
空间相关性分析的符号数据分类方法*
2019-07-11 07:28付康安王文剑郭虎升
计算机与生活 2019年7期
付康安,王文剑,郭虎升
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006
1 引言
在现实生活中,符号数据(categorical data)[1-2]在实际应用领域普遍存在,例如在生物医学中,构成DNA序列的核苷酸属性由A、T、G和C四种离散的符号编码而成,血型分为A、B、O和AB型等。这类数据的属性取值是一个有限的符号集合,是定性的,仅描述数据的特征,不提供实际的大小和数量,包括标称属性和序数属性。其中,标称属性的属性值彼此之间没有顺序,只有两种状态,即“等”或“不等”,例如“性别”属性,有“男”和“女”之分;而序数属性的属性值彼此之间有顺序,但相互之间的差值是未知的,属性值关系是“大于”“小于”“等于”,如“饮料量”属性有“大杯”“中杯”“小杯”等属性值,很明显,“大杯”和“小杯”之间的差异性要比“大杯”和“中杯”之间的差异性大。尽管在公开的数据集上下载的符号数据集中大多数是1、2、3等数字,但那只是表示不同的属性值,仅仅是为了方便存储等考虑,不能进行定量分析。
由于符号数据缺乏数值数据固有的几何特性,因此对于数值数据分析的理论和算法无法直接应用在符号数据上。目前关于符号数据的分析主要集中在聚类分析方面[3-7]。对于符号数据的分类,较经典的算法有决策树算法、贝叶斯分类器,其中代表性的算法有C4_5决策树算法[8-9]、朴素贝叶斯分类器[1-2](naive Bayes classifier,NBC),也有采用0-1相异性度量的K-最近邻算法[2,10](K-nearest neighbor,KNN)。尽管这些算法能够进行符号数据分类,但是这些方法要么简单地假定符号属性之间是相互独立的,而这又与实际情况不符;要么通过简单的0-1相异性度量或者其扩展版本,但这种度量方法并不能很好地揭示符号数据的内在组成结构,这些问题都会影响最终的分类结果。同时,相较于数值数据分类算法,符号数据的分类算法在分类性能上仍然有很大的提升空间。因而,为了有效地提高符号数据的分类性能,研究符号数据的分类方法仍然有很大的应用价值。
综上所述,由于符号数据缺乏数值数据固有的几何特性,使得那些性能优越的数值数据的分类方法无法直接处理符号数据。为了有效提高符号数据的分类性能,通过深入挖掘符号数据不同属性值与标签之间可能存在的空间结构关系,结合互信息和条件熵信息度量方法,定义了一种符号数据空间表示方法。该方法既能够保留符号数据的原始信息,也体现出属性值与标签之间的相关性,还能够有效地度量不同属性值之间的差异性。在此基础上,分别与SVM(support vector machine)[11]和KNN模型分类器相融合,提出一种基于空间相关性分析的符号数据分类方法SCA_SVM(SVM classification algorithm based on space correlation analysis)算法和SCA_KNN(KNN classification algorithm based on space correlation analysis)算法。在UCI标准数据集上,通过与其他传统的符号数据分类方法进行实验对比,结果表明SCA_SVM算法和SCA_KNN算法能够有效地提高分类性能。
2 空间相关性分析的符号数据分类方法
2.1 属性与标签的空间相关性分析
给定一个样本集D={(x1,y1),(x2,y2),…,(xn,yn)}其,中xi为样本,yi∈{1,2,…,C}为样本标签,A={a1,a2,…,am}是m个特征属性的集合,aj的取值范围为{aj1,为变量(对应当前属性可取值的个数,|d|≥ 2),xij是样本xi在特征属性aj下的符号属性值。
为了进一步计算符号数据特征属性中不同属性值之间的距离或相似度,首先将原始符号数据的特征属性通过独热编码(直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制)的方式映射到欧式空间,也就是进行特征扩容,这样属性值之间的距离就可以在欧式空间中进行几何运算。在此基础上,为了更好地度量不同属性值之间的距离或差异性,通过分析属性值和标签之间的相关性,定义了一个符号数据量化表示方法。
在新的表示方法中,首先分析属性值和标签之间的相关性,这里借鉴互信息和条件熵两种信息度量方法,定义了两个不同的相关性计算方法I(·)和H(·)。特征属性aj下属性值ajk和标签c的相关性和计算方法如下:
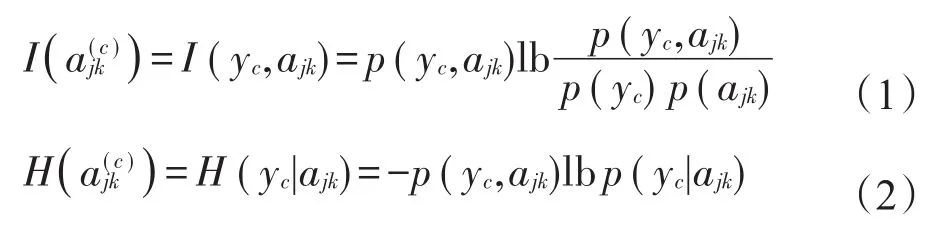
其中,p(ajk)、p(yc)、p(yc,ajk)和p(yc|ajk)分别表示属性aj取值为ajk的概率,标签yi取值为c的概率,ajk与yc的联合概率和条件概率。依据大数定律,这里使用频率来近似表示相应的概率。计算方法如下:

式中,IF(·)是一个指示函数,即IF(tr ue)=I1,F(false)=0。
由式(1)~式(3)可以得到两个属性值ajk与标签的相关性矩阵O-I(ajk)和O-H(ajk),表示形式如下:

对于特征属性aj,其不同属性值的O-I(aj)表示过程如下所示:

O-H(aj)的形成过程与O-I(aj)类似,其展开形式如下:

对于样本xi,基于空间相关性分析的O-I(xi)和O-H(xi)表示形式如下:


通过挖掘符号数据不同属性值与标签之间的相关性,定义一个符号数据量化表示方法,该方法不仅可以保持原始符号数据的信息完整性,而且能够有效度量不同属性值之间的差异性。
2.2 基于空间相关性分析的分类方法
基于空间相关性分析的符号数据表示方法将符号数据特征属性的属性值映射到空间表示的结构中,使得传统的面向数值数据的分类方法都能得到应用。本文采用两种通用的分类模型SVM和KNN,与相关性度量方法I(·)和H(·)结合进行分类学习,得到SCA_SVM-I、SCA_SVM-H、SCA_KNN-I、SCA_KNN-H四种模型。
2.2.1 SCA_SVM算法

步骤1对于训练集TrainU,根据式(1)或式(2)分别计算出各属性值和各个标签之间的相关性或。
步骤2通过空间相关性分析方法,根据式(6)或式(7)将符号数据重新表示在相关性矩阵O-I(xi)或O-H(xi)中。
步骤3在新的O-I(xi)或O-H(xi)上用SVM进行训练,得到分类超平面f。
步骤4根据O-I(xi)或O-H(xi)将测试集TestX转换为相应的数值数据OTestX(xi),用得到的分类超平面f进行分类测试。调参数得到最优的分类的超平面f*,并统计实验结果。
2.2.2 SCA_KNN算法

步骤1对于训练集TrainU,根据式(1)或式(2)分别计算出各属性值和各个标签之间的相关性或。
步骤2通过空间相关性分析方法,根据式(6)或式(7)将符号数据重新表示在相关性矩阵O-I(xi)或O-H(xi)中。
步骤3根据O-I(xi)或O-H(xi)将测试集TestX转换为相应的数值数据OTestX(xi)。
步骤4根据欧氏距离的度量方法,找到最近的K个样本点,按照投票的方式进行标签预测,并统计实验结果。
3 实验结果与分析
为了验证算法的有效性,本文将SCA_SVM和SCA_KNN算法应用于UCI数据集,并与C4_5、NBC、KNN和Chen[12]算法进行比较。由于本文的重点在于如何挖掘不同属性值和标签之间的关系,因此有关KNN和SVM模型参数选择将不在文中具体讨论,相关内容可参考文献[13-14]。这里KNN模型的参数K取3,SVM模型采用RBF的核函数,核参数取1,惩罚参数c设置为1 000,本文算法的属性权重wj参数全部设置为1/m。为了减少实验的随机性,所有实验重复10次,取均值为实验结果。
3.1 数据集与性能评价指标
本文选取了UCI数据库[15]上9个常用的符号数据集进行实验分析,如表1所示。
本文采用“微F1”(micro-F1)[2]作为分类性能的

Table 1 Description of experimental data sets from UCI表1 UCI上的实验数据集描述
评价指标。其定义如下:

3.2 结果比较与分析
3.2.1 两种相关性度量的比较
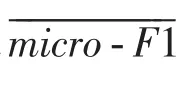

Table 2 Confusion matrix表2 混淆矩阵

其中,nup和ndown分别表示测试准确率大于和小于平均分类性能指标的个数。
从图1可以看出,对于相关性度量方法I(·)和H(·),从评价指标micro-F1上看,KNN模型分类器,相关性度量方法I(·)在7个数据集上的micro-F1指标更高,其中的3个数据集(promote、Hayes-Roth和balance)上优势比较明显,而在另外的两个数据集(dermatology和Tic-Tac-Toe)上的结果与度量方法H(·)相差不大。SVM模型分类器,两种度量方法的micro-F1指标基本一致。从标准差STD上来看,两种度量方法的STD的差别不太明显,离散程度基本一致,表明算法的鲁棒性较好。
3.2.2 与Chen方法的比较
Chen方法[12]是一种基于核方法的分类方法,可以用于朴素贝叶斯分类器(NBC)、K-最近邻(KNN)等模型中,具有良好的分类性能。本小节将SCA_SVM和SCA_KNN与之比较,比较结果如表3所示。由于文献[12]中没有给出详细的算法,只列出了结果。因此,这里只在6个相同的数据集上进行实验结果的对比,最优的micro-F1值由下划线标出。
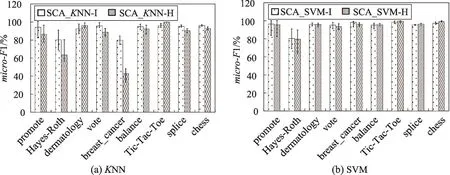
Fig.1 Comparison of micro-F1 between two measures on same model图1 两种度量方法对同类模型micro-F1的比较
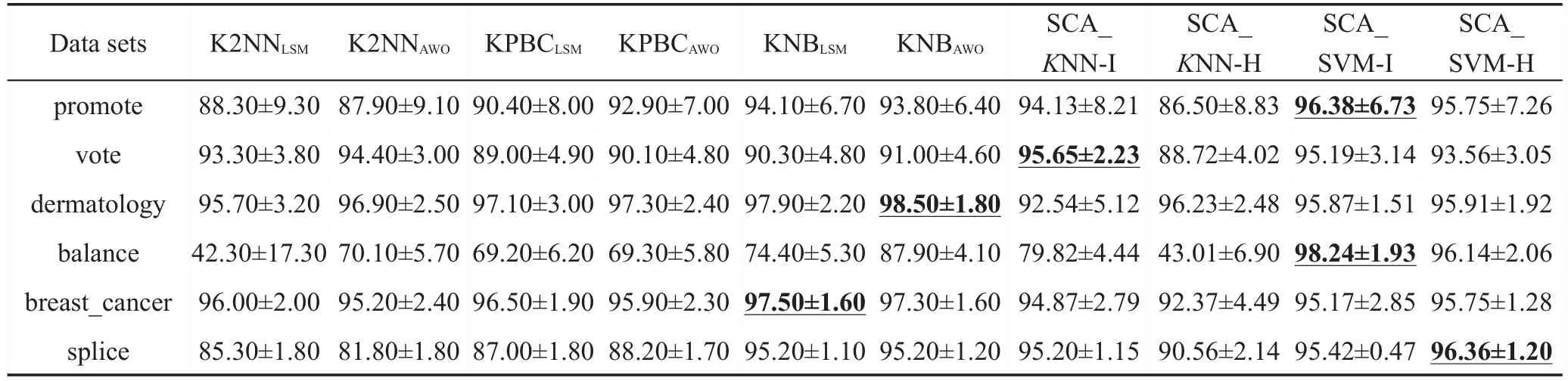
Table 3 Comparison of micro-F1 with Chen approaches表3 与Chen方法的micro-F1对比 %
从表3可以看出,本文提出的SCA_SVM算法比Chen提出的基于不同分类器下的6种算法在评价指标micro-F1上要好。尤其在数据集balance上的micro-F1值更明显,相较于KNB(kernel naïve Bayes)模型提高了10.34%(98.24%-87.90%),相较于K2NN(kernelK-nearest neighbor)模型提高了28.14%(98.24%-70.10%),相较于KPBC(kernel prototype-based classification)模 型 提 高 了 28.94%(98.24%-69.30%)。SCA_KNN算法比Chen提出的基于KNN模型分类器的K2NN算法以及KPBC算法在4个数据集上的结果更优,而在另外的dermatology和breast_cancer上相差不大。
3.2.3 与其他方法的比较
在9个UCI符号数据集上,本文4种算法与C4_5决策树、NBC算法和KNN算法3种传统的符号数据分类算法评价指标micro-F1(均值±标准差)的实验对比结果如表4所示。每个数据集上最优的micro-F1值由下划线标出,↑表示本文方法比其他3种方法最优micro-F1值更好。其中KNN方法采用0-1相异性度量方法计算距离。
从表4可以看出,在采用的9个UCI数据集中,相比其他3种算法,本文算法在绝大多数的数据集上的分类性能是最优的。其中,基于SVM模型分类器的两种算法在8个数据集上都提高了分类性能,而在另外的breast_cancer上的结果也与最优的结果相近,差距为-1.44%,在balance上的准确率提高值最大,提高值为27.65%;基于KNN模型分类器的SCA_KNN-I算法在7个数据集上都提高了分类性能,在另外的dermatology和breast_cancer上的差距分别为-2.3%和-1.9%,而SCA_KNN-H算法在3个数据集(dermatology、Tic-Tac-Toe和splice)上提高了分类性能,在另外5个数据集上的结果与最优的结果相近,仅仅在balance上表现得不是太好。此外,从测试结果的标准差来看,相比其他3种算法,在micro-F1比较接近的数据集promote、vote和breast_cancer上,本文的SCA_SVM和SCA_KNN算法仅仅在breast_cancer上的标准差较大一些,这表明本文算法有更好的稳定性。
为了更直观地观察各算法的统计分布情况,图2给出各算法对9个数据集micro-F1指标的箱线图,并在图中分别用圆圈“○”和星形“*”标注均值和中值。
由图2可以看出,本文方法在7个数据集上的上下限范围较小,尤其在dermatology、balance、Tic-Tac-Toe和splice上的上下线范围最小,表现出非常高的稳定性。虽然本文方法在Hayes-Roth和breast_cancer的稳定性有较小的下降,但更高的上限值表明本文方法具有达到最优分类性能的能力,并在大多数数据集上有更高的上限。
为了进一步说明本文算法的有效性,对实验结果的评价指标micro-F1进行了T检验(T-test)并获得相应的P值(P-values),一般以P-values<0.05为显著,P-values<0.01为非常显著。首先,建立假设H0,SCA_KNN(或SCA_SVM)算法与其他算法之间的micro-F1没有显著性差异;假设H1,SCA_KNN(或SCA_SVM)算法与其他算法之间存在显著性差异。T-test对评价指标micro-F1产生的P-value如表5、表6所示(大于0.05的P-values值由下划线标出)。

Table 4 Comparison of micro-F1 index by different algorithms on data sets表4 数据集上不同算法的micro-F1指标对比 %

Fig.2 Boxplot of micro-F1 index for different algorithms on 9 data sets图2 不同算法在9个数据集的micro-F1指标的箱线图
从表5可以看出,绝大多数的P-values都小于0.05,并且大部分的P-values也都小于0.01,甚至远小于该值。这说明H0假设是不成立的,即假设H1成立,也就是本文的SCA_SVM算法与其他算法之间存在显著性差异。此外,对于在数据集dermatology、vote和breast_cancer上出现的不显著现象是符合实际情况的,因为从图2和表4上的结果可以看出这些数据集上的指标micro-F1值比较接近,具有相似的统计分布。
从表6可以看出,绝大多数的P-values都小于0.05,并且大部分的P-values也都小于0.01,甚至远小于该值。这说明H0假设是不成立的,即假设H1成立,也就是本文的SCA_KNN算法与其他算法之间存在显著性差异。此外,对于SCA_KNN-H算法出现比较多的不显著现象也是符合实际情况的,因为从图2和表4上的结果可以看出SCA_KNN-H算法的实验结果micro-F1与其他算法比较接近。
从上述的实验分析可以看出,在SVM模型分类器上,SCA_SVM-I算法和SCA_SVM-H算法相对于其他3种传统的符号数据分类算法以及Chen提出的算法具有更高的分类精度,且算法的鲁棒性也更好;在KNN模型分类器上,SCA_KNN-I和SCA_KNN-H这两种算法也比传统的KNN算法在分类性能上要更好。因此,本文提出的基于空间相关性的符号数据分类方法具有更好的分类性能。

Table 5 P-values produced by T-test for micro-F1 index(SCA_SVM algorithm)表5 T-test对指标micro-F1产生的P-values(SCA_SVM算法)
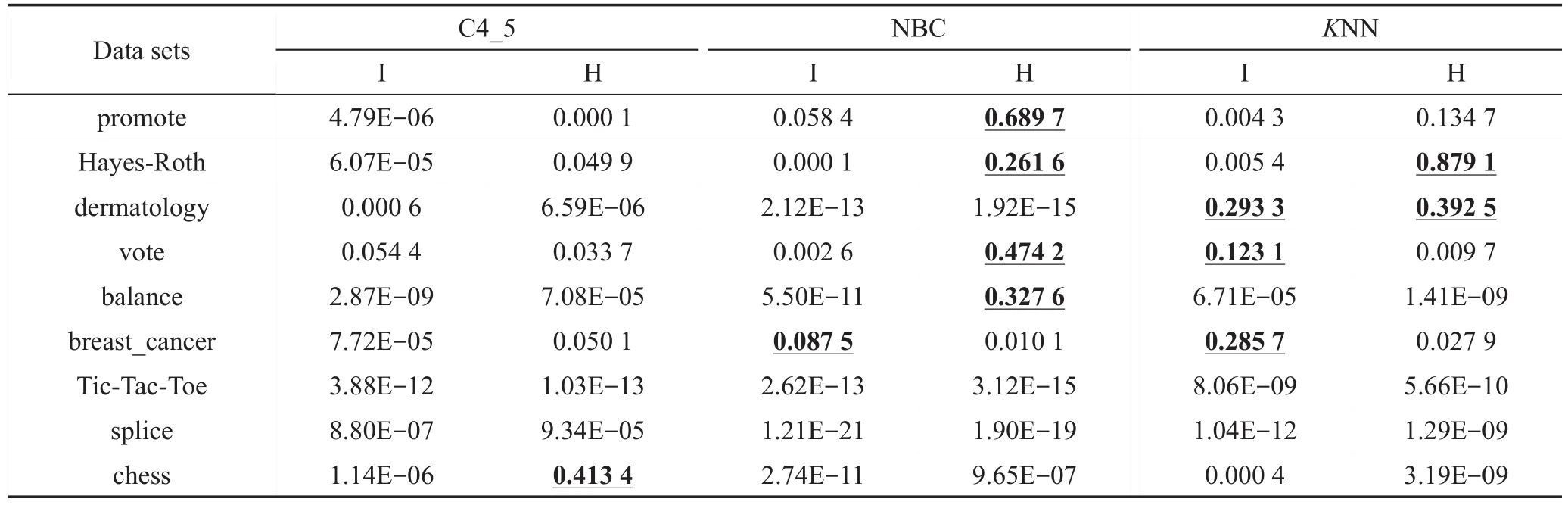
Table 6 P-values produced by T-test for micro-F1 index(SCA_KNN algorithm)表6 T-test对指标micro-F1产生的P-values(SCA_KNN算法)
4 结束语
本文针对符号数据分类方法分类精度低的问题,充分挖掘了属性值与标签的关联信息,提出了一种基于空间相关性分析的符号数据分类方法,通过定义两种属性值和标签的空间相关性表示方法,不仅可以保持原始符号数据的信息完整性,而且能够有效度量不同属性值之间的差异性,从而有效提高了符号数据的分类性能。另外,本文的研究工作也是对SVM和KNN模型分类器应用的扩充。然而,由于在数据的再表示过程中,为了保留符号数据的完整性,对原始数据进行了特征扩容,这就直接提升了原始数据集的维度,造成了分类模型复杂化。在未来的工作中,针对该问题将考虑引入特征选择的方法或者针对特征属性设置阈值,以评价是否对该特征进行特征扩容,从而避免由于维度灾难导致的模型复杂化和分类效率降低。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
电子产品世界(2022年4期)2022-04-21
计算机研究与发展(2022年1期)2022-01-19
计算机系统应用(2021年2期)2021-02-23
计算机应用(2020年12期)2020-12-31
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机测量与控制(2019年4期)2019-05-08
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
文苑(2015年9期)2015-09-10
