
基于一致性预测器的中医证素组合诊断模型
2014-07-26 01:21王华珍洪燕珠
厦门大学学报(自然科学版) 2014年1期
王华珍,吕 兵,洪燕珠
(1.华侨大学计算机科学与技术学院,福建 厦门361021;2.厦门大学医学院,福建 厦门361102)
近年来,中医学术界提出了证素组合辨证的新辨证体系,即通过“症候获取—证素识别—证型判断”三个环节进行辨证.在中医诊断过程中,首先获取病人临床症状(如寒热、疼痛、二便、舌象、脉象等),接下来分析这些症候对病位(如心、肝、脾、肺、肾、胃等),病性(如风、热、湿、痰、气虚、血虚、阴虚等)等贡献度,计算出各个证素的权重,然后通过阈值判断筛选出若干个证素(如脾气亏虚证、肝阳上亢证、心肾不交证、肺火犯肺证、肝肾阴虚证等),最后由这些证素的组合确定出证型[1].从机器学习角度看,当对新出现的被测数据(病例)进行模式判别时,要求分类器能够同时输出多个类别(证素组合),则分类器必须是特殊的域预测分类器而非传统的点预测分类器.目前存在的解决方案主要是将证素权重度量方法与传统分类器进行组合,输出所有类别(证素)的权重值而非单点预测值.如模糊集与贝叶斯分类器或支持向量机(support vector machine,SVM)组合,贝叶斯网络与支持向量机组合,关联规则与决策树组合,熵理论与神经网络(neural network,NN)组合等[2].此外还有特定的多标记分类器算法(multilabel learning,MLL),主要通过对传统机器学习算法进行改编以适应域预测输出.如李国正等[3]对K近邻算法(K-nearest neighbour,KNN)进行改编,从而将MLL-KNN应用在中医冠心病证素组合诊断.但以上这些算法的证素权重值大都由特定数据集计算得到,纯粹是一种计算方法,缺乏理论意义和统计可解释性.因此机器学习模型经常受到主流统计学家的诟病,无法得到中医医生的信任.
本文引入一致性预测器(conformal predictor,CP)构建中医证素组合诊断模型.CP以算法随机性水平值作为证素的重要性度量,以算法风险水平为阈值,选取符合条件的若干个类别作为可选类别进行输出[4].这种域预测形式恰好符合中医证素组合诊断模式,并且CP的算法风险水平属于假设检验理论的范畴,具有明确的统计意义和可解释性,能够被医疗研究领域的学者所接受.本文的研究对象是中医慢性疲劳临床证候数据集.慢性疲劳综合征是现代高效快节奏生活方式下出现的一组以长期极度疲劳(包括体力疲劳和脑力疲劳)为主要突出表现的全身性证候群.目前西医对于慢性疲劳的病因不明确,尚未找到有效的防治措施;中医药治疗慢性疲劳虽然有一定的优势,但由于目前关于慢性疲劳的中医证候诊断及疗效评价尚无统一、规范、客观化的标准,使中医药防治慢性疲劳的临床疗效缺乏说服力[5-6].本研究将对慢性疲劳的证素辨证体系研究进行有益的探索,提供重要的方法学支持.
1 CP模型
1.1 算法原理
CP是一种带置信度的域预测分类器,其置信度能对预测域进行有效的风险评估,已引起全世界众多研究者的研究与讨论,被广泛应用到生物医学数据、传感数据、图像数据、时间序列数据等领域[7].
CP理论认为机器学习一般假设训练学习样本服从独立同分布假设(i.i.d分布),而独立同分布假设可以等同于Kolmogorov算法随机性假设.假设实际问题已经输出了训练样本序列z(n-1)=(z1,z2,…,zn-1),并给定待测数据xn.CP将对xn预赋每个可能的类别值y∈Y={1,2,…,C},组成检验样本zyn=(xn,y)(将会有C个检验样本,即((xn,1),(xn,2),…,(xn,C)).再将检验样本zyn和训练样本z(n-1)n连接构成检验样本序列,这时会有C串的检验样本序列
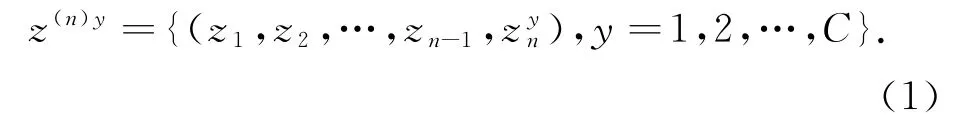
接下来利用统计学的假设检验方法对上述C串检验样本序列逐一进行算法随机性(i.i.d分布)的显著性检验(又称假设检验).检验统计量p值的构造方案如下:首先设计样本奇异映射函数:
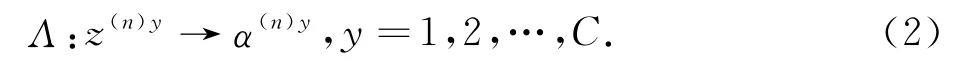
对z(n)y中的每一个样本进行一一对应的奇异值映射,得到一维奇异值样本序列样本奇异值αi表示对应样本zi隶属于整体z(n)y数据分布(即i.i.d分布)的不一致程度(nonconformity).根据奇异值序列α(n)y就可以计算出z(n)y的算法随机性水平值:
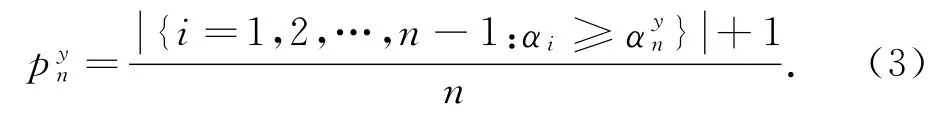
当对待测数据xn进行预测时,把统计量值与显著水平标准ε比较.若值小于ε则拒绝原假设,即以算法风险水平ε(对应的置信度为1-ε)为阈值,CP输出预测结果为:
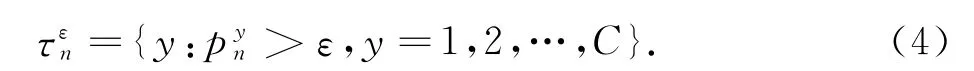

以上公式称为CP有效性定理[4].满足公式(5)则说明CP的预测域具有可校准性.由于置信度与算法风险水平互补,因此有效性定理也可以解释为CP算法的准确率不低于置信度.
1.2 样本奇异值映射函数设计
CP需要设计样本奇异映射函数将检验(高维)样本序列(公式1)一一对应地映射成样本(一维)奇异值序列(公式(2)).CP一般利用传统机器学习方法对高维样本序列进行数据挖掘,从而获取样本的奇异值.随机森林(random forest,RF),SVM,NN,朴素贝叶斯分类器(Naïve Bayesian,NB)等算法被嵌入到CP框架中用来计算样本的奇异值[8-9].列举如下:
1)CP-RF:该方法利用RF算法计算样本的奇异值.RF是树分类器CART的组合分类器算法,当对数据集构建RF模型后,数据集中的任意两个数据能够获得基于RF的相似性度量.对于任一样本zi,CP-RF的样本奇异值映射函数设计方案如下:
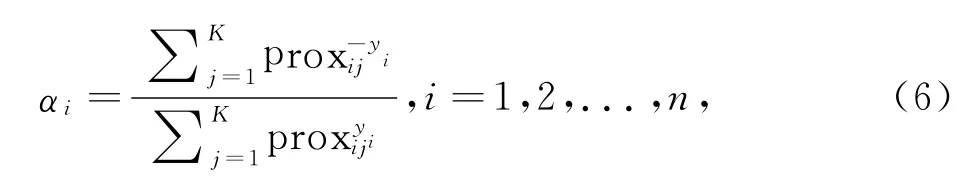
2)CP-KNN:当在样本原始空间里度量两个样本之间的距离,则CP-RF退化成CP-KNN.相应地,对于任一样本zi,样本奇异值度量公式如下:

3)CP-NB:该方法利用NB模型计算样本的奇异值.NB是一种基于后验概率的分类器,后验概率越高,则对应的类别越可能成为真实的类别.因此对于任一样本zi,一种直观的样本奇异值计算方案是:
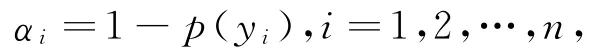
其中p(yi)是被测数据xi的预测为类别yi的后验概率.NB通过对数据集进行频数统计获得类概率等模型参数,同样适用于具有离散特征的中医数据分析.但由于NB需要提供数据分布等先验知识,并且要求数据的特征之间具有独立无关性,使其在机器学习领域具有局限性.
2 实验数据
本文使用的慢性疲劳数据集是通过流行病学整群抽样调查法收集的.首先设计慢性疲劳中医临床症状分级量化表,其次在2007年8月至2008年12月期间对福建省闽南地区的大学、中学、小学教师及医院的医生和护士进行流行病学调查及临床证候调查,记录患者症状、舌象和脉象等临床证候信息.临床证候有95个,即慢性疲劳数据集有95个特征,每个特征的取值方法为:用0表示患者无该症状,1表示有此症状.然后根据2名主治医师以上职称的专家研究商讨后,对病例进行证素组合诊断.根据前期初步研究结果,慢性疲劳证素主要有脾虚证、心虚证、肝郁证和气虚证共4类[10].将每个证素看作一种类别,将标记脾虚证为类别1,心虚证为类别2,肝郁证为类别3,气虚证为类别4.这样慢性疲劳数据集的类别集中的元素将是1,2,3,4.以此为标准确诊为慢性疲劳的患者有736例.以175号样本为例,该样本的类别集为{1,2,4},表明该病例同时呈现脾虚证,心虚证和气虚证,没有出现肝郁证.在736个病例中,呈现单证素结果的病例有169个,多证素组合的病例有567个.
3 实验结果与讨论
本实 验 将 CP-RF 与 CP-NB,CP-KNN,MLLKNN进行对比.当运行CP算法时需要对训练样本进行模式转换,将多类别模式样本转换为常规的单类别模式样本.在实验中根据类别集的类别数目对数据进行复制,每一份指派其中的一个类别为该数据(病例)的类别.仍以175号样本(类别集为{1,2,4})为例,需要复制2次,这样一共得到3份175号数据,并分别指定类别为1,2,4.当运行 MLL-KNN算法时采用参考文献[3]提供的算法程序,在预测新数据时将K近邻中类概率大于阈值0.5的所有类别作为预测类别进行输出.当使用RF和NB算法时,相关参数采用默认值.对K值设置时选取K=1,5,9,11进行实验.在实验中采用“留一法”进行交叉验证,这样将获得736个测试结果.以下对这些结果进行分析.
3.1 阈值对预测域的影响
在中医证素组合诊断实践中,需要指定阈值以筛选出合适的证素.一般来说,阈值对最后筛选得到的证素数目影响很大.将阈值设置得过高,则选出的证素数量减少,可能会漏掉某些重要的证素;如果设置得过低,则选出的证素集中将会有大量冗余证素.因此阈值的确定是中医多证素组合诊断的关键技术之一.指定一系列不同的阈值,算法将输出一系列对应的预测域.统计这些预测类别集与真实类别集的拟合率,其结果如图1所示,其中算法参数K=1.

图1 不同阈值下4种算法的拟合率比较(K=1)Fig.1 Comparison of matching ratios with different threshod values for four methods(K=1)
在图1中,对于 CP算法,即 CP-RF、CP-NB和CP-KNN,阈值是风险水平ε(对应的置信度为1-ε);而对于MLL-KNN,阈值是比率值.由图1可以看出,CP-RF的表现远远好于CP-NB和CP-KNN,这说明利用RF模型进行样本奇异函数设计是有效的,即式(6)能够深刻地刻画出样本的奇异性,从而使式(3)给出的算法随机性水平值是一种有效的证素重要性度量.而由于中医数据的特征一般呈现相关、离散等特点,NB算法和KNN算法都无法适用这类数据的数据挖掘,无法正确地度量出证素的重要性值.从CP-RF与MLL-KNN的对比可以看出,CP-RF的最高拟合率是0.997 3,远 远 高 于 MLL-KNN 的 最 高 拟 合率0.870 9.从整体曲线看,在[0.01,0.28]低阈值情况下CP-RF的拟合率高于MLL-KNN,在其他高阈值情况下CP-RF的表现比MLL-KNN差.但是CP算法的优势是具有良好的实用性,因为在实践中使用者希望机器预测结果具有较高的置信度,这将需要指定较低的算法风险水平作为CP预测域的阈值.针对CP-RF可以看出,在较低阈值[0.01,0.2]范围内(即置信度值为[80%,99%]),拟合率基本不变,保持在[0.982 3,0.997 3]之间.这说明在高置信度下 CP-RF的拟合率不仅非常高,还具有很好的稳定性,这将克服不同的阈值对预测域中证素数目的波动性,解决中医多证素组合诊断关键的技术难题之一.
接下来考察算法参数K在其他取值下对实验结果的影响.针对实践中使用者通常使用的置信度值99%,90%,80%(对应的阈值为0.01,0.1,0.2),各种算法的拟合率汇集在表1中.
从表1可以看出,在K取不同值时CP-RF的拟合率表现都远远高于其他3种算法,这说明K的取值不是区分不同算法性能的关键参数.也进一步表明,采用RF模型作为样本奇异值映射函数是有效的,能对被测病例的各个证素进行可靠的重要性评估,从而获得准确的证素组合诊断结果.针对CP-RF算法可以看出,K取不同值时其拟合率几乎没有变化,这说明CPRF对K值参数具有很好的鲁棒性.又由于RF对自身建模参数也是鲁棒的,因此CP-RF算法具有很高的自动化水平程度,弥补了人工专家诊断成本高昂等缺陷.
3.2 CP准确率的校准性
CP最显著优势是对预测结果提供有效的置信度评估,即CP预测域的准确率能够被置信度所校准(或框围).在对736个证素组合(多类别)预测域统计准确率时,需要根据真实类别集的类别数目进行重复统计.针对真实类别集中的每一个类别,若出现在预测域中则统计为正确一次,否则统计为错误一次.以175号样本(类别集为{1,2,4})为例,假设CP算法的预测域是{1,2},则175号样本被统计3次,其中预测正确2次,错误1次.准确率由正确次数比总的统计次数获得.指定一系列不同的算法风险水平阈值(置信度),统计相应的预测域准确率,得到准确率与置信度之间的关系曲线,实验结果如图2所示.
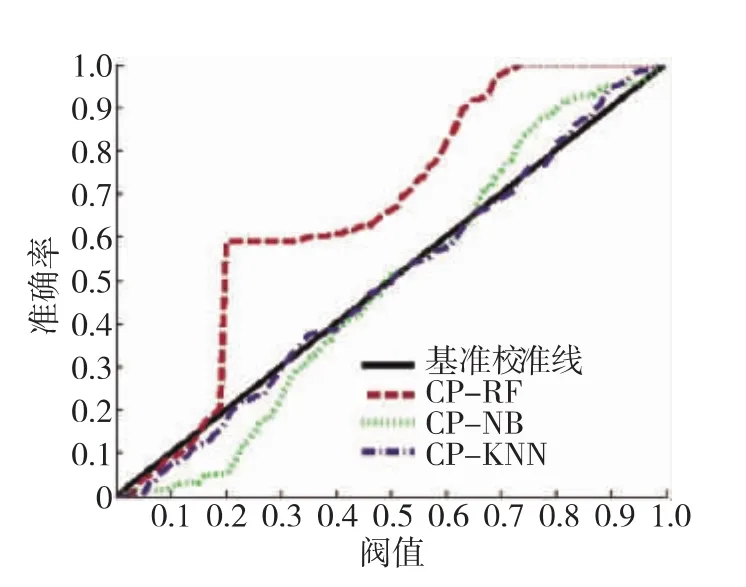
图2 3种CP算法的校准性比较Fig.2 Comparison of calibration for three CP models
在图2中,对角线基准校准线意味着准确率与置信度精确相等.由图2可以看出,CP-RF,CP-NB和CP-KNN 3种模型的准确率校准线与“基准校准线”基本拟合,特别是在置信度值比较高的阈值情况下(置信度值大于0.4以上),3条准确线都贴合甚至高于“基准校准线”.这说明在使用者广泛接受的高置信度阈值区域内,CP算法的准确率不低于置信度值,CP的准确率能够被置信度阈值所框围,满足校准性.然而在置信度阈值比较低的区域内(置信度小于0.4),CP-NB和CP-KNN的准确率校准性略低于“基准校准线”,这种现象一方面来自于实验数据量没有充分大而带来的统计波动误差,另一方面也可能是因为数据模式转换(例如上述175号样本被统计3次)导致数据集差异性降低.这两个因素对分类性能较差的CP-NB和CPKNN带来明显的副作用.然而对CP-RF模型,其准确率值大都超过指定的置信度值,即式(5)中CP-RF的错误率小于指定的算法风险水平,这体现了CP-RF模型的优越性.CP模型以算法风险水平(置信度)为阈值,而置信度属于假设检验理论范畴,具有明确的统计意义和可解释性,能够被医疗信息处理专家所接受.这区别于MLL-KNN等算法,其阈值一般通过简单频数计算获得,没有明确的可解释性.
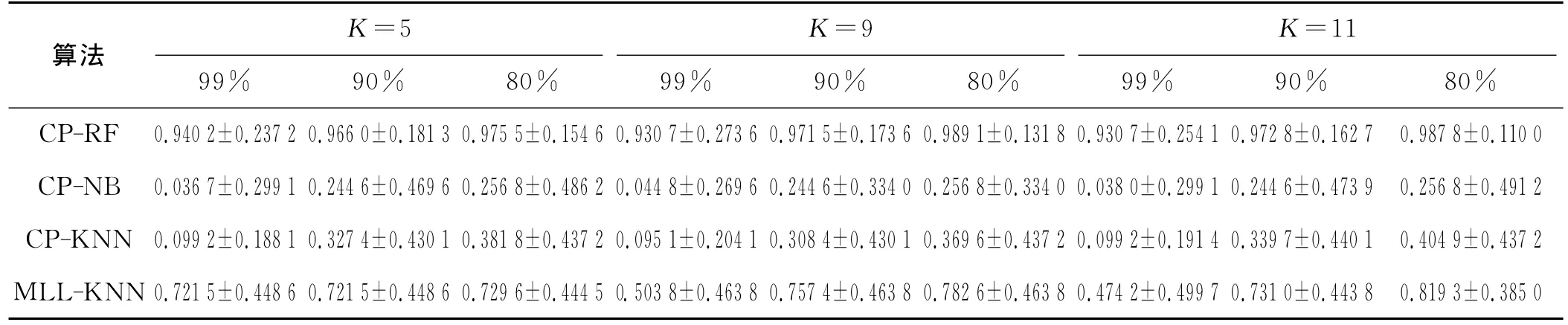
表1 4种算法在不同K值下的拟合率比较Tab.1 Comparison of matching ratios for four methods with different Kvalues
4 结 论
本文采用CP模型构建中医慢性疲劳证素组合诊断模型.CP以样本序列算法随机性水平为证素的重要性度量,以算法风险水平为阈值进行域预测输出.在实验中RF,NB,KNN等算法被嵌入到CP框架中用来计算样本奇异值.实验结果表明,对于实践中常用的置信度范围[80%,99%],CP-RF的拟合率大大高于其他域预测分类器,并且保持在[0.982 3,0.997 3]基本不变.这说明CP-RF不仅准确率非常高,还具有很好的稳定性.克服了阈值选取对预测域的波动性,解决了中医证素组合诊断关键的技术难题之一.同时CP预测域结果的准确率不低于置信度阈值,能够被置信度所校准,具有明确的统计意义和可解释性,能够被中医医生所接受,将在临床诊疗应用中发挥积极的辅助作用.
[1]朱文锋,何军锋,晏峻峰,等.确定证素辨证权值的 “双层频权剪叉”算法[J].中西医结合学报,2007,5(6):607-611.
[2]Su S B.Recent advances in zheng differentiation research in traditional Chinese medicine[J].International Journal of Integrative Medicine,2013,1(7):1-10.
[3]Liu G P,Li G Z,Wang Y L,et al.Modelling of inquiry diagnosis for coronary heart disease in traditional Chinese medicine by using multi-label learning[J].BMC Complementary and Alternative Medicine,2010,10(1):37-49.
[4]Vovk V,Gammerman A,Shafer G.Algorithmic learning in a random world[M].New York,USA:Springer,2005.
[5]王天芳,薛晓琳.亚健康状态与慢性疲劳综合征[J].中国中西医结合杂志,2008,28(1):77-79.
[6]张振贤,张烨,王扬,等.理虚解郁方对慢性疲劳综合征患者负性情绪及皮质醇与5-羟色胺的影响[J].上海中医药大学学报,2012,26(5):38-40.
[7]Gammerman A,Vovk V.Hedging predictions in machine learning[J].Computer Journal,2007,50(2):151-177.
[8]Wang H Z,Lin C D,Yang F,et al.Hedged predictions for traditional Chinese chronic gastritis diagnosis with confidence machine[J].Computers in Biology and Medicine,2009,39(5):425-432.
[9]Vanderlooy S,Maaten L V D,Sprinkhuizen-Kuyper I.Off-line learning with transductive confidence machines:an empirical evaluation[C]∥Proceedings of the 5th International Conference on Machine Learning and Data Mining in Pattern Recognition.Germany:Leipzig,2007:310-323.
[10]洪燕珠,周昌乐,张志枫,等.慢性疲劳患者中医常见证候要素研究[J].中医杂志,2009,50(12):1114.
猜你喜欢
广州中医药大学学报(2022年10期)2022-10-13
世界科学技术-中医药现代化(2022年2期)2022-05-25
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
世界科学技术-中医药现代化(2021年9期)2021-12-31
世界科学技术-中医药现代化(2021年8期)2021-12-21
机电产品开发与创新(2020年2期)2020-05-07
计算机应用(2018年5期)2018-07-25
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
