
一种嵌入项目元数据的跨项目协同过滤推荐算法
2018-04-13 10:17刘学军陈振春
小型微型计算机系统 2018年4期
王 秀,刘学军,陈振春,邵 帅
(南京工业大学 计算机科学与技术学院,南京 211816) E-mail: wangxiu@njtech.edu.cn
1 引 言
随着现代化技术的逐渐普及,人们进入了一个网络信息时代,在享受网络带来便利的同时也陷进了“信息过载”境遇,如何从海量的信息资源中准确而快速地寻找到自己感兴趣的事物是一件及其困难的事情.而推荐系统可以有效解决这一问题,其通过收集、挖掘相关信息主动向用户推荐相关物品.常用的推荐算法可以大致分为如下几类:协同过滤推荐算法(Collaborative Filtering,CF)、基于内容的推荐算法(Content-based Recommendation,CB)以及混合推荐算法(Hybird Recommendation).
协同过滤是目前应用最成熟的推荐算法之一,根据用户之间的评分、浏览及购买历史等历史行为比较,为目标用户寻找兴趣或特征相似的用户作为邻居,并为目标用户推荐其可能喜欢的项目.其又可以分为基于用户(User-based CF)和基于项目(Item-based CF)的算法两类.User-based CF算法根据用户对物品的喜欢情况分析用户之间的相似性,然后推荐相似用户喜欢过的物品;Item-based CF算法同理,根据物品被用户的喜欢情况分析物品的相似度,然后向其推荐相似物品.
传统的协同过滤推荐算法主要通过余弦、Pearson等方法来计算用户间的相似度[1],其核心思想是,将不同的项目视为不同的维度通过利用用户-项目评分信息,然后根据用户在相同维度上的评分来计算其相似度.然而用户的评分数据非常稀疏[2],用户之间共同评分的项目因此也更少,使得当根据余弦、Pearson方法来计算用户间的相似度时,不能准确地得到结果,致使推荐系统的性能急剧下降.
因此,本文提出了一种嵌入项目元数据的跨项目协同过滤推荐算法(A Cross-Item Collaborative Filtering Recommendation Algorithm For Embedded Item Metadata),即CICF.将原来基于用户共同评分项目计算相似性,通过嵌入项目元数据(即属性信息),利用用户与项目及其属性的交互,实现了基于元数据表示的跨项目计算相似性.主要做法是,通过挖掘出用户在有限的评分数据上表现出来的项目偏好,利用贝叶斯概率将用户对项目属性的偏爱程度的差值作为项目的相似性度量,最后再利用推土机距离(EMD)代替常规距离实现跨项目的用户相似度计算.缓解了推荐的数据稀疏以及冷启动的问题,更好地支持了具有零或低同时出现的项目推荐.本文的工作也延伸了共现项目的内涵,拓展了共现项目的范围.
本文第2节主要阐述协同过滤推荐算法的相关工作并系统总结了其优缺点;第3节主要介绍嵌入项目元数据的跨项目协同过滤推荐算法;第4节进行详细的实验对比与分析;第5节对研究工作进行了总结与归纳,同时提出了下一步要做的工作.
2 相关工作
为了提高系统推荐精度,国内外研究者展开了一系列的研究,提出了诸多改进的推荐算法.
Zhang等人[3]利用异构网络嵌入和深度学习嵌入方法,从结构知识、文本知识和视觉知识在知识库中自动提取语义表示.Rafailidis等人[4]提出了融合信任关系的协同过滤算法,该算法综合考虑了用户之间的相似关系与信任关系这2方面因素,确保了推荐结果不受恶意推荐的影响.Sar等人[5]提出一个在现有CF算法上(第一层)的两层框架来最优化推荐给用户的列表(第二层),该方法考虑了列表内部项目的相互影响以及项目疲劳、趋势、上下文信息等.郭磊等人[6]提出了一种结合推荐项目之间关联关系的社会化推荐算法,重点研究具有关联关系的推荐项目.Dong等人[7]研究的是异构社交网络中的链路预测和推荐算法,提出了RFG模型,借助用户间交朋友的同一性原理,将RFG模型与网络结构信息相结合,从而向用户推荐相关信息.高等人[8]通过将用户在不同类型上下文中的认知水平、认知有用性、认知风险、有效认知行为等认知领域概念引入到偏好获取过程中,显著提高了偏好获取的准确度.
一些推荐算法采用了不同的相似度度量方法来确定用户之间的相似性[9,10].Vasile等人[11]使用产品嵌入,其将产品映射到一组潜在因素,并计算在该新表示上的相似性.Patra等人[12]提出利用Bhattacharrya相似性度量方法来寻找一对已经被评价过的项目之间的相似性.Li等人[13]考虑了用户的偏好相似性,推荐的信任度以及社会关系来建立新的社会度量公式,以提高推荐精度.Zhang等人[14]考虑到用户在项目类别上的偏好,计算每个项目上不同类别的排名分数来产生推荐.
但以上研究的用户间相似性还是通过共同的评分数据来计算的.本文通过嵌入项目元数据,采用贝叶斯概率来计算项目特征的相似性,并结合EMD方法,将项目属性信息融入到用户的相似度计算中,这种方法改变了传统方法中一对一(即只考虑用户在相同项目上的评分)的相似度计算,实现多对多(即考虑用户在不同项目上的评分)的相似度计算,在一定程度上缓解评分数据稀疏对用户相似度计算的影响.该算法能有效解决目前传统的相似性度量方法存在的问题和不足,提高推荐的准确性.
3 嵌入项目元数据的跨项目协同过滤推荐算法
3.1 传统的相似性度量方法分析
随着信息网络的不断普及,互联网中推荐系统的规模逐渐扩大,用户和商品的数量动辄千百万计,且两个用户间的交叉极少.例如我们研究最平常的MovieLens数据集和Netflix数据集的稀疏度分别是4.5%和1.2%,然而其实这些都是极其密的数据了.下面我们将分析在数据稀疏的情况下,余弦相似性、Jaccard相似性、度量方法相似性还有相关相似性度量方法存在的问题.

这样做虽然提高了计算性能,但是在数据稀疏的情况下,用户只对一小部分数据有评分,而对未评分项目,用户不一定不喜欢,对项目的评分也不一定为0.
在Jaccard相似性度量方法中,仅考虑了项目间的共同评分个数对相似度的影响,而没有考虑项目间的评分差距.我们定义一个用户集合U={uk|k∈M}和一个项目集合I={i|i∈N},N表示项目ID集合,M表示用户ID集合.如果有10个用户对项目i,j共同评分,但每个用户对项目i,j的评分值相差很大,那么这两个项目并不能认为是相似的.只有当两个评分比较接近时,我们才认为这两个项目具有相似性.
在相关相似性度量方法中,根据计算经用户u1与用户u2评分的项目集合的交集来得到用户之间的相似性.然而,用户只有在比较多的项目上评分才比较相似.在用户评分数据极端稀疏的情况下,通常只存在一两个共同评分的项目集合.在这样小的项目集合上计算的两个用户的相似性,存在很大的误差.因此,相关相似性度量方法在用户评分数据极端稀疏的情况下也存在一定的弊端.
3.2 嵌入项目元数据相似度计算
项目元数据是指描述项目的一些基本信息、元素,这里指属性.推荐系统中所涉及到项目的属性信息,比如电影评价网站会将电影分为爱情片、喜剧片、科幻片、惊悚片等,一个项目可能同时具有多个属性.我们通过分析用户对这些项目属性的偏爱程度,能够进一步提高推荐精度.我们将用户的所有评分项目分为喜爱与不喜爱两种,利用贝叶斯概率计算用户喜爱的项目集合中出现某一特征的概率,以及用户不喜爱的项目集合中出现这一特征的概率,以此来计算当项目i出现这一特征时,用户喜爱项目i的概率,最后再将此概率用来计算项目i与项目j的相似度.

(1)

定义项目属性集合A={ap|p∈L},L表示属性ID集合,ap为两个用户所喜欢项目的共同属性.根据贝叶斯概率,则项目集合具有属性ap时,用户uk喜欢的概率为
(2)

由公式(1)可知,项目集合具有属性ap时,用户u1喜欢的概率为
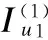

定义D={di,j|i,j∈N}表示用户u2在项目i上的偏好与用户u2在项目j上的偏好之间的距离,那么用户u1在项目i上的偏好与用户u2在项目j上的偏好之间的距离为
(3)
那么最终基于项目的相似度为
Si,j=1-di,j
(4)
di,j越小,说明用户u1对项目i的偏好与用户u2对项目j的偏好程度越一致,即项目i与项目j对于用户u1与用户u2来说相似性就越高.为了更好的理解公式(2)与公式(3),我们可以表示为用户-项目-属性三分图,如图1所示.

图1 用户-项目-属性三分图Fig.1 User-item-attribute tripartite graph

对任意的项目i,如果用户对项目i没有评分,我们使用如下方法预测用户q对项目i的评分:
·利用公式(3)与公式(4)计算项目i与其他项目的相似性.
·将相似度最高的k个项目作为项目i的最近邻居集合IiNB={inb1,inb2,…,inbk},使得i∉IiNB,并且相似性逐渐递减.
·预测用户q对项目i的评分:
(5)
这里的rq,j表示用户q对项目i相似项目j的评分,Si,j表示项目i与项目j的相似性.
通过上述方法处理后,对于任意的项目i,用户q对项目i的评分为
(6)
然后,我们利用嵌入项目元数据来计算用户的相似性.
3.3 基于跨项目的用户相似性计算
用户的相似性计算,这里我们使用推土机距离(earth mover′s distance,简称EMD)方法,这种方法主要用来衡量签名(分布、特征量集合)之间的不相似性[15],和欧式距离一样,它们都是一种距离量的定义,可以测量某两个分布之间的距离.这里我们将EMD方法与推荐系统相结合,改变了传统协同过滤推荐系统中只针对相同评分项目进行用户相似度计算.传统的协同过滤推荐的用户相似度计算利用余弦、Pearson 等用户相似度计算方法基于用户在相同评分项目上的偏好进行计算,忽略了项目与项目之间的关联.在数据极其稀疏的情况下,用户很可能没有共同评分项目,便很难计算出用户之间的相似度.在本文中,我们根据计算出的相似项目,用户在相似项目上的评分也能表现出用户之间的相似性.
我们首先定义一个偏好流量F={fi,j},其中fi,j表示用户u1在项目i和用户u2在项目j之间的偏好转移量,这时候最小化总的转移代价W:
W=∑i∈Iu1∑j∈Iu2fi,jdi,j→min
(7)
偏好转移量必须满足以下的线性约束:
fi,j≥0,i,j∈N
(8)
∑j∈Iu2fi,j≤ω(θu1,i),i∈Iu1
(9)
∑i∈Iu1fi,j≤ω(θu2,j),j∈Iu2
(10)
∑i∈Iu1∑j∈Iu2fi,j=min(wu1,wu2)
(11)
这里wu1、wu2分别表示用户u1、u2对项目i、j的偏好总和,即wu1=∑i∈Iu1ω(θu1,i) ,wu2=∑j∈Iu2ω(θu2,j) ,其中ω(θu1,i)、ω(θu2,j)由公式(1)计算得到.Iu1、Iu2分别表示用户u1、u2评分的项目集合.di,j表示为用户u1在项目i上的偏好与用户u2在项目j上的偏好之间的距离,由公式(3)计算得到.公式(8)表示用户能够选择性的转移偏好.公式(9)和公式(10)表示用户u1(u2)在项目上i(j)能提供的偏好转移总量不能超过用户u1(u2)对项目上i(j)的偏好.公式(11)表示用户u1与u2在所有项目上的偏好转移总量.

(12)
如图1中,用户u1与用户u2只有共同评分项目i2,使用余弦或者Person方法计算用户相似度只能基于共同的评分项目i2上,并不能很好的反应用户的偏好.而EMD方法具有跨项目特性,能够利用项目元数据将共同项目外的其他评分项目融入到相似度计算中.
由EMD定义及公式(12)可知,用户u1与用户u2的相似度为
sim(u1,u2)=1-EMD(u1,u2)
(13)
3.4 产生推荐
传统的基于用户的协同过滤算法通常使用阈值或top-N等方法来选择最相似的用户作为最近邻居集合.本文通过提出的嵌入项目元数据的跨项目相似性度量方法,得到待预测用户的最近邻居集合,然后对用户产生相应的推荐列表.定义用户u的最近邻居集合为UuNB,则用户u对项目i的预测评分Ru,i的计算方法如下:
(14)

3.5 算法描述
综合3.1~3.4节中的计算步骤,可以得到嵌入项目元数据的跨项目协同过滤推荐算法如下:
输入:用户-项目的评分矩阵以及项目-属性列表.
输出:用户的推荐项目列表.
Begin
1)Foreach
2)CalculateSi,j
4)Endfor
5)Foreach
6)Calculatesim(ua,uk)
7)Endfor
8)PredictRu,i
9)构造推荐列表,根据用户对未评价项目的预测评分Ru,i,选择预测值的前top-N项目推荐给用户
End
3.6 算法复杂度分析
整个算法分为嵌入项目元数据相似度计算,基于跨项目的用户相似性计算以及预测计算三个部分.假设用户数目为M,项目集合数量为N.其中相似度计算的复杂度是O(MN),预测部分的计算复杂度是O(MN).EMD距离计算复杂度主要表现在求解优化公式的Orlin算法上,算法复杂度为O(M3logM).在文献[17]中,通过小波变换将EMD距离计算复杂度降为线性,可以通过得到近似EMD距离的值来进一步降低复杂度.
4 实验结果及分析
4.1 数据集
本文的实验数据采用了Movie Lens数据集[18].该数据集被广泛应用于推荐系统的文献,包括四个增加大小的数据集.实验中选取了该数据集的约10万条评分记录,包括850个用户关于1529部电影的打分记录,大小为100k,稀疏度为93.7%.
为了验证推荐算法的准确性,将实验数据的评分矩阵进一步划分为训练集和测试集,训练集数据用来学习或训练推荐方法中的相关参数,测试集数据用来验证推荐算法的准确性.为了保证实验的准确性,我们采用交叉验证(Cross-Validation)进行算法性能的评估.本文采用5折交叉验证,取5次结果的均值作为算法的性能度量.
4.2 推荐质量的度量标准
本实验采用平均绝对误差MAE(Mean Absolute Error)作为度量标准.MAE衡量预测准确性的标准是计算预测评分与实际评分之间的偏差值.MAE越小,算法的推荐结果越准确.
现在给出如下定义:用户预测评分集合为{p1,p2,…,pm},用户实际评分集合为{q1,q2,…,qm},m表示预测的次数,则MAE的计算公式如下:
4.3 实验结果与分析
本文设计了三组实验,分别从与传统相似度方法比较、基于相似项目的评分预测以及数据稀疏度比较这三个方面来探索CICF方法的推荐算法的性能.
实验1.不同相似度算法的比较
该实验主要比较本文提出的CICF方法与余弦、PMFUI[6]、BCF[12]方法的评分预测准确度.PMFUI方法重点关注推荐项目间的关联关系,其认为用户应该更关注具有关联关系的推荐项目,提出利用此关系提高推荐效果.BCF是一个基于邻居的协同过滤方法,主要利用Bhattacharrya相似性度量来发现一个积极用户的邻居.实验结果如图2所示.
图2中,横坐标表示不同数量的最近邻居,分别取K=10,15,20,25,30,纵坐标表示MAE值.由图可以看出,随着最近邻居数的增加,MAE值逐渐变小.与此同时,我们可以发现本文提出的CICF方法的MAE值明显小于余弦、BCF和PM-FUI方法,这意味着CICF方法的推荐精度优于其它两种方法.这是因为CICF方法在计算用户相似度时充分考虑了项目之间的相似度,能够通过项目属性实现跨项目推荐,充分利用了共同评分项目以外的其它评分项目,可以更加准确的计算出用户之间的相似度,从而提高了预测的准确度.
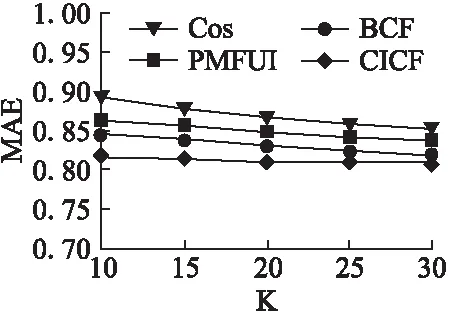
图2 不同推荐算法计算的MAE比较Fig.2 MAE comparison of different recommendation algorithms
实验2.基于相似项目的评分预测
该实验将余弦、BCF、PMFUI方法使用本文提出的基于相似项目的评分预测公式与CICF方法做预测准确度比较.选择相似项目时,我们将从邻居用户的评价项目中选择与待预测项目的相似度不低于0.8的项目作为相似项目以确保相似项目与待预测项目的相关性.试验结果如图3所示.此外,为了验证基于相似项目的评分预测公式与基于传统的评分预测公式的准确度,我们取K=10做了图4所示的对比.

图3 不同相似度算法基于相似项目的MAE比较Fig.3 MAE comparison of different similarity algorithms based on similar items

图4 两种评分预测公式的对比Fig.4 Comparison of two different rating prediction
由图3和图4可以看出,不管是基于传统的评分预测公式还是基于相似项目的评分预测公式,CICF方法总是优于余弦、BCF和PMFUI方法.与此同时,我们还可以发现,基于相似项目的评分预测要优于传统的评分预测公式.这是因为基于相似项目的评分预测公式充分考虑了相似项目对评分预测的影响.当最近邻居集合中没有对待预测项目进行评分时,传统的评分预测公式则认为该邻居用户对预测项目没有影响,降低的预测的准确度.因此,基于相似项目的评分预测更有效.
实验3.数据稀疏度对相似度算法的影响
该实验主要通过改变训练集与测试集数据占评分数据的比例,观察在不同稀疏性情况下的推荐精度.该实验分别选取20%、40%、60%以及80%的评分数据作为训练集,相应的80%、60%、40%以及20%的评分数据作为测试集,最近邻居数取K=10.实验结果如图5所示.

图5 不同稀疏性比较Fig.5 Comparison of different sparseness
图5中,横坐标表示为训练数据所占的百分比,及不同稀疏度的数据集,纵坐标表示MAE值.由图可知,当训练数据集所占比例不断提高,这几种算法的推荐效果也在不断变好.图中PMFUI方法的效果要比余弦方法好,而CICF方法比余弦和PMFUI方法更准确.并且在评分预测公式中,使用基于相似项目的各个算法要比只使用传统的评分预测公式更加准确.另外,在评分数据稀疏的情况下,基于相似项目的评分预测方法更加有效,并且CICF方法能够达到较好的评分预测精度.这是因为,在评分数据稀疏的情况下,用户之间的共同评分项目减小,CICF方法在计算用户相似度时充分考虑了项目之间的相似度,能够通过项目属性实现跨项目推荐,充分利用了共同评分项目以外的其它评分项目,可以更加准确的计算出用户之间的相似度,从而提高了预测的准确度.
5 总 结
本文提出了一种嵌入项目元数据的跨项目协同过滤推荐算法.这是对传统的协同过滤推荐算法中只能根据用户在相同项目上的评分来进行推荐的改进.本文通过嵌入项目元数据,首先挖掘出用户在有限的评分数据上表现出来的项目偏好,利用贝叶斯概率将用户对项目属性的偏爱程度的差值作为项目的相似性度量,最后再利用推土机距离代替常规距离实现跨项目的用户相似度计算.在进行评分预测时,将相似项目融入到评分预测公式中,能更有效的提高预测精度.一系列的实验证明,本文提出的算法与其它算法相比能进一步提高推荐效果.在未来的工作中,我们将进一步对算法优化改进,考虑如何将文本内容与视觉内容融合到本文提出的算法中,以便进一步改善推荐的效果.
[1] Wang L,Meng X,Zhang Y.A heuristic approach to social network-based and context-aware mobile services recommendation[J].Journal of Convergence Information Technology,2011,6(10):339-346.
[2] Abbas A,Zhang L,Khan S U.A survey on context-aware recommender systems based on computational intelligence techniques[J].Computing,2015,97(7):1-24.
[3] Zhang F,Yuan N J,Lian D,et al.Collaborative knowledge base embedding for recommender systems[C].ACM SIGKDD International Conference,ACM,2016:353-362.
[4] Rafailidis D,Crestani F.Collaborative ranking with social relationships for Top-N recommendations[C].ACM SIGIR Conference on Research and Development in Information Retrieval,ACM,2016:785-788.
[5] Sar Shalom O,Koenigstein N,Paquet U,et al.Beyond collaborative filtering: the list recommendation problem[C].International Conference on World Wide Web.International World Wide Web Conferences Steering Committee,2016:63-72.
[6] Guo Lei,Ma Jun,Chen Zhu-min,et al.Incorporating item relations for social recommendation[J].Chinese Journal of Computers,2014,37(1):219-228.
[7] Dong Y X,Tang J,Wu S,et al.Link prediction and recommendation across heterogeneous social networks[C].Proceedings of the ICMD.Washington: IEEE Computer Society,2012:181-190.
[8] Gao Quan-li,Gao Ling,Yang Jian-feng,et al.A preference elicitation method based on Users′ cognitive behavior for context-aware recommender system[J].Chinese Journal of Computers,2015,38(9):1767-1776.
[9] Bobadilla J,Ortega F,Hernando A.A collaborative filtering similarity measure based on singularities[J].Information Processing & Management,2012,48(2):204-217.
[10] Hu Y C.Recommendation using neighborhood methods with preference-relation-based similarity[J].Information Sciences,2014,284(6):18-30.
[11] Vasile F,Smirnova E,Conneau A.Meta-Prod2Vec:product embed
dings using side-information for recommendation[C].ACM Conference on Recommender Systems,ACM,2016:225-232.
[12] Patra B K,Launonen R,Ollikainen V,et al.A new similarity measure using Bhattacharyya coefficient for collaborative filtering in sparse data[J].Knowledge-Based Systems,2015,82(2):163-177.
[13] Li Y M,Wu C T,Lai C Y.A social recommender mechanism for e-commerce: Combining similarity,trust,and relationship[J].Decision Support Systems,2013,55(3):740-752.
[14] Zhang L,Xu J,Li C.A random-walk based recommendation algorithm considering item categories[J].Neurocomputing,2013,120(10):391-396.
[15] Pele O,Werman M.Fast and robust earth Mover′s distances[C].In:Proc.of the Int′l Conf.on Computer Vision,Piscataway: IEEE Computer Society,2009:460-467.
[16] Korte B H,Vygen J.Combinatorial optimization: theory and algorithms[M].Springer Publishing Company,2007.
[17] Applegate D,Dasu T,Krishnan S,et al.Unsupervised clustering of multidimensional distributions using earth mover distance[C].ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Diego,Ca,Usa,August.DBLP,2011:636-644.
[18] Harper F M,Konstan J A.The movie lens datasets: history and context[M].ACM,2015.
附中文参考文献:
[6] 郭 磊,马 军,陈竹敏,等.一种结合推荐对象间关联关系的社会化推荐算法[J].计算机学报,2014,37(1):219-228.
[8] 高全力,高 岭,杨建锋,等.上下文感知推荐系统中基于用户认知行为的偏好获取方法[J].计算机学报,2015,38(9):1767-1776.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
河北画报(2020年8期)2020-10-27
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
中学生数理化(高中版.高一使用)(2018年6期)2018-07-09
雪莲(2017年2期)2017-05-12
