
基于主题模型分析与用户长短兴趣的活动推荐
2018-04-13 10:03高泽锋徐明华
小型微型计算机系统 2018年4期
高泽锋,王 邦,徐明华
1(华中科技大学 电子信息与通信学院,武汉 430074) 2(华中科技大学 新闻与信息传播学院,武汉 430074) E-mail:zefenggao@163.com;wangbang@hust.edu.cn;xuminghua@hust.edu.cn
1 引 言
近年来,基于活动的社交网络(EBSNs),例如meetup1和豆瓣同城2,得到了广泛的发展.这些网站不仅为传播各种各样的社交活动提供了一个方便的平台,也在用户之间构建了一个庞大的社交网络.由此,不管是学术界还是工业界,如何高效地为用户推荐个性化的活动成了一个热门的领域[1,2].活动推荐与其他产品的推荐不一样,因为产品推荐通常并没有被嵌入到社交网络中,没有考虑各种复杂的社交关系.所以,社交网络中的活动推荐面临很多新的挑战.
推荐系统的常见方法可分为两种:一种是协同过滤算法,一种是基于内容的推荐算法.在基于内容的推荐算法中,对音乐、电影这一类的物品做推荐时,主要使用的方法是用标签来表征物品的特征[5],而在对类似于微博这样的文本内容做推荐时,特征值的提取主要有两种方式,一种是基于语义的方法,一种是基于统计的方法[6];本文即采用基于语义的方法来建立用户兴趣模型.
在对文本使用基于内容的推荐方法时,传统的做法是将用户所有的历史记录数据进行处理分析,并对用户兴趣爱好进行建模[8],然而这种方法并没有考虑用户的长短兴趣随时间的变化可能有所改变.虽有少量研究考虑了用户的长短兴趣变化[7,10],但没有区分用户行为记录中的不同行为类别,亦未加入行为权重因素进行加权考虑.
本文根据用户行为记录结合了用户的行为权重计算得到用户的兴趣模型,又结合时间衰减函数分别建立用户的长期兴趣模型和短期兴趣模型.根据用户的长期兴趣向量与活动的类别进行匹配,得到用户偏好的活动类别,然后进一步基于用户的短期兴趣向量与所选择的活动类别中的具体活动进行相似度计算,从而得到每一类别中待推荐的活动.最后对所选活动根据相似度高低进行重排,取相似度高的前K个活动,形成最后的活动推荐列表.
本文的主要贡献包括以下几点:
1)通过结合时间衰减函数以及行为权重分别计算了用户的长短期兴趣模型,更准确地描述了用户的兴趣爱好及其可能的变化趋势;
2)通过用户的长兴趣匹配活动类别后,舍弃相似度低的活动类别,减少了计算量的同时也能提高推荐的准确率;
3)通过爬取的实际社交网站数据进行了实验,结果验证了此方法的有效性和高效性.
2 整体框架
图1是本文个性化活动推荐算法的一个整体框图.首先,根据豆瓣平台上的活动类别将待推荐的活动进行分类,并分别计算每个类别的主题分布.根据用户所有参加和感兴趣的活动记录,赋予行为权重并结合时间函数计算得到用户的长期兴趣偏好.接着,根据用户近段时间的活动记录计算得到用户的短期兴趣偏好.在进行活动推荐时,首先依据用户长期兴趣偏好,对活动类别计算相似度,选取相似度高的前几类活动.其次,在所匹配的活动类别中,根据用户短兴趣与活动的相似度高低选取前K个活动.最后对所选的活动,根据相似度的高低做一个重排序,并选取TopK作为最终的活动推荐结果.

图1 用户个性化活动推荐框架图Fig.1 Frame map of user′s personalized event recommendation

图2 用户兴趣向量训练流程图Fig.2 Flow chart of user′s interest vector training
3 用户长短兴趣建模
3.1 LDA主题模型
本文利用LDA(Latent Dirichlet Allocation)概率主题模型建立用户兴趣模型.LDA是一种非监督的机器学习技术,主要被用来识别大规模文档集或语料库中潜在的主题信息[3].
LDA模型有三层:
1)单词层:从语料库中提取出来一个词频大于一定数量的单词集V={w1,w2,…,wv};
2)主题层:主题集Φ={z1,z2,…,zk}中的每一个zk,都是一个基于单词集V的概率多项分布,可以被表示成φ=
3)文档层:就单词层而言,采用词袋方法,每一篇文档被表示成一个词频向量di=
LDA模型采用了狄利克雷分布作为概率模型分布的先验分布,α和β分别是文档-主题分布以及主题-词分布的先验知识.在给定的α和β下,由LDA模型生成一篇文档的过程可以表述如下:
1)从狄利克雷分布Dir(α)中取样生成文档i的主题分布θi;
2)从主题的多项式分布θi中取样生成文档i的第j个单词的主题Zi,j;
3)从狄利克雷分布Dir(β)中取样生成主题Zi,j对应的词分布φzi,j;
4)从词语的多项式分布φzi,j中采样最终生成词语wi,j.重复这样的过程就可以生成一篇文档.
由吉布斯采样可以得到α和β的近似值,即得到了文档-主题的分布,以及主题-词的分布.于是,训练后的活动文本的LDA特征向量可表示如下:
3.2 用户的兴趣模型构建
本文使用上文所述的LDA模型来对活动文本进行潜在主题分布计算,进而计算出用户的长短期兴趣模型.图二为计算用户兴趣模型的流程图.
3.2.1 用户长时兴趣模型的计算
取用户所有历史记录,使用LDA主题模型计算得到每个活动文本的特征向量,结合行为权重和时间衰减函数计算得到用户的长时兴趣向量.具体步骤如下:
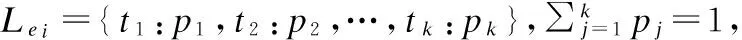
b)对每个活动ei,若用户参与了该活动,则取权重α1,若用户只是对该活动感兴趣,则取权重α2.用公式(1)计算fei,
fei=αj*lei,j∈{1,2}
(1)
并称该fei为活动ei体现的无衰减的用户兴趣向量.
c)对每个ei,结合时间衰减公式[4]
f(t)=e-λ*t
(2)

(3)
可以看到用户长兴趣向量中的每一维代表的主题都与活动的特征向量相对应,所以他们之间计算相似度是完全合理的.
3.2.2 用户的短兴趣模型的计算
取用户近期的历史记录,使用LDA主题模型计算得到每个活动文本的特征向量,结合行为权重和时间衰减函数计算得到用户的短时兴趣向量.具体步骤如下:

4 活动的个性化推荐
4.1 推荐算法核心步骤
1)将所有待推荐的活动依据豆瓣平台上的类别分成13组,表示成E={E1,E2,…,E13}.

(4)
(5)
3)对用户U,使用公式(6)将U的长兴趣向量Lu与lE={lE1,lE2,…,lE13}中每个类别的主题向量求余弦相似度,得到H={H1,H2,…,H13}.对H进行降序的排序后,取相似度值Top 3的类别记为T={Htop1,Htop2,Htop3}.
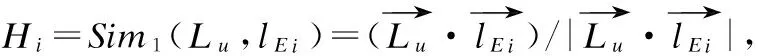
(6)

(7)
5)遍历S,将这3K个活动根据相似度高低进行快速排序,取相似度值最高K的个活动加入列表R,得到R={e1,e2,…ek}作为最后的推荐结果.
4.2 算法伪代码
算法1.选取为用户U推荐的活动类别

输出:为用户推荐的活动类别列表T
1.初始化SUM=0;初始化列表T,H为空;
2.FOR EACHlEiINlE:
4. 将Hi及对应类别名加入中;
5.SORT(H);
6.T=TOP3(H);
7.RETURNT;
Hi表示用户的长兴趣向量与活动类别的主题向量的点积,即相似度.将Hi以及对应的活动类别加入到列表H中,遍历完所有的活动类别之后把得到的H列表根据其中的相似值的高低降序排序,之后取相似值较高的三类活动加入到列表中返回.
算法2. 为用户推荐topK的活动
输出:为用户推荐的topK活动列表R
1.初始化列表R,R′为空;
2.FOR EACHTiINT:
3. 初始化列表E,S,找到对应类别的活动加入E
4. FOR EACHejINE:
6. 将Sj及对应的活动id加入到列表S中
7. SORT(S)
8. 取topK(S),加入到列表R′中
9.SORT(R′)
10.R=topK(R′)
11.RETURNR
遍历完活动类别列表T之后得到的活动列表R′包含了3K个活动,对R′根据相似值的高低再排序,取值较高的前K个活动作为最终的推荐结果.这样做的原因是算法最终只需要推荐K个活动,那么只需要对每个类别中与用户短兴趣向量相似度较高的前K个活动进行重排序,相对于把三类活动全部整合再排序可以大大节约计算时间和计算机内存的消耗.
5 实验分析
5.1 实验数据
实验选取了2015年9月21日至2016年9月20日这一年的豆瓣同城中上海地区的活动数据.共爬取活动15052个活动,25902个用户.活动类别共有音乐,展览,戏剧,讲座等13类别.由于实验将划分前十个月的用户记录作为训练数据,后两个月的记录作为测试记录,用户数据中有很大一部分的无效数据,所以进行了一定的预处理:
1)将训练时间段内活动记录数小于6个用户数据剔除,将测试时间段内活动记录数小于3个的用户数据剔除;
2)将训练活动数或者测试活动数大于100个用户认为是异常用户,剔除掉;
3)有部分用户虽然符合训练活动数和测试活动数,但是由于他的活动记录中的个别活动无法爬取到,导致测试或训练数不符要求也要剔除掉;
4)对后两个月的测试活动中剔除掉0用户参与并且0用户感兴趣的干扰活动.
最终预处理完之后留下11607个训练活动作为训练集,3362个测试活动作为测试集;用户部分剔除掉了大量的无效数据,留下509个有效用户,他们分别有至少6个的训练活动数据和至少3个的测试活动数.
实验训练集与测试集数据的划分:实验取2015年9月21日至2016年7月20日这十个月作为训练期,用户在这段时间的数据记录用来训练用户的兴趣模型,取2016年7月21日至9月20日之间的两个月的活动记录作为测试数据.
5.2 评价标准
论文选取了标准的评价指标作为该推荐算法的评价机制,对每个用户,分别计算:
1)准确率PU(L),即系统为用户推荐的L个活动中用户参加或者感兴趣的活动所占的比例[9].
2)召回率RU(L),即一个用户感兴趣的或者参加的活动被推荐的概率,定义为推荐列表中用户喜欢的活动与所有用户喜欢的活动的比率.
3)F1值,由于推荐的准确率和召回率与推荐列表的长度都是相关的,一般推荐列表增加,准确率会下降而召回率上升,所以需要一个包含准确率和召回率的二维向量来反映算法的表现.
(8)
4)P@n值,即推荐的个活动中前n个活动的准确率.由于本次实验选取的用户的测试活动数至少为3个,因此实验对应地统计至少为3的推荐结果,即主要考察P@1与P@3.
5.3 实验结果
5.3.1 时间函数和衰减因子
用户长兴趣模型结合了时间衰减函数进行计算.从实验数据的分析中发现,通常一个用户参与活动并不是非常频繁,一般一个月内参与一次到两次,所以公式(2)中的时间t的单位以月作为单位.

图3 不同取值下的算法效果对比图Fig.3 Comparisonofalgorithmeffectsunderdifferentvalues图4 不同LDA维数下的实验结果图Fig.4 ExperimentalresultsofdifferentdimensionsofLDA图5 α1=1时α2变化对算法效果的影响图Fig.5 Influenceofthechangeofα2ontheeffectofthealgorithmwhenα1=1
对于衰减因子λ的选取,论文对不同取值下的推荐结果进行了对比,实验结果见图3.可以看到λ的取值从0.3变化到1时,算法的各项指标均呈现缓慢上升趋势;当λ从1变化到1.5时,算法各项指标变化趋于平缓后略有下降趋势.但对性能指标的影响并不是十分明显,因此以下实验结果中选取λ=1.
5.3.2 LDA主题维数的选择
由于实验中使用的数据已经带有分类信息,故不再使用LDA主题分布来做分类,但是LDA主题的维数的多少可以衡量活动的每个潜在主题的区别度.维数越少,则训练出来的主题之间存在着较小的关联性,主题之间的区别度就较大;维数越多,训练出来的主题之间的区别度就较小.来看下面的对比实验:
可以看出随着LDA维数的增加,各项指标呈现略有所上升的趋势,当维度被放大到100维之后,前四项指标还是略有增加,但是P@3指标相较略有所下降,所以后续实验选择100维LDA模型.
5.3.3 行为权重值选取
在计算用户的长短兴趣模型时,对于用户表现出来的不同行为赋予了不同的权重,若用户参与了某个活动,取权重α1,若用户只是对该活动感兴趣,则取权重α2.这两个权重的意义在于不同的行为体现的用户的兴趣是不同的,直观的判断是用户参加的活动比用户感兴趣的活动更加符合用户的兴趣,即α1>α2.对于这两个参数对推荐结果的影响,论文进行了实验,结果如下:
从图5可以看出:当α1固定为1时,α2从0.1变化到1,实验的各项指标均是先有上升趋势,到α2=0.3时,各项指标达到最大值,α2>0.3之后,各项指标趋于平缓后有下降趋势.所以取α2为0.3.
从图6可以看出:当α2固定为0.3时,α1从0.5变化到1,实验的各项指标先有上升趋势,当α1=0.9时,各指标达到最大值,之后基本保持平稳.所以取α1为0.9.
5.3.4 活动类别数选取
对于上面所述的算法中,用长兴趣匹配活动类别后,首先选取了相似度最高的TopS个类别,论文进行了实验判断活动类别数S.
图7绘出了用户参与活动类别数的统计图.可以观察到,参与活动类别数最多的人群是2类、3类、4类.统计结果显示,509个用户中有336个用户参加了2到4类活动,占了66%.
图8绘出了选取不同活动类别数的活动推荐准确率,以及对比了另外两种算法的准确率.可以看到S取3的时候比选2的情况下准确率略高一点,比选4的时候准确率略低一点.由于准确率相差非常的小,出于计算量的考虑,将S的取值定为3.但是不管S的取值是多少,高相似度类别算法的实验准确率都明显比其他两种实验的准确率要高.
5.4 对比其他方法

图6 α2=0.3时α1变化对算法效果的影响图Fig.6 Influenceofthechangeofα1ontheeffectofthealgorithmwhenα2=0.3图7 用户参与的活动类别数-人数统计图Fig.7 Summarygraphofnumberofeventcategoriesforusers-numberofpeople图8 选取不同活动类别数的准确率对比以及三种方法的推荐准确率对比图Fig.8 Contrastofdifferentnumberofeventcategoriesandcontrastofthreemethods
为了验证论文提出的算法性,论文与以下两种同类算法进行了对比实验:
1)采用均衡各类别活动的占比方法[7]得到个性化推荐列表;
2)采用长兴趣匹配所有活动法[8]得到个性化推荐列表;
3)采用论文提出的方法得到的推荐列表.
评价标准分别为准确率、召回率、F1值、P@n指标以及时间消耗.实验结果见表1.
从实验结果可知:
1)均衡占比法的准确率明显比其他两种方法低,说明在活动推荐中,大多数用户的兴趣爱好往往集中在某几个类别中,并不会对平台上所有的活动类别都感兴趣.
2)论文提出的方法相较于长兴趣匹配法各项指标都要好,说明长兴趣用来匹配活动类别比较合适,而匹配具体活动时依据用户短兴趣进行选择会更精确.
3)论文提出的方法比其他两种方法在计算时间上都要优秀一个数量级,说明这样的做法在不失准确率的基础上大大提高了算法执行效率.
6 总结与展望
论文提出了一种基于LDA主题模型,并且结合用户长短期兴趣的活动推荐算法.算法中结合了时间衰减函数与行为权重计算用户的稳定兴趣爱好,与活动类别做相似度计算,选取相似度最高的前三类活动.对类内的活动又结合用户近期行为得到的短兴趣向量做依据计算与每个活动的相似度.取类内活动相似度最高的topK,汇总重排序后再取topK作为最后的推荐结果.实验结果显示这样的方法在准确率,召回率,F1值以及执行效率等指标上都优于其他同类算法.

表1 各方法在top_3、top_5、top_10推荐性能上的比较Table 1 Comparison between different approaches in top_3,top_5 and top_10 recommendation
本文还有一些待改进的地方:由于首先选取了与用户长兴趣相似度最高的少量类别活动类别进行类别筛选,能够减少时间复杂度,但这可能使得算法推荐活动的覆盖率会相较其他算法有所下降,这是今后需要进一步提高的地方.
[1] Jie Bao,Yu Zheng,David Wilkiem,et al.Recommendations in location-based social networks:a survey [J].Geoinformatica(GEOINFORMATICA),Springer,2013,19(3):525-565.
[2] Pavlos Kefalas,Panagiotis Symeonidis,Yannis Manolopoulos.A graph-based taxonomy of recommendation algorithms andsystems in lbsns [J].IEEE Transactions on Knowledge and DataEngineeing(IEEE Knowl Data EN),2016,28(3):604-622.
[3] Blei D M,Ng A Y,Jordan M I.Latent dirchlet allocation[J].Journal of Machine Learning Research(J Mach Learn RES),2003,3(4/5):993-1022.
[4] Ding Yi,Xue Li.Time weight collaborative filtering [C].Proceedings of the 14th ACM International Conference on Information and Knowledge Management(CIKM),Bremen,Germany,ACM,2005.
[5] Gao Na,Yang Ming.Topic model embedded in collaborative filtering recommendation algorithm[J].Computer Science,2016,43(3):57-61.
[6] Sun Tie-li,Yang Feng-qin.An approach of building and updating user interestprofile according to the implicit feedback[J].Journal of Northeast Normal University,2003,35(3):99-104.
[7] Chen Jie,Liu Xue-jun,Li Bin.Personalized microblogging recommendation based on long-term and short-term interest of user[J].Journal of Chinese Computer Systems,2016,37(5):952-956.
[8] Guo Yu.Design and implenmentation of a test recommender system of social network based on latent dirichlet allocation[D].Beijing:University of Chinese Academy of Sciences,2015.
[9] Zhu Yu-xiao,Lu Lin-yuan.Evaluation metrics for recommender systems[J].Journal of University of Electronic Science and Technology of China,2012,41(2):163-175.
[10] Gao Xing,Yang Xiu-mei,Sun Yong,et al.Research of news recommendation based on dynamix user's interest matrix [J].Journal of Chinese Computer Systems,2016,37(5):948-951.
附中文参考文献:
[5] 高 娜,杨 明.嵌入LDA主题模型的协同过滤推荐算法[J].计算机科学,2016,43(3):57-61.
[6] 孙铁利,杨凤芹.根据用户隐式反馈建立和更新用户兴趣模型[J].东北师大学报自然科学版,2003,35(3):99-104.
[7] 陈 杰,刘学军,李 斌.一种基于用户长短期兴趣的微博推荐方法[J].小型微型计算机系统,2016,37(5):952-956.
[8] 郭 宇.基于LDA的社会化网络文本推荐系统的设计及实现[D].北京:中国科学院大学,2015.
[9] 朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163-175.
[10] 高 兴,杨秀梅,孙 咏,等.基于时间段的动态用户兴趣度矩阵的新闻推荐研究[J].小型微型计算机系统,2016,37(5):948-951.
征稿简则
一、征稿范围:《小型微型计算机系统》杂志刊登文章的内容涵盖计算技术的各个领域(计算数学除外).包括计算机科学理论、体系结构、计算机软件、数据库、网络与通讯、人工智能、信息安全、多媒体、计算机图形与图像、算法理论研究等各方面的学术论文.
二、来稿要求:本刊主要刊登下述各类原始文稿:
1.学术论文:科研成果的有创新、有见解的完整论述.对该领域的研究与发展有促进意义.
2.综述:对新兴的或活跃的学术领域或技术开发的现状及发展趋势的全面、客观的综合评述.
3.技术报告:在国内具有影响的重大科研项目的完整的技术总结.
三、注意事项
1.来稿务求做到论点明确、条理清晰、数据可靠、叙述简练,词义通达.
2.来稿必须是作者自己的科研成果,无署名和版权争议.引用他人成果必须注明出处.
3.本刊采用在线投稿方式,可登陆http://xwxt.sict.ac.cn/进行在线投稿.
4.格式要求:题目(中、英文)、摘要(中、英文)、作者的真实姓名(中、英文)、作者的单位、城市(中、英文)、邮政编码、E-mail(便于联系的)、关键词(中、英文4~7个),中图分类号、作者简介、基金项目.
(1) 英文部分的作者姓名使用汉语拼音,单位英文名称须给出英文全称,不要使用缩略语;
(2) 作者简介包含作者姓名、性别、出生年、最高学历、技术职称、研究方向(若作者中有中国计算机学会(CCF)会员,请注明,并给出会员号).凡第一作者为CCF会员/高级会员/学生会员者,将享受八五折的版面费优惠;
(3) 基金项目的类别与项目编号.
5.中、英摘要:文章摘要具有独立性和自明性,含正文等量的主要信息,一般为250~300字,采用第三人称表述.
6.参考文献:未公开发表的文献不得列入.文后所列参考文献统一排序,且必须在正文中引用.中文参考文献应给出对应的英文译文.其具体书写格式为:
(1) 图书:[编号]作者姓名(姓在前,名在后),书名,出版社地址,出版社,出版年.
(2) 期刊:[编号]作者姓名、文章题目、刊物名称,出版年,卷号(期号):起止页码.
(3) 会议论文:[编号]作者姓名.论文题目.见:编者、论文集全名、出版地:出版者,出版年,起止页码.
(4) 网络文献:请给出文献作者或单位名,文章题目、网址、发布日期.
7.插图和表:插图必须精绘并用计算机激光打印,一般不超过7幅.图应结构紧凑,不加底纹,不要做成彩色的,图宽最好不超过8厘米,图内字号统一使用6号宋体,字迹、曲线清晰,必要时给出坐标名称和单位.每个图、表均给出中英文图注(如:“图1:***图;”“Fig.1:***”)和表注(如:“表1:***表”,“Table 1:***”).
8.计量单位:稿件中一律使用《中华人民共和国法定计量单位》.外文和公式中应分清大、小写和正、斜体,上、下角的字母、数码位置准确.易混淆的字母或符号,请在第一次出现时标注清楚.
9.本刊在收到作者稿件经初审后立即给作者电子邮箱发“稿件收到通知”.除作者另有明确要求外,本刊原则上只与第一作者联系,作者投稿后若4个月无消息,可自行改投它刊.通过初审的稿件将收到本刊给予的编号,并需邮寄审稿费.
10.本刊对不拟录用的稿件只发给“退稿通知”,恕不退回原稿,请自留底稿.
11.稿件一经发表,将酌致稿酬,并寄送样刊.
本刊文章现被国内外多家数据库收录,作者著作权使用费与本刊稿酬一并给付,作者若不同意将文章收录,请在投稿时说明.
编辑部地址:沈阳市浑南区南屏东路16号《小型微型计算机系统》编辑部邮政编码:110168
电话:(024)24696120 E-mail:xwjxt@sict.ac.cn网址: http://xwxt.sict.ac.cn
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
小学生学习指导(中年级)(2021年4期)2021-04-27
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
少儿画王(3-6岁)(2020年4期)2020-09-13
课堂内外(初中版)(2020年5期)2020-06-19
中学生数理化·中考版(2015年10期)2015-09-10
小说月刊(2012年3期)2012-05-08
