
基于评分可靠性的跨域个性化推荐方法
2018-12-14 05:26曲立平吴家喜
计算机应用 2018年11期
曲立平,吴家喜
(哈尔滨工程大学 计算机科学与技术学院,哈尔滨 150001)(*通信作者电子邮箱quliping@hrbeu.edu.cn)
0 引言
近几十年来,随着互联网的快速发展,人们能够获取的信息越来越多,但是用户在面对数量庞大、内容丰富的信息的同时,对如何获取自己真正想要的信息存在着困惑,因此,大量以个性化推荐为代表的过滤网络工具应运而生。目前个性化推荐领域大多数研究人员主要研究单领域推荐,如Netflix和Last.fm。单领域推荐往往存在数据稀疏和冷启动两大主要问题,使得用户的个性化推荐效果不理想。如何整合多个不同域中的数据来实现用户精准推荐已成为近来个性化推荐的研究热点。
推荐系统如何根据用户对一类信息(或物品)的喜好,向其推荐其他类型的信息(或物品),被称为跨域推荐[1-4]。在跨域推荐中存在随意评分的用户, 例如,有的用户即使对购物过程不满意,但因为好评返红包等原因仍对物品给出较高的评分;而有的用户即使对购物过程满意,因为心情不好等原因对物品给出较低的评分。当该物品的评分数量较少时,随意评分使得该物品的评分并不能准确表现出用户的偏爱,从而对推荐结果的准确性产生较大的影响。
目前,大部分研究人员在将辅助域中数据迁移到目标域的过程中,忽略了随机评分的存在[5-10]。文献[11]注意到了随意评分的存在,为所有用户统一设置了阈值。统一阈值的设置,由于其阻止了随意性评分对目标域信息的干扰,理论上与不设置阈值的数据迁移相比,其推荐结果的准确率会有所提高; 然而,不同用户评分的随意性是不同的,为所有用户统一设置阈值,不能很好地体现这种随意性,据此,本文提出一种基于评分可靠性的跨域个性化推荐方法。该方法针对不同的评分可靠性,为用户设置不同的阈值,以减少随意评分对推荐效果的影响。
1 推荐流程
基于评分可靠性的跨域个性化推荐方法的推荐流程主要包括3个阶段:预处理阶段、处理阶段和评估阶段,如图1所示。
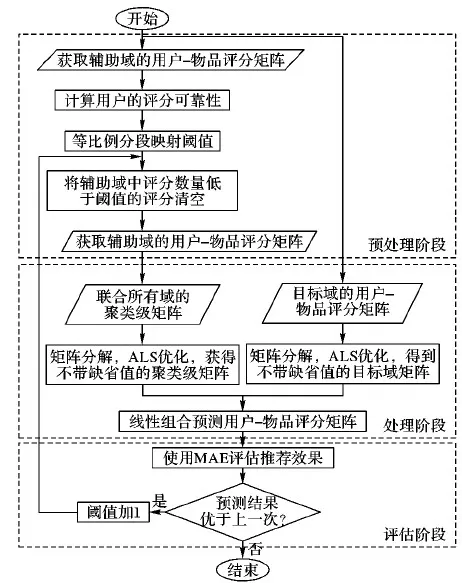
图1 推荐流程
2 基于用户评分可靠性的阈值的设置
为了降低用户的随意评分对推荐效果的影响,本文首先计算用户评分的可靠性,以此来判断用户评分的可信程度。对评分可靠性较高的用户,为其设置较低的阈值; 对评分可靠性较低的用户,为其设置较高的阈值。
2.1 用户评分可靠性
本文使用用户评分可靠性来描述用户评分的可信程度,其值为用户对所有物品的评分与该物品评分的平均值的标准差,记为Varu,如式(1)所示:
(1)

由式(1)可知,Varu值越小,该用户的评分可靠性越高。
2.2 阈值的设置
对于评分可靠性低的用户,如果其评分的物品的评分数量较少,则该用户的随意评分将对推荐结果的准确性产生很大的影响,在将辅助域的数据向目标域迁移时,该用户对该物品的评分应被忽略。只有当其评分的物品的评分数量较多时,用户的随意评分对推荐结果的准确性的影响才能被忽略。而对于评分可靠性高的用户,因为其评分能够反映用户的真实喜好,无论其评分的物品的评分数量多还是少,都可以将辅助域的该数据向目标域迁移。
用户评分的最高分为5分,最低分为0分。从式(1)可以看出,用户评分可靠性的取值范围为[0,5)。按可靠性取值从低到高且间隔长度为1进行分段,可以将用户评分可靠性的取值分为0,(0,1],(1,2],(2,3],(3,4]和(4,5)共六段。对于用户可靠性取值为0的用户,为其设置阈值为T;取值为(0,1]的用户,设置阈值为T+1;取值为(1,2]的用户,设置阈值为T+2,以此类推。
3 推荐处理步骤
基于评分可靠性的跨域个性化推荐方法的处理步骤[11]如下:
1)对每个域进行矩阵分解,并使用交替最小二乘法(Alternating Least Squares, ALS)进行优化,得到最优用户特征矩阵和物品特征矩阵,如式(2)所示:
R=Um*k*Vk*n
(2)
其中:k为特征数,m为用户数,n为物品数,Um*k是用户特征向量,Vk*n是物品特征向量,R是用户-物品评分矩阵。
2)使用K-Means聚类算法对用户-物品特征矩阵中的用户、物品进行聚类。
3)计算每个聚类用户对应聚类物品的评分的平均值,如式(3)所示:
(3)
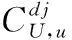
4)通过上述的聚类级计算,得到某类用户对某类物品的聚类级用户-物品评分矩阵Rc,如式(4)所示:
(4)

(5)

(6)
其中参数α的取值需要随着实验不断地调整,直到最终的评估准确率不再升高为止。
4 实验研究
4.1 实验数据
实验采用了Amazon数据集。该数据集是从1996- 05至2014- 07时间段产生的,共1亿多条用户评分,每条评分记录包括用户ID、物品ID、用户对物品的评分和评分时间戳。由于数据集中Books、Movies和Music三个域的数据量较大,为了避免推荐时数据过于稀疏,本实验在这三个域上进行。
4.2 对比模型
实验的对比模型是文献[11]提出的基于簇类的跨域矩阵分解(Cross-domain Clustering-Based Matrix Factorization, CCBMF)模型。CCBMF模型分为基于簇类的跨域矩阵分解-统一设置阈值(CCBMF-Common Threshold, CCBMF-CT)模型和基于簇类的跨域矩阵分解-不设置阈值(CCBMF-No Threshold, CCBMF-NT)模型。基于簇类的跨域矩阵分解-个性化设置阈值(CCBMF-Personalized Threshold, CCBMF-PT)模型是本文提出的模型,该模型是在CCBMF模型的基础上,根据用户的评分可靠性来个性化的设置用户的阈值。
4.3 实验设计
对Books、Movies和Music域,分别都从2013- 07到2014- 07时间段中用户评论数量为1,2,…,10的物品中随机选取20个数据,再从用户评论数量为10以上的物品中随机选取300个数据组成用户数为500的训练数据集,剩下的数据作为测试数据集。在实验中,设置特征值数量为20,聚类数量为20。在矩阵分解的过程中,设定目标函数值为0.1。聚类矩阵与目标矩阵线性组合时,α取值为0.5。
4.4 评估指标
实验采用MAE作为评估指标[12]。MAE的数值越小,推荐的质量就越高,MAE的计算公式如式(7)所示:
(7)
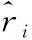
4.5 结果及分析
实验共分3组进行,分别以Books、Movies和Music作为目标域,其他两个域作为辅助域,阈值T依次从0开始递增,计算CCBMF-NT、CCBMF-CT和CCBMF-PT的MAE(Mean Absolute Error)值。实验结果如表1所示。
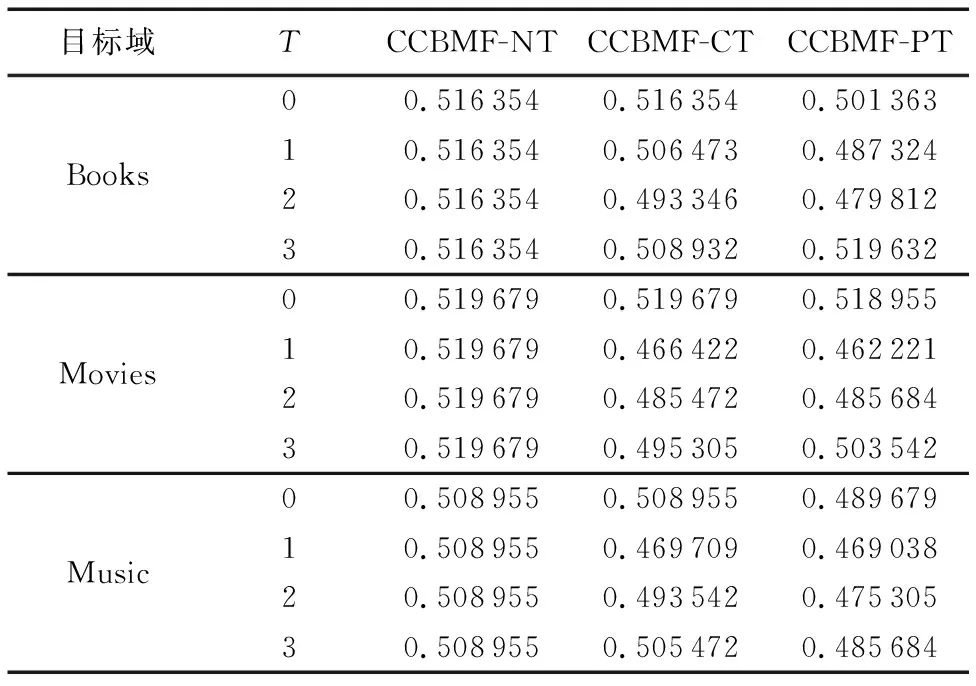
表1 模型在Books、Movies和Music域的MAE值
实验过程中发现:随着阈值T的增大,设置阈值的推荐效果反而不如没有设置阈值的推荐效果好。因此,实验在阈值为3后不再继续递增阈值。由此可知,在Amazon数据集中,随意评分的用户的数量较少。
从表1可以看出:除了目标域为Books且阈值T为3时,其他情况下,CCBMF-CT 和CCBMF-PT的MAE值均小于CCBMF-NT的MAE值,即在将辅助域中数据迁移到目标域的过程中,整体上,设置阈值比不设置阈值的跨域推荐具有更高的预测评分的准确度;除了目标域为Books且阈值T为3,目标域为Movies且阈值T为2和3时,其他情况下,CCBMF-PT的MAE值均小于CCBMF-CT的MAE值,即在将辅助域中数据迁移到目标域的过程中,整体上,个性化的设置阈值比统一的设置阈值的跨域推荐具有更高的预测评分的准确度。
5 结语
本文提出了基于评分可靠性的跨域个性化推荐方法,给出了用户评分可靠性的计算方法和个性化阈值的设置方法,描述了跨域个性化推荐方法的推荐流程。通过Amazon数据集验证了本文方法的推荐效果优于没有设置阈值的推荐效果,也优于为用户统一设置阈值的推荐效果。不过该方法仍然存在不足,即根据用户的评分可靠性等比例分段划分阈值相对较简单,进一步需要研究的是如何根据评分数据分布进行非等比例分段划分阈值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
建材发展导向(2021年19期)2021-12-06
科学家(2021年24期)2021-04-25
临床骨科杂志(2020年1期)2020-12-12
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
