
基于激光诱导击穿光谱及共识规则技术的海鱼重金属污染感知数据采集与检测应用研究
2024-05-29 04:22孙寒冰刘德亮
客联 2024年2期
孙寒冰 刘德亮
摘 要:本文选取海鱼泥蚶为研究对象,产自浙江省沿海人工养殖区,污染重金属离子分别为铜、锌、铅、镉等。结合LIBS光谱特性及重金属元素的激发谱线,进行指纹信息筛选、数据挖掘和模式识别等数学算法,研究基于误差拟合法的共识规则,使共识模型的预测稳定性更好,实现LIBS技术在复杂体系海鱼重金属污染信息的快速检测。通过LIBS光谱特征集形成的成员模型,如何分配权系数来构建共识模型。包括:筛选那些与重金属离子高度相关的谱线或其形态的特征信息,来构建成员模型。通过拟合成员模型间的误差且使各误差之间的相关性最低,来拟合共识模型,分配权系数,使拟合模型的误差最小。解决常规成员模型单一、信息量不足的缺陷;尽量多地挖掘LIBS光谱数据的信息。提高检测结果的精度和准度。
关键词:LIBS光谱;海鱼重金属污染
一、研究方案
不同重金属富集和交叉污染下的海鱼饲养及重金属富集信息的分布。分别以养殖基地和可控环境下同步进行饲养,选用我国沿海典型的养殖海鱼泥蚶作为研究对象。污染指标为四种典型重金属离子(铜、锌、铅、镉),单一污染以及它们的交叉(混合)污染。利用正交表试验设计10个浓度梯度下的污染水平(2, 4, 6, …, 20微克/升),进行重金属胁迫下饲养。鉴于泥蚶的新陈代谢周期、重金属富集水平(富集量在一个月内基本达到稳定),因此饲养周期设定为五天一个周期,即5/10/15/20/ 25/30天,共计六个时间周期。同时采集实际过程中邻近重金属污染源处的泥蚶样本。将每一期收集到的泥蚶样本存在于同一个密封袋,视作为一个样本,存放于-4℃冰箱保存。
LIBS光谱分析技术的样品预处理及光谱采集系统的参数优化。由于LIBS光谱分析受水分影响,因此,需要对泥蚶样本进行处理。重金属与海鱼体内的蛋白质、脂肪等组分结合,形成的络合物结构相对稳定,对海鱼的肌肉及内脏进行烘干处理以及烘干、磨粉、压片等处理,减少水分和样本非均质对模型构造的干扰以期获取可靠的光谱信息。搭建LIBS光谱采集系统,研究光谱采集参数,包括积分时间、参比校正时间、激光源的光源强度、扫描时间间隔、扫描次数等对响应信号获取的影响,确定最优的系统采集参数,提高光谱采集系统的重现性、信噪比。LIBS光谱数据的预处理。研究各种重金属离子污染的泥蚶样本与健康泥蚶的光谱信号差异,对比不同种类、不同浓度下的重金属离子污染海鱼拉曼光谱响应信号的变化规律。采用位移校正、多元散射校正、基线校正、小波去燥处理、标准正态分布校正等方法对原始光谱数据预处理,来提高各种光谱数据的信噪比,降低采样不均匀以及各种噪音的影响。
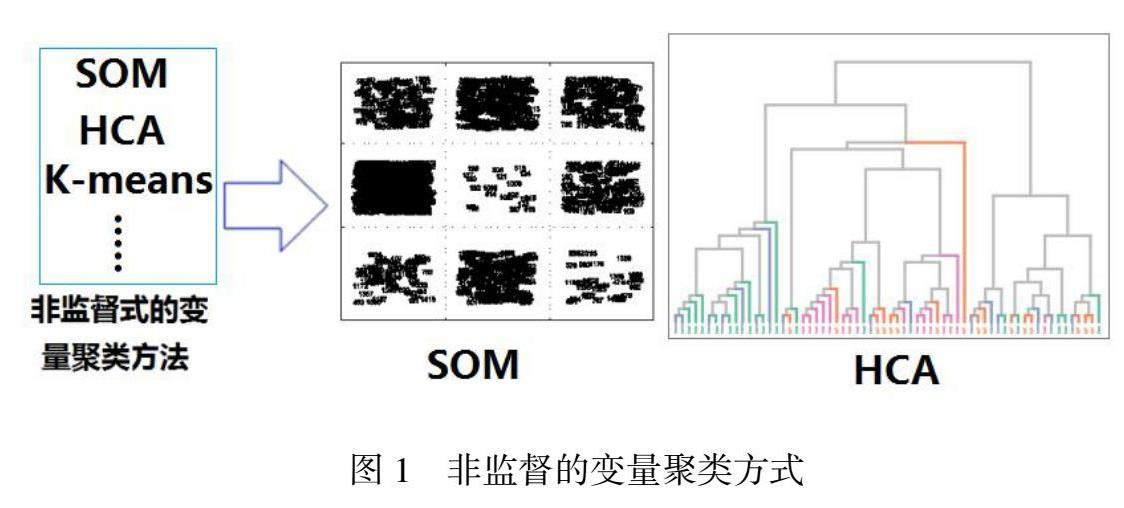
脉冲峰变量的非监督聚类,其聚类单元代为特征构建成员模型。利用非监督的聚类方法将具有变化趋势相似的谱峰变量分类为一个聚类单元,即首先将具有相似性的光谱变量自动聚类,再以各变量聚类单元单独或联合地构建定性、定量模型。选择那些预测性能表现较好的校正模型,作为潜在的成员模型,用于后续的共识模型的构建。非监督的聚类方法有自组织映射(Self-organizing mapping, SOM)、层次凝聚聚类算法(Hierarchical Agglomerative Clustering,HCA)、K均值法(K-means)等。同时分析特定重金属谱线的形态特征,统计谱峰的强度、面积、比值等,分别构建成员模型。
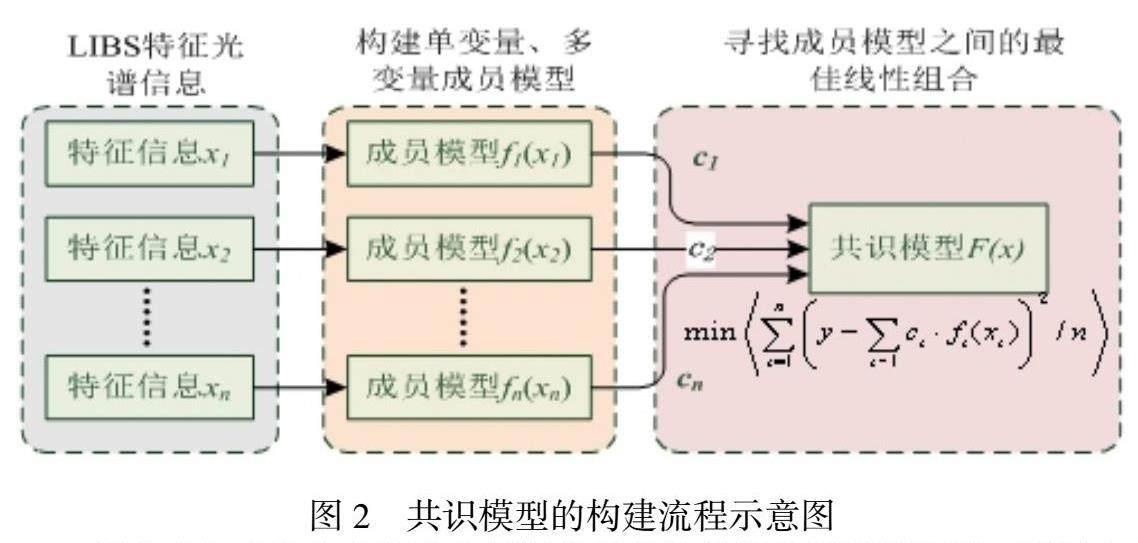
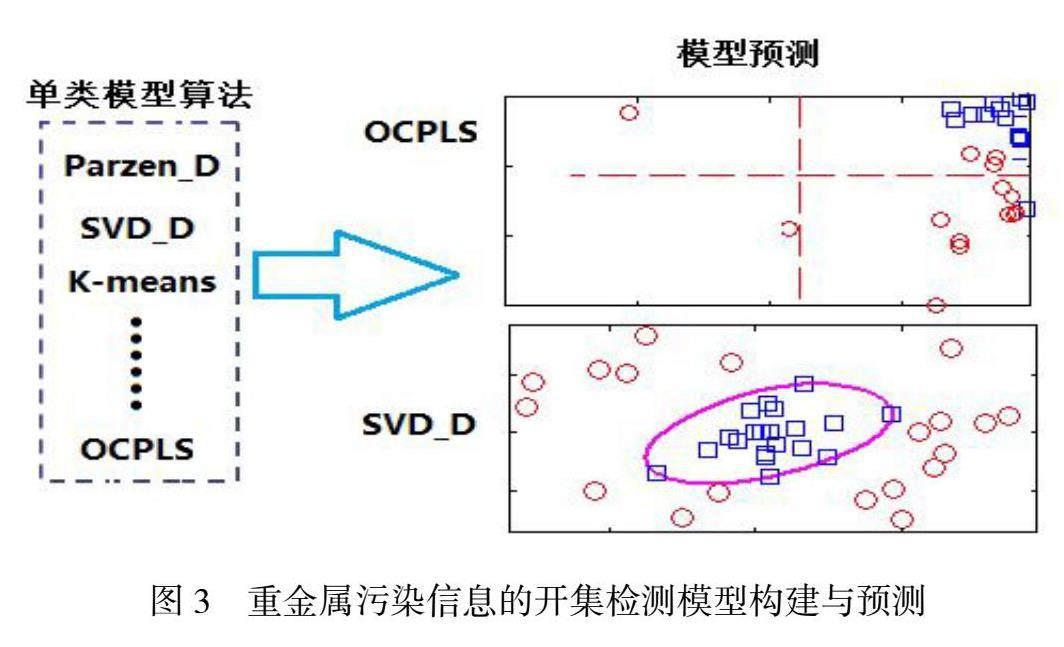
多成员模型有效融合成共识模型。它并不是一种基于特征空间映射的建模方法,而是融合多个成员模型、按特定共识规则分配权系数ci,从而达成共识,其流程如3所示。首先,成员模型fi(xi)是基于训练集样本的各特征集{x1 , …, x2}分别构建而成;其次是融合各成员模型(如式1),根据权系数ci来计算各成员模型预测值与真实值之间残差的平方和(Mean root errors, MSE)(如式2);最后,设定约束条件(0 部分未知或完全未知重金属污染信息的单类分类模型构建。通过上述筛选的特征指纹图谱及共识模型后,将已知重金属污染的光谱数据、交叉污染的光谱数据、健康样本的光谱数据定义为正类,根据所获得的正类样本所有数据进行边界描述,估计其边界,落在边界内可判定为正类;若落在边界外,模型将拒绝检测(可定义为异常类)。尝试引进单类识别算法,如支持向量机数据描述鉴别分析(SVDD)、核最近邻描述(KNN)、单类偏最小二乘回归分类(OCPLS)等数学建模算法,利用隐含的非线性核函数映射提升單类分类模型的识别性能,实现其在复杂体系下的海鱼重金属污染信息的检测(请见图4)。 二、技术路线 针对重金属污染的泥蚶进行激光诱导击穿光谱的的快速检测,包括人工饲养受重金属污染的泥蚶样本、LIBS特征波段及脉冲峰形态参数的挖掘、成员模型的优化、共识模型的构建、单类分类器的设计等。 三、结论 通过本项目的研究,未知污染体系下,探究单类分类模型对未知光谱信息与目标类别的识别及内部隐含关系。基于实际养殖过程中,无法对生态环境中所有重金属及其他污染物信息进行枚举,不能训练所有的污染类型,只能对其中的某些具体的污染类型进行训练建模。因此,针对训练样本的光谱响应信号的特点与分布规律,确定合理的数据描述边界,拒绝识别未受模型训练过的样本描述边界,挖掘不同类别间的函数隐含关系来扩大样本范围,构建单类分类器来识别健康样本。这是解决复杂基质和多种重金属污染体系下的识别目标海鱼样本的关键问题。 作者简介:孙寒冰,宿州学院信息工程学院教师。刘德亮,宿州学院信息工程学院教师。 基金项目:博士科研启动基金2023BSK023。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
快乐语文(2021年13期)2021-06-15
小学生学习指导(当代教科研)(2021年6期)2021-05-23
马克思主义哲学研究(2020年1期)2020-11-26
人大建设(2019年12期)2019-11-18
创新作文(3-4年级)(2017年9期)2018-04-13
创新作文(小学版)(2017年26期)2017-02-26
作文周刊·小学二年级版(2016年23期)2016-09-14
中国光学(2015年5期)2015-12-09
发明与创新(2015年17期)2015-02-27
