然利用定义6中的区分函数可以求出所有的约简,但寻找信息系统的所有约简是NP完全问题,而且在实际应用中,我们不必找出所有约简,有时找到一个约简就能满足需要.本文中,我们不去寻找所有约简,而是寻找发生的可能性最大的约简.
依据区分矩阵的定义可知,某个属性在区分矩阵中出现的频率越高,该属性可区分的对象数就越多,进而表明它的重要性就越大.另外如果Mij中只有一个属性,该属性一定在约简中.进一步分析可知,区分矩阵中某项的属性个数越小,该项对分类所起的作用就越大.
由于寻找所有约简是NP完全问题,目前几乎所有的约简算法都是基于启发式的,其策略依赖于属性重要性的定义,因此对属性重要性的定义是一个关键问题.基于上面的分析,本文构建的属性重要度必须满足以下3条规则:
(1)区分矩阵中某些属性出现的越频繁,该属性就越重要;
(2))区分矩阵中某项若只有一个属性, 则该属性的重要性最大;
(3)区分矩阵某项中属性个数越小,该项中属性的重要性越大.
在构建属性重要度之前,我们先分析约简产生的过程.
定理1设S=(U,AT,V,f)是信息系统,M为S的区分矩阵,R⊆AT为S的一个约简当且仅当以下两个条件同时成立:
(1)∀1≤i,j≤n,Mij≠∅⟹R∩Mij≠∅;
(2)∀a∈R,∃i,j, 使得
Mij≠∅,(R-{a})∩Mij≠∅.
由定理1可知,一个约简和区分矩阵中每个非空属性集的交都不能为空.也就是说,约简中的属性取自于且只能取自于区分矩阵中这些非空属性集.
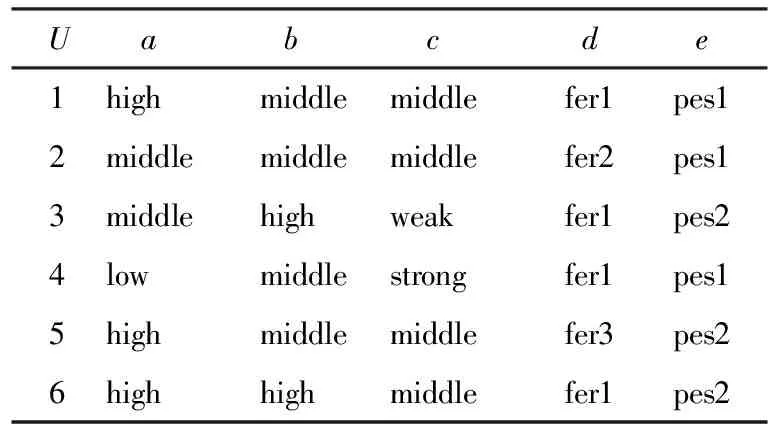
令MS={Mij|Mij≠∅, 1≤j 进一步分析可知,如果R⊆AT是一个约简,由定理1可得到如下结论: (1)∀a∈R,a必取自于MS中一个或多个属性集. (2)∀Si∈MS,一定有R中的属性取自于Si. 约简总是存在的且不唯一,我们要得到一个约简,必须从S=i中取一个属性.本文在Si中,优先选取概率较大的属性. 以下我们计算一个属性出现在约简中的概率. MS={S1,S2, …,Sl},不失一般性,不妨设 (1) (2) 对于约简中的核有下面定理. 定理2若属性ai是核,即ai∈Core(S),则ai出现在约简中的概率P(Bi)=1. 证明若属性ai是核,则ai在MS中一定以单属性集的形式出现,即{ai}∈MS.设{ai}在MS中排第k位.则由(1)式可得 于是 =0. 证毕. 注1: (1)由以上分析可知,属性ai出现在约简中的概率P(Bi)满足上面提到的属性重要性的3条规则.因此我们把P(Bi)作为属性ai的重要度是合理的. (2)文献[4]和文献[5]以属性在区分矩阵出现的次数或频率作为属性的重要度,而我们是以属性出现在约简中的概率作为属性的重要度的. P(Bi)越大,表示属性ai出现在约简中的可能性越大.下面我们以P(Bi)为属性ai的重要度给出最大可能约简的定义, 并构造最大可能约简算法. 定义7(最大可能约简)以空集作为初始约简集,将属性出现在约简中的概率作为属性的重要度,依次选择属性重要度较大的属性添加到约简集中,直至得到一个约简为止. 这样得到的约简,我们称之为最大可能约简.接下来我们给出一个寻找最大可能约简的算法. 算法(最大可能约简算法): 输入:S=(U,AT,V,f) 输出: 最大可能约简R 步骤1 由定义5求区分矩阵M,计算集合MS; 步骤2 由(2)式计算各个属性出现在约简中的概率P(Bi); 步骤3 R=∅; 步骤4 计算A=∪MS,并选取A中概率最大的属性a(如果有多个,就任选一个),R=R∪{a}; 步骤5 删除MS中含属性a的元素,即 MS=MS-MS+(a),(其中MS+(a)表示MS中含有属性a的元素组成的集合); 步骤6 若MS≠∅,转步骤4,否则算法结束,输出最大可能约简R. 下面给出上述算法的时间复杂度分析. 注2: (1)由定理2可知,核属性出现在约简中的概率为100%,因此核一定优先选入约简中. (2)最大可能约简总是存在的,但不唯一. 为了进一步说明本文提出的最大可能约简算法,下面给出两个实例. 例1以表1给出的信息系统为例,说明最大可能约简算法的可行性和有效性. 表1中信息系统的区分矩阵M为 M= 表1 信息系统 由此可得MS为: MS={{a,d},{a,b,c,e},{a,c},{d,e}, {b,e},{b,c,d,e},{a,c,d},{a,d,e},{a,b,d,e},{a,b,c,e},{a,b,c,d}, {a,c},{a,c,d,e},{a,b,c,e},{b,d}} 于是A={a,b,c,e},根据(2)和(1)式计算每个属性的概率: 按照最大可能约简算法,先将属性a添加到约简R中,在MS中删去含有a的元素,得 MS={{d,e,},{b,e},{b,c,d,e},{b,d}}, A=∪MS={b,c,d,e}.接着将属性d加入到R中,删去MS中含有d的元素,MS={{b,e}},A=∪MS={be},再将属性e加入R中,删去e的元素,此时,MS=∅,则得到最大可能约简为R={a,d,e}. 从此例可以看出,尽管属性c出现在约简中的概率和属性e出现在约简中的概率相等,但在将属性a,d加入约简R的过程中被删去.故在最大可能约简R中并不含有c. 例2 表2给出一个信息系统,我们来求该信息系统的最大可能约简.以此说明核属性出现在约简中的概率为1,以及最大可能约简不是唯一的. 表2 信息系统 表2中信息系统的区分矩阵为: MS={{a,b,c},{a,b,c},{a,c},{a,b,c},{b,c},{a,b},{b},{a,b,c},{b,c},{a,b}}. 而A={a,b,c},根据(2)式和(1)式计算每个属性的概率: 按照最大可能约简算法,先将属性b添加到约简R中,在MS中删去含有b的元素,MS={{a,c}},A={a,c},这时,属性a和属性c的概率一样,如果将属性a加入到R中,删去MS中含有a的元素,此时,MS=∅,于是得到最大可能约简为R={b,a}.如果将属性c加入到R中,则得到最大可能约简为R={b,c}. 由此例可以看出: (1)在区分矩阵中,属性b是单属性集,即属性b是核,它出现在约简中的概率P(b)=P(B2)=1; (2)最大可能约简是不唯一的. 属性约简是粗糙集理论的核心内容.因为寻找信息系统的所有约简是NP完全问题,所以本文在区分矩阵的基础上提出了最大可能约简算法,为粗糙集的属性约简提供了新的方法.该算法在区分矩阵的基础上,计算每个属性出现在约简中的概率,并根据概率的大小,对属性进行排序,将概率大的属性优先添加到约简中,直到得到一个约简.本文提出的最大可能约简是粗糙集理论在实际应用中的探索.理论分析结果表明,本文的算法是有效可行的.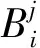
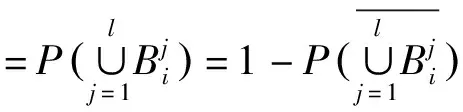


3 实例分析
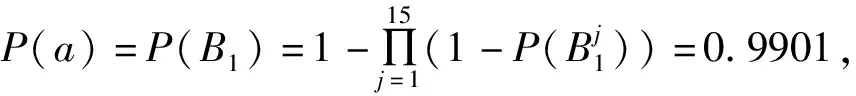
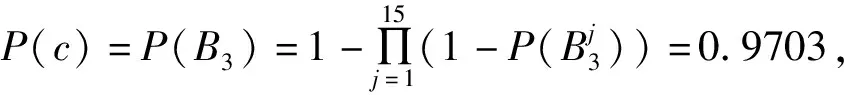




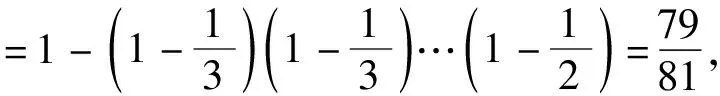


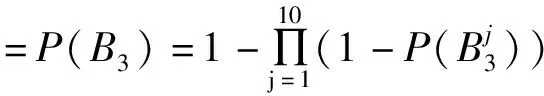
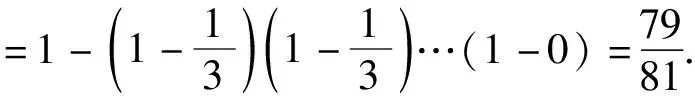
4 结语
猜你喜欢
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
科教导刊·电子版(2021年6期)2021-05-06
成都信息工程大学学报(2019年2期)2019-08-28
奥秘(创新大赛)(2019年3期)2019-03-13
系统管理学报(2018年3期)2018-08-13
自动化学报(2018年2期)2018-04-12
中学生数理化·八年级物理人教版(2017年6期)2017-11-09
智能系统学报(2017年3期)2017-08-01
厦门理工学院学报(2016年3期)2016-11-10
百科探秘·航空航天(2016年5期)2016-11-07
