
基于模糊集的网络新闻评论的情感特征提取研究
2014-03-27 02:42佘玉梅丁冬冬王米利刘敬凤
云南民族大学学报(自然科学版) 2014年4期
庄 丽,佘玉梅,江 涛,丁冬冬,王米利,刘敬凤
(云南民族大学 数学与计算机科学学院,云南 昆明 650031)
随着网络的普及,网络上用户生成的内容越来越多,如博客、论坛、新闻评论等,成为大众参与社会生活的一种新的平台.相关研究表明,绝大多数网民对新闻评论的内容都基于新闻正文,外加很多自己对新闻事件的看法,除一般事实外,还有大量的主观性内容,对之后阅读新闻和评论的网民有着引导和交流的作用[1].研究还显示网络新闻跟帖评论所针对的话题,一般都是时事热点和备受大众关注的新闻事件,网民在网络上表达出来的意见,不仅反映了公众对社会重大公共事件的关注度与参与度,也反映了公众不同的价值判断和思想动态,对社会和国家了解民情民意,制定相关政策有着很大的影响,新闻评论越来越具有参考和研究价值.
网络新闻评论具有社会新闻共有的及时性和网络评论独具的开放性和多元性等特征,所以网络新闻评论的情感特征提取相对来说更加困难,其难点主要有:
1) 评论内容的随意性,出现很多与新闻内容无关,不具有任何价值的干扰信息;
2) 评述内容普遍都只有几十个字的长度,情感特征不集中;
3) 错误噪声、别字、简字、俚语和引入的网络新词较多,用语不规范;
4) 指代不明确,思维发散,很多评论有很强的背景知识.
在研究方法上,由于新闻评论的语义具有模糊性,对具有模糊性的自然语言进行情感模糊化建模是可行的,其中模糊理论是处理模糊问题的有效工具之一,因此本文的目标就是找出一个有效的情感特征提取方法,运用模糊集理论对其进行特征词的扩充,建立有效的情感特征词库.实验表明,这种情感特征提取方法更适用于网络新闻评论,基于模糊集的情感特征词库的扩充比传统的扩充方法更有效.
1 模糊理论
美国的控制论专家Zadeh在1965年提出了模糊集理论,1973年又提出了用模糊语言描述系统的方法,给出了模糊集合和模糊语义的相关定义[2],把模糊数学与人工智能相结合进行了研究.
模糊语义的产生主要是由于客观事物具有连续性与语言符号具有的离散性之间的矛盾关系.在数学模型上,我们用离散的语言符号来标志连续的事物时,就会产生边界的模糊性.
定义1 一个语言变量是一个五元组(F,T,U,G,M).
其中F是语言变量的名称;T表示语言变量F的语言值总体构成的集合,也叫做辞集,即一个具体的语言值名称记作fi,我们把T表示为T=f1+f2+…,T取有限个数.U则是语言变量F的论域;G代表句法规则,通过该规则产生了F的语言值的名称;M被称为语言规则,T中的每个语言值fi的辞义M可以看成在论域U上fi的一个模糊集合[3].
2 基于网络新闻评论的情感特征词提取
网络评论中情感语义挖掘的关键技术是提取情感特征词,而传统意义上情感词一般由形容词和副词体现,但新闻评论中语料的特殊性需要更多不同词性的词语作为特征,例如“哈哈”等叹词可以单独作为一句话或一条评论,有着很强的感情色彩,因此在评论语料中还需要进一步的筛选和标注分类.本文认为传统研究的文本分类方法局限性较多,主要表现在不能很准确地区分情感词汇和普通词汇,而且传统方法更加忽略了词汇和词汇搭配后带来的情感倾向性的变化,所以本文采取的方法是分阶段逐步优化选取情感特征.
S1(Phrase)=(RDF(Phrase)/(NDF(Phrase)+1).
(1)
S2(Phrase)=(RTF(Phrase)/(NTF(Phrase)+1).
(2)
其中Phrase表示在文中分词标注后的短语,RDF(Phrase)表示Phrase出现在所有评论中的次数,RTF(Phrase)是Phrase在所有评论中出现的累计总次数,NDF(Phrase)是Phrase出现在所有不同新闻中的次数,NTF(Phrase)表示Phrase在所有新闻中出现的累计总次数.
先对评论中出现的词进行打分,然后按S1的得分进行排序,设定S1(Phrase)不小于最小分数min(Phrase)(设为3),在满足条件的语料中再按S2的得分进行排序,S2(Phrase)的最小分数min(Phrase)也不得小于3,得分较高的标注为高频特征词.考虑到这些情感特征词中仍有大量的噪音和不规范的地方,因此再进行人工筛选排除,对特征词进行情感倾向标注,最终得到正向情感语料库(PBF)和负向情感语料库(NBF)合成的初级情感语料库(BF).
3 情感特征词库的扩充
考虑到直接使用初级情感语料库难免会使召回率过低,不能达到很好的效果,因此我们运用模糊理论扩充初级情感语料库(BF)得到模糊情感语料库(GF),本文主要对语料库中的形容词和副词进行同位词扩充.
由语言变量的定义可知,语言变量的辞义M可以看成论域上的一个模糊集合M(x).本文应用模糊集合对提取的网络新闻评论情感特征词中的形容词和副词作为语言变量进行了情感语义模糊化处理,其中在可行域上扩充的特征词的褒贬程度分别用G(好,Good)、B(坏,Bad)表示,扩充情感词的强度由小到大依次表示为S(少)、M(中)、L(大)、VL(极),中间没有情感倾向的特征词表示为Z.我们选出的情感特征词分别扩充为VLB、LB、MB、SB、Z、SG、MG、LG、VLG 9个级别,分别表示极度贬义、相对贬义、贬义、略有贬义、中性、略有褒义、褒义、相对褒义、极度褒义,每个都对应一个模糊隶属度函数,这里我们称为初级扩充模糊集,如图1.
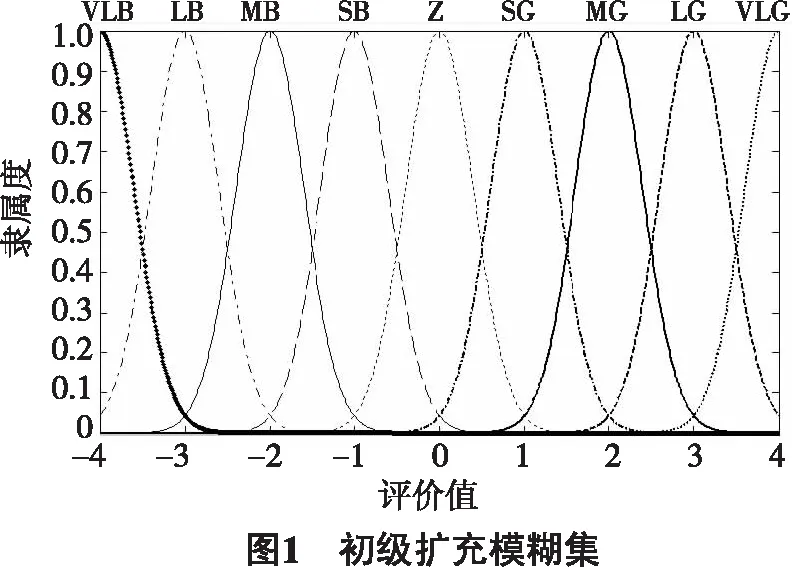
图1表示在Matlab模糊工具箱中扩充情感词褒贬程度的初级扩充模糊集.针对上述各级别建立了扩充模糊集,因此高斯函数型的模糊隶属度函数在定义域[-4,4]上表示为
(3)
式中σw、cw为模糊隶属度函数的参数,其情感级别与w的取值相对应,其中w∈{VLB,LB,MB,SB,Z,SG,MG,LG,VLG};扩充的情感特征词语的程度值用x来表示;y表示相应的情感评价词程度的隶属度;当x=cw时,y=1,得σw=0.4,当y越接近于1时,表示情感特征词隶属于这一情感级别的程度就越大.
在北京大学研制的数据库NTCIR-6中就定义了1 241万个词与词之间的同位关系和情感递进关系,同时还记录了它们之间的匹配次数(MacthCnt)和同位关系之间的置信度[4].本文对初级情感语料库中形容词和副词都进行了语义模糊扩充,用自动验证的方法来检查这些扩充的情感特征词汇.我们把每一个扩充得到的候选特征词的同位正向词数(P)与负向扩充词数(N)进行比较,满足P>N且P>=min(Phrase)时,即归为正向模糊情感语料库;N>P且N>=min(Phrase)时,归为负向情感语料库.这样经过过滤后的正负扩充模糊语料库与初级情感语料库构成了模糊情感语料库(GF).
4 实验
本文针对搜狐网近期最热的新闻事件《10岁女孩电梯内摔打1岁半男童 疑似将其扔下25楼》,截止到2013年12月9日有111 372次浏览,19 075人评论跟帖;网易新闻网《重庆长寿法院受理”女孩抛童”案 原告索赔30万元》参与人数为121 298人,评论有13 731条;人民网《重庆摔打男童案 女孩称阳台逗玩致其坠落》共有157 956人关注,585人评论,共计收集新闻评论33 391条,经过人工筛选出与新闻主题无关和无感情倾向的语句2 894条后,从中抽取10 000条作为训练语料.
本文采用哈工大信息检索实验室的分词系统,对语料进行了词性的标注,用其开发的汉语句法分析器DeParser对句子进行分析.实验中用本文的特征词提取方法对比了基于句法分析提取词性因素作为特征词的方法,对比实验提取的词性因素为形容词、副词、动词和名词4类[5],从而构建了通用情感特征词表(GC)(如表1).

表1 特征词提取的例词
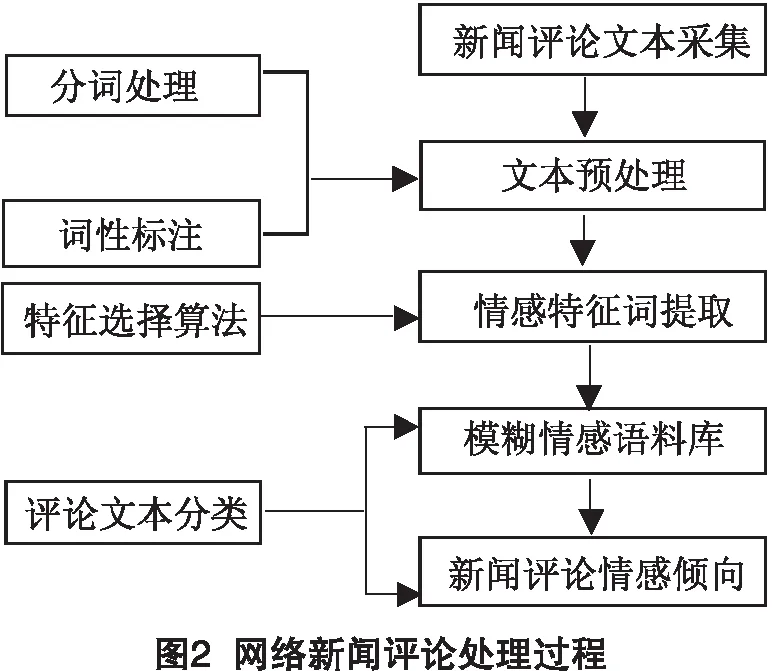
针对特征词的情感极性分类,本文采用了基础情感字典,主要基于知网[6]、《褒义词词典》、《贬义词词典》[7]为主,选用的基础情感词典中共有情感词汇 5 281 个,其中有 2 807 个褒义词,有 2 474 个贬义词.同时采用SVM和朴素贝叶斯[8]2种分类方法对语料进行分类处理,对比评价指标,结果显示本文对新闻评论内容情感特征提取的方法要优于根据词性对文本内的特征词的提取,而且NB分类方法也略微好于SVM分类方法.实验流程如图2所示.
实验采用Precisiom(查准率)和Recall(召回率)作为评价分类结果的指标,用朴素贝叶斯分类方法和SVM分类方法对不同的特征提取方法形成的语料库进行评测时,公式如下:
(4)
(5)
其中True(ci)是分类为ci并且正确的文档数,Response(ci)是分类为ci的文档数[9].
用朴素贝叶斯分类方法从中提取了1 493个特征词,其中正向词155个,负向词1 338个;用SVM分类方法提取的特征词为1 342,正向词为132个,负向词为1 210个.从实验结果中的召回率和准确率进行对比可知,朴素贝叶斯分类方法较适合用于新闻评论的情感分类研究,NB模型比SVM模型的召回率高出接近2%.而且本文对情感特征词的提取方法也比传统研究中根据词性提取关键词的方法好很多,如表2.
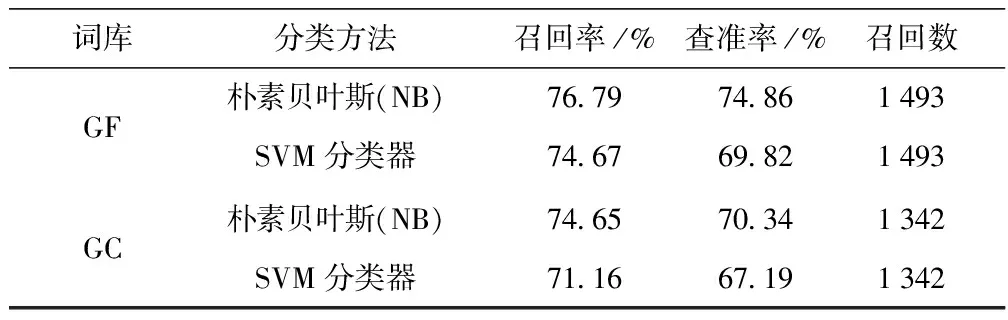
表2 模糊情感特征词库(GF)和通用情感特征词库(GC)的实验对比结果
5 结语
本文主要研究了网络新闻评论情感特征提取的难点,从模糊语义角度对特征提取进行了阐述,提出了用模糊理论扩充特征词语料库,并且与传统方法根据词性提取的特征词进行了对比实验,效果有明显提高.
上述研究中还存在一些问题尚未得到解决:①不同主题词和不同特征词之间的关系识别问题;②基准词选择的准确性问题,它直接影响到词汇倾向性分析的结果.通常基准词的选定是由研究者决定,具有较大的不客观性和不确定性,优化和度量基准词的选择方法是重要的研究课题.本文今后的研究将会基于初级扩充模糊集对情感词汇本体从隶属于情感分类、极性、强度等角度进行描述,构建模糊情感细分语料库,结合修饰词的模糊语言算子等方法对每条新闻评价的情感值进行模糊计算,通过对大量特征词情感值的综合计算得到网络评论者对新闻事件的情感倾向,分析出大量用户对某一情感目标的主要情感倾向等.
参考文献:
[1] 王代强,李旭曜.我国网络新闻评论文献综述[J].新闻与传播研究,2011(7):16-18.
[2] ZADEH L A. Fuzzy sets[J].Information and Control, 1965, 8(3):338-353.
[3] 刘颖.基于消费者网络评论情感的产品模糊推理研究[D].大连:大连理工大学,2010.
[4] 陶富民,高军,周凯.面向话题的新闻评论的情感特征选取[J]. 中文信息学报,2010 (03):37-43.
[5] 娄德成,姚天防.汉语句子语义极性分析和观点抽取方法的研究[J].计算机应用,2006,26(11):622-625.
[6] JINDAL N, LIU B. Identifying comparative sentences in text document[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2006:24-251.
[7] LIN,WU D D. Using text mining and sentiment an analysis for online forums hotspot detection and forecast [J].Decision Support Systems,2010(48):354-386.
[8] 杨鼎,阳爱民.一种基于情感词典和朴素贝叶斯的中文文本情感分类方法[J].计算机应用研究,2010,27 (10):3737-3739.
[9] 王素格,李伟.面向中日关系论坛的情感分类问题研究[J].计算机工程与应用,2007,43(32):174-177.
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
湖北民族大学学报(自然科学版)(2021年1期)2021-04-02
数学大世界(2021年4期)2021-03-30
山东农业大学学报(自然科学版)(2020年5期)2020-11-02
西华大学学报(自然科学版)(2018年6期)2018-11-24
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
新闻传播(2016年21期)2016-07-10
新闻传播(2015年9期)2015-07-18
新闻传播(2015年3期)2015-07-12
