
求解带容量约束车辆路径问题的改进遗传算法
2024-03-21 01:59徐伟华邱龙龙张根瑞魏传祥
计算机工程与设计 2024年3期
徐伟华,邱龙龙,张根瑞,魏传祥
(昆明理工大学 交通工程学院,云南 昆明 650000)
0 引 言

遗传算法(genetic algorithm)自1975年提出以来,目前已被广泛应用于路径规划[13]、参数寻优[14]、车间调度[15]等实际工程领域。传统遗传算法求解CVRP时,存在收敛速度慢、求解精度不高、局部搜索能力差等问题,针对这些问题,本文提出了改进遗传算法(improved genetic algorithm)。
1 问题描述及模型建立
1.1 问题描述
本文研究的带有容量约束的车辆路径问题由一个配送中心,若干台可用车辆及多个分散客户组成,求解该问题的目标是在满足容量约束的情况下,为分散的客户找到最短的配送路线,并安排好服务次序。
CVRP定义为一个有向图G=(V,E),顶点集V={0,1,2,…,N},边集E={(i,j)|i,j∈V},其中0代表配送中心,节点 {1,2,…,N} 代表有特定需求qi的客户,其中i={1,2,…,N},节点i到j之间的距离用dij表示。可用配送车辆集合M={1,2,…,k},质地相同,最大容量限制均为Q。如果车辆k直接从客户i出发到达客户j,则xijk=1,否则xijk=0;如果车辆k直接服务客户i,则yik=1,否则yik=0。
1.2 模型建立
建立如下数学模型
(1)
约束条件
(2)
(3)
(4)
(5)
(6)
(7)
其中,式(1)为目标函数,即车辆配送总距离最短;式(2)表示每个客户仅由一辆车服务式;式(3)为车载容量约束,即每条路径上客户需求量之和不超过配送车辆最大载重限制;式(4)保证每个客户都被服务到;式(5)和式(6)表示车辆服务时一定有路径连接;式(7)表示所有线路均从同一仓库开始,服务结束后回到仓库。
2 求解CVRP的改进遗传算法
2.1 染色体编码与解码
本文采用自然数编码,将所有节点(不含配送中心)编码组成一条染色体。如1个配送中心,8个客户点以及2台可用车辆组成的编码为{23486751},解码时先将第一个客户点2加入到配送路径中,再判断下个客户3加入路径是否能满足车载容量约束,若能满足,则将该客户加入当前配送路径;若不能满足,则取当前客户点为下一条配送路径的起点,并更新上一条路径。以此规则,可获得配送路线分别为{02340}、{0867510},每条路线由一辆车服务。图1(a)为染色体编码,图1(b)为染色体解码。

图1 染色体编码与解码
2.2 初始种群生成
对于CVRP的求解,本文采用贪婪算法生成初始种群,并引入车载容量限制。相比随机生成策略,贪婪算法可以产生质量更高的初始种群。生成初始解的步骤如下:
步骤1 随机从所有客户点中选出一个点作为染色体的首位基因;
步骤2 通过计算选出与当前点距离最近且满足约束条件的客户作为下一个基因,直到所有客户加入染色体,且没有重复;
步骤3 重复步骤1和步骤2N次,即可生成规模为N的初始种群。
2.3 启发式交叉算子
交叉操作模拟了自然界生物种群交配的过程,对选中的两个个体使用交叉算子来产生新的个体。随机交叉算子虽然能够增强算法的全局寻优能力,但随着客户点的增多,可能会增加无效搜索,降低搜索效率,针对这一缺点,本文提出了基于贪婪策略的启发式交叉算子(heuristic cros-sover operator)。其基本思想是:子代以继承父代染色体的一个基因为基础,并以距离为启发函数,优先搜索距离当前点最近的客户作为下一个基因,再逐步搜索子代的其余基因。基于贪婪策略的启发式交叉算子的具体操作如下:
随机选取两个父代染色体X1={x11,x12,…,x1N} 和X2={x21,x22,…,x2N},则产生子代染色体的步骤为:
步骤1 随机选择父代的一个位置xi作为起点,并将该点作为子代的第一个基因;
步骤2 分别找出xi在父代X1和X2的位置x1i和x2i。若xi在父代的最后一位,则其下一位是父代的第一位。更新子代Child1:选取父代X1和X2,找出x1,i+1和x2,i+1所在父代中对应的基因,计算x1i与x1,i+1及x2i和x2,i+1间的距离,若d(x1ix1,i+1)≥d(x2ix2,i+1),则将x2,i+1作为子代Child1中xi的后一位基因,否则将x1,i+1作为xi的后一位基因。更新子代Child2:选取父代X1和X2中找出x1,i-1和x2,i-1所对应的基因,计算x1i与x1,i-1及x2i和x2,i+1间的距离,若d(x1ix1,i-1)≥d(x2ix2,i-1),则将x2,i-1作为xi的后一位基因,否则将x1,i-1作为子代Child2中xi的后一位基因。
步骤3 将xi从父代X1和X2中删除,得到X′1和X′2。
步骤4 将步骤2中得到的基因作为新的起点。
步骤5 循环步骤2~步骤4,当子代Child1和Child2中的基因个数均为N,则循环结束,得到最终的Child1和Child2。
如图2所示,对于有8个客户点的CVRP,随机选取图2(a)所示两个个体X1和X2,以5为起点,作为染色体Child1和Child2的第一位。图2(b)和图2(e)分别是父代X1和X2经过步骤2~步骤4一次更新得到的个体,并确定1和3作为Child1和Child2的下一位基因。当子代中基因个数都为8时,循环结束得到图2(c)和图2(f)所示的Child1和Child2。

图2 基于贪婪策略的启发式交叉算子交叉过程
2.4 变异算子
由于随机变异算子变异范围较大,不利于算法的局部寻优,于是本文在两点随机交换变异的基础上引入最近邻搜索算子,将变异的范围缩小,以提高局部搜索能力。
最近邻定义为:对于包含n个客户点V={v1,v2,…,vn} 的CVRP而言,任意一个客户点vi(i=1,2,…,n) 的最近邻就是距离该客户最近的k个客户点的集合,记为U={c1,c2,…,ck},k=1,2,…,n。为了衡量vi与近邻点的远近程度,引入近邻度λ,定义式(8),其中d代表vi与集合U中点集的欧式距离,d值越大,则近邻度λ越小,表示距离越远;反之越近
(8)
(9)
(10)
选取两个变异点Cm和Cn的步骤如下:
步骤1 使用式(9)和式(10)分别计算出U中每个点被选择的概率以及前j个点被选择的累计概率;
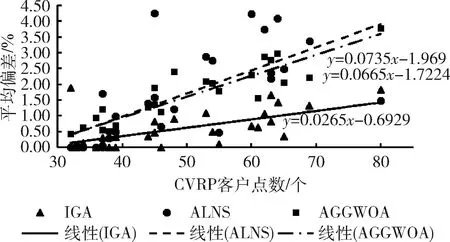
步骤2 分别生成两个0到1之间不重复的随机数r1和r2,若r1≤p1,则近邻点Cm为c1,若pj-1 步骤3 将染色体中近邻点Cm和Cn对应的客户位置互换,得到新的染色体,即完成变异操作。 个体的适应度值大小决定了个体能否被保留和继续进化,个体适应度值越大,被保留下来的概率越大。本文以个体所对应的配送距离的倒数作为个体的适应度,配送距离越长则适应度值越小。适应度计算公式为 (11) 选择策略决定了个体是否能保留下来继续进化。常用的轮盘赌选择法是比例选择的一种,个体被选择的概率与其适应度值大小成正比。但由于该方法是基于概率的选择,往往会产生较大误差,有时适应度值大的个体也无法被选中。相比于轮盘赌法,精英选择策略能把当代适应度值最好的个体保留下来继续进化,也能很好地保留种群的多样性,缺点是局部最优个体不易被淘汰。鉴于两种方法的优缺点,本文采用精英选择策略和轮盘赌法结合的方式进行个体的选择,具体操作步骤如下: 步骤1 将交叉和变异操作产生的新个体与父代种群合并,并删除重复个体,得到种群M; 步骤2 将剩余个体按照适应度值大小降序排列; 步骤3 从排列中选取数量为N/2个适应度值最大的个体; 步骤4 根据公式计算 (M-N/2) 个剩余个体被选中的概率 (12) 步骤5 使用轮盘赌法选取N/2个个体; 步骤6 将步骤3和步骤5中得到的个体合并组成新的种群。 为提高算法的局部搜索能力,本文使用单点局部插入算子,在邻域搜索的基础上寻找更好的可行解。对于x1、x2和x3这3个点,若d(x1,x2)≤d(x2,x3),则以点x2为圆心,d(x2,x3) 为半径画圆,将在圆内但不包含点x2和点x3的所有点组成集合W。优化时将点x2依次插入集合W中的所有点的下一位,得到一组新的可行路径,将可行路径的适应度值与初始路径适应度值进行对比,将适应度值优者更新为当前路径。如图3(a)所示为一个配送中心以及2辆车构成的初始配送路径,vehicle1和vehicle2对应的两条配送路线存在交叉,以d(x2,x3) 为半径的圆包括3个点,使用单点局部插入策略后得到图3(b)~图3(f)所示的5组可行路径,将5组可行路径进行对比,图3(c)的路径长度最短,则使用该路径为当前路径。 图3 单点局部插入算子 输入:算例数据集、种群规模N、变异概率Pm、交叉概率Pc、最大迭代次数Gmax、最近邻搜索范围K。 输出:最优解f(x*)。 (1)根据2.2节初始化种群X={X1,X2,…,XN},Xi={xi1,xi2,…,xin},i=1,2,…,n; (2)计算初始种群中个体的适应度值f(Xi),i=1,2,…,n; (3)While 判断算法是否满足终止条件,满足则解码后输出最优解f(x*),否则执行下一步操作; 根据2.3节使用基于贪婪策略的启发式交叉算子进行交叉操作; 再按照变异概率选出n个个体根据2.4节进行变异操作; 将交叉和变异产生的个体与父代个体合并,根据2.6节的选择策略选出N个个体; 根据2.7节对算法进行局部优化; (4)End while. 本文选取CVRP标准算例库中SetE、SetA和SetP的部分算例对本文算法进行测试,算例源自于http://vrp.atd-lab.inf.puc-rio.br/index.php/en/,算法程序在Matlab r2018a中编写,计算机操作系统为Windows7,运行内存大小为8.0 GB,处理器为四核酷睿i5-3470@3.2 GHz.经过反复测试,本文实验参数选取如下:初始种群规模N=100,最大迭代次数Gmax=300,变异概率为Pm=0.1,最近邻搜索范围K=10,启发式交叉算子的交叉概率为Pc=0.8。 对比实验中所有算例结果皆由算法独立运行20次,表中下划线加粗字体表示算法求得最优解,NA表示文献未对该算例进行求解,其中Opt为目前已文献最优解,Best表示最优解,Worst表示最差解,Er表示最优解偏差,Mr表示平均偏差,Time为运算时间,单位s,Average为平均值,最优解偏差和平均偏差分别可用式(13)和式(14)计算 (13) (14) (1)实验1 选取CVRP算例集中SetE的9个算例,将本文的IGA与GA作比较,GA实验参数设置为N=100、Gmax=300、Pm=0.1、Pc=0.8。计算结果对比见表1。实验结果显示,本文IGA能在9个算例中找到其中的5个最优解,最优值偏差仅为0.36%,GA为1.96%,求解最优值偏差降低了81.63%;在求解精度上,IGA的平均值偏差在1%以内,而GA为3.16%,求解平均偏差降低了70.25%;在求解时间上,IGA对9个算例的平均求解时间为73.20 s,而GA的平均求解时间为581.42 s,求解时间减少了87.41%,表明改进遗传算法求解CVRP的效率明显高于传统遗传算法。 表1 GA和IGA求解CVRP SetE类算例结果比较 (2)实验2 选取CVRP算例集中SetA的27个算例,对比已发表文献中的算法LNS-ACO[4]、ALNS[7]、AGGWOA[8]、EFFA[9],对本文IGA的优化效果进行分析,表中下划线加粗体表示最优解,NA表示该文献未对算例进行求解,计算结果见表2。求解结果中,本文IGA在27个算例中能求得其中的15个最优解,优于AGGWOA算法的13个以及ALNS算法的9个最优解,略差于LNS-ACO的17个最优解。5种算法求解结果的最优解偏差都在1%以内,本文IGA的最优解偏差仅为0.17%,优于其它4种算法;在求解精度方面,本文IGA求解的平均偏差为0.62%,优于ALNS的1.81%和AGGWOA的1.57%。在求解时间上,文献[5-7]未给出求解时间,本文IGA平均求解时间为86.07 s,LNS-ACO为2336 s。 (3)实验3 选取CVRP算例集中SetP中的20个算例,测试结果见表3。实验结果显示:本文IGA在20个算例中能求得13个最优解,优于所对比算法ALNS的8个、AGGWOA和LNS-ACO的12个最优解。在求解精度方面,本文IGA的最优解偏差为0.11%,优于ALNS的1.15%、AGGWOA的0.22%,EFFA的0.52%以及LNS-ACO的0.32%;本文IGA求解结果的平均偏差为0.67%,优于ALNS的1.81%和AGGWOA的1.27%。在求解时间上,LNS-ACO平均耗时2078 s,本文IGA平均耗时为77.42 s。 表3 ALNS、AGGWOA、EFFA、LNS-ACO和IGA求解CVRP SetP类算例结果比较 图4和图5展示了ALNS、AGGWOA和IGA求解SetA类算例的平均偏差回归曲线,图4中3种算法的平均偏差斜率分别为kALNS=0.0735,kAGGWOA=0.0665,kIGA=0.0265,图5中kALNS=0.0428,kAGGWOA=0.0527,kIGA=0.0305。和其它两种算法对比,IGA求解平均偏差回归曲线的斜率最小,表明随着客户数量的增多,3种算法的求解平均偏差都逐渐增大,但IGA增加的最慢。由此可知:IGA求解性能稳定性强于所对比的两种算法。 图4 SetA类算例求解平均误差回归曲线 图5 SetP类算例求解平均误差回归曲线 图6分别是算例En22k4、Pn51k10和An80k10的最优路径图和迭代图,由迭代图可以看出,本文所提算法的求解速度较快,求解性能较好,能使用较少的迭代次数找到最优解。 图6 最优路径及算法迭代 综合以上实验,在求解CVRP时,本文提出的IGA对比传统遗传算法具有求解速度快,精度高的优势,对比算法ALNS、AGGWOA、EFFA、LNS-ACO这4种算法,也具有较好的优化效果,说明该IGA是求解CVRP的有效算法。 遗传算法求解CVRP的效率和精度受多种因素的影响,如初始种群生成、种群数量、交叉和变异算子、选择算子、评价方法等,本文主要研究了交叉算子和变异算子对算法求解CVRP性能的影响,并针对传统遗传算法的不足提出了改进策略。 (1)随机交叉算子虽有利于全局寻优,但也增大了无效搜索的概率,基于贪婪策略的交叉算子不仅能加快算法寻优速度,在全局寻优上也有较好表现。变异操作能使种群产生新的个体,但随机变异范围过大,会降低算法的搜索效率,引入最近邻搜索算子,能有效缩小变异范围,提高算法局部搜索能力。 (2)通过实例验证分析,本文提出的改进遗传算法能有效克服传统遗传算法的缺点,求解CVRP时具有求解速度快,精度高,稳定性好的优点,说明本文算法能有效求解CVRP,对解决此类组合优化的问题具有一定的参考价值。2.5 适应度评价
2.6 选择策略
2.7 局部优化

2.8 改进遗传算法伪代码
3 算例验证和结果分析
3.1 实验环境及参数设置
3.2 实验与结果分析




4 结束语
猜你喜欢
大学教育科学(2022年6期)2022-12-06
——基于人力资本传递机制
贵州财经大学学报(2022年5期)2022-11-16
计算机仿真(2022年8期)2022-09-28
数学物理学报(2021年2期)2021-06-09
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
东北财经大学学报(2017年6期)2017-12-15
——基于子女数量基本确定的情形
中南财经政法大学学报(2017年1期)2017-02-08
数学物理学报(2016年3期)2016-12-01
中国塑料(2016年11期)2016-04-16
