
浅谈多分类器动态集成技术
2015-08-22 02:22:08姜季春令狐红英
科技视界 2015年24期
姜季春 王 蔚 令狐红英
(1.贵州大学计算机科学与技术学院,贵州 贵阳 550025;2.贵州燃气〈集团〉有限责任公司,贵州 贵阳 550000;3.贵州师范学院,贵州 贵阳 550001)
0 引言
分类技术是数据挖掘、机器学习及模式识别中一个重要的研究领域,已在生物认证、手写体识别和文字识别、医疗诊断、图像识别、网络安全入侵检测等众多领域得到广泛应用。分类的准确性是衡量分类器性能的最重要指标之一,集成分类器的目的在于获得高性能的分类结果。分类器集成主要是通过对多个单分类器进行组合来提高分类性能。尽管传统的集成分类技术已经应用到很多领域,但随着科技的发展,人们对应用结果有了更高的要求。这就意味着人们希望通过对传统的静态集成分类技术的改进,得到满足应用领域深层次要求的高性能的集成算法。于是,多分类器动态集成技术应运而生,研究分类器集成技术以提高集成分类的性能指标,已成为众多领域的研究热点。
1 多分类器集成
1.1 背景
分类器集成利用单分类器的互补功能,获得比单个分类器更好的分类性能。按照是否针对待分类样本的具体特征来自适应地选取分类器,得到静态集成(Static Ensemble)和动态集成(Dynamic Ensemble)两种多分类器集成方法。多分类器静态集成方法在训练过程中就将最终识别模型的分类器权重和数目都确定下来,就这意味着在分类预测的过程中所有待分类样本均使用相同的识别模型。和静态集成方法相比较,分类器动态集成方法在预测过程中会根据待分类样本的具体特征来自适应地选取适合的分类器进行集成,这种特性说明动态集成具有更好的针对性和灵活性。另外,分类器动态集成受抽取样本的影响小于静态集成,可以显著提高分类系统的泛化能力,进而有效地保证了分类的精度。
1.2 多分类器集成的框架
多分类器集成系统虽然可以有效提高分类的精度,但是构造多分类器系统确是一个复杂的事情。由于目前对于多分类器集成技术的理论分析还不尽完善,在应用的过程中主要依赖于学者们的实践经验。通常来说,多分类器集成问题包含分类器集合的构造和组合方法两大部分。分类器集合构造部分用于生成多个分类器,组合方法部分则是通过某种方法根据单个分类器的预测情况形成最终的判决,其框架如图所示[1]。

图1 多分类器集成框架图
在分类器集成系统中,组成识别模型的单个分类器的输出形式要受到所使用的集成方法的影响。一般来说,单个分类器有决策级输出、排序级输出和度量级输出三种主要的输出形式。通常而言,集成的信息量和单分类器的输出等级有关。单分类器的输出级别越高,所集成的信息就越丰富,理论上可以获得的分类结果就越好。单分类器的三种输出形式如下:
(1)决策级输出:没有其他附加的信息,输出结果仅用于单纯的分类决策,如身份识别后输出接受和拒绝两种结果;
(2)排序级输出:通常用于目标类别数目众多的情况,且输出的类别按可能性由大到小进行排序;
(3)度量级输出:输出的结果为概率、信度、距离等度量值。
1.3 单分类器的设计
在单分类器的设计中,一些方法考虑显示地实现分类器的多样性,另一些方法则是隐含地实现了分类器的多样性。将已知的单分类器设计方法归纳如下:
(1)在同一个训练集中生成一组不同类型的单分类器[2]。比如使用决策树、神经网络、贝叶斯分类算法训练单分类器,将这些类型不同的单分类器作为集成所用的成员分类器。这组分类器在分类的侧重点和效果上存在差别,并且所得分类结果的输出表示方法也不相同,因此在使用这些单分类器集成分类结果的时候需要进行调整。
(2)从初始的训练样本中抽取得到不同的训练集,训练多个类型相同的单分类器[3-4]。这种方法通过可重复的随机抽样,根据样本分类的难易程度分别赋予不同的权重得到多个训练集,从而训练出一组具有多样性的单分类器。
(3)根据样本的属性特征划分不同的训练样本子集生成多个单分类器,实现分类器的多样性[5]。将一个大的特征向量空间划分为若干较小的特征空间,分别构建一个单分类器,再将这些单分类器集成到一起。这种方法比在整个特征空间中训练一个分类器获得更高的时间、空间效率。
(4)通过调整训练样本的标记属性得到不同的训练集,分别训练得到单分类器[6]。这种方法不仅改变了训练样本的标记属性,同时也增加了训练样本标记属性的噪声,从而实现分类器之间的多样性。
(5)合并类别标号。对于类别数目较大的训练集,随机将多个类别的样本划为两个子集,并将同一子集中的训练样本归为一类。对于合并后的两类训练集用拟合算法训练单分类器。这种方法通过多次重复的随机类别合并得到成员分类器。
1.4 单分类器的集成方式
在训练得到一组单分类器之后,即可进行单分类器的输出集成,以获得待分类样本的目标类别。单分类器的集成分为全部集成和部分集成两种类别:
(1)直接进行集成,即是集成全部单分类器。如果通过训练集生成的单分类器分类精度和相互之间的多样性较高,则可以直接采取某种集成方法来融合各个单分类器的输出结果。
(2)进行选择性集成。许多集成方法都选择使用大量单分类以得到较高的分类性能,但是这种做法会带来一些问题,例如增加计算和存储的开销;随着单分类器规模的增加,难以保证分类器之间的差异度等等。有研究证明只选择一部分适合的单分类器同样可以取得集成所有分类器的分类性能,甚至得到更好的分类效果。这类研究方法的主要思想是首先生成一组初始单分类器序列,然后根据一定的准则从中选择合适的单分类器进行集成。
2 多分类器动态集成技术
2.1 动态集成技术的原理
动态集成的原理是利用不同的分类模型的错误分布信息来指导分类器的集成过程,即是对于给定的一个待分类样本,尽可能地选择那些能够将其正确分类的分类器进行分类。其原理为不同类型的分类器具有不同的错误分布,而对于同种类型的分类器来说,错误分布往往集中于某一特定的区域中。唐春生和金以慧[7]在研究中给出了动态集成技术的4个基本出发点:
(1)在样本空间中,不同的样本处于不同的区域,并且具有不同的特征;
(2)针对不同的样本,各个分类器的分类效果是有差别的;
(3)在样本空间的不同区域,同一个分类器的分类性能会有所变化;
(4)分类器对最终判决具有一定的支持作用,且分类器输出的不同待测类别与实际类别之间存在一定的相似性。
根据以上内容总结得出分类器动态集成的思想:分析对于不同待分类样本所在区域上的各个单分类器的性能,使其自适应地选择一组分类器,最后利用某些特定的组合方法集成判决分类结果。分类器动态集成方法考虑了各个单分类器的特性和待分类样本的自身特征,具有比静态集成方法更好的针对性和灵活性。通常来说,动态集成方法能够获得比静态集成方法更好的分类效果。
2.2 多分类器动态集成的框架和方法
如图2所示为多分类器集成的框架的三个主要部分:
(1)在训练集TS中训练生成一组单分类C;
(2)使用训练集TS或测试集VS来生成能力区域RoC(Region of Competence);
(3)得到各个单分类器在能力区域内的性能,这一过程需要根据待分类样本Xt的自身特征来确定。随后自适应地选择部分分类器或者指定分类器权重用于最终的动态集成分类。
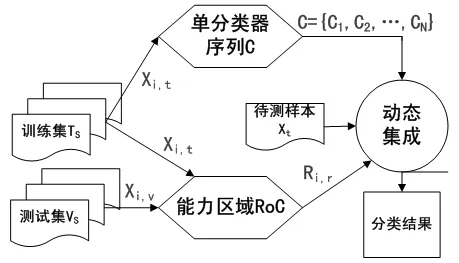
图2 多分类器动态集成的框架
要实现分类器动态集成,关键在于如何构建能力区域和选择何种集成方法[8]。能力区域的构建需要选择出一组能够反映单分类器预测性能的样本集,单分类器在样本中训练得到的分类器必须具备良好的分类效果。
总结一下目前流行的能力区域构建方法:
(1)基于KNN的方法。该方法的核心思想是假如一个样本在特征空间里的k个最相邻的大多数样本都属于某一个类别,则该样本也被判为这个类别,并具有这个类别上样本的特性。KNN方法经常使用欧几里德距离、曼哈顿距离等来求解,在确定分类决策上只依据最邻近的一个或者几个样本的类别来判决待分样本所属的类别,如DCS-LA(Hard Selection)方法,DCS-LA(Soft Selection)方法,KNORA-E 方法等。
(2)基于不同数据集的方法。该方法是通过利用一定的技术得到不同的能力区域,用于构建单分类器,如AO-DCS算法等。
(3)基于聚类的方法。该方法采用聚类算法产生规定数目的训练样本集,在分类阶段通过计算待分类样本和样本集聚类中心的距离得到距离最近的一组训练样本进行分类。如CS(Clustering and Selection)方法,M3CS方法等。
集成方法的选择也是分类器动态集成中的重要环节之一。流行的集成方式有:
(1)动态选择方法。该方法的思想是通过对待分类样本的特征分析从单分类器序列中选择部分性能优良的单分类器实现集成分类。
(2)动态投票方法。该方法的思想是在分类迭代过程中根据待分类样本的特征为各个单分类器动态分配权重,然后执行加权集成分类。
(3)结合动态选择和动态投票的混合集成方法。该方法集合了前两种方法的优势,先根据待分类样本特征选择单分类器序列,再为其动态分配权重,最后执行集成判决。
3 多分类器动态集成技术的不足
和静态集成分类方法相比,分类器动态集成方法在预测时可以动态地、实时地组合单分类器或者为其分配权重,获得更好地分类性能。但是动态集成本身存在一些缺点,在应用过程中需要注意。比如,动态集成过程中需要调用其他方法,如特征选择、聚类分析、KNN方法等;由于待分类样本和训练集分布的差异引起分类性能显著下降;对于不同的待分类样本进行分类器序列的优选,造成算法时间复杂度的增加;还有部分动态集成方法,为了追求优良的局部性能,需要一些特定的训练集,当训练集规模不足的情况下就会影响分类性能。
4 结束语
为了在各个应用领域中更好地满足人们对分类性能的需求,由于分类器动态集成技术更加灵活、更具针对性,并且能够取得更好的分类效果,因此成为了机器学习和数据挖掘等领域的一个研究热点,分析和研究分类器动态集成技术具有较高的理论价值和应用价值。本文介绍了分类器动态集成技术的原理、框架和方法,总结了该技术在应用中存在的一些不足之处,为后继的应用研究提供了理论参考。
[1]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2004.
[2]W.B.Langdon,S.J.Barrett,B.F.Buxton.Combining decision trees and neural networks for drug discovery[C].Genetic Programming Proceedings of the 5th European Conference,EuroGP 2002,Kinsale,Ircland,2002,60-70.
[3]Y.Freund,R.E.Schapire.Experiments withane wboosting algorithm[C].Proceedings of the13th International Conferenceon Machine Learning,Morgan Kau fmann,1996,148-156.
[4]Loris Nanni,Alessandra Lumini.Fuzzy Bagging:A novel ensemble of classifiers[J].Pattern Recognition,2006(39):488-490.
[5]YongSeog Kima,W.Nick Streetb,Filippo Mencaer.Optimal ensemble construction viameta-evolutionary ensembles[J].Expert Systems with Applications,2006(30):705-714.
[6]Gonzalo Martinez-Munoz,Alberto Suarez.Switching class labels to generate classification ensembles[J].Pattern Recognition,2005,(38):1482-1494.
[7]唐春生,金以慧.基于全信息矩阵的多分类器集成方法[J].软件学报,2003(6):1103-1109.
[8]欧吉顺.多分类器动态集成技术研究[D].江苏:江苏大学计算机科学与通信工程学院,2010.
猜你喜欢
科技创新与应用(2020年6期)2020-02-29 10:39:27
电子测试(2018年1期)2018-04-18 11:52:35
北京理工大学学报(2016年6期)2016-11-22 11:17:22
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
