
面向微博热点话题发现的改进BBTM模型研究*
2019-07-11 07:28郭文忠
计算机与生活 2019年7期
黄 畅,郭文忠,郭 昆+
1.福州大学 数学与计算机科学学院,福州 350116
2.福州大学 网络计算与智能信息处理重点实验室,福州 350116
3.福州大学 空间数据挖掘与信息共享教育部重点实验室,福州 350116
1 引言
伴随着传统互联网和移动互联网的快速发展,微博得以蓬勃发展。微博允许用户通过网页、外部程序和手机安卓端等发布140字符以内的消息,实现消息共享。微博的短文本性、及时性和交互性等优点受到大众认可,已经逐渐成为了人们获取和发布信息的重要工具。如何从海量的杂乱无章的微博数据中挖掘热点话题已经成为了亟待解决的问题。微博热点话题是指在短时间内被大量微博用户高度关注的话题。微博用户可以发布原创微博来发表自己对某个话题的看法,也可以通过转发、评论和点赞等互动传播方式来关注某个话题微博。由上可知,微博热点话题具有突发性和传播性。
传统的热点话题发现主要是用于发现新闻报道等长文本的热点话题,代表性方法有基于聚类算法的热点话题发现方法[1-5]和基于潜在狄立克雷分配(latent Dirichlet allocation,LDA)主题模型的热点话题发现方法[6-10]。基于聚类算法的热点话题发现方法是基于统计原理对文本进行向量化,然后计算两个文本间的几何相似度,再对文本进行聚类,最终生成话题。由于此类算法仅考虑文本的统计特征,生成的热点话题质量不佳。基于LDA主题模型的热点话题发现不仅考虑文本的统计特性,还考虑文本的词共现特性。因此,基于LDA主题模型的方法在热点话题发现的精度方面优于基于聚类的方法[11]。但是,由于微博最多只包含140个字符的短文本,每篇微博可能只包含一个主题,提供的信息量较少,且缺少上下文的信息,即存在数据稀疏问题。造成传统的基于聚类的方法和基于LDA主题模型的方法不适用于微博稀疏文本中的话题发现。为了克服基于LDA主题模型的方法在处理稀疏数据时的困难,一些学者对LDA模型进行改进,提出了EM-LDA(e-commerce microblog-LDA)、Labeled-LDA等改进模型[12-13]。但是,这些模型仍然不能完全解决数据稀疏条件下的短文本中的热点话题发现问题。
目前,Yan等[14]在2013年提出的基于词对信息的词对主题模型(biterm topic model,BTM),能够较好地解决短文本的稀疏问题。但是,BTM仅适用于普通话题的发现,不能直接用于发现热点话题。王亚民等[15]利用BTM模型进行微博舆情热点发现,克服了传统模型在文本建模中所面临的高维度和稀疏性问题,提高了热点话题的质量。李卫疆等[16]引入BTM话题模型来处理微博短文本的同时整合了K-means聚类算法来对BTM模型所发现的话题进行聚类,缓解了短文本的数据稀疏性问题,提高了话题的质量。但是直接基于BTM模型生成的话题不一定是热点话题,可能附带普通话题。Yan等[17]在2015年提出了一种针对突发性话题发现的主题模型BBTM(bursty biterm topic model),可以直接实现突发话题的发现。引入词对的突发特性,生成的话题可以排除非突发话题。
基于主题模型的热点话题发现方法对主题数目K的变化十分敏感。如果K值设置过大,一个话题将会被拆分成多个语义相近的子话题;如果K值设置过小,则会造成多个话题被叠加生成一个话题。目前,基于主题模型的热点话题发现方法几乎都通过人工指定话题数目,因此如何实现自适应学习话题数目K成为一个待解决的问题。
针对微博短文本特征稀疏、高维度,以及目前基于主题模型的热点话题发现方法需要人工指定话题数目等问题,提出基于改进BBTM模型的热点话题发现方法H-HBTM(hot topic-hot biterm topic model)。首先,进行微博预处理,包括微博去噪、微博分词和特征选择等。其次,结合微博文本的突发特性和传播特性计算词对的热值突发概率,将词对的热值突发概率作为BBTM模型的先验概率,引入词对的热值突发特性,生成的话题可以排除非热点话题。最后,借鉴文献[18]中提出的主题相似度最小模型最优的思想[18],设计一种基于密度的H-HBTM最优K值选择方法,自适应学习BBTM模型最优主题数目。
本文主要贡献如下:
(1)设计一种基于词的突发性的特征选择算法。利用词的突发概率进行特征选择,提取突发词作为特征,能够有效地去除不具突发特性的非热点词。
(2)提出一种词对热度的表征方法。词对的热度综合了微博文本的转发、评论和点赞特性以及词对的突发特性,更全面地表示了词对的热度,有助于排除非热点话题。
(3)设计一种基于密度的H-HBTM最优K值选择方法。自适应学习最优话题数目,取代人工指定话题数目,克服了因话题数目设置不当,造成话题质量低下的问题。
2 相关工作
2.1 主题模型
BTM模型打破了传统主题模型如LDA模型的文档主题层,通过将文档转换为词对,通过对整个语料库的词对建模学习主题,克服微博文本稀疏问题的同时考虑了词之间的语义联系,较传统主题模型更好地理解微博文本信息,但BTM模型不能直接用于热点话题发现,需要对生成的话题进行后处理,例如将BTM模型与聚类算法结合提取热点话题。
BBTM模型为BTM模型的一种改进,是一种针对突发性话题发现的主题模型。模型的核心思想是量化词对的突发概率,作为BTM建模的先验知识,实现突发话题的发现。
此外,BTM和BBTM模型都需要人工指定最优的主题数目K,并且BTM和BBTM模型对于主题数目K的变化非常敏感。目前,基于LDA主题模型的主题数确定方法较为成熟。
Blei等[19]采用困惑度(perplexity)作为主题质量的评估指标,困惑度越小的话题模型越优。选择困惑度最小时的话题数作为主题模型的最优话题数,但是困惑度倾向于选择大的主题数目,造成抽取的主题之间相似度较大,主题间的辨识度不高。曹娟等[18]深入分析了最优主题数目与主题之间的相关性,证明了当主题之间平均余弦距离最小时,模型最优。他们将最优K值选择与模型参数估计统一在一个框架里,提出了一种新的基于密度的最优K值选择方法。但是,该方法的主题向量用主题词分布来表示,具有高稀疏性和高维度的特征,主题间相似度计算具有高复杂性。
2.2 词嵌入
传统文本向量化常采用向量空间模型(vector space model,VSM)表示。向量空间模型表示的文本向量存在稀疏性和高维度的缺点,计算复杂,同时还忽略了词与词之间的语义关系。Hinton[20]首先提出词向量的概念,词向量将每一个词映射成一个固定长度的密集向量,通过词向量间的距离表示词间的相似关系。2003年Bengio等[21]提出三层神经网络构建语言模型,该语言模型可以根据文本的上下文内容推断下一个词。2013年Mikolov等[22]提出并开源了Word2Vec模型,包括CBOW(continuous bag of words model)和 Skip-gram(continuous skip-gram model)。CBOW模型输入特征词的上下文相关的词对应的词向量,输出特征词的词向量。Skip-gram模型正好与CBOW想法相反,输入一个词的词向量,输出这个词对应的上下文词向量。
3 话题发现的基本概念
定义1(微博的传播值)表示微博文档d被转发、评论和点赞的得分,如式(1)所示。该得分越高,则该微博是热点微博的可能性越大。

其中,spreadd表示微博d的传播值,fwd表示微博d被转发的次数,comd表示微博d被评论的次数,topd表示微博d被点赞的次数。γ、χ、μ分别表示转发、评论和点赞操作对微博的传播值的影响程度。
定义2(词的突发概率)词w在t时刻的突发值burstw,t与历史平均突发值burstw,history和burstw,t之和的比值表示词的突发概率,如式(2)~式(4)所示。

其中,burstRatew,t表示词w在t间隙的突发概率,Mt表示t间隙内的微博数目,i表示t间隙内的第i条微博,Nw,i表示t间隙内词w在第i条微博中出现的次数,σ用于过滤低频词,slot表示相关时隙大小。
定义3(词对热值突发概率)词对b在t时刻的热度值hotb,t相对于历史平均热度值hotb,history的增长率,如式(5)~式(7)所示。

其中,hotRateb,t表示词对热值突发概率,δ用于过滤低频词对,slot表示相关时隙大小,spreadi,b指词对所在微博的传播值。
定义4(话题的词向量表示)指该话题下最有代表性的m个关键词的词向量与其在该话题下分布概率之积的和。

其中,k表示话题向量,n表示话题向量维度,ki表示话题向量对应i维上的值,m表示关键词数目,wij代表该话题下第j个关键词的词向量第i维上的值,ratej表示第j个关键词在该话题下的分布概率。
定义5(余弦相似度)向量k和向量d的相似度Simkd用两个向量间的余弦距离表示。

其中,ki表示k向量对应i维上的值,di表示d向量对应i维上的值。
定义6(平均话题相似度)等于两两话题向量间的相似度的均值。

其中,Simavg表示平均话题相似度,Simi,j表示第i个话题和第j个话题的相似度,n表示话题数量。
定义7(文档的词向量表示)该文档所有词的词向量的平均值。

其中,d表示文档向量,n表示文档向量维度,di表示文档向量对应i维上的值,m表示文档中词的数目,wij代表该文档中第j个词的词向量第i维上的值。
4 H-HBTM算法的设计与实现
BBTM模型存在未进行特征词选择,需要人工指定话题数目K,以及词对突发概率只对词对的出现频数进行量化等问题。在改进BBTM模型中,新增特征词选择,采用基于密度的方法实现话题数目K的自动确定以及词对的突发概率量化新增词对的传播属性等。提出基于改进BBTM模型的热点话题发现算法H-HBTM。
H-HBTM算法主要由5部分组成。
(1)微博文本预处理。对微博数据集进行微博去噪、分词、去停用词等预处理操作。
(2)特征选择与词对热值概率化。采用词的突发概率进行特征选择,将微博短文本表示成词对集,并计算词对的热值突发概率,作为BBTM模型的先验概率。
(3)话题数目K的自动确定。采用基于密度的H-HBTM最优K值选择方法选择BBTM模型的最优K值,确定最优BBTM模型。
(4)基于最优BBTM模型的热点话题发现。
(5)微博聚类。判定每个微博文本的话题。
以下各节分别对这5部分进行详细阐述。
4.1 微博文本预处理
文本预处理的目的在于降低数据噪声,为微博文本的建模做准备。文本的预处理工作主要包括按创建日期对微博分片、去除噪声微博、微博分词、词性标注、去停用词等。
微博热点话题是指在短时间内被大量微博用户高度关注的话题,热点话题具有时间性和突发性。因此对微博文本进行建模前需要将微博按时隙划分,在H-HBTM算法中,将微博按照创建的日期进行分片。
噪声微博指微博内容与热点话题无关的微博。噪声的存在会干扰话题发现过程,降低话题质量。噪声微博的共性是被转发、评论和点赞的概率很小。因此可以根据式(1)计算每条微博的传播值,将传播值为0的微博标注为噪音微博并剔除。
分词和词性标注利用HanLP开源工具实现,为了分词过程中能够发现新词,分词时将微博中#之间的词提取出来,加入到词库中。去停用词指去除对热点话题发现意义不大的词以及非中文字符的词,留下名词、动词、形容词等对热点话题发现有意义的词。
4.2 特征选择与词对热值概率化
4.2.1 特征选择
微博中的词可以分为热点词和非热点词。热点词是指与热点话题相关的词,在文本中出现的频数具有短期突增的特点,即具有突发性。利用词的突发特性选择微博特征,选择突发概率大于某一阈值的词作为微博的特征。
基于词突发性的特征选择的基本过程如下。
算法1基于词突发性的特征选择
输入:分词后的文本集text,词突发概率阈值ε,相关时隙大小slot。
输出:文本特征集features。
1.根据式(3)计算每个词在t时隙内突发值。
2.根据式(4)计算每个词在与t时隙相关的slot个时隙中的历史突发值。
3.根据式(2)计算词的突发概率。
4.判断每个词的突发概率是否大于阈值ε,如果是,将词加入特征集features。
4.2.2 词对热值概率化
BBTM模型将词对的突发概率作为先验知识,进行突发话题的发现,其中的突发值只考虑了文本中词对的出现频数。热点话题相关的微博不仅仅表现为相关的微博数变多,还表现为相关的微博被转发、评论和点赞的次数增多。热点词对是微博的组成部分,也具有突发性和传播性。改进BBTM模型中用词对的热值突发概率取代突发概率作为BBTM模型的先验知识,传入BBTM模型中,排除非热点话题。词对的热值综合词对的突发性和传播性,既考虑词对在文本中的出现次数,也考虑词对所在微博的传播值,更好地表示词对的热值。
词对热值概率化的基本过程如下。
算法2词对热值概率化
输入:特征选择后的文本集textFe,相关时隙大小slot。
输出:词对以及词对热值概率binaryTermsHot。
1.统计词对,微博文本中的每个词与其前后10个词分别构成词对。
2.根据式(7)计算每个词对在t时隙内热值。
3.根据式(6)计算每个词对在与t时隙相关的slot个时隙中的历史热值。
4.根据式(5)计算词对的热值概率。
4.3 话题数目K的自动确定
BBTM模型的话题数目K的自动确定,遵循主题相似度最小主题最优的原则,寻找平均话题相似度最小时的话题数。改进文献[18]中的基于密度的自适应最优LDA模型的选择方法,采用词嵌入的方式来表示话题向量,通过将话题向量的维度控制为200维,大大降低了话题相似度计算的复杂程度。改进方法称为基于密度的H-HBTM最优K值选择方法。H-HBTM算法中的词嵌入模型采用Word2Vec中基于负采样的Skip-gram词向量训练模型。基于密度的H-HBTM最优K值选择方法,首先,初始化话题数K。其次,调用BBTM模型生成话题以及话题词,计算所有话题之间的相似度以及平均话题相似度。比较平均话题相似度与历史话题相似度的大小,如果平均话题相似度大于历史话题相似度,则下一轮话题的变化方向则与本轮相反(初始变化方向为减),然后统计每个话题的话题密度即与该话题的话题相似度小于平均话题相似度的话题数,统计噪声话题数即话题密度小于K/3的话题数,接着根据话题的变化方向将话题数加或减噪声话题数,得到下一轮的话题数,一直重复直至话题数不再改变或者达到最大迭代数。
基于密度的H-HBTM最优K值选择方法的基本过程如下。
算法3基于密度的H-HBTM最优K值选择
输入:词对及其对应的热值概率集binaryTermsHot,最大迭代次数Kit。
输出:话题数K。
1.随机初始化话题数目K,K∈(20,60)。设置标志位flag=-1,用于记录话题数的变化方向,设置历史话题相似度为simHis=1,最优话题数topic=K,最优相似度simBest=1。
2.调用BBTM模型生成话题和话题词,根据式(9)~式(11)计算平均话题相似度simAvg。
3.判断平均话题相似度simAvg与历史话题相似度simHis的大小。如果simAvg大于simHis,flag变为其相反数,否则保持不变。
4.更新当前最优话题数和最优话题相似度。如果simBest>simAvg,则simBest=simAvg,simHis=simAvg,topic=K。
5.统计每个话题的话题密度,即与该话题相似度小于平均相似度的话题数。
6.计算噪声话题数C,即话题密度小于K/3的话题数。
7.更新话题数K,K=K+flag×C。
8.重复步骤2~7,直至话题K不再改变时返回K,或者Kit达到最大时返回最优话题数topic,函数结束。
4.4 基于最优BBTM模型的热点话题发现
H-HBTM算法的第4部分是利用最优K值和词对热值概率化产生的词对及其热值突发概率对微博词对集进行BBTM建模,以获取微博热点话题及所对应的话题词分布。
4.5 微博聚类
微博聚类将每个微博文本归入其所属的热点话题。聚类的思想是将每个微博文本归入相似度最大的热点话题中。聚类的方法:首先,计算微博文本的文本向量与所有热点话题向量的余弦相似度。其次,选择余弦相似度大于阈值且最大时对应的热点话题作为该微博的话题。
基于词嵌入的微博聚类算法基本过程如下。
算法4基于词嵌入的微博聚类算法
输入:微博集textFe,话题集topics。
输出:微博及其所属的话题。
1.根据式(13)获取微博文本的文本向量。
2.计算该文本的文本向量与所有热点话题向量的余弦相似度。
3.选择相似度最大并且大于0.5的热点话题作为该文档所属的热点话题,如果未找到符合的热点话题,则该微博属于非热点微博。
4.6 算法复杂度分析
首先分析算法的时间复杂度。设每个时隙微博文档共有M篇,词对数量NB,词数量NW,BBTM模型迭代次数Nit,最优K值选择迭代次数Kit。一条微博中文字符个数dw,词个数dp。t表示第t个时隙,s表示相关时隙大小。
在微博文本预处理中,微博分片时间复杂度为O(tM),微博去噪的复杂度O((s+1)M)=O(sM),每条微博分词的复杂度是,去停用词的时间复杂度为dp。因此微博文本预处理的时间复杂度为O(tM+
在特征选择与词对热值概率化中,特征选择的时间复杂度O((s+1)NW)=O(sNW),词对热值概率化中,统计词对时间复杂度O((s+1)M(dp×10))=O(sMdp)。t间隙内的词对热值计算O(NB),历史词对热值计算O(sNB),突发热值概率计算的时间复杂度为O(NB),因此特征选择与词对热值概率化的时间复杂度为O(sNW+sMdp+(s+2)NB)=O(s(NW+Mdp+NB))。
在话题数目K的自动确定方法中,BBTM模型的时间复杂度为O(Nit(K+1)NB)=O(NitKNB),最优K选择的迭代次数为Kit。因此,自动确定K的时间复杂度为O(KitNitKNB)。
基于最优BBTM模型的热点话题发现的时间复杂度为O(NitKNB)。微博聚类的时间复杂度为O(MK)。
接下来分析算法的空间复杂度。微博文本预处理中,需要的存储空间为O((s+1)M)=O(sM)。特征选择与词对热值概率化计算时需要存储特征集合、预处理后的文本、相关时隙词对集及其热值、t时隙的词对和热值以及热值概率,空间开销O(NW+(s+1)M+2sNB+3NB)=O(NW+s(M+NB))。话题数目K的自动确定方法和基于BBTM模型的热点话题发现方法需要的存储空间均为O((K+1)(1+NW)+2NB)=O(KNW+NB)。微博聚类需要存储t时隙的微博,其空间复杂度为O(M)。
综上所述,H-HBTM算法的空间复杂度为O(sM+NW+s(M+NB)+2(KNW+NB)+M),由于在热点话题发现过程中slot,t,M,K<<NW,因此算法总的空间复杂度为O(NW+NB)。
5 实验结果与分析
5.1 度量指标
(1)话题质量评估
话题质量评估指标采用Mimno等[23]提出的CS(coherence score)指标。CS值越大,表示生成的话题质量越好,CS计算公式如下所示。

评估话题集的整体质量采用ACS(average coherence score)指标,其计算公式如下所示。

(2)热点话题精度评估
F值是信息检索中一种结合查准率(precision,P)和查全率(recall,R)的平衡指标,F值越大表明热点话题抽取效果越好。

式中,Fi表示话题i的F值,Pi表示话题i的查准率,TPi表示属于话题i的文本中被正确识别的文本数,FPi表示不属于i话题被错误识别为i话题的文本数目,TPi+FPi表示被算法识别为i话题的文本数,查准率反映热点话题聚类的准确率。Ri表示话题i的查全率,FNi表示属于话题i的文本被错误识别为其他话题的个数,TPi+FNi表示真正属于i的文本数,查全率反映话题聚类的全面性。F是查全率和查准率的综合指标,β是F值的调和参数,一般取β=1。
5.2 数据集
实验数据采用八爪鱼软件随机抓取从2018年1月20日至2018年1月24日的微博,共计30 000多条构成本实验原始数据,用于发现1月24日的微博热点话题。每天的数据分布如表1所示。其中,每条微博数据由微博内容、微博创建时间、转发数、评论数和点赞数构成。

Table 1 Time distribution of experimental data表1 实验数据时间分布说明
5.3 参数设置
根据参考文献[14],LDA的参数取值为alpha=0.05,beta=0.01。BTM、BBTM和H-HBTM参数取值为alpha=50/K,K为话题数,beta=0.01。所有方法的迭代次数均设置为2 000次。H-HBTM的其余参数的取值为slot=4,δ=1,γ=0.7,χ=0.2,μ=0.1。
5.4 实验和结果
在本节中,对H-HBTM的参数、话题数目K的自动确定、话题质量和微博聚类进行了实验,以验证提出的H-HBTM算法的有效性。
(1)算法参数实验
H-HBTM算法特征选择参数热词突发概率阈值ε选取会影响最终话题的质量。ε取值范围(0,1),如果ε取值过大则会缺失部分热点词,如果ε取值过小,则无法完全过滤非热点词,两者都会影响话题质量。因此进行了参数ε变化对话题质量影响的实验。实验结果如图1所示。实验结果ACS指标越大表示话题质量越好,由于实验结果所得的ACS值都是负数,取它的相反数为纵坐标画图,因此结果值应取最低点。从图中所知,参数ε取0.4时,话题质量得分相反数最小,说明此时生成的话题质量最好,因此实验中参数ε的取值为0.4。

Fig.1 Experimental results of parameterε图1 参数ε的实验结果
(2)话题数目K的自动确定实验
H-HBTM算法中采用基于密度的H-HBTM最优K值选择方法称为KHBTM,用于确定话题数目K。为了证明该方法的有效性,将其与原方法基于密度的自适应最优LDA模型的选择方法(KLDA)进行比较。
图2为KHBTM和KLDA自适应学习话题数目K过程中的平均话题相似度的变化过程。从图中可以看出,两种方法都是话题数目为35时,平均话题相似度最低,与人工标注的热点话题数目一致。多次实验的结果显示KHBTM和KLDA两种方法判定的话题数目与真实数目有时会存在误差,但是误差范围不超过±3。因此,基于密度的H-HBTM最优K值选择方法能够较好地确定话题数目K。

Fig.2 Performance on selecting K of KHBTM and KLDA图2KHBTM和KLDA方法选择K的性能表现
接下来比较两种方法的运行时间,话题数设置为(10,20,…,100),总共10组进行实验。在相同的话题数目下,比较两种方法迭代一轮所耗用的时间。
图3显示KHBTM和KLDA两种方法在不同话题数目下迭代一轮所消耗的时间。由图3可知,KHBTM和KLDA两种方法随着话题数的增加,耗用的时间都是总体呈增长趋势。其中,KHBTM耗时比KLDA耗时略少,主要是因为KLDA采用话题分布作为话题的向量,维数与微博文本中的特征词个数相同,一般可达上万维。而KHBTM中,话题向量采用Word2Vec词嵌入的方式表示,将话题向量维数控制为200维,大大降低了话题向量维度,使得每轮迭代过程中话题相似度计算时间缩短。
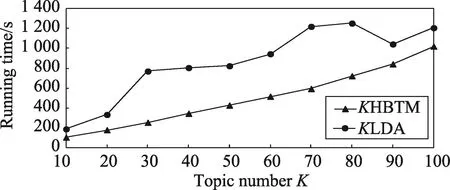
Fig.3 Running time cost of adaptively learning topics K图3 自适应学习话题数目K的运行时间
(3)话题质量实验
将H-HBTM与基于BTM、LDA和BBTM的热点话题发现方法进行对比。因为BTM适用于主题提取,直接使用BTM模型生成的话题不一定是热点话题。因此,在进行BTM建模前,增加与H-HBTM相同的微博去噪操作,过滤噪声微博,以实现热点话题发现。称增加微博去噪的BTM方法为H-BTM(hotbiterm topic model)。LDA和BBTM模型均做相似处理,处理后的方法分别称为H-LDA(hot-latent Dirichlet allocation)和H-BBTM。实验中,话题数目K设置为人工标注的话题数35。将上述方法生成的热点话题集中的每个话题z有关的词w按照P(w|z)降序排列,选择靠前的T个词依据式(14)计算话题z的质量得分。然后按照式(15)对每种方法生成的所有话题质量得分求平均值,作为该方法的话题质量得分。
表2给出四种方法生成的热点话题的质量得分情况。从表2可以看出:H-LDA生成的话题质量最差,因为微博短文本篇幅短小,提供的信息量较少,且缺少上下文的信息,利用LDA模型分析微博短文本数据时就容易造成数据稀疏性的问题。而H-BTM、H-BBTM和H-HBTM算法的底层都是基于BTM主题模型。BTM主题模型对所有微博所包含的词对集建模,克服了短文本的数据稀疏性问题,因此对短文本的处理能力优于LDA。H-BBTM算法效果高于HBTM,表明考虑词对的突发概率有助于提升话题的质量。H-HBTM算法话题质量得分优于H-BBTM,表明微博的转发、评论等传播特性对热点话题发现具有积极作用。这主要是由于微博的传播特性加大了热点词对对热点话题的贡献度,降低了非热点词对对热点话题发现的干扰程度。因此,生成的话题质量更优。
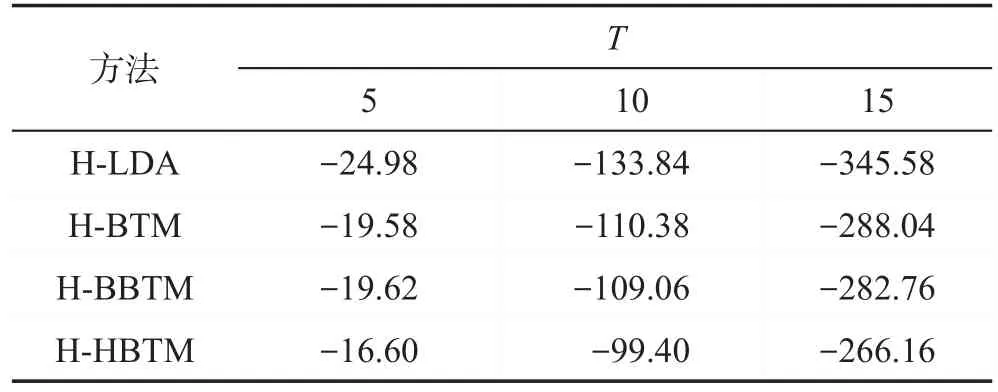
Table 2 Topic quality score表2 话题质量得分
为了更加直观地对实验结果进行比较,以话题“朝天门缆车原址复建”和“王菲那英重逢”为例,分别列出人工标注生成的热点词汇以及采用H-LDA、HBTM、H-BBTM和H-HBTM方法所得的排在前10位的热点词汇。结果如表3所示。
从表3可以看出,与人工标注的话题词集相比,H-LDA得到的词集中含有较多无关词。H-BTM产生的词存在少量干扰词,如朝天门缆车今年原址复建话题中提取的“搜索”“搜寻”,同时,那英王菲重逢话题中存在话题重叠问题,它与鹿晗、关晓彤、李易峰春晚邀约话题重叠,主要是由于数据集中前者话题有关的数据量比后者小很多,以致于无法将那英王菲重逢话题单独提取。H-BBTM利用词对的突发概率克服了数据量小的话题易产生话题重叠的问题,同时提取的词中不存在无关词,但是仍存在少许非热点词如朝天门缆车今年原址复建话题中的“正式”以及那英王菲重逢话题中的“完成”“传出”。HHBTM提取的话题词基本与人工标注集一致,能够覆盖整个话题表述,也解决了数据量小的话题易产生话题重叠的问题。
为了比较每种方法产生的热点话题词的效果,将每种方法提取的热点话题词集与人工标注的热点话题词集进行比较,将两者公有词个数作为该方法在话题上得分,两个话题的得分的平均值作为方法的最终得分,得分越高表明该方法生成的热点话题集与人工标注生成的话题集越接近,即效果越好。表4给出了H-LDA、H-BTM、H-BBTM和H-HBTM方法的最终得分。
由表4可知,四种方法中,H-HBTM的得分最高,可以得知,它得到的话题词与人工标注的最接近。综上所述,H-HBTM可以更加准确有效地提取各热点话题下的热点词。

Table 3 Topic words from different methods表3 不同方法所得的话题词

Table 4 Score from different methods表4 不同方法所得的话题得分
(4)微博聚类实验
在微博聚类实验中,将H-HBTM与H-LDA、HBTM和H-BBTM进行对比。H-HBTM采用基于词嵌入的微博聚类算法,H-LDA、H-BTM和H-BBTM则选择模型产生的文本话题分布中分布概率最高的话题,作为微博文本的话题。图4为H-HBTM与HLDA、H-BTM和H-BBTM话题发现算法在所爬取的微博数据集上的实验结果。

Fig.4 Comparison of average accuracy of 4 differentmethods图4 四种不同方法的平均精度比较
P_Avg、R_Avg和F_Avg分别指平均查准率、平均查全率和平均F值,是所有话题的对应指标上的平均值。从图4可以看出:H-HBTM的平均查准率、平均查全率以及两者的综合指标平均F值均略高于其他算法,这主要是由于H-HBTM提取的话题词质量较优,因此话题聚类结果也较好。故H-HBTM算法能够更加准确有效地挖掘热点话题。
6 结束语
本文提出了一种基于改进BBTM模型的热点话题发现方法H-HBTM,用于发现微博中的热点话题。H-HBTM综合了微博文本的转发和评论等传播特性以及词对的突发特性以更好地表征词对的热度,用词对的热值概率代替BBTM模型中的词对的突发概率,实现热点话题发现。采用基于密度的最优K值选择方法,实现自适应学习H-HBTM算法的话题数目,使得热点话题发现算法的话题数目无需人工指定。在抓取的数据集上的实验表明:H-HBTM相比H-BTM、H-BBTM能够更准确地提取热点话题。未来的工作将考虑在并行计算框架上实现HHBTM的并行热点话题发现。同时,通过跟踪话题的产生、发展以及消亡过程,实现热点话题的演化追踪。
猜你喜欢
林业与环境科学(2022年2期)2022-07-12
昆钢科技(2022年2期)2022-07-08
小猕猴智力画刊(2021年6期)2021-08-05
建材发展导向(2019年10期)2019-08-24
动漫界·幼教365(大班)(2018年9期)2018-05-14
动漫界·幼教365(大班)(2018年6期)2018-05-14
中国新技术新产品(2016年19期)2016-12-12
作文大王·低年级(2016年3期)2016-03-11
中国有色金属(2014年23期)2014-03-13
中学理科·综合版(2008年3期)2008-03-07
