
面向WSN的聚类头选举与维护协议的研究综述
2018-10-25 01:21陈君梅
现代计算机 2018年27期
陈君梅
(广州大学华软软件学院软件工程系,广州 510900)
0 引言
最近几年,研究者已经为WSN提出了很多聚类方法,其中,节约能耗是这类协议的主要目标。聚类协议的操作通常分为三个阶段:聚类头选举、聚类形成以及数据传输。每一个协议的主要部分都是聚类头选举算法,因为它能定义一个网络的能效。除了能效,聚类协议还有其他的聚类目标,例如覆盖率和容错性等。
本文旨在综述WSN中近十年的聚类协议。首先,本文讨论了WSN中的聚类目标和聚类特征分类,然后详细概述了各个聚类协议的聚类头选举与维护过程,最后统计并分析了这些聚类选举的聚类特征和选举聚类头节点的考虑因素。
1 WSN中聚类协议的聚类目标和特征
在聚类协议中,节点被组成了若干个聚类,每个聚类都有一个聚类头节点,该类节点用于更高层次的通信,从而可降低通信消费,分层的WSN如图1表示。
不同的聚类协议,聚类头选举算法存在不同。故在该部分我们首先讨论了聚类目标,然后讨论了聚类特征,为后面统计与分析各类聚类协议做准备。

图1 分层的WSN[1]
( 1)聚类目标
在现有的文献中,聚类算法的目的各有不同。在WSN中,聚类也有着不同的目的。其中,节能是这些目的中最重要也是最常见的。我们将这些聚类目标大致分为首要和次要的。首要目标意味着在聚类过程中最重要且最本质,而次要目标意味着对于网络来说不是最本质,但是它们能够通过聚类而达到。文献[2]中给出了聚类目标,如图2所示。
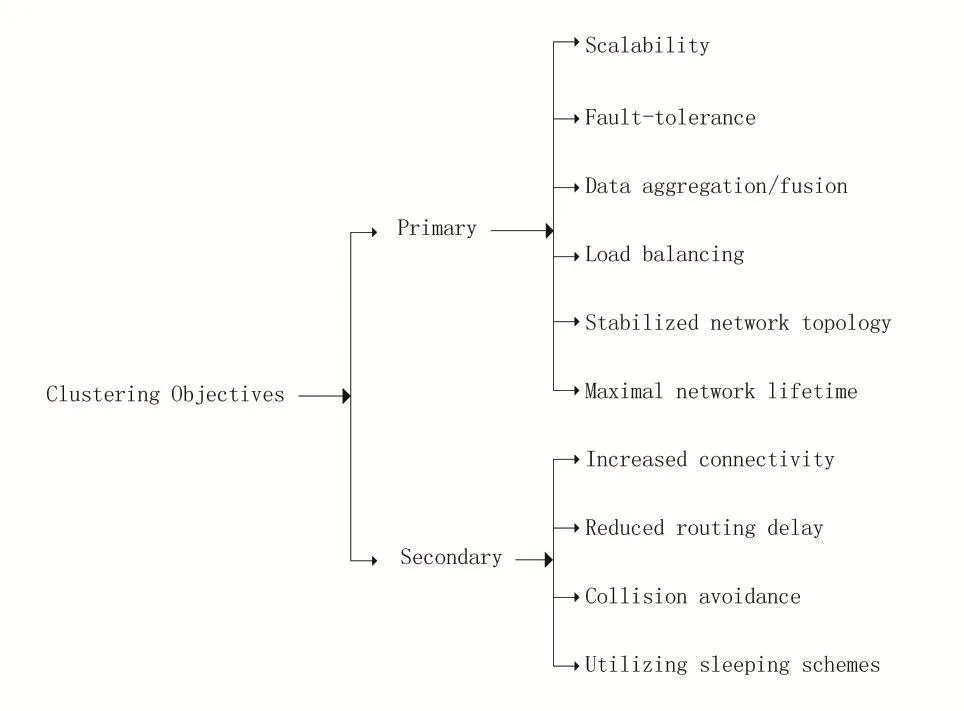
图2 聚类目标概述[2]
( 2)聚类特征
为了讨论各类聚类方法,该部分将给出一些聚类特征。通常,WSN聚类协议有三种主要的特征:聚类及其聚类头的特性,以及聚类过程的特性。其中,聚类特性通常有:聚类的数目、大小、聚类内部通信,以及聚类间通信;聚类头特性包括节点的移动性、类型以及充当的角色;聚类过程中,通常考虑的是聚类的方法、目标,以及聚类头的选择等特性。图3给出了聚类特征的一个分类。
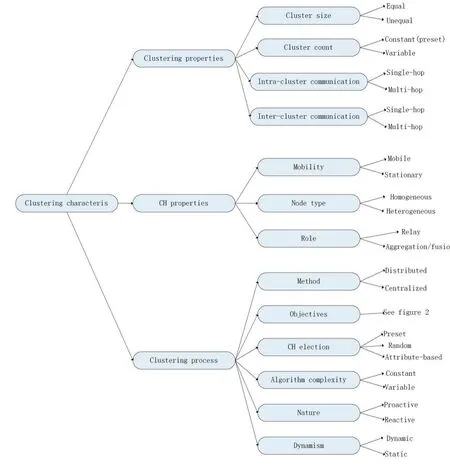
图3 WSN中聚类协议的聚类特征[2]
2 聚类头选举与维护算法
该部分,本文将详细阐述WSN近十年来的聚类头选举与维护算法。本文即将讨论的聚类头选举与维护协议如图4所示。
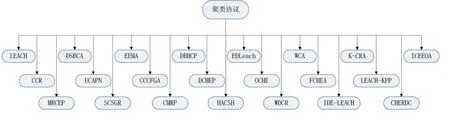
图4 聚类协议分类图
( 1)LEACH
LEACH(Low-Energy Adaptive Clustering Hierar⁃chy,低能耗自适应聚类分层)是WSN中最有名的分层聚类协议,在该协议中,一群节点形成一个聚类,并由一个节点充当这群节点的聚类头节点。这些节点基于接收信号强度选举聚类头,使得该节点充当传递信息至基站的路由者。这种方式可能减少能耗,因为只有聚类头节点而不是所有的节点在传输数据。最佳的聚类头节点个数为总节点个数的1/5。所有数据处理,例如数据融合和聚集的工作都由聚类头节点担任。为了均衡节点的能耗,LEACH在运行过程中不断地循环执行聚类头的重构。算法操作使用了“轮”的概念,每一轮由初始化和稳定工作两个阶段组成。在初始化阶段,每个节点产生一个0~1之间的随机数,如果某个节点产生的随机数小于所设的阈值T()n,则该节点发布自己是聚类头的消息[3]。
( 2)CCR
CCR(Cluster-based Coordination and Routing frame⁃work,基于聚类的协作与路由框架)通过传感器-传感器协作(AAP)使用自适应聚类协议配置传感器节点。在AAP中,聚类过程的执行包括三个阶段:①确定网络中最佳的聚类数目(k);②选举合适的聚类节点充当聚类头;③限制配置的频率。每个节点基于剩余能量、数据速率和节点的度计算其权重。让Di成为节点i到其邻居节点的平均距离,Ni是其邻居节点的总数,Ei是其可用的能量以及pi是通信速率。节点i计算它的权重Wi为:
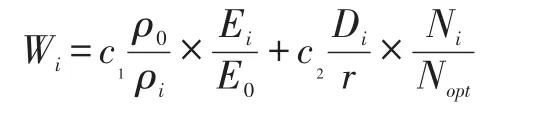
由于节点的异构性,E0和ρ0分别代表最低能量级别和节点的数据速率。系数c1和c2分别代表能量和数据速率参数的权重因子。最终选出权重大于其所有邻居节点的节点作为聚类头[4]。
( 3)MRCEP
MRCEP(Multipath Routing for Cluster-based and Event-based Protocol,基于聚类和事件的多路径路由协议)的主要设计特征是能效和多跳传输。该协议的目的在于权衡中继节点的剩余能量(能效)和中继节点距离基站的距离(最短)的来寻找最佳的传输汇集数据至基站的中继路径。MRCEP的操作被分割成轮,每一轮都包括两个阶段:形成聚类和选择聚类头,以及中继节点的选择。在每一轮之后,该协议将通知聚类选举聚类头以及重新创建一系列中继节点的路径。
当网络探测到突发事件,则该事件附近的节点将被触发去测量指定的感知属性。这些节点广播REQ_CLUSTER消息给它们的邻居,该消息包含节点IDi,剩余能量数Rres(i)以及从事件处感知的描述信息数据I(i)。在时间t1期间,每个节点将从所有的其他节点处接收REQ_CLUSTER消息并且执行聚类头函数:
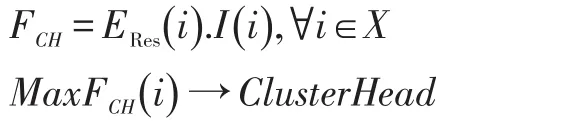
其中,X是被事件激活的节点集合。在t1时间之后,拥有最大函数集合的节点,其选举自身为聚类头并存储所有节点的节点ID,然后在节点能够传输其感知数据至基站时创建TDMA调度去安排每个节点。这些调度的功能就是避免数据传输时的冲突。聚类头接收到所有其他节点的数据,收集并聚集他们,然后选择中继节点,创建至基站的路径[5]。
( 4)DSBCA
DSBCA(A Balanced Clustering Algorithm with Dis⁃tributed Self-Organization,分布式自组织网络的均衡聚类算法)中指出,DSBCA有3个阶段:聚类头选举、建立和循环。第一阶段中,DSBCA首次随机选择一个节点Ut去触发聚类过程,然后触发节点Ut去计算它的连通度和距离基站的距离,以此去决定聚类半径k,从而成为临时的聚类头。DSBCA遵循分布式方法,以自组织模式而没有中心控制的方式去建立分层结构。在这个阶段,聚类头由Ut的k跳邻居中权重最大的担当。其权重公式中考虑的因素有:剩余能量、连通度和节点被选为聚类头节点的次数。这使得本文生成的聚类将均衡能耗和位置[6]。
( 5)UCAPN
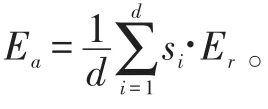
如果节点si没有在ti时间内接收到Head_Msg,该节点则在其通信范围Rc内广播其为聚类头的消息,否则则将进入聚类头选举的竞争阶段。为了产生一个不均衡的聚类,每个节点计算自身的竞争半径Rc。
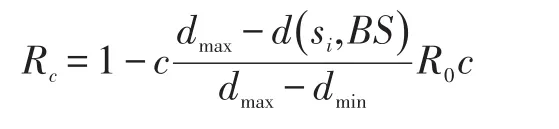
其中,dmax和dmin分别是距离基站的最大和最小距离,c是一个权重因子,R0c是一个最大竞争半径。每个节点发送Join_Msg信息至最近的聚类头,该信息包括id和剩余能量。每个聚类头根据接收的Join_Msg创建一个节点调度清单,并通过广播Sync_Msg发送调度清单给聚类成员[7]。
( 6)SCSGR
SCSGR(A Secure Clustering Scheme for Geographi⁃cally Routed Wireless AD Hoc Networks,安全聚类方案)使用CCA重聚类算法,它是一个保护加权算法,网络中的节点i均基于聚类变量Ci值决策局部的聚类头,它可以是多个聚类参数的加权和。聚类变量的Ci等式为:Ci=a×di+b×Eri。其中,di为节点i的连通度,Eri为节点i的剩余能量,系数a和b满足:a+b=1。节点周期性广播信标,以此决策出最满足聚类指标的邻居节点[8]。
(7)EEMA
EEMA(Proposed Energy-Efficient Multi-Layered Architecture,能效的多层结构)中指出,在许多聚类协议中,每个协议最重要的部分是聚类头选举算法。本文的思路是选举高剩余能量、与基站距离小的节点担任聚类头节点。为达此目的,本文介绍了新的概率法,如下所示:
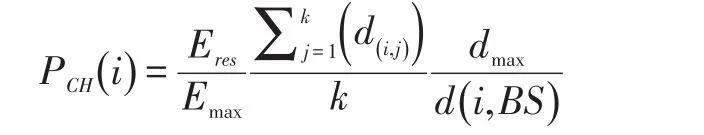
其中,Eres和Emax分别表示节点i的剩余能量和初始能量,k是节点i在聚类范围Rc内的邻居节点数,d(i,j)表示节点i和 j之间的欧氏距离,dmax和d(i ,BS)分别表示网络中最远节点和节点i到基站的距离。该概率使得那些具有更高剩余能量的节点能更接近节点较密集区,也使得这些节点到基站的聚类更近,这使得其概率比其他节点更高,因此,更有机会被选举为新的聚类头[9]。
(8)CCCFGA
CCCFGA(A Cluster-Based Coordination and Com⁃munication Framework Using GA,使用遗传算法的基于聚类的协作和通信框架)中指出,GA选择可以成为聚类头的最佳候选节点。GA的输入是能量参数,即:①节点的初始化能量;②节点的剩余能量;③网络的平均能量。无线电模块在能耗以及网络生命周期中占有重要角色。节点通过GA算法计算概率选举聚类头。GA重复循环产生最佳结果。每一次循环均包括以下步骤:①选举;②再产生;③评估;④替代。适应度函数检查每一次新一代产生的结果去得到最佳值[10]。
(9)CMRP
CMRP(Cluster based Multipath Routing Protocol,基于聚类的多路径路由协议),在该协议中,基站选取聚类头节点的条件为:①任何两个聚类头不应该在彼此的邻居节点中;②每个聚类头的剩余能量Er应该大于其阈值;③每个聚类头至少有k个邻居节点。即,基站依赖于两个独立的因素选举聚类头:一个是剩余能量Er,另外一个是节点的度D(邻居节点数目)。让Pr表示任何节点x成为聚类头节点的概率,其公式表达为:
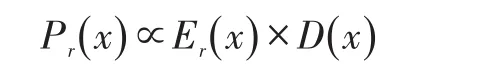
在重新聚类阶段,基站发起重新聚类的过程,为了平衡传感器节点间的负载,基站监测网络中每个传感器节点的剩余能量,如果发现剩余能量低于阈值的聚类头节点,基站将选择另外的聚类头以及相应的路径,这确保了剩余能量低于阈值的节点不充当聚类头,而是充当聚类成员,该行为增加了网络的生命周期[11]。
(10)DBHCP
DBHCP(A Distance-Based Hierarchical Clustering Protocol,基于距离的分层聚类协议)的首要目标是增加网络生命周期,该算法由基站收集所有节点信息,将此形成节点信息表,然后执行聚类头选举:基站首先设置信息表中的第一个节点为聚类头,然后该聚类头发布选举消息,而最近节点通过发送一个ACK报文给聚类头作为响应,聚类头发送一个TDMA给成员节点,聚类头发送新形成的聚类成员给基站。接着,基站考虑表中下一个节点作为聚类头的选举:如果该节点已经是一个聚类头,或者是先前形成的聚类的一员,它将发送一个NAK报文给基站,基站然后移动到表中的下一个节点;如果考虑的节点不是聚类头,或者不是聚类的一员,它将被选举为聚类头。相应地,它发送一个ACK报文给基站。重复上述过程直到所有节点均在聚类内。
而在聚类头轮换过程中,将由最初形成的聚类维护所有循环,在每一次循环的开始,聚类头基于剩余能量在一个聚类内部循环,拥有最高剩余能量的节点成为聚类头,新的聚类头传输一个TDMA给所有成员节点。当一个聚类中的所有节点均死亡,那么该聚类将从网络中消失[12]。
(11)DCHEP
DCHEP(Dynamic Cluster Head Election Protocol,动态聚类头选举协议)是动态聚类头选举协议。为了建立分层的网络,汇聚节点发送信标去广播它的身份,邻居节点收到该信标,将发送一个联合请求给发送者,并设置其发送者为父类节点。在网络建立阶段,连接着的节点会基于一个利用伪随机数值设计可变剩余能量的方式决策是否成为聚类头。聚类头将以同样的方式广播自己的身份。
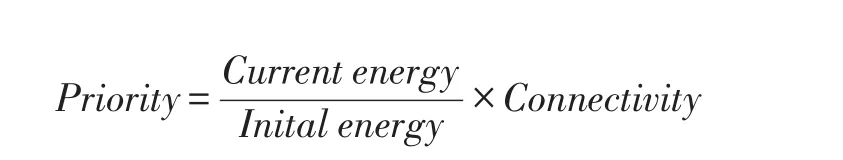
每个节点通过使用可变的剩余能量、初始能量以及值为0~1的连通性计算优先级,使得那些没有可变路径到达汇聚节点的节点不能成为聚类头节点,成为聚类头节点的概率计算公式如下:
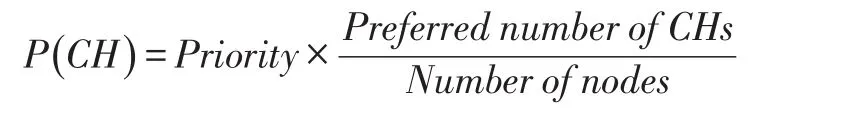
该计算在节点第一时间收到信标,或者节点在连接之后错过了信标的最大数时被触发。事先定义的聚类节点数是很重要的参数,因为它会影响网络覆盖率和聚类间的冲突。为一个移动分层WSN选择最佳数目的聚类头节点取决于应用需求和节点的移动速度。聚类节点数目的设置不作为本文的研究点,本文在配置文件中设置聚类节点数为总节点数的20%。每个节点根据P(CH)生成的伪随机数决策自身是否成为聚类头节点[13]。
(12)HACSH
HACSH(Hierarchical Agglomerative Clustering Sin⁃gle Hop,单跳分层分块聚类)使用分层式分块聚类形成聚类,该方法的优点以及特点在于它能返回最佳的聚类个数。不像其他的类似K-means方法,需要使用一个随机数k来决定聚类个数。本文的提出的聚类头选择算法包括初始化聚类、重新聚类以及选择聚类头三个阶段。初始化阶段使用HAC算法生成聚类数k,k的值小于节点数n,在第一次循环时,我们通过最小距离选取出每个聚类中距离基站最近的节点。节点i与基站的距离计算公式如下:
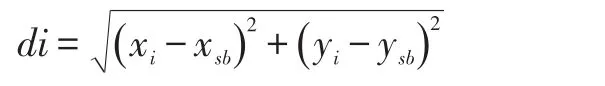
然后将节点划分到根据HAC算法生成的聚类数目的聚类中,并且把距离基站最近的节点分别安排在各个聚类中。重新聚类时,每个节点均关联k个聚类中的某一个,本文通过以下公式计算聚类的opti点。

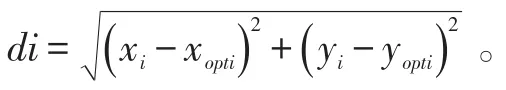
(13)EDLeach
本文提出了EDLeach协议,它在LEACH协议选举聚类头的概率公式中综合考虑了节点的能量和地理位置,在聚类头选举时通过概率选取出最合理的节点成为聚类头。DELeach协议的聚类头选举阈值公式如下:
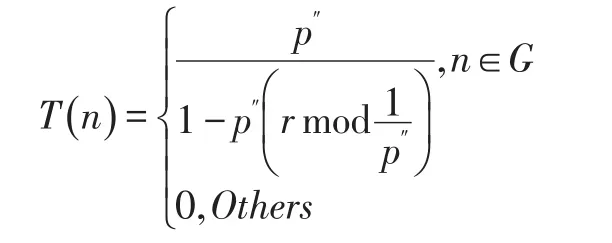
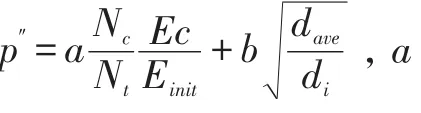
(14)OCHE
OCHE(an agent based Optimal Cluster Head Elec⁃tion technique,基于代理的最佳聚类头选取技术)是基于代理的最佳聚类头选取技术。该技术包含了最佳聚类头选举算法,该算法使用剩余能量级别(REL)和剩余停留时间(RTS)两个参数选择聚类头。其中,REL指节点在任何时间的剩余能量级别,RTS指该节点的下一个移动时间或者计算它在该聚类中的剩余停留时间。本文提出的OCHE算法选出的聚类头节点是聚类中剩余能量最多,以及剩余停留时间最长的节点。即:
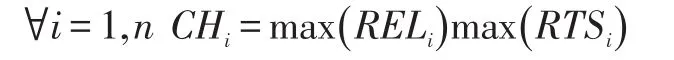
由此可见,聚类头选举频率也是影响移动WSN功率的因素之一,因为频繁的重新选举聚类头将会消耗节点的能耗。所以本文提出的算法考虑了聚类头选举的次数的最小化[16]。
(15)WDCR
WDCR(Weight Driven Cluster head Rotation for wire⁃less sensor network,权重驱动的聚类头轮询)是权重驱动聚类头循环算法,该算法在聚类头选举开始阶段,每个节点计算自身距离基站的距离。为了建立一个不等聚类大小的网络,所有的节点将计算竞争性半径,然后广播一个hello报文给所有的邻居节点。hello报文包括节点的唯一标识、剩余能量、节点成为聚类头节点的次数,以及距离基站的距离。一旦hello报文被重新保存,节点开始初始化它的参数。此外,所有的节点计算机自身的权重,以及初始化聚类头变量的默认值为false。在竞争阶段,每个节点基于自身的权重计算它的等待时长。如果超过时长,节点 j未曾收到聚类头报文,它将设置聚类头的值为true,并且在其半径范围内广播聚类头报文。此外,为了成为最终的聚类头,每个被选的聚类头节点将基于权重值再次决策,若其权重在它的通信范围内最高,它将宣称自身为最终的聚类头节点。另外,如果在其范围内有其他的节点权重大于它,则它将放弃聚类头的竞争,宣布自身为聚类成员,之后将通过广播加入报文加入最近的聚类[17]。
(16)WCA
WCA(Clustering Approach Using Node Mobility,使用节点移动性的聚类方法)是考虑了节点移动性的聚类方法。本文认为节点的移动性是造成能量消耗的重要原因。因此,选择低移动性节点充当聚类头能限制能耗从而最大化网络生命周期。开始阶段,本文通过如下公式计算节点的移动性。

该等式计算了节点直至当前时间T的移动性。(xt,yt)和(xt-1,yt-1)分别是节点v在t和t-1时的坐标。节点移动性级别ML可定义为移动速度超过6 m h。节点的速度若是等于或者大于ML将被认为是恶意节点。该类节点不能参与聚类头节点的选取。而移动能力较为弱的节点将会进入聚类头选举环节。选举的过程如下:
①每个节点广播一个hello报文用于发现他的邻居节点,节点的邻居节点集为:
②每个节点计算自身的连通性、剩余能量和自身与其邻居节点之间的距离。距离计算如下:

(17)FCHEA
FCHEA(Fuzzy Cluster Head Election Algorithm,模糊聚类头选举算法)是模糊聚类头选举算法。类似于LEACH协议,本文提出的算法也采用论的概念,在每一轮中,每个节点选择一个[0~1]之间的随机数,如果随机数小于阈值T,那么该节点被选为当前的聚类头节点。该聚类头节点使用模糊方法计算它们的机会值,然后广播聚类头消息至所有在其通信范围内的节点。聚类头消息包括节点id,剩余能量以及机会值。被选为聚类头节点的节点其剩余能量最多。如果当前聚类头收到剩余能量大于自身的聚类头消息,那么当前聚类头将降为成员节点,并选择最近的聚类头,加入其形成聚类。然后,在分配的时间槽期间,成员节点发送其数据至相应聚类头,其余时间处于休眠状态从而节约能量[19]。
(18)IDE-LEACH
IDE-LEACH(Improved Distance Energy based LEACH,基于距离能量的LEACH)是基于距离能量的LEACH方案。该方案使用初始化能量、节点距离汇聚节点或基站的距离以及节点的持续能量来考虑聚类头的选择。阈值计算公式如下:
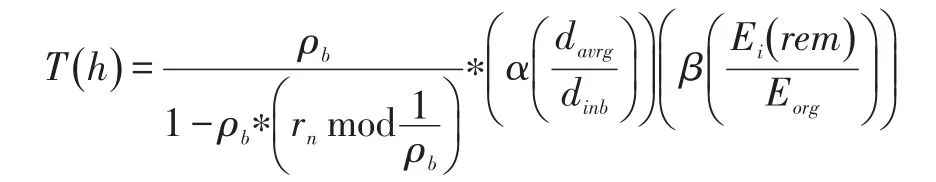
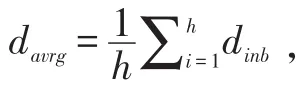
(19)K-CRA
K-CRA(A research on Clustering Routing Algorithm based on K-means++,基于K-means的聚类路由算法)是K-means的聚类路由算法。本文认为基于随机选择聚类头会造成数量不均的聚类以及不均衡的能量消耗,故本文提出了一个基于K-means算法去划分聚类,以及改进了LEACH算法计算聚类头的公式,具体操作如下:
本文的聚类头选举分为两个阶段:网络初始化阶段和聚类头更新阶段。在网络初始化阶段,每个聚类的聚类头由基站选举出每个聚类中距离聚类中心最近的节点作为聚类头节点。距离计算公式如下:
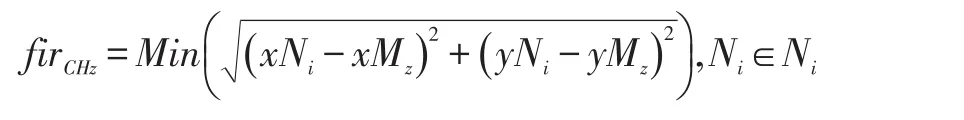
当聚类头的能量低于阈值,将会根据如下公式选出新的聚类头。
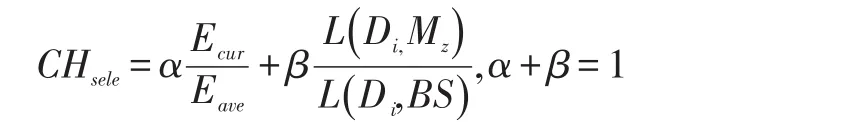
其中,α和β是相关参数,Ecur和Eave分别是节点的剩余能量和平均能量,L(Di,Mz)和L(Di,BS)分别是节点距离聚类中心和基站的距离。最后将选出每个聚类当中CHsele值最大的节点作为该聚类的聚类头[21]。
(20)LEACH-KPP
LEACH-KPP(research on wireless sensor networks clustering algorithm based on K-means++,基于 K-means++的无线传感网分簇算法)是基于K-means++的无线传感网分簇算法。该算法综合考虑了节点的剩余能量、与基站间的距离,以及与上一轮聚类头间的距离。从而避免与基站远以及剩余能量少的节点担任聚类头,并且选出的聚类头会接近上一轮聚类头。聚类头选取函数T()n改进为:
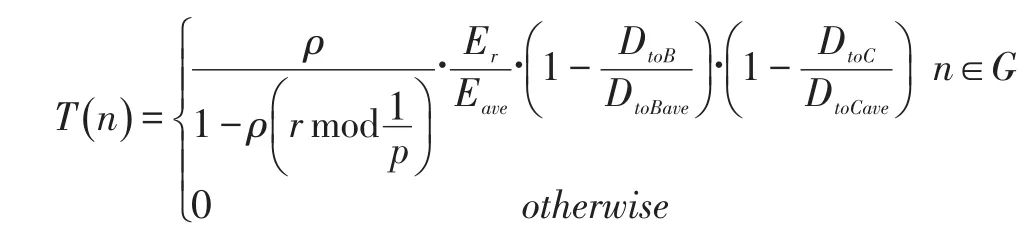
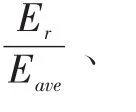
(21)CHERDC
CHERDC(Cluster Head Election using Residual En⁃ergy and Density Control,使用剩余能量和密集度控制的聚类头选举)算法在聚类头选举阶段,每个节点决策自身为聚类头还是聚类成员。在每一轮中,节点将会接收RTi报文,RTi报文包含其邻居节点的所有信息。在该算法中,Ni.Stat表示节点i的状态。事实上,节点 j在一开始都会设置自身为聚类头节点,然后加入竞争阶段,其状态可能变改为聚类成员或依旧为聚类头节点,每个节点与其邻居节点比较剩余能量,如果发现邻居节点剩余能量大于自身,则不得不设置自己的状态为聚类成员。如果二者的剩余能量相等,则进一步比较节点的密集度,密集度更高的节点将更有可能成为聚类头节点。节点密集度的计算公式如下:
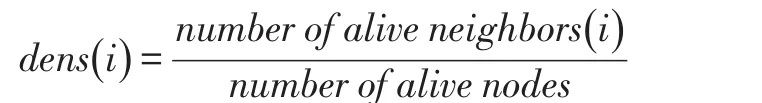
该公式可以保证在每个节点的传递范围内,只会存在一个聚类头节点[23]。
(22)ICEEOA
ICEEOA(Energy Optimization Algorithm for Hierar⁃chical Routing Based on Improved Cluster Election,改进聚类头选举的分层传感网络能力优化算法)是改进聚类头选举的分层传感网络能力优化算法。本文提出的聚类头选举算法中,在聚类头竞争时,基于原来计时机制的基础上,增加了成员个数参数,这避免了成员个数较多的候选聚类头节点成为聚类头节点的概率,改进的公式为:
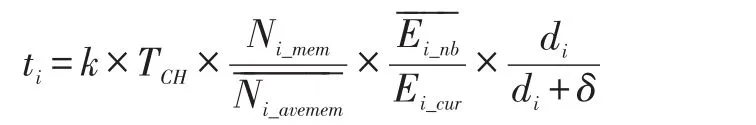
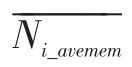
3 聚类头选举与维护协议的统计与分析
本部分,我们首先根据聚类协议的聚类特征,统计了上述阐述的聚类算法,如表1所示,接着以柱状图的形式分析了各个聚类算法的聚类特性、聚类头特性和聚类过程特性,分别如图5、图6、图7所示;然后统计了各个聚类协议中聚类头选举的考虑因素,如表2所示,并以饼状图的形式展现了各类因素在选取聚类头时所占的权重,如图8所示。
由表1,分别统计了聚类协议的聚类特性、聚类头特性、聚类过程特性,分别如图5、图6、图7所示。其中:
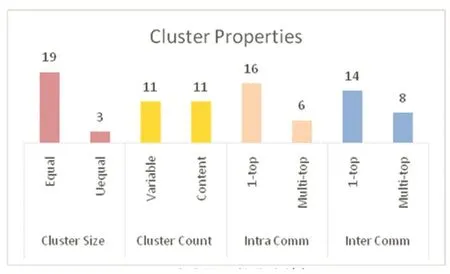
图5聚类协议的聚类特性
图5 显示,现有的聚类协议在考虑聚类特性时,聚类尺寸相同的情况多于尺寸不同的情况,而聚类的数目,随机生成的数目和固定的数目基本持平,而聚类数目变化的情况多半是因为在选举聚类头节点时采用了随机函数,从而使得聚类数目不固定;而在数据传递过程中,现有的聚类协议中,单跳的使用远远大于多跳,这也正是为了节约能耗的表现。
图6显示,现有的聚类协议在考虑聚类头特性过程中,聚类头处于静止状态的情况多于处于移动的情况,因为聚类头的移动会造成网络拓扑的变化从而使得它的管理费用比固定节点的消费要高,并且,节点的移动会造成重新聚类的频率增高,也会增加能耗。而在考虑节点的类型时,大都数的WSN,节点的初始功率都是相等的,只有少部分考虑了节点的异构性。此外,聚类协议中的聚类头,基本在充当中继角色的同时,还会承担一定的数据聚集与融合工作。
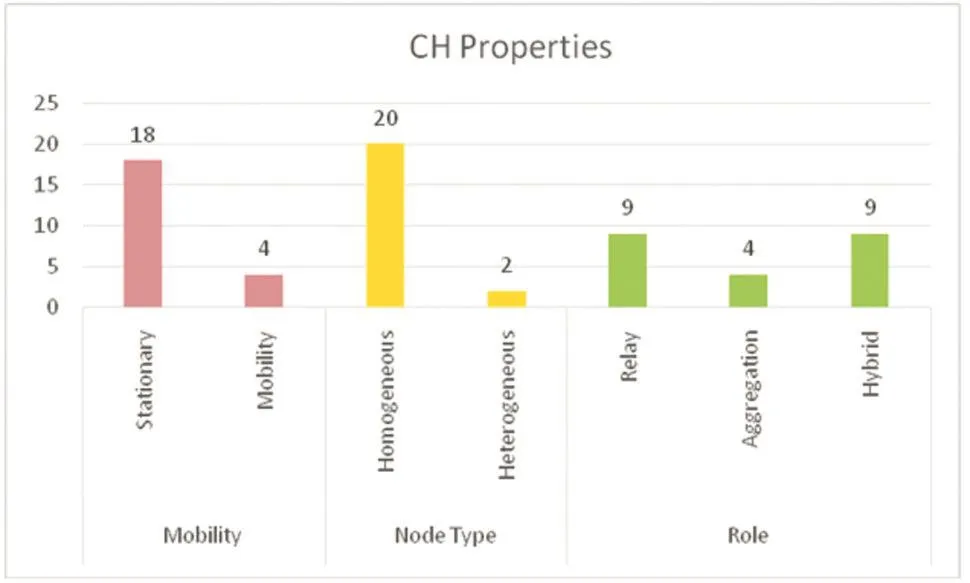
图6 聚类协议的聚类头特性
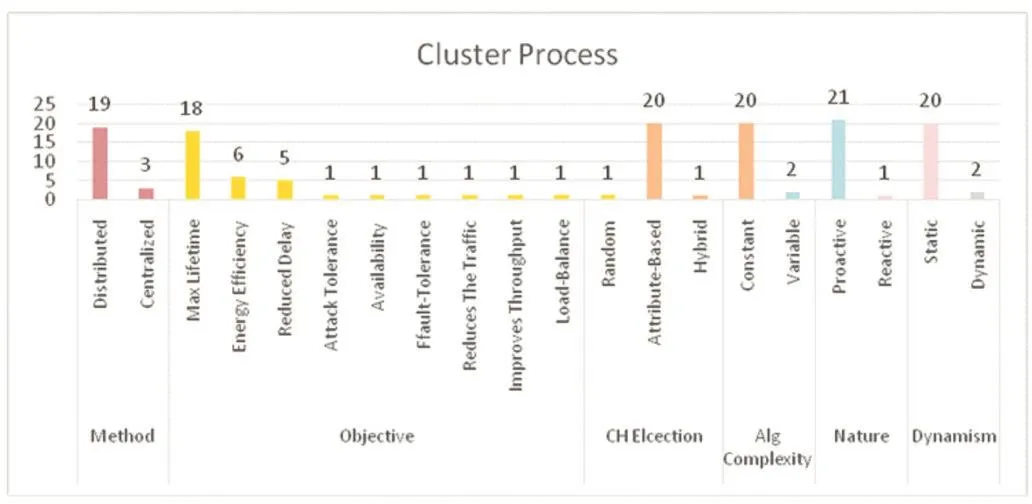
图7聚类协议的聚类头特性
图7 显示,现有的聚类协议在考虑聚类过程特性时,在方法的采取方面,分布式方法远远多于集中式管理,这也是由于WSN中节点数目较多,分布式管理更加有效;而在考虑聚类目标时,主要目的是增加节点的能效、减少数据的传输时延,从而延长网络的生命周期。选取聚类头时,考虑到随机生成容易选出能效差的节点充当,从而增大重新聚类的频率会浪费节点能耗,故而,越来越多的聚类协议采取基于属性的方式生成聚类头,使得生成的聚类头最优,从而降低能耗。
每个节点在考虑聚类头时,考虑的因素各不相同,表2统计了各类聚类协议采取的聚类头选取因素。
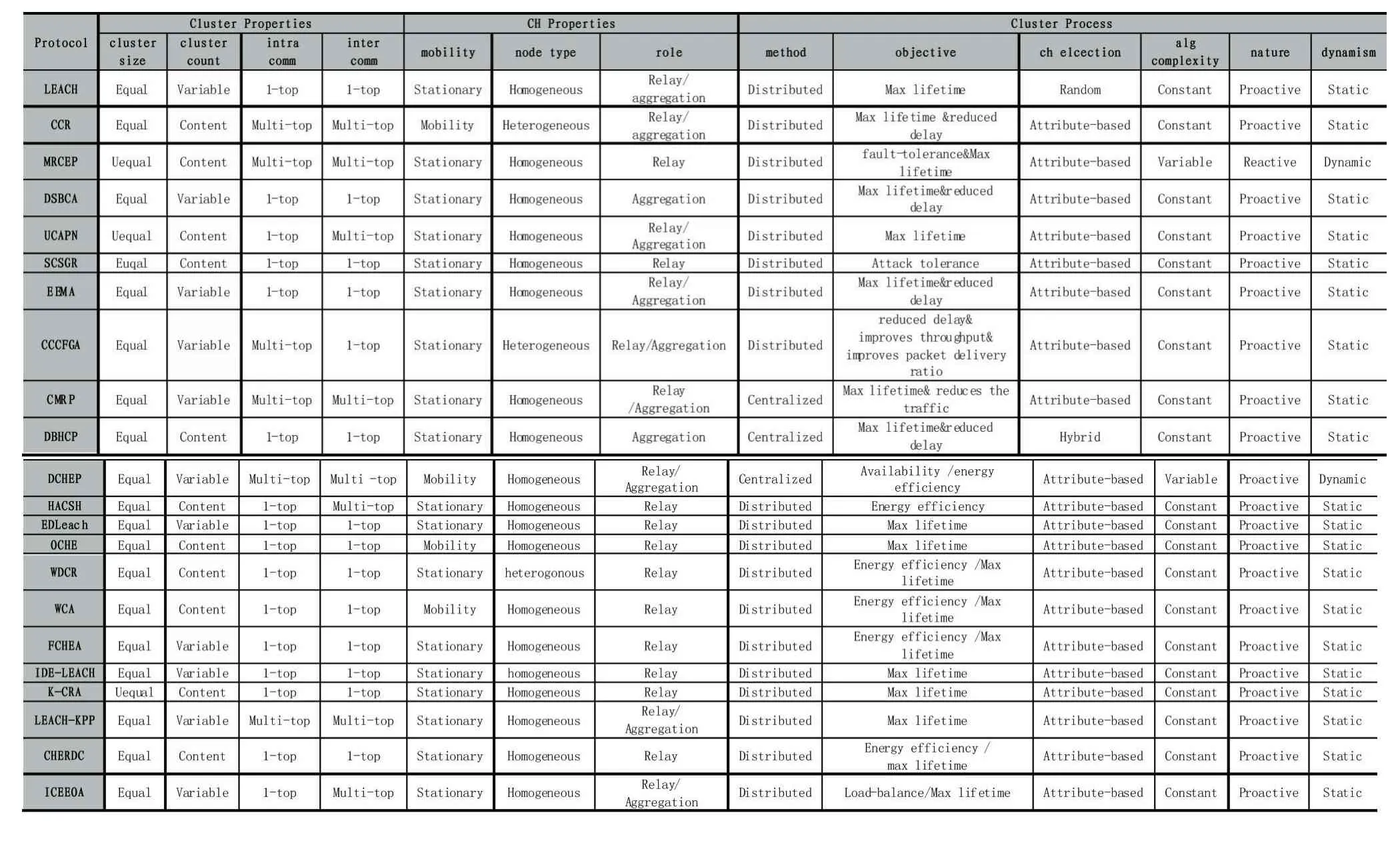
表1 聚类协议的聚类特性、聚类头特性以及聚类过程特性统计表
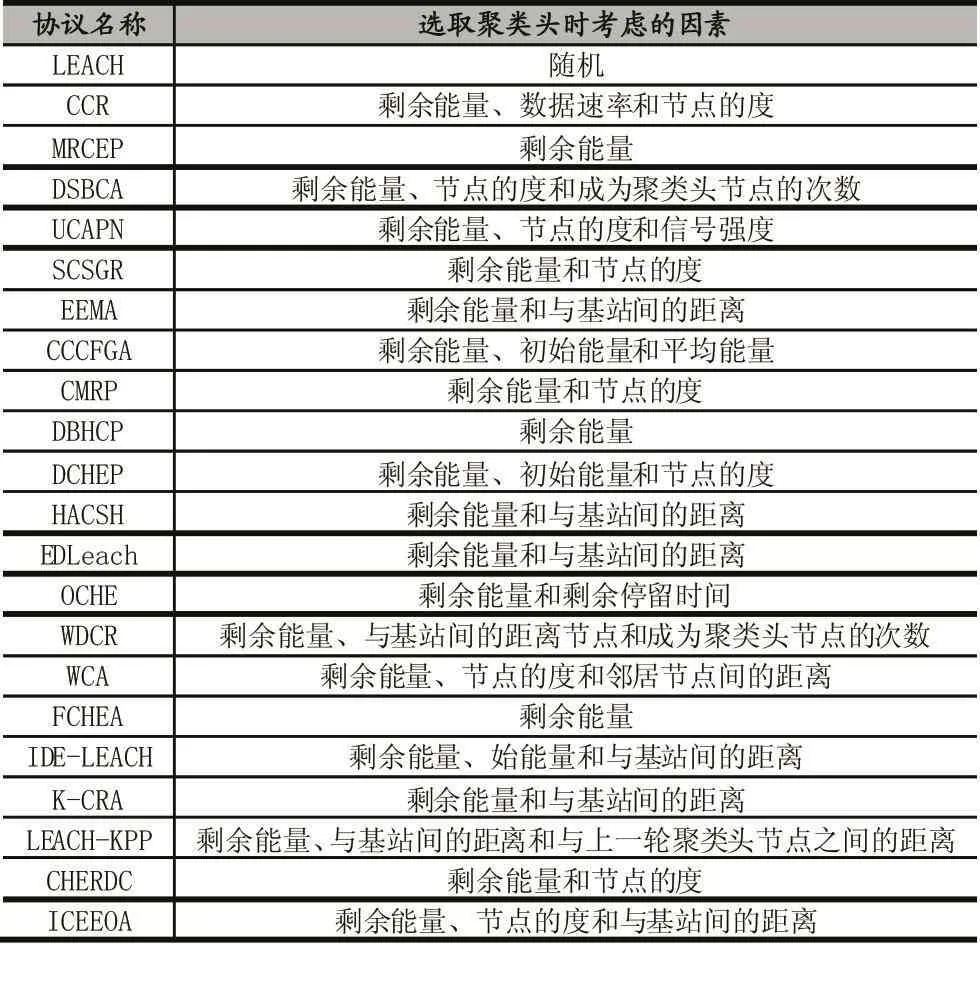
表2 聚类协议的聚类头选举的考虑因子
根据表2,统计出各个聚类协议在选举聚类头时考虑的因素比例,如图8所示。
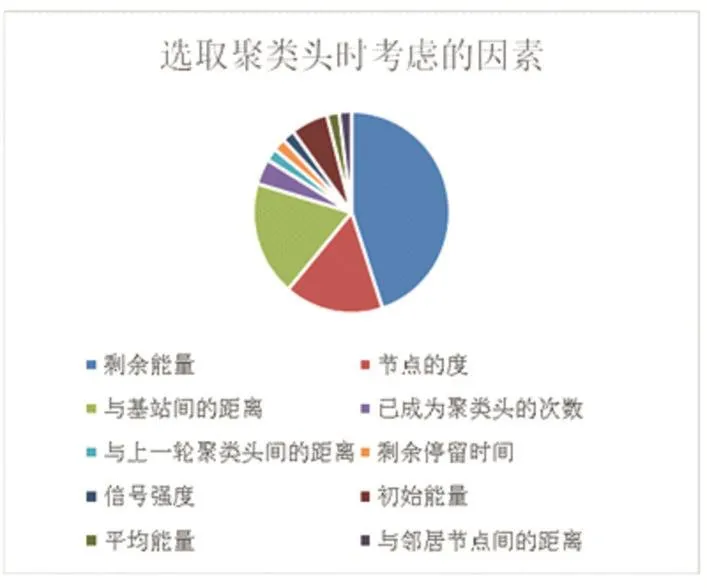
图8选举聚类头时考虑的因素
图8 表示,在现有的聚类协议中,聚类头的选举与维护主要考虑的因素是节点的剩余能量、其次是与基站的距离以及节点的度。剩余能量多、与基站较近,以及自身的邻居节点更多的节点有更高的几率被选为聚类头节点,这样的节点充当聚类头,能够保证聚类的稳定性,也会降低聚类头选举的频率,从而提高节点的能效,最终达到延长网络生命周期的目的。
4 结语
聚类协议在无线传感器中扮演着一个重要的角色,而聚类头的选举与维护又是聚类协议中最关键的部分,故,本文综述了WSN中22个各类聚类协议的聚类头选举与维护算法,统计并分析了这22个算法的聚类特征以及选取聚类头的考虑因素。分析结果表示:①现有的聚类协议在考虑聚类特性时,聚类尺寸相同的情况多于尺寸不同的情况,而聚类的数目,随机生成的数目和固定的数目基本持平,数据传递多数采用单跳的方式。②现有的聚类协议在考虑聚类头特性过程中,聚类头处于静止状态的情况多于处于移动的情况,节点的类型大多数是同构节点而异构节点,此外,聚类协议中的聚类头,基本在充当中继角色的同时,还会承担一定的数据聚集与融合工作。③现有的聚类协议在考虑聚类过程特性时,分布式方法远远多于集中式管理,考虑聚类目标时,主要目的是增加节点的能效、减少数据的传输时延,从而延长网络的生命周期,而选取聚类头时,越来越多的聚类协议采取基于属性的方式生成聚类头,使得生成的聚类头最优,从而降低能耗。而所考虑的属性性质当中,节点的剩余能量、节点距离基站的距离以及节点的度又是主要考虑的因素。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国新通信(2022年4期)2022-04-23
计算机应用与软件(2021年7期)2021-07-16
恋爱婚姻家庭·青春(2019年9期)2019-12-10
恋爱婚姻家庭(2019年26期)2019-09-14
小学生导刊(2018年34期)2018-12-18
舰船电子对抗(2017年6期)2018-01-11
探索科学(2017年4期)2017-05-04
互联网天地(2016年1期)2016-05-04
山东青年(2016年3期)2016-02-28
