
云环境下基于任务执行行为感知的可信资源调度算法
2018-04-13 10:03王福成王必晴
小型微型计算机系统 2018年4期
齐 平,王福成,王必晴
1(铜陵学院 数学与计算机科学系,安徽 铜陵 244000) 2(合肥工业大学 管理学院,合肥 230039) E-mail:qiping929@gmail.com
1 引 言
云计算以网络化的方式聚合计算与通信资源,同时使用虚拟化技术将大量成本较低、计算能力较弱的计算实例整合为一个具有强大计算能力的资源共享池,为用户提供可以缩减或扩展规模的计算资源[1,2].由于云计算系统资源由广域分布的异构资源构成,且各类资源动态加入和退出云系统具有随机性,因此如何实现计算资源的有效配置和共享使用是云计算领域研究必须解决的关键问题之一[3].目前,关于云环境下的资源管理策略已有了较多研究,针对不同的计算任务和优化目标,云资源调度算法大致可以划分为以下几类:①考虑资源负载均衡、提高资源利用率[4,5];②满足任务执行时间[6]、能耗费用[7,8]、用户QoS[9,10]等约束条件;③基于需求预测的虚拟机资源按需分配策略[11,12];④多目标优化算法[13,14].
云资源的可靠性可定义为在规定时间和规定条件下完成规定任务的能力或概率[15].由于云计算系统是一个大规模复杂系统,而云计算的核心思想是硬件、软件资源的服务化,因此云服务商需要通过虚拟化软件将物理机虚拟化为多台具有不同服务属性的虚拟机,再以虚拟机为基本单位提供计算能力.在此过程中,物理机内部元件故障或链路故障等因素都可能使放置于其上的虚拟机不能正常工作,从而导致用户任务无法完成.因此,在拥有无数资源节点的云环境中,如何获取可信的云资源,并将云任务分配到值得信任的资源节点上执行就显得异常重要,而传统的云资源调度算法往往只考虑用户任务的单一服务质量需求,或多个服务质量需求的组合优化问题,并未深入考虑资源节点的可信需求问题.
近年来,在国内外分布式系统资源管理的相关研究中,有关如何获取可信云资源的研究已经取得了不少成果.然而,云应用对资源需求的多样性、动态性和灵活性给云资源管理带来了新的挑战.
首先,可靠性驱动的云资源调度算法通过各类可靠性模型的构建,对云环境下资源节点的可信度进行度量.然而,已有可靠性度量模型并未充分考虑云计算环境下资源节点的异构性、动态性和广域性等特点,缺乏对任务在资源节点上执行可靠性以及数据在通信链路上传输可靠性的综合分析.
其次,现有可靠性驱动的云资源调度模型大多采用基于静态或动态队列的资源调度模型,即表调度算法,可表述为基于贪心策略的可信资源需求与虚拟机资源供给的最优匹配问题,仅能适用于求解固定目标的局部最优解,而难以统筹考虑并行任务的整体可靠性需求,也难以描述云任务对物理机资源的使用偏好问题.
针对上述问题和并行任务图的特点,本文的主要贡献有:
1) 根据并行任务及胖树形云系统的结构特点,综合考虑云计算环境下资源节点与通信链路的可靠性问题,在此基础上提出基于任务执行行为的云系统可靠性度量模型;
2) 针对表调度算法表达能力的局限性,本文设计了基于遗传智能的可信云资源调度算法.该算法通过熵值法综合可靠性需求与服务质量需求,不仅能够有效提高云任务执行的整体可靠性,还兼顾了云任务的数据本地性问题,有效降低云任务的平均调度长度.
2 相关工作
云资源的信任管理和可信调度问题,目前已得到国内外学者的大量研究,其核心思想是通过构建各类信任评价模型,为应用任务选择高可信度的虚拟机资源,从而避开虚拟机的易失效时段进行使用.
Wang等[16]借鉴社会学中的人际关系网络,通过分析节点间的历史交互数据,利用Bayes方法对节点的可信度进行评估,构建基于信任机制的可信调度模型;Cao[17,18]以人际关系信任模型为基础,提出一种基于直接信任度、推荐信任度和第三方服务性能反馈的可信度量模型,该模型通过基于熵权的主客观赋权法将各评价指标综合起来,选择可信动态级最大的计算资源执行云任务;文献[19]通过云模型刻画云资源节点的信任变化,提出基于云模型的主观信任评价方法;Tang[20]、Luo[21]针对信任评估的不确定性以及可能存在的样本不足的问题,分别提出了基于模糊逻辑和基于置信度的主观信任管理模型;Deng等[22]提出了一种可信优化的资源调度算法,构建基于身份可信、能力可信、行为可信的综合信任模型.Abawajy等[23]提出了一种云计算环境下基于可信评估的信誉系统,使得交互能够在相互信任的基础上完成;Raghebi等[24]则通过用户任务反馈机制,在用户历史反馈数据的基础上构建云服务信任评估模型;Li等[25]引入粗糙集理论和诱导有序加权平均算子评估云服务的性能,提出一种自适应的信任管理模型;Fan等[26]考虑信任评估的不同侧面,将各类信任评估模型通过模糊逻辑以及证据推理方法进行综合,构造基于模糊推理系统的云服务信任评估模型.
上述文献从不同角度构建了各类信任评估模型来满足云任务对服务资源的可信需求.然而,以上算法往往只分析了任务在云资源上执行的可靠性及其失效规律,或是通过任务执行行为分析了数据在通信链路上通信的可靠性,并未综合分析两种可靠性及其相互关系.此外,以上文献多采用队列进行资源调度建模,使用贪心策略为用户任务匹配当前可信度最高的虚拟机资源,因而该类算法仅能找到当前的局部最优解而难以统筹全局,且调度目标单一,不易根据实际需求而灵活变化.
3 问题建模
云资源调度问题可描述为云计算环境下用户任务需求与云资源供给的最优匹配问题,由云环境下n个虚拟机资源与m个用户任务组成.考虑云任务之间可能具有数据先后依赖关系或优先约束,且云资源节点之间的连接方式复杂多样,本文采用有向无环图(Directed Acyclic Graph,DAG)描述云计算环境下具有相互依赖关系和数据交换的并行任务,采用胖树型结构描述云资源节点的系统构成,分别定义如下:
定义1.(并行任务DAG模型) 考虑云任务之间的优先约束关系,本文将云计算环境下的并行任务描述为一个DAG图,可用四元组表示,即DAG=(T,E,W,Tp).其中T={t1,t2,…,tm},表示m个云任务的集合;E={eij|ti,tj∈T}⊆T×T,表示云任务之间的相互依赖关系,即任务ti为任务tj的前驱,当所有前驱任务执行完成后,任务tj才能执行;W={w1,w2,…,wm},表示云任务的计算量集合;Tp={ti|indegree(ti)=0,1≤i≤m},表示当前可并行任务,即入度为0的云任务集合,同时设定云任务DAG图的入口节点和出口节点都为1.
定义2.(云资源系统) 考虑云计算环境下资源节点之间的相互连接方式多种多样,本文使用胖树型拓扑结构对云数据中心网络进行描述,可用五元组表示,即Cloud=(V,C,B,H,R),其中V={v1,v2,…,vn},表示云环境下n个虚拟机资源节点的集合;C={cij|vi,vj∈V}⊆V×V,表示虚拟机资源节点之间的通信链路集合;B={bij|vi,vj∈V,cij∈C},表示通信链路cij=(vi,vj)的平均带宽;H={hij|vi,vj∈V,cij∈C},表示通信链路cij的历史交互数据;R={r1,r2,…,ri},表示云环境下i个物理机资源的集合.
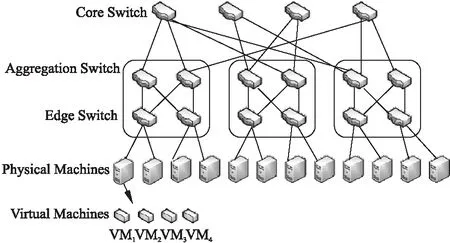
图1 云数据中心结构Fig.1 Cloud data center framework
如图1所示的三层胖树型结构,由上而下分别为核心层、汇聚层和接入层,物理机通过接入层路由器接入网络、共享资源,而核心层路由器则是数据中心对外交换数据的必经桥梁,需要传递来自更多物理机的大量数据,其带宽决定了能够通过该数据中心的最大任务数.
4 基于任务执行行为感知的云系统可靠性度量模型
本节对可靠性需求、服务质量需求分别进行建模描述,构建基于任务执行行为感知的可靠性度量模型.
4.1 可靠性需求
将云任务ti∈T调度到虚拟机资源vdst上,且成功执行的条件是:
1) 任务tj所依赖的数据成功传输到虚拟机vdst上,即将任务tj所需数据从源虚拟机资源vsrc成功传输到目标虚拟机资源vdst上,需要保障通信链路的可靠性;
2) 任务tj在虚拟机vdst上执行时不能发生失效,即保障虚拟机执行任务的可靠性.
因此本文构建云系统可靠性度量模型,将云系统可靠性Φ划分为云资源节点可信度ΦNode和通信链路可信度ΦPath,按照式(1)进行综合,其中f(.)为可信度综合函数,满足凸函数的性质,由云任务对两类云系统资源的可靠性需求程度决定.
Φ=f(ΦNode,ΦPath)
(1)
4.1.1 云资源节点可信度度量
假设云资源节点执行任务只存在成功和失效两种状态.已有研究[23,30,31]通过对云计算系统失效日志进行统计分析发现,云资源节点失效表现出很强的时间、空间分布规律.
时间分布规律可表述为:如将物理机失效的间隔时间视为随机过程,则该过程服从形状参数k<1,尺度参数λ>0的Weibull分布.当云资源节点刚启动时,其可靠性较低,随着运行时间的逐步增加,可靠性也相应提高,而当执行时间超过某阈值后,该资源节点可靠性则越来越低,直至发生不可恢复失效.
设Weibull分布形状参数为k,尺度参数为λ,则其概率密度函数和累积分布函数分别如式(2)和式(3)所示.
(2)
cdf(x)=1-e-(x/λ)k
(3)
失效率函数表示当前未发生失效,而未来即将发生失效的概率.由式(2)和式(3)可得云系统中资源节点的Weibull分布失效率函数h(x),如式(4)所示:
(4)
失效概率越大则机器发生失效的可能性越高,因此定义云资源节点执行任务的可信度ΦNode如式(5)所示:
(5)
空间分布规律可表述为:物理机失效事件具有空间上的规律性,即大部分失效发生在少部分物理机上,而刚失效的资源节点由于比较脆弱,较易于再次发生失效.因此,针对物理机失效的空间分布规律,对于失效刚恢复的资源节点,本文选择将其搁置时间一定时间再加入空闲资源池以供调度使用,设置搁置时间为δ.
4.1.2 通信链路可信度度量
将任务tj调度到目标虚拟机资源vdst上执行前,需要将其前驱任务的相关数据由源虚拟机vsrc通过通信链路c(src,dst)传输到目标虚拟机vdst上.本文通过分析云资源节点之间的历史交互数据,使用证据理论和Bayes方法度量通信链路c(src,dst)的可信度ΦPath.
设云计算环境下存在2个资源节点x和y,使用二项事件(成功/失败)描述其数据传输结果,当节点x和y发生n次交互后,其中成功次数为u,失败次数为v,则将其间通信链路c(x,y)的可信度ΦPath定义为第n+1次交互成功的概率.由于资源节点x和y之间交互成功的后验概率服从Beta分布,如将单次节点交互过程中交互成功的先验概率设为随机变量θ,假定θ服从均匀分布U(0,1),则其后验概率密度函数如式(6)所示:
(6)
通信链路可信度ΦPath定义为通信链路c(src,dst)在网络中提供可靠通信的能力,是对未来交互成功概率的预测,即交互经验分布的期望值,如式(7)所示:
(7)
当云资源节点之间不存在历史交互或交互数据较少不足以进行评估时,引入中间推荐节点计算链路可信度.设云资源节点x和z,y和z交互独立,交互次数分别为n1、n2,其中交互成功、失败次数分别为(u1,v1)和(u2,v2),则其通信链路c(x,y)的可信度ΦPath定义为:
(8)
4.2 服务质量需求
为简化模型,本文考虑服务质量属性为任务响应时间,实际应用中可按需求进行扩展.
任务响应时间(ResponseTime,RT)包括云资源节点之间进行数据传输的通信时间和云任务的执行时间.由于云系统中资源节点在不同供应电压下的计算速度不同,且资源节点之间的通信带宽往往随时间动态变化,因而定义云任务的执行时间为计算资源在最大供应电压下执行云任务所需的时间,定义通信时间为以资源节点间的平均带宽进行数据传输所需的时间.
在实际应用中,由于各项服务质量属性的量纲、数量级都不相同,因而需要对初始数据按照式(9)做无量纲标准化处理,将其转化至[0,1]范围内,其中max(xi)和min(xi)分别表示第i项服务质量属性的最大值和最小值.
(9)
4.3 组合调度目标
本文考虑的调度指标包括可靠性(Reliability)和任务响应时间(Responsetime),定义组合调度目标如式(10)所示:
(10)
其中WReliability、WRT分别表示可靠性、任务响应时间的权重,该权重通过熵值法[27]根据各项指标所含信息有序度的差异,即信息的效用价值确定.云系统可靠性在代入计算前需按式(11)做无量纲标准化处理,将其转化至[0,1]范围内.
(11)
5 基于任务执行行为的可信云资源调度算法
5.1 并行任务调度描述
云计算环境下的并行任务调度是在充分考虑任务之间的相互依赖关系的基础上,将云任务分配到各虚拟机资源上协同执行的过程.如在并行任务DAG图中,任务之间存在数据的依赖关系,其中任务t1为任务t2和t3的后续任务,不妨设任务t1调度到虚拟机资源vi上执行,而任务t2和t3分别调度到虚拟机资源vj和vk上执行,则任务t1和t2、t3之间的数据传递应通过虚拟机资源vi和vj、vk之间的通信链路进行,若虚拟机资源vi和vj处于同一物理机,则通信时间可忽略不计.
由此,如式(12)所示,可将并行任务调度问题描述如下:
1)后续任务tj在虚拟机资源vt上的开始执行时间Tstart(tj,vt)应大于其所有前驱任务的最迟执行完成时间Tpred-exec(tj)与前驱任务的最大数据传递时间Tpred-comm(tj)之和;
2)同一虚拟机资源上同一时间只能执行一个任务;
3)最大化组合调度目标,即提高任务执行的整体可靠性,降低任务调度长度.
(12)
5.2 遗传算法设计
5.2.1 染色体编码
染色体编码有多种方式,本文设计遗传算法采用资源—任务的间接编码方式,即染色体由资源串与任务串两部分组成.其中,任务串为满足任务之间优先关系的拓扑序列,资源串为执行各任务的虚拟机资源标号.不妨设染色体为{t1,t2,…,tm|v1,v2,…,vn},则t1,t2,…,tm为满足优先约束的并行任务拓扑序列,v1,v2,…,vn为执行任务的相应虚拟机资源标号.
通过分析可知,当并行任务数量大于虚拟机资源数,即m>n时,序列v1,v2,…,vn中存在相同资源,即将不同任务先后调度到同一虚拟机资源上执行;反之,即m 5.2.2 适应度函数 遗传算法通过适应度函数的计算来完成下一代的选择进化,本文所述并行任务的组合调度目标是在满足任务执行优先顺序的前提下,最大化任务执行的可靠性需求,最小化任务调度长度.因此对于有效染色体X,定义适应度函数为: (13) 5.2.3 选择操作 选择操作是对个体适应性的评价方式,利用选择操作可将当前群体中的优良基因复制到下一代群体.本文采用比例选择操作,即个体被选择的概率由个体的适应度大小决定,即Psel(Xi)=f(Xi)/∑f(X). 5.2.4 交叉操作 由于本文构造的染色体由任务串和资源串组成,因此交叉操作也分别由任务串交叉操作与资源串交叉操作组成.任务串的交叉操作具体方法为:对于一对染色体X1、X2,其任务串分别为X1task和X2task,随机产生同一位置的断点,将X1task的左半部分作为其后代第1部分,将X2task的右半部分作为后代的第2部分;资源串的交叉操作具体方法为:对于一对染色体X1、X2,其资源串分别为X1VM和X2VM,随机产生同一位置的断点,将断点右半部分进行交换. 5.2.5 变异操作 变异操作是在当前群体中按照一定概率产生新的个体.如上文所述,变异操作也由任务串变异操作和资源串变异操作组成,其具体方法为在任务串和资源串中分别选择一位进行突变. 算法1.任务执行行为感知的遗传调度算法EBAGS()输入: 并行任务T={t1,t2,…,tm},云虚拟机资源V={v1,v2,…,vn}输出:任务—资源分配序列,任务调度长度,任务执行成功率1生成初始种群X0={t10,t20,…,tm0|v10,v20,…,vn0}2分别计算云资源节点可信度与通信链路可信度;3设迭代次数t=04IF(t<最大迭代次数||满足适应度阈值;t++)5 {选择操作,选择与复制概率为Ps;6 交叉操作,交叉概率为Pc;7 变异操作,变异概率为Pm;8 计算当前种群适应度;}9由染色体解码调度方案;10计算任务调度长度与任务执行成功率 为验证和评价提出的基于任务执行行为感知的可信云资源调度算法性能,本文对开源云仿真软件CloudSim3.0[28]进行扩展,构建云仿真实验平台.CloudSim是基于Java的离散事件模拟工具包,能够对物理主机、虚拟机资源、云服务和虚拟化云数据中心进行仿真,其资源分配层提供了可扩展接口,支持云计算的资源管理和调度模拟.在CloudSim中,云数据中心由大量物理主机构成,而每个物理主机都可虚拟化为多台虚拟机资源,云数据中心根据预置的分配参数与策略为虚拟机分配物理资源(包括CPU、内存、带宽等),之后由虚拟机根据用户定义的调度策略执行云任务. 实验参数设置如下:本文构建了胖树型数据中心网络,接入层、汇聚层和核心层路由器数及转发延迟预先给定,设定每台物理机最多可虚拟化为4台虚拟机资源,通信链路传输速度介于2Mbit/s ~10Mbit/s.并行任务DAG图由并行仿真任务自动生成软件随机生成,设定云任务在云资源上的执行时间介于10s~50s;云任务类型以及任务间传输的数据量根据其通信计算比率CCR(Communication to Computation Ratio,CCR)决定,CCR为并行任务DAG图中所有任务间通信量与所有任务计算量的比值,CCR>1表示云任务为通信密集型任务,反之则为计算密集型任务;根据大规模云计算实验床的系统失效日志分析,设置资源节点执行任务时节点失效事件服从Weibull分布,其形状参数k为0.75,尺度参数为λ为60,设定刚失效资源近期再次发生失效的频率在1~3之间满足均匀分布.在所有仿真实验中,对于上述每一组随机产生的参数集,实验结果采用10次实验的平均值. 本文选择可靠性综合函数f(ΦNode,ΦPath)为线性函数:Φ=αΦNode+(1-α)ΦPath,其中ΦNode和ΦPath代入计算前先进行归一化处理,α为可靠性需求因子,反映了云任务对云资源节点以及通信链路的可靠性需求程度,且α∈(0,1).本项实验讨论可靠性需求因子α对任务执行成功率的影响. 本组实验对算法在不同可靠性需求因子下的任务平均执行成功率进行比较,实验相关参数设置如下:随机生成云任务数为100的应用程序任务图,服务资源数为200,链路数为400.本组实验中,可靠性需求因子α的取值分别为:0、0.3、0.7和1,当α=0时,可靠性综合函数f(ΦNode,ΦPath)=ΦPath,即只考虑通信链路的可信度;当α=1时,可靠性综合函数f(ΦNode,ΦPath)=ΦNode,只考虑云资源节点的可信度. 图2 可靠性需求因子对任务平均执行成功率的影响Fig.2 Effect of reliability requirement factor to average ratio of successful execution 实验结果如图2所示,由图可见,对于不同类型任务,当只考虑通信链路的可信度或只考虑云资源节点的可信度时,任务平均执行成功率均较低,而综合考虑两方面影响因素时,任务平均执行成功率得到显著地提高;与此同时,对于CCR<1的计算密集型任务,α=0.3时的任务平均执行成功率明显低于α=0.7时的任务平均执行成功率,而对于CCR>1的通信密集型任务,实验结果则相反.实验说明,对于不同类型的云任务应根据其通信计算比率选择适当的可靠性需求因子,同时也体现了本文提出云系统可靠性度量模型的有效性. 为验证本文提出基于任务执行行为感知的遗传调度算法性能,在不同任务数量的情况下,比较经典表调度算法HEFT算法[29]、CTDLS算法[17]和本文算法在任务平均执行成功率,平均调度长度两方面的性能.实验参数设置如下:CCR=1,可靠性需求因子α为0.5,服务资源数为200,链路数为400,随机生成云任务数为50~140的应用程序任务图. 实验结果如图3,图4所示.由图3可见,随着任务数量的增加,三种算法的任务平均执行成功率均有降低,其中EBAGS的执行成功率高于CTDLS,同时远高于HEFT,充分体现了本文提出算法对并行任务整体执行成功率的提升. 从图4可见,EBAGS和CTDLS的平均调度长度均低于HEFT.这是由于HEFT虽然尽可能将任务调度到具有最早完成时间的资源上执行,然而HEFT并未考虑云任务的可信需求,任务执行失效增加了任务被重新调度的次数.与此同时,EBAGS充分考虑了云任务的可信需求与服务质量需求,在构建基于遗传智能的全局调度优化基础上,还通过数据本地性设置(即当待调度虚拟机处于同一物理机时,其通信时间忽略不计),将任务尽可能调度到该任务所依赖的数据所放置的物理机上执行,缩短了任务通信时间,有效地降低了任务的平均调度长度. 图3 三种算法在不同任务数下的任务执行成功率比较Fig.3 Comparison ratio of successful execution of three algorithms under varying number of tasks 图4 三种算法在不同任务数下的平均调度长度比较Fig.4 Comparison ratio of scheduling length of three algorithms under varying number of tasks 本组实验在不同任务类型的情况下,比较HEFT算法、CTDLS算法和EBAGS算法在任务平均执行成功率,平均调度长度两方面的性能.实验相关参数设置如下:随机生成任务数为100的应用程序任务图,服务资源数为200,链路数为400,设置云任务CCR值分别为0.1、1、10,相应设定EBAGS算法的可靠性需求因子分别为0.7、0.5、0.3. 实验结果如图5、图6所示,对于不同类型任务,EBAGS的任务平均执行成功率总是高于CTDLS和HEFT,而EBAGS的平均调度长度低于其他2个算法,从另一侧面说明了本文提出云资源调度算法的有效性. 云计算环境下任务执行的可靠性是当前云资源调度算法的研究热点.针对现有以队列方式进行建模的可信云资源调度模型的局限性,本文首先构建了基于任务执行行为的云系统可靠性度量模型,该模型根据并行任务及胖树形云系统的结构特点,以及资源节点失效规律分析,综合考虑了云计算环境下资源节点与通信链路的可靠性问题;其次,设计了基于遗传智能的可信云资源调度算法,该算法将云任务的资源需求与云资源的动态供给的最优匹配问题转换为考虑整体可靠性的全局最优化问题,同时考虑了云任务的服务质量需求与数据本地性需求,为用户任务选择可信资源提供了切实可行的办法.本文的下一步工作将进一步考虑如何根据云计算环境的动态变化自适应调整资源节点可信度与通信链路可信度的权值. 图5 三种算法在不同任务类型下的任务执行成功率比较Fig.5 Comparison ratio of successful execution of three algorithms under varying kinds of tasks 图6 三种算法在不同任务类型下的平均调度长度比较Fig.6 Comparison ratio of scheduling length of three algorithms under varying kinds of tasks [1] Rochwerger B,Breitgand D,Levy E,et al.The reservoir model and architecture for open federated cloud computing[J].IBM Journal of Research and Development,2009,53(4):1-17. [2] DanielNurmi,Rich Wolski,Chris Grzegorczyk,et al.The eucalyptus open-source cloud-computing system[C].Proceedings of the 2009 9thIEEE/ACM International Symposium on Cluster Computing and the Grid,2009:124-131. [3] Buyya R,Yeo C,Venugopal S,et al.Cloud computing and emerging IT platforms:Vision,hype and reality for delivering computing as the 5thutility[J].Future Generation Computer Systems,2009,25(6):599-616. [4] Cao Jie,Zeng Guo-sun,Kuang Gui-juan,et al.An on-demand physical resource allocation method for cloud virtual machine to support random service requests[J].Journal of Software,2017,28(2):457-472. [5] Xu Li,Zeng Zhi-bin,Yao Chuan.Study on virtual resource allocation optimization in cloud computing environment[J].Journal on Communications,2012,33(1):9-16. [6] Darbha S,Agrawal D.Optimal scheduling algorithm for distributed memory machines[J].IEEE Transactions on Parallel and Distributed Systems,2012,9(1):87-95. [7] Zhu Da-kai,D Mosse,R Melhem.Power-aware scheduling for and/or graphs in real-time systems [J].IEEE Transactions on Parallel and Distributed Systems,2014,15(9):849-864. [8] Kim K,Buyya R,Kim J.Power aware scheduling of bag-of-tasks applications with deadline constraints on DVS-enabled clusters[C]. Proceedings of the 7thIEEE International Symposium on Cluster Computing and the Grid,2007:541-548. [9] Xu Bao-min,Zhao Chun-yan,Hua En-zhao,et al,Job scheduling algorithm based on Berger model in cloud environment[J].Advances in Engineering Software,2011,42(3):419-425. [10] Li Qin,Li Yong,Tu Bi-bo,et al.QoS-guaranteed dynamic resource provision in Internet data centers[J].Chinese Journal of Computers,2014,37(12):2395-2406. [11] Song Ying,Sun Yu-zhong,Shi Wei-song.A two-tiered on-demand resource allocation mechanism for VM-based data centers[J].IEEE Trans on Services Computing,2013,6(1):116-129. [12] Shi Xue-lin,Xu Ke.Utility Maximization model of virtual machine scheduling in cloud environment[J].Chinese Journal of Computers,2013,36(2):252-262. [13] Topcuoglu H,Hariri S,Wu M Y.Performance-effective and low complexity task scheduling for heterogeneous computing[J].IEEE Transactions on Parallel and Distributed Systems,2012,13(3):260-274. [14] Mezmaz M,Melab N,Kessaci Y,et al.A parallel bi-objective hybrid metaheuristic for energy-aware scheduling for cloud computing systems[J].Journal of Parallel and Distributed Computing,2011,71(10):1497-1508. [15] Ding Yan,Wang Huai-min,Shi Pei-chang,et al.Trusted cloud service[J].Chinese Journal of Computers,2015,38(1):133-149. [16] Wang Wei,Zeng Guo-sun,Tang Dai-zhong,et al.Cloud-DLS:dynamic trusted scheduling for cloud computing[J].Expert Systems with Applications,2012,39:2321-2329. [17] Cao Jie,Zeng Guo-sun,Jiang Huo-wen,et al.Trust-aware dynamic level scheduling algorithm in cloud environment [J].Journal on Communications,2014,35(11):39-49. [18] Cao Jie,Zeng Guo-sun,Niu Jun,et al.Availability-aware scheduling method for parallel task in cloud environment[J].Journal of Computer Research and Development,2013,50(7):1563-1572. [19] Wang Shou-xin,Zhang Li,Li He-song.Evaluation approach of subjective trust based on cloud model[J].Journal of Software,2010,21(6):1341-1352. [20] Tang Wen,Chen Zhong.Research of subjective trust management model based on the fuzzy set theory[J].Journal of Software,2003,14(8):1401-1408. [21] Luo Jun-hai,Fan Ming-yu.A subjective trust management model based on certainty-factor for MANETs[J].Journal of Computer Research and Development,2013,47(3):516-523. [22] Deng Xiao-heng,Lu Xi-cheng,Wang Huai-min.Study on trust evaluation based resource scheduling in iVCE[J].Chinese Journal of Computers,2017,30(10):1750-1762. [23] Abawajy J.Determining service trustworthiness in inter-cloud computing environments[C].In Proceedings of 2009 10thInternational Symposium on Pervasive Systems,Algorithms and Networks,2009:784-788. [24] Raghebi,Zohre,Mahmoud.A new trust evaluation method based on reliability of customer feedback for cloud computing[C]. In Preceedings of 2013 10thInternational ISC Conference on Information Security and Cryptology,2013:1-6. [25] Li Xiao-yong.Du Jun-ping.Adaptive and attribute-based trust model for service-level agreement guarantee in cloud computing[J].IET Information Security,2013,7(2):144-154. [26] Fan Wen-juan,Yang Shan-lin,Pei Jun.A novel two-stage model for cloud service trustworthiness evaluation[J].Expert Systems,2014,31(2):136-153. [27] Yager R.On the entropy of fuzzy measures[J].IEEE Transactions on Fuzzy Systems,2000,8(4):453-461. [28] Calheiros R N,Ranjan R,Rose C A F D,et al.Cloudsim:a novel framework for modeling and simulation of cloud computing infrastructures and services[R].GRIDS-TR-2009-1.Grid Computing and Distributed Systems Laboratory,The University of Melbourne,Australia,March 2009. [29] Topcuoglu H,Hariri S,Wu M Y.Performance-effective and low complexity task scheduling for heterogeneous computing[J].IEEE Transaction on Parallel Distribution System,2002,13(3):260-274. 附中文参考文献: [4] 曹 洁,曾国荪,匡桂娟,等.支持随机服务请求的云虚拟机按需物理资源分配方法[J].软件学报,2017,28(2):457-472. [5] 许 力,曾智斌,姚 川.云计算环境中虚拟资源分配优化策略研究[J].通信学报,2012,33(1):9-16. [10] 李 青,李 勇,涂碧波,等.QoS保证的数据中心动态资源供应方法[J].计算机学报,2014,37(12):2395-2406. [12] 师雪霖,徐 恪.云虚拟机资源分配的效用最大化模型[J].计算机学报,2013,36(2):252-262. [15] 丁 滟,王怀民,史佩昌,等.可信云服务[J].计算机学报,2015,38(1):133-149. [17] 曹 洁,曾国荪,姜火文,等.云环境下服务信任感知的可信动态级调度算法[J].通信学报,2014,35(11):39-49. [18] 曹 洁,曾国荪,钮 俊,等.云环境下可用性感知的并行任务调度算法[J].计算机研究与发展,2013,50(7):1563-1572. [19] 王守信,张 莉,李鹤松.一种基于云模型的主观信任评价方法[J].软件学报,2010,21(6):1341-1352. [20] 唐 文,陈 钟.基于模糊集合理论的主观信任管理模型[J].软件学报,2003,14(8):1401-1408. [21] 罗俊海,范明钰.基于置信度的MANETs主观信任管理模型[J].计算机研究与发展,2013,47(3):516-523 [22] 邓晓衡,卢锡成,王怀民.iVCE中基于可信评价的资源调度研究[J].计算机学报,2017,30(10):1750-1762.5.3 任务执行行为感知的遗传调度算法(Execution Behavior Aware Genetic Scheduling Algorithm,EBAGS)

6 仿真实验及分析
6.1 仿真实验环境和设置
6.2 云系统可靠性度量模型的有效性

6.3 不同任务数量情况下的算法性能比较

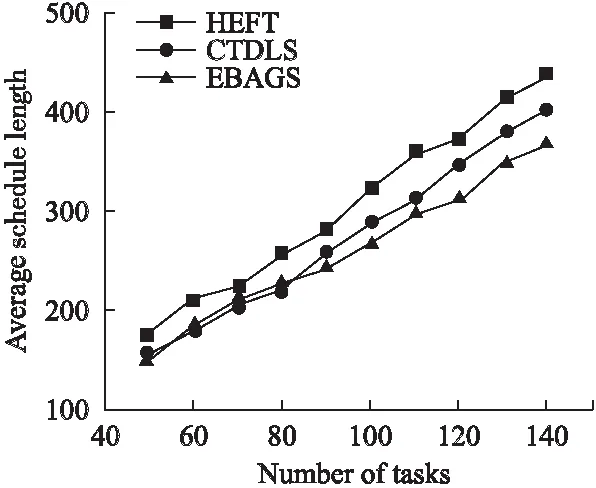
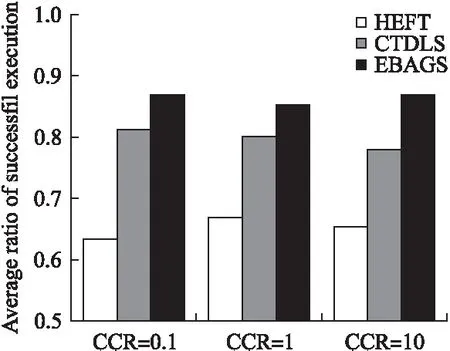
6.4 不同任务类型情况下的算法性能比较
7 结束语

猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
网络安全与数据管理(2022年6期)2022-07-13
北京航空航天大学学报(2022年6期)2022-07-02
建材发展导向(2021年15期)2021-11-05
移动通信(2021年5期)2021-10-25
北京航空航天大学学报(2021年6期)2021-07-20
铁道通信信号(2020年10期)2020-02-07
北京航空航天大学学报(2019年9期)2019-10-26
计算机测量与控制(2019年6期)2019-06-27
电子制作(2018年23期)2018-12-26
