
实现系统规模化的龙芯3号桥片设计与验证
2014-04-03 01:44鲍庆元李孟春王焕东王启银
计算机工程与应用 2014年9期
鲍庆元,李孟春,王焕东,曾 露,王启银,赵 锐
BAO Qingyuan1,LI Mengchun1,WANG Huandong2,ZENG Lu2,WANG Qiyin3,ZHAO Rui3
1.太原理工大学,太原 030024
2.中国科学院 计算技术研究所,北京 100190
3.大同供电分公司,山西 大同 037008
1.Taiyuan University of Technology,Taiyuan 030024,China
2.Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China
3.State Grid Datong Power Supply Company,Datong,Shanxi 037008,China
1 引言
纵观当今的信息产业技术发展,各个国家都在不断努力进行着产业转型,尤其以日本为主的微电子技术在20世纪率先发展起来,取得了重大成就,带动国内各相关领域的飞速进步。而自多核处理器的出现至今,并行计算机可以实现大规模科学与工程计算,高性能超级计算机也加速了人类对科学领域的量化分析和探索研究,并且代表着国家的科技发展水平。除了一般性的科研计算外,在信息服务、金融、地理、国防、生物医药等领域,超级计算机全天候地进行着高速并行数据处理,为各个行业提供研究和服务需求发挥重要作用。
以中科院计算技术研究所为核心的科研团队,开发出的基于mips架构的龙芯3号系列处理器已成功应用于国内超级计算机,已处于国内计算机CPU芯片研发技术领先水平。现在,在国家核高基项目支持下,我国首台自主设计的龙芯3B八核处理器的万亿次高性能计算机“KD-90”,通过专家组鉴定,集成了十颗龙芯3B处理器,理论计算峰值可达每秒1万亿次。
在单片处理器的性能保证上,本课题将对基于国产的龙芯3号多片互连体系结构进行规模扩展,主要工作集中在片间通信的一致性消息传递方面。为了使数据在读写时保持一致,需要通过一种机制来维护系统间数据交换时的Cache一致性。基于目录结构的高速缓存一致性协议可以将事务请求维护起来,并且更好地实现了CC-NUMA系统扩展,也是本文研究的主要内容。
2 三态转换的一致性协议
发生状态变换的触发事件主要有五个,本地读RD,本地写WR,替换REP,远程读rRD,远程写rWR。下面就图1所示来说明一下状态是如何进行转换的,这里不再讨论自转移事件。

图1 高速缓存块状态转移
初始状态为I:当处理器核发生RD操作时,系统将请求发给远端处理器,得到响应后,本地处理器将会收到一个共享状态的缓存备份;当处理器核发生WR操作时,系统将请求发给拥有此缓存块的处理器,当返回响应后,本地处理器将得到一个独占的缓存备份。
初始状态为S:当处理器核发生REP时,处理器核将本地缓存块换出到下一存储层,并且将本地缓存块无效;远端处理器发生rWR时,系统将本地缓存块无效,并返回响应;当处理器核发生WR操作时,在实际应用中为了降低请求处理的开销,无法从共享状态直接到达独占状态,虚线表示,必须经过无效状态。系统会将所有拥有共享块的处理器核无效处理(包括本地),得到响应后,本地处理器核再重复上述的由I状态变到M状态的转换过程。
初始状态为M:当处理器核发生REP时,处理器核将本地缓存块换出到下一存储层,并且将本地缓存块无效;远端处理器发生rWR时,系统将本地缓存块无效,并返回响应;当远端处理器发生rRD时,系统将本地缓存块置为共享状态,并返回响应。
3 CC-NUMA系统及目录组织
基于目录的高速缓存一致性协议,是将数据块与其所在处理器位置相关联实现的。在长期的对目录协议的研究中,研究人员设计出不同的目录组织形式,最主要的组织经常采用位向量的方式[3]。通过对目录中位向量的查找可以实现点对点的数据响应,同时一致性问题也由目录来进行相应维护。目录的结构可以充分发挥出CC-NUMA系统的局部性优势,如果当访问失效时,在本地节点可以查找到相应数据块,则不必通过远程端写回,降低了延迟开销。但是,位向量目录所使用的存储器大小与系统中处理器核数n的平方成正比,所以当n过大时,目录协议的存储开销也会随之增大,并且系统的性能开销也会受到缓存备份数量的影响。
对于目录的组织来说,可以实现的形式分为两种,分别是扁平目录方案和层次目录方案[4-5]。如图2所示,左图为扁平目录组织,右图为层次目录组织。

图2 目录组织形式
扁平目录组织是将一个块的目录信息存放在一个固定位置。图2中的P是处理节点,每当发生读失效时,处理节点会直接访问统一的宿主节点进行查询,因为访问的路径和延迟不同,所以图中会有不同长短的连线。这样的结构方案比较简单,所有的一致性事务全都会到一个地方来处理,但是也带来了问题,所有的处理节点无论路径大小都会去访问同一节点,对于路径远的处理节点经常访问时就会增大开销。并且,对于向大规模CC-NUMA系统扩展的情况来说就会出现更差的性能,如果将宿主节点放在片内的话,随着处理器核数的增加会增大芯片面积的成本开销。
层次式的目录可以有效地解决这些问题。在大规模的系统中,访问可以选择最短路径,有效地利用了局部性的优势。对于目录开销问题,层次化的目录存储开销可以分摊到其他的硬件当中,减轻了片内因存储器而耗费面积。但是,在层次式的目录方案中,与扁平目录方案发生失效的一致性事务情况不同,层次结构的一致性事务可能会遍历整个目录级,每一次的访问都会去查询目录节点上的目录信息,造成一定的访存延迟。但是,当系统扩展到一定规模时,对于那些局部性较好的程序来说,这种目录方案将会体现出好的一面来。
降水中的稳定同位素D与18O在补给过程中,将大气D与18O的信号传递给地下水,地下水在渗透的过程中使得水中同位素的含量发生变化,这些变化为地下水来源调查提供了基础[15]。地下水的δD与δ18O含量在垂向上具有明显的分层特点,整体表现为随着地下水的埋藏深度的增加,地下水的δD与δ18O值逐渐偏负,指示着地下水不同含水层段上水力联系微弱[16]。
4 桥片设计
4.1 桥片的意义
龙芯3A处理器由4颗处理器核组成[6],在片内通过二级缓存统一维护多核处理器的一致性问题,内部构成CC-NUMA系统。而处理器间的一致性问题就不能单靠二级缓存来维护整个系统的一致性了。随着系统规模的扩大,数据访存的Cache一致性请求也会不断增加,导致目录访问冲突、延迟增加等问题,这都是需要在构建更大规模的CC-NUMA系统中考虑的因素。因此,在互连系统间利用桥片来处理跨区域访存的一致性事务。并且,通过在桥片中加入远程Cache模块,可以降低访存延迟,使大规模的CC-NUMA系统开销能够得到降低。
4.2 结构设计
Origin2000/3000是一种典型的CC-NUMA系统,采用与龙芯处理器构架相同的MIPS R10000。具有良好可编程性的分布式共享结构DSM,在很大的范围内实现了系统的可扩展性,256节点内,系统都具有线性扩展能力。Origin系统经典的4立方体结构[7],通过中间路由,使同位置的处理节点相互连接起来,然后每个节点会根据地址信息在内部路由给需要访问的处理节点。最近到最远路径访问的延迟比约为1∶4。在并行程序中,保持局部范围的访问可以发挥出这种体系结构的极大优势来。由于Origin系列构架还是过于复杂,128处理器的系统已将近达到了性能的峰值。而当今的处理器多为多核处理器,龙芯3号系列的处理器集成了多处理器核,在芯片内部已完全构成了小规模的CC-NUMA系统结构,而通过桥片,可以经过简单化的外部扩展,构成大规模的CC-NUMA服务器系统。
整个系统将分成两级目录形式将所有的处理器核的一致性问题进行硬件的维护,一级目录由64位位向量组成,用来维护处理器的片内和本系统的一致性问题,统一由二级缓存来保存处理器核的缓存块状态。龙芯3A处理器最多支持8芯片直连,而当系统规模超过8片时,就需要通过桥片来进行跨系统访问和一致性维护。二级目录在桥片中维护,目录记录的将不再是处理器核的私有一级缓存块状态,而是本互连系统中芯片的块状态。通过粗向量的方式,以更大的粒度来解决大规模系统多核处理器的数据一致性问题,从而可以降低目录方面的开销。像二级缓存维护处理器核的一致性一样,桥片中粗向量会维护多片系统的一致性问题。此时,桥片的Cache目录将会记录一组块的位向量,当系统需要查找时,粗向量会指向某个处理节点,然后再通过上一级目录查找到具体所要访问的核。
4颗龙芯3A8处理器(第8版龙芯3A芯片)可以构成一个CC-NUMA互连系统。3A8可以通过HT接口实现两两互连,再通过桥片构成一个完整的互连系统。每个桥片可以通过PCIe总线连接其他的桥片,利用4个PCIe接口可以组建多种Mesh网络,简单的二维Mesh网络可以通过X-Y的路由方式,即首先向X方向路由再向Y方向路由的方法到达目标桥片,构成Mesh网络。也可以构建更大规模的CC-NUMA系统,最多可以使64个桥片进行互连,形成三维的立方体Mesh网络。但实际应用中,只考虑扩展到16片互连的情况,避免因路径太长而产生极大的延迟开销问题。如图3给出两个互连系统的结构图。
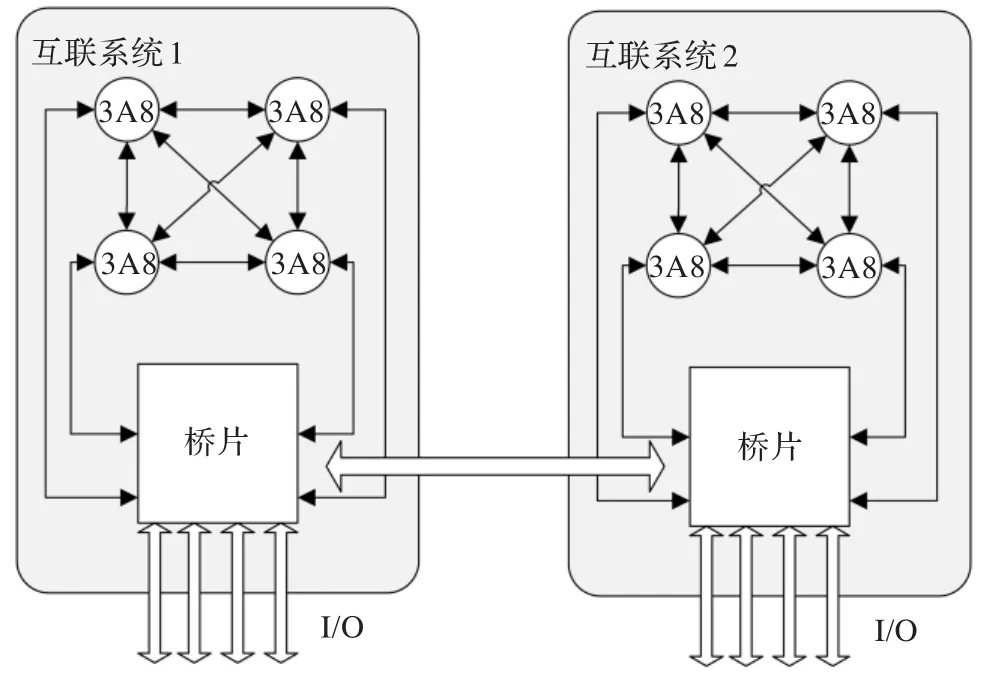
图3 两个互连系统通过桥片实现系统级互连
在桥片内部主要包括三种控制模块:远程缓存控制器(RMC),本地目录控制器和I/O接口控制器。远程缓存控制器主要的功能是将本系统要访问的远程地址请求转发给远程系统,当远程系统收到请求时,经过各个存储层数据的取回,再通过远程系统的同等桥片,将数据响应给请求端。在收到来自远程系统的数据响应后,控制器不会立即将数据发送给请求的处理器核,会先把数据缓存起来,并且记录下缓存块状态和位向量后再将数据发送给请求处理器核,缓存的数据以便本地其他处理器核请求相同地址的访存时可以迅速返回数据而不需要再跨系统进行访问。
3A处理器是通过HT总线实现片间互连的,包括处理器-处理器,处理器-桥片。在图4简化的结构图中可以看到4路HT总线代表连接4片龙芯处理器,通过协议转换模块,由AXI片内总线协议实现内部的消息传递[8]。由于CC-NUMA是主要利用局部性原理来实现系统的高效性,所以不会发生高频的外部地址访问。RMC模块只需连接容量为1 MB的高速缓存模块用来存储远程系统地址的数据并且记录下本地拥有该数据块的芯片的位向量。在远程控制模块的下游会将上游的请求路由到指定的I/O设备(远程桥片),发往其他系统桥片的本地控制器。

图4 桥片局部模块RMC结构
5 仿真验证及性能分析
5.1 仿真环境
在仿真环境中,主要针对验证RMC模块功能进行搭建,如图5所示。首先,环境会模拟芯片内4个master(龙芯3A处理器)发出AXI的读写请求,这里可以先使用一个简单的MUX模块实现仲裁,将请求串行发给RMC。利用交叉开关直接将请求发送给slave(这里放置一个可以处理AXI一致性请求的二级缓存),二级缓存下游连接DDR3内存模块,这样就可以先利用具有相似结构和一致性功能的二级缓存来实现对RMC的验证。
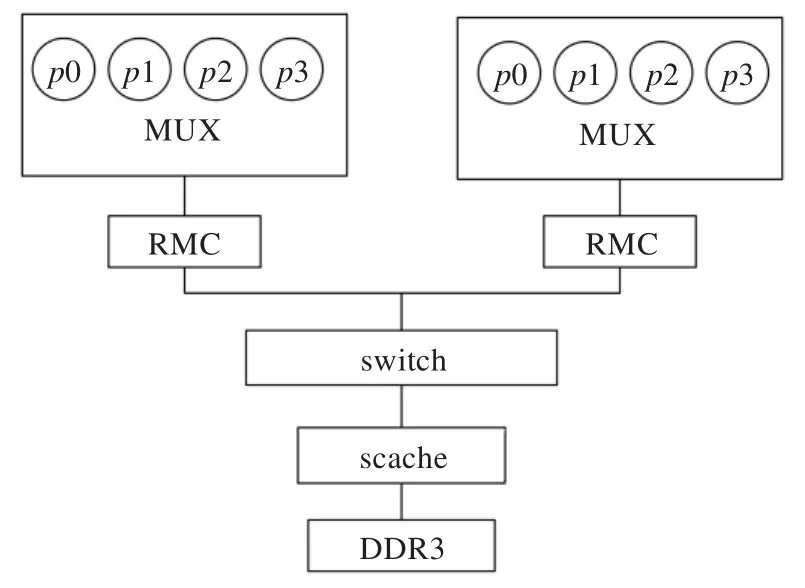
图5 仿真环境方案
5.2 定向验证
通过verilog、SV(Systemverilog)来编写环境,并使用Synopsys公司提供的VCS进行编译和前仿。手工编写特定向量的仿真环境可以初步验证模块功能的正确性。在外加特定激励的情况下,观察响应数据及一致性事务等是否达到预期的结果。图6为仿真抓取的波形。

图6 RMC仿真波形
可以看到,仿真开始时会让4个master同时对同一外部地址发起读请求(G1),请求会逐一去访问RMC,第一次访问时会发生失效,RMC会将请求下发给二级缓存,再给到内存最终查找到数据。数据会沿路返回给RMC(G2),当RMC接受到数据后会响应第一个发起请求的处理器。然后其他三个处理器的请求会依次被RMC处理。在接下来的不同处理器的同地址访问会在RMC模块中全部命中,所以数据会在很短的周期内将返回给3个处理器。当另一端某个处理器再次发起同地址的写请求时(G3),本地4个处理器都会收到无效请求,并且返回4个无效确认(G4)。在二级缓存收到来自所有拥有共享缓存块返回的确认时,才会将数据块发送给发起写请求的处理器(G5)。
从上述的处理过程中,可以分析出同地址不同情况的访存延迟,如表1所示。当第一个处理器发出读请求时,访存延迟没有变化。但是,当其他处理器第二次访问相同外部地址的数据时,请求会发送给之前预存的Cache块,数据直接返回给请求端,由于还需要处理一致性事务,所以会额外增加几拍延迟,可是看到第二次的访存延迟也只有前一次的1/4。而第三次以后,由于数据块已经是共享状态,不需要再有一致性事务处理产生的延迟,所以访存会进一步加快。而远程系统在首次写请求时,需要经过桥片到桥片的访问和一致性事务处理过程,产生相当于从内存取回数据的延迟开销。

表1 访存一致性延迟开销
同时,在对同地址的一致性请求事务的处理过程中,系统会严格遵守一个序关系,只有当一件事务完全结束后,才会去处理下一个请求。而在不同地址的访问过程中则不需要严格保持序关系,这样可以提高访存效率。
5.3 随机验证
随机测试技术是大规模集成电路仿真验证中重要的环节之一,在处理器的行为级功能验证方面,它具有重要地位。人工编写定向测试会花费大量的时间成本,并且也很难做到覆盖所有要验证的各个角落,可重用性较差。所以用随机测试向量为DUT提供大量的随机数据流,可以有效地提高验证效率并具有灵活性和可移植性。
基于此环境之上,还需要进行随机发送大量请求来了解该模块的性能。激励方面仍然采用带有一致性的AXI请求,随机选择读和写两种情况,并在预先设定的地址域内发送。在图6中可以看到,冷失效的情况是必然出现的,但是在大量的随机请求中,冷失效、冲突失效和维护Cache一致性引起的失效所占比重较小,而影响最大的是容量失效。所以有必要对Cache的不同容量和失效率之间的关系进行分析。从图7的统计结果中发现,当块大小是64 B的缓存时,可以明显看出失效率随着缓存容量的增加而降低,在芯片面积允许的情况下,采用大容量的Cache可以有效提高桥片的命中率。同时,使用8way(相联度)的Cache也可以降低失效率,但是相比于4way,8way的硬件条件更高,访存延迟也会增加,对提高性能而换来的好处不明显。

图7 Cache容量与失效率关系
由于Cache模块中会以一种队列的机制来维护大量请求集中到来的状况,所以在同地址(顺序)和不同地址(乱序)的访存操作中不会导致冲突现象发生。
6 结束语
本文从具体的龙芯处理器配套桥片设计侧面阐述了CC-NUMA系统向大规模扩展的思想,并且分析在大规模系统中如何来维护好全局一致性问题。通过针对龙芯处理器特性的了解,在配套的桥片中加入了缓存的结构设计,这样桥片就不仅仅作为跨系统访问的桥梁,同时兼有多级缓存的功能,提高访存效率。在当今访存优化竞争的年代,每降低一点访存延迟都会给计算机性能提高一大块。同时,龙芯处理器内部将沿用基于目录的高速缓存一致性协议,设计也会将这种一致性方法应用到桥片中,这样可以保持处理器和桥片在一致性问题上的高度统一。在程序设计方面,具有良好的局部性的并行程序将会更加高效地运行在多核,多处理器,多系统的CC-NUMA体系当中。桥片也为Linux更加稳定地应用在大规模系统提供保障。本文实现了桥片预期的功能,并且搭建了针对模块所需的验证环境,在环境中,对桥片的部分功能给出了正确的验证结果。但是在完整可靠的设计和验证工作中还有大量的问题有待解决,为了最终可以实现成功流片,还需继续努力做好此后的工作。
[1]景涛.多核环境下基于L2 cache的目录一致性协议的研究[D].哈尔滨:哈尔滨工程大学,2010.
[2]夏宏,任捷.基于WishBone总线Cache数据一致性方案[J].计算机工程与应用,2006,42(9):93-95.
[3]王焕东,高翔.龙芯3号互联系统的设计与实现[J].计算机研究与发展,2008,45(12):2001-2010.
[4]Culler D,Singh J,Gupta A.Parallel computer architecture:a hardware/software approach[M].[S.l.]:Morgan Kaufmann Pub,1999.
[5]潘国腾,窦强,谢伦国.基于目录的Cache一致性协议的可扩展性研究[J].计算机工程与科学,2008,30(6):131-133.
[6]Bryant R E,O’Hallaron D R.Computer systems:a programmer’s perspective[M].[S.l.]:Addison-Wesley Educational Publishers Inc,2010.
[7]Laudon J,Lenoski D.The SGI origin:a CC-NUMA highly scalable server[C]//ACM SIGARCH Computer Architecture New,1997.
[8]ARM,AMBA3.0,AXI protocol specification[S].2004.
[9]Almaless G,Wajsburt F.On the scalability of image and signal processing parallel applications on emerging CC-NUMA many-cores[C]//Design and Architectures for Signal and Image Processing(DASIP),2012.
[10]Gao Yuhui,Zhu Mingfa,Huo Jiantong.Design and implementation of BIOS for Godson-3A interconnections[C]//Computer and Management(CAMAN),2011.
[11]Wang Ruibo,Lu Kai.Using transactional memory on CCNUMA systems[C]//Networked Computing(INC),2010.
[12]杨鹏飞.多核环境Cache一致性协议研究[D].哈尔滨:哈尔滨工程大学,2011.
[13]陈杰,章军.一种集成“龙芯1号”IP核的SoC的体系结构[J].计算机工程与应用,2007,43(19):111-114.
[14]屈文新,樊晓娅.“龙腾”2微处理器Cache单元的设计与实现[J].计算机工程与应用,2006,42(17):22-25.
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
公民与法治(2022年5期)2022-07-29
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
华人时刊(2016年13期)2016-04-05
燕山大学学报(2015年4期)2015-12-25
信息安全与通信保密(2015年9期)2015-11-02
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
初中生世界·八年级(2009年8期)2009-11-03
