
冗余代码缺陷检测方法
2012-06-06 03:04龚丹丹王甜甜苏小红马培军
哈尔滨工业大学学报 2012年7期
龚丹丹,王甜甜,苏小红,马培军
(哈尔滨工业大学计算机科学与技术学院,150001 哈尔滨)
冗余代码缺陷检测方法
龚丹丹,王甜甜,苏小红,马培军
(哈尔滨工业大学计算机科学与技术学院,150001 哈尔滨)
为解决冗余代码缺陷检测复杂度较高且检测精度较低的问题,设计并实现了基于控制结构的冗余代码检测模型.通过对TOKEN序列建立复合语句结构信息表,精简了程序的控制依赖关系,并在此基础上对幂等操作、死代码以及冗余赋值3种冗余代码进行检测,有效降低了缺陷检测复杂度.通过分析Linux开源代码表明,本模型可以快速的检测大规模程序,并且具有较低的误报率和漏报率.因此本模型可以帮助程序员发现进而修正软件缺陷,维护软件可靠性.
冗余代码;TOKEN序列;代码标准化
程序中的冗余代码意味着算法设计、代码实现中存在着问题.冗余代码不仅影响软件的测试评估和运行效率,同时还存在着潜在的安全隐患,并由此而引发语义和逻辑缺陷,而这些缺陷很难被已有的软件缺陷检测工具检测到,因此,需要对程序中的冗余代码进行检测.目前的冗余代码检测算法普遍误报率较高,很多学者针对缺陷误报率,进行了广泛的研究.其中,符号执行类方法[1-5]成为当前热门的检测方法,但在遇到循环、过程调用、选择分支过多时,符号执行实现困难.文献[6-9]根据区间运算理论提高检测精度,但目前现有的区间运算理论支持的数据类型单一,并不能解决非线性函数的区间运算和复杂条件表达式的区间运算.同时,这些方法都是基于控制依赖图和数据依赖图,分析的复杂度高,并不适合测试大型软件.本文具体分析了冗余代码不同类型所产生的误检原因,制定了相关的抑制误检的策略,有效提高了检测的精确度.
基于TOKEN序列的检测方法,由于其具有最佳的时空效率,已经被广泛用于重复代码检测.基于TOKEN序列的重复代码检测是将程序表示成TOKEN序列,使用模式匹配技术检查代码间的相似度,识别词法相似的程序代码,代表工具有Duploc、 NICAD、 Dup、 CCFinder、 CP-Miner等[10-14].这些方法的时间与空间开销较低,因此适合于分析大规模程序,然而它们只是在词法级别上对代码进行分析,并不能考虑语法或语义,仅仅只是处理程序的顺序结构,而无法处理选择和循环结构.简单的结构代码改变就可使该方法失效,因此不适合直接在TOKEN序列的基础上检测冗余代码.系统依赖图是程序的语义表示,能够充分表示程序的数据依赖、控制依赖信息以及函数调用信息,这适合于检测冗余代码缺陷,但因其系统依赖图的复杂度较高,并不适合于检测大规模程序.
针对上述分析,本文提出了精简的控制依赖关系,通过对TOKEN序列建立复合语句控制结构信息表,降低程序表示和分析的复杂度,以达到检测大型软件中的冗余代码的目的.
1 代码标准化
由于编程语言语法的多样性和代码实现的灵活性,相同的算法可能有多种不同的代码表达方式.例如,有些程序元素可以用一条语句表示,也可以用多条语句构成的语句序列表示(int i,j;等价于int i;int j;),这种现象称为代码多样化.识别这种语法表达形式多样但语义等价的代码,给程序分析带来了困难[15],直接影响了缺陷检测的精确度.程序标准化[16]是根据一系列标准化规则对程序进行语义等价的转换[17]的过程,目的是使语法表示不同但语义等价的程序有相同的系统表示,从而消除代码多样化,简化程序分析.
本文在TOKEN序列的基础上,根据一系列标准化规则进行结构语义等价的转换.转换规则如下.
1)将表达式转换为只引用变量而不定义变量的形式,从而消除副作用.例如:

2)拆分变量声明语句.例如:
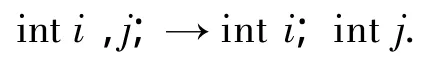
3)拆分变量声明与初始化语句.例如:
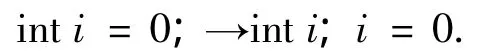
4)拆分连续的赋值语句.例如:
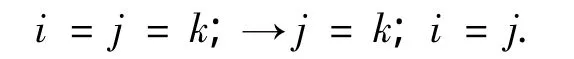
5)转换++、--运算符.例如:

6)转换符合运算符(+=、- =、*=、/=、%=).例如:
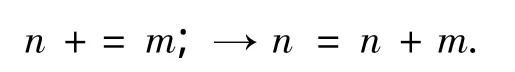
7)如果复合表达式中含有函数调用语句,则用临时变量替换该函数调用语句.例如:
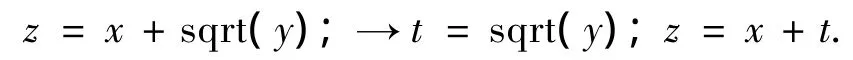
8)如果函数调用语句中的实参是复合表达式,则用临时变量替换该复合表达式.例如:
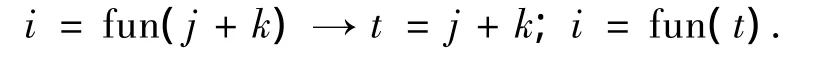
9)如果return语句返回的是复合表达式,则用临时变量替换该复合表达式.例如:
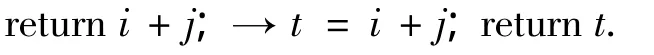
在消除代码多样化后大多数语法不同但语义等价的程序具有相同的TOKEN表示.这为冗余代码缺陷检测奠定了良好的基础,不仅可以简化程序分析,而且可以消除由于代码多样化所产生的误检.
2 复合语句控制结构信息表
复合语句控制结构信息表(CNT)记录了各复合语句的开始-结束位置等重要信息,按照CNT遍历程序的TOKEN序列,可以准确控制程序的扫描路径,CNT只记录复合语句信息,不需要分析整个程序的控制依赖关系,其复杂度远远低于控制依赖图.
冗余代码缺陷检测,需要考虑程序的控制依赖关系,因此,不能直接利用传统的TOKEN序列进行检测.
针对上述问题,本文针对每个函数建立复合语句控制结构信息表,存储复合语句的结构信息.根据结构信息表扫描TOKEN序列,充分考虑了程序的控制信息,节省了时间与空间,以达到应用于大规模程序的目的.
定义1(复合语句控制结构信息表(Compound node table,CNT)) 复合语句控制结构信息表是记录程序P中的所有复合语句(选择、循环)的开始、结束位置等关键信息的集合,它能够精简的记录程序的所有控制依赖关系,其结构定义如图1所示.
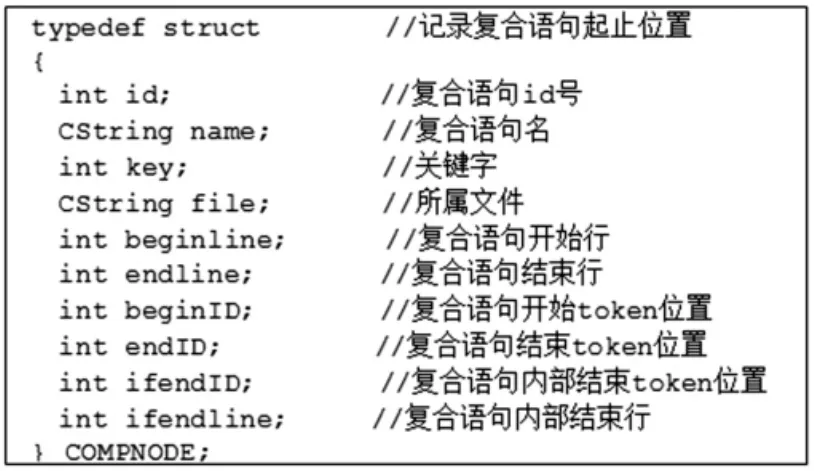
图1 复合语句控制结构信息表结构
对于多分支的选择结构,不仅应该记录选择结构的结束位置(endID)和结束行(endline),还应该记录各个分支内部的结束位置(ifendID)和结束行(ifendline),以便进行精确的路径分析.例如图2所示,多分支选择结构if(第13行),其内部分支结束位置ifendline=16,总分支结束位置endline=20;对于第33行的else分支,其内部分支结束位置即为总分支的结束位置,即endline=ifendline=20.循环结构无需考虑多分支情况,因此for的endline与ifendline的值相同.

图2 复合语句控制结构信息表实例
3 冗余代码缺陷检测
3.1 方法框架描述
冗余代码检测模型如图3所示,主要包括3个部分:
1)将程序转换为TOKEN序列,并在其基础上进行代码标准化,简化程序分析的同时消除由于代码多样化所产生的误检,进而在标准化的TOKEN序列基础上检测幂等缺陷.
2)TOKEN序列缺少程序的结构化信息,因而不能很好的表示变量的依赖关系.系统依赖图的复杂度较高,不适合分析大规模程序.针对此点,本文建立CNT,精简了控制依赖关系,即能保证时间与空间复杂度,又能充分表示程序的控制依赖关系.
3)根据CNT,在标准化后的TOKEN序列上检测死代码和冗余赋值缺陷.
最后根据缺陷检测结果,输出缺陷检测报告.
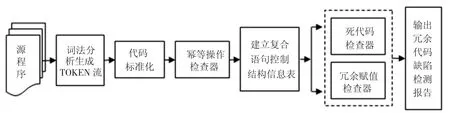
图3 冗余代码缺陷检测模型
3.2 幂等操作检查器
幂等操作包括下列3种情况:
1)赋值给自己(x=x);
2)被自身除(x/x);
3)自己与自己的位操作(x|x)或(x&x).
本检查器直接扫描程序的TOKEN序列,当所扫描的 TOKEN 为运算符“=”、“/”、“|”、“&”任一运算符时,比较运算符左右两端的TOKEN是否相等,如果相等,报告此缺陷.图4为利用幂等操作检查器所检查到的缺陷.
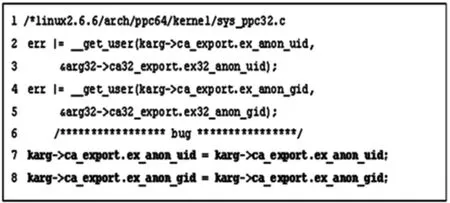
图4 利用幂等操作检查器可以检测出的软件缺陷
3.3 死代码检测器
所谓检查器,是指检测在程序运行时不可到达的代码.通过在Linux中的实验表明,此类缺陷的产生原因主要是由于break和return所导致的奇怪控制流.例如:break后面但和break同属一个块的执行语句为死代码;所有条件分支都包含return,则后面的代码将不会被执行等等.
该检查器涉及程序的控制信息,因此,根据CNT,在TOKEN序列的基础上进行控制结构分析.对每条路径,标记所有可由路径所到达的语句.对于未标记的语句给出错误信息.为了提高效率,本检查器以函数为单位进行检测,并跳过宏定义,图5为死代码检测具体算法.
此算法的关键之处在于按复合语句结构列表计算结束位置,充分考虑选择、循环的嵌套情况,根据不同的情况计算TOKEN序列的扫描跳转位置,即根据不同情况选择ifendID和endID.此检查器找到很多明显的错误,并且无误检.
图6、7为利用死代码检查器所检查到的缺陷.图6中第6行return语句后的语句不会执行,图7中循环中包含的if-else语句中两个分支均跳出循环,则后面的第13~18行语句不会被执行.

图5 死代码检查器算法
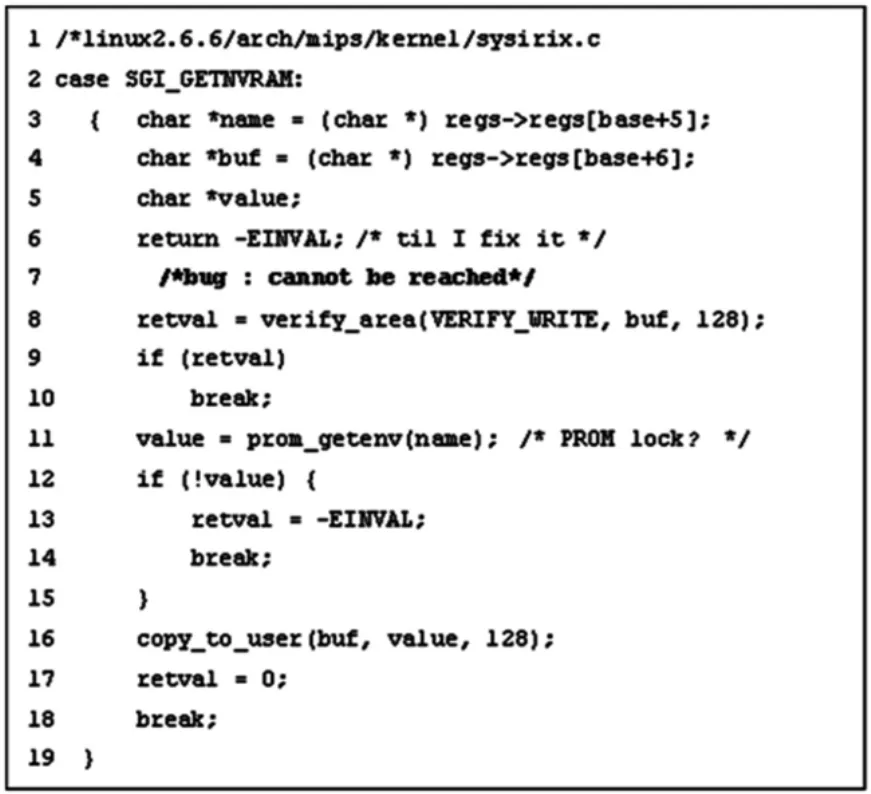
图6 死代码检测实例1
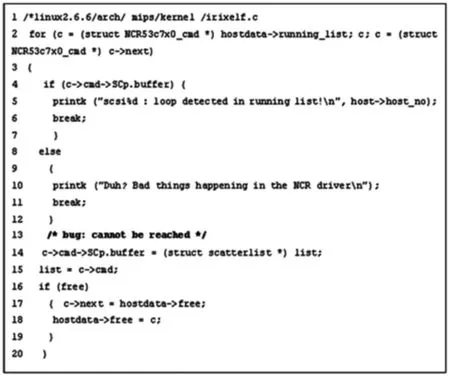
图7 死代码检测实例2
3.4 冗余的赋值语句检查器
该检查器跟踪变量的生存周期,在每个赋值语句处向前跟踪所有路径上的该变量.如果变量在退出所在域或被重新赋值前没被使用,并且变量并非作为函数参数返回值,则发送错误信息.
该检查器涉及程序的控制依赖分析,则仅在TOKEN序列的基础上扫描必然带来大量误检.因此,本文根据CNT,在TOKEN序列的基础上进行控制结构分析,在最佳的时空效率下保证了检测精度.
此检查器的误检大多来自于保守编程.本文分析了保守编程的具体情况,根据不同的情况,制定不同的策略:
1)特殊赋值或前面有类型定义:p=head;int i=5;此类情况为保守编程,不给出错误信息.
2)第1次赋值(除情况1外).可能是保守编程为变量赋初值,也可能是直接为变量赋值,对于此情况给出警告信息.具体算法如图8所示.

图8 冗余的赋值语句检查器算法
对于赋值语句位于循环结构中的情况,不仅要考虑”x=”中的”x”以及后面赋值的变量直接使用了循环变量,还要检测”x”以及后面赋值的变量间接使用循环变量的情况,以减少误检.
图9中列出了此检查器检测的Linux代码冗余缺陷,第5行第1次为变量赋值,给出警告信息,第7行变量赋值后未使用,给出错误提示.

图9 冗余的赋值语句检测实例
4 实验结果与分析
4.1 实际开源代码缺陷检测结果分析
本文对开源代码Linux-2.6.6中的部分模块进行了检测.本文实验条件为:Intel酷睿2双核T5670,1.80 GHzCPU,1GB 内存,开发用工具为VC++6.0.表1~表3列出了实际开源代码缺陷检测的实验结果.

表1 幂等缺陷检测结果统计

表2 死代码缺陷检测结果统计

表3 冗余赋值缺陷检测结果统计
4.2 人工注入缺陷检测结果分析
为了统计漏检率,本文对部分Linux源代码进行了人工注入缺陷实验.表4~表6列出了人工注入缺陷检测实验结果.
通过在Linux源代码中实验表明,本文所提出的冗余代码缺陷检测算法可以快速的识别大规模程序中的幂等操作、死代码以及冗余赋值缺陷,并且检测精度高,误报率及漏报率均为0.幂等缺陷检查器直接在TOKEN序列基础上进行扫描,时间复杂度最低.而死代码和冗余赋值缺陷检测以函数为单位,在TOKEN序列的基础上,利用CNT查找程序的控制依赖关系,时间复杂度略有提高.冗余赋值检测器为了有效抑制误检,对于变量定义后第1次赋值,有可能是保守编程,给出警告.若变量不是第1次赋值,报告冗余赋值缺陷.

表4 人工注入幂等缺陷检测结果统计

表5 人工注入死代码缺陷检测结果统计

表6 人工注入冗余赋值缺陷检测结果统计
5 结论
1)提出了代码标准化规则,且消除代码多样化,并简化程序分析,有利于消除缺陷检测中因代码多样化产生的误检.
2)本文提出了CNT,精简了程序中控制依赖关系的表示.
3)设计并实现了基于控制结构的冗余代码缺陷检测模型,对程序中的幂等操作、死代码以及冗余赋值3种冗余代码进行检测.该模型针对各种可能产生误检的原因进行了分析,制定了相关的抑制误检的策略.通过实验证明,本模型可以快速检测大规模程序,并且具有较低的误报率和漏报率.
[1]ZHANG Jian.Constraint solving and symbolic execution[C]//Proceedings of the Verified Software:Theories,Tools,Experiments.Heidelberg,Berlin:Springer-Vierlag,2005:539 -544.
[2]XU Xiao,ZHANG Xiaosong S,LI Xiongda.New approach to path explosion problem of symbolic execution[C]//Proceedings of the 2010 First International Conference on Pervasive Computing,Signal Processing and Applications.Washington,DC:IEEE Computer Society,2010:301-304.
[3]COHEN M B,DWYER M B,SHI Jiangfan.Exploiting constraint solving history to construct interaction test suites[C]//Proceedings of the Testing:Academia and Industry Conference-Practice And Research Techniques.Washington,DC:IEEE Computer Society,2007:121 -130.
[4]PAPADAKIS M,MALEVRIS N.Automatic mutation test case generation via dynamic symbolic execution[C]//Proceedings of the 2010 IEEE 21st International Symposium on Software Reliability Engineering.Washington,DC:IEEE Computer Society,2010:121-130.
[5]PAPADAKIS M,MALEVRIS N.A symbolic execution tool based on the elimination of infeasible paths[C]//Proceedings of the 2010 Fifth International Conference on Software Engineering Advances.Washington,DC:IEEE Computer Society,2010:435 -440.
[6]王雅文,宫云战,肖庆,等.区间运算在软件缺陷检测中的应用[C].苏州:第五届中国测试学术会议论文集,2008:51-52.
[7]王雅文,宫云战,肖庆,等.扩展区间运算的变量值范围分析技术[J].北京邮电大学学报,2009,32(3):36-41.
[8]王志言,刘椿年.区间算术在软件测试中的应用[J].软件学报,1998,9(6):438-443.
[9]GHODRAT M A,GIVARGIS T,NICOLAN A.Expression equivalence checking using interval analysis[J].IEEE Transactions on Very Large Scale Integration(VLSI)Systems,2006,14(8):830 -842.
[10]DUSCASSE S,RIEGER M,DEMEYER S.A language independent approach for detecting duplicated code[C]//Proceedings of the IEEE International Conference on Software Maintenance.Washington,DC:IEEE Computer Society,1999:109-118.
[11]ROY C K,CORDY J R.NICAD:accurate detection of near-miss intentional clones using flexible pretty-printing and code normalization[C]//Proceedings of the 2008 the 16th IEEE International Conference on Program Comprehension.Washington,DC:IEEE Computer Society,2008:172 -181.
[12]BAKER B.Parameterized duplication in strings:algorithms and an application to software maintenance[J].SIAM Journal on Computing,1997,26(5):1343 -1362.
[13]KAMIYA T,KUSUMOTO S,INOUE K.CCFinder:a multilinguistic token-based code clone detection system for large scale source code[J].IEEE Transactions on Software Engineering,2002,28(7):654-670.
[14]LI Zhenmin,LU Shan,MYAGMAR S,et al.CP-miner:finding copy-paste and related bugs in large-scale software code[J].IEEE Transactions on Software Engineering,2006,32(3):176-192.
[15]RIEGER M.Effective clone detection without language barriers[D].Switzerland:Dissertation,University of Bern,2005.
[16]De JONGE M,VISSER E,VISSER J.XT:a bundle of program transformation tools system description[J].E-lectronic Notes in Theoretical Computer Science,2001,44(2):79-86.
[17]VISSER E.A survey of strategies in rule-based program transformation systems[J].Journal of Symbolic Computation,2005,40(1):831 -873.
Redundancy detection based on control structure analysis
GONG Dan-dan,WANG Tian-tian,SU Xiao-hong,MA Pei-jun
(School of Computer Science and Technology,Harbin Institute of Technology,150001 Harbin,China)
To deal with the problems such as high complexity and low accuracy of redundancy detection,a model of redundancy detection based on control structure analysis is proposed and implemented.This paper predigests the complexity of control structure by establishing a compound node table for tokens,which reduces the complexity of redundancy detection,and then detects the idempotent operations,dead code and redundant assignment.Experimental results of the open source code of Linux show that this model can find redundant code accurately and also has a low time-complexity.With this model,it is very convenient for developers to detect and correct these kinds of defects,and thereby to further guarantee the software quality.
redundant code;TOKEN;code standardization
TP311
A
0367-6234(2012)07-0058-06
2011-06-21.
国家自然科学基金资助项目(61173021);高等学校博士学科点专项科研基金资助项目(20112302120052,20092302110040);中央高校基本科研业务费专项资金资助项目(HIT.NSRIF.201178).
龚丹丹(1982—),女,博士研究生;
苏小红(1966—),女,教授,博士生导师;
马培军(1963—),男,教授,博士生导师.
龚丹丹,gongdandan0418@126.com.
(编辑 张 `红)
猜你喜欢
榆林学院学报(2022年4期)2022-08-02
铁道通信信号(2019年1期)2019-03-21
中国惯性技术学报(2019年6期)2019-03-04
计算机与生活(2018年8期)2018-08-15
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
中学生数理化·高一版(2017年1期)2017-04-25
理科考试研究·高中(2016年9期)2016-05-14
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
石油化工自动化(2014年6期)2014-09-10
