
基于样本原生特征的投毒防御方法
2024-03-21 01:48:02刘枭天郝晓燕陈永乐
计算机工程与设计 2024年3期
刘枭天,郝晓燕,马 垚,于 丹,陈永乐
(太原理工大学 信息与计算机学院,山西 晋中 030600)
0 引 言
目前,投毒防御是对机器学习模型在训练阶段遭受攻击的主要防御方式,针对数据投毒攻击的通用防御方法主要有两种,一是Diakonikolas等[1]提出的Sever,该算法使用基础学习器实现投毒防御;二是Chen等[2]提出的De-Pois,通过比较模型之间的预测差异,实现投毒防御。已有的通用防御方法主要存在的问题如下:①均难以保证数据集不被污染,需要在保证数据集“干净”的前提下进行防御;②均难以对未知模型进行防御。
针对机器学习数据集安全方面的问题,考虑对数据集中的样本进行检测,剔除数据集中的恶意样本,从而保证数据集的“干净”。在数据集制作过程中,一些离群点、异常值,即扰动较大的恶意样本可以通过数据清洗等方式剔除出去,但只添加极少扰动的样本——投毒样本却仍存在于数据集中。在数据投毒攻击领域,投毒样本经模型训练后,改变了模型分类边界,从而降低模型的预测准确率,由于投毒样本中添加的扰动很小,投毒样本原有的特征并没有大幅度改变。受此启发,将投毒样本的原生特征与人为特征分离后,提高模型对样本原生特征的训练权重,即可实现样本的正确分类。
基于此,本文设计一种投毒样本原生特征的提取方法,采用耦合infoGAN结构实现样本原生特征与人为特征的分离与提取;构建了一个重构投毒样本的原生特征的网络框架,实现对投毒样本的检测及对机器学习模型的防御。
1 相关工作
机器学习模型的非健壮性促进了投毒防御方法的发展。根据防御对象的不同,针对数据投毒攻击的防御方法又可分为针对特定类型攻击的防御方法和通用投毒防御方法两大类。
针对特定类型攻击的防御方法包括基于标签翻转的投毒防御[3,4]、基于Clean-label的投毒防御[5-7]、基于训练生成模型的投毒防御[8,9]和基于最优训练集的投毒防御[10-13]。这些防御方法都是针对特定类型的数据投毒攻击进行防御,当涉及针对不同学习任务的攻击时,其防御效果会变差;而现有的通用防御方法主要有Server和De-Pois,Diakonikolas等[1]提出的Sever,该算法在存在离群点及异常值的情况下具有很强的理论鲁棒性,但由于该算法难以拟合各种未知DNN模型,因此可能会防御失败;Chen等[2]提出的De-Pois,该算法需要训练一个模拟模型,通过比较模拟模型和目标模型之间的预测差异,区分投毒样本和正常样本,但由于在构建模拟模型的过程中,很难保证数据集不被污染,因此,训练出来的模拟模型很难保证其预测准确率。到目前为止,在数据投毒防御领域,很少有防御效果较好的通用防御策略。
针对样本特征分离这一难题,在对抗防御领域,Pouya Samangouei等[14]和Jin等[15]利用GAN模型生成了对抗样本的近似样本,该近似样本满足干净样本特征分布,即提取了对抗样本的鲁棒性特征,从而实现对抗防御。然而这种基于GAN结构的防御方法直接在原始数据集上进行样本特征提取,增加了防御的复杂性和难度,同时存在计算时间长、实现效率低的缺点。
2 基于样本原生特征的投毒防御
由于infoGAN结构可以训练得到数据集中有意义的图像特征,使模型学习到样本的可解释性特征,因此本文采用耦合infoGAN结构实现样本原生特征与人为特征的分离与提取,生成样本的防御标签,构建了机器学习模型的整体防御框架,最后给出投毒样本特征提取算法及投毒样本检测算法,并详细说明投毒防御方案infoGAN_Defense。
2.1 样本的特征表示
机器学习模型由输入层、隐藏层及输出层组成。本文用f(x)表示模型将输入示例x传播到倒数第二层(隐藏层最后一层)时对应的函数,用f(X)表示样本集X传播到倒数第二层时对应的函数。
定义1 样本原生特征及人为特征:样本原生特征指在模型正确分类时样本所依赖的特征,人为特征指攻击者为欺骗模型所精心设计的微小扰动。给定一个样本集对
2.2 基于样本原生特征的投毒防御框架
在数据投毒攻击中,样本特征被修改的投毒样本利用其人为特征欺骗模型,使得攻击者攻击成功;标签被修改的投毒样本虽然在输入空间内的数据特征并未发生改变,但经模型训练后,该样本在特征空间内的高维特征与其对应的基类样本的高维特征分别所属不同的类别,改变了模型训练集中原有的数据分布,从而改变模型的分类边界,导致模型误分类,降低了模型的预测准确率。
因此,本文将问题表述如下:对于机器学习模型来说,模型所依赖的训练集中数据的特征及标签均有可能受到污染,即当模型遭受攻击时,模型训练到的是投毒样本的人为特征,此时投毒样本在特征空间内的高维特征会发生变化,改变模型原来的分类边界,因此,本文首先设计了一种投毒样本特征提取算法,使目标模型经过训练后可以关注到投毒样本的原生特征,从而实现对投毒样本的正确分类;之后本文设计了投毒样本检测器,可以检测并移除机器学习模型训练集中的投毒样本;最后,本文通过得到的样本正确标签更新训练集,重新训练模型,实现了目标模型对投毒样本的正确分类,保证了模型在预测阶段对样本的预测准确率。(模型防御框架如图1所示)。

图1 模型防御框架
基于样本原生特征的投毒防御主要包括3个步骤:
(1)分离并提取投毒样本的原生特征及人为特征。进行投毒防御的第一步是有效分离并提取投毒样本的原生特征与人为特征,通过训练,使得模型提高对投毒样本原生特征的训练权重,即是模型关注到投毒样本的原生特征。本文利用鉴别器共享参数的耦合infoGAN结构实现特征分离及提取。
(2)投毒样本检测算法的设计。由于投毒样本在模型训练前后所属类别会发生变化,本文在获取样本的正确标签后,通过比较样本在模型训练前后的标签是否发生变化,实现了投毒样本的检测及移除。若标签发生改变则为投毒样本,反之,则为基类样本。
(3)实现模型防御。本文将训练集输入到机器学习模型中进行训练,将隐藏层输出的样本高维特征作为耦合infoGAN结构的输入,利用infoGAN结构重构样本原生特征和人为特征,之后利用模型的softmax层生成样本正确的防御标签,最后,模型使用更新标签后的训练集重新训练,生成新的模型,这就是模型的防御机制。
2.3 投毒样本特征提取器设计
实现投毒防御的关键在于建立高效的投毒样本特征提取算法,而使用样本的高维特征作为耦合infoGAN结构的输入,不仅可以简化耦合infoGAN结构分离提取样本原生特征与人为特征的过程,同时能加快耦合infoGAN结构的收敛速度。为了使模型达到防御多种类型投毒攻击的目的,本文提出了一种基于生成对抗网络的投毒样本特征提取算法,该算法利用耦合infoGAN结构实现样本原生特征与人为特征的分离与提取。
本文采用两个infoGAN模型结构同时进行训练的方式实现需求,降低了训练过程的复杂度。同时本文采用infoGAN模型鉴别器共享参数的方式实现对生成数据的判定,这种方式使得当投毒样本输入到鉴别器时,可以捕捉到投毒样本的原生特征,从而提高投毒样本原生特征提取的准确性。图2为投毒样本特征提取器的设计原理,其中,投毒样本特征提取器由两个infoGAN模型耦合而成,在样本高维特征输入到infoGAN模型中后,生成器A与生成器B分别用于生成样本的原生特征与人为特征,之后利用鉴别器进行分类并反馈分类结果,生成器得到反馈结果后,继续更新infoGAN模型参数,直到infoGAN模型收敛。在投毒样本提取特征的过程中,一方面,基类样本集与投毒样本集分别输入到两个infoGAN模型中,保证了样本原生特征与人为特征提取的独立性;另一方面,两个infoGAN模型的鉴别器会通过共享参数的方式进行更新,从而提高了infoGAN模型对投毒样本原生特征的关注度。(投毒样本特征提取器如图2所示)
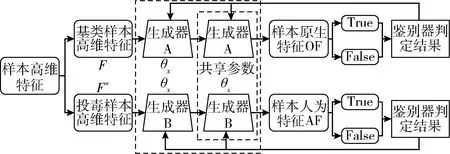
图2 投毒样本特征提取器
本文将模型训练所得的样本高维特征输入到耦合infoGAN模型中,实现投毒样本的特征提取。算法1给出了投毒样本特征提取的形式化描述。该算法具体按照以下步骤实现特征提取:
(1)首先需要初始化infoGAN模型的参数,并将基类样本高维特征集F=f(X)与投毒样本高维特征集F′=f(X′) 分别作为模型A_infoGAN与B_infoGAN的输入;
(1)
(2)
其中,A_G(·)表示A_infoGAN的生成器函数,B_G(·)表示B_infoGAN的生成器函数;D(·)表示鉴别器对应函数。
(3)将生成的样本原生特征与人为特征分别送至鉴别器A_D与B_D,鉴别器的功能是判断生成的样本特征是否为真,即使得A_D输出A_G(f(x)) 的值为1的概率尽可能低,B_D输出B_G(f(x′)) 为1的概率尽可能低。本文可将A_D与B_D的损失函数量化为
lossA_D=E[logD(f(x))]+E[log(1-D(A_G(f(x))))]-
λI(c;A_G(f(x),c))
(3)
lossB_D=E[logD(f(x′))]+E[log(1-D(B_G(f(x′))))]-
λI(c;B_G(f(x′),c))
(4)
其中,I(·)为正则化约束项,λ为平衡系数,c为附加的隐含编码。由于我们需要使目标模型在特征空间关注到投毒样本的原生特征,因此本文采用鉴别器共享参数的方式进行实现,并可将优化鉴别器参数的目标函数量化为
(5)
(4)本文采用交替优化的方式训练infoGAN模型。鉴别器优化参数后,将鉴别结果反馈至生成器;如果鉴别器 A_D鉴别结果为True,则返回1,反之,返回0;鉴别器B_D亦是如此。而生成器A_G与B_G分别根据得到鉴别结果,基于式(1)、式(2)更新生成器参数,直到模型收敛。
算法1:投毒样本特征提取算法
输入:基类样本集X、投毒样本集X′、基类样本高维特征集F=f(X)、投毒样本高维特征F′=f(X′)
(1)Initialize(A)
(2)Initialize(B)
Repeat
(7)根据式(5)更新鉴别器参数;
(8)鉴别器将鉴别结果反馈至生成器;
(9)生成器基于式(1)、式(2)更新生成器参数,生成新一轮的样本特征;
Until 模型收敛
End
2.4 投毒防御方案infoGAN_Defense构建
基于投毒样本特征提取算法,本文进一步提出了投毒防御方案infoGAN_Defense。由于投毒样本特征提取器中的A_G可以使模型提高对投毒样本原生特征的关注度,因此,当我们不明确目标模型的训练集中是否含有投毒样本时,可以将目标模型训练至隐藏层最后一层,并将隐藏层的输出作为A_G的输入,冻结A_G的所有参数,重构样本原生特征并提高其权重,将重构后的样本数据送入目标模型的softmax层进行分类,若样本标签发生改变,则该样本为投毒样本;反之,则为基类样本,这就是投毒样本的检测原理,算法2为投毒样本检测算法的形式化描述。
若在检测出投毒样本之后对该样本标签进行更新,得到标签正确的训练集,然后将更新后的训练集作为目标模型的输入,重新对目标模型进行训练,当训练完成后,模型可以对投毒样本进行正确分类,实现了模型防御。infoGAN_Defense投毒防御方案的形式化描述如算法3所示。
算法2:投毒样本检测算法
输出:投毒样本集P
Repeat
(1)xf←Layer(Tsoftmax)
(2)if (xflabel_begin≠xflabel_new) then
(3)do P←P∪xf
Return 投毒样本集P
End
算法3:infoGAN_Defense投毒防御方案训练算法
输入:样本集X=Xclean∪Xpoison、目标模型T、投毒样本特征提取器A_infoG
输出:更新参数后的目标模型T′
(1)Trainset(T)←X
(2)获取目标模型隐藏层输出Fall
(3)F′all←A_infoG(Fall)
Repeat
(4)x′f←Layer(Tsoftmax(xf))
(5)if (label(xf)≠label(x′f)) then
(6) doxflabel≠x′flabel
Untilxf∉F′all
(7)F″all←update(F″all,X)
(8)X′←update(X,F″all)
(9)Trainset(T)←X′
Return 训练完成的模型T′
End
3 实验分析
本文在MNIST数据集上进行实验,实现基于样本原生特征的投毒防御方案,并与现有典型投毒防御方案进行对比,分析我们提出的投毒防御方案infoGAN_Defense的有效性。
3.1 实验设置
本文选择Tensorflow框架+MNIST数据集进行训练,评估infoGAN_defense的防御效果,其中,MNIST数据集由10个类别手写数字的28×28灰度图像、包含60 000张图像的训练数据集和10 000张图像的测试数据集组成。本实验将会采用卷积神经网络模型进行训练,并评估infoGAN_defense防御效果。
3.2 防御效果分析
本文利用直接梯度法制作所需投毒样本,并将一定比例的投毒样本注入MNIST数据集中,生成新的训练集,之后利用infoGAN_Defense方案进行防御。
首先,本文通过将不同比例的投毒样本注入模型,并分析此时模型的预测准确率变化趋势,评估投毒样本的制作有效性。为更准确地说明实验结果,本文进行多次训练迭代,并选取不同投毒情况下模型的准确率作为评估依据。投毒样本生成有效性评估结果如图3所示,由图3可以看出,在模型未使用防御方案前,我们将生成的投毒样本注入到训练集中明显降低了模型的预测准确率,这就表明我们生成的投毒样本是有效的,成功攻击了模型;而当我们使用防御方案infoGAN_Defense后,模型的预测准确率未出现明显下降的趋势,因此表明,本文所提出的防御方案infoGAN_Defense可以有效提高模型的预测准确率。为了进一步评估防御方案infoGAN_Defense的有效性,我们将infoGAN_Defense与现有的投毒防御方案进行对比,并观察不同防御方案下模型的预测准确率。

图3 投毒样本生成有效性评估
从图3可以看出,随着投毒率的增加,模型的预测准确率逐渐降低,因此本文选择模型平均预测准确率所对应注入样本集的投毒样本比例进行实验。为得出infoGAN_Defense的投毒防御效果,本文将15%的投毒样本注入训练集中进行训练,并选取4种针对特定类型攻击的投毒防御方法与infoGAN_Defense进行防御效果的对比。
图4给出了infoGAN_Defense与现有投毒防御方案的模型预测准确率对比结果(infoGAN_Defense防御效果如图4所示)。由图4可以看出,在针对基于Clean-label的投毒攻击进行防御时,infoGAN_Defense达到与Deep-kNN几乎同样的防御效果;而针对其余3种投毒攻击进行防御时,infoGAN_Defense防御效果明显较好,模型准确率明显提高;同时,我们比较了infoGAN_Defense与通用投毒防御策略De-Pois的防御效果,可以看出,De-Pois在针对基于训练生成模型的投毒攻击进行防御时,防御效果比infoGAN_Defense要差,但比认证防御(certified defense,CD)防御效果好,而infoGAN_Defense均可以有效防御现有的数据投毒攻击,且平均准确率达到90%以上。

图4 infoGAN_Defense防御效果
3.3 算法复杂度对比
在投毒防御算法设计过程中,除算法有效性外,还需要进行算法复杂度分析。现有的投毒防御方法均是直接对原始数据集进行处理,而本文提出的infoGAN_Defense算法处理的是模型训练得到的样本数据高维特征,这就大大降低算法的复杂度,加快了样本特征提取的速度,减少了所需的训练时间。
为验证算法的时间复杂度,本文选用MNIST数据集进行实验,观察并比较4种针对特定类型攻击的投毒防御方法与infoGAN_Defense所需要的训练时间和测试时间。CD、TRIM、De-Pois均需要训练一个新的模型,因此非常耗时;Deep-kNN和标签消毒(label sanitization,LS)需要原始数据集进行处理,相比之下,infoGAN_Defense只需要重构从模型中提取的样本高维特征,因此,训练成本远小于现有的投毒防御方法。infoGAN_Defense复杂度对比结果如图5所示,从图5看出,infoGAN所需的训练时间最短,测试时间与现有方法所需的测试时间接近,综合训练时间与测试时间两个指标来看,infoGAN_Defense算法时间复杂度最低,效率最高。

图5 infoGAN_Defense复杂度对比
4 结束语
随着机器学习在安全关键领域的应用,模型的安全性能尤为重要。现有的通用投毒防御研究可以应对特定类型的投毒攻击,但难以对未知模型进行拟合,导致防御失败。本文从样本特征的角度入手,设计一种投毒样本原生特征的提取方法,构建一个重构样本特征的框架,以完成投毒样本的检测及模型的防御。在MNIST数据集上的防御结果验证了基于样本原生特征投毒防御方法的有效性,并且优于现有的防御技术。未来,我们将进一步研究样本特征提取器算法,旨在提高特征提取的精确度,进一步提升机器学习模型的预测准确率。
猜你喜欢
通信学报(2022年10期)2023-01-09 12:33:40
小猕猴智力画刊(2022年4期)2022-05-05 21:38:36
国防科技大学学报(2019年4期)2019-07-29 03:40:14
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
系统工程与电子技术(2016年5期)2016-11-02 00:37:48
噪声与振动控制(2015年4期)2015-01-01 07:08:21
小雪花·成长指南(2014年8期)2014-08-26 00:57:49
教育与职业(2014年1期)2014-04-17 14:28:07
计算机工程(2013年1期)2013-09-29 05:19:50
