
Hadoop集群中影响应用性能的因素分析
2018-04-13 10:03马生俊陈旺虎郭宏乐乔保民李新田
小型微型计算机系统 2018年4期
马生俊,陈旺虎,郭宏乐,乔保民,李新田
(西北师范大学 计算机科学与工程学院,兰州 730070) E-mail:1780761723@qq.com
1 引 言
随着科学研究、社交网络、电子商务、互联网、移动通信等领域的蓬勃发展,每天都有大量数据的产生,且数据产生的速度越来越快.据统计,平均每秒有200万用户在使用谷歌搜索,Facebook用户每天共享的内容多达40亿条,Twitter每天处理的数量超过3.4亿[1].根据IDC(国际数据公司)的研究,与2009年相比,全球数字信息总量将在2020年增长44倍,估计能达到35.2ZB[2].数据来源广而快,数据量庞大而多样,常规的处理技术和方法已经很难满足处理需求.云计算(Cloud Computing)[3]应运而生,以并行编程模型、海量数据分布存储、海量数据管理、资源管理和虚拟化等为主要技术,其中编程模型和海量数据分布存储是最核心的技术.Hadoop[4]作为云计算的一款开源实现工具,被越来越多的国内外IT公司和高校院所应用和研究,如:雅虎的云计算系统、IBM 的蓝云项目、亚马逊的EC2都是基于Hadoop 的实现;BAT(百度、阿里、腾讯)、华为、中国移动、网易、金山等公司都不同程度的采用 Hadoop进行应用研发[5].
随着Hadoop被工业界和学术界越来越广泛地应用和高度地重视.近年来,为了在大数据处理方面取得较高的效率,研究者们在Hadoop框架与功能增强方面针对不同的应用领域做了相应的改进和优化,使性能取得了一定的改善[6].研究者们一方面着眼于优化存储方案,另一方面致力于提升处理能力,其目的是提高Hadoop集群环境的效率,减少处理成本.如:文献[7]针对异构的Hadoop集群提出了一种自适应平衡的数据存储策略;文献[8]针对Hadoop存储系统存储成本高、可扩展性低、节点负载均衡不足等问题,提出了一种基于范德蒙码的分散式动态存储策略;文献[9]针对云环境和服务器集群两种不同的环境,分析处理大数据所面临的机遇和方法,在云环境中处理大数据时,提出并设计了以资源配置和任务调度为主要问题的优化方案.
Hadoop集群环境中如何提高应用性能、减少执行时间已成为研究的热点.工欲善其事必先利其器,从而分析影响应用性能的因素至关重要.文中重点关注数据集类型、数据块大小,集群环境规模等因素;探讨不同规模的集群环境中,输入不同类型的数据集,分割成不同大小的数据块对应用性能的影响;通过实验,给出不同规模的集群环境中,输入不同类型的数据集,分割不同大小的数据块对应用性能影响的变化规律;分析实验结果,得出如何提高应用性能的结论.
本文贡献:初步探索了在Hadoop集群环境中影响应用性能的数据集类型,数据块大小,集群规模等因素,发现处理不同类型的数据集时,一方面我们应该清楚集群规模越大并不一定应用性能越好,另一方面我们可以适当的增大数据块的大小、减少map任务数以取得较好的性能.
论文后续内容安排:第二部分介绍相关工作;第三部分针对Hadoop云平台详细分析HDFS(Hadoop Distributed File System)和MapReduce并分析数据集类型和数据块大小对应用性能的影响;第四部分介绍实验,给出实验结果,分析结果发现数据集类型、数据块的大小、集群环境规模对应用性能的影响规律;第五部分给出结论并指出接下来的工作.
2 相关工作
Hadoop作为一种新的计算模式以其自身的特点和优势已被广泛应用,如何提高应用性能、减少执行时间已成为研究的热点.Hadoop集群环境中影响应用性能的因素很多,研究者们根据不同的领域,对多种因素已开展了许多研究,主要涉及文献有[10-20]等.
文献[10]从应用着手分析Hadoop存在的不足,利用作业和任务的多重并发平衡磁盘和网络带宽,减小传输瓶颈出现的可能性,以提高系统性能;该文献采用固定规模的集群环境进行实验,文中没有考虑集群规模发生变化时应用的性能将出现什么变化.文献[11]针对由物理机和虚拟机混合组成的异构集群环境进行Hadoop性能测试,得出由于虚拟机的高I/O开销,导致Hadoop的性能相比传统的纯物理节点集群急剧降低;该文献采用不同的数据量进行测试;但没有考虑集群环境规模和数据块大小的变化对固定数据量执行时间的影响.文献[12]和文献[13]从单机环境和分布式环境的角度采用多种经典数据集测试Hadoop框架的几种文件输入方式处理小文件的性能差异,得出减少任务数有利于提高性能的结论;但是,两文献只是从单一角度进行实验说明,未对单机和分布式两种环境进行统一的测评.文献[14]通过在Amazon EC2(Elastic Compute Cloud)的两种不同类型的虚拟机上搭建Hadoop集群环境测试Wordcount,TeraSort等多种应用,得出集群规模的变大可提高应用处理效率、减少执行时间;该文献考虑了集群规模的变化对应用性能的影响,但没有考虑数据集类型以及对相同大小的数据集分割成不同大小的数据块对应用性能的影响.文献[15]通过在OpenStack云平台搭建Hadoop集群测试影响应用执行性能的因素,得出数据量的大小和集群规模是影响应用性能的主要因素;该文献采用任务数的默认个数,没有考虑在数据量和集群规模一定时划分不同大小的数据块对应用执行性能的影响.文献[10-15]不同程度的从各个方面探讨影响Hadoop框架性能的因素,但是尚未对集群环境规模、数据集类型、数据块大小进行深入的探讨.
此外,文献[16]考虑了影响节点存储性能的CPU、内存、系统结构、磁盘的读写速度等因素,提出了一种对节点存储性能进行度量的方法,在数据存储时综合考虑节点的存储性能和节点与客户端的网络距离两个因素进行数据节点的选择,改进数据放置的负载均衡、提高异构集群的数据传输速率.文献[17]提出了一种基于XOR码的编码和译码方式相对简单的优化策略,可进行数据的恢复操作.文献[18]针对作业过程中数据传输和数据处理流程,提出了虚拟网络拓扑结构的优化机制,减少了数据传输和处理的总开销,提高了MapReduce云框架处理大数据的整体性能.文献[19]为大规模增量计算扩展了Hadoop框架提出了一种新的Hadoop框架——Incoop.Morton K[20]等人为有效预测作业结束时间提出了一种计算MapReduce执行进度的算法等很多算法层面的改进.文献[16-20]从Hadoop框架着手,针对不同的应用领域,采用不同的方法对其进行改进和优化,期望提高Hadoop框架的性能.
上述研究中,有从Hadoop框架本身出发补充其不足,扩展其应用领域;更有探讨影响Hadoop集群环境性能的因素,如集群环境的异构,内部处理机制,集群规模以及网络环境等多种因素.但是,没有将集群规模、数据集类型和数据块的大小对Hadoop集群环境性能的影响进行统一分析.文中重点关注了输入不同类型的数据集,分割不同大小的数据块在不同规模的集群中对应用性能的影响.
3 Hadoop介绍及因素分析
Hadoop是由Apache Software Foundation 公司受到 Google Lab 开发的 Map/Reduce 和 GFS(Google File System) 的启发所开发的分布式系统基础架构.Hadoop框架最核心的设计是HDFS和MapReduce.HDFS为海量的数据提供了永久存储,则MapReduce为海量的数据提供了高效计算[21].
3.1 HDFS数据分布存储技术
HDFS是一个主/从(Master/Slave,M/S)结构的存储海量数据的系统,用来存储大量的数据.用户看来,HDFS与传统的文件系统一样,可以通过目录对文件执行增删改查等操作.有一个主节点(Namenode)和若干从节点(Datanode)组成.Namenode负责管理文件系统的命名空间,记录文件数据块在每个Datanode上的位置和副本信息,协调客户端(Client)对文件的访问,记录命名空间内的改动或命名空间本身属性的改动.Datanode存放实际的数据,一个文件被物理地切割成若干数据块(Block)(默认大小为64M),这些Block尽可能分散地存储在不同的Datanode上,HDFS为保证数据的安全性在不同的机架上设置了Block的副本(默认备份数为3).
HDFS的工作过程是Client请求操作文件的指令由Namenode接收,Namenode将存储数据的Datanode的IP返回给客户端,并通存放副本的Datanode,由Client直接从Datanode读取文件数据.与此同时,Namenode更新其的元数据内容,不参与文件的传送.整个文件系统采用标准的TCP/IP协议通信.其系统的架构如图1所示.

图1 HDFS架构示意图Fig.1 HDFS architecture
3.2 MapReduce并行编程模型
MapReduce是一种主/从结构的处理海量数据的并行编程模型和计算框架,用于对大规模数据集的并行处理.MapReduce 采用一种“分解归约”的基本思想,把对大规模数据集的操作,分发给一个主节点(Jobtracker)管理下的各个分节点(Tasktracker)共同完成,然后整合各个Tasktracker的中间结果得到最终的结果.上述处理过程被MapReduce抽象为map和reduce两个函数;map函数负责把任务分解成多个子任务,reduce函数负责把子任务处理的结果汇总起来.

图2 MapReduce执行过程示意图Fig.2 MapReduce execution flow
在Map阶段,MapReduce将任务的输入数据逻辑地划分成固定大小的多个片段(Split),然后将每个Split进一步处理成一批< K1,V1 >(键值对).首先,Hadoop为每个Split创建一个map任务用于执行用户定义的map函数;其次,将对应Split中的< K1,V1 >作为输入,得到中间结果
3.3 因素分析
通过3.1和3.2对Hadoop核心框架的介绍,可以知道Hadoop处理数据时,先通过HDFS将数据按固定大小物理地分割为多个Block,以Block为单位分散地存储在节点上;后通过MapReduce将这些Block参照用户定义逻辑地划分为多个Split,并以Split为单位处理数据.可见,Block是存储数据的单位,Split是处理数据的单位.可以将Hadoop数据处理流程用图3简单表示.

图3 Hadoop数据处理流程图Fig.3 Hadoop data processing flow
一般地,采用默认大小将数据集物理地分割为多个Block时,有多少个Block就会逻辑划分成多少个Split,一个Split就是一个map任务,而一个Split只能包含一个文件中的数据即不会同时包含两个及以上文件中的数据[22].换句话说,数据集中只有一个文件且数据量大于Block的大小时,有多少个Block就有多少个map任务;数据集中有多个文件且每个文件的数据量都小于Block的大小时,有多少个文件就有多少个map任务.
Hadoop设计的初衷是为了处理大文件数据集,处理数据量少在GB,大至PB,甚至更大的文件数据集[23].大多数企业或者科研单位拥有PB级的存储数据集,这些数据集既有达到几十GB的大文件,又有仅为几十KB的小文件[24];对于几十GB的大文件,分割的Block数就是执行的map数,对于十几KB的小文件,文件数才是执行的map数.假设现有一数据集需要处理,其数据量大小为10GB,按照Hadoop默认Block大小(64MB)分割,若数据集只包含一个大文件,则需要执行的map数约为160个;若数据集包含多个平均大小为32KB的小文件,则需要执行的map数约为327680个,相比之下,可以发现处理小文件执行的map数远远大于大文件执行的map数.
在数据量一定的情况下,面对大文件和小文件构成的数据集,是采用Hadoop默认的Block大小分割数据,还是根据数据集的构成类型选择合适的Block大小分割数据,即分割成不同大小的Block会对应用性能有什么样的影响,性能的差异又如何,急需一个量化的描述.故此,文中主要探讨在不同规模的Hadoop集群环境,输入不同类型的数据集,分割成不同大小的Block对应用性能的影响.
4 实验分析
4.1 实验平台
实验用到的物理机为11台联想 ThinkServer RD650 服务器即11个节点(Node).所有节点的硬件配置是GenuineIntel处理器、32G内存、2T硬盘.所有节点都是CentOS 7.0操作系统,JDK 1.8.0_101JDK环境,Hadoop-2.6.4云框架.实验系统环境如表1所示.
4.2 实验设计
实验中的11个Node,其中一个为主节点(master),其余都为从节点(slave).因实验用于探讨在不同规模的Hadoop集群环境中,输入不同类型的数据集,分割不同大小的数据块对应用性能的影响,所以实验以最简单也是最能提现MapReduce思想的单词计数Wordcount程序作为测试应用.由于Hadoop集群环境是一种分布式的环境,在任务执行时需要大量的数据传输,为尽可能的减少网络对实验的影响,在实验环境中,将11个Node连接在同一台普联TL-SG1024DT千兆机架式交换机上形成一个局域网,网络带宽为1000Mb/s,网络拓扑如图4所示.
表1 实验环境
Table 1 Experiment environmnet

操作系统CentOS7.0Hadoop环境Hadoop-2.6.4JDK环境JDK1.8.0_101硬件配置GenuineIntel处理器32G内存2T硬盘

图4 实验网络拓扑图Fig.4 Network topology desining in the experiment
实验数据来源于100本英文txt类型的名著,根据不同的数据集类型,将数据进行处理,通过多次拷贝得到实验要求的数据量2048MB.实验中Block的大小可修改配置文件(hdfs-site.xml)中dfs.block.size的大小得到满足实验要求的Block,其他保持默认配置,如数据备份数为3,Reduce任务数为1.
实验中不同大小的Block(单位:MB)变化如表2所示.
表2 数据块大小变化表
Table 2 Value range of Block size

TimesBlockSize116232364412852006256
实验中集群环境规模采用两种规模.
ClusterScale-1(CS1):集群环境中只有1个Slave节点.
ClusterScale-2(CS2):集群环境中有10个Slave节点.
实验中数据集的类型采用两种类型.
DatasetType-1(DT1):由1个大txt文件组成.
DatasetType-2(DT2):由100个小txt文件组成.
4.3 实验结果
根据4.2实验设计,分别在两种集群环境规模(ClusterScale-1,ClusterScale-2)中对两类数据集(DatasetType-1,DatasetType-2)设置不同大小的Block进行实验.对每一次实验都进行3遍求其平均值,得到map和reduce任务执行时间即M-time和R-time,求和M-time和R-time得到任务执行的总时间T-time,分别得如下结果(时间单位为:ms).
1)在集群规模为ClusterScale-1,数据集类型为DatasetType-1时实,验结果如表3所示.
表3 实验结果表-11
Table 3 Experiment results-11

TimesMapperM-timeR-timeT-time1128540785119276660061264377752750144527663322860324426033029241623444117204251645511217563149822325456820970013854223554
2)在集群规模为ClusterScale-1,数据集类型为DatasetType-2时,实验结果如表4所示.
表4 实验结果表-12
Table 4 Experiment results-12

TimesMapperM-timeR-timeT-time1130554169122728676897210549679795670592467310048091793874574791410047881291799570611510047152291654563176610046630491557557861
3)在集群规模为ClusterScale-2,数据集类型为DatasetType-1时,实验结果如表5所示.
表5 实验结果表-21
Table 5 Experiment results-21
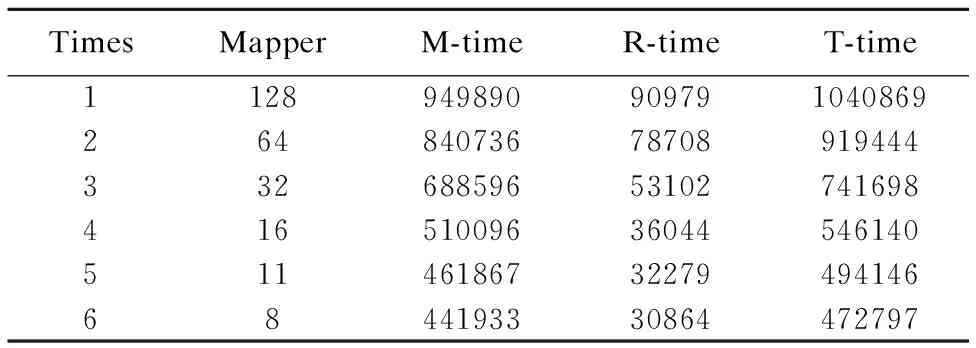
TimesMapperM-timeR-timeT-time1128949890909791040869264840736787089194443326885965310274169841651009636044546140511461867322794941466844193330864472797
4)在集群规模为ClusterScale-2,数据集类型为DatasetType-2时,实验结果如表6所示.
表6 实验结果表-22
Table 6 Experiment results-22

TimesMapperM-timeR-timeT-time1130100221675345107756121059581287712910352573100936903783001015203410093538277408101279051009276917742210051136100926223756381001861
4.4 实验分析
1) 在集群规模相同、数据集类型不同的情况下由图5,图6可知,在由1个Slave或10个Slave节点组成的集群环境下,将数据量相同的两类数据集分割成不同大小的Block时,处理单文件数据集的时间越来越少于多文件数据集;且随着Block的增大,处理单文件数据集的时间呈先迅速后缓慢的趋势越来越少,而处理多文件数据集的时间基本不变.

图5 小规模集群下数据集类型对时间的影响Fig.5 Impact of dataset type on execution time in the 1 slave node cluster
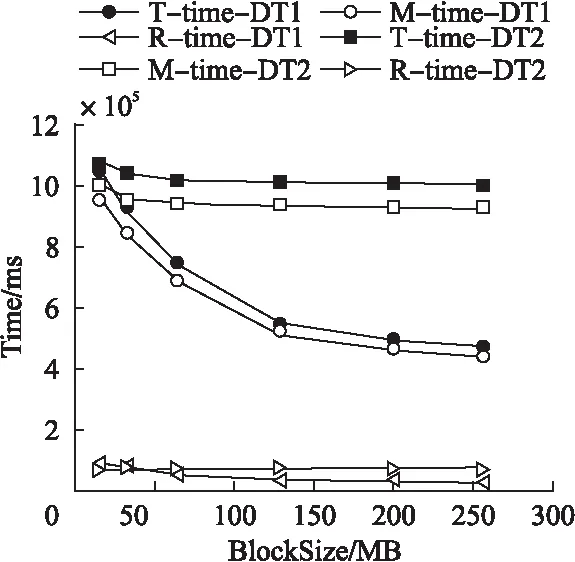
图6 大规模集群下数据集类型对时间的影响Fig.6 Impact of dataset type on execution time on the 10 slave node cluster
分析表3至表6发现map任务数是导致两类数据集的处理时间呈上述变化的原因.例如,在Block为16MB时,两类数据集的map任务数(128,130)基本相等,所以在此处两类数据集的处理时间基本相等;随着Block的增大,单文件数据集的map任务数呈指数变化趋势减少,其处理时间以一致的趋势减少;而多文件数据集的map任务数基本保持在100未变,其处理时间也以一致的趋势基本保持不变.
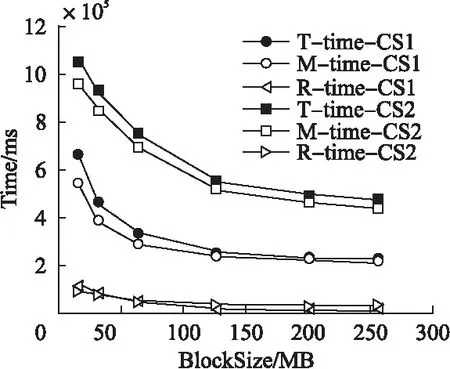
图7 单文件数据集下集群规模对时间的影响Fig.7 Impact of cluster scale on execution time under the unique file dataset

图8 多文件数据集下集群规模对时间的影响Fig.8 Impact of cluster scale on execution time under the multiple file dataset
2)在数据集类型相同、集群规模不同的情况下.由图7和图8可知,在两种规模的集群环境下,将数据量相同的多文件数据集分割成不同大小的Block处理时,1个Slave节点组成的集群所需的时间大约是10个Slave节点组成的集群所需时间的1/2;然而,reduce任务的执行时间基本相等,map任务的执行时间相差约为1/2,可知map任务是导致此现象的决定因素.
5 总 结
Hadoop集群环境中影响应用性能的因素很多.文中重点关注不同规模的集群环境、不同类型的数据集、不同大小的数据块对应用性能的影响.采用Hadoop云框架单词统计(Wordcount)应用作为测试应用进行实验;分析实验结果可得,一方面,在相同规模的集群环境下,将数据量相同的两类的数据集分割成不同大小的Block处理时,随着Block的增大,两类数据集的处理时间随着各自map任务数的变化趋势变化,且单文件数据集的处理性能明显优于多文件数据集.另一方面,相同量的数据集下,在两种规模的集群环境中将数据集分割成不同大小的Block处理时,1个Slave节点组成的集群的处理效率大约是10个Slave节点组成集群的2倍,且map任务的执行效率是导致此现象的决定因素,这是一个奇怪的现象,理应处理相同的数据量,多个节点处理的效率应比单个节点更高才是.
本文工作可以作为研究Hadoop集群环境中影响应用性能因素的一个重要基础.下一步,将研究文中出现的奇怪现象——大规模集群环境的处理效率远低于小规模集群环境,进而深入分析和探讨Hadoop集群环境中影响应用性能的因素,尽可能全面地分析各种因素对应用性能的综合影响.
[1] Feng Deng-guo,Zhang Min,Li Hao.Big data security and privacy protection[J].Chinese Journal of Computers,2014,37(1):246-258.
[2] Xu Ji,Wang Guo-yin,Yu Hong.Review of big data processing based on granular computing[J].Chinese Journal of Computers,2015,38(8):1497-1517.
[3] Mell P,Grance T.The NIST definition of cloud computing[J].Communications of the Acm,2011,53(6):50.
[4] Hao Shu-kui.Brief analysis of the architecture of Hadoop HDFS and MapReduce[J].Designing Techniques of Posts and Telecommunications,2012,21(9):37-42.
[5] Wang L,Laszewski G V,Younge A,et al.Cloud computing:a perspective study[J].New Generation Computing,2010,28(2):137-146.
[6] Dong Xin-hua,Li Rui-xuan,Zhou Wan-wan,et al.Performance optimization and feature enhancements of Hadoop system[J].Journal of Computer Research and Development,2013,50(S2):1-15.
[7] Zhang Shao-hui,Zhang Zhong-jun,Yu Lai-xing.A big data placement strategy for adaptive balance data storage in heterogeneous Hadoop cluster[J].Modern Electronics Technique,2016,39(10):49-53.
[8] Song Bao-yan,Wang Jun-lu,Wang Yan.Optimized storage strategy research of HDFS based on vandermonde code[J].Chinese Journal of Computers,2015,38(9):1825-1837.
[9] Ang D,Liu J.Optimizing big data processing performance in the public cloud:opportunities and approaches[J].Network IEEE,2015,29(5):31-35.
[10] Luan Ya-jian,Huang Chong-min,Gong Gao-sheng,et al.Reasearch on performance optimization of Hadoop platfrom[J].Computer Engineering,2010,36(14):262-263.
[11] Liu Dan-dan,Chen Jun,Liang Feng,et al.A performance analysis for Hadoop under heterogeneous cloud computing environments[J].Journal of Integration Technology,2012,1(4):46-51.
[12] Yuan Yu,Cui Chao-yuan,Wu Yun,et al.Performance analysis of Hadoop for handling small files in single node[J].Computer Engineering and Applications,2013,49(3):57-60.
[13] Li San-miao,Li Long-shu.Performance analysis of four methods for handling small files in Hadoop[J].Computer Engineering and Applications,2016,52(9):44-49.
[14] Gohil P,Garg D,Panchal B.A performance analysis of MapReduce applications on big data in cloud based Hadoop[C].2014 International Conference on Information Communication and Embedded Systems,Chennai:IEEE,2015:1-6.
[15] Ahmad N M,Yaacob A H,Amin A H M,et al.Performance analysis of MapReduce on OpenStack-based hadoop virtual cluster[C].2014 IEEE 2nd International Symposium on Telecommunication Technologies,Langkawi:IEEE,2014:132-137.
[16] Wang Yong-zhou,Mao Su.A blocks placement strategy in HDFS[J].Computer Technology and Development,2013,23(5):90-92.
[17] Zhu Y,Lee P P C,Hu Y,et al.On the speedup of single-disk failure recovery in XOR-coded storage systems:theory and practice[J].Mass Storage Systems & Technologies,2012,22(5):1-12.
[18] Li Li-yao,Zhao Shao-ka,Xu Hua-rong.MapReduce performance optimization strategy based on a cloud platform[J].Journal of Lanzhou University(Natural Sciences),2015,51(5):752-758.
[19] Bhatotia,Pramod,Wieder,et al.Incoop:MapReduce for incremental computations[C].Proceedings of the 2nd ACM Symposium on Cloud Computing,New York:ACM,2011:1-14.
[20] Morton K,Friesen A,Balazinska M,et al.Estimating the progress of MapReduce pipelines[C].2010 IEEE 26th International Conference on Data Engineering,California:IEEE,2010:681-684.
[21] Junqueira B F,Reed B.Hadoop:the definitive guide[J].Journal of Computing in Higher Education,2001,12(2):94-97.
[22] Tom White.Hadoop:the definitive guide[M].Beijing:Tsinghua University Press,2015:256-258.
[23] Jia Yu-chen.Design and implementation of the key techniques for storing and retrieving massive small files in hadoop[D].Nanjing:Nanjing University of Posts and Telecommunications,2015:3-4.
[24] Llc C S P.Cloud computing introduction[C].2014 IEEE Technology Time Machine Symposium,San Jose:IEEE,2014:1-1.
附中文参考文献:
[1] 冯登国,张 敏,李 昊.大数据安全与隐私保护[J].计算机学报,2014,37(1):246-258.
[2] 徐 计,王国胤,于 洪.基于粒计算的大数据处理[J].计算机学报,2015,38(8):1497-1517.
[4] 郝树魁.Hadoop HDFS和MapReduce架构浅析[J].邮电设计技术,2012,21(9):37-42.
[6] 董新华,李瑞轩,周湾湾,等.Hadoop系统性能优化与功能增强综述[J].计算机研究与发展,2013,50(S2):1-15.
[7] 张少辉,张中军,于来行.异构Hadoop集群下自适应平衡数据存储的大数据放置策略[J].现代电子技术,2016,39(10):49-53.
[8] 宋宝燕,王俊陆,王 妍.基于范德蒙码的HDFS优化存储策略研究[J].计算机学报,2015,38(9):1825-1837.
[10] 栾亚建,黄翀民,龚高晟,等.Hadoop平台的性能优化研究[J].计算机工程,2010,36(14):262-263.
[11] 刘丹丹,陈 俊,梁 锋,等.云计算异构环境下Hadoop性能分析[J].集成技术,2012,1(4):46-51.
[12] 袁 玉,崔超远,乌 云,等.单机下Hadoop小文件处理性能分析[J].计算机工程与应用,2013,49(3):57-60.
[13] 李三淼,李龙澍.Hadoop中处理小文件的四种方法的性能分析[J].计算机工程与应用,2016,52(9):44-49.
[16] 王永洲,茅 苏.HDFS中的一种数据放置策略[J].计算机技术与发展,2013,23(5):90-92.
[18] 李立耀,赵少卡,许华荣.基于云平台的MapReduce性能优化策略[J].兰州大学学报:自然科学版,2015,51(5):752-758.
[22] Tom White.Hadoop权威指南[M].北京:清华大学出版社,2015:256-258.
[23] 贾玉辰.Hadoop中海量小文件存取关键技术的设计与实现[D].南京:南京邮电大学,2015:3-4.
猜你喜欢
科学与社会(2022年1期)2022-04-19
今日农业(2021年8期)2021-11-28
智能制造(2021年4期)2021-11-04
北京大学学报(自然科学版)(2021年3期)2021-07-16
纺织科学研究(2021年6期)2021-07-15
电脑爱好者(2020年19期)2020-10-20
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
汽车零部件(2017年2期)2017-04-07
知识就是力量(2017年2期)2017-01-21
