
多关系社交网络中社团结构发现算法*
2019-07-11 07:28江淼淼孙更新
计算机与生活 2019年7期
江淼淼,孙更新,宾 晟
青岛大学 数据科学与软件工程学院,山东 青岛 266071
1 引言
社交网络是一种典型的复杂网络[1-2],它是由社交网络中个体成员之间的关系互动而成,主要研究个体之间的联系以及行为活动。社交网络中用户间的关系可能来源自现实世界,也可能来源于网络用户在社交网络中的网络行为和网络交流,并且随着发展逐步形成了网络社团结构。因此,社交网络必然是一个多关系网络,作为网络节点的用户,他们之间必然存在着多种关系。例如,在Facebook、Twitter、新浪微博等社交网络中,依据用户的行为方式,用户间至少存在关注、回复、转发和阅读四种显式关系,如果进一步对微博内容和用户间的互动行为进行分析,可以从中发现用户的兴趣和偏好,从而找到用户之间存在的各种隐式关系。
虽然多关系社交网络广泛存在于现实生活中,但针对多关系社交网络的相关研究却较少,其主要原因是缺乏适合表述多关系社交网络的复杂网络模型。传统的复杂网络模型仅能描述一个系统中的同类个体及个体间的单一关系,二分图模型[3]仅仅可以对两类节点间的相互关系进行描述,而且无法表述同一类节点间的关系,层次网络模型[4-7]虽然可以描述多类个体及其相互关系,但该模型首先需要将节点划分到不同的层次后再进行研究,然而现实问题往往很难分清层次关系。本文基于课题组提出的多子网复合复杂网络模型[8]构建多关系社交网络,该模型通过子网描述了同类个体间的单一关系,基于该模型的组网运算,可以灵活地实现多个子网的复合,进而方便地实现了在同一个复杂网络中对异质个体间的多种关系的描述。
社团结构是指网络中的节点可以分为不同的组,组间的联系相对稀疏,组内的联系相对紧密[9]。社团结构发现在揭示网络拓扑结构、分析网络传播特征等方面研究具有重要价值。例如,科研合作关系网络是一个典型的多关系社交网络,其中包含论文合著关系、论文引用关系、论文与作者对应关系、研究领域相似关系等,通过发现该网络中的社团结构可以将作者和论文归于不同研究领域[10]。为了发现多关系网络中的社团结构,Cai等人[11]根据用户查询抽取出一组线性组合关系来挖掘出符合用户需求的社团。Rodriguez等人[12]提出了一种代数方法将多关系网络投射到单关系网络上,以避免处理多关系网络上复杂的异构数据。王金龙等人[13]利用多关系链对多关系社交网络中的社团结构进行挖掘分析。这些已有方法在多关系网络社团结构发现时或是分析不同性质的节点对于社团划分的影响,或是考虑不同关系系数及关系间的相互作用对社团划分的影响,但都无法将网络中不同性质的节点按照多种关系划分到同一个社团结构中。
本文利用多关系社交网络中信息传播的特性,在分析复杂网络传统的社团结构划分算法基础上,利用多子网复合复杂网络模型的混合度和混合权[14]计算多关系综合影响强度,提出基于该模型的多关系社交网络的社团结构划分算法。在海豚社会网络和空手道俱乐部网络[15]验证了该算法对于单关系网络中社团结构划分的正确性,并利用AMiner数据集构建论文合作多关系社交网络,通过多元线性回归算法得到网络中不同关系的影响强度,取得了良好的社团结构划分结果。
2 多子网复合复杂网络模型
2.1 定义
多子网复合复杂网络模型能够描述复杂系统中不同类个体间的多种关系[16]。该模型(简称复合网)可以使用一个四元组G=(V,E,R,F)来表示:
(1)V={v1,v2,…,vm},表示节点的集合,m=||V是集合中元素的个数。
(2)E={vh,vl|vh,vl∈V,1≤h,l≤m}⊆V×V,表示节点间连边的集合。
(3)R=R1×R2×…×Ri×…×Rn={(r1,r2,…,ri,…,rn)|ri∈Ri,1≤i≤n},Ri表示节点间一种相互作用关系集合,ri表示节点间的一种相互作用关系,n是节点间相互作用关系的总数,若则表示网络为多关系网络。
(4)映射是边集E经过φ函数投影在F中找到唯一对应的映射,表示边上具有的关系类型。
2.2 子网加载运算
通过复合网中定义的子网加载运算可以将若干个复杂网络组成新的复合复杂网络。子网加载运算能复合两个或两个以上的复杂网络,新的复合网的关系向量空间维数增大,其相关节点间相互关系的变化可通过空间向量的相关运算完成。
子网加载运算的具体定义如下:
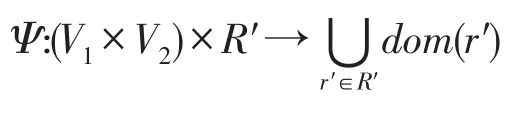
(1)V=V1∪V2;
(2)E⊆E1∪E2∪(V1×V2);
(3)R=R1∪R2∪R′;
(4)映射F:E→2R,当1≤h,l≤|V|;
(5)S=dom(r1)×dom(r2)×…×dom(ri)×…×dom(rn),ri∈R,1≤i≤n;
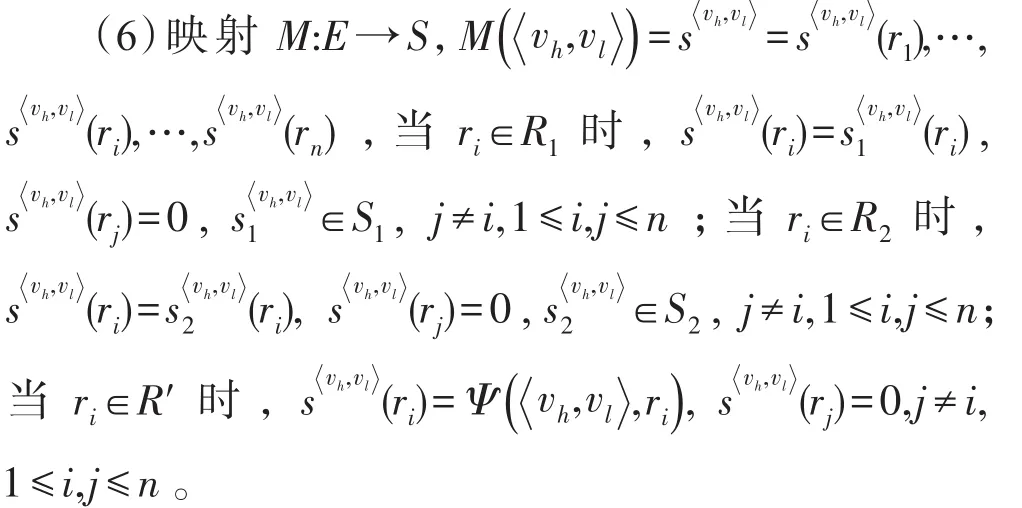
称R′为加载关系集合,vh,vl∈V1×V2为外部边,vh、vl为边界节点。
图1所示为由3个向量复合网Σ1、Σ2和Σ3通过子网加载运算构建多关系复合网的过程。3个向量复合网对应关系分别为r1、r2、r3,对应关系强度dom(r1)={1},dom(r2)={2},dom(r3)={3},以向量复合网Σ1为基底,将Σ2作为子网加载到Σ1上,加载映射关系强度映射为,类似地继续加载子网Σ3。
2.3 节点混合权和节点混合度
节点混合权:设节点vh∈V,关系强度比例系数(sf1,sf2,…,sfk),则节点vh的混合权:
其中,为节点关于关系的权。
节点混合度:设节点vh∈V,关系强度比例系数(sf1,sf2,…,sfk),则节点vh的混合度为:

以图1为例,设定关系r1、r2、r3的权均为0.5,其关系强度比例系数sf1、sf2、sf3均为1,节点0关于关系r1的度,关于关系r2的度,关于关系r3的度,则节点0的混合度1=5,节点0关于关系r1的权,关于关系r2的权,关于关系r3的权,则节点0的混合权为
3 复杂网络中的信息传播
3.1 单关系复杂网络上的信息传播过程
初始时网络中的所有节点都没有携带信息,首次传播开始,设置其中一个节点i为信源节点并赋予其非空信息量I,设该节点的邻居节点集合为Vi,此时网络中信息分布为X=(0,…,I,…,0),信源节点通过连边向Vi中的节点传播信息,其邻居节点接收完信息后将继续向各自的相邻节点集合Vii传播信息,但作为接收方的节点并不是完全接收来自信源节点的信息,而是以一定概率p接收[17];第二次传播时,集合Vi=(0,…,I1,…,0,…,Ij,…,0,…,In)表示所有携带信息的节点集合,集合Vi中的节点既可以向邻居节点传送信息,也可以接收来自其相邻节点的信息。由于接收方节点并不能接收全部外来的信息,当网络规模较大时,仅靠单次传播,网络中部分距离信源节点较远的节点接收到的信息较少,不能充分表示信源节点对这些节点的影响。因此,需要信息在网络中迭代传播T次后,网络中所有节点所携带的信息量分布情况才能表示信源节点对整个网络信息传播的影响能力。根据每个节点作为信源节点时,网络中信息量的分布向量,就可以计算网络节点间的相似性。
节点之间传递信息可以通过一个传播概率矩阵P表示,其具体定义如下:

其中,D为由节点的度构成的对角矩阵,W为网络的邻接矩阵。该公式表示网络中的节点i向节点j传送信息时,节点j不是全部接收而是以如下概率接收:

图2是一个简单的复杂网络,其传播概率矩阵P为:

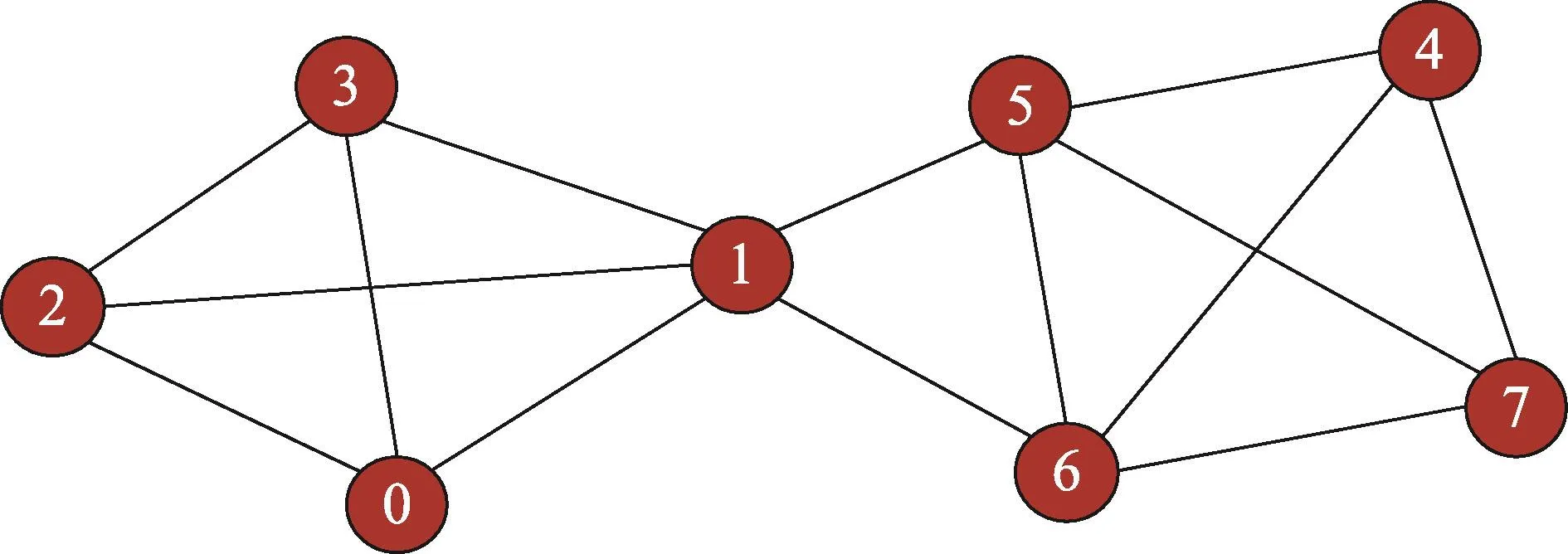
Fig.2 Example of single relationship complex network图2 单关系复杂网络示例
分别以节点0、2、7作为初始信源节点,则网络中初始信息分布可以分别表示为:

设置传播次数T=3,得到信息在全部网络节点上的最终分布情况:
X0={1.00,0.42,0.62,0.62,0.03,0.10,0.10,0.03}
X2={0.62,0.42,1.00,0.62,0.03,0.10,0.10,0.03}
X7={0.03,0.16,0.03,0.03,0.60,0.50,0.50,1.00}
利用欧氏距离等相似性度量,就可以根据信息量分布向量X0、X2和X7得到节点0、2、7之间的相似性。
3.2 多子网复合复杂网络模型上的信息传播过程
可以将信息传播扩展到多关系社交网络中,R=(r1,r2,…,ri,…,rn)表示网络中存在的关系集合,基于多子网复合复杂网络模型,构建包含n种关系的复合网。与单关系复杂网络类似,复合网中的每个节点也是按照一定的比例p接收信息,不同的是需要考虑节点与邻居节点连边上所具有的各种关系的相互作用对接收信息概率p的影响。
复合网信息传播概率矩阵P̂具体定义如下:

其中,̂为节点混合度组成的对角矩阵,̂为网络的邻接混合权矩阵,该矩阵中的元素可表示为:

邻接混合权矩阵中的元素是对节点vh和节点vl间所存在的各种关系的关系强度的加权求和。其中,sfri表示节点vh和节点vl之间关于关系ri的关系强度比例系数,kri′为关系ri的关系强度。
在邻接混合权矩阵的基础上,节点vh的混合权也可表示为:

依次选择网络中的节点作为信源节点并赋予1个单位的信息量,网络中其余节点的信息量为0。以网络中一个节点s为例,设节点s为信源节点,其携带信息量为1,初始化s节点表示的向量为0,…,1,0),第一次传递过程,由该节点向其邻居节点传递信息,这一过程用数学公式表示为,向量中的元素为第一次传递后网络各个节点所携带的信息量;第二次传递过程,接收到信息的节点向其相邻节点传递信息,若其相邻节点也具有信息,其也可以接收来自相邻节点的信息,这一过程的数学表达式为,向量中的元素为第二次传递后网络各个节点携带的信息量;类似地,每次传播后的信息表示为在下次传播前,设即信源节点在t+1次传播开始时信息量始终为1。这样通过网络各节点T次传播后的信息量分布向量,将得到能表示节点影响力的信息分布矩阵。
以图1中的复合网为例,多关系复合网上信息传播过程如图3所示。
设3种关系的比例系数均为1,关系强度分别为1、2、3,节点0为源节点X0=(1,0,0,0,0,0,0,0),则P̂计算如下:

4 基于信息传播的多关系社交网络社团结构发现算法
4.1 关系强度和关系系数的计算
利用多子网复合复杂网络模型的子网加载运算得到的多关系社交网络中将包含多种关系R={(r1,r2,…,ri,…,rn)|ri∈R,1≤i≤n}。各节点的度和权在复合网模型中分别被定义为由关系强度和关系比例系数共同决定的混合度和混合权,而节点的混合度和混合权又直接影响到节点在网络中信息传播的能力,并最终决定了网络社团结构的划分。因此,多关系社交网络社团结构发现算法中至关重要的一步就是确定各种关系的关系强度和关系比例系数。
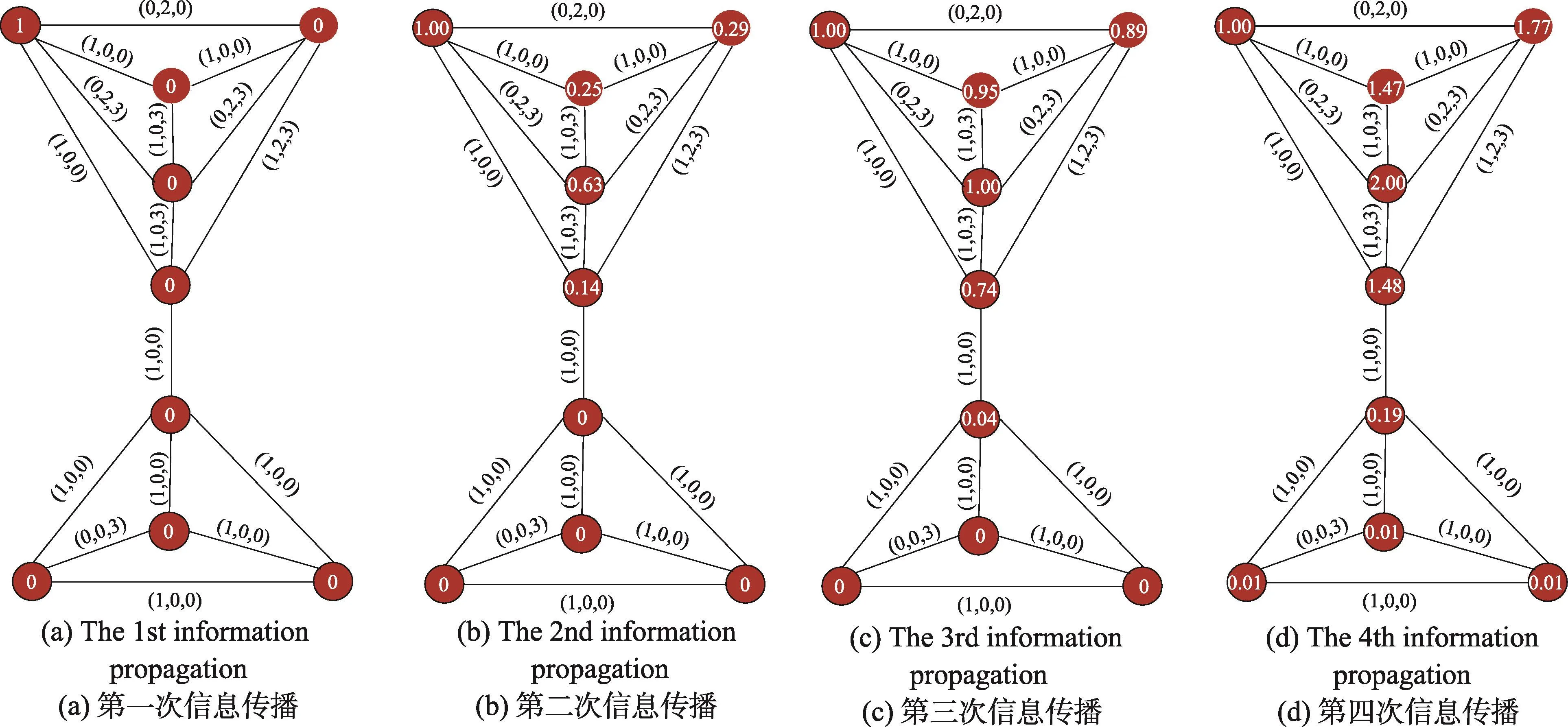
Fig.3 Example of information propagation in multiple relationships network图3 多关系网络中信息传播过程示例
本文借鉴多元线性回归算法[18]的思路,由用户提供先验数据集,即部分已划分好社团结构的数据,使得同一社团结构中的节点两两连边,不在同一个社团结构中的节点间没有连边,从而得到社团结构分明的目标网络Gtarget,目标网络的邻接矩阵M̂表示如下:

根据得到的目标网络,通过线性回归的方法使复合网中的节点在子网加载运算后的多关系R下尽可能拥有与目标网络中节点相似的信息传播能力。首先,根据先验数据集的数据建立一个复合网,该复合网在多关系R下的传播概率矩阵P̂由混合度对角矩阵D̂和邻接混合权矩阵Ŵ经过矩阵运算得到。为了使复合网中各节点与目标网络中的各节点的传播能力尽可能相似,就需要通过关系比例系数的设置使复合网的传播概率矩阵P̂尽可能地拟合目标网络的传播概率矩阵P,而关系比例系数作为各种关系在多关系网络中重要性的度量标准,主要影响复合网中节点的混合度。因为复合网中节点在各子网中的度和目标网络中的度已知,提取各子网和目标网络中各个节点的度分别组成向量和这样复合网的混合度对角矩阵与目标网络的度对角矩阵的拟合就可以转化为提取关系比例系数SF=(sf1,sf2,…,sfk)的线性回归问题,即:

以图1的复合网为例,若节点(0,1,2,3,8)和节点(4,5,6,7)分别划分为一个社团,则目标网络如图4所示。

Fig.4 Target network图4 目标网络
目标网络对应的传播概率矩阵为:

根据线性回归算法,计算3种关系对应的关系比例系数:

可以将矩阵简化为:

最后可得:

4.2 多关系社交网络社团结构发现算法
复杂网络中的社团结构是根据网络节点的相似性对节点进行划分,又被称为复杂网络中的聚类[19]。因此,可以使用数据挖掘中的聚类方法发现复杂网络中的社团结构。本文利用多关系复杂网络中的信息传播,将多关系社交网络中的节点转换为适合聚类算法处理的数据结构,并且依据网络中的信息传播计算网络节点间的相似性,从而将成熟的数据挖掘聚类算法应用于多关系社交网络的社团结构发现。
本文在K-means聚类算法[20]的基础上提出了CSDM(community structure detection in multi-relationships social networks)算法来发现多关系社交网络中的社团结构。K-means算法的最大缺点是对初始聚类中心点的选择敏感,作为聚类中心点的初始值将直接影响到最终聚类的结果。
复杂网络中通常把节点的重要性称为中心性,作为网络中刻画节点重要性的基础指标,度中心性认为节点的影响力与邻居节点的数量有关,即邻居节点数目越多,则该节点在网络中的影响力越大。设节点vh与节点vl关于关系ri的路径长度为,定义节点vh关于关系ri的中心度为:

其中,等式右边分子部分表示与其他所有节点关于关系ri的路径长度之和的最小值,分母部分表示节点vh与其他节点关于关系ri的路径长度之和。中心度的值越接近于1,说明该节点与其他所有节点的路径长度之和越小,其中心地位越强;中心度的值越接近于0,说明其中心地位越弱。
CSDM算法将选取复合网中中心度较大的节点作为初始聚类中心点,然后按照经典K-means聚类算法的步骤,对多关系社交网络进行社团结构划分。算法的具体步骤如下:
输入:利用复合网构建的多关系社交网络Gcom,网络节点数N。
输出:社团结构划分集合Result。
1.根据先验数据集,构建目标网络Gtarget;
2.构建复合网Gcom,得到复合网的混合度对角矩阵和邻接混合权矩阵̂;
3.利用线性回归算法,根据目标网络对角矩阵D,得到复合网中关系比例系数SF=(sf1,sf2,…,sfk);
5.Result=∅;
6.在复合网中分别以各节点为初始信源节点进行T次信息传播,得到可用于聚类的信息量分布向量:
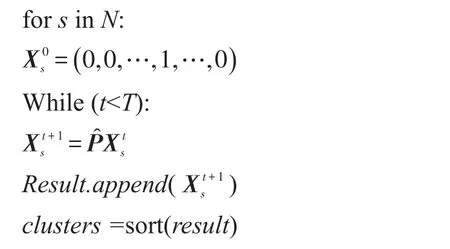
7.选取复合网中中心度较大的节点作为初始聚类中心点;
8.利用K-means经典算法进行聚类:
kmeans=KMeans(clusters).fit(Result)
9.Returnkmeans
5 实验结果与分析
5.1 单关系社交网络社团结构划分
单关系网络可以视为多关系复杂网络的一种特例,为了验证CSDM算法的性能,首先在海豚社会网络和Zachary空手道俱乐部网络这两个用于验证社团结构发现算法正确性的通用数据集中进行了社团结构划分实验,并与GN(Girvan-Newman)算法[21]和Newman快速算法[22]进行了比较。
在两个单关系网络上分别应用CSDM算法,所得社团结构划分分别如图5和图6所示。

Fig.5 Community detection result of dolphin network图5 海豚社会网络社团结构划分结果

Fig.6 Community detection result of Zachary karate club图6 Zachary空手道俱乐部社团结构划分结果
模块度Q[23]经常被选作衡量复杂网络社团结构发现算法划分结果优良的标准,Q值越大,则说明复杂网络社团结构划分越合理,相应的社团划分算法越有效。
表1是CSDM算法、GN算法与Newman快速算法在海豚社会网络和Zachary空手道俱乐部网络中的社团划分结果的模块度值的比较。可以看出在Zachary空手道俱乐部网络的社团结构划分上,CSDM算法的模块度略低于GN算法,但在海豚社会网络社团结构划分上,CSDM算法的模块度是最高的。

Table 1 Comparison of modularity value among various algorithms表1 不同算法模块度值比较
5.2 多关系社交网络社团结构划分
CSDM算法主要是为了进行多关系社交网络中社团结构划分的,在实验中利用AMiner[24]提供的DBLP_citation_network数据集来构建多关系社交网络以验证CSDM算法的正确性。
AMiner是一个利用数据挖掘和社会网络分析等技术提供语义信息抽取、专家搜索、权威机构搜索等功能的搜索引擎,其提供的DBLP_citation_network数据集[25]包括2 244 021篇论文,4 354 534条引用关系,AMiner将该数据集中的数据按照研究领域分为information security、database data mining information retrieval等10个类别,每个类别中包含了文献名、作者、文献索引、引用文献等信息,本实验从information security、human computer interaction ubiquitous computing、database data mining information retrieval这 3个类别中,共抽取600条出现频率最高的文献,与该文献的作者和其参考文献索引组成实验数据集。
首先,根据论文引用关系建立共引论文关系网络,根据论文作者关系建立论文共著关系网和论文与作者对应关系网。完成三个子网构建后,运用多子网复合复杂网络的子网加载运算构建多关系复合网。复合网中包含论文和作者两类节点,论文节点间的共引论文关系,作者节点间的论文共著关系以及论文和作者节点间的论文与作者对应关系等三种关系。
根据AMiner网站中输入不同类别关键字进行搜索得到的论文和学者的检索结果,剔除某些明显异常值后作为计算三种关系对应的关系比例系数线性回归分析的数据样本,共选取了200组样本数据进行预测。针对实验数据中多关系社交网络中存在的论文共著关系r1、论文与作者对应关系r2、共引论文关系r3,构建的三元线性回归模型如下:

其中,a0、sf1、sf2和sf3为回归系数。由于都已经将各种关系的权重值转化到统一的单位上来,因此就不再有常数项a0了。
使用最小二乘法进行参数估计,建立方程组如下:

依据200组样本数据,对方程组求解得到参数估值的平均值为sf1=1.102,sf2=0.206,sf3=0.208。
针对实验中构建的多关系社交网络进行社团结构划分时,设三种关系的关系比例系数为SF=(1.102,0.206,0.208),关系强度均为1,则社团结构划分如图7所示。
为了衡量多关系社交网络社团结构划分效果,定义查准率和纯净度[26]如下:
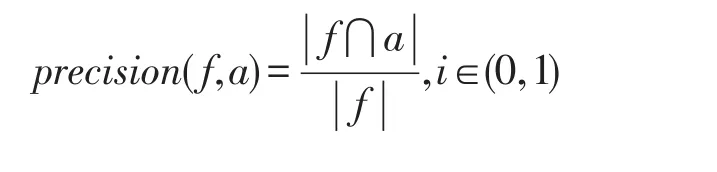
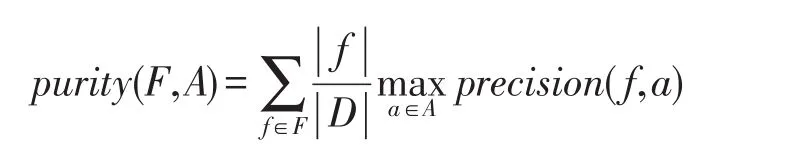
其中,f∈F为本次社团结构划分中的一个社团结构,a∈A为依据AMiner官方数据进行分类的一个类别集合。各个社团的查准率precision是其相对于官方分类各集合能取到的最大准确率,纯净度purity是划分结果中各个社团查准率的加权平均值,能较为全面地衡量社团结构划分结果的优良。
Regression-based算法[27]是通过用户的需求来得到关系的最优组合的关系抽取算法,是一种寻找符合用户需求的社团结构较好的方法。将CSDM算法与Regression-based算法在多关系社交网络中社团结构划分结果的纯净度进行比较,如表2所示。

Table 2 Comparison of purity value among various algorithms表2 不同算法纯净度比较
从表2可以看到,相比于Regression-based算法,CSDM算法的查准率略有提高。这说明利用CSDM算法划分的社团结构与实际情况更加吻合。
6 结束语
现实社交网络的节点间存在着多种关系,只通过其中某一种关系对网络进行社团结构划分难以取得与实际情况较为一致的结果。本文基于多子网复合复杂网络模型,通过信息传播方法将多关系社交网络中的节点转化成能够被聚类算法处理的向量形式,进而利用传统聚类算法完成多关系社交网络中的社团结构划分。提出的CSDM算法综合考虑了现实社交网络中多种关系的相互作用以及异质节点间的相互影响,充分利用网络中存在的多种关系对不同性质节点进行准确的社团结构划分,通过在实际数据集上的实验分析,证明了CSDM算法具有良好的社团结构划分效果。这种将网络中异质节点划分到同一社团结构中的技术,可以应用于基于社交网络的推荐系统中,用来解决协同过滤技术中的稀疏问题和冷启动问题。
虽然本文所提算法在多关系社交网络中的社团结构划分中具有良好的划分结果,但没有充分考虑各种关系强度对社团结构划分的影响,每次都需要计算所有子网关系去调整各种关系强度。此外,算法时间复杂度较高,在分析规模较大的网络时需要较多的时间。因此,如何缩小参数范围、去除冗余关系、降低算法时间复杂度、改进聚类算法是未来的主要工作,如何融合多关系社交网络社团结构发现技术与协同推荐技术也是非常值得研究的问题。
猜你喜欢
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
World Journal of Diabetes(2019年3期)2019-04-16
军事文摘(2017年16期)2018-01-19
读与写·教育教学版(2017年10期)2017-11-10
学苑创造·A版(2017年1期)2017-01-19
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
