
基于CNN和BiLSTM网络特征融合的文本情感分析
2018-12-14 05:26董红斌
计算机应用 2018年11期
李 洋,董红斌
(哈尔滨工程大学 计算机科学与技术学院,哈尔滨 150001)(*通信作者电子邮箱852221609@qq.com)
0 引言
近年来,随着互联网的高速发展,每天不断地产生大量文本、音频、图片、视频等数据,其中文本信息的数据量最大,但文本信息杂乱无章,人工很难区分和整理,因此,对文本数据进行分类变得越来越重要。最初深度学习(Deep Learning)在图像和语音识别领域取得了优异成绩,而近年来深度学习在文本分类中的应用也越来越广泛,与传统的文本分类方法,如朴素贝叶斯、K最近邻(KNearest Neighbor,KNN)和支持向量机(Support Vector Machine, SVM)等算法相比,不需要人工设计特征[1],而是利用深度学习模型自动提取文本特征,显著提高了文本分类的速度,并取得比传统文本分类更好的分类效果。
深度学习是机器学习中的一条重要分支,深度学习是利用多重非线性变换结构对数据进行高阶抽象的算法[2]。最近几年,深度学习算法在自然语言处理领域取得了十分出色的成果,其中卷积神经网络(Convolutional Neural Network, CNN)充分利用多层感知器的结构,具备很好的学习复杂、高维和非线性映射关系的能力,在图像识别任务和语音识别任务中得到广泛的应用[3-4],并取得很好的效果。Kalchbrenner等[5]提出把CNN应用于自然语言处理,并设计了一个动态卷积神经网络(Dynamic Convolution Neural Network, DCNN)模型,以处理不同长度的文本; Kim[6]提出的英文文本分类的模型,将经过预处理的词向量作为输入,利用卷积神经网络实现句子级别的分类任务。虽然卷积神经网络在文本分类中取得了巨大的突破,但是卷积神经网络更加关注局部特征而忽略词的上下文含义,这对文本分类的准确率有一定的影响,所以本文利用双向长短时记忆(Bidirectional Long Short-Term Memory, BiLSTM) 网络解决卷积神经网络模型忽略词上下文含义的问题。
神经网络在特征的自动学习和表达中发挥越来越重要的作用,对于序列化输入,循环神经网络(Recurrent Neural Network, RNN)能够把邻近位置信息进行有效整合[7-8],处理自然语言处理的各项任务。RNN的子类长短期记忆网络模型(Long Short-Term Memory, LSTM)[9-10],对序列信号进行建模的神经网络模型,可以作为复杂的非线性单元用来构建大型的神经网络结构,同时能避免RNN的梯度消失问题,具有更强的“记忆能力”,能够很好地利用上下文特征信息和对非线性关系进行拟合的能力,保留文本的顺序信息。RNN有多种变种循环神经网络模型,主要应用于文本分类的有双向循环神经网络(Bidirectional RNN)[11],由于文本中词的语义信息不仅与词之前的信息有关,还与词之后的信息有关,两个RNN左右传播组合而成的双向循环神经网络能进一步提高文本分类的准确率。
本文的主要贡献如下:
1) 利用BiLSTM代替传统RNN和LSTM,BiLSTM解决传统RNN中梯度消失或梯度爆炸问题;同时一个词的语义与它之前信息和之后信息都有关,而BiLSTM充分考虑词在上下文的含义,克服了LSTM不能考虑词之后信息的弊端。
2) 将卷积神经网络和BiLSTM进行融合,既能利用卷积神经网络提取局部特征的优势,又能利用双向长短时记忆网络兼顾文本序列全局特征的优势,利用BiLSTM解决卷积神经网络在文本分类中忽略词的上下文含义的问题,提高了特征融合模型在文本分类的准确率。
1 词向量
1.1 词嵌入
深度学习方法进行文本分类的第一步是将文本向量化,利用词向量表示文本,作为卷积神经网络和BiLSTM网络模型的输入。传统的文本表示方法是基于向量空间模型或one-hot表示:向量空间模型中向量维度与词典中词的个数线性相关,随着词数增多容易引起维度灾难;而one-hot虽然简单但忽略了词之间的语义相关性。词向量解决了向量空间模型和one-hot的问题,将高维稀疏的特征向量映射为低维稠密的词向量,有效避免了维度灾难的发生,且可以直接计算词语之间的语义相关性。Bengio等[12]提出用神经网络概率语言模型(Neural network Probabilistic Language Model,NPLM)来处理文本信息。Mikolov等[13-14]基于NNLM(Neural Network Language Model)提出Word2vec模型,并给出了利用CBOW(Continuous Bag-Of-Words)和Skip-gram两种模型构建词向量。与NNLM不同的是Word2vec不局限于利用前n-1个单词来预测第n个单词,而是以n为大小的窗口来计算窗口中心词出现的概率,实现了利用上下文预测。CBOW和Skip-gram两个都是以Huffman树作为基础,Huffman树中非叶子节点存储的中间向量的初始化值是零向量,而叶子节点对应词的词向量是随机初始化的。CBOW是根据上下文预测一个词,训练过程中由三部分构成,如图1所示,分别为:输入层(input)、映射层(projection)和输出层(output);输入层为词W(t)周围的n-1个单词的词向量,如果n取5,则词W(t)的前两个词为W(t-2),W(t-1),后两个词为W(t+1),W(t+2),它们对应的向量记为V(W(t-2)),V(W(t-1)),V(W(t+1)),V(W(t+2)),从输入层到映射层将4个词的向量形式相加,而从映射层到输出层需构造Huffman树,从根节点开始,映射层的值沿着Huffman树进行logistic分类,并不断修正各中间向量与词向量,得到词W(t)所对应的词向量V(W(t))。
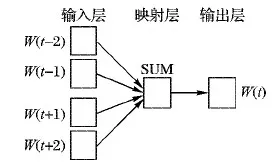
图1 CBOW模型
Skip-gram模型与CBOW刚好相反,如图2所示,同样由输入层、映射层和输出层构成。Skip-gram输入是当前词W(t)的向量形式,输出是周围词的向量形式,通过当前词来预测周围的词,如果上下文窗口大小设置为4,已知中间词W(t)所对应的向量形式为V(W(t)),利用V(W(t))预测出周围4个词所对应的向量形式,Context(w)={V(W(t+2)),V(W(t+1)),V(W(t-1)),V(W(t-2))},Skip-gram模型计算周围词向量是利用中间词向量V(W(t))的条件概率值来求解,公式如下:
P(V(W(i))|V(W(t)))
(1)
其中V(W(i))∈Context(w)。
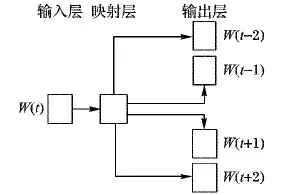
图2 Skip-gram模型
1.2 词向量相似度
通过将词向量与向量空间模型和one-hot对比,发现词向量维度由上千维稀疏向量变为了低维稠密的向量形式,同时词向量中包含了自然语言中的语义和语法关系,通过Skip-gram模型训练得到的词向量可以更加容易地计算词语之间的语义相关性,利用词向量之间余弦距离表示词语之间的关系,余弦相似度值越大,词语间关系越大,余弦相似度值越小,词语间关系越小。如图3所示是利用如家酒店3 000条评论分词、去除停用词等预处理后计算与“房间”这个词最相关的10个词及余弦相似度值。

图3 词向量语义相似度
2 CNN与BiLSTM特征融合模型
2.1 卷积神经网络模型
本文利用图4所示的卷积神经网络模型提取局部特征。卷积神经网络进行文本分类时,首先将词W(i)利用word2vec转化为对应的词向量V(W(i)),并将由词W(i)组成的句子
映射为句子矩阵Sj。
如图4所示,其中V(W(i))∈Rk,代表句子矩阵Sj中第i个词向量为K维词向量,Sj∈Rm×k,m代表句子矩阵Sj中句子的个数,句子矩阵Sj作为卷积神经网络语言模型的嵌入层的向量矩阵。其中将句子矩阵表示为Sj={V(W(1)),V(W(2)),…,V(W(m))}。
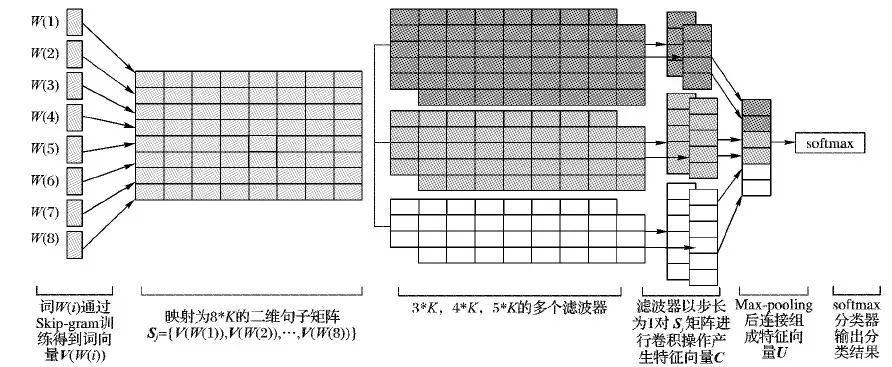
图4 卷积神经网络模型示意图
卷积层用大小为r×k的滤波器对句子矩阵Sj执行卷积操作,提取Sj的局部特征;
ci=f(F·V(W(i:i+r-1))+b)
(2)
其中:F代表r×k的滤波器,b代表偏置量;f代表通过RELU进行非线性操作的函数;V(W(i:i+r-1))代表Sj中从i到i+r-1共r行向量;ci代表通过卷积操作得到的局部特征。随着滤波器依靠步长为1从上往下进行滑动,走过整个Sj,最终得到局部特征向量集合C:
C={c1,c2,…,cr-h+1}
(3)
对卷积操作得到的局部特征采用最大池化的方法提取值最大的特征代替整个局部特征,通过池化操作可以大幅降低特征向量的大小;
di=maxC
(4)
最后将所有池化后得到的特征在全连接层进行组合输出向量U:
U={d1,d2,…,dn}
(5)
最后将全连接层输出的U输入softmax分类器中进行分类,模型利用实际分类中的标签,通过反向传播算法进行参数优化。
P(y|U,W,b)=softmax(F·U+b)
(6)
2.2 BiLSTM模型
由于RNN能学习任意时间长度序列的输入,但随着输入的增多,难以学习到连接之间的关系,产生长依赖问题,即对前面时间的一些节点的感知力下降,进而会发生梯度消失或者梯度爆炸现象。LSTM能解决RNN以上的问题,其核心是利用记忆细胞记住长期的历史信息和用门机制进行管理,门结构不提供信息,只是用来限制信息量,加入门其实是一种多层次的特征选择方式。如图5所示,门机制中各个门和记忆细胞的表达式如下:
LSTM遗忘门表达式:
Zf=sigmoid(Wf·[V(W(i),ht-1]+bf)
(7)
LSTM输入门表达式:
Zi=sigmoid(Wi·[V(W(i)),ht-1]+bi)
(8)
Z=tanh(Wc·[V(W(i)),ht-1]+bc)
(9)
LSTM细胞更新表达式:
Ct=Zf*Ct-1+Zi*Z
(10)
Zo=sigmoid(Wo·[V(W(i)),ht-1]+bo)
(11)
LSTM最后的输出表达式:
ht=Zo*tanh(Ct)
(12)
其中:Zf、Zi、Z、Zo分别代表遗忘门,输入门,当前输入单元状态和输出门;ht-1、ht分别代表前层隐层状态和当前隐层状态;Wf、Wi、Wc、Wo分别代表遗忘门的权重矩阵、输入门的权重矩阵、当前输入单元转态权重矩阵和输出门的权重矩阵;bf、bi、bc、bo分别代表遗忘门偏置项、输入门偏置项、当前输入单元偏置项和输出门偏置项。

图5 LSTM单元结构图
图6所示为本文所用的BiLSTM模型。虽然LSTM解决了RNN会发生梯度消失或者梯度爆炸的问题,但是LSTM只能学习当前词之前的信息,不能利用当前词之后的信息,由于一个词的语义不仅与之前的历史信息有关,还与当前词之后的信息也有着密切关系,所以本文利用BiLSTM代替LSTM,既解决了梯度消失或者梯度爆炸的问题,又能充分考虑当前词的上下文语信息。利用BiLSTM对句子矩阵Sj={V(W(1)),V(W(2)),…,V(W(m))}学习,得到的文本特征具有全局性,充分考虑了词在文本中的上下文信息。

图6 BiLSTM模型
2.3 本文特征融合模型
如图7所示,本文的特征融合模型由卷积神经网络和双向长短记忆网络(BiLSTM)融合组成。卷积神经网络部分第一层是词嵌入层,将词嵌入层的句子矩阵作为输入,矩阵的列是词向量的维度,矩阵的行为sequence_length;第二层是卷积层,进行卷积操作,提取局部特征,文献[15]对基准卷积神经网络的文本分类参数进行分析,当词向量100维时,滤波器为3×100,4×100,5×100会取得较好的分类效果,所以本文分别选用3×100,4×100,5×100大小滤波器各128个,步长stride大小设置为1,padding为VALID,进行卷积运算,通过卷积操作来提取句子的局部特征;第三层进行最大池化操作,提取关键特征,舍弃冗余特征,生成固定维度的特征向量,将三个池化操作输出的特征拼接起来,作为第一层全连接层输入特征的一部分。

图7 CNN与BiLSTM特征融合模型
BiLSTM部分第一层是词嵌入层,将嵌入层的句子矩阵作为输入,每一个词向量维度设置为100维;第二层、第三层均为隐藏层,隐藏层大小均为128,当前输入与前后序列都相关,将输入序列分别从两个方向输入模型,经过隐含层保存两个方向的历史信息和未来信息,最后将两个隐层输出部分拼接,得到最后BiLSTM的输出,代码如下:
output_blstm=rnn.static_bidirectional_rnn(fw,bw,inputs)
利用BiLSTM模型提取词的上下文语义信息,提取文本中词的全局特征。本文在第一个全连接层(Fully Connected layers, FC)前,使用tensorflow框架中的concat()方法对CNN和BiLSTM输出的特征进行融合,融合代码如下:
output=tf.concat([output_cnn,output_blstm],axis=1)
将融合后的特征保存在output中,作为第一个全连接层的输入,在第一个全连接层与第二个全连接层之间引入dropout机制,每次迭代放弃部分训练好的参数,使权值更新不再依赖部分固有特征,防止过拟合,最后输入到softmax分类器输出分类结果,本文softmax回归中将x分类为类别j的概率为:
(13)
3 实验与分析
3.1 实验环境
本文实验环境如下:操作系统为Ubuntu16.04,CPU是Intel Core i5-7500,GPU为GeForce GTX 1050Ti,显卡驱动为NVIDIA-SMI 384.111,内存大小为DDR3 8 GB,开发环境为Tensorflow 1.2.1,开发工具使用的是PyCharm。
3.2 实验数据
本文数据集分为两个部分:第一部分实验数据为搜狗实验室的全网新闻数据(SogouCA),来自多家新闻站点近20个栏目的分类新闻数据,SogouCA数据为2012年6月— 7月期间国内、国际、体育、社会、娱乐等18个频道的新闻数据,提供URL和正文信息,经过预处理后,数据大小为2.3 GB左右,将其利用Skip-gram模型训练得到100维的词向量; 第二部分数据集是如家酒店的用户评论数据集,正负样本各3 000条。其中90%用作训练集,10%用作测试集。由于SogouCA语料库规模足够大能训练出高质量的词向量,所以本文利用训练SogouCA得到的100维词向量去初始化第二部分的数据集,若第二部分数据集中的词在SogouCA数据中就将当前词利用SogouCA训练得到的词向量表示,若没有则采用随机初始化方式表示。
本文使用word Embedding将文本转化为低维、稠密的词向量。图8是利用T-SNE(T-distributed Stochastic Neighbor Embedding)对如家酒店的用户评论数据集中1 000个词在低维空间中的可视化结果,低维空间可视化效果更直观,相关性越大的数据距离越近,越会聚集在一块。

图8 词向量空间可视化
3.3 实验参数
实验参数的选取直接影响最后的实验结果,表1列出了本文融合模型的卷积部分和单CNN中的参数与对应的参数值。表2列出了本文融合模型的双向长短时记忆网络部分和单BiLSTM中的参数与对应参数值。
通过固定参数的方法,分别比较100维、200维的词向量,滑动窗口大小比较3、4、5、7,滑动窗口数量分别取40、80、128进行比较,dropout的比例对比了0.3、0.5、0.6,L2正则项λ比较了3、5、7对实验结果的影响,通过对比如上参数对模型准确率的影响,当取表1参数值时CNN模型取得了较好的分类效果。

表1 卷积神经网络参数
BiLSTM的参数比较了100维、200维的词向量,层数默认取2层,隐藏层大小对比了128和256,最终发现词向量100维、隐藏层大小为128时模型分类准确率最高。Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率,不断迭代更新网络参数,加快模型收敛,所以本文选取Adam作为优化函数。
3.4 实验结果及分析
为验证本文提出的CNN和BiLSTM特征融合模型的分类性能,分别将本文特征融合模型与单CNN模型、单BiLSTM模型、传统机器学习SVM及其他深度学习模型进行对比实验。
本文首先在第二部分数据集上将本文特征融合模型与单CNN模型和单模型BiLSTM进行了对比,且特征融合模型中CNN和BiLSTM的参数与单CNN模型、单BiLSTM模型中的参数相同,均为表1、表2中的参数值,且学习率均设置为0.001。
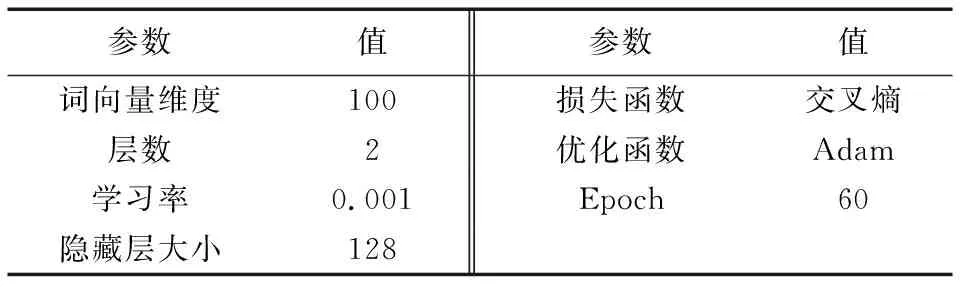
表2 BiLSTM模型参数
图9~10分别给出了单CNN模型、单BiLSTM模型和本文模型的准确率和损失函数变化图。
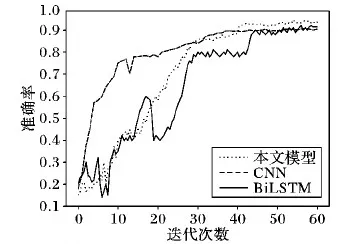
图9 3种模型准确率比较
由图9对比发现,融合模型在测试集上的收敛速度慢但准确率均高于单CNN、单BiLSTM模型。对比图10发现,单CNN、单BiLSTM模型的loss值下降到稳定值的速度比融合模型下降到稳定值的速度快,但最终loss值都下降到了一个很低的稳定值,模型都取得较好收敛效果。
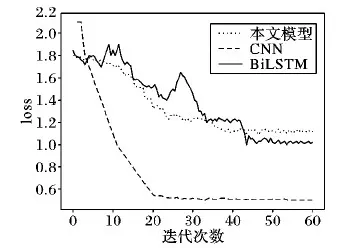
图10 3种模型损失比较
如表3所示,本文所提融合模型的分类准确率比单CNN[15]模型的分类准确率上提升了4.27%,比单BiLSTM模型[16]分类准确率提升3.31%。利用CNN提取文本局部特征,BiLSTM模型提取文本全局特征,将两种互补模型进行特征融合,取得了比单模型都好的分类准确率。

表3 单模型和融合模型结果对比
由于Sogou数据量过于庞大,本文从Sogou数据集中只选取了汽车和体育两个类别,且从每个类别随机抽取全部数据的一部分进行实验,本文利用Sogou新闻数据集中的汽车和体育两类数据集各3 000条,其中90%为训练集,10%为测试集。
本文不仅与单模型进行了对比,还与传统的机器学习算法SVM及其他的深度学习模型进行对比,实验结果如表4所示。文献[15]将文本特征提取、文本特征表示和归一化后,输入到SVM中学习分类决策函数,基于结构风险最小化,转化为二次型寻优问题,求最优值,虽然取得了较好的分类效果,但本文融合模型分类效果明显优于SVM;文献[18]中提出的Attention Based LSTM模型,通过引入Attention model计算历史节点对当前节点的影响力权重,有效解决了信息丢失和信息冗余等长期依赖问题,探究了文本上下文对文本分类的影响,提高了文本分类的准确性,但本文所提融合模型在分类准确率上取得了更好分类结果;文献[19]中Bag of Words文本分类忽略了词序、语法和句法信息,每个词相互独立,而文本模型充分利用了卷积神经网络模型提取局部特征和BiLSTM兼顾文本序列全局特征取得了优于BOW文本分类的效果, 并与文献[20]中所提C-LSTM(CNN-LSTM)的CNN和LSTM统一模型相比较,C-LSTM首先通过使用CNN提取文本特征,然后将特征编码输入LSTM进行分类,发现本文所提融合模型有效提高了文本分类的准确率。

表4 融合模型与其他模型结果对比
4 结语
本文提出了一种基于卷积神经网络和BiLSTM网络的特征融合模型用于文本分类研究,该模型既能利用卷积神经网络有效提取文本的局部特征,又可以利用BiLSTM兼顾文本的全局特征,充分考虑了词的上下文语义信息。将本文所提融合模型与单CNN模型、单BiLSTM模型进行了对比实验,本文所提融合模型分类准确率优于单CNN、单BiLSTM模型。此外本文还与传统机器学习模型SVM及其他深度学习模型进行了比较,结果表明本文所提特征融合模型在分类准确率上优于对比的模型,本文融合模型有效地提升了文本分类的准确率。然而本文融合模型并未使用深度较深的卷积神经网络,未来将研究深度较深的卷积神经网络融合BiLSTM模型对文本分类准确率的影响。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
