
基于单链表的二叉树非递归遍历算法
2012-01-15 03:52王防修
武汉轻工大学学报 2012年4期
王防修,周 康
(武汉工业学院数学与计算机学院,湖北武汉430023)
二叉树是一种重要的非线性数据结构,其应用[1-4]相当广泛。因此,掌握二叉树的各种特性是灵活使用二叉树的基础。在二叉树的所有特性中,二叉树的遍历是需要掌握的重点。传统遍历二叉树的方式一般采用递归遍历算法[5-9]。然而,这种递归遍历算法存在明显缺点:①算法难以反映二叉树被访问的详细过程;②在遍历过程中需要消耗大量系统栈空间;③递归算法比非递归算法需要花费更多的时间。
因此,为了克服二叉树递归遍历算法的这些缺点,相继出现了二叉树的非递归算法[10-17]。从这些论文的内容可以明显发现,所有遍历二叉树的非递归遍历算法都需要借助栈或队列来实现。如二叉树的先序遍历、中序遍历和后序遍历需要借助栈实现非递归算法,而二叉树的层次遍历需要借助队列实现非递归算法。从现有的研究成果可以看出,所有的非递归遍历二叉树的算法都采用静态栈或静态队列来存储节点地址。事实上,在未遍历一棵二叉树之前,是无法知道该二叉树到底包含多少节点的。这直接导致静态栈和静态队列应该分配多大的内存空间才比较合适的问题。如果空间分配太小,就会在遍历过程中出现栈空间或队列空间不足的情形;相反,如果栈空间或队列空间定义过大,对遍历小规模的二叉树又是一种内存空间浪费。因此,如果不能精确定义栈空间和队列空间的大小,就会大大限制二叉树的非递归算法的应用范围和解决实际问题的能力。
本方案通过引入单链表并对其操作加以限制,从而得到链栈和链队列。由于链栈和链队列都能根据需要动态增加和减少各自的栈空间和队列空间,使得将链栈和链队列应用于二叉树的非递归遍历算法,就不会出现栈空间和队列空间浪费或不足的情形。因此,链栈和链队列可以很好解决目前非递归遍历二叉树存在的缺点,大大提高非递归遍历二叉树算法的通用性。
1 链栈和链队列的模块设计
单链表的插入和删除位置是任意的,可以是表首、表尾或表的中间任意位置。如果限定元素的插入和删除只能在表首进行,此时的单链表就变成链栈。同样,如果限定只能在单链表的表首删除元素,而在单链表的表尾插入元素,则此时的单链表就变成链队列。为方便算法描述,特将单链表定义如下:
typedef struct node*link;
struct node{
elsemtype data;
link next;};
1.1 链栈的模块设计
1.1.1 链栈的初始化
void ini_stack(link*s){
*s=NULL;}
链栈的初始化说明,在做栈操作之前的栈是没有栈空间的空栈。
1.1.2 元素入栈
void push(link*s,elemtype x){
link q;
q=(link)malloc(sizeof(*q));
q->data=x;q->next=*s;*s=q;}
每当有一个元素入栈,就首先为该元素申请一个节点的空间,然后将该元素保存在该节点的数据域中,最后将该节点在表首插入,使得新入栈的元素总在栈顶。
1.1.3 元素弹栈
int pop(link*s,elemtype*x){
link q;
if(*s==NULL)return 0;
else{q=*s;*s=q->next;*x=q->data;free(q);return 1;}
}
如果函数返回0,表示栈已经空,没有元素可以出栈。当函数返回1,表示保存在*x中的出栈元素有效。每从栈中弹出一个元素,就回收单链表的表首节点。
从链栈的入栈和出栈操作可以发现,每成功入栈一个元素,链栈就增加一个节点的栈空间,每成功出栈一个元素,链栈就减少一个节点的栈空间。
1.2 链队列的模块设计
1.2.1 链队列的初始化
void ini_queue(link*front,link*rear){
*rear=*front=NULL;}
链队列的初始化说明,在做队列操作之前的链队列是不占内存空间的空队列。
1.2.2 元素入队模块
void in_queue(link*front link,*rear,elemtype x){
link q;
q=(link)malloc(sizeof(*q));q->data=x;q->next=NULL;
if(*rear==NULL)*front=*rear=q;
else{(*rear)->next=q;*rear=q;}
}
每当有一个元素入栈,就首先为该元素申请一个节点的空间,然后将该元素保存在该节点的数据域中,最后将该节点在表尾插入,使得新入队的元素总在队尾。需要注意的是,当第一个元素入队时,需要同时改变队首指针,而不仅仅是队尾指针。
1.2.3 元素出队模块
int out_queue(link*front,link*rear,elemtype*x){
link q;
if(*front==NULL)return 0;
else{q=*front;*front=q->next;*x=q->data;free(q);
if(*front==NULL)*rear=NULL;return 1;}
}
如果函数返回0,表示队列已空,没有元素可以出队。当函数返回1,表示保存在*x中的出队元素有效。每从队列中出队一个元素,就回收单链表的表首节点。如果此时队中只有一个元素可以出队,注意出队之后需要同时修改队首和队尾指针。
2 二叉树的非递归遍历算法描述
2.1 使用链栈的非递归遍历算法
二叉树的遍历一般表现为先序遍历、中序遍历和后序遍历三种。这三者的递归算法很简单,但其非递归算法只有在深入理解二叉树以及栈的先进后出特性之后才能得到。
2.1.1 先序遍历二叉树的非递归算法
步骤1 首先将根节点入栈。
步骤2 弹出栈顶节点并访问该节点。如果该节点的右孩子非空,则将其右孩子入栈。如果该节点的左孩子不空,则将其左孩子入栈。
步骤3 重复步骤2,直至栈空为止。
2.1.2 中序遍历二叉树的非递归算法
步骤1 从二叉树的根节点出发,沿着左子树一直往下走,将暂时不能处理的节点都入栈,直到找到一个节点的左子树为空为止,并将该节点入栈。
步骤2 如果栈不空,则从栈中弹出一个节点并访问之。
步骤3 转向步骤2中被访问节点的右孩子。
步骤4 重复步骤2和步骤3,直到栈空并且二叉树中的所有节点被访问为止。
2.1.3 后序遍历二叉树的非递归算法
步骤1 首先将根节点入栈。
步骤2 每次从栈中弹出一个节点,为了保证先访问左右子树后再访问根节点,要检查该节点的左、右子树是否已经被访问过。如果未被访问,则将该节点的右、左孩子依次入栈。如果已被访问,则弹出该节点并访问之。
步骤3 重复步骤2,直至栈空为止。
2.2 使用链队列的二叉树层次遍历算法
步骤1 首先将根节点入队。
步骤2 每次从队首取出一个节点并访问之,如果该节点的左孩子不为空,则将左孩子入队;如果该节点的右孩子不空,则将右孩子入队。
步骤3 重复步骤2,直至队空为止。
3 算法实现
为了更加清楚地表达本文的主旨,有必要对上面介绍的部分算法的实现加以呈现。通过这两个算法的实现,将更能体现链栈和链队列在解决栈空间或队列空间方面的优势。现将二叉树定义如下:
type struct node1*bintree;
struct node1{
datatyrpe data;
bintree lchild,rchild};
3.1 用链栈实现先序遍历二叉树的非递归算法
void preorder1(bintree t){
link s=NULL,q;bintree p;int flag;
if(t! =NULL)push(&s,t);
while(s!=NULL)
{flag=pop(&s,&p);//弹栈
显示出栈元素;
if(p->rchild! =NULL)push(&s,p->rchild);//如果右孩子非空,则右孩子入栈
if(p->lchild! =NULL)push(&s,p->lchild);//如果左孩子非空,则左孩子入栈
}}
3.2 用链队列实现层次遍历二叉树的非递归算法
void level_order(bintree t)
{bintree p;int flag;link front,rear,q;
front=rear=NULL;
if(t! =NULL)in_queue(&front,&rear,t);//根节点入队
while(front!=NULL)
{flag=out_queue(&front,&rear,&p);//出队
显示出队元素;
if(p->lchild! =NULL)in_queue(&front,&rear,p->lchild);//左孩子入队
if(p->rchild! =NULL)in_queue(&front,&rear,p->rchild);//右孩子入队
}}
4 算法测试
现给出如图1和图2所示的二叉树,当将其进行非递归遍历,分别得到如表1和表2所示的结果。

图1 7个节点的二叉树
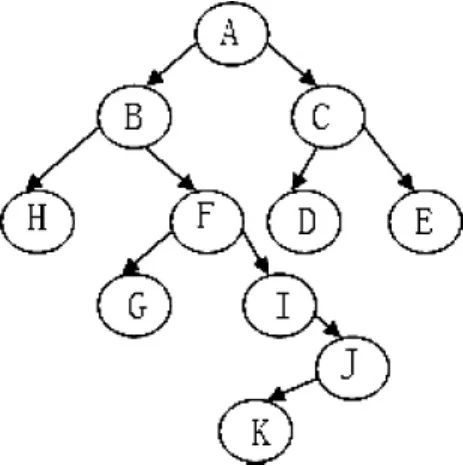
图2 11个节点的二叉树

表1 7个节点的二叉树非递归遍历结果

表2 11个节点的二叉树非递归遍历结果
表中的A(1)表示字符A在栈顶或表首时,此时的单链表的长度为1,其他如此类推。从表1和表2的结果可以明显发现:①非递归遍历所需要的栈空间和队列空间都比二叉树的节点数少;②不同结构的二叉树,它对栈空间和队列空间的需求量是不一样的;(3)二叉树遍历所需的栈空间和队列空间是没有任何规律的。
因此,采用动态分配栈空间和队列空间能够按需分配二叉树所需要的内存空间,只要内存空间足够大,能够适合于任意二叉树的非递归遍历。
5 结束语
基于单链表实现链栈和链队列的方法,实现了栈空间和队列空间的动态增加和减少,大大提高了非递归遍历二叉树的适用范围,同时降低了内存空间的浪费,提高了二叉树的遍历速度,且能在任何情况下按需分配栈空间和队列空间。总之,只要内存空间允许,链栈和链队列在实现二叉树的非递归遍历算法的过程中总能满足算法对栈空间和队列空间的需求。
[1] 裴洪虎,郭锐锋.三角形二叉树在数控加工仿真中的应用[J].计算机工程,2011,37(21):214-216,219.
[2] 孙文胜,刘婷.一种改进的基于二叉树搜索的防碰撞算法[J].计算机工程,2011,37(10):257-259.
[3] 周燕,侯整风.基于有序二叉树的快速多模式字符串匹配算法[J].计算机工程,2010,36(17):42-44.
[4] 范柏超,王建宇.结合特征选择的二叉树SVM多分类算法[J].计算机工程与设计,2010,31(12):2883-2885.
[5] 杨智明.基于二叉树前序遍历的递归算法分析[J].保山学院学报,2010(2):62-64.
[6] 郭金华,占明.浅议二叉树的遍历[J].科技信息,2010(17):65.
[7] 尹帮治.基于链栈数组的二叉树按层遍历递归算法[J].重庆科技学院学报,2009,11(3):167-169.
[8] 尹帮治.二叉树遍历的通用递归算法研究与实现[J].电脑知识与技术,2008(3):132-134.
[9] 郝阳阳.二叉树遍历方法的研究和应用[J].内江科技,2008(4):45.
[10] 陈宇,于洋.遍历二叉树的非递归算法[J].计算机应用,2009(9):160,146.
[11] 罗帅.二叉树遍历的非递归算法分析与实现[J].电脑知识与技术,2008(2):678-680.
[12] 张亚萍,陈得宝.二叉树遍历教学方法研究[J].牡丹江师范学院学报,2010,73(4):69-70.
[13] 黄霞.二叉树的先序遍历和中序遍历的非递归算法[J].电脑开发与应用,2009,23(1):53-54,59.
[14] 黄霞.二叉树后序遍历的非递归算法[J].现代计算机,2009(10):57-60.
[15] 孙毅,张丽.新型二叉树后序遍历非递归算法[J].金陵科技学院学报,2008,24(1):27-29.
[16] 柴宝杰,马弘伟.用栈无标记变量后序遍历二叉树算法[J].牡丹江师范学院学报,2008,64(3):18-20.
[17] 马相芬.中序遍历二叉树的算法实现[J].科技信息,2008(12):227,281.
猜你喜欢
少先队活动(2022年5期)2022-06-06
现代计算机(2021年14期)2021-07-09
少先队活动(2020年7期)2020-08-14
中国海洋大学学报(自然科学版)(2019年2期)2019-12-07
——基于二叉树的图像加密
数字通信世界(2019年4期)2019-06-03
天水师范学院学报(2018年5期)2018-12-04
小学生学习指导(低年级)(2018年10期)2018-10-13
小学生作文(中高年级适用)(2017年6期)2017-07-07
武汉轻工大学学报(2016年4期)2017-01-16
现代检验医学杂志(2016年4期)2016-11-15
