
融合偏好交互的组推荐算法模型
2018-03-27 01:27:58李博涵王雅楠秦小麟
小型微型计算机系统 2018年2期
郑 伟,李博涵,2,3,王雅楠,秦小麟,2
1(南京航空航天大学 计算机科学与技术学院,南京 211106) 2(软件新技术与产业化协同创新中心,南京 210016) 3(江苏易图地理信息科技股份有限公司,江苏 扬州 225000)
1 引 言
在当今信息时代当中,电子商务的发展十分迅速,并且在日常生活当中得到了广泛的普及,随着网络信息的飞速增长,信息过载的问题日益严重,而推荐系统(Recommender Systems)可以有效缓解该问题,因此推荐系统已经逐渐成为人们关注和研究的焦点[1].目前大多数领域的推荐系统仅仅是针对单个用户进行推荐,然而在日常生活中用户的很多消费行为都是以组群的形式参与的,比如多个用户一起去聚餐、旅行、看电影、订外卖等,针对这种多个用户参与的情况,推荐系统则需要考虑到组内用户之间的协同问题,因此其算法设计和模型实现过程要比单用户的推荐系统更为复杂,这种由多个用户共同参与的推荐系统被称之为组推荐(Group Recommendations)[2].组推荐与单用户推荐在过程上最主要差别是组推荐需要对组成员的偏好进行融合,并通过各种形式的融合策略使推荐结果在总体满意度、公平性、可理解性方面达到相应的需求.
在组推荐的过程中,由于群组成员准备共同进行消费活动,所以一般情况下组内成员之间会进行一些交互活动或将要进行一些交互活动,比如互相交流一下自己曾经的消费状况或者自己的喜好等,而这些交互活动往往会对组内其他成员的未知偏好造成一定影响,比如现实生活中存在如下实例.
例:A、B、C三个用户相约看电影.其中,A曾经观看过电影I并且对电影I进行过评分,而B和C并未观看过电影I,也就是说用户A对电影I的偏好已知而用户B、C对电影I的偏好未知.因此如果三个用户之间关于电影I发生交互,那么A对电影I的偏好(评分)在交互过程中将会在一定程度上影响到B和C对电影I的未知偏好.
目前大多数的组推荐算法当中,并没有考虑到上述这种交互关系,然而这种交互关系的影响在组推荐当中往往尤为重要,这也是组推荐区别于单用户推荐的主要特性之一.虽然已经有部分组推荐的研究工作当中考虑到了成员交互的这种影响关系,但是这些研究工作着重研究的是在偏好融合过程中的组内成员影响关系,其主要思想是根据组内成员的特征、角色、影响力等因素给每个用户分配不同的权重,然后根据该权重对成员的偏好进行融合,通过用户权重的方式去体现用户之间的这种交互关系,这些方式都无法体现出群组中已知偏好对于未知偏好的影响作用.
本文提出的偏好交互模型与以往组推荐中的偏好交互有所不同,模型着重考虑的是偏好交互对于组内成员中未评分项的影响,也就是说如果组内的某个成员对于特定物品的评分未知,那么就表明该成员对于该物品完全不了解,此时基于情绪传染以及一致性等社会现象[3],该成员对该物品的偏好自然地会受到组内其他已评分用户的影响,该种类型的影响区别于相关文献中的用户权重的交互方式,因为对于未知的物品,人们对他人的依赖作用会加大,从而其潜在偏好不单纯受限于组内其他用户在群组中影响力因素的影响.
基于以上考虑,本文的工作主要是针对在组推荐中组内用户评分预测过程的优化处理,为了在组推荐过程中体现出以上这种影响关系,提出了一种融合偏好交互的组推荐算法模型,其主要思想是在用户评分预测的过程中加入偏好交互的因素,而并非局限于偏好融合过程,并通过用户的历史成组信息以及推荐后评分反馈生成用户的个性化组推荐参数,从而在推荐过程当中实现用户之间偏好的模拟交互,进而提高推荐结果的真实满意度和准确率,主要有以下贡献:
1)提出了传统组推荐系统中未考虑到的影响因素,即组内已评分用户对未评分用户潜在偏好的影响,并分析了其影响对组推荐的重要性.
2)基于用户间潜在的偏好影响,设计了模拟交互的组推荐偏好预测模型.该模型作为一种组推荐偏好预测的优化,可以与其他组推荐算法结合从而提高推荐结果的准确率.
3)基于上述预测模型,提出了一种偏好模拟交互式的组推荐系统框架.通过该框架,可以将算法模型应用到实际组推荐当中,增加其实用性.
4)将本模型与UBCF与IBCF算法结合,并通过使用MovieLens数据集对模型的性能进行评估和验证,实验结果表明在存在偏好交互作用的群组当中,融合偏好交互的算法的表现明显优于传统算法.
2 相关工作
2.1 偏好预测
推荐系统对于用户偏好预测一般采用协同过滤的方法,该方法是通过相似度测量去预测推荐项.按照不同的相似度计算对象协同过滤主要分为两种类型:基于用户的协同过滤(UBCF)和基于物品的协同过滤(IBCF).当拥有用户-物品评分矩阵时,需要计算用户之间或物品之间的相似度,在推荐系统中通常会使用皮尔逊相似度,以UBCF为例,皮尔逊相似度计算用户u和用户v之间的相似度公式如下:
(1)
其中ru,i为用户u对于物品i的评分,如果将∑i∈I替换成∑i∈Iu∩Iv,公式则变为只考虑用户u,v共同评分的项目,得到的sim(u,v)取值为-1到1,其值越高表示相似度越高.
在获得了用户之间的相似度后,可以得到与目标用户u相似的一组用户集合S,于是目标用户u对于物品i的预测评分可以表示为:
(2)
对于IBCF的相似度计算以及评分预测公式也可根据上述方法相似得出,不再罗列.
2.2 推荐融合
传统的推荐系统是针对单个用户进行推荐的,那么对用户的未评分项进行预测之后就可以基于用户-物品的评分矩阵进行物品的推荐了,然而对于组推荐而言,推荐的结果需要满足所有组内成员的需求,因此还需要考虑到对所有组内成员进行协同的问题,进而需要通过一定的融合策略对组内成员的偏好进行融合.
根据在组推荐中偏好融合发生的阶段不同,偏好融合的内容也不同,主要分为两类:推荐结果融合[12]和评分融合[11].推荐结果融合是指先根据组内用户的个人偏好生成其个人的推荐列表,然后再对组内所有用户的个人推荐列表按照融合策略进行融合得到组的推荐列表.评分融合是指先将组内的所有成员的评分偏好融合成一个总体的偏好评分作为群组的评分,然后再根据该评分对组进行进一步推荐.由于偏好融合过程当中会涉及到每个用户对候选物品的评分,所以对于用户未评分项目经常需要先对其进行预测,然后在对组成员的偏好进行融合,因此该过程多与协同过滤方法结合来最终生成组推荐的推荐结果.
2.3 群组推荐
MusicFX[13]是最早的组推荐研究工作之一,它的方法是分析个人用户的偏好,为用户组找到相对合适的音乐去播放.PolyLens[15]是单用户推荐系统MovieLens的一个扩展,它目的是为群组用户去推荐合适的电影,它是通过协同过滤去预测个人未评分项,融合个人偏好最终得到组的整体偏好.除此之外,Gartrell等人[16]利用了社会关系对偏好影响的交互作用,他们提出了一种一致性函数,函数合并了三大要素:分歧要素,社会要素和专家要素,首先将这三大要素进行量化,然后使用一致性函数将其合并为一个单独的值,该方法可以高效地合并个人推荐列表.Chen等人[6]提出了一种在组推荐融合中加入交互的方法,他认为在群组推荐融合的过程中不同用户拥有着不同的群组影响力,并通过遗传算法去获取组内成员的权重,一定程度上提高了偏好融合过程的公平性.Campos等人[17]用贝叶斯网络表示群组成员间的交互及群组决策过程,通过贝叶斯网络学习方法根据用户历史评分获取群组成员间的偏好影响关系.后续也有很多的研究工作通过各种方法去获取组推荐中不同用户的影响度权重.
经调研,虽然现有的部分算法提及到了用户之间的偏好交互,但其交互过程与本文提出算法模型的交互过程两者的立足点不同,之间并不冲突,其主要区别如下:现有文献的交互过程其关键在于权重,即不同用户的不同影响力,其交互作用于推荐融合的过程.本文算法中的交互过程其关键在于未知偏好受到的影响,其交互作用于评分预测的过程.综上,本文中的交互作为传统组推荐算法的一种补充仍具有一定的研究意义.
3 融合偏好交互的组推荐算法
3.1 组成员间的偏好交互
在组推荐当中,由于参与到推荐的是一组用户,在群组中用户之间必然存在互相的关联,从而必不可少会发生一些交互活动,群组中某些用户的未知项在交互的过程当中就会受到组内其他成员的影响,从而改变群组成员的偏好,比如,将引言当中实例进行展开说明,由用户A、B、C组成的群组G准备共同观看一场电影,他们对于Titanic,Star Wars两部电影的评分记录如图1,其中“?”表示该用户并未做过评分即未观看过该部电影.在群组G中,对于Titanic这部电影只有A对其进行过评分,而Star War这部电影只有A、B做过评分,因此若该组内存在交互作用,那么用户B、C对于Titanic的未知评分将会受到用户A对其的评分5的影响,用户C对于Star War的未知评分将会受到用户A对其评分3以及用户B对其评分4的影响.
因此基于上述影响关系,提出了如下的受到组内成员偏好交互影响的评分预测方法,其定义如下:
(3)
其中R(I)u,i表示群组g中的用户u对于自己未评分的物品i受到群组其他成员偏好交互影响的评分.Ug,i表示在群组g中所有对物品i评过分的用户集合.wu,v表示用户v对用户u的影响权重,在现实的情况下,组内用户之间的影响程度可能并不相同,因此在生成R(I)u,i的时候应考虑到不同用户影响程度的关系,下面给出一种隐式获取wu,v的方法.
在现实生活中关系越密切的人往往会一起活动的频率会更高,彼此之间的影响程度也会越大,所以wu,v也可以用来表示为两人关系的亲密度,因此可以通过用户之间的亲密度去近似wu,v的值.如果在没有用户之间亲密关系的数据来源的情况下,对于wu,v的取值可以基于这样一种思想:如果用户之间共同进行活动的次数越多,那么用户之间的关系越密切,wu,v的取值就越高.因此对于wu,v定义如下:
wu,v=1+lg(su,v+1)
(4)
其中su,v代表用户u,v之间共同进行活动的次数,若wu,v随着su,v的变大而呈线性方式增长,显然对于实际应用来说不太合理,因此对于su,v的值进行了对数处理来限制其增长速度,随着模型的不断被使用,wu,v的值也逐渐趋于稳定,不同用户之间的亲密度区别程度也将更加明显.此外用户之间的亲密程度并非是一成不变的,随着时间和环境等因素的变化用户之间的亲密度可能会发生一些变化,因此在对su,v取值的时候可以根据不同的应用场景设定不同的阈值,在增加阈值之后su,v可以如下定义:在n个月内用户u,v之间共同活动的次数,或在最近的n次活动中用户u,v之间共同活动的次数,其中n为所设定的阈值.
3.2 融合偏好交互的组推荐偏好预测算法
由公式(3)已经获得了经过组内成员偏好交互影响的评分预测方法,但是由于用户本身的个人喜好不同,对于用户的未评分项目,用户并不会完完全全放弃个人原本的喜好,因此用户依然会保留用户本身对于某项物品的基本看法,对于这部分因素对预测评分的影响,将其定义为自我预测部分R(S).对于自我预测部分,一般采用以评分为基准传统的偏好预测算法,其中最典型的方法就是协同过滤,因此在下文中涉及到R(S)的部分主要应用UBCF和IBCF两种方法进行说明和解释.
基于上述基本想法,提出了一种融合偏好交互的组推荐偏好预测模型,该模型结合了用户在群组活动中对于某件物品的偏好交互影响以及自我预测的影响,对于该预测模型给出以下基本公式:
Ru,i=euR(I)u,i+(1-eu)R(S)u,i
(5)
其中Ru,i表示用户u对物品i的预测评分,eu表示组内偏好交互部分对于用户u的影响力,1-eu表示自我预测部分对于用户u的影响力,整个偏好交互改进的评分预测过程如算法1所示,该算法是将本模型与UBCF算法结合来进行说明的.之所以应用到了eu这个参数,是因为考虑到用户在群组中受到他人的影响程度的不同,有些用户自我意识比较强,对于自己未知的物品也不太容易受到他人的影响,该类用户的eu值偏低,而有些用户则恰好相反,他们对于未知物品的偏好更容易受到他人的影响,该类用户的eu值则会偏高.
算法1.融合偏好交互的UBCF算法 I-UBCF
输入:未评分项所属的用户u和物品i,以及u所属的群组g
输出:未评分项的预测评分Ru,i
1. RatedGroup←getRatedUsers(g,u,i);
//获取群组内所有除用户u外对i评过分的用户集合
2.ifrateGroup == nullthen
3.Ru,i← UBCF(u,i);
//评过分的用户集合为空时应用UBCF方法预测ru,i
4.else
5.influencedRating← 0;
6.weightAmount← 0;
7.foreveryRatedUserin RatedGroupdo
8.influencedRating←influencedRating+wu,ratedUser(rratedUser,i-ave(rratedUser));
//累加所有组内用户的影响评分
9.weightAmount←weightAmount+wu,ratedUser;
//累加所有拥有影响作用的用户权重
10.endfor
11.RIu,i←ave(ru) +influencedRating/weightAmount;
//计算偏好交互部分的评分
12.RSu,i← UBCF(u,i); //计算自我预测部分的评分
13.Ru,i←eu*RIu,i+ (1-eu)*RSu,i;
//计算获取I-UBCF的预测评分
14.endif
15.returnRu,i; //返回未评分项的预测评分
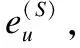
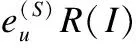
将上述公式经过变换,可得:
(6)
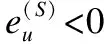
算法2.交互参数eu获取算法CalculateInteraction
输入: I-UBCF的自我预测部分评分RSu,i,偏好交互评分RIu,i
推荐后用户真实评分ru,i
输出:一次获取的eu值
1.ifRIu,i!=RSu,ithen

3.ifeus< 0then
4.eus← 0; //小于0的值则赋0
5.elseifeus>1then
6.eus← 1; //大于1的值则赋1
7.endif
8.ifEu.length == 10then
9. removeOldestElement(Eu);
//当Eu包含元素满10个则删除最早的元素
10.endif
12.endif
13.eu← sum(Eu) / Eu.length;
//计算Eu中元素的平均值并赋值给eu
14.returneu; //返回eu的值

(7)
3.3 算法应用

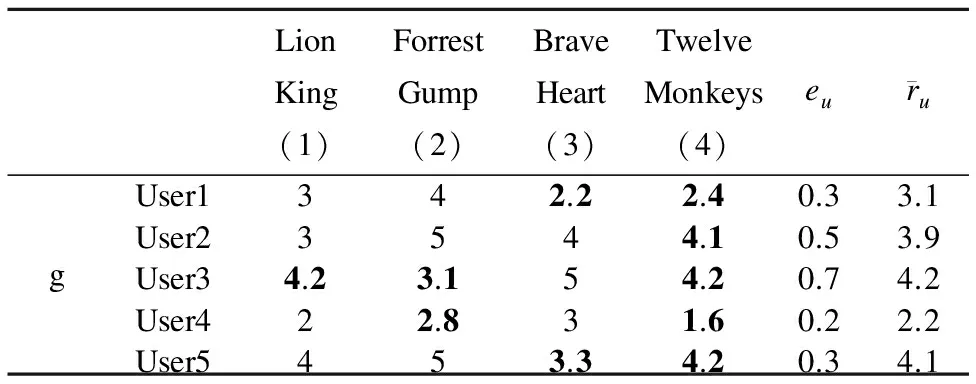
表1 群组g的用户信息表
Table 1 User information Table of group g
LionKing(1)ForrestGump(2)BraveHeart(3)TwelveMonkeys(4)eurugUser1342.22.40.33.1User23544.10.53.9User34.23.154.20.74.2User422.831.60.22.2User5453.34.20.34.1
表2 群组g的用户6个月内的成组记录表
Table 2 Grouped record of group g in 6 months
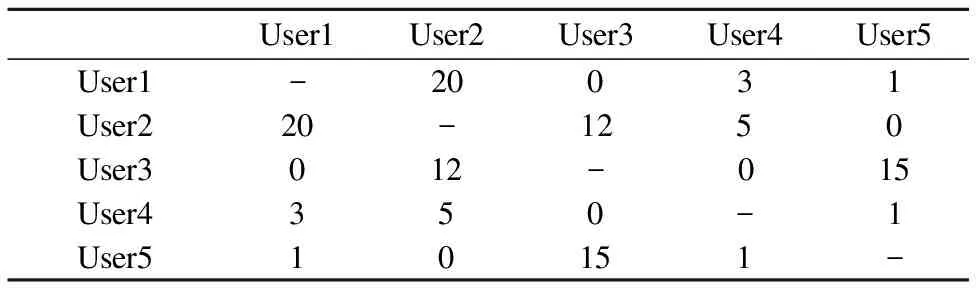
User1User2User3User4User5User1-20031User220-1250User3012-015User4350-1User510151-
首先根据表2当中的数据,应用公式(4)先计算获得群组g中用户之间的亲密度wu,v,比如w1,2=1+lg21因此w1,2=2.32,w1,3=1+lg1因此w1,3=1,其他成员间的亲密度也可相似得出.
得到成员之间亲密度后便可以对评分预测中偏好交互部分的评分进行计算了,以User1对于Brave Heart的偏好交互部分计算为例.首先获取组内所有对Brave Heart评过分的用户,可以得到组内用户User2,User3,User4,因此User1对于Brave Heart的偏好将受到User2,User3,User4的影响,并获取User1与他们的亲密度分别为w1,2=2.32,w1,3=1,w1,4=1.6,由公式(3)可计算得User1对于Brave Heart偏好交互部分的预测评分R(I)1,3=3.3,接下来将自我预测和偏好交互两部分的评分进行融合,由表2,User1的受交互影响度e1=0.3,用户通过协同过滤自我预测的评分R(S)1,3=2.2,因此由公式(5)可以计算获得通过偏好交互调整的User1对Brave Heart的评分R1,3=2.5.对于User1对Twelve Monkeys的评分预测过程,由于组内不存在曾经对Twelve Monkeys评过分的用户,也就是说组内所有用户对于Twelve Monkeys都不了解,所以对于Twelve Monkeys的预测不存在偏好交互的部分.表中剩余部分的组内成员未评分项的预测评分也可以相似得出,经过上述过程调整后的群组g用户信息如表3,其中下划线的评分项表示经过偏好交互调整的评分.之后便可以根据该表去进行下一步的推荐.
4 偏好交互式组推荐系统框架
传统组推荐系统的生命周期可分为4个阶段:收集群组成员数据、获取群组成员偏好信息、生成组推荐、推荐结果的评价和反馈.文献[14]中给出了一种基于以上4个阶段的四层组推荐系统框架,融合偏好交互的组推荐算法模型在上述框架的基础上提出了一种偏好交互式的组推荐系统框架,框架变为了五层结构,并对每层的内容进行了调整,如图2.
表3 调整后的群组g的用户信息表
Table 3 Adjusted user information Table of group g
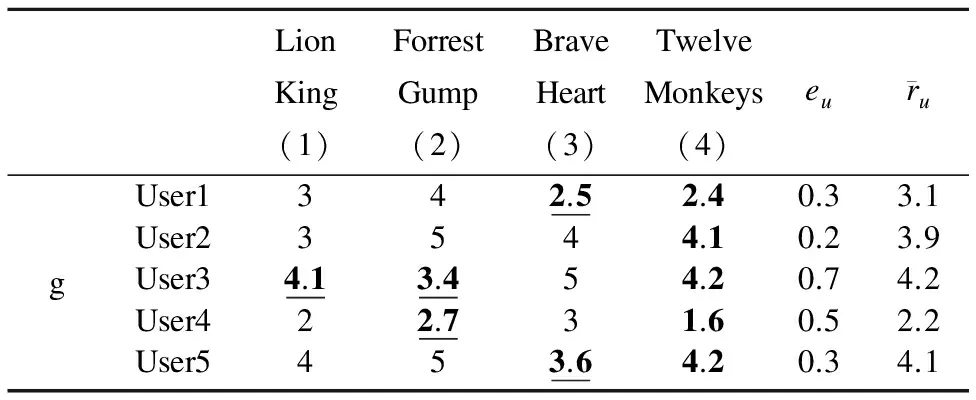
LionKing(1)ForrestGump(2)BraveHeart(3)TwelveMonkeys(4)eurugUser1342.52.40.33.1User23544.10.23.9User34.13.454.20.74.2User422.731.60.52.2User5453.64.20.34.1
偏好交互式的组推荐系统和传统的组推荐系统在框架上主要有以下区别:
1)在数据采集层和数据预处理层上,传统的组推荐系统只需要处理与用户的基础偏好相关数据,而偏好交互式组推荐系统还要去获取群组中用户之间与交互相关的数据,所以偏好交互式框架将这两层分别分成两部分,基础数据部分和交互数据部分.基础数据部分与传统的框架类似负责处理用户偏好提取相关的数据,交互数据部分则是负责组内用户与交互数据提取相关的数据,比如公式(4)中wu,v的获取与公式(7)中eu的获取都是在该部分中计算提取出来的.
2)传统组推荐在预测用户未评分项时不涉及到偏好交互,所以偏好交互层是提出的框架区别于传统框架的核心层,其主要作用是将基础数据和交互数据进行融合处理,从而生成经过用户交互处理后的偏好及评分数据.其中主要包括处理评分矩阵稀疏问题的协同过滤(如2.1节中的UBCF与IBCF)、在群组中结合交互数据对组内用户进行交互处理的交互策略(如应用公式(4)获取R(I)u,i的方法)以及将两部分数据进行合理整合的整合方法(如应用公式(5)的整合公式),最终生成适用本次组推荐的交互式个性化评分.
3)推荐的推荐生成层的目的是生成最终适用于本次推荐群组的推荐结果传统框架中的生成方法在交互式框架中同样适用,在评价反馈层交互式框架中除了效用评价之外还新增了结果反馈的部分,在推荐之后对于某些重要数据进行结果的反馈,对于某些自适应性的推荐算法,收集来的数据将应用到对模型的调整及一些参数的改良,如3.2小节中用户的个性化参数eu的计算过程就需要该层获取的反馈数据去进行调整.
框架之中各部分涉及到的算法和策略,除了可以应用上文中提到的算法之外,还可以替换成与组推荐相关适用于相应模块的其他算法,偏好交互式组推荐系统框架可以作为一种研究和设计组推荐系统的新思路,在组推荐的过程中加入偏好交互的作用,在实际应用中使推荐结果更满足用户需求.
5 实验及分析
5.1 数据集
本实验采用的数据集是MovieLens 100K数据集,该数据集是由GroupLens实验室在movielens网站上对大量用户的电影评分收集得到,其中包括了943个用户对于1682部电影的共100000条五分制(1-5分)的评分记录,并且每个用户至少已经对20部电影评过分.
现存的与推荐系统有关的数据集当中,暂时还不存在与组推荐相关的数据,包括实验所选取的数据集,其中仅包含了与用户个人相关的推荐数据并不包括任何组信息,因此需要对数据集进行预处理,参照[12]中的处理方法,首先将用户根据特定的群组规模进行分组,然后根据用户间亲密度的正态分布,随机模拟用户之间的亲密度wu,v,同时在不同的偏好交互影响力eu下对不同算法进行比较.为了对算法进行衡量,实验采用标准的方法将数据集分为两部分,即在数据集当中随机选择60%的数据作为训练集,40%作为测试集,算法通过训练集当中的数据进行推荐,然后根据测试集中的数据对推荐结果进行验证.具体的评价方法将在5.2中给出.
由于数据集的来源是个人对于电影的喜好评分,并且本身不存在任何与组有关的信息,自然数据当中不会存在任何用户间的交互因素,因此在上述数据集的基础上模拟出了一种带有交互因素的数据集,通过收集校园中以组的形式报名的30名志愿者之间彼此的共同消费活动记录以及其个人性格等因素,据此提取用户之间亲密度以及参数eu,然后再根据收集到的数据近似出两者的高斯分布,进一步根据该分布模拟出数据集中用户之间的交互参数,并根据该参数对测试集的数据进行调整,然后把调整后的数据集作为带有用户间交互影响的模拟数据集进行测试.
实验的主要目的是将融合偏好交互的组推荐算法与未加交互的算法进行比较,并通过没有交互影响的数据集与带有交互影响的数据集分别进行评估,从而证明在组推荐评分预测过程中加入偏好交互的重要性.
5.2 评价体系
实验将采用RMSE[6]与nDCG[18]两种评价参数对算法模型进行评估,RMSE可以去评估评分预测的质量,它表示物品的预测评分与实际评分的均方根误差,其计算公式如下:
(8)
其中M表示数据集中预测的评分数量,Ru,i表示用户u对物品i的预测评分,ru,i为真实评分.RSME为一个非负值,其值越低表示预测值的精度越高.
nDCG是标准的信息检索评价指标,可以用来评价推荐列表的准确度,其公式如下:
(9)
其中reli表示推荐列表中第i位的物品的真实评分,maxDCGn
表示DCGn所有可能的最大值,即n个物品当中最优化的排序得到的DCGn的值,n表示推荐结果的个数,本实验中n=5,它更接近于真实推荐列表的长度.为了计算nDCG需要知道用户对于推荐列表中所有物品的真实评分,然而在测试集当中仅仅包含了少量的用户对于推荐列表中物品的评分,因此采用[12]中的方法去计算nDCG,即计算推荐列表在测试集当中投影的nDCG.
5.3 实验结果
本实验分别对无交互影响的原始数据集和经过交互调整的数据集分别进行了实验,在不同偏好交互影响力eu以及不同组规模下,对传统协同过滤算法与融合偏好交互的算法表现进行比较.其中I-UBCF表示基于偏好交互的UBCF算法,I-IBCF表示基于偏好交互的IBCF算法.

图3 原始数据集下RSME值对比Fig.3 Comparison of RSME in original dataset

图4 原始数据集下nDCG值对比Fig.4 Comparison of nDCG in original dataset

图5 经过交互调整的数据集下RSME值对比Fig.5 Comparison of RSME in adjusteddataset
由图3可以得出,在原始的数据集下,由于传统的协同过滤的评分预测方法与分组无关,所以其RSME值不会受到组规模变化的影响,同时在交互参数eu值较低的时候,基于偏好交互的算法预测误差与传统方法相差不大,然而在eu值较高的时候,偏好交互的算的效果却不如传统方法.图4的实验结果说明,在原始数据集中,传统的组推荐算法给出的推荐列表的准确率要优于经过偏好交互改进的算法,并且随着组规模的逐渐变大差距就越明显.因此结合图3可以得出,提出的偏好交互改进的组推荐算法模型并不适用于无群组内无交互作用的推荐系统中.但由于模型提出的交互参数是根据反馈的方式获取的,因此随着模型的使用eu的值会变得适当低,并不会影响到整个组推荐系统的效率.
图5是在经过交互调整的数据集下推荐算法RSME值的对比结果,由此可知在存在偏好交互的群组之中,经过偏好交互改进的组推荐算法预测评分的误差更小,尤其是在规模较大的组群当中的表现更好.由图6,在经过交互调整的数据集中,偏好交互改进的推荐算法在推荐列表准确度上的表现有了明显的提升,尤其是当交互参数eu以及组规模较大的时候,因此结合图5可以得出,在存在偏好交互作用的群组当中,本文提出的算法优势更明显.

图6 经过交互调整的数据集下nDCG值对比Fig.6 Comparison of nDCG in adjusteddataset
根据实验结果可以得出结论,当群组之中存在偏好交互影响的应用场景之中,偏好交互式的组推荐算法优于传统的组推荐算法.在实际有关组推荐的应用之中,组推荐的目标群体往往是存在社交关系的一些群体,其中大都会涉及到用户之间的交互影响,并且在本模型的推荐算法与用户交互有关的参数eu及wu,v都是通过自适应的方式去获取的,因此被推荐的群组中无论涉及到的交互作用有多少,算法模型都会在推荐系统不断使用过程当中逐渐调整使其推荐效果达到最好,因此本文提出的算法模型在涉及到用户交互的组推荐场景之中具有一定的实际意义.
6 结束语
在组推荐之中,用户的未知偏好往往受到组内成员的偏好交互的影响作用较大,基于该想法,本文提出了一种基于偏好交互的组推荐算法模型.算法模型对组推荐的用户评分预测过程进行了优化,将预测过程分为偏好交互和自我预测两部分,从而将用户的未知偏好在评分预测过程当中加入群组用户之间偏好交互的影响作用,使推荐结果更准确,减少用户的交互成本.实验结果表明,当群组之中存在交互作用的情况下,算法模型将会明显提高组推荐的准确度.
[1] Xu Hai-ling,Wu Xiao,Li Xiao-dong,et al.Comparison study of Internet recommendation system[J].Journal of Software,2009,20(2):350-362.
[2] Garcia I,Pajares S,Sebastia L,et al.Preference elicitation techniques for group recommender systems[J].Information Sciences,2012,189(8):155-175.
[3] Masthoff J,Gatt A.In pursuit of satisfaction and the prevention of embarrassment:affective state in group recommender systems[J].User Modeling and User-Adapted Interaction,2006,16(3):281-319.
[4] Aggarwal C C.Recommender systems:the textbook[M].Springer Publishing Company,Incorporated,2016.
[5] IrfanAli,Sang-WookKim:group recommendations:approaches and evaluation[J].Information Management and Communication,2015:105:1-105:6
[6] Boratto L,Carta S,Chessa A,et al.Group recommendation with automatic identification of users communities[C].IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology,IEEE Computer Society,2009:547-550.
[7] Tang Fu-xi,Liu Ke-jian,Feng Ling,et al.Researchonthe integration strategy of group recommendation based on user′s interactive behaviors[J].Journal of Xihua University (Natural Science),2016,35(3):51-56.
[8] Crossen A,Budzik J,Hammond K J.Flytrap:intelligent group musicrecommendation[C].Proceedings of the 7th International Conference on Intelligent User Interfaces,San Francisco,USA,2002:184-185.
[9] Lieberman H,Van Dyke N,Vivacqua A.Let′s browse:a collaborativebrowsing agent[J].Knowledge-Based Systems,1999,12(8):427-431.
[10] Kim J K,Kim H K,Oh H Y,et al.A group recommendation system for online communities[J].International Journal of Information Management,2010,30(3):212-219.
[11] Garcia I,Sebastia L,Onaindia E.On the design of individual andgroup recommender systems for tourism[J].Expert Systems with Applications,2011,38(6):7683-7692.
[12] Baltrunas L,Makcinskas T,Ricci F.Group recommendations with rank aggregation and collaborative filtering[C].ACM Conference on Recommender Systems,Recsys 2010,Barcelona,Spain,September,2010:407-423.
[13] Mccarthy J F,Anagnost T D.MusicFX:an arbiter of group preferences for computer supported collaborative workouts[C].ACM Conference on Computer Supported Cooperative Work.ACM,2000:363-372.
[14] Zhang Yu-jie,Du Yu-lu,Meng Xiang-wu.Group recommender systems and their applications[J].Chinese Journal of Computers,2016,39(4):745-764.
[15] O'Connor M,Cosley D,Konstan J A,et al.PolyLens:a recommender system for groups of users[C].Conference on European Conference on Computer Supported Cooperative Work.Kluwer Academic Publishers,2001:199-218.
[16] Gartrell M,Xing X,Lv Q,et al.Enhancing group recommendation by incorporating social relationship interactions[C].International ACM Siggroup Conference on Supporting Group Work,Group 2010,Sanibel Island,Florida,Usa,November,2010:97-106.
[17] Campos L M D,Fernández-Luna J M,Huete J F,et al.Managing uncertainty in group recommending processes[J].User Modeling and User-Adapted Interaction,2009,19(3):207-242.
[18] Pessemier T D,Dooms S,Martens L.Comparison of group recommendation algorithms[J].Multimedia Tools & Applications,2014,72(3):2497-2541.
附中文参考文献:
[7] 唐福喜,刘克剑,冯 玲,等.基于用户交互行为的群组推荐偏好融合策略[J].西华大学学报自然科学版,2016,35(3):51-56.
[14] 张玉洁,杜雨露,孟祥武.组推荐系统及其应用研究[J].计算机学报,2016,39(4):745-764.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
课程教育研究(2020年7期)2020-04-21 07:46:30
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
电子测试(2018年14期)2018-09-26 06:04:10
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:42
现代教育科学·中学教师(2015年2期)2015-10-21 19:45:21
现代教育科学·中学教师(2015年3期)2015-10-21 19:26:51
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
天津市教科院学报(2015年2期)2015-02-13 01:11:49
