
基于用户行为特征的多维度文本聚类
2018-12-14 05:31黎万英黄瑞章丁志远陈艳平徐立洋
计算机应用 2018年11期
黎万英,黄瑞章,2,3,丁志远,陈艳平,2,徐立洋
(1.贵州大学 计算机科学与技术学院,贵阳 550025; 2.贵州省公共大数据重点实验室(贵州大学),贵阳 550025;3.计算机软件新技术国家重点实验室(南京大学),南京 210093)(*通信作者电子邮箱rzhuang@gzu.edu.cn)
0 引言
随着Twitter、微博等社交媒体的广泛使用,给传统文本内容聚类方法带来挑战。由于社交媒体中存在大量短文本,导致基于文本内容聚类中的特征稀疏问题比较严重。另外,除了文本内容,社交媒体数据还包含很多用户行为信息,如:点赞、转发、评论、关注、引用等(也称“用户行为特征”)。缺少用户行为特征的聚类方法不能对社交媒体数据的分布特征进行建模。除了Twitter、微博等“新媒体”外,有些传统文本中也包含有用户行为信息,如学术论文中的合作作者和参考文献等。
为了在文本内容的基础上有效利用用户行为特征进行聚类,本文提出了结合用户行为特征的多维度文本聚类(Multi-dimensional Text Clustering with User Behavior Characteristics, MTCUBC)模型,该模型主要针对传统多维度聚类中存在的两个问题:1)传统多维度聚类主要使用文本内容和超链接等“静态特征”,缺乏对用户行为特征的有效利用;2)传统多维度聚类只是简单地将多个维度空间进行线性叠加,没有考虑不同维度空间的差异性。本文提出的MTCUBC模型根据文本相似性在不同空间上应该保持一致的原则,将用户行为特征作为约束(constrains)来辅助聚类。同时,采用度量学习(metric learning)方法来精确地调节每个属性值,从而提高聚类的效果。
本文通过两个数据集对模型进行验证。实验结果表明,该方法与单维度文本聚类方法相比有明显的改进,与多维度聚类方法比较也有明显的提升。
1 相关工作
在相关研究中,多维度聚类备受关注,例如:在网络中,广泛使用图像、音频、超链接、文本等不同类型的特征来进行聚类。在早期的研究中,数据的标注信息经常被用作多维度聚类的约束。例如,文献[1]提出了一种将有标记和未标记样本进行合并的方法; 文献[2]提出了一种成对约束(pair-wise)的聚类框架,使用标记数据作为约束来指导聚类过程; 文献[3-4]均研究了带标记和未标记样本聚类结果的影响。这类方法的实现需要部分数据带有标注信息,难以在无标注数据集中使用。
在约束聚类中,文献[1,5]通过修改聚类目标函数实现多维度空间聚类,其中,文献[1]在K-Means算法的基础上,提出如何修改利用流行的聚类算法应用到实际问题中,文献[5]提出半监督聚类算法,将部分未标记的数据进行聚类,然后用已知类来预测未来样本点的类别。文献[6]提出了成对约束聚类方法。这类模型均使用约束来修改聚类的目标函数,但由于特征的高维稀疏性而影响聚类效果,没有考虑能改善文本间距离测量的距离度量方法。
文献[7]提出学习距离矩阵的方法;文献[8]给出成对约束的聚类框架,并提出一种主动选择成对约束的方法来改进聚类效果;文献[9]将社会行为信息的相似性嵌入到视觉空间中; 为了提高多维度聚类的结果,文献[10]使用相似的文章来学习距离矩阵;文献[11]提出使用相似的文章作为约束,为每个类学习出一个距离矩阵的聚类方法;文献[12]提出一种可以同时进行多维度聚类和特征选择的方法,该方法主要是针对高维数据稀疏问题;文献[13]提出基于隐马尔可夫条件随机场的多维度聚类框架;文献[14]提出一种多维度K-Means聚类算法,该算法为每个维度指定一个权重,使其与聚类结果相关联,其中维度用给定的内核矩阵表示,并且内核的加权组合与簇并行学习;文献[15]提出一种多类型的网络文本聚类(Multi-type Features based Web Document Clustering, MFRC),为每一个特征空间设置一个权重值。
在成对约束聚类中,文献[10]结合梯度下降和迭代过程来学习马氏矩阵(Mahalanobis metric);文献[16]提出冗余成分分析算法,它只用必连约束来学习马氏距离,但是这些矩阵学习方法都只训练出一个距离矩阵。
与前面的模型相比,本文提出的MTCUBC模型允许度量学习方法利用成对约束和无标签数据来学习出多个距离矩阵,使实验结果有很大提升。
2 模型的提出
2.1 社会特征的学习
本文将社会维度中的用户行为特征嵌入到词维度聚类中,因此,如何将复杂、无结构的用户行为特征加入到有结构的词维度空间是本文首先要解决的问题。用论文中作者和参考文献间的关系来举例说明,xi={a1,a2, …,an}表示社会维度中第i篇论文中出现的作者和论文引用参考文献中的作者的表示,其中作者出现为1,不出现为0,并且当前论文中的作者及参考文献中的作者只取前三位。社会维度中,作者间的相似性对于词维度的聚类有帮助,为了证明这一点,本文收集了两个数据,以Aminer论文集[17]为例进行说明,该数据集收集了3 000篇论文,统计有8 812个词和22 373个作者。对于每篇论文中的作者,若他们引用的文章都有较高的相似性、较低的差异性,则这些文章中的作者有相同的爱好领域。本文抽象出社会维度中的作者特征和词维度中的词特征向量来计算它们之间的相似度,假如要给作者推荐参考文献,除了从文章的内容以外,社会相似度也是一个可靠、可以考虑的指标。
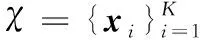
2.2 基于约束的聚类算法
由于有标签的样本比较少,文献[16]考虑到使用约束方法比提供有标签的数据更现实,因此使用相似文章对来学习距离,虽然类标签可能未知,但用户仍然可以指定对应样本是否属于同一个簇,所以约束的方法也比类标签更通用。
针对传统聚类方法不能直接利用约束的问题,基于约束的聚类算法是使用标注数据作为约束来辅助聚类,但本文中没有标注好的样本,是通过在社会维度(social)聚类后,挑选具有较高相似度的文章对作为约束来辅助词(word)维度聚类,此时挑选的文章对类别是确定的。利用约束将目标函数和约束条件结合起来可以解决这一问题。
设M表示是一组必须关联的文章,其中(xi,xj)∈M表示xi和xj应该被聚到同一个类中。让W={ωij}作为M中违反约束的惩罚因子,所以目标是最小化下面的目标函数:
(1)
其中:I为指示函数,I[true]=1和I[false]=0。li和lj在社会维度中有较高的相似度,在词向量维度聚类中应该被聚到同一个类中,否则将会受到相应惩罚。
2.3 基于度量学习聚类
为调节向量中每个属性的贡献度,本模型不是统一地给定某个权重参数,而是通过一个度量学习矩阵来给每个属性一个权重,这样更能满足每个属性间的差异性。
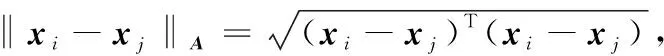
在调整矩阵聚类相关工作中,文献[10, 17]调整矩阵权重同时满足最小化必连(must-linked)样本间的距离和最大化必不连(cannot-kinked)样本间的距离,而且存在基本的限制:对于所有的类都只能用同一个矩阵, 允许每个簇h有单独的一个权重矩阵Ah,可以证明,在这种广义K-means模型下,完整的数据最大对数似然函数等价于最小化目标函数:
(2)
其中:第二项是第li个高斯与协方差矩阵Ali-1的正态常数。
2.4 MTCUBC模型
结合式(1)和(2),即结合约束与度量学习方法。在较少约束违反的情况下,最小化在学习矩阵下的聚类分散度,可以得到目标函数:
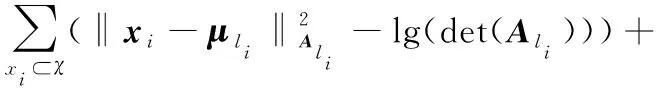
(3)
如果统一约束开销ωij,所有约束违背都平等对待; 然而,在必连(must-link)集合中,对那些违背约束且离得远的点的惩罚应该大于那些违背约束且离得相对较近的点。直观地说:如果两个必连点根据当前的距离度量方法相距很远,则度量是非常不充分的,并且需要对它进行严格的修改。由于两个簇中参与了同一个必连的违背行为,相应的惩罚应该影响到两个簇的度量, 这可以通过对式(3)的第二部分乘以一个惩罚值来实现,该惩罚值表示为:
(4)
加入惩罚值后的目标函数如下:
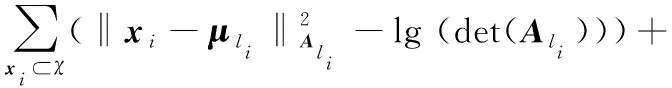
(5)
惩罚仅针对那些违背约束的样本。M是社会维度中满足一定相似度的样本。忽略不相连(cannot-link)的样本,因为在社会维度中不同作者的两篇文章,在词向量维度中其内容可能相似。从式(5)可以看出,公式由两部分组成,其中惩罚因子wij为每个约束提供一个权重,同时该约束也体现公式中两部分之间的相对重要性。
3 算法求解
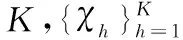

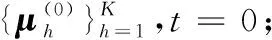
步骤2 重复下面的过程直到收敛:
③t=t+1。
EM算法和复杂度分析如下。
算法主要分两个步骤:一是从社会维度中挑选相似对,二是计算词维度中特征间的距离。在第一步中,要计算两两向量间的距离,时间复杂的在O(m2I)级别上,其中I为迭代次数,m表示论文的数量。第二步中,时间复杂度O(Ikm),其中I为迭代的次数,k为类的个数,m为论文数量。
K-Means算法对初始化和类的个数比较敏感,好的初始中心点对K-Means聚类算法很重要。首先介绍初始化方法,本实验采用的方法是先在必连集合中随机挑选一个点作为初始化中心点,在必连以外的集合中挑选第二个中心点且离第一个中心点的距离最远,同理,第三个中心点是所有样本点中距离前两个中心点距离最远的点。这样做可以加快数据的聚类收敛速度, 由于K-Means对初始点比较敏感,该方法也能一定程度上促进聚类。
期望最大(Expectation Maximization, EM)算法是在概率模型中寻找参数最大似然估计的算法。求解式(5)中的矩阵A,同时要找到聚类的最优效果,不断迭代优化聚类结果,该过程就是一个EM算法过程。下面具体介绍EM的实现过程。
E步 在文献[14,18]中,通过使用能够代表当前类的样本点用于更新数据点的分布。在简单的K-Means中,聚类过程中是没有交互的,本文的方法是在E步和M步中不断交替:E步是将每个样本点分配到每个类中,M步将重新估计中心点和度量学习距离矩阵,在本文模型作用下使所有样本点到各自的类中心点距离之和最小。
值得注意的是,这个分配步骤是依赖于顺序的,因为M的子集和每个类有关,可能会改变样本点的分配。做了随机分配的实验:每个点会分配到离它最近的类中去,同时也会涉及到最少数量的约束对。实验表明,分配的顺序不会导致聚类质量的显著差异,所以在评估中使用随机分配的策略。
在E步骤中,样本点的分配遵循的原则是保持目标函数Jmtcubc最小,因此,当所有的点都被重新分配时,目标函数Jmtcubc相比上一次将会减少或是保持不变。简而言之,结合成对约束和度量学习来指导聚类过程使聚类达到更好的效果。
M步 用每个类中的所有点xh重新估计当前的类中心μh,因此,每个簇中的分布对于目标函数Jmtcubc来说都是最小的。因为约束违背值依赖于类的分配,而成对约束不参与中心点的重新估计步骤,所以这些在M步都不会发生,因此,只有Jmtcubc的第一个距离分量最小化,重新估计样本中心点的步骤实际上与K-Means算法类似。
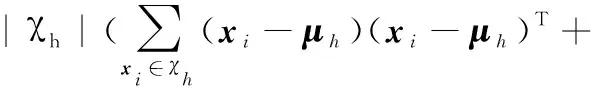
(6)
其中Mh是必连约束的子集,包含当前分配给第h个簇的点。
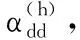
(7)
因为每个Ah是式(7)中的协方差矩阵之和的逆,其和不能为奇异值,如果其中任何一个元素为奇异值时,可以通过添加单位矩阵乘以矩阵A-1的迹(trace)的一部分来加以限制:Ah-1=Ah-1+εtr(Ah-1)I。从直观上看,距离学习修改了聚类变形算法使得相似的点离得更近。
4 实验及分析
本文在两个数据集上验证MTCUBC模型的有效性, 实验结合了用户行为特征和文本词向量空间的特征,使用社会特征辅助词向量空间的聚类。
4.1 数据集
用向量空间模型表示文本特征时,很难对稀疏高维数据集进行聚类, 因为聚类算法容易遇到局部最优而停止迭代,从而导致聚类质量差。在以往的研究中,文献[19]在文本集上用SP-K-means(SParse K-means)算法,其文本集大小比单词空间的维数小,可以看出,在大多数初始化过程中,集群之间的文档迁移很少,这导致算法收敛后的聚类质量较差。这种现象在许多实际应用中出现,例如,当将搜索结果聚类到网络搜索引擎中时,通常聚类中的网页数量是数以百万计的,然而,特征空间的维度,对应于所有网页中的单词的数量是成千上万的,而且因为它只包含少量的所有可能的单词,所有每个网页都是稀疏的,在这种情况下,度量学习结合成对约束方法就可以凸显它的优势,并且可以显著提高聚类的质量。为了证明MTCUBC模型中度量学习文本聚类的有效性,本文使用了具有稀疏性、高维特征的Aminer论文数据集[17]和NIPS Papers数据集[20]。
Aminer论文数据集和NIPS Papers论文数据集,收集了大量关于计算机科学的学术论文信息, 两个数据集都包含论文信息、论文引用、作者信息和合作者信息等, 每篇文章都包含paperID、authorID、摘要和参考文献等属性。在数据预处理中,本文只考虑每篇论文的前三个作者, 同样,参考文献的作者也是只取前三个。在两个数据集中,将词向量维度和社会维度分别用view1、view2表示。实验数据集的统计信息如表 1 所示。
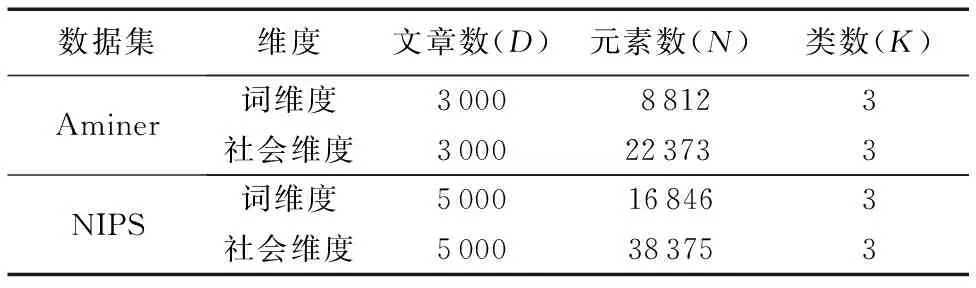
表1 Aminer 和NIPS Paper数据集信息
4.2 聚类评估
本文主要采用NMI(Normalized Mutual Information)作为聚类算法的度量标准。NMI的定义如下:
(8)
算法聚类后的簇集合表示为C={c1,c2,…,ck},标准的聚类标签表示为:L={l1,l2,…,lj}。其中I(X;Y)=H(X)-H(X|Y)表示随机变量间的互信息,H(X)为X的熵,H(X|Y)为在给定Y时X的条件熵。NMI取值范围为0~1,值越大说明聚类效果越好。
4.3 实验结果与分析
实验表明,在两个数据集中,社会维度特征的加入对MTCUBC算法的实验结果有一定的影响, 从而证明结合社会维度约束的度量学习方法的NMI值比单独的社会维度或词维度的聚类结果好; 同时MTCUBC模型的结果也比基于特征选择的加权多视角聚类(Weighted Multi-view Clustering with Feature Selection, WMCFS)模型[12]、多视角聚类(Multi-view Clustering)[21]中的多视角EM算法(Multi-View EM, MVEM)的结果好, 其中WMCFS算法出自文献[12],它提出一种可以同时进行多维度聚类和特征选择的方法, 该方法主要是针对高维数据稀疏提出的解决办法。
由表2可以看出: MTCUBC模型与相对应的单维度(social-single和word-single)聚类结果相比有明显的提升,提升效果达到10个百分点到14个百分点; 与其他两个多维度算法(WMCFS和WMCFS)聚类结果相比提升7个百分点。
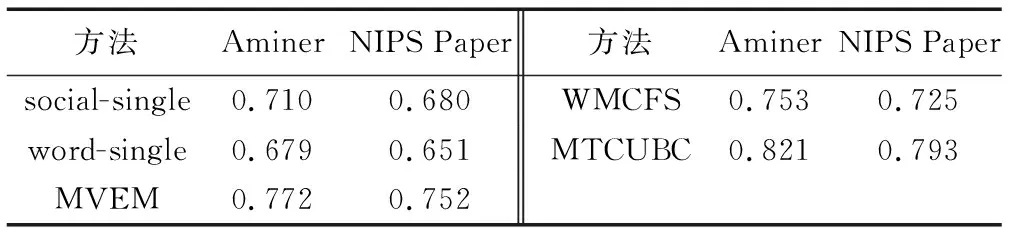
表2 MTCUBC模型在两个数据集上与单维度和多维度方法的对比实验
图1表示MTCUBC模型在两个数据集中,几个多维度聚类模型的聚类效果与加入约束对数量间的关系。可以看出,在没有约束的情况下:WMCFS模型变成传统的K-means算法,MVEM模型变成单维度的文本聚类,MTCUBC模型的结果优于WMCFS模型,因为从式(5)可以看出,MTCUBC模型由两部分组成,第二部分的约束不起作用,度量学习矩阵的结果取决于第一部分,其结果优于WMCFS模型。此时,单维度的MVEM模型优于MTCUBC模型,MVEM聚类算法是一个基于概率的算法,准确度高于MTCUBC模型。
在加入约束后,每个方法的聚类效果都有所提升,在加入2 000个左右约束对时,聚类的提升效果不明显,分析原因是加入的这些约束对中,很大比例的约束对相似度比较高,能被分到同一个类中,或是不能被分到同一个簇中但受到的惩罚比较小,没能改变其最初的聚类结果。
在约束对超过2 000时,聚类效果提升比较明显,在约束对数量达到10 000对左右时算法处于收敛状态。在没有约束时,MVEM算法效果比本文MTCUBC模型好,但随着约束对数量的增加,本文模型MTCUBC的聚类效果超越了WMCFS算法。整个过程中MTCUBC算法都比WMCFS算法的效果好,WMCFS算法是使用一个合适的参数,把多个维度线性叠加,而本文模型使用度量学习方法将多个维度结合,度量矩阵能影响到每个向量中的元素,而非简单的维度之间的叠加关系。
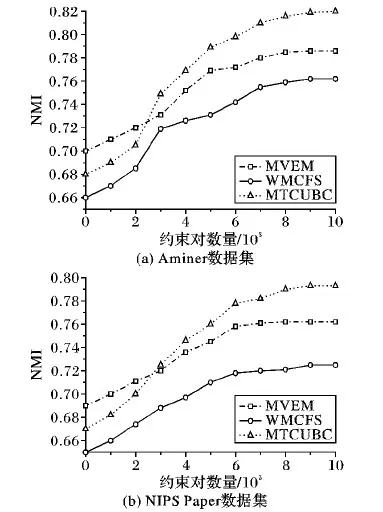
图1 MTCUBC模型与几个多维度算法在两个数据集上NMI对比
5 结语
为提高聚类效果,除利用文本自身内容外,还充分利用和文本内容相关的用户行为信息,带约束的聚类方法结合度量学习方法来改善传统多维度聚类中不同维度线性结合问题,使得用户行为信息在聚类过程中充分发挥作用; 同时,每个簇中都会学习出一个度量矩阵,改善多个类共用一个度量矩阵的情况。本文中对惩罚的开销值ωij有待细化,深究每一维数据的权重值。
在未来的工作中,为得到更准确的聚类结果和充分利用社会信息,拟研究如何利用更多空间聚类结果来互相辅助提升聚类效果。例如,可以将社会维度,词维度、主题维度等特征综合利用,并使用双向辅助作用来提高聚类结果。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
中学生数理化(高中版.高考数学)(2022年2期)2022-04-26
华夏教师(2021年28期)2021-05-23
华夏教师(2021年28期)2021-05-23
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
商周刊(2017年7期)2017-08-22
小学阅读指南·低年级版(2017年1期)2017-03-13
人生十六七(2015年6期)2015-02-28
