
基于改进FP-Growth算法的基因-疾病关系自动提取的应用研究
2020-03-23 04:56王明令纪怀猛
洛阳师范学院学报 2020年2期
王明令, 王 苹, 纪怀猛
(阳光学院人工智能学院,福建福州 350015)
计算机技术为数据存储与搜索提供了便利,使以往很难被利用的海量数据能经由数据分析、数据挖掘的方式,发现其中潜藏的有意义的规则和信息.这样的大数据分析应用被广泛运用在许多领域.其中文本数据挖掘的方式能在社区意见、产品评论、舆情预警、客户分群、热点预测、医疗科研等方面提供信息挖掘与规则发现.诸如在传媒情绪研究领域,学者王鹏为解决个体生涯辅导的准确性,结合生活设计范式提出一种将文本挖掘和项目反应理论相结合的新的生涯适应力测评方法[1];学者王超等研究中文词语衔接的概率语言模型,在短文本数据挖掘中针对文本语义进行量化分析[2];学者钟智锦等详细总结了文本挖掘技术在新闻传播学科中的使用场景和特征等[3].在金融运行领域,学者孟志青等利用文本挖掘技术构建金融领域的情感词典,通过贝叶斯方法将其合成网络情绪指数,应用ARMA-GARCH族模型分别刻画网络情绪与个股收益序列[4];学者吴寅恺等研究使用文本挖掘和网络爬虫技术从报刊文章中提取金融风险的信息[5].在电商推广领域,学者崔永生通过对在线评论的文本挖掘,了解消费者真正的购物需求[6].
生物信息学是近年来的研究热点之一,它综合了计算机科学、信息技术与生物学研究的数据与技术手段,对生物学的研究数据——如基因序列、蛋白质序列等——进行分析与加工,得出有价值的信息与规则.学者唐金凤等利用文本挖掘技术分析抗生素后效应(PAE), 为抗生素的合理应用提供参考[7];学者甄曙光等利用文本数据挖掘技术研究中医临床诊疗数字化、文本向量呈像,试图得出中医辨证论治及理法方药的规律性[8];学者刘燕等对癌症基因组数据进行挖掘,对特异癌症基因加以注释并实现可视化展示[9];学者宋嘉麒等以遗传模型对基因-疾病关联进行研究,在实例中比较了不同参数先验信息对合并效应量的影响[10];在学者宋嘉麒等人后续的研究中,继续以贝叶斯模型对基因-疾病关联进行研究[11];学者李雪探讨基于云平台提高基因病诊断率的诊断模式[12].
其中对基因序列的研究是生物信息学的一项重点.经由成熟的医疗技术能够测定与获取生物的基因序列数据,并使用计算机技术将基因序列以多个线性序列编码的方法来表示染色体上携带的数据.这些对医疗研究与生命学研究等都是极有价值的信息数据.
1 基因-疾病关联
现代的医学研究发现,人类基因与疾病之间存在一定的因果关联.某一种或多种基因的存在预兆着一种或多种疾病发作的可能性,基因与疾病之间呈现多对多的复杂关联性.如果医疗工作者能深入了解基因与疾病之间的关联性,能从病体表征上预先察知发病的可能性,就能对某些疾病做到良好的治疗作用,甚至做好预防工作.
传统的生物学实验统计分析存在效率不高的缺陷.而且基因和疾病的种类都非常复杂,仅仅依靠实验室测试的方式进行关联关系建立或排除工作量较大.如果有一个预测目标,来进行基因与疾病之间关联性的实验,就能更好地提高医疗科研的工作效率和准确性.人工智能的数据分析是一个很好的办法,利用数据挖掘的关联规则分析挖掘,能发现基因和疾病数据的特性和关联性强弱.
已知的生物科学与医疗科研工作都累积了大量的基因序列数据和疾病信息.其中,生物科学研究者为现有的基因序列做了较好的结构化数据表示,并大量公开地在网络上发布,使针对基因序列的统计研究与特征描述能更方便地进行.而针对疾病信息的结构化数据较少,一方面因为疾病的表征形式过于复杂,使对疾病的结构化数据描述方式没能很好地统一;另一方面是因为长期以来人工、手工记录的大量医疗数据没能被很好地利用的缘故.
可见要充分利用现有医疗数据进行基因与疾病关联的研究,首先要做好医疗数据的结构化.本文所采取的医疗数据来自武汉某医院神经内科的病历,经由前期数据录入、数据清洗、关键词生成、主题提取等工作,形成了可供进一步挖掘基因-疾病关联的医疗数据.本文应用的基因数据使用网络公开的NCBI数据库的子库PubMed数据库.
2 文本挖掘与关联规则FP-Growth算法
在文本挖掘的模式中,TF-IDF是经典的计算模式.其中TF代表某个关键词的词频,也就是该关键词在相关系列文档中出现的次数;IDF代表提及某关键词存在的文档数量在总的文档数量中所占的比例的倒数.
即:
TF=关键词k在文档中出现的次数
TF与IDF参数能很好地说明关键词与文档之间的关联紧密度.假设当前的TF关键词为基因,IDF为疾病主题数据集.当TF词频较大时,说明多种疾病病历文本描述与TF关键词基因相关,也就是该基因对应了多种关于疾病的描述.当IDF较大时,说明提及该关键词的文档数较少.但是IDF较大也可能是在疾病文献中对该基因的描述较少.但是当IDF较大时,该基因关键词与对应文档的关联性更强.当TF和IDF联合使用时,能表现出关键词与文档之间关联的强弱.
将关键词k表示为kx,文档f表示为fy,关键词k在文档f中出现的次数表示为nx, y,文档集合中文档数表示为M.则:
(2.1)
(2.2)
(TF-IDF)x, y=TFx, y*IDFx
(2.3)
当比较基因k与病历文档f之间的关联时,运用TF-IDF模式能有效发现基因与疾病之间的关联.在运用TF-IDF模式时,关键词出现的词频是一个重要的参数,也就是说挖掘关键词对应的频繁项是重要的研究内容.数据挖掘的关联规则算法正是通过挖掘频繁项来确认两个项之间的关联度强弱.
FP-Growth算法是由经典Apriori算法改进而来的.Apriori算法在挖掘频繁项时会生成大量候选集,效率较低.FP-Growth算法只需要在挖掘过程中扫描数据集两次,通过递归演算FP-tree子项频次的方式,剔除频次较低(关联度低)的子项,最终形成单一的路径,效率较高.一个FP-Growth算法的流程如图1所示.
FP-Growth算法构造FP-tree来存储项的频次,每个项以路径的方式存储在FP-tree中.FP-tree在构建的过程中删除小于最小支持度(最小项出现频次)的项,留下出现频次较高的项.与其它树形结构不同,FP-Growth的项可以在一个FP-tree中出现多次.一个FP-tree中的项只有在项-频次完全不同的时候,才会分枝.FP-tree节点表示为一个项及其在序列中出现的频次,路径表示该序列出现的次数.越靠近根节点的项,其频次越高.一个FP-tree通过链接来连接相似的项,类似于一个链表.一个FP-tree示例图如图2所示.

图1FP-Growth算法的流程图
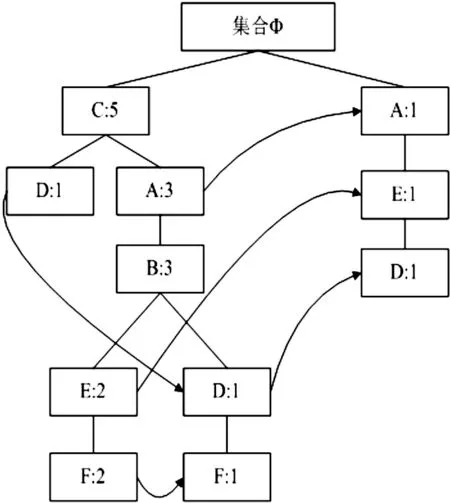
图2 一个FP-tree示例图
3 FP-Growth算法局限与改进
FP-Growth算法不需要在构建过程中存储频繁项集,所以对算法空间的利用率较高.但是FP-Growth算法属于深度优先算法,在构建的过程中递归地调用树结构,形成每一条路径分枝,这就导致了当数据集比较大的时候,为了能生成路径,FP-Growth算法会反复遍历FP-tree,构造数据的FP-tree结构会变得很庞大,对系统资源的消耗较大,甚至可能导致内存溢出.
为了能够降低FP-tree在构建过程中的内存消耗,提高其路径计算的并行性是一个可行的方法.
许多学者已经对FP-Growth算法的并行优化提出了自己的建议,学者孙鸿艳等基于Map/Reduce并行计算模型,对频繁模式树的存储结构进行改进,并利用HDFS实现数据存储[13];学者陆可等基于Spark框架, 通过对支持度计数和分组过程的优化改进了FP-Growth算法[14];学者朱颢东等提出的基于Hadoop框架的分布式FP-Growth算法,以实现海量数据的频繁模式FP挖掘方式[15];学者李赞等提出基于FP-growth的前后部项约束关联规则挖掘算法,关键在于对用户感兴趣的规则前后部项进行标记,构成约束条件,能对事务集进行筛选,压缩事务空间[16];学者何晴等用哈希头表代替头表,通过合并频繁模式树中支持数相同的结点,压缩了树的规模[17].
本文以粒子群优化,提出一种改进的FP-Growth算法.改进的基本思路分为两步:
第一步,先将要进行分析的数据集分成若干块.这里采用平均分配的切分法,避免随机大小的数据块引发效率不平衡问题.切分后的数据集小于原数据集,因此在分别进行递归运算构造FP-tree时能较好地被载入内存.同时,分块数据集能够进行并行构造操作,以提升算法的效率;
第二步,当数据集被分块操作之后,显然进入路径计算的并行构建阶段.针对并行优化的算法有很多,这里采用粒子群优化算法.
粒子群优化算法(PSO,Particle Swarm Optimization)是一种并行算法,源于对大规模外出的鸟群觅食方式的模仿.粒子群优化算法假设每一只外出在搜索空间觅食的鸟儿就是一个粒子,它对应每个问题的优化解.鸟儿粒子在随机搜索问题最优解的时候,搜索已经确认离食物(最优解)最接近的附近区间.每个鸟儿粒子的属性表示为由优化函数所决定的一个适应值,并且带有一个决定粒子下一步搜索方向和距离的速度.当鸟儿粒子初始化时,是一群随机的鸟儿粒子群,在每一次迭代过程中,个体鸟儿粒子随时向整个鸟群共享自己的信息,以帮助其它鸟儿粒子调整更新自己的状态.用于更新个体鸟儿粒子的参数有两个,其中一个参数是个体鸟儿粒子本身所找到的最优解,即个体极值;另一个参数是个体鸟儿粒子共享信息后,整个鸟群当前找到的最优解,即全局极值.随着迭代运动的继续,粒子群体在解空间中由随机、无序的初始化状态,慢慢进化,最终得到最优解.
设同时有n个鸟儿粒子在D维搜索空间中搜索飞行,在某一时刻n,鸟儿粒子i有位置xi、飞行速度vi、个体最优解极值pi、当前全局最优解极值pg等几个参数,即鸟儿粒子i在搜索过程中对应的位置Xi、速度Vi、个体最优解极值Pi、当前全部鸟儿粒子搜索到的全局最优解极值Pg为:
Xi=(xi1,xi2, …,xiD)i=1, 2, …,N
(3.1)
Vi=(vi1,vi2, …,viD)i=1, 2, …,N
(3.2)
Pi=(pi1,pi2, …,piD)i=1, 2, …,N
(3.3)
Pg=(pg1,pg2, …,pgD)i=1, 2, …,N
(3.4)

(3.5)
其中ω为惯性因子,c1和c2为学习因子,δ和η为[0, 1]之间的随机数.
4 改进Fp-Growth算法的基因-疾病关系提取
基因数据集与病历文本数据集都是比较特殊的文本,呈现高度的离散性,适合使用FP-Growth算法进行关联规则挖掘.而粒子群算法也在适合离散的解空间中并发操作,优化最优解的查找.以粒子群算法优化FP-Growth算法在基因-疾病关系自动提取运算时,因为基因数据集相对规范,结构化程度高,所以这里只对病历文本数据集进行数据集分块.利用粒子群算法改进的FP-Growth算法的基因-疾病关系提取过程图如图3所示.
提取过程包括以下几步:
第一步,读取基因数据集和疾病文本数据集;
第二步,将病历数据集平均分为n块,减少载入内存的负担,做并发处理之用;

图3 改进的FP-Growth算法的基因-疾病关系提取过程图
第四步,并发处理的模块i中,递归添加构建FP-tree i;
第五步,并发处理的模块i中,以粒子群算法优化规则学习,迭代地搜索全局最优解,加快搜索效率,生成优化的树结构路径与节点链接;
第六步,并发处理的模块i中,生成FP-tree,列举所有组合i;
第七步,合并FP-tree;
第八步,导出、筛选基因-疾病关联关系频繁项,生成规则集,提取其中有意义、有价值的信息并解读.
在合并FP-tree的过程中,由于并发操作得到的结果必然存在频次相同的节点,因此对FP-tree的合并原则主要有:
(1)如果节点i的子节点>1,则节点i不能再进行向上的合并操作;
(2)只有相同频次的节点(项)才能被合并;
(3)合并后的节点,以合并的所有节点组合为名.
5 仿真实验
本文在实验时采用NCBI数据库的子库PubMed数据库,读取其中的基因序列数据,疾病文本数据使用武汉某医院神经内科的病历文本转换而得的主题数据集.通过改进的FP-Growth算法对其进行基因-疾病关系的文本挖掘所得出的规则集,经由专业医生确认有较好的相关性,使用粒子群算法优化后,FP-Growth的运行效率更是明显提高.
6 结论
FP-Growth算法对疾病相关文本的挖掘有较好的适应性,但FP-Growth算法在数据集较大时,对内存载入有较大的负担.本文提出划分数据集,以并行的方式生成FP-tree的方法,并由粒子群算法改进FP-tree的构建,加快了FP-tree的生成.实验的不足一则在于病历文本的样本数仍然不足,对验证大数据集上的FP-Growth算法的效率仍嫌不足;另一方面则是中文病历文本的数据挖掘准确性还应该继续提升,在中文划分词组、疾病别名与基因关联关系、疾病别名与疾病权威名对应关系等方面,需要进一步的数据质量提升.这是需要进一步改进的问题.
猜你喜欢
学与玩(2022年9期)2022-10-31
客联(2022年3期)2022-05-31
新世纪智能(数学备考)(2021年9期)2021-11-24
中国新闻周刊(2021年26期)2021-07-27
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
天津诗人(2017年2期)2017-11-29
读者(2017年5期)2017-02-15
信息安全研究(2016年4期)2016-12-01
