
基于孪生网络和重排序的行人重识别
2018-12-14 05:26陈首兵王洪元
计算机应用 2018年11期
陈首兵,王洪元,金 翠,张 玮
(1.常州大学 信息科学与工程学院,江苏 常州 213164; 2.常州信息职业技术学院 电子与电气工程学院,江苏 常州 213164)(*通信作者电子邮箱hywang@cczu.edu.cn)
0 引言
行人重识别(Person Re-Identification, Re-ID)[1]通常可以被视为一个图像检索问题,即从不同的相机中来匹配行人。给定一张查询的行人图像,行人重识别旨在从非重叠摄像机视角下的行人图像库中找出与该行人是同一个行人的图像。由于摄像机捕获的行人图像受到光照、姿势、视角、图像分辨率、相机设置、遮挡和背景杂乱等影响,会导致同一个行人图像发生很大的变化,因此行人重识别仍是计算机视觉中的一项具有挑战性的任务。
特征表示和度量学习是很多现有的行人重识别文献的主要方法。卷积神经网络(Convolutional Neural Network, CNN)在学习特征表示方面或深度度量[2-8]方面已经表现出优势。如图1所示,有两种CNN模型,即识别模型和验证模型。这两种模型在训练的输入、特征提取及损失函数方面都有所不同。1993年,Bromley等[6]首先使用验证模型在签名验证中进行深度度量学习,最近,研究人员开始将验证模型应用于行人重识别,重点关注数据增强和图像匹配; Yi 等[7]将行人图像分成三个水平部分,并训练三部分CNN来提取特征; 后来,Ahmed等[9]通过添加一个不同的匹配层来提升验证模型; Wu等[10]使用更小的过滤器和更深的网络来提取特征; Varior等[11]将CNN与一些门函数相结合,其目的是自适应地聚焦于输入图像对的相似部分,但因为查询图像必须与图库中的每幅图像配对以通过网络,所以计算效率低下。最近,不少研究者们已经将重排序方法[12-14]用到行人重识别中。Ye等[13]将全局和局部特征的共同最近邻组合为新的查询,并通过结合全局和局部特征的新排序表来修改初始排序表; 文献[14]利用k最近邻集合来计算不同基线方法的相似度和相异度,然后进行相似度和相异度的聚合来优化初始排序列表。然而,由于通常包含错误匹配,因此直接使用k最近邻进行重排序可能会限制整体性能。为解决这个问题,本文将k互近邻方法用到行人重识别中来进行重排序。
本文提出一种用于Re-ID的深度学习孪生网络,它基于CNN识别模型和CNN验证模型,可以同时计算识别损失和验证损失。该孪生网络可以同时学得一个具有辨别力的CNN特征和相似性度量,因此可以提高行人检索准确率,本文还将重排序加入到行人重识别中,通过k互近邻方法降低图像错误匹配情况,最后将欧氏距离和杰卡德距离(Jaccard distance)加权来对排序表进行重排序,在两大行人重识别数据集上的实验表明重排序可以进一步提高行人匹配率。

图1 验证和识别模型之间的区别
1 相关工作
1.1 验证模型
验证模型将行人重识别视为一个二类识别任务,将一对图像作为输入并判断它们是否是同一个行人。很多先前的文章把行人重识别看作二分类任务或相似性回归任务[2-3]。给定一个标签s∈{0,1}, 0表示不是同一个行人,1表示同一个行人。验证网络将同一个行人的两幅图像映射到特征空间中的附近点, 如果图像是不同的人,点就相隔较远。验证模型中的主要问题是只使用了弱的行人重识别标签,没有考虑所有标签信息。
1.2 识别模型
识别模型将行人重识别视为一个多类识别任务,把一幅图像作为输入并预测其行人身份,其充分利用了Re-ID标签,并被用于特征学习[15]。识别模型直接从行人输入图像中学习非线性函数,并在最后一层后使用交叉熵损失。在测试期间,从全连接层提取特征,然后进行归一化。两幅图像的相似性是通过其归一化的CNN特征之间的欧氏距离来度量的。识别模型的主要缺点是没有考虑图像对之间的相似性度量。
1.3 重排序
重排序在一般的实例检索中已经得到大量研究[4-5]。以前的一些论文利用了最初排序表中排名最高的图像之间的相似性关系,例如最近邻[16]。如果返回的图像排在查询图像的k个最近邻之内,则它可能是真正的匹配,可以用于随后的重排序。不过,错误匹配的图像也可能包含在查询图像的k近邻中, 因此,直接使用top-k排序的图像可能会在重排序中引入噪声并影响的最终结果。
k互近邻[4-5]是解决上述问题的有效方法。如果两张图片同时互为k近邻,那么它们就是k互近邻,即当其中一张图片作为查询图片时,另一张图片就排在其最靠前的k个位置, 因此,k互近邻提供了一个更严格的匹配规则。重排序方法的框架如图2所示,给定一张查询行人图片和一个行人图库,为每个行人提取外貌特征和k互近邻特征。然后再分别计算图库中每个行人与查询行人的原始距离d和杰卡德距离dJ,将d和dJ结合起来得到最终距离,使用最终距离来进行重排序得到新的排序表。
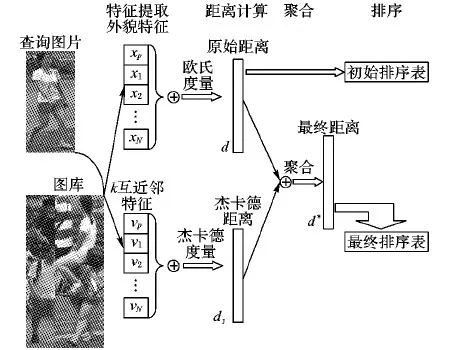
图2 重排序框架
2 网络框架和重排序
2.1 整体网络
本文的网络是一个卷积孪生网络,结合了验证模型和识别模型。图3简要说明了网络的框架, 网络包括2个ImageNet预训练的CNN模型ResNet50[17],3个卷积层,1个平方层和3个损失,受识别标签t和验证标签s监督。给定n个尺寸为224×224的图像对,使用两个完全相同的ResNet50模型作为非线性特征函数并输出4 096维特征f1、f2。f1、f2分别用于预测两个输入图像的行人身份t,用平方层来比较高维特征f1、f2,然后f1、f2共同地预测验证标签s。最后,softmax损失被应用于三个目标函数。

图3 本文模型结构
2.2 识别损失
在框架中有两个ResNet50,它们共享权重并同时预测输入图像对的两个身份标签。为了在新数据集上对网络进行微调,本文用卷积层替换了预训练的CNN模型ResNet50的最后全连接层(1 000-维)。Market1501中751个行人用于训练,所以这个卷积层有751个大小为1×1×4 096的内核,该内核连接到ResNet50的输出f,然后再添加一个softmax单元来归一化输出,最终张量的大小是1×1×751。ReLU激活函数没有加在卷积之后。类似于传统的多类别识别方法,本文使用交叉熵损失进行行人身份预测,公式如下:
(1)
(2)
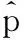
2.3 验证损失
以前的一些论文在中间层包含了一个匹配函数[2,8,10],本文直接比较了高维特征f1、f2用于相似性评估。来自微调CNN的高维特征已表现出了辨别能力[18],其比中间层的特征更为紧凑,所以在本文的模型中,行人描述符f1、f2在识别模型中直接受到验证损失的监督。如图3所示,本文用平方层(非参数层)来比较高维特征,平方层表示为fs=(f1-f2)2,其中f1、f2是4 096维特征,fs是平方层的输出张量。
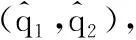
(3)
(4)

本文没有使用对比损失:一方面,对比损失作为回归损失,让同类特征尽可能地接近, 由于在行人重识别领域每个行人的训练次数有限,所以可能会使模型过拟合;另一方面,在随机位置引入零值的dropout[19],在对比损失前不能应用于特征,但本文模型中的交叉熵损失可以用dropout来正则化模型。
2.4 重排序
给定一个查询行人图片p和包含N张图片的图库G,G={gi|i=1,2,…,N},两个行人p和gi之间的原始距离可以用欧氏距离来度量,可用式(5)表示:
(5)
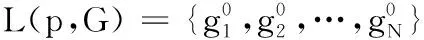
(6)
其中:|·|表示集合中候选行人的个数。k互近邻S(p,k)定义如下:
S(p,k)={(gi∈M(p,k))∩(p∈M(gi,k))}
(7)
与k近邻相比,k互近邻与p更相关。然而由于照明、姿势、视角及遮挡的变化,可能有些正样本既不在k近邻里,也不在k互近邻里。针对这个问题,采用把S(p,k)里每个候选人的k/2互近邻加到一个更鲁棒的集合S*(p,k)里,用式(8)表示:
S*(p,k)←S(p,k)∪S(q,k/2); ∀q∈S(p,k)
(8)
由文献[14]可得,如果两张图片相似,那么它们的k互近邻集合会重叠,即在集合里有一些相同的样本。相同的样本越多,这两张图片越相似。p和gi之间的新距离可以由它们的k互近邻特征的杰卡德度量计算得到,杰卡德距离(Jaccard distance)可以用式(9)表示:
(9)
其中|·|表示集合中候选行人数。如果S*(p,k)和S*(gi,k)共享更多元素,gi更可能是正确的匹配。结合原始距离和杰卡德距离来对初始排序表进行重排序,最终的距离d*用式(10)表示:
d*(p,gi)=(1-λ)dJ(p,gi)+λd(p,gi)
(10)
其中:λ∈[0,1],λ表示惩罚因子,惩罚远离p的gi。当λ=0,仅考虑杰卡德距离; 当λ=1,仅考虑原始距离,λ的取值在实验部分有分析说明。最后,得到的重排序后的排序表L*(p,G)按照最终距离的升序排序。
3 实验
本文使用微调的预训练CNN模型ResNet50在两大行人重识别数据集Market1501[3]和CUHK03[2]上进行实验。
3.1 数据集和评价指标
数据集 Market1501包含1 501个行人的32 668个带标签的边界框。每个行人的图像最多由6台摄像机拍摄, 边界框直接由可变形零件模型(Deformable Part Model, DPM)[20]检测而不是使用手绘边界框,这更接近现实的场景。数据集被分为训练集和测试集,训练集包含751个行人的12 936个裁剪图像,测试集包含750个行人的19 732个裁剪图像。在测试中,使用3 368张包含750个行人的手绘图像作为查询集来识别测试集上的正确行人身份。对于每个查询图像,旨在从19 732个候选图像中检索出正确匹配的图像。
CUHK03数据集包含1 467个行人的14 097张在香港中文大学校园里收集的裁剪图像。每个行人由两个相机所拍摄,且每个行人在每个相机中平均具有4.8张图像。数据集提供了两种边界框,分别是由手动标注的边界框和由DPM检测到的边界框,在DPM检测到的边界框上评估本文的模型,这更接近现实的情况。数据集划分为1 367个行人的训练集和100个行人的测试集,重复20次随机分割用于评估。表1列出了两大数据集的具体信息。

表1 实验中使用的数据集的详细信息
评价指标 本文使用两个评价指标来评估所有数据集上的行人重识别方法的性能: 第一个评价指标是累积匹配特征(Cumulative Match Characteristic, CMC)曲线,把行人重识别看作是一个排序问题,使用Rank1来描述,Rank1指在图库中第一次就成功匹配的概率,就是排在排序表中第一位的图片是正确结果的概率,通过实验多次取平均值得到; 第二个评价指标是平均精度均值(mean Average Precision, mAP),它是平均精度(Average Precision, AP)的均值,把行人重识别看作是一个目标检索问题[3],使用mAP来度量。AP和mAP的公式如下所示:
(11)
其中:r是检索图像的排序号;P(r)是已经检索的图像中相关的图像占的比例;rel(r)是检索图像的排序号的二元函数,是相关图像值为1,否则为0。

(12)
其中Q是查询的次数。
3.2 参数分析
实验中参数k和λ是先在验证集中进行测试,然后选取最好的参数在测试集上使用,画图时采用控制变量法。当探讨Rank1和mAP与λ的关系时,保持k不变;当探讨Rank1和mAP与k的关系时,保持λ不变。图4为在Market1501上Single Query(Single Query是指使用一个行人的一张图片作为查询集)和Multiple Query(Multiple Query指使用一个行人的多张图片作为查询集)情况下λ的取值对Rank1和mAP的影响,可以看出当λ为0.3时,Rank1和mAP达到最优值。图5为在Market1501上k的取值对Rank1和mAP的影响,从图中可以看出,当k为12时,Rank1和mAP取得最优值。在CUHK03上λ和k分别为0.8和8时,Rank1和mAP达到最优值,因为图与Market1501中的图类似,所以没有在文中给出。
3.3 实验结果与分析
表2与表3分别是Single Query和Multiple Query情况下多种方法在数据集Market1501上的Rank1和mAP的比较。表2和表3中与本文方法(其中:本文方法1是将识别模型和验证模型进行结合的孪生网络,可同时学习一个具有辨别力的CNN 特征和相似性度量,并预测两个输入图像的行人身份以及判断它们是否属于同一个行人; 本文方法2是在方法1的基础上加上了重排序方法,将欧氏距离和杰卡德距离加权来对排序表进行重排序)比较的有DADM(Deep Attributes Driven Multi-camera)[21]、Multiregion CNN[22]、DNS(Discriminative Null Space)[23]、Gate Re-ID[11]、ResNet50-Basel[17]、PIE(Pose Invariant Embedding)[24]和SOMAnet[25]等方法。本文方法相比其他方法对Re-ID性能都有显著提升, 如表2中本文方法1的Rank1达到80.82%,mAP达到62.30%,重排序后又分别提升了2.62个百分点和6.45个百分点,明显高于DADM和DNS等方法,其中DADM方法只使用有限数量的标记数据逐步提高属性的准确性,使得行人属性更具有鲁棒性。

图4 在Market1501上参数λ对Re-ID性能的影响

图5 在Market1501上参数k对Re-ID性能的影响
表4和表5分别是在CUHK03数据集上single-shot和multi-shot环境下多种方法Rank1和mAP的比较。DeepReID[2]、IDE(ID-discriminative Embedding)[26]、DNS、IDE+XQDA(ID-discriminative Embedding+Cross-view Quadratic Discriminant Analysis)[26]、ResNet50-Basel、LOMO+XQDA(Local Maximal Occurrence Representation+Cross-view Quadratic Discriminant Analysis)[27]、S-LSTM(Siamese Long Short-Term Memory)[28]和Gate-SCNN[11]等方法与本文方法作比较。single-shot是指在gallery(图库)里面只有一张图片和probe(查询集)是同一个行人,multi-shot是指在gallery里面有多张图片和probe是同一个人。如表4中所示,本文方法2产生了85.56%的Rank1和88.32%的mAP,远超过IDE和DNS等方法。

表2 Single Query情况下多种方法在数据集Market1501上的比较
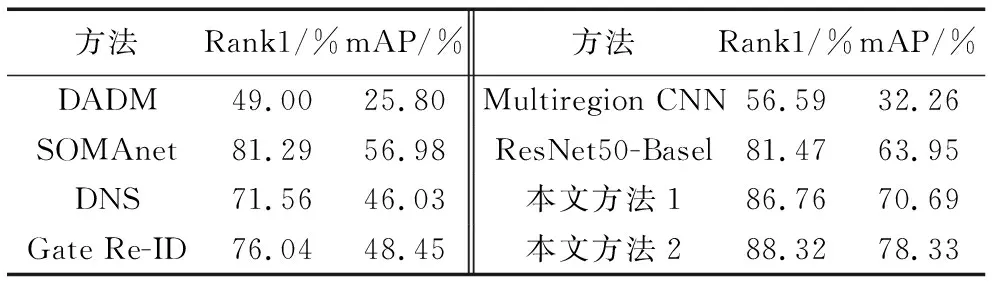
表3 Multiple Query情况下多种方法在数据集Market1501上的比较

表4 CUHK03数据集single-shot环境下多种方法的比较

表5 CUHK03数据集multi-shot环境下多种方法的比较
4 结语
由于验证模型和识别模型有各自的优点和局限性,具体来讲,验证模型提供了相似性评估,但仅使用了弱的Re-ID标签,没有考虑所有的标注信息,缺乏图像对和其他图像之间关系的考虑;识别模型使用了强的Re-ID标签,但没有考虑图像对之间的相似性度量,所以本文将这两种模型结合起来,提出一种用于Re-ID的孪生网络,可以同时学得具有辨别力的CNN特征和相似性度量,因此可以提高行人检索准确率。重排序也是提高行人重识别识别率的重要一步,但是以往的k近邻方法可能会遇到错误匹配的图像也包含在查询图像的k近邻中的情况,而k互近邻提供了一个更严格的匹配规则,本文使用k互近邻方法有效地降低图像错误匹配的情况,最后将欧氏距离和杰卡德距离加权来对排序表进行重排序。在两个大型的行人重识别数据集Market1501和CUHK03上的实验结果表明,Re-ID性能都有明显提升,超过了很多方法。如何找到更好的方法在更多的数据集上进一步提升Re-ID匹配率将是下一步的研究工作。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
名家名作(2021年4期)2021-05-12
意林(2021年5期)2021-04-18
科普童话·学霸日记(2020年1期)2020-05-08
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2019年2期)2019-01-10
中国诗歌(2018年6期)2018-11-14
小天使·一年级语数英综合(2017年6期)2017-06-07
