
低层特征与高层语义融合的人体行为识别方法
2018-04-13 10:03王忠民周肖肖王文浪
小型微型计算机系统 2018年4期
王忠民,周肖肖,王文浪
(西安邮电大学 计算机学院,西安 710121) E-mail:zhou_xiao629@163.com
1 引 言
跌倒是导致中老年人安全与健康问题的主要原因之一,对于中老年人的跌到检测有着重要意义.但是由于跌倒行为的数据采集困难,造成样本集中该行为数据所占的比例较少,这种小样本数据会造成训练集中各行为的数据不平衡和跌倒行为数据不充足等问题.
传统基于低层统计特征的人体行为识别方法是利用加速度数据提取统计特征来识别人体日常行为,如静止、跑步、走路等,其具有较广泛的应用前景[1-3].该类方法侧重于整体的分类准确率,在样本集中包含小样本数据行为时,该类方法会为了整体的分类效果牺牲小样本行为的识别准确率,导致对包含小样本行为的数据集的平均识别率较低[4].
对于不平衡数据来说,小样本类通常是影响整体分类准确率的主要原因.国内外研究人员对小样本数据问题的研究取得了一定成果[5,6].在数据预处理方面主要通过重采样技术[7,8],对样本进行过采样或者欠采样,调整样本集不平衡程度,但这类采样方法的随机性和盲目性,容易造成重要样本信息的丢失,影响分类效果.在分类算法方面主要是对现有分类算法的改进,提升算法对小样本数据行为的识别准确率,如最小二乘支持向量机是改变了支持向量机的标准约束条件和风险函数,以便于提高训练效率[9].这类分类算法只考虑了数据的低层统计特征与类别之间的关系,而忽略了低层特征和高层语义特征、高层语义特征与类别之间的关系,导致这些分类方法泛化性较差,存在一定的分类局限性.
作为对类别的高层特征描述,语义属性学习在图像描述、图像识别与检索、人脸检测和零样本识别方面有较好的应用[10-13].引入语义属性的分类方法解决了低层特征与类别之间的语义差距,但是该类方法目前在计算机视觉中图像分类领域应用较为广泛,在人体动作识别应用方面主要是对视频中人体行为的检测.文献[14]虽提出了属性学习在加速度传感器数据中的人体行为识别方法,但该文献中站立、坐着和躺着这三种行为的各个属性对应相等,即这三类行为的属性向量相同,造成这三种行为的识别率较低,进而影响整体的识别效果.
考虑到上述因素,在识别含有小样本行为的数据集时,为将低层特征和语义属性特征的信息进行互补,本文提出一种结合低层特征与语义属性特征的人体行为识别方法.在基于低层特征人体行为识别的基础上引入语义属性,增加表达行为的属性数目,避免行为之间属性表达相同,利用特征、属性和行为类别之间的关系获取高层语义属性集,将其与低层特征集分别输入到随机森林分类器中,利用融合算法将两种信息的识别结果进行最优选择,得到最终的识别结果.引入语义属性的分类方法不但提高了传统低层统计特征分类方法和属性特征分类方法的泛化性能,而且提高了小样本数据行为的分类识别精度.
2 结合两种特征的人体行为识别方法
2.1 识别方法的结构框图
结合低层特征与语义属性特征的人体行为识别方法如图1所示,主要包括3部分:基于低层统计特征的分类识别、基于高层语义特征的分类识别和两种特征信息分类结果的融合.
第一部分是基于低层统计特征的分类识别,该部分按照传统的基于加速度传感器的人体识别方法进行识别[1,3],得到对样本低层特征的预分类结果,由于该类方法的研究已经较为成熟,本文不做过多叙述;第二部分是基于语义属性特征的分类识别,依据提取的低层统计特征,通过属性检测器得到样本对应的属性特征,再对属性特征进行分类,得到预分类结果;第三部分是两种特征信息分类结果的融合,该部分是将两种特征信息的预分类结果按照融合算法进行最优选择,对两种特征信息识别性能进行互补.
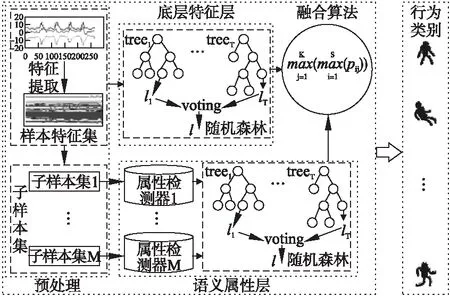
图1 结合两种特征的人体行为识别方法Fig.1 Human activity recognition combined with low-lever feature and high-lever semantic feature
2.2 语义属性学习
行为的语义属性是指能体现行为动作变化较直观的中间层特征,例如,“走路”这一行为可以用“身体中速运动”、“腿部运动”,“胳膊中速运动”等属性来表示[15].行为的语义属性与低层特征之间最大的区别在于前者具有明确的语义,是可以被人类直观理解的,且不同行为的语义属性特征是由低层特征得到的.
高层语义属性的人体行为识别方法的核心思想是将属性特征作为低层特征与行为之间的桥梁,是对行为类别的高级特征表示.如图2所示,语义属性学习分为两个阶段,第一阶段需要构建低层特征与语义属性之间的关系,第二阶段需要构建语义属性与类别之间的关系.

图2 语义属性学习Fig.2 Semantic attribute learning
在人体行为识别中,属性描述可看作是某行为语义含义的特征描述,属性学习可视为对这种语义描述的学习.假设X表示特征空间,其共有D种特征,xi={X1,X2,…,XD}表示行为样本i的D维特征向量,Y表示行为类别空间,行为类别有K种,y∈{Y1,Y2,…,YK}表示人体行为类别,A表示属性空间,共有M个属性,ai={A1,A2,…,AM}表示行为样本i的M维属性向量.那么属性分类模型可表示为低层特征到语义属性、语义属性到行为类别之间的映射,即:
f:X→A→Y
(1)
上式可被分解为如下形式:
H=F2(F1(x))
(2)
其中F1:X→A是低层特征层到语义属性层的映射,包括M个属性检测器,每一个属性检测器将特征向量映射到相对应的属性维度上,得到样本的属性向量.F2:A→Y是属性层到类别标签的映射,包含一个对属性向量进行分类的分类器,其将属性向量映射到类别空间.
2.3 高层语义特征的人体行为识别
属性学习应用到人体行为识别的具体实现如图3所示.为实现低层特征与语义属性之间的关系,基于语义属性特征的分类识别方法需要为每个属性检测器划分子训练集,由每个属性检测器得到相应的属性值;对于语义属性与行为类别之间的映射关系,通过属性-行为矩阵,将上一步得到的属性向量利用分类器算法进行预测,得到该属性向量的各行为分类概率.

图3 高层语义特征分类识别Fig.3 recognition of high-lever semantic feature
在含有小样本行为的样本集中,属性可以用来弥补小样本行为的数据信息不足.利用样本数多的行为数据学习属性检测器,然后利用学习后的属性检测器对小样本行为数据进行预测识别.例如,利用大量的下楼行为的数据学习“身体向下运动”这一属性检测器,学习好的检测器将不仅可以检测下楼动作的属性是否存在,还可以检测跌倒动作的属性是否存在.
2.3.1 属性-行为矩阵的构建
属性-行为矩阵是反映行为和语义属性之间的表征关系,代表行为与属性之间是否关联,即如何由属性特征来描述行为对象.定义M×K维的属性-行为矩阵,其中M表示属性个数,K表示行为类别种类,每一行表示各行为在某一属性下的值,元素aij的值代表属性i和行为j之间是否关联,这样每一种行为便可由一列属性表示.矩阵中每个属性为二值属性,根据属性与行为之间的关联是否存在而取值,存在则aij=1,反之则aij=0.图4所示是本文实验中定义的二值属性-行为矩阵.在实际应用中,可以使用属性描述来定义一个新添加的行为,即相当于在该属性-行为矩阵中添加一个新的列.

图4 属性-行为矩阵Fig.4 Attribute-activity matrix
2.3.2 属性检测器
获得属性-行为矩阵之后,低层特征需要通过属性检测器获取高层语义属性,得到样本低层统计特征对应的属性特征.为检测每一训练样本所对应的各个属性是否存在,需要预先对每个属性训练相应的属性检测器.具体步骤如下:
步骤1.为每一个属性检测器生成一个子训练集.在某一属性下,子训练集由正样本集和反样本集组成,为减少重新采集数据带来不必要的研究损耗,将低层特征训练样本集中与该属性有关的所有带标签行为样本看作为正样本集,并将样本标记为1,类似地,反样本集是由低层特征训练样本集与该属性无关联的所有行为样本组成,样本标记为0.这样得到的子训练集便是该属性检测器的输入训练样本集.
步骤2.定义的属性是二值属性,则检测属性是否存在相当于二元分类问题,随机森林、决策树、支持向量机、贝叶斯等分类方法[16]都可以用来检测属性,本文使用随机森林作为属性检测器进行属性检测,得到样本的属性值.
步骤3.对属性检测器进行训练后,特征样本由M个属性检测器中分别获得对应的属性值,将其按照属性-行为矩阵组合成样本的属性向量ai={A1,A2,…,AM},这便是从低层特征得到的语义属性特征.
2.3.3 属性分类器
由已有研究证明随机森林对样本分布不均匀和缺失特征数据的问题仍可以维持识别准确度,且不容易出现过拟合问题[17].语义属性特征分类方法的分类器采用随机森林算法,将语义属性特征作为该分类器的输入,根据属性-行为矩阵,预测得到最终属性所代表的行为类别.该过程类似于传统基于低层特征的分类识别,即将语义属性特征看作低层特征信息,作为分类器的输入数据,分类器对其特征信息进行训练和测试,得到输出的分类概率.
2.4 两种特征分类融合
传统基于低层统计特征的分类识别侧重整体的识别效果,对于含有小样本行为的样本集的识别效果不理想.当行为类别较多时,基于语义属性特征的分类识别中可能会存在某些行为的属性表达相近或相同,造成这些行为容易误判.如图4中,属性集中如果不包含行为水平方向和垂直方向的运动属性,走路、上楼和下楼这三种行为的属性表达将相同.
由已有研究发现,对多模型的识别性能进行互补可以使用分类器融合方法来实现.其他多分类器融合方法是对同一低层统计特征的多个分类器识别结果进行融合,而本文提出的方法是利用分类器对两种不同特征信息的识别结果进行融合,实现了两种特征信息的组合.
融合算法主要包括多数投票法、最大值法、平均值法、乘积法等[18],由于只是为了充分利用语义属性特征和低层特征包含的有效信息,对两种特征表达的信息进行互补,本文使用应用较为广泛的最大值法进行两种特征的融合.
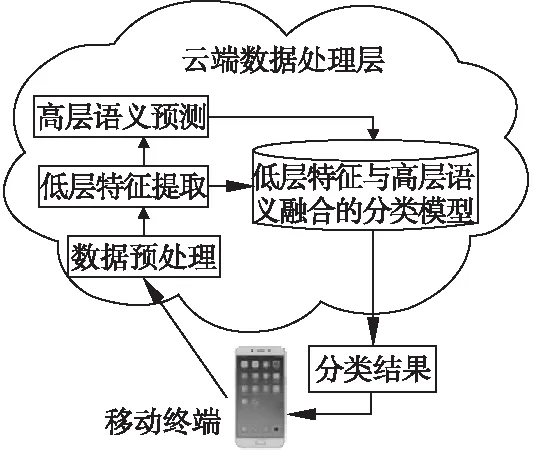
图5 基于融合模型的识别框架Fig.5 Recognition framework based on fusion model
在实际应用中,随着宽带增加、网速提高,将所提出的融合模型结合“移动端+云端”平台进行人体行为识别,其整体框架如图5所示.在云端利用采集到的数据进行融合分类模型的训练,当用户利用移动平台将自身采集到的数据实时上传到云端时,云端通过训练后的分类模型进行预测处理,并将处理结果实时返回给用户移动端.
3 实验结果及分析
3.1 数据集与实验设计
所有实验数据均基于Android智能手机的内置加速度传感器,在现实环境中,由17名包括不同性别、不同年龄段的实验者采集走路、跌倒、静止、跑步、上楼和下楼这6种日常行为的三维加速度数据,采集时每位实验者的智能手机放置位置分别为手中、包中和裤子口袋中,放置方向包括手机横放,颠倒放置和平放,采样频率为50Hz.6种行为中,考虑到跌倒行为的加速度数据较难采集,实验中该行为的训练数据共采集了156条数据,其他行为的加速度数据各进行10次采集,单次采样时间为5秒,为减少其他行为训练数据对实验带来不必要的影响,在实验中其他行为的训练样本选择相同的数目,进行测试时跌倒样本数量和其他行为一致,具体数据分布如表1所列.在进行实验时,为了更好地模拟真实场景,将训练集中跌倒样本的数量从5到156进行增加,从而观察跌倒行为训练样本数目的变化对识别率的影响.
表1 实验数据集
Table 1 Experimental dataset
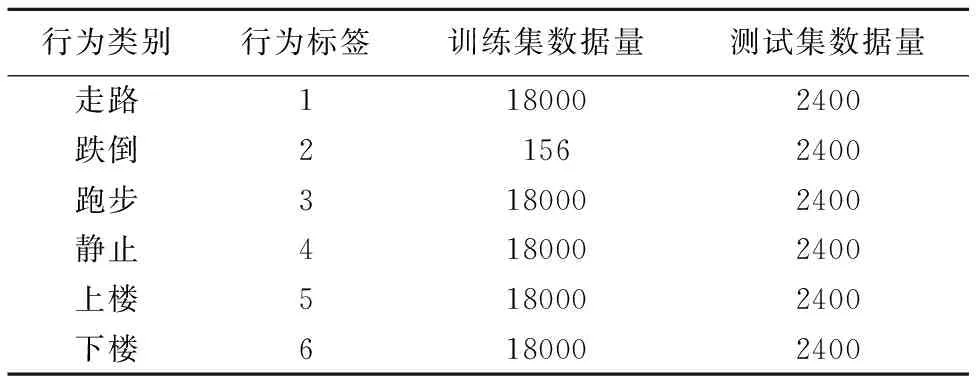
行为类别行为标签训练集数据量测试集数据量走路1180002400跌倒21562400跑步3180002400静止4180002400上楼5180002400下楼6180002400
在实际采集数据时,实验者自身动作差异、手机放置位置与放置方向差异会对采集的数据造成一定的干扰.因在不同坐标系下合成加速度都相同,实验中为解决手机内置传感器的坐标随着人体运动不断改变的问题,选取合成加速度来减少每轴加速度输出值的坐标映射计算.其中ax、ay和az分别代表轴的加速度,合成加速度为:
(3)
由于合成加速度与方向无关,为反映人体在上下、左右、前后方向的运动趋势,需要根据每个轴的加速度计算水平和垂直方向的加速度.垂直方向的加速度为:
av=az
(4)
水平方向的加速度为:
(5)
3.2 实验步骤
具体的实验步骤如下:
1)获取低层特征.首先对采集到训练集和测试集的加速度信息进行滤波处理,计算三个坐标轴合成加速度、垂直加速度和水平加速度;其次采用传统的基于加速度传感器数据的特征提取方法,提取具有时频域特征的特征向量集{平均值,中位数,最大值,最小值,范围,方差,标准差,均方根,x轴与y轴数据的相关系数,y轴与z轴数据的相关系数,x轴与z轴数据的相关系数,频谱能量};最后采用蚁群算法[3]对初步提取的特征集进行特征优选,其参数设置如表2所示,得到最终训练和测试所需的低层特征集{中位数,范围,x轴与z轴数据的相关系数,y轴与z轴数据的相关系数}.
2)获取语义属性特征.首先定义属性-行为矩阵;其次按照属性-行为矩阵划分各属性检测器的子训练特征集;最后利用各低层特征训练子集学习各属性检测器,预测低层特征测试集对应的语义属性特征.
表2 蚁群算法参数设置
Table 2 Parameter setting of ant colony algorithm

参数 值 迭代次数MI5初始信息素水平u00.5特征值个数n2,3,4,5信息素启发因子α0.8期望启发因子β0信息素参数ρ0.3概率变化系数ε0.9蚂蚁个数m3激励因子l0.8阈值Q0.85
3)两种特征分类融合.首先利用随机森林分类器分别对低层特征和高层语义特征进行分类训练和测试,得到两者的分类概率;其次对每一个行为类别,根据最大融合算法从两个特征分类概率中找出可能是该行为的概率的最大值;最后按照取最大法的判决函数找出这些值中最大的行为类别标签作为最终的分类结果.
3.3 实验对比与性能分析
实验中小样本行为是跌倒行为,在基于低层特征分类方法、高层语义特征分类方法和特征分类融合方法下,各行为的识别率随着跌倒行为训练样本数目的变化如图6所示.
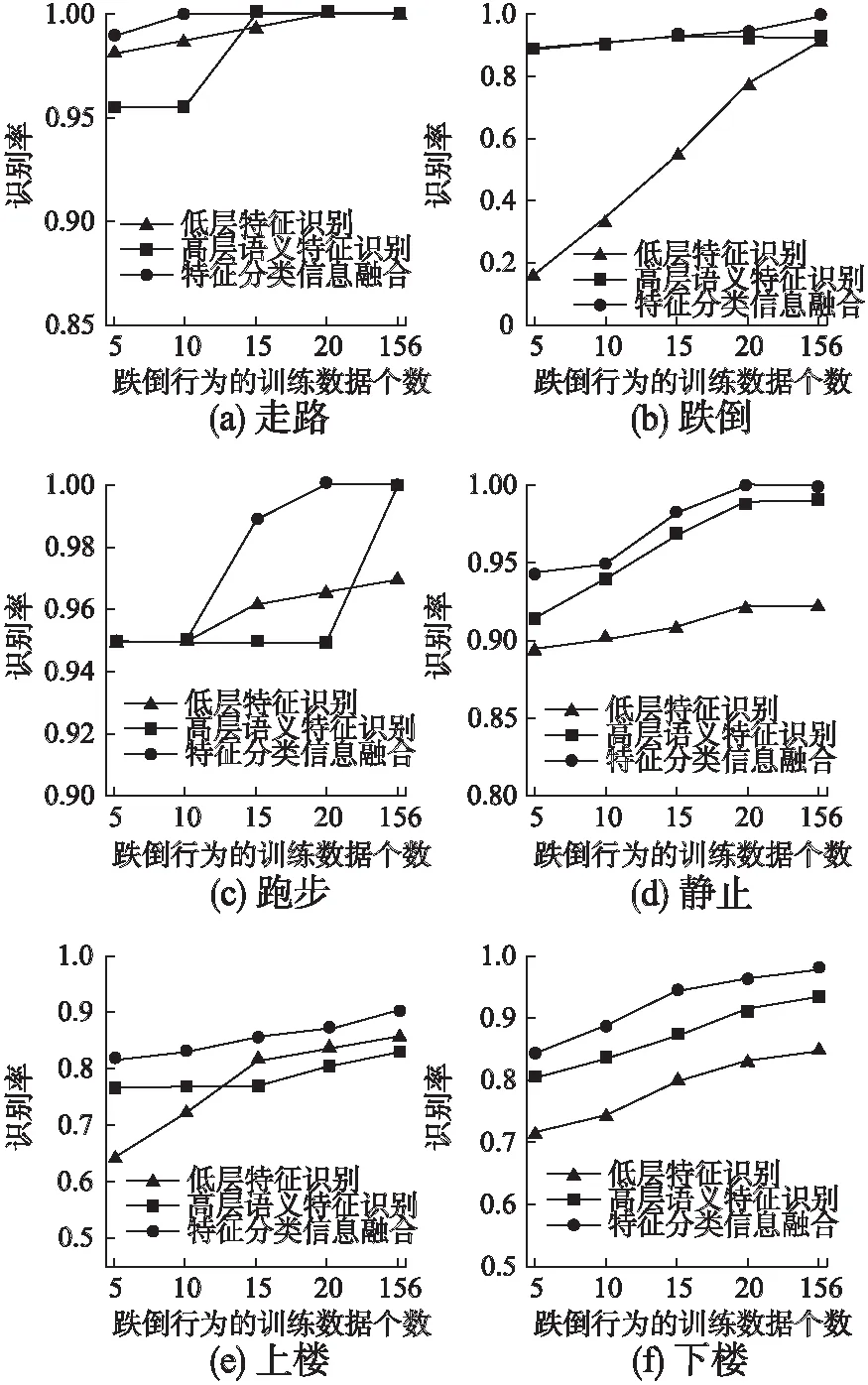
图6 跌倒样本个数变化对各行为识别率的影响Fig.6 Influence of the activity recognition rate with the number of fall down changing
在低层特征分类识别中,对于跌倒这一行为,其识别率随着训练样本数的增加有明显的提高,每增加5个小样本数据,识别率增长约20%;在整个跌倒训练集样本个数变化过程中,上楼和下楼各有1%的提升,其他3种行为的识别率无较大变化.这种现象的原因在于利用低层特征分类方法进行人体行为识别时,需要足够多的各种行为训练数据以供分类器用来学习,跌倒行为样本过少,导致其与训练集中其他行为的数据不平衡,跌倒行为无法提供足够的用于分类器学习的特征数据,致使跌倒行为识别率较低;其他行为训练数据比较充足,在跌倒行为的样本数发生变化时,对其影响不明显.
在高层语义特征识别中,根据属性-行为矩阵中小样本行为和其他行为之间的属性关系,相同属性下,跌倒行为的属性检测可以共享其他行为的低层特征信息.图6结果显示,高层语义属性分类方法中,跌倒行为训练数据的变化对6种行为的识别率无较大影响,但是上楼、下楼和跑步这三种行为的属性表达比较相近,致使上楼和跑步的识别率相较于低层特征分类方法有所下降.
从以上分析可看出,这两种分类方法各有优缺点.而本文提出的结合低层特征和高层语义属性特征的人体行为识别方法,利用取最大值法将两种特征的有用信息进行互补,各行为的识别率较前两个分类方法有所提高.
三种识别方法对跌倒行为、其他行为和所有行为的总体性能对比如图7所示,在跌倒行为的训练样本个数为10时,相较于低层特征分类方法,特征分类信息的融合方法对于跌倒行为的识别率提高了57.37%,对其他行为的识别率提高4.35%,对6种行为的平均识别率提高了17.4%.与语义属性分类方法相比,特征分类信息的融合方法对于跌倒行为的识别率提高了1.19%,对其他行为的识别率提高2%,对于6种行为的平均识别率提高了2.66%.说明了本文分类方法的识别性能对于低层特征分类和高层语义特征分类均有所提高,验证了特征融合方法的有效性.

图7 三种方法识别性能对比(跌倒行为的样本个数为10)Fig.7 Comparison of recognition performance of three methods(the number of fall down is 10)
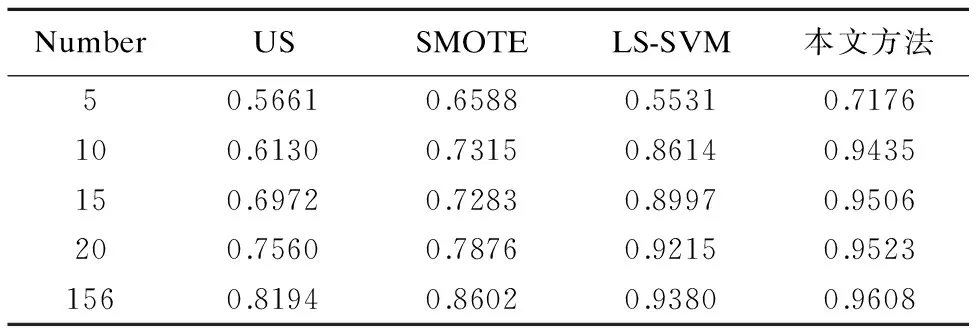
为验证本文特征分类信息的融合方法与其他小样本数据分类方法的识别性能,将本文方法与欠抽样方法(Under-sampling,US)、过抽样方法(Synthetic Minority Over-sampling Technique,SMOTE)和最小二乘支持向量机(least squares support vector machine,LS-SVM)进行比较,结果如表3所示,其中Number表示训练数据集中跌倒行为的样本个数.
由表3可看出,随着训练数据集中跌倒行为样本个数的变化,本文方法的平均识别率和其他方法相比有明显提高.其中在小样本数据个数为10时,相较于欠抽样方法、过抽样方法和最小二乘支持向量机,本文方法的平均识别率分别提高了33.05%、21.2%和8.21%.
在Number从5增加到10时,本文所提方法的平均识别率提高了22.59%,Number从10变化到156时,平均识别率变化了1.73%.这说明该方法在小样本行为的样本数较少的时候,对样本数的变化较为明显,对样本个数变化有较好的敏感度,在样本数较少的情况下有较好的稳定性.
表3 本文方法与其他方法平均识别率的比较(%)
Table 3 Compared with the average of recognition rate of other methods
NumberUSSMOTELS-SVM本文方法50.56610.65880.55310.7176100.61300.73150.86140.9435150.69720.72830.89970.9506200.75600.78760.92150.95231560.81940.86020.93800.9608
以上实验结果表明,本文方法对基于低层特征与语义属性特征的信息进行了互补,可以有效的实现小样本数据行为的识别.
4 结束语
为解决跌倒检测中跌倒行为的样本采集困难,数据集中该行为样本过少导致的识别效果较差的问题,提出了结合低层特征与高层语义特征的人体行为识别方法.该方法引入高层语义属性概念,从低层特征和行为类别之间获取中间层语义特征,并将其识别性能与低层特征识别性能进行互补,提高传统低层特征识别方法对含有小样本数据行为的泛化性能.实验结果表明,该方法对跌倒行为的识别率和6种行为的平均识别率在一定程度上均有所提高,验证了所提方法的有效性.但是在具体应用中仍存在一些问题,当行为类别较多时,其高层语义属性的选择会越来越复杂;实际平台中云端数据处理速度以及云端和移动终端之间网络传输速率等也会影响整个识别系统性能,如何更好地解决这些问题是下一步的研究内容.
[1] Su X,Tong H,Ji P.Activity recognition with smartphone sensors [J].Tsinghua Science and Technology,2014,19(3):235-249.
[2] Heng Xia,Wang Zhong-min.Human activity Recognition based on accelerometer data from a mobile phone [J].Journal of Xi′an University of Posts and Tele comm-unications,2014,9(6):76-79.
[3] Wang Zhong-min,Cao Dong.A feature selection method for behave-or recognition based on ant colony algorithm [J].Journal of Xi′an University of Posts and Telecommunications,2014,19(1):73-77.
[4] Wang S,Yao X.Multi-class imbalance problems:analysis and potential solutions[J].IEEE Transactions on Systems,Man,and Cybernetics—Part B:Cybernetics,2012,42(4):1119-1130.
[5] Ali Mirza Mahmood.Class imbalance learning in data mi-ning -a survey[J].International Journal of Communicati-on Technology for Social Networking Services,2015,3(2):17-36.
[6] Rajeshwari P,Maheshwari D.A study of imbalanced classification problem [J].International Journal of Advan-ced Research in Computer and Communication Engin-eering,2016,5(8):66-69.
[7] Wu Lei,Fang Bin,Diao Li-ping,et al.Imbalanced data resampling based on oversampling and under-sampling [J].Computer Engineering and Applications,2013,49(21):172-176.
[8] Yan Xin.Comprehensive oversampling and under-sampling study of imbalanced datasets[D].Jilin: Northeast Electric Power University,2016.
[9] Zhao Hui,Huang Jing-tao,Tan Shu-cai.Research on classification of imbalanced data based on least squares support sector machine[J].Microelectronics & Computer,2010,27(4):33-37.
[10] Parikh D,Grauman K.Relative attributes[C].IEEE International Conference on Computer Vision (ICCV),2011,6669(5):503-510.
[11] Lampert C H,Nickisch H,Hameling S.Learning to detect unseen object classes by between-class attribute transfer[C].IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR),2009:951-958.
[12] Yu Yong-bin,Liu Qin-yi,Mao Qi-rong,et al.Facial expression recognition method based on semantic attribute [J].Journal of Chinese Computer Systems,2016,37 (2):332-336.
[13] Cheng H T,Griss M,Davis P,et al.Towards zero-shot learning for human activity recognition using semantic attribute sequence model[C].ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp),2013:355-358.
[14] Le T N,Zeng M,Tague P,et al.Recognizing new activities with limited training data[C].International Symposium on Wearable Computers (ISWC),2015:67-74.
[15] Cheng H T,Sun F T,Griss M,et al.Nuactiv:reco-gnizing unseen new activities using semantic attribute based learning[C].International Conference on Mobile Systems,Applications,and Services (MobiSys),2013:361-374.
[16] Lara O D,Labrador M A.A survey on human activity recognition using wearable sensors[J].Communication Surveys & Tutorials,IEEE,2013,15(3):1192-1209.
[17] Río S D,López V,Benítez J M,et al.On the use of map reduce for imbalanced big data using random forest[J].Information Sciences,2014,285(20):112-137.
[18] García-Pedrajas N,Ortiz-Boyer D.An empirical study of binary classifier fusion methods for multiclass classi-fication [J].Information Fusion,2011,12(2):111-130.
附中文参考文献:
[2] 衡 霞,王忠民.基于手机加速度传感器的人体行为识别[J].西安邮电大学学报,2014,9(6):76-79.
[3] 王忠民,曹 栋.基于蚁群算法的行为识别特征优选方法[J].西安邮电大学学报,2014,19(1):73-77.
[7] 吴 磊,房 斌,刁丽萍,等.融合过抽样和欠抽样的不平衡数据重抽样方法[J].计算机工程与应用,2013,49(21):172-176.
[8] 闫 欣.综合过采样和欠采样的不平衡数据集的学习研究[D].吉林:东北电力大学,2016.
[9] 赵 会,黄景涛,谈书才.最小二乘支持向量机的一种非均衡数据分类算法[J].微电子学与计算机,2010,27(4):33-37.
[12] 于永斌,刘清怡,毛启容,等.基于语义属性的人脸表情识别新方法[J].小型微型计算机系统,2016,37(2):332-336.
猜你喜欢
热带气象学报(2022年2期)2022-08-24
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
报刊荟萃(上)(2018年3期)2018-04-24
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
妇女生活(2016年5期)2016-05-26
