
基于改进的G-P算法的相空间嵌入维数选择
2014-04-03 01:44高俊杰王豪
计算机工程与应用 2014年9期
高俊杰,王豪
GAO Junjie,WANG Hao
上海交通大学 电子信息与电气工程学院自动化系,系统控制与信息处理教育部重点实验室,上海 200240
Department of Automation, Shanghai Jiao Tong University, and Key Laboratory of System Control and Information Processing, Ministry of Education of China, 200240, China
1 引言
混沌时间序列是由混沌动力系统产生的单变量或多变量的时间序列。相空间重构是混沌时间序列分析的基础,重构的质量直接影响到后期分析的效果。1981年Takens提出了坐标延迟重构法[1],认为只要选择合适的延迟时间和嵌入维数,就能重构出一个与原系统具有相同拓扑性质的动力学系统。因此,延迟时间τ和嵌入维数m的选取很重要。
如果m选取过小,吸引子会折叠,甚至自相交,导致邻域内包含不同轨道的相空间点,将使得重构后的吸引子形状和原始吸引子不一致,影响后续研究的准确度;但如果m选取过大,吸引子的几何结构完全打开,但却将噪声的影响放大,也导致计算量急剧增加。综上,通常选取嵌入维数其中D是动力系统的关联维数[2]。
确定关联维数最常用的是 Grassberger和Procaccia提出的饱和关联维数法(简称G-P算法)[3]。目前对该算法的研究主要集中在无标度区的合理选择及自动识别上,比如:汪富泉等利用三折线段逼近法来确定无标度区[4];费斌等通过遗传算法选取标度区的起止点[5];党建武等根据置信度和相关性指标来选择无标度区[6]。还有一部分研究是将G-P算法与其他算法结合来求取嵌入维数,比如吕威等将自相关法与G-P法构成循环迭代系统,通过不断优化得到参数[7]。但对于G-P算法其他方面的不足,则较少有人研究。所以本文针对原G-P算法的其他不足之处,提出了一种改进的算法,通过对邻域半径区间、步长和线性部分进行合理的选择,更准确客观地求取嵌入维数,而且通过在程序上的改进,能够有效地减少运算量,缩短程序运行时间。
2 G-P算法
2.1 G-P算法原理
对混沌时间序列 x(n), n = 1,2,…,N,以延迟时间τ和嵌入维数m进行相空间重构,相空间中的相点为。给定一个邻域半径r,定义关联积分如下:

式中:r为邻域半径,M=N-(m-1)τ为相空间中相点数目(N是时间序列长度),θ(·)为Heaviside单位函数(定义为θ(x)=0,ifx<0;θ(x)=1,ifx≥0),为无穷范数。
关联积分是一个累积分布函数,表征了相空间中任意两个相点间距离小于邻域半径的概率,用来刻画相点聚集程度。
当r→0时:如果奇异吸引子是一维结构,则C(m, r)正比于r;如果吸引子是二维结构,则C(m, r)正比于 r2;同理类推,当吸引子是D维结构时,则有C(m, r)正比于 rD,即:

即:

称D为时间序列的关联维数。
所以为了求取关联维数,可以在坐标系中画出一系列不同嵌入维数m时,ln C(m, r)~lnr的关系曲线,曲线中线性部分的斜率就是当系统嵌入维数为m时吸引子的关联维数值 D(m)。一般来说,D (m)会随m的增加而增大。当D(m)不再增加,而趋于稳定时,即为饱和关联维,对应的m即为奇异吸引子的最佳嵌入维数。这也是混沌序列与随机序列的区别特征之一,随机序列的关联维数是不会趋于一个稳定值的。
2.2 G-P算法的不足
通过深入分析和仿真试验,发现G-P算法有以下几个不足:
(1) 邻域半径r的选取主观随意性太强。r的选取直接影响关联积分C(m, r),若r取得太小,则邻域内没有包含任何相点,C(m, r)趋于0;若r取得太大,超过了相空间中相点的最大距离,将包含所有相点,C(m, r)趋于1。这两种情况都将给关联维数的判断造成困难。
目前对于r值区间范围的选取仍没有统一的方法,大多是通过试凑法、效果观察法来决定,个人主观性太强,缺乏客观性。而ln C(m, r)~ln r关系曲线在不同的r值区间段上表现出的斜率变化情况是差异较大的,这使得判断线性部分斜率饱和与否更加困难,甚至误判关联维数值。如图1所示,是对同一个样本数据,采用不同的r值区间范围,通过G-P算法得出的关系曲线。可以看出曲线的变化之大,从而得出结论:r值区间范围选取的规范性对结果有重大影响。

图1 同一样本数据,不同r值区间范围的关系曲线
(2) 邻域半径r变化步长的选取。步长太小,将极大地增加运算量,而且噪声影响也会被放大,影响正确的结果;步长太大,样本点太少,精度难以保证。有些文献为了达到计算点在对数坐标中等间距的效果,采用按2的次幂来取点,但这样做样本点太少,精确度难以保证。
(3) 无标度区间的判定不客观,斜率的饱和与否靠主观判断。系统关联维数值就是ln C(m, r)~lnr关系曲线上线性部分(称为无标度区间)的斜率。而对无标度区间的判定目前主要是靠主观观察,选定主观所认为的线性区间,然后主观判断该区间线段的斜率是否达到饱和。但从图 1可以看出,对斜率饱和与否进行主观判断容易有出入。
(4) 求取关联积分时运算量巨大,如果不加以优化,算法无法满足实用性要求。按照原算法,如果m取 Km个不同值,r取 Kr个不同值:就要进行 Km次相空间重构以得到相点;每次重构后针对不同的r值要进行 Kr次个相点的距离计算;对于长度为m维的两个相点,要得到其距离需要做m组相点元素间的减法运算及值比较;并将这些点距离与r比较得关联积分。但本文分析发现这样的算法原理和多层循环嵌套的计算结构存在大量重复计算。
3 改进的G-P算法
3.1 改进的G-P算法原理
针对G-P算法的上述不足,本文提出以下改进方法:
(1) 对邻域半径r值区间的选取,本文以相点间距离的最小值为r值下限,以相点间距离的最大值为r值上限,即。如此的区间选取方法具有两个好处:第一,算法本身可根据序列的数值分布情况,自适应调整区间范围,既排除了人为主观性因素,也克服了区间固定导致的无法适应不同序列的难题;第二,可以综合考虑时间序列的全局性质,具有较好的稳定性。
(2) 步长采用均匀递增的方法,保证 C(m, r)的平缓变化及足够的样本点,使无标度区间在双对数坐标系中容易判断,并满足精度要求。
(3) 针对无标度区间的确定,本文采用基于BDS统计限定范围的快速自动判定法。根据 BDS统计结论[8]:如果时间序列是独立同分布,则当N→∞时,关联积分有。此时重构相空间中的点几乎是均匀分布,重构吸引子轨道在相空间完全展开。 并且r=k·σ/2,k=1,2,3,4(σ是时间序列的均方差);N≥3000;m=2,3,4,5时,符合这个结论的合理估计。因此,本文选定[ln(σ/2),ln(2σ) ]作为无标度区间的界限是有数理统计依据的。下面的仿真试验也证明了这种选取的合理性。
再对选定的该范围内的曲线用最小二乘法分别拟合,得到各条线段的斜率(称为一次斜率,也即D(m)值),据此画出D(m)~m的关系曲线;最后通过对D(m)~m曲线的斜率(称为二次斜率)计算,当二次斜率小于所设定的阈值、充分接近零时,即说明 D(m)趋于饱和,此时即为系统关联维,所对应的m即为最佳嵌入维数,如图3、图4所示。至此可以实现维数的自动计算。
此处改进利用 BDS统计对无标度区间的范围进行了有效限定,可以大大减少后续拟合求一次和二次斜率的运算量,从而快速得到结果。而且进一步保证了无标度区间的正确锁定。
(4) 本文主要从三个方面对算法进行优化以达到提高速率的目的。
a) 从算法原理上去除重复计算。
首先,相空间重构是为了形成相点以计算点间距离,完全可以在计算距离时按重构规则直接从原始数据中读取得到相点的各维元素值,没必要进行Km次重构,既减少运算量,又解决 Km次重构带来的内存占用问题,这对于数据量大的序列效果尤其显著。

所以前m次减法运算是重复的,只要用以下递推公式(5)就能进一步减少运算量:

b) 从程序结构上去除重复计算
在相同的m值条件下,相点间的距离并不会随r变化,因此由于使用循环嵌套的计算结构而导致的重复计算rK次相点距离是没必要的。新算法对程序结构进行调整:先用上一步的方法只计算一次相点间距离;再将点距离与r比较;而且,根据传递原理“”,又能进一步减少大量的重复比较运算。
c) 变“数据计算”为“数据读取”。
对于计算机,从内存中读取数据远比计算数据要高效得多。为此本算法在内存中建立 Km个表,按如下规则存储相点间的距离:第k个表格的第i行第j列元素表示嵌入维为mk时重构相空间中第i个相点和第j个相点的距离(存储原理如图2所示)。而且利用上一步的递推方法,制作这 Km个表格的运算量并不大。计算关联积分时,只要读取对应的上三角矩阵的元素,并与r比较一次即可,去除了原算法中重复计算、重复比较的冗余运算。

图2 相点距离存储的原理示意图
综上,虽然由于多个参数的同时变化,无法精确量化本文的改进算法相对于原G-P算法在运算量上的改进程度,但从分析中是可以明显看出新算法在减少运算量方面的效果的。
3.2 改进的G-P算法仿真试验
根据改进的 G-P算法在 Matlab 7.6.0(R2008a)平台上编成软件,限于篇幅,仅以Lorenz、Rossler两个典型的混沌系统为对象进行仿真试验[9,10]。结果如表1和图3、图4所示。
结果分析:
1,改进算法计算出的关联维非常接近理论值,说明是准确有效的;
2,适用于不同的混沌系统,说明改进算法的稳定性和适用性都较好;
3,本算法的改进在程序运行速度上提高的程度与参数 Km、 Kr、原始数据的长度有关,无法统一测定。但用上述例子进行多次测算,分别取和16,,统计平均运算时间仅为原算法的1/26和1/19。而且原时间序列的数据长度越长,运行时间的提高效果越明显。说明本文在算法效率上的改进是有显著效果的。
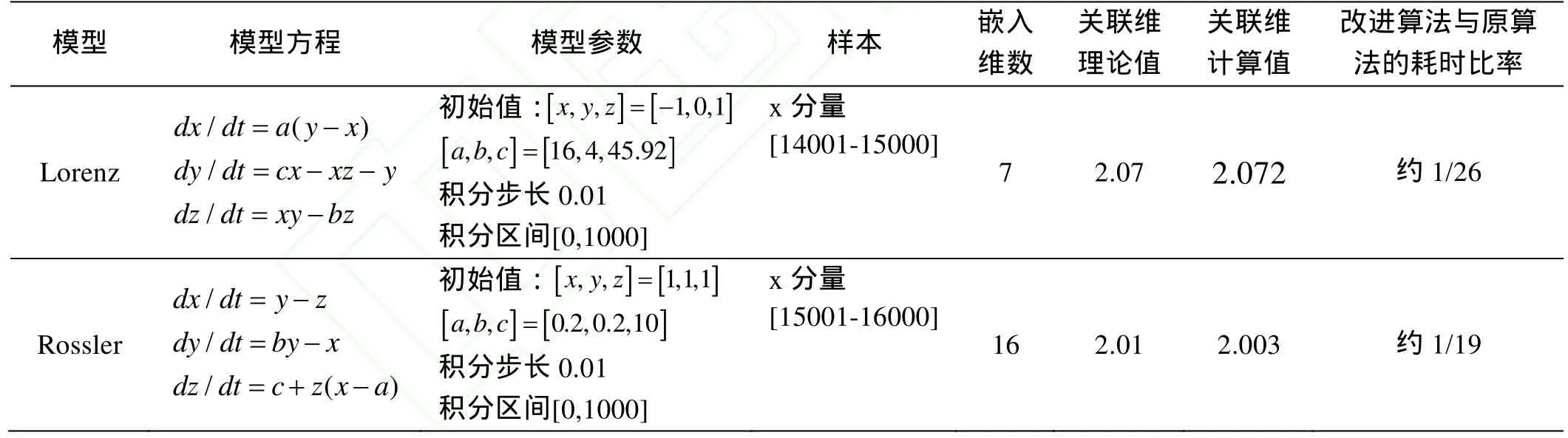
表1 改进的G-P算法仿真试验

图3 改进的G-P算法求解Lorenz系统x分量嵌入维数

图4 改进的G-P算法求解Rossler系统x分量嵌入维数
4 结束语
本文针对G-P算法求取混沌时间序列相空间维数存在的不足,提出了改进。主要对邻域半径的区间选取、步长、无标度区间的判定三个方面进行了深入分析,并提出了改进方法,实现自动准确计算系统维数;并通过算法原理和程序结构的改良,去除重复、繁杂计算,提高程序效率。仿真试验证明了本文提出的改进的G-P算法具有很好的准确性、稳定性及实效性,可以为混沌时间序列的进一步分析提供良好的基础。
[1]Takens F. Detecting strange attractors in turbulence[J].Lecture notes in Math,1981,898:361-381.
[2]Martin Casdagli. Chaos and Deterministic versus Stochastic Non-Linear Modelling[J]. Journal of the Royal Statistical Society:Series B (Methodological),1992,54(2):303-328.
[3]Grassberger P, Procaccia I. Characterization of strange attractors[J]. Physical Review Letters,1983,50(05):346-349.
[4]汪富泉,罗朝盛.G-P算法的改进及其应用[J].计算物理,1993,10(3):345-351.
[5]费斌,蒋庄德,王海容.基于遗传算法求解分形无标度区的方法[J].西安交通大学学报,1998,32(7):72-75.
[6]党建武,施怡,黄建国等.分形研究中无标度区的计算机识别[J].计算机工程与应用,2003,39(12):25-27.
[7]吕威,王和勇,姚正安等.改进嵌入维数和时间延迟计算的GP预测算法[J].计算机科学,2009,36(5):187-190.
[8]W A Broock, J A Scheinkman, W D Dechert, et al. A test for independence based on the correlation dimension[J].Econometric Reviews,1996,15(3):197-235.
[9]吕金虎,陆君安,陈士华.混沌时间序列分析及其应用[M].武汉:武汉大学出版社,2002:14.
[10]Argyris J, Andreadis I, Pavlos G, et al. The influence of noise on the correlation dimension of chaotic attractors[J].Chaos, Solitons & Fractals, 1998, 9(3): 343-361.
猜你喜欢
现代应用物理(2021年3期)2021-11-10
中国建材科技(2020年6期)2020-03-23
中学生理科应试(2019年3期)2019-07-08
湖南教育·C版(2018年3期)2018-06-05
福建中学数学(2016年7期)2016-12-03
浙江大学学报(理学版)(2016年1期)2016-05-14
河北工业大学学报(2016年6期)2016-04-16
电测与仪表(2015年14期)2015-04-09
电测与仪表(2014年24期)2014-04-09
技术经济(2014年10期)2014-02-28
