
基于CNN-BLSTM-XGB的入侵检测
2024-03-21 01:48徐东方徐洪珍邓德军
计算机工程与设计 2024年3期
徐东方,徐洪珍,2,3+,邓德军
(1.东华理工大学 信息工程学院,江西 南昌 330013;2.东华理工大学 软件学院,江西 南昌 330013;3.东华理工大学 江西省网络空间安全智能感知重点实验室,江西 南昌 330013)
0 引 言
网络入侵检测可分为基于误用和基于异常的检测方式[1,2]。基于误用的网络入侵检测采用预定义的已知攻击模式,对已知网络攻击具有较高的检测准确率,但不能检测新的网络攻击类型,具有一定的局限性[3]。基于异常的网络入侵检测通过分析用户行为,对网络入侵进行监测,定义常规用户活动特征模型,将网络入侵事件分为正常或异常。因此,该方法可以检测新的攻击。基于异常的网络入侵检测通常通过训练由机器学习或深度学习组成的网络模型来检测网络中存在的异常行为[4]。但随着攻击类别的多样化和网络流量的激增,传统机器学习算法对大规模网络入侵数据的高维性和非线性特征的处理具有一定的局限性,难以适应新型的网络攻击环境,而深度学习算法由于具有较优的深层特征提取能力而被广泛用于网络入侵检测领域[5]。
本文提出一种基于CNN-BLSTM-XGB的混合网络入侵检测方法,从入侵检测数据时间和空间层面进行特征提取,采用XGBoost完成对特征信息的识别、分类,在NSL-KDD和CICIDS2017两种数据集上可以更高效、更准确地实现网络入侵数据的多元分类。
1 相关研究
针对基于深度学习领域网络入侵检测方法的研究,Jia等[6]使用信息熵来确定深度置信网络(deep belief network,DBN)中隐含神经元的数目和网络深度,获得较高的检测精度。Rao等[7]采用平滑L1正则化来加强自编码器(Autoencoder,AE)的稀疏性,利用深度神经网络(deep neural networks,DNN)对攻击类别进行分类,该方法在检测率和误报率方面均优于传统模型。Li等[8]针对网络入侵数据时序特征检出率低问题,提出GRU-RNN网络模型,该模型采用NSL-KDD数据集进行多分类评估。Ma等[9]为了提升网络入侵数据的时序感知力,使用WaveNet对卷积进行堆叠操作,BiGRU对模型进行训练与分类,通过NSL-KDD、UNSW-NB15和CICIDS2017这3个数据集进行分类评估以验证模型的性能。Abdulhammed等[10]使用主成分分析(principal component analysis,PCA)作为网络入侵数据降维,然后采用随机森林(RF)对PCA处理后的CICIDS2017数据集进行二分类与多分类实验。为了充分提取网络入侵数据的空间与时序特征信息,Abdallah等[11]将CNN与LSTM组合,从数据的时间和空间层面进行考虑,通过InSDN数据集进行评估,在二元分类取得较高的检测准确率。但该方法将LSTM直接用于CNN网络后面进行时间特征提取,经CNN提取后的特征信息输入到LSTM,损失了部分时序信息。
虽然目前研究者们对网络入侵检测的研究方法已经取得了较高的检测准确率,但还存在以下问题:第一,单一模型无法充分提取网络入侵的多种数据特征信息。例如,CNN可以学习网络入侵数据的空间特征,而LSTM可以对数据的时序特征进行提取。多模型的结合会提取到更全面更充分的特征信息。第二,网络入侵多分类准确率偏低。现有的方法研究大多数基于异常和正常进行二元分类,事实上网络入侵检测的攻击类型有很多种,对不同攻击数据进行标记,检测难度要高于二元分类问题。
2 基于CNN-BLSTM-XGBoost的混合网络入侵检测
本文在对网络入侵数据进行预处理的基础上,采用CNN与BLSTM结合搭建网络特征提取结构,可以比单一神经网络提取到更加全面的特征信息,且可以从前后两个方向提取网络数据集中隐藏的时间序列信息。另外,传统神经网络采用softmax激活函数构建的单层分类器,容易受到噪声数据的影响,造成分类精度降低,而XGBoost可以克服单一分类器对网络入侵检测数据分类的不足[12]。因此,本文结合CNN、BLSTM和XGBoost各自的优势,提出基于CNN-BLSTM-XGBoost的混合网络入侵检测方法,具有更好的网络入侵检测多分类准确率。图1、图2分别给出本方法的整体框架和CNN-BLSTM-XGBoost网络模型。

图1 基于CNN-BLSTM-XGBoost的网络入侵检测框架

图2 CNN-BLSTM-XGBoost网络模型
2.1 数据预处理
2.1.1 独热编码
独热编码通过将离散特征映射到欧式空间,可以更好地计算离散特征之间的距离,有利于提高模型的运算效率。NSL-KDD数据集中存在3个离散特征值:“flag”、“pro-tocol_type”、“service”。原始NSL-KDD数据集已划分好相应的训练集和测试集,但测试集中“flag”、“protocol_type”、“service”特征维度比训练集少6个类别信息。对训练集和测试集的3个特征分开进行独热编码,会造成生成的数据相差6个特征维度。因此,本文首先把训练集和测试集合并,再统一进行独热编码处理。经独热编码量化后,数据由原来的42维变为121维数据。CICIDS2017数据集没有相关离散特征,无需进行独热编码处理。
2.1.2 数据清洗
数据清洗通过检查数据的一致性,处理数据集中的无效值和冗余信息,可以有效提高用于训练模型的数据质量。对两个数据集中的Nan值分别进行填零处理。CICIDS2017数据集中每个数据包含84个特征字段,但存在一些冗余数据,如:“Flow ID”、“Source IP”、“Source Port”、“Destination IP”、“Protocol”和“Time stamp”特征字段,网络入侵检测反应的是具有网络行为的特征信息,而这6个字段为特定网络标识的特征字段,因此归为冗余特征,进行删除,每条样本特征维度由84个减少为77个。CICIDS2017数据集中的“Flow Bytes/s”与“Flow Packets/s”特征包含“infinity”值,在处理这些数据通常有两种处理办法,一种是直接删除,另一种是替换特征列中的最大值,本文采用的是后者,通过检索相同特征列中最大值进行替换。原始数据经数据清洗处理可以有效避免对模型训练产生影响。
2.1.3 标准化处理
数据的标准化处理使得数据与原始数据保持相同的线性关系,有助于提高模型的收敛速度和精度。本文采用的标准化公式如下
(1)
式中:r为原始数值特征,z为标准化后的值,μ与s分别为特征数值的平均值与标准差。
2.2 CNN-BLSTM-XGBoost网络模型
CNN-BLSTM-XGBoost网络模型如图2所示,其中特征提取、特征融合和检测分类的过程如下。
2.2.1 特征提取


图3 BLSTM 网络结构
CNN与BLSTM的相互独立化设定有助于最大化提取网络入侵数据的特征信息。网络入侵数据的特征提取具体过程如下:
(1)利用CNN提取空间特征的步骤如下:
步骤1 将经过预处理的网络入侵数据传入卷积层;
步骤2 通过第一个双层卷积提取浅层网络入侵数据的空间特征信息,并通过权值共享,降低模型复杂度,这里采用ReLU函数对提取特征信息做非线性映射。ReLU函数表示为
f(x)=max(0,x)
(2)
步骤3 采用最大池化层对上述双层卷积进行2倍欠采样,对提取的特征信息降维处理,以减少计算量;
步骤4 重复第二步和第三步提取深层网络入侵数据的特征信息;
步骤5 利用BN缓解网络梯度消失,提高模型训练速度;
步骤6 加入参数为0.3的丢弃层,防止过拟合;
步骤7 将提取特征信息扁平化,输入全连接层,输出空间特征信息,记为X1。
(2)利用BLSTM提取时序特征信息的步骤如下:
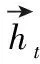
(3)
(4)

(5)

步骤2 经BLSTM处理,将输出序列yt依次输入BN层、参数为0.3丢弃层和Flatten层进行处理,输出时序特征信息,记为X2。
2.2.2 特征融合
使用Keras序贯模型中Concatenate层[15]对CNN和BLSTM提取的特征信息进行融合,保存CNN-BLSTM的网络结构与权重信息,输出网络图层,网络图层包含CNN-BLSTM模型的网络结构与权重信息。图4给出了详细的特征融合结构信息。

图4 特征融合的结构信息
特征信息融合的步骤如下:
步骤1 Concatenate层融合X1,X2特征信息为总特征输出信息;
步骤2 输出网络图层,用于XGBoost模型的加载使用。
2.2.3 检测分类
极端梯度提升(eXtreme gradient boosting,XGBoost)[16]是一种强大的分类和回归方法,以弱预测模型集成的形式产生最终预测结果。与其它集成算法相比,XGBoost具有更快、更准确的优势[17]。
经特征融合层输出的融合特征信息仅包含各个攻击特征类别信息,但XGBoost模型输入数据形状需要同时包含样本总数和特征个数。因此,本文通过XGBoost调用Keras中的model类获取CNN-BLSTM模型的输入层到Concatenate层的网络结构,即获取网络图层。网络图层输出的特征信息用于XGBoost模型输入,经XGBoost模型训练输出最终的检测分类结果。XGBoost检测分类可归结为构建树的过程,通过对目标函数(obj)进行优化,分数越小,树的结构越好,分类的结果就越准确。
其中,XGBoost构建树的过程如下:
步骤1 XGBoost加载训练好的CNN-BLSTM网络结构与权重信息,获取网络图层,输出经CNN-BLSTM提取的特征信息;
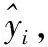
(6)
式中:fj是第j棵树的叶子分数,F表示决策树的集合,表示为

(7)
式中:f(x) 表示其中的一棵树,wq(x)代表叶节点的权重,q表示每棵树的结构,T表示树中叶子节点个数,即表示每个分支预测的攻击类别。Rm→T表示将样本映射到对应的叶子节点,该模型的目标是从n个训练样本集中学习k棵树;
步骤3 通过最小化目标函数优化最终结果,目标函数L(t)表示为
(8)

(9)

(10)
(11)

L(t)≈

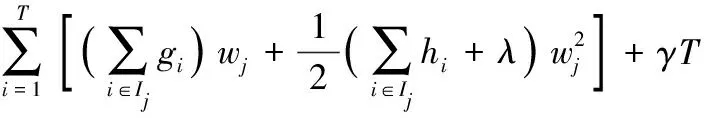
(12)
式中:Ij={i|q(xi)=j} 表示叶子t的实集,gi表示损失函数的一阶导数,hi表示损失函数的二阶导数,可分别表示为
(13)
(14)


(15)
(16)
步骤6 算法结束,输出分类检测结果。
3 实验及结果分析
3.1 实验环境
本实验采用window11系统,AMD Ryzen 75800H CPU,内存8.0 GB,显卡NVIDIA GeForce RTX 3060,采用Python3.9,Keras深度学习框架进行实现。
3.2 实验数据集
本文采用目前主流的NSL-KDD数据集和CICIDS2017数据集分别对提出的方法进行评估。NSL-KDD数据集克服了KDD cup99数据集的缺点,广泛应用于网络入侵检测方法的评估[18],共包含DoS、Probe、R2L和U2R这4种异常类型的样本和一个正常类型样本。这些样本被细化为39种攻击类型,表1为对数据划分后的数据分布情况。

表1 NSL-KDD数据集
CICIDS2017数据集[19]是最新的网络入侵检测数据集之一,包含良性和最新的攻击类型数据,类似真实世界数据(PCAPs),通过使用加拿大研究所网站公开提供的CICFlowMeter软件,对数据集进行完整的标记。数据采集共计5天时间,包含2 830 473条数据样本,每条记录包含83个不同的特征与一个标签列,标签类别包含一个良性类别和14种攻击类型数据,具体的采样信息见表2。

表2 CICIDS2017数据集
3.3 评价指标
为了评估模型的检测性能,使用精确率(precision)、召回率(Recall)、F度量(F1score)和准确率(Accuracy)作为评价指标。这些指标通过使用4种度量来计算,即真阳性(TP):正确分类的异常记录的数量。真阴性(TN):正确分类的正常记录数量。假阳性(FP):分类错误的正常记录数量。假阴性(FN):错误分类的异常记录数量。
准确率:真实样本检测与总记录的百分比
(17)
精确率:精度是正确预测的攻击与总预测攻击的比例
(18)
召回率:表示预测为正类样本数量与正类样本总数的比例
(19)
F度量:表示精度和召回率指标的调和
(20)
3.4 实验设置及结果分析


图5 CNN-BLSTM模型损失(NSL-KDD)
由图5、图6所示,CNN-BLSTM模型迭代次数分别在80和90次达到收敛,数据集的不平衡性导致验证集在前期训练过程中拟合性不是很好。图7、图8为XGBoost模型训练的损失曲线,在NSL-KDD数据集上,训练次数在600收敛,在CICIDS2017数据集上训练至1000达到收敛,经CNN-BLSTM提取的特征信息在XGBoost训练模型中拟合性能良好。多分类的实验结果如表3、表4所示。

表3 NSL-KDD数据集的不同攻击类型评估/%

表4 CICIDS2017数据集的不同攻击类型评估/%

图6 CNN-BLSTM模型损失(CICIDS2017)

图7 XGBoost模型损失(NSL-KDD)

图8 XGBoost模型损失(CICIDS2017)
实验给出所有攻击类别的评分结果,由表1、表2给出的样本分布情况,结合表3、表4每种攻击类别的检测率来看,小样本数据的检测准确率、精度等较低。CICIDS2017数据集中“Infiltration”、“Web Attack Sql Injection”和“Heartbleed”攻击类型检测精确率为1,反应异常,实则为模型的误判;根据表2中的样本分布,这3类数据占比可以忽略不记,样本过少,导致模型在训练过程中偏向多类别数据,难以学习到少数类数据的特征信息,很难被模型识别,因此容易产生误判。小样本数据一般属于罕见攻击类型,对于样本中大部分特征,模型具有良好的检测率,说明CNN-BLSTM设计的合理与有效性,可以充分学习到样本的类别信息,因此可以很好区分每种攻击数据的类型。
由表5结果显示,本文提出的方法与CNN、CNN-BLSTM模型分类相比,在精确率等评价指标均有一定的提升,CNN-BLSTM与CNN对比,模型准确率等也有小幅度提升,验证BLSTM的增加对网络入侵数据中时序特征提取的有效性。CNN-BLSTM与XGBoost模型的结合,两种数据集的检测准确率均有提升,也验证了采用XGBoost模型替换带有softmax激活函数全连接层的有效性。为了进一步说明本方法的效果,本文还与现有的一些类似工作进行了对比。Abdallah等[11]提出CNN-LSTM的网络入侵检测方法,使用InSDN数据集进行评估,本文根据文献中提供的网络结构以及相关参数使用本文数据集进行方法复现。与其它方法对比情况见表6。

表5 自身模型多分类对比/%
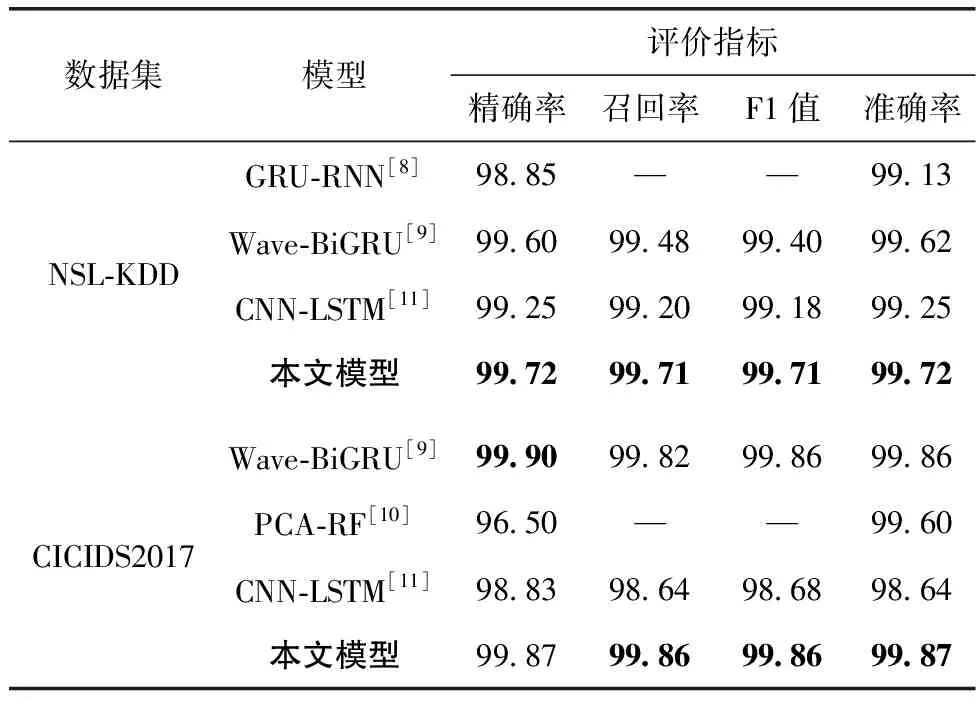
表6 与其它模型多分类对比/%
文献[11]的方法与表5中本文设计的CNN-BLSTM模型相比,在NSL-KDD数据集上检测准确率高0.01个百分点,但是在CICIDS2017数据集上表现不如本文构建的CNN-BLSTM模型。从表6可以看出,本文研究方法,总体表现优于其它方法。CICIDS2017数据集中的精确率比文献[9]略低,但是在NSL-KDD数据集上,本文方法具有更好的表现力。总体来说,本文提出的网络入侵检测方法具有较高的检测准确率。
4 结束语
当前的网络入侵检测方法无法充分且全面提取网络入侵特征信息,因而无法对攻击信息进行良好的分类。本文提出的CNN-BLSTM-XGB入侵检测方法可以充分且全面挖掘入侵数据的时空特征信息,在两种不同的网络入侵公开数据集进行方法评估,均具有较高的检测准确率。同时也给出具体攻击类别的检测结果,除了数据中的罕见攻击类型产生误判,其它攻击类型均具有良好的检测准确率。考虑到小样本攻击类型数据量少,很难被模型学习到,而GAN在图像数据平衡方面已取得一定的成效,下一步工作将GAN引入网络入侵数据平衡处理部分,或许会取得不错的平衡效果。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
