
基于FARIMA的铁路数据网流量趋势预测
2019-03-14 07:56:46张治鹏
铁道学报 2019年2期
孙 强,周 洋,张治鹏
(北京交通大学电子信息工程学院,北京 100044)
近年来随着中国高速铁路的快速发展,铁路通信业务的多样化程度迅速提升,其对通信网络的信息化要求日益增高。作为铁路通信MIS系统的基础,铁路数据网承载的业务应用越来越多,其重要性提升的同时,复杂程度也逐渐增加。准确了解当前及未来网络的负载情况,对于网络运营、网络规划具有重要意义,能够避免由于局部资源紧张而带来的网络拥塞[1],实现未来网络动态带宽管理以及智能化调度平台。当前铁路数据网还处于简单粗略的监控阶段,因此对网络流量进行合理高效的建模分析,预测网络流量趋势迫在眉睫。针对网络流量建模预测,科研人员提出了很多优秀的模型和算法[2],例如自回归滑动平均模型ARMA(Auto-Regressive and Moving Average Model),但ARMA模型不能表示长相关性。因此,本文结合铁路网络特性以及周期性,提出基于分形自回归综合滑动平均FARIMA(Fractional Autoregressive Integrated Moving Average)模型的铁路数据网流量预测方法,能够准确预测铁路数据网流量趋势,优化网络性能[3-4],帮助网络及时进行扩容。
1 FARIMA模型原理
流量建模分析的基础和参考依据主要来源于网络中流量的特性,其中最重要的两个特性分别是流量数据自相关性和流量数据长相关性。同时数据周期性也是流量建模时可以参考的特性之一[5-6]。FARIMA模型是一个自相似模型,能够同时捕获流量数据的长相关特性LRD(Long-Range Dependence)和短相关特性SRD(Short-Range Dependence)。对于任意时序序列{Z(n),n∈Z+},其FARIMA(p,d,q)模型可表示为[7]
φ(B)dZ(n)=θ(B)e(n)
( 1 )
式中:e(n)为均值为0、方差为σ2的白噪声序列;d=H-0.5,为模型的差分因子,可以反映序列的长相关特性,H为赫斯特(Hurst)指数;d为分形差分算子,其公式为
( 2 )

φ(B)和θ(B)为稳定的多项式。
φ(B)=1-φ1B-φ2B2-…-φpBp
( 3 )
θ(B)=1-θ1B-θ2B2-…-θqBq
( 4 )
式中:φ(B)为自回归项AR(Auto Regressive);θ(B)为滑动平均项MA(Moving Average);p为自回归阶次;q为滑动平均阶次。
ARMA(p,q)模型可表示为φ(B)Z(n)=θ(B)e(n),FARIMA模型的不同在于d。对任意的时序序列Y(n)=dZ(n),可以把Y(n)当成是一个保留了短相关特性的新过程,符合ARMA(p,q)的定义,通过ARMA(p,q)对新过程选择合适的阶数和参数,便可得出FARIMA的参数。
2 基于FARIMA模型的预测方法设计
FARIMA模型预测可以分为模型建立过程和算法预测过程。模型建立过程中最为重要的问题是FARIMA模型中参数d,p,q的选择。而FARIMA过程可以分为差分过程以及ARMA过程。整个趋势预测过程如下:
步骤1检验流量数据是否平滑,如果不平滑进行数据聚合处理。
步骤2对流量序列进行零均值化处理,使其转换为均值为0的数据序列。
步骤3计算序列的Hurst指数,并进行d阶分数差分处理,消除序列的长相关性,使其符合ARMA建模过程。
步骤4进行ARMA模式识别,对模型进行定阶定量。
步骤5通过判断ARMA过程拟合残差是否为白噪声。
步骤6通过多个模型对给定的序列进行拟合,从中选择最优的拟合模型。
步骤7预测ARMA过程序列的趋势数据。
步骤8对ARMA预测的数据进行d阶分数差分得到FARIMA模型预测值。
2.1 Hurst指数估计

( 5 )
R/S统计量可表示为
( 6 )
若随机过程具有长相关特性,则
( 7 )
式中:C为常数。寻找一条满足最小均方差准则的直线,该直线斜率即为Hurst指数的值H。通过d=H-0.5得到d值。经过d阶差分,便可将数据的长相关转化为短相关过程Y(n),可用ARMA模型对其进行拟合,Y(n)具体表达式为
( 8 )
( 9 )
根据递推关系可以得出
(10)
2.2 ARMA过程模型定阶
根据样本自相关函数ACF(Auto-Correlation Function)和偏自相关函数PACF(Partial Auto-Correlation Function)表现出来的性质来选择适当的模型[9],模式确定原则见表1。

表1 ARMA模型定阶方法

(11)
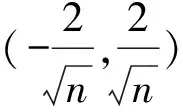
2.3 参量估计

(12)
本文根据Kalman算法进行ARMA多步预测[12],验证模型的平稳特性。当序列ACF和PACF处于95%置信区间时,可证明残差序列为随机序列。在建立的多个模型中,选择拟合程度最好的模型,本文使用AIC信息准则来选择最优模型,AIC计算公式[13]如式(13)所示。ARMA模型预测得到的结果,经过反d阶差分可得到FARIMA预测值。
(13)
3 实验结果与分析
本文选取铁路数据骨干网6个月的链路入口实际流量作为建模数据基础,预测接下来2个月的流量趋势,并与真实的数据进行对比。对基础数据做聚合处理生成平滑的以天为时间轴的序列。同时根据铁路数据承载网络的实际特性,其具有一定的周期性,因此对原始数据进行差分,差分周期选择为7,并对其进行零均值化处理(即每一个样本值都减去所有样本值的平均值),处理后的流量数据如图1所示。
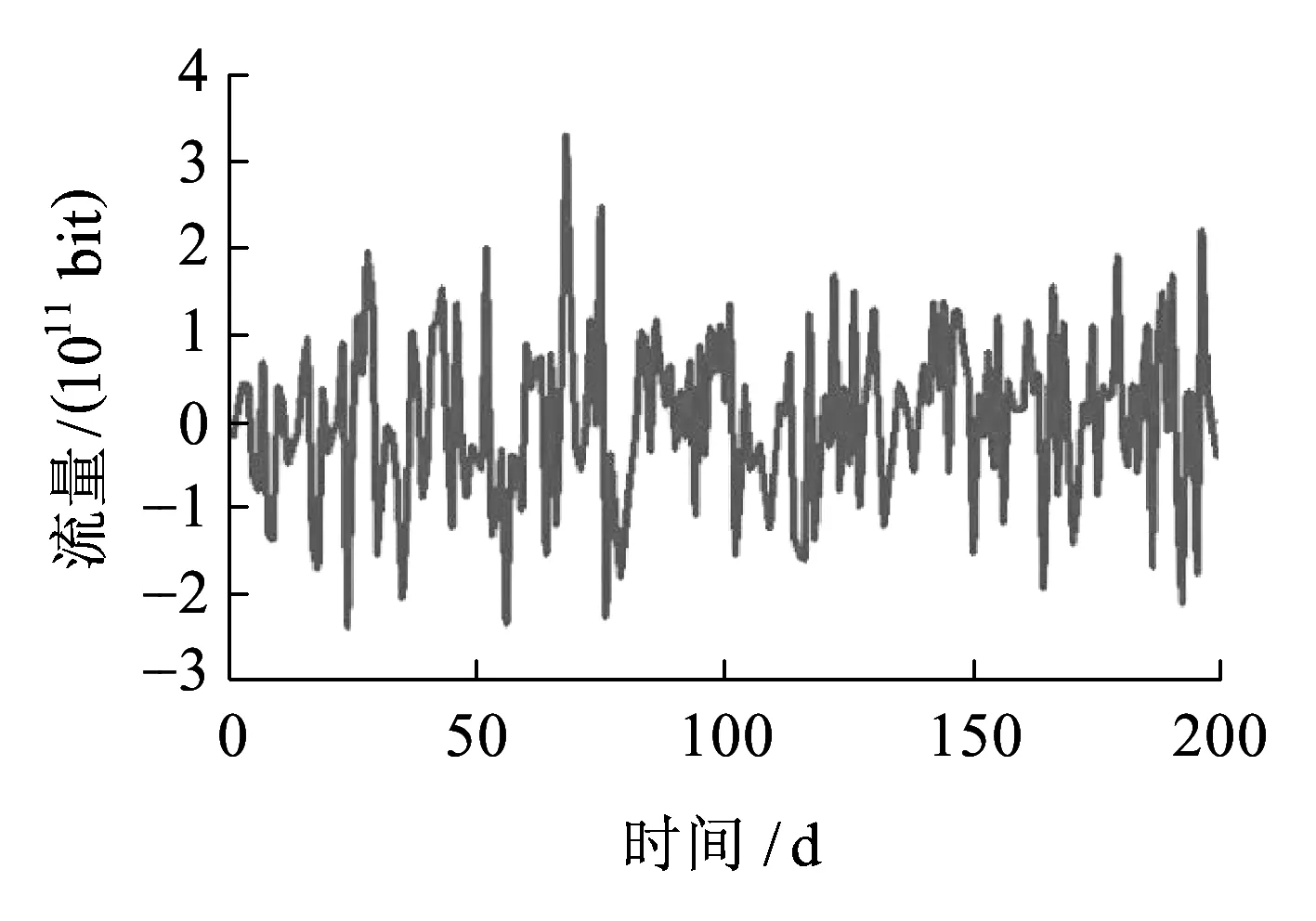
图1 预处理后的流量波形
通过MATLAB平台进行R/S估计,如图2(a)所示,得出H为0.687,根据d=H-0.5,进而能得到差分阶数为0.187,对数据进行分数差分,再次检验差分后Hurst值H,如图2(b)所示,得出差分后的H为0.515,基本去除了流量数据的长相关性。

(a)差分前 (b)差分后图2 数据集差分前后R/S统计量
根据周期特性,本文选取21阶自相关函数值和偏自相关函数值进行辅助定阶,计算结果如图3所示。
由图3可知,左侧ACF取值在4,5阶(最底部为1阶)落入置信区间,6阶处超出置信区间,之后取值均处于置信区间内,同时取值出现拖尾,基于前文分析,q值可以取6(若忽略6阶超出置信区间的情况,q值也可以选择3)。右侧PACF取值在4,5阶落入置信区间,同样在6阶处超出,但之后取值均落在置信区间内,因此p值可以取6。本文基于统计产品与服务解决方案SPSS(Statistical Product and Service Solutions)仿真得到ARMA(3,6)和ARMA(6,6)参数,见表2,表3。

(a)ACF (b)PACF

图3 21阶ACF和PACF

表2 ARMA(3,6)参数选择
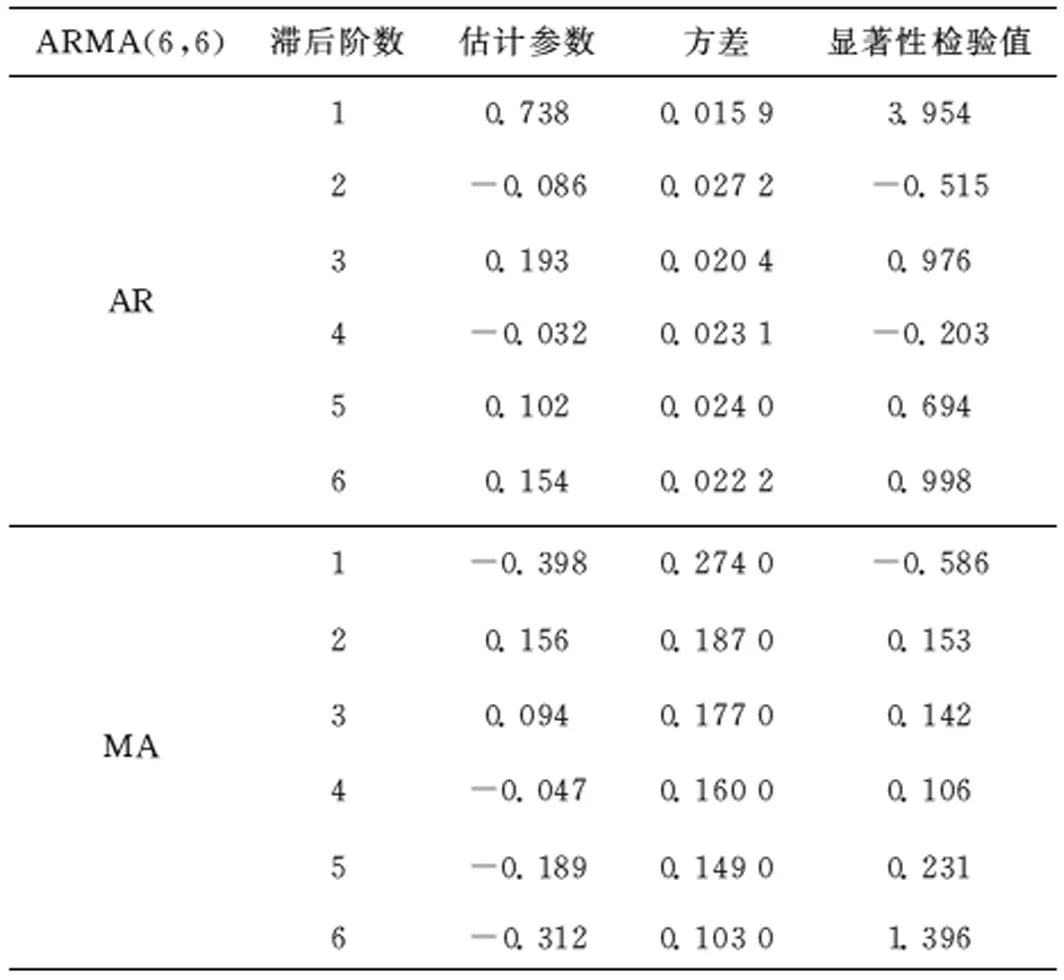
表3 ARMA(6,6)参数选择
表2、表3中,显著性检验值数值越大表明参数对因变量的影响越大,由表中数据可知,ARMA(3,6)相对于ARMA(6,6)的拟合程度更好。其拟合曲线如图4所示,且ARMA(3,6)的AIC值更低。因此,本文选用ARMA(3,6)模型。
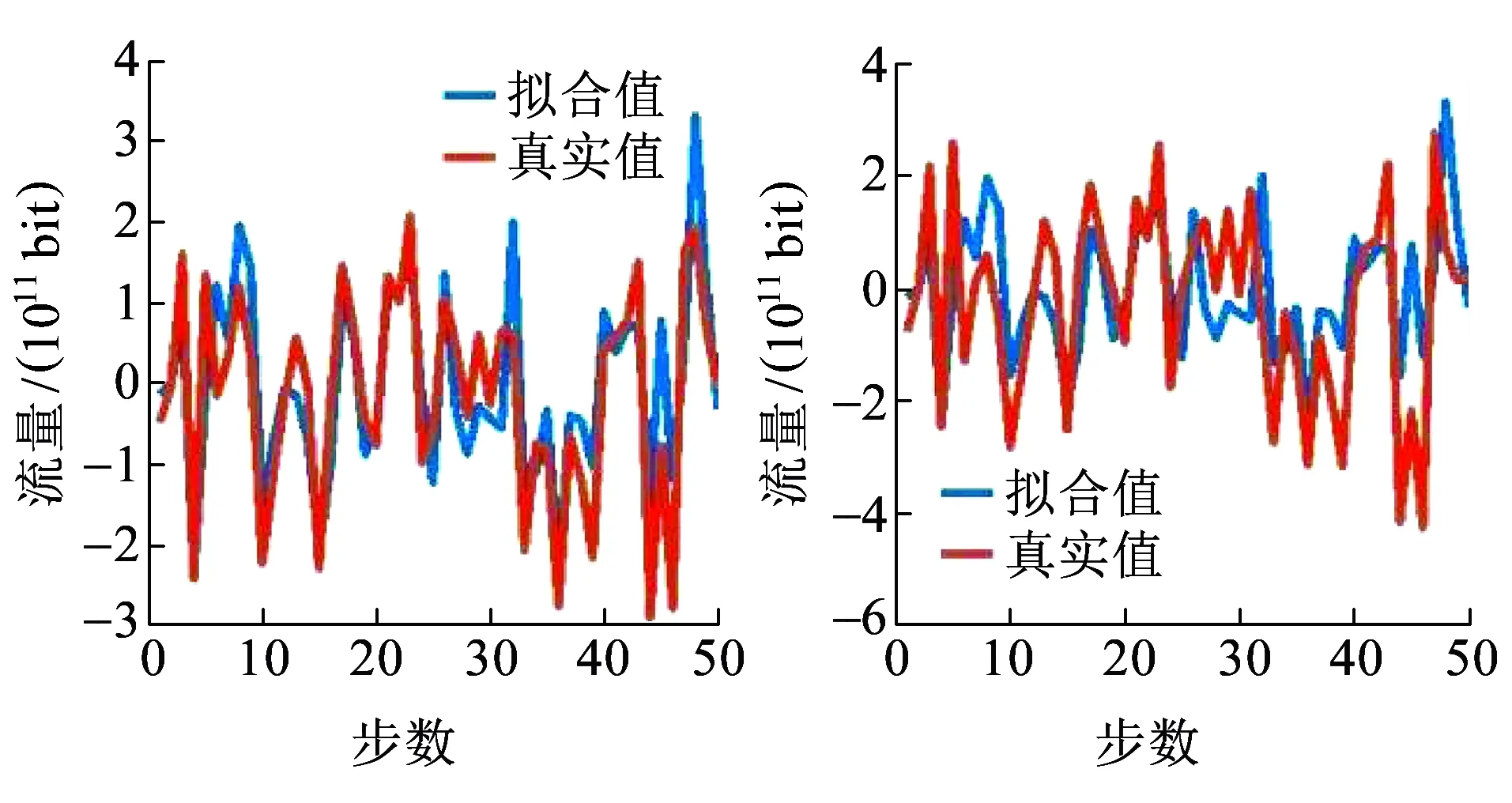
(a)ARMA(3,6) (b)ARMA(6,6)图4 ARMA(3,6)和ARMA(6,6)拟合对比
根据上述得出的ARMA模型以及d参数,可以得出FARIMA模型关系如下
0.187z′(t)=0.653z′(t-1)-0.183z′(t-2)+
0.176z′(t-3)+e(t)-0.398e(t-1)+
0.156e(t-2)+0.09e(t-3)-0.047e(t-4)-
0.189e(t-5)-0.312e(t-6)
(14)

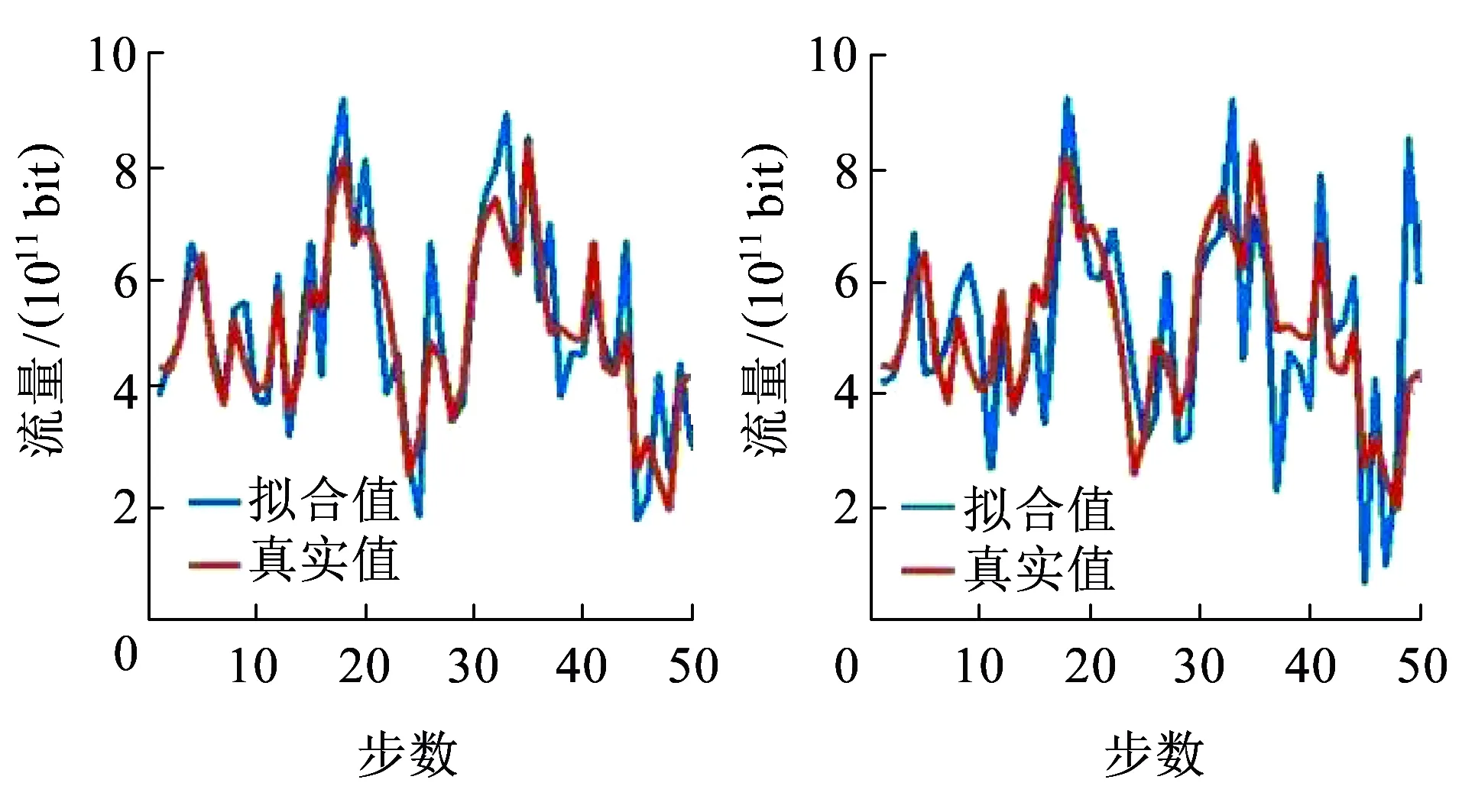
(a)FARIMA (b)ARMA图5 FARIMA模型与ARMA模型结果
为了验证模型的准确度,本文通过计算FARIMA模型和ARMA模型的平均绝对误差MAE、均方根误差RMSE、归一化均方误差NMSE、绝对百分比误差MAPE和信噪比SNR5项参数,对两种模型拟合结果进行对比,其结果见表4。其中MAE,RMSE,NMSE,MAPE值越低证明拟合程度越好,SNR值越高越好,可见FARIMA模型各项参数均优于ARMA模型。

表4 FARIMA与ARMA评估
4 结束语
本文提出的基于FARIMA铁路数据网流量趋势预测方法以FARIMA模型为基础,并对流量序列模型构建和参量选择等原理进行详细分析,通过选取实际流量数据集搭建数据建模平台,验证方法的可行性,并根据多项技术指标进行拟合效果检验。实验结果表明,使用该方法能够准确预测网络流量趋势,预测平均绝对误差达到6.27、平均绝对误差率达到0.091,比传统的基于ARMA模型的预测方法拟合精准度更高。但随着预测步长的增加,拟合残差会越来越大。因此,在进行大步长预测的前提下可增加数据集的数量。
猜你喜欢
内江师范学院学报(2022年4期)2022-04-27 02:22:32
湖北师范大学学报(自然科学版)(2021年3期)2021-09-08 01:00:48
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
数学物理学报(2021年1期)2021-03-29 03:14:30
铁道通信信号(2018年10期)2018-12-06 09:34:58
铁道通信信号(2018年9期)2018-11-10 03:26:34
现代传输(2016年3期)2017-01-15 14:23:04
现代传输(2016年2期)2016-12-01 06:42:46
铁道通信信号(2016年9期)2016-06-01 12:10:31
信息安全研究(2015年3期)2015-02-28 20:17:57
