
深度学习模型下多分类器的入侵检测方法*
2019-07-11 07:28陈建虎肖成龙万广雪肖振久
计算机与生活 2019年7期
陈 虹,陈建虎,肖成龙,万广雪,肖振久
辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105
1 引言
随着信息化及互联网的高速发展,网络已遍布生活中的各个角落,伴随而来的就是网络安全问题,其中,如何有效识别网络攻击行为是网络安全中的核心问题。入侵检测(intrusion detection)技术作为解决该核心问题的解决方案之一,一直以来是网络安全人员研究的热点,也取得了很好的检测效果。但近些年,随着网络信息的爆炸性增长,传统入侵检测方法很难在海量数据环境下取得较好的检测效果,因此,如何在海量数据环境下构建一种有效的入侵检测模型成为亟待解决的重要问题。
目前,基于机器学习(machine learning)的入侵检测是该领域的一个重要研究课题[1],但将单一的机器学习算法应用于入侵检测分类过程往往难以直接获得一个有较强泛化能力的分类器。集成学习(ensemble learning)的出现很好地解决了这一问题。研究表明,集成学习能够提高分类器的泛化能力[2]。1991年由Freund提出的提升算法(Boosting)[3-4]是最具代表性的集成学习算法之一,该算法用于分类问题中首先通过改变训练样本的权重学习多个弱分类器,然后将这些分类器进行线性组合得到强分类器,但该过程要求事先知道弱分类器分类正确率的下限。针对这一缺陷,1995年Freund和Schipare改进了Boosting算法,提出AdaBoost算法。该算法将指数函数作为损失函数,且不需要任何弱分类器的先验知识,被广泛应用于各种实际问题中[5-6]。2001年,Friedman在AdaBoost算法的基础上,对AdaBoost算法进行改进,提出了Gradient Boosting框架算法。该算法的损失函数除指数函数外,还可为平方损失函数、对数函数[7-8]。Gradient Boosting通常将决策树作为基础模型,因此往往被称为梯度提升决策树(gradient boosting decision tree,GBDT)。GBDT由多棵决策树累加而成,其令模型损失函数总是沿着梯度下降方向,通过不断迭代最终使得残差趋近于0。该模型每次训练都可得到一棵决策树,其过程简单、高效,且对训练数据有着很好的解释性。同时将训练好的基础决策树进行累加得到的强分类器对数据有着稳定且高的分类精度。其次相较于传统的机器学习方法需经过繁琐的调参、训练、验证等流程才能得到较强的分类模型,GBDT只需训练若干弱分类器便可,大大降低了计算资源的消耗。因此,GBDT被广泛应用于解决分类及回归问题[9-10]。但目前很少有文章将GBDT应用于入侵检测领域,本文充分利用GBDT的强泛化能力,对数据的可解释性,模型简单、高效且对数据分类精度高、实用性强等特性,将其应用于入侵检测的分类中。然而,现有网络入侵检测数据呈现海量、高维的特性,利用该数据训练GBDT分类器时,如果数据的输入特征数目过大,则会严重影响分类器的性能,造成分类性能较差。同时该数据中可能存在一些无意义或有相互依赖关系的特征,大量此类特征的存在容易引发“维数灾难”且使得模型内部结构变得复杂,计算难度增大,不利于实际应用[11]。因此,如何解决这些问题是将GBDT应用于入侵检测分类中的前提。
2006年,Hinton等人提出了一种深度信念网络(deep belief networks,DBN)的深度学习模型,该模型通过组合低层特征形成更加抽象的高层表示属性类别,以发现数据的分布式特征表示,其以强大的自动特征提取能力在语音识别、图像识别等领域取得了巨大的成就[12-15]。通过这些领域的研究发现DBN在处理海量、高维的复杂数据方面比传统神经网络更加优异。将DBN应用于复杂入侵检测数据的处理过程具有以下优势:(1)利用DBN强大的特征提取能力,从高维的数据中自动提取特征,降低了数据各特征之间的依赖关系,同时实现了对高维数据的降维;(2)DBN模型通过建立各层之间的数据映射,能够很好地表征原始特征数据与所提取特征数据之间复杂的映射关系,非常适用于对海量、高维数据的处理,具有一定的实用性。目前,将DBN应用于入侵检测领域仍处于探索阶段[16],文献[17]提出一种基于DBN的混合入侵检测模型,该文将DBN与其他非深度结构的特征学习方法进行对比,并利用SVM(support vector machine)分类器进行分类,从而验证了DBN较传统浅层机器学习方法的学习效率更高。文献[18]提出一种DBN-MSVM(deep belief nets based multiclass support vector machine)的入侵检测模型,该模型在DBN的基础上利用二叉树结构构造SVM分类器,取得了很好的分类效果。文献[19]首先利用概率质量函数(probability mass function,PMF)对数据进行编码,然后利用DBN进行分类,该方法在一定程度上提高了DBN模型的分类精度。文献[20]对深度学习应用于网络安全的现状以及发展趋势进行了详细的阐述及展望,对入侵检测方法的探索有指导意义。
本文将GBDT应用于入侵检测领域,针对GBDT在入侵检测分类过程中存在的问题,充分利用DBN对海量、高维数据处理的优势,提出一种深度信念网络下一对一梯度提升树的多分类器(multi-classifier for one-to-one gradient boosting decision tree under deep belief network,DBN-OGB)入侵检测方法。该方法首先利用海量入侵数据经预训练、微调构建出较优的深度信念网络。然后,利用该网络从输入数据中自动提取出低维、具有代表性的特征数据。接着,将得到的特征数据根据对应的标签每两类分为一组分类器训练数据,并利用GBDT对各组数据进行训练,得到对应的二分类分类器模型。最后,通过训练得到的所有二分类器便可对数据进行分类,分类过程中使用一对一法,即数据在所有分类器中出现最多的类别为该数据的分类类别。利用NSL-KDD数据集[21]进行仿真实验表明,DBN-OGB方法在海量数据中有着稳定且高的准确率和检测率,为海量数据下入侵检测模型的构建提出了一种新的方法。
2 相关理论
2.1 深度信念网络
深度信念网络是一种由多层受限玻尔兹曼机(restricted Boltzmann machines,RBM)堆叠构成的无监督的层级产生式模型(hierarchical generative model)。该模型旨在将学习到的信息进行逐层传递,从而在最高层得到信息的低维特征表示。其模型如图1所示。
由图1可知,DBN模型学习过程可分为预训练(pre-training)和微调(fine-tuning)两个阶段。在预训练阶段,各RBM层独立训练,并将低层RBM的输出作为高一层RBM的输入,直至最后一层RBM训练结束。该过程只是保证数据各RBM层的训练达到最优,为了让DBN模型达到全局最优,在预训练过程结束后对模型进行微调。微调过程通常选用BP(back propagation)算法,采用有监督的学习方式,利用模型实际输出与期望输出之间的误差进行反向传播,从而对DBN模型参数进行全局调优。
2.1.1 RBM训练过程
受限玻尔兹曼机(RBM)本质上是一种基于能量的、由可视层(visible layer)和隐藏层(hidden layer)中的神经元彼此相互连接构成的具有两层结构且无自反馈的生成式随机神经网络。
图2给出了一个具体的RBM模型,其中可视层、隐藏层分别有n、m个神经元,vi、hj分别为可视层和隐藏层的第i个和第j个神经元节点的状态值,ai、bj分别为对应神经元的偏置(bias),w为层间连接权值,用wij表示可视层第i个神经元与隐藏层第j个神经元之间的权值,θ=(w,a,b)表示模型整体参数。算法1给出了k为1时利用CD-k快速学习算法[22]训练RBM模型的过程。其中S表示训练数据集,S(t)表示该集合中的第t条数据,T表示数据总量,η为学习率,error为训练过程中产生的误差。

Fig.2 RBM model图2 RBM模型
算法1RBM训练过程


2.1.2 BP反向传播
BP神经网络在训练过程中可根据训练数据输出结果与期望结果之间的误差进行误差反向传播,从而对网络中各层权值进行更新。根据这一特性,在DBN模型最高层添加一层实际输出结果,这样便可根据输出结果的误差值利用BP反向传播对DBN模型中的参数进行微调。BP神经网络通过误差信号的求解来进行误差反向传播,假设BP网络中h表示第h个隐层,各隐层按前向输出分别记为y1,y2,…,yh。d表示期望输出,o表示实际输出,j表示前层第j个神经元,k表示后层第k个神经元,w为各层权值,c为各层偏置,μ表示学习率。则输出层的误差信号为:

第h隐层的误差信号为:
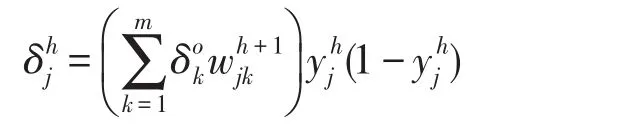
则各层权值调整为:

根据式(3)便可对DBN模型中的参数进行微调。
2.2 GBDT训练过程
GBDT是一种利用Gradient Boosting方法迭代地生成多个弱分类器并整合成一个强分类器的决策树累加模型,其思想如图3所示。
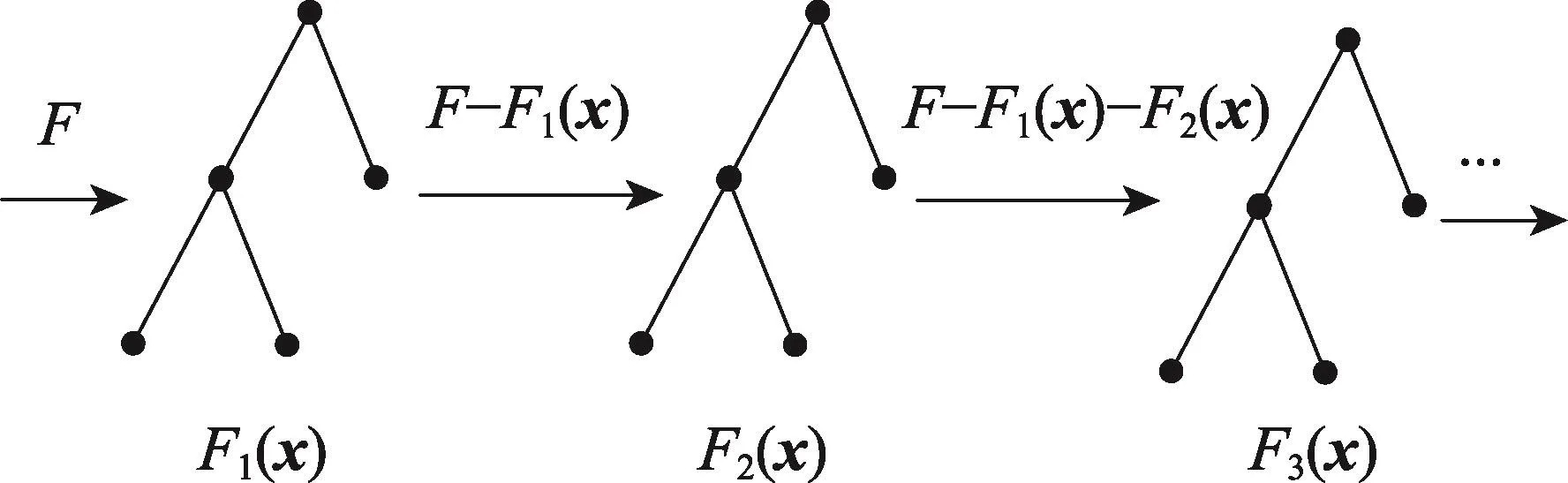
Fig.3 GBDT iteration model图3 GBDT迭代模型
由图3可知,GBDT模型的训练过程是线性的。假设输入向量值x和输出值y之间存在着未知的数量关系,目的是学习一个函数F(x)来预测数值结果y。训练过程中,首先通过训练数据F训练第一棵决策树,得到其预测值F1(x),然后根据F1(x)与F的残差训练第二棵决策树,得到其预测值F2(x),以此类推,模型最终结果是将各棵决策树进行累加,即F(x)=F1(x)+F2(x)+…。
在每个弱分类器的训练过程中,都是对残差进行拟合,即为损失函数的反向梯度。假设m表示第m个弱分类器,则残差拟合后,前一次迭代预测值Fm-1(x)加上本轮拟合残差hm(x)便可得到Fm(x)。对于给定损失函数L(y,F(x)),学习率为ρ,共有M个弱分类器的GBDT模型,其训练过程如算法2所示。
算法2GBDT training process


3 DBN-OGB方法
本文提出的深度信念网络下一对一梯度提升树的多分类器入侵检测方法的详细实现过程如图4所示,包括训练和测试两个过程,每个过程都通过三个步骤实现,实验过程中利用NSL-KDD数据集进行仿真。
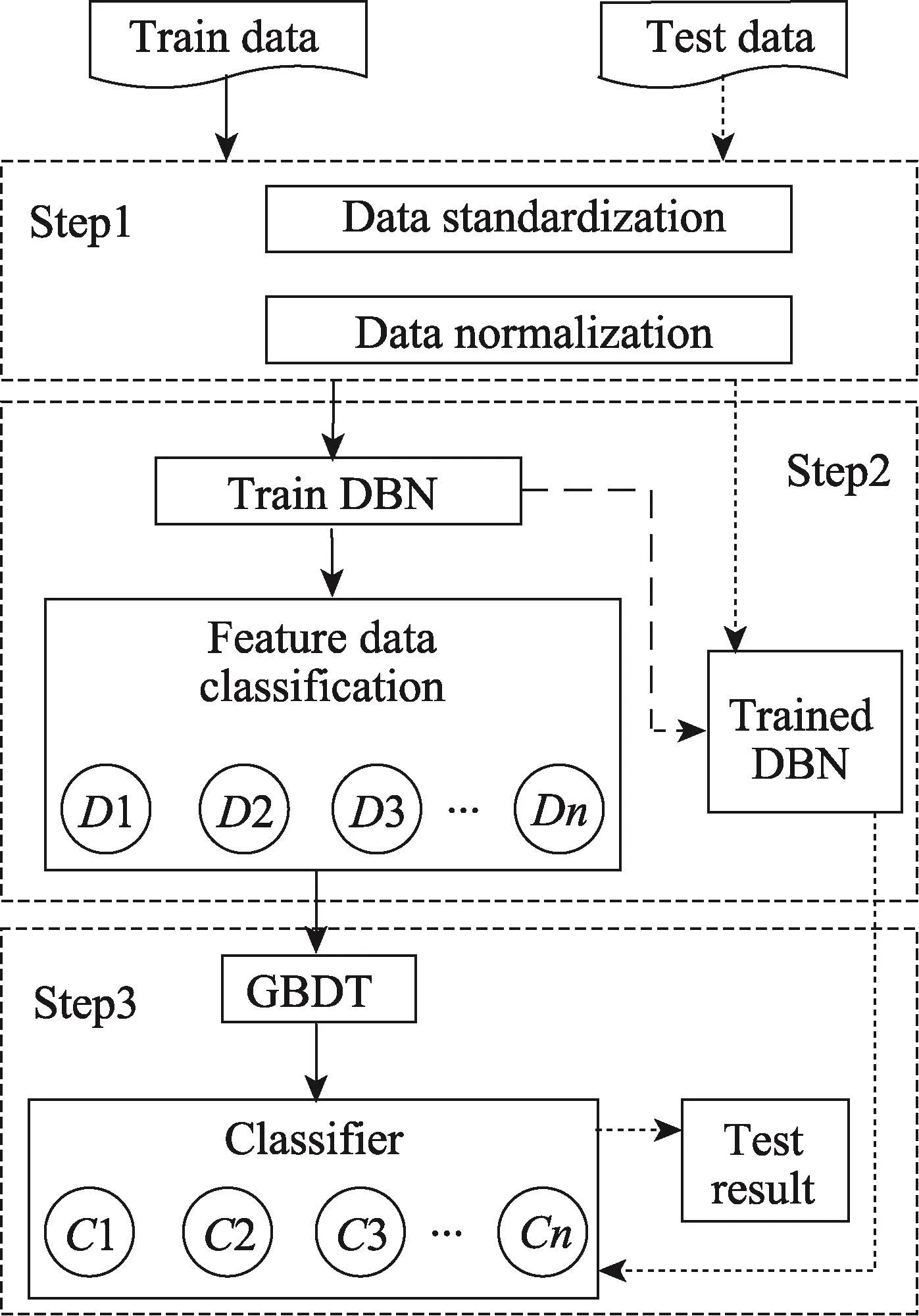
Fig.4 DBN-OGB method图4DBN-OGB方法
3.1 训练过程
选取带有标签的数据集(train data)对模型进行训练,图4所示的DBN-OGB方法训练过程如下:
步骤1将训练数据集中的特征数据和对应的标签进行分离,并对特征数据进行标准化(data standardization)和归一化(data normalization),对标签数据进行数据映射,这样便可利用映射数据对DBN模型进行微调。其详细处理过程见4.2节。
步骤2训练DBN模型(train DBN)分为预训练和微调两个阶段。
预训练过程如下:
(1)初始化训练总次数为P,p=1为第p次训练,将步骤1中处理后的特征数据作为第一层RBM的输入。
(2)输入所训练RBM层的训练数据。
(3)根据算法1训练RBM模型。
(4)若error的值小于所规定的误差值或p>P,则该RBM层训练结束,保存该层参数,并将该层的输出作为下一RBM层的输入,执行(2);否则,执行(5)。
(5)根据算法1训练RBM模型,但本次训练过程中RBM模型的参数θ由上一次训练得到。
(6)p+=1,执行(4)。
微调过程如下:
(1)在DBN模型的最高层添加一层输出层,初始化其与最高RBM层之间的权值。初始化训练总次数为Q,q=1为第q次训练,输出误差bp_error=0。步骤1中处理后的特征数据为BP模型的输入数据。假设该数据总数为T,t=1为第t条数据。BP模型初始化参数为预训练过程中得到的参数θ。
(2)输入第t条数据,根据模型参数θ结合式(1)计算各层的输出。
(3)计算输出层期望输出与实际输出的误差,假设BP模型中变量定义如2.1.2小节所示,则bp_error+=sum((dk-ok)2)。
(4)根据式(3)对模型参数θ进行更新。
(5)若t<T,则t=t+1,执行(2);否则执行(6)。
(6)若bp_error=bp_error/T小于规定的误差或q>Q,则微调过程结束,保存模型参数;否则执行(7)。
(7)q+=1,t=1,bp_error=0,执行(2)。
通过上述两个过程的训练,便可得到训练好的DBN模型(trained DBN)。由于本文所采用的GBDT模型只能对数据进行二分类,因此在该模型中利用一对一法进行分类器的训练。一对一法训练分类器指对多个类别的数据每两类分为一组进行分类器的训练,即假设有k类数据,则需训练k(k-1)/2个分类器。因此,将训练数据通过DBN模型逐层传递,直至最高RBM层输出其对应的特征数据后,利用各条特征数据对应的标签将数据每两类分为一组分类器训练数据(feature data classification),其分类结果分别为D1,D2,…,Dn。
步骤3利用步骤2中得到的各组数据训练分类器(classifier)的过程如下:
(1)初始化弱分类器的个数M,学习率ρ,i=1,采用L(y,F(x))=ln(1+e(-2yF(x))),其为负二项对数似然函数。
(2)输入第i份训练数据Di,并将Di中的两种数据类别标签分别映射为-1和1。
(3)根据算法2训练强分类器Ci。
(4)i+=1,执行(2),直至所有的分类器训练数据训练完毕,执行(5)。
(5)保存各个强分类器,模型训练结束。
3.2 测试过程
利用训练好的分类器对带有标签的数据(test data)进行测试,图4所示DBN-OGB方法测试过程如下:
步骤1同训练过程中的步骤1,但该过程中对数据标签不做处理。测试过程中的数据标签只是为了与测试结果进行比较,从而验证入侵检测方法的性能。
步骤2将步骤1中处理过的特征数据输入训练好的DBN模型(trained DBN)中,经最高RBM层输出优化处理后的测试数据。
步骤3将优化后的各条测试数据分别输入到训练好的各个二分类器中,将分类结果(-1,1)映射为对应二分类器的数据标签,对该条测试数据的标签进行投票,票数最多的标签便为该条数据的分类结果,待所有数据测试完毕,输出测试结果(test result)。
4 实验分析
4.1 实验数据
本文采用NSL-KDD数据集中的训练数据(Train)和20%的训练数据(20Train)作为仿真实验数据。NSLKDD是在KDD99数据集的基础上去除冗余、不合理的数据所得到的数据集。该数据集能够很好地分析入侵检测方法的性能,且对于不同的入侵检测方法其评价结果是一致的,具有可比性。所选数据集中各种不同攻击的数据分布如图5所示。
4.2 数据处理
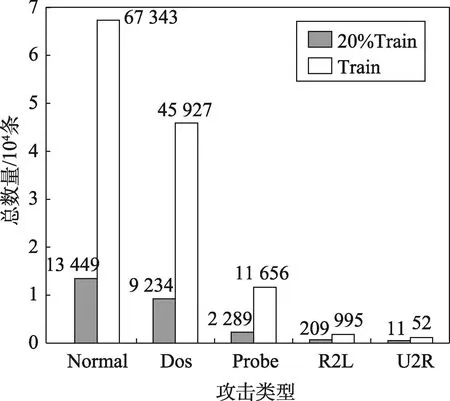
Fig.5 Attack data distribution图5 攻击数据分布
NSL-KDD数据集中,数据分为前41维的特征数据和第42维的数据标签(label)。特征数据中包含38个数值(numeric)类型特征和3个字符(nominal)类型特征,而在实际应用过程中往往需要统一的数据类型,其处理过程如下:
(1)标签分离。将数据中的特征数据和其对应的标签进行分离,对于训练数据,需对标签进行数值映射。本文采用五维整数进行映射,过程如下:将Normal映射为1,0,0,0,0;将Probe映射为0,1,0,0,0;将Dos映射为0,0,1,0,0;将R2L映射为0,0,0,1,0;将U2R映射为0,0,0,0,1。
(2)标准化。将特征数据中的3类字符类型(protocol_type、service、flag)标准化为数值类型,过程如下:protocol_type类型中3种字符tcp、udp、icmp对应的数值编码分别为1,0,0、0,1,0、0,0,1;同理,service类型中有70个不同的字符值,其对应的数值分别为从1到70对应位置取1,其余位置取0的二值编码;flag类型中有11个不同的字符值,其对应的数值分别为从1到11对应位置取1,其余位置取0的二值编码。特征数据经标准化后为122维的数据。

4.3 实验环境及评价标准
在入侵检测领域,准确率(accuracy,AC)、检测率(detection rate,DR)和误报率(false alarm,FA)是评价入侵检测模型好坏的几个重要指标。准确率用于评价模型整体的识别能力;检测率用于评价模型对攻击数据的识别能力;误报率用于评价模型对正常数据的识别能力。本文所采用的实验环境及评价标准如下。
(1)实验环境
操作系统,Windows 10;处理器,Intel®CoreTMi5-4200M CPU@2.50 GHz;内存(RAM),4.00 GB;系统类型,64位操作系统;编程环境,python3.5。
(2)评价标准
准确率、检测率及误报率的定义如下:

4.4 DBN-OGB方法参数设置
经过多次实验,结合参考文献[18],选取一组较优的DBN-OGB方法参数,详见表1。NSL-KDD数据集经处理后输入数据的维数为122维,即DBN模型的输入层神经元个数为122,选取3层RBM结构,其神经元个数依次为90、60、30,模型输出层神经元个数与标签映射数值维数相同为5。RBM训练过程中将训练数据每50条作为一个批次进行训练,所有批次数据训练完毕记为1次预训练,共训练300次。微调阶段,训练迭代次数为100,RBM和BP训练过程的终止误差值都为0.01。训练GBDT分类器过程中,弱分类器的个数为100。
4.5 实验结果
4.5.1 DBN-OGB方法验证分析
为验证DBN-OGB方法的有效性,本文采用十折交叉法进行验证,首先将20%的训练数据(20%Train)随机分成10份,每次将其中1份作为测试数据,剩下9份作为训练数据进行训练,这样便得到10份验证结果,见表2。

Table 1 Parameter settings表1 参数设置

Table 2 10-fold cross-validation表2 十折交叉验证
由表2可知,除第1、5组数据的检测率低于99%外,其余各组数据的准确率、检测率都高于99%。这10组数据的平均准确率、平均检测率分别为99.26%和99.21%,说明DBN-OGB方法具有稳定的检测性能,且其平均误报率为0.72%。这些数据说明该方法对于入侵数据的检测是有效的。
4.5.2 整体对比
为进一步分析DBN-OGB方法,本文从Train数据集中随机抽取如表3所示的5组实验数据对该方法进行验证,同时与DBN-MSVM方法、直接使用DBN方法及GBDT方法进行对比,具体实验结果如图6~图8所示,这5组数据的平均准确率、平均检测率、平均误报率见表4。
由表4中的数据可知,DBN-OGB方法整体上较对比方法中效果最好的DBN-MSVM方法的准确率和检测率分别提升了0.56%和1.03%,且该方法的性能明显优于直接使用DBN和GBDT方法。由图6、图7可知,对于不同的训练和测试数据,DBN-OGB方法的准确率和检测率较高且趋于稳定,其余三种方法的准确率和检测率都有一定的波动性,特别是DBN方法的准确率和GBDT方法的检测率波动较大。对于各组数据的误报率,采用DBN方法得到的实验数据分别为15.87%、16.69%、17.75%、9.67%和13.48%,该方法的误报率高,结合图8可知DBN-OGB方法的误报率波动较小,且优于DBN-MSVM方法。对以上数据分析说明本文所提出的DBN-OGB是一种稳定且性能优异的入侵检测方法。

Table 3 Experimental data表3 实验数据

Fig.6 Accuracy图6 准确率

Fig.7 Detection rate图7 检测率

Fig.8 False alarm图8 误报率

Table 4 Average results表4 平均结果 %
4.5.3 性能对比
为验证DBN-OGB方法对不同攻击类型的识别能力,本文从Train数据集中随机抽取了两份数据集,分别用一份训练,一份测试,其实验结果与对比实验结果见表5。
由表5可知,DBN-OGB方法和DBN-MSVM方法对于不同攻击类型的检测率基本持平,但DBNOGB对于U2R攻击类型的识别能力优于DBNMSVM。GBDT方法仅对Normal类型和Dos攻击类型的识别能力较强,但对于数量较少的U2R攻击类型的识别能力较差。对DBN方法而言,不同的训练数据对于不同类型攻击的检测率差别较大,如对于第一份数据,其对Normal、R2L类型的检测率分别为97.48%、58.31%,但对于第二份数据,其对应的检测率又为89.11%和100.00%。综上分析可知,本文所提出的DBN-OGB方法对不同攻击类型的数据也具有稳定且高的识别能力。
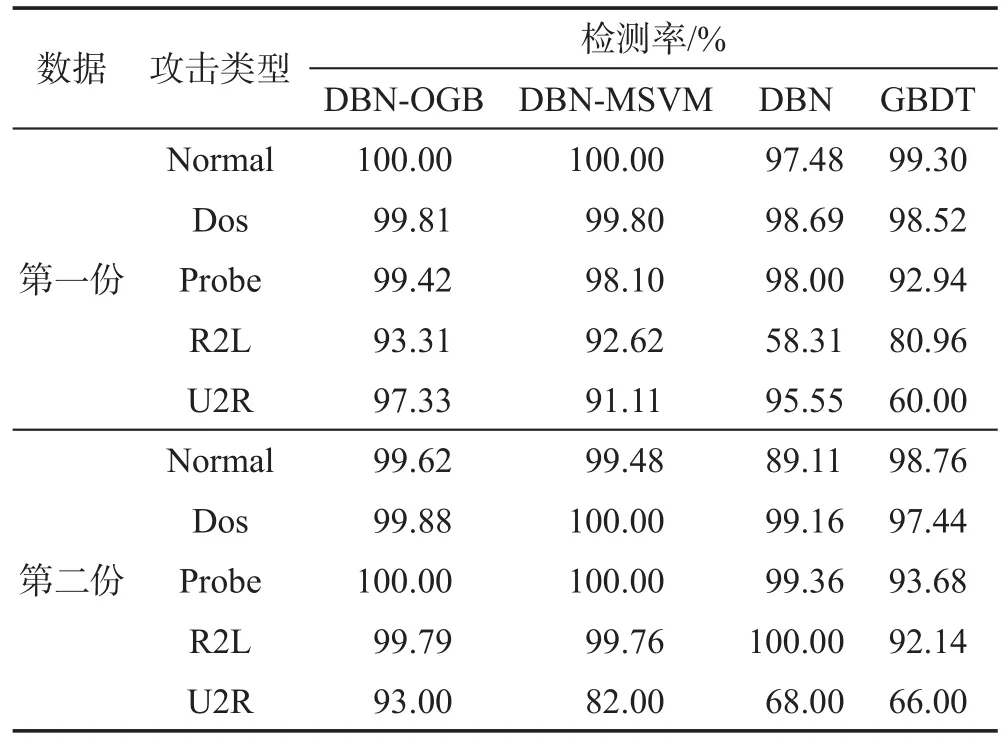
Table 5 Performance comparison表5 性能对比
5 结束语
针对传统智能化入侵检测方法对海量入侵检测数据检测性能较差的问题,本文充分利用GBDT的强泛化能力,对数据的分类精度高且稳定、实用性强等特性将其应用于入侵检测的分类过程。但由于目前入侵检测数据呈现高维、复杂的特性,直接利用GBDT进行分类的效果不理想。进而本文利用DBN对海量、高维复杂数据优异的处理能力,从原始数据中自动提取特征数据训练对应的GBDT分类器,从而提出了一种DBN-OGB入侵检测方法,该方法有一定的实用价值。采用NSL-KDD数据集的验证结果显示DBN-OGB方法的平均准确率和检测率都高于99.00%,说明该方法有着稳定且优异的检测性能,其很好地解决了传统智能化入侵检测方法检测性能较差的问题。同时,在对比实验中,该方法的准确率和检测率相较于其他方法都有较为明显的提升,也说明DBN-OGB是一种有效、可行的入侵检测方法。虽然该方法具有稳定且较强的检测性能,但其误报率也较高,实验中其平均值达到0.65%,因此,如何在保证现有检测性能的基础上,降低该方法的误报率是需进一步解决的问题。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
计算机测量与控制(2019年4期)2019-05-08
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
科技视界(2015年24期)2015-08-22
