
面向e-Learning的教育资源聚类系统的设计与实现 *
2014-11-28 23:11吴林静刘清堂黄景修
中国电化教育 2014年10期
吴林静,刘清堂,黄 焕,刘 嫚,黄景修
(华中师范大学 教育信息技术学院,湖北 武汉 430079)
面向e-Learning的教育资源聚类系统的设计与实现*
吴林静,刘清堂,黄 焕,刘 嫚,黄景修
(华中师范大学 教育信息技术学院,湖北 武汉 430079)
随着信息技术的发展和e-Learning学习模式的兴起,网络上教育资源的数量在急速增长,但是学习者却往往淹没在知识的海洋中,出现认知迷航等问题。针对教育资源定位困难的问题,该文研究了教育资源的聚类组织方法,设计并实现了一个面向e-Learning的教育资源聚类系统。该系统可以将资源检索的结果按照一定的算法划分为多个子类别,并通过可视化的方式对划分的结果进行呈现,从而为学习者提供更加精确的资源导航和更为快速的资源定位。在实际使用中,系统的使用者认为,与简单返回资源列表的方式相比,图形化的资源组织与呈现方式能够更好地起到资源导航的作用。
e-Learning;资源聚类;聚类引擎;可视化
一、引言
资源是教与学过程中的一个重要组成部分,优质的教育资源能够极大地提高教学效果,降低学习者的认知负荷,提高学习绩效[1][2]。尤其是随着网络技术的发展,e-Learning作为一种新型的学习模式得到了广泛的关注和应用[3][4]。e-Learning是一种自主性的、分布式的、个性化的学习环境[5],学习者具有较高的自由度和随意性,由于缺乏教师的干预和引导,该环境下的教育资源建设就显得更为重要和迫切[6][7]。
随着资源的数量越来越多,其质量也开始变得良莠不齐,而且资源之间没有统一的信息模型,缺乏良好的组织结构,这给学习者的资源利用带来了很多不便和障碍,主要体现在以下两个方面:
(1)现有的资源管理主要采用以“主题词”为核心,“资源、索引和元数据目录”三要素为基础的资源组织与服务模式。这种基于主题词的资源组织模式不便于学习者从大量的教育资源中快速地定位出自己所需要的资源。学习者往往需要从大量的主题词命中的资源列表中再次进行甄别和筛选。
(2)海量的教育资源大大提高了知识获取的难度,容易导致用户在学习过程中出现“学习迷航”和“认知过载”等问题[8]。
导致上述问题的根本原因在于资源缺乏有效的组织方式[9][10]。人工对资源进行标注和组织虽然可以缓解上述问题,但人工组织费时费力。而聚类技术是一种新型的资源自动组织方法[11],是指计算机自动将资源按照一定的算法划分为多个簇,其中每个簇内部的资源具有较高的相似度,而簇与簇之间具有较低的相似度。由于其不需要监督和引导的特征,聚类技术已经在资源组织和导航领域得到了广泛的应用[12]。因此,针对e-Learning中资源组织模式所存在的不足,本文将聚类技术引入到了教育资源的组织中,设计并实现了一个面向e-Learning的教育资源聚类系统。通过在资源组织中引入聚类技术为用户提供歧义性较小的、更加清晰的、具有良好组织结构的资源集合[13]。
二、教育资源聚类系统的设计
(一)资源聚类系统的需求分析
资源聚类系统的设计目标是对网络上分散的教育资源进行二次组织,针对用户的检索需求,提供更加清晰的教育资源呈现方式。针对上述目标,本文认为教育资源聚类系统的功能需求应包含以下几个方面:
1.对各类教育资源的采集、组织与检索。为了实现对教育资源的组织和聚类,系统需要对网络上的相关教育资源进行采集,并提供检索功能,这是整个聚类系统的数据来源。
2.根据用户的检索需求对检索命中的结果进行聚类。聚类是系统的核心,是资源二次组织的关键。当用户提交检索需求后,系统需要通过一定的聚类算法对检索结果进行处理和运算,从而为用户提供结构更加清晰的检索结果。
3.聚类结果的可视化呈现。根据人类信息获取的一般规律,与文字相比,人们更倾向于从图形中获得信息。图形以更加直观和便于理解的方式揭示数据的本质。因此,聚类系统应能够通过可视化的方式呈现资源的检索与聚类结果。
(二)资源聚类系统的体系架构设计
为了保证系统的体系架构清晰和功能模块的低耦合性与可扩展性,本文采用分层的方式来设计整个系统。系统被划分为三层:数据源层、数据处理与语义聚类层和应用层,系统架构如图1所示。
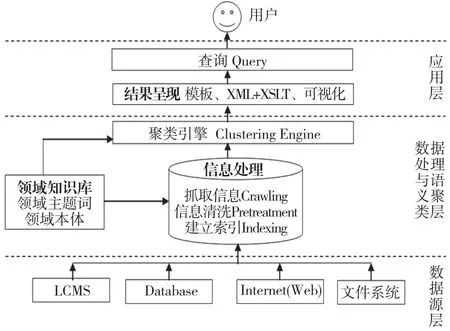
图1 系统体系架构图
1.数据源层
该层的主要作用是采集各类与学科相关的教育资源作为整个系统的数据来源,例如文件系统中的文本类文件、从Internet上爬取的各类主题资源、著名搜索引擎(如Google、Bing)的返回结果、数据库系统中的数据记录以及学习内容管理系统中的学习内容和学习记录等。
2.数据处理与语义聚类层
该层的主要作用是对数据源中收集到的数据进行处理和聚类。首先对数据源中的数据进行去重、去除标签、图片和广告等噪声信息等预处理操作,对数据内容进行清洗和过滤。然后对经过清洗之后的数据内容建立索引以供后续处理步骤使用。建立索引完成后,聚类引擎将对索引的内容进行聚类处理,聚类引擎主要使用URL聚类、来源聚类和k-means聚类算法对资源进行聚类。在信息处理过程和聚类引擎工作的过程中,领域知识库为整个处理过程提供相关的领域背景知识。领域知识库中包括领域主题词库、领域本体等。
3.应用层
应用层的主要作用是面向用户,提供资源检索与聚类服务。系统通过一定的显示模板对聚类结果进行显示,并通过不同的可视化方式展示聚类结果,方便用户查看。同时在应用层为用户提供查询的接口,以便于用户对资源进行查询。
(三)聚类系统的功能模块设计
资源检索系统的功能是根据用户输入的检索关键词从数据源中检索出与其相关的所有资源,并采用一定的聚类算法对检索出的资源进行聚类,然后通过一定的可视化方式将聚类结果呈现给用户。整个系统的工作流程如图2所示。
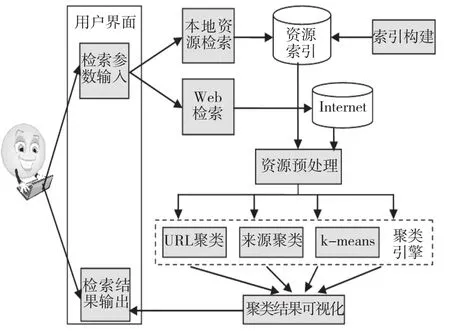
图2 资源聚类系统的基本工作流程
系统的主要功能模块包括以下几个部分:用户界面中的检索参数输入模块和检索结果输出模块、索引构建模块、本地资源检索模块、Web检索模块、资源预处理模块、聚类引擎中的URL聚类模块、来源聚类模块和k-means聚类模块、以及聚类结果可视化模块。下面对每个模块的主要功能进行介绍。
1.用户界面
用户界面的主要作用是面向用户,用于输入资源检索相关的参数和向用户呈现资源检索与聚类的结果。检索参数输入模块包括检索词的输入、返回资源的数目、资源聚类算法等参数。返回资源的数目指的是检索命中的资源按照相关度排序之后返回部分排序靠前的资源的数量,由于Internet上的资源数量众多,若对所有命中资源进行聚类,则所需的时间太长,用户难以接受,而且根据用户资源浏览的习惯,用户一般仅关注检索返回结果中的最靠前的部分资源,因此在聚类时,可以指定仅下载部分命中资源进行聚类。资源聚类算法是让用户可以选择使用不同的聚类算法,可供选择的参数有:按照资源的URL进行聚类、按照资源记录的来源进行聚类、使用k-means算法进行聚类。
2.索引构建模块
该模块的主要作用是对系统自己采集的一些资源数据如本地文件系统、数据库系统中的记录、使用网络蜘蛛采集的各种主题资源、学习内容管理系统中的资源等构建索引。
3.本地资源检索
该模块的主要功能是依照用户输入的查询关键字从已经建立好的索引中检索出与其匹配的所有资源,并按照用户设置的返回资源的数量从命中的资源中下载相应数量的资源供后续步骤使用。
4.Web检索
该模块的主要功能是从Internet上检索相关的资源。由于Internet上的资源数量众多,其采集和处理必然需要巨大的人力和物力资源,因此为了节省资源,在该模块中本系统直接使用著名搜索引擎返回的结果,并对这些结果进行整合和合并之后作为数据源。本模块中使用的开放的搜索引擎接口包括:Google搜索引擎、Yahoo搜索引擎、Bing搜索引擎、EntireWeb搜索引擎、Ask搜索引擎等。这些搜索引擎返回的结果包括与检索词匹配的资源的标题、内容摘要(Snippet)、来源、资源URL等信息。
5.资源预处理:资源预处理模块的主要作用是对检索返回的结果进行一定的预处理,为进一步的聚类做准备。主要的预处理操作包括:对标题和资源的内容(或搜索引擎返回的Snippet)进行分词、去停用词操作,统计特征的频率,并计算其权重,对于标题中的特征赋予比内容中的特征更高的权重,形成待聚类资源集合的特征—文档矩阵。
6.聚类引擎
聚类引擎的功能是通过一定的聚类算法对经过预处理之后的资源进行聚类运算,得到聚类的结果,并为结果中的每一个类簇生成标签。聚类引擎也是本系统的核心功能。
7.聚类结果可视化
聚类结果可视化模块的功能是通过图形的方式来呈现资源聚类的结果,这种图形化的呈现方式可以帮助用户更好地了解资源在各个类别中的分布情况。
三、聚类引擎的资源聚类算法
在聚类引擎中本文一共设计了3种聚类算法,分别为URL聚类、来源聚类和k-means聚类算法。其中URL聚类和来源聚类是按照资源的简单元数据信息进行聚类。k-means聚类则是按照资源的语义内容进行聚类,也是本系统的核心聚类算法。
(一)URL聚类
URL的主要功能是按照资源的URL地址进行聚类,将来源于同一URL的资源聚类在一起。由于域名是层次结构,包含多个级别,因此在按照URL进行资源聚类时,本模块也按照域名的层次结构形成层次状的聚类结果,顶级类别包括:com、cn、net、IP等,然后依次按照下一级的域名进行聚类。其聚类效果如图3所示:
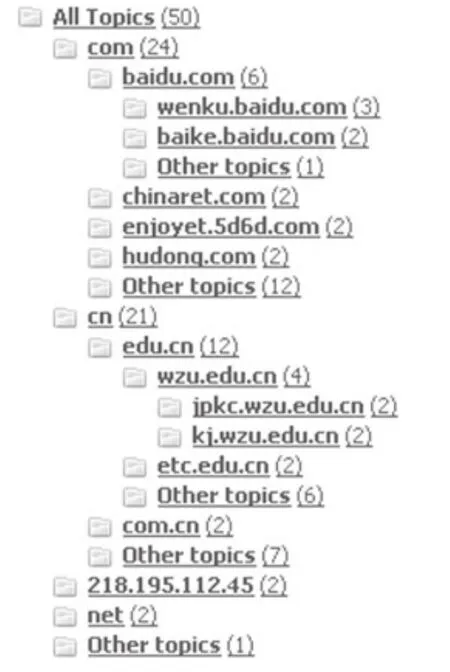
图3 资源URL聚类示意图
(二)来源聚类
来源聚类的功能是按照资源的来源进行聚类,这里的来源指的是当前资源来自于某一搜索引擎的检索结果或者大型的知识库系统。在本系统中,Web资源的来源主要包括Google、Yahoo、Bing、Ask、Wikipedia等主要搜索引擎和知识库(如图4所示)。
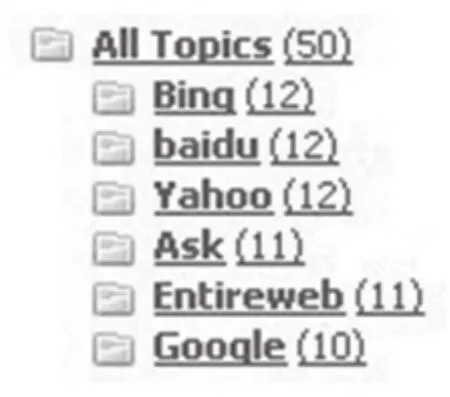
图4 资源来源聚类示意图
(三) k-means聚类
该模块的主要功能是使用k-means算法[14]对待聚类的资源进行聚类。该模块的输入是待聚类的资源集合,经过k-means算法对资源进行聚类之后,返回的结果是每一个类簇及其所包含的资源。算法的基本流程如下:
输入:待聚类的特征—文档矩阵,目标类别的个数k
输出:聚类结果
流程:
(1)从资源集合D中随机选择k个资源作为类别划分的初始参照点c1,c2,c3……ck.
(2)根据资源之间的相似度,将集合中的每一个资源划分到与其相似度最高的参照点所代表的类别中。即:对于一个资源di和某一初始参照点cm,如果Similarity(di,cm)> Similarity(di,cj),其中1<=j<=k,且j≠m,则将资源di划分到类别cm中。资源相似度的计算采用经典的余弦相似度计算方法。
(3)完成资源集合中所有资源的类别划分之后,重新计算每一个类别的质心′,其计算方法一般采用如下公式:

四、教育资源聚类系统的实现
(一)系统实现的相关技术
根据对系统的体系架构和系统功能的设计,本文使用J2EE技术对系统进行了开发和实现。系统中各个层次所采用的具体技术如图5所示。
从系统实现上来说,整个系统分为四层:持久层、数据访问层、业务逻辑层和表现层。数据持久层的主要作用是对系统中的数据进行持久化存储,在本系统中使用mysql数据库系统对资源元数据、领域本体和本地资源进行存储。数据访问层的作用是对持久层中的数据进行访问,并将得到的数据提供给业务逻辑层,在该层中本系统使用的主要技术是Jdom工具包,Jdom工具包主要用来对xml文件进行解析。在业务逻辑层,主要使用J2EE技术来完成系统中的相关业务逻辑,如各种预处理和聚类算法的实现,使用tomcat软件作为Web容器发布整个应用。表现层的主要作用是面向用户提供输入和输出接口,主要采用的是基于xml+xslt的页面排版与布局技术,聚类结果的可视化呈现则通过Flash技术来实现,以尽可能地保证用户界面的美观和友好。
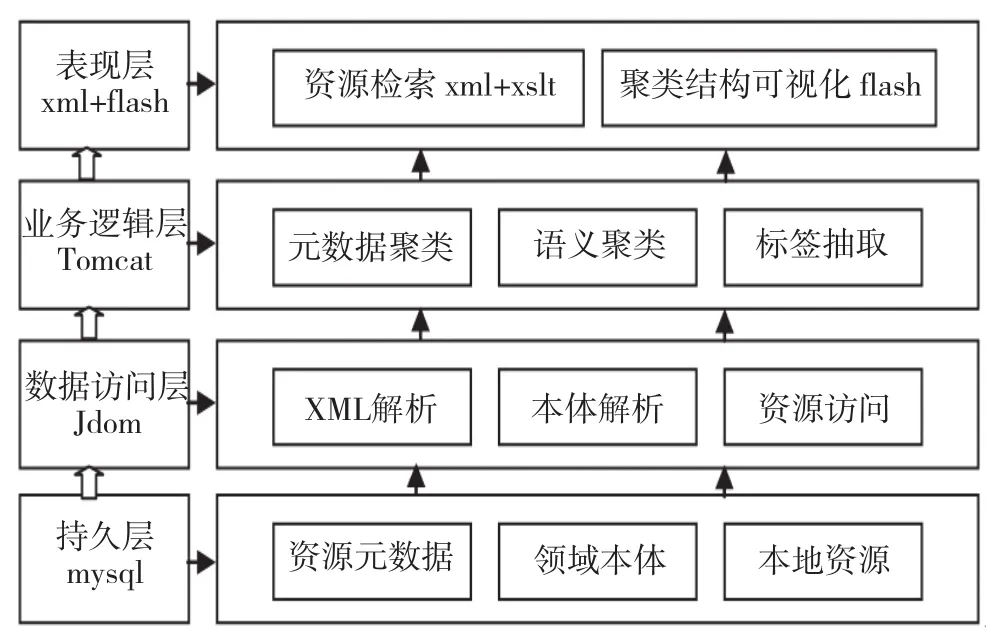
图5 系统实现的具体技术
(二)Web资源检索与聚类的实现
Web资源的检索与聚类是指依据用户输入的关键词,从Internet中检索相关的资源与信息,并对检索得到的结果进行聚类和二次组织。
1.检索源的实现
由于Internet上的资源数量巨大,如果全部进行采集和存储的话需要耗费巨大的采集和存储的资源。因此,在本项目中,我们没有构建独立的网络爬虫来对网络资源进行采集,而是借鉴元搜索引擎的方式,将检索词提交给其他搜索引擎进行查询,然后对返回的查询结果进行比较、去重和排序等组织之后,形成一个较为完善的检索结果返回给用户。我们选择了Google、EntireWeb、Bing等搜索引擎为目前Internet上较为主流的相关搜索引擎,利用其开发的相关API,直接调用其检索结果作为本系统的检索源,从而达到节省系统开销的目的。
2.聚类的实现
获得检索源后,系统将对检索命中的资源进行聚类整合,并为每个类别生成一个语义标签,再将聚类结果呈现给用户。由于互联网上的资源众多,因此关于某一个主题的资源的个数往往可能达到百万级。对于如此众多的资源,如果全部都下载,则需要耗费很长的时间,而且对数量巨大的资源进行聚类也需要耗费较长的时间。如果等待的时间较长,必然会降低用户体验。同时,根据一般用户的浏览和访问习惯,用户往往比较关注排列靠前的资源,越靠后的资源被关注的可能性越小,而且大部分往往只会选择性地浏览前几十条或者几百条记录,而不会花费精力去浏览全部的百万数量级的资源。鉴于这些特点,本系统在得到检索结果之后,不会全部下载所有的命中结果,而是按照用户的需求,选择下载前50条命中记录、前100条命中记录、前150条命中记录或者前200条命中记录。这样,资源下载和聚类的效率都将得到提高,从而使用户能够得到更好的用户体验。当用户选择了下载资源的个数之后,系统会按照一定的聚类算法对下载的资源进行聚类。本系统中可供选择的聚类算法包括:按照资源来源聚类、按照资源的URL聚类和k-means算法聚类。聚类完成后,将聚类结果向用户进行展示。
(三)聚类结果可视化的实现
为了让用户对聚类结果有更直观的了解,本系统实现了对聚类结果的可视化展示。考虑到应用的普适性与通用性,我们选择Flash技术来作为前端的展示技术。根据每个聚类类别中所包含的资源的数量来计算其在圆形饼图中所占面积的大小,从而从整体上展示资源在不同主题中的分布情况。同时可视化呈现效果将与右边的资源列表相关联,在可视化图形中单击某个类别时,饼图的中心会显示当前类别的名称,同时右侧的资源列表会相应展示该类别中的所有资源。通过Flash技术实现的聚类结果的可视化效果如图6所示。

图6 聚类结果的可视化
五、总结
随着网络资源数量的不断增加,如何进行有效的资源二次组织以更好地满足学习者的需求将成为亟待解决的问题。本文通过将聚类技术引入到教育资源的组织过程中,设计并实现了面向e-Learning的教育资源聚类系统。该系统实现了对Web教育资源和本地教育资源的检索以及检索结果的聚类,并可以通过可视化的方式来呈现聚类的结果。学习者可以通过图形的方式了解资源在不同类别中的分布情况,并快速选择自己感兴趣的类别,从而提高资源检索和定位的效率。在系统的实际使用过程中,这种资源聚类与可视化呈现的方式获得了学习者的认可。大部分学习者认为,与简单返回资源列表的方式相比,图形化的资源组织与呈现方式能够更好地起到资源导航的作用。当然,本文也依然存在很多有待完善和改进的地方。如由于聚类算法本身的复杂性,其时间复杂度非常高,所以使用该方法难以在短时间内快速处理大量的数据。同时,资源语义聚类的精度也有待进一步提高。这些难点都将是后续研究中重点关注的问题。
[1] 余胜泉,朱凌云.《教育资源建设技术规范》体系结构与应用模式[J].中国电化教育,2003,(3):52- 54.
[2] 高宏卿,汪浩.基于云存储的教学资源整合研究与实现[J].现代教育技术,2010,20(3):97-101.
[3] Fernando A, Mikic Fonte, Juan C. Burguillo, Martín Llamas Nistal. An intelligent tutoring module controlled by BDI agents for an e-learning platform[J].Expert Systems with Applications, 2012,39(8):7546-7554.
[4] 何克抗.E-Learning的本质——信息技术与学科课程的整合[J].电化教育研究,2002,(1):3-6.
[5] 李晓建,陈磊,陈世鸿.教育资源语义模型研究[J].武汉大学学报(理学版),2005,51(3):342-346.
[6] 葛道凯.E-Learning数据挖掘:模式与应用[J].中国高教研究,2012,(3):8-14.
[7] 王亮,徐明.数字教育资源超市“个性化资源推送”的设计与实现[J].现代教育技术,2011,21(1):136-141.
[8] 蒋银健,郭绍青.Thinkfinity网络教育资源的组织及开发模式研究[J].中国电化教育,2012,(12):45-49.
[9] 赵呈领,杜静,万历勇,陈慧.知识组织技术与方法的研究及应用[J].中国电化教育,2014,(4):77-86.
[10] 朱珂,刘清堂,叶阳梅. 基于主题图的网络课程知识组织研究[J].中国电化教育,2014,(1):91-96.
[11] 陈磊,王云华,陈世鸿.基于概念的教育资源元素材聚类方法研究[J].武汉大学学报(理学版),2005,51(3): 347-350.
[12] 赵红霞,宫淑红,汪晓东. 教育资源创新推广的评价研究[J].中国电化教育,2009,(2):59-64.
[13] 郑庆思,杨现民,余胜泉.泛在学习环境下学习资源的聚合研究[J].现代教育技术,2013,23(12):79- 84.
[14] Ming-Chao Chiang, Chun-Wei Tsai, Chu-Sing Yang. A timeefficient pattern reduction algorithm for k-means clustering[J].Information Sciences, 2011,181(4):716-731.
吴林静:讲师,博士,研究方向为人工智能与教育应用(wlj_sz@126.com)。
刘清堂:教授,博士生导师,研究方向为知识服务、教育资源的数字版权保护(liuqtang@mail.ccnu.edu.cn)。
黄焕:讲师,博士,研究方向为教育资源组织与管理(hbdx_hh@163.com)。
2014年6月10日
责任编辑:马小强
The Design and Development of Educational Resources Clustering System Oriented to e-Learning
Wu Linjing, Liu Qingtang, Hung Huan, Liu Man, Huang Jingxiu
(School of Educational Information Technology, Central China Normal University, Wuhan Hubei 430079)
With the development of information technology and e-Learning, the amount of online educational resources is growing rapidly. However, learners have difficulties when they use these resources. They are always submerged in the ocean of knowledge and have cognitive trek problems. Aimed at these problems, we study the educational resources organization method based on clustering. And then we design and development an educational resources clustering system oriented to e-Learning. This system can classify the resources into several clusters according to certain algorithms. And then it can visualize the clustering results. The system can provide learners with a more accurate resources navigation and location than general methods. In practice, users of the system point that compared to the list of resources in general search engine, graphical resources organization is better to understand and plays a better role in resources navigation.
e-Learning; Resource Clustering; Clustering Engine; Visualization
G434
A
1006—9860(2014)10—0085—05
* 本文受国家自然科学基金项目“面向Web信息的知识融合关键技术研究(项目编号:61272205)”、教育部新世纪优秀人才计划项目(项目编号:NCET-13-0818)和国家“十二五”科技支撑计划课题“农民工技能培训与综合服务研究与集成(项目编号:2012BAD35B02)”资助。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
师道·教研(2022年1期)2022-03-12
海洋信息技术与应用(2020年1期)2020-06-11
甘肃教育(2020年20期)2020-04-13
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
传媒评论(2019年4期)2019-07-13
自动化学报(2018年2期)2018-04-12
中国教育信息化(2015年18期)2015-08-23
中国教育信息化(2015年5期)2015-08-22
